
YOLO-MFD: Object Detection for Multi-Scenario Fires

Abstract
1. Introduction
- We explore image characteristics and target extraction mechanisms for fires, proposing a lightweight detection algorithm for multi-scenario smoke and flame detection. Additionally, to address the current scarcity of data, we created a new fire image detection dataset named Multi-scenario Fire Dataset (MFDB) to facilitate fire image detection across diverse scenarios.
- To address the missed detection issues caused by deformations in smoke and flames, a Scale Adaptive Perception Module (SAPM) is proposed. By superimposing the spatial-domain branch and frequency-domain branch along the channel dimension, and subsequently fusing spatial- and frequency-domain information through pointwise convolution, the module captures rich feature information to enhance the model’s perception capability.
- To address the issue of low detection accuracy in fire image target detection caused by complex background information suppressing critical fire features, we propose a Feature Adaptive Weighting Module (FAWM) that enhances detection precision without increasing computational overhead.
- To improve the detection of small flames and targets in fire images, a fine-grained Small Object Feature Extraction Module (SOFEM) is introduced. By embedding combinations of convolutional receptive fields within a spatial pyramid sampling structure, a finer multi-scale representation is achieved.
2. Related Work
2.1. Traditional Fire Detection Methods
2.2. Fire Detection Based on Deep Learning
2.3. Hybrid Fire Detection
3. Research Method
3.1. Overall Structure
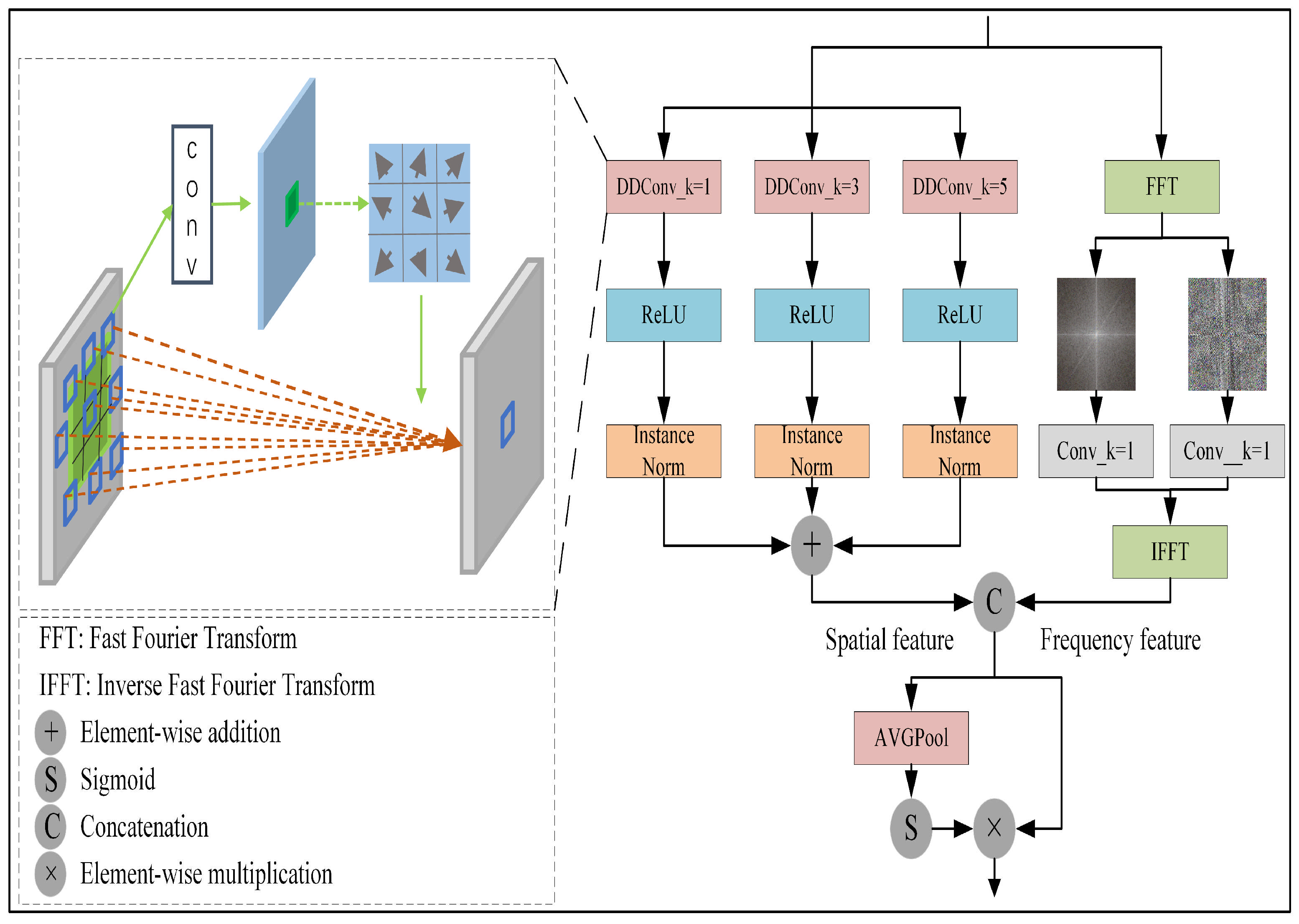
3.2. SAPM
3.2.1. Spatial-Domain Branch
3.2.2. Frequency-Domain Branch
3.3. FAWM
3.4. SOFEM
4. Experiment and Analysis
4.1. Experimental Environment
4.2. Evaluation Metrics
4.3. Dataset
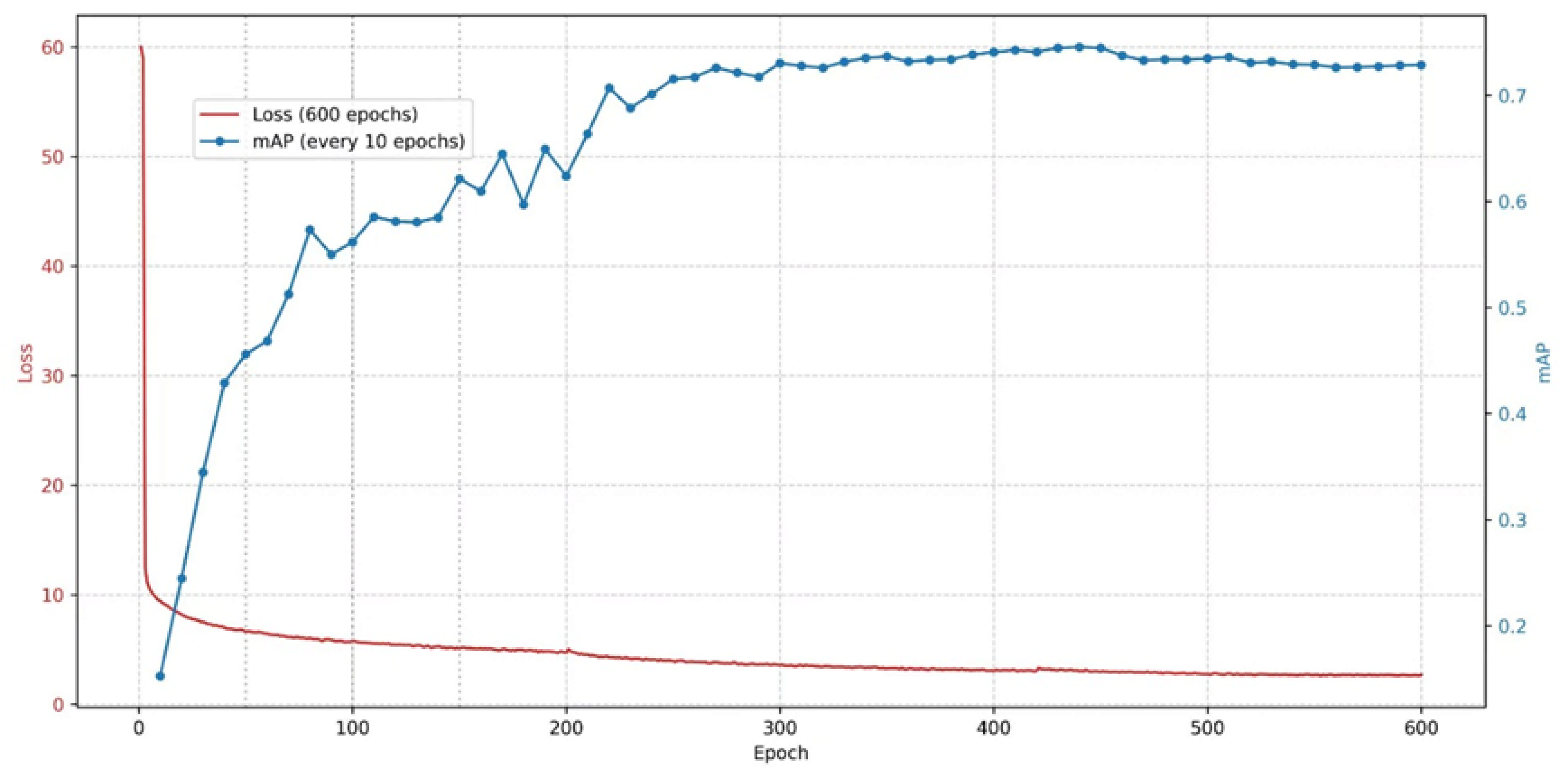
4.4. Ablation Experiment
4.4.1. Ablation Experiment
4.4.2. An Ablation Experiment on SAPM
4.4.3. Overall Comparison
4.4.4. Comparison of Small Targets
4.4.5. Visual Comparison
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tao, C.; Zhang, J.; Wang, P. Smoke detection based on deep convolutional neural networks. In Proceedings of the 2016 International Conference on Industrial Informatics-Computing Technology, Intelligent Technology, Industrial Information Integration (ICIICII), Wuhan, China, 3–4 December 2016; pp. 150–153. [Google Scholar]
- Filonenko, A.; Kurnianggoro, L.; Jo, K.H. Comparative study of modern convolutional neural networks for smoke detection on image data. In Proceedings of the 2017 10th International Conference on Human System Interactions (HSI), Ulsan, Republic of Korea, 17–19 July 2017; pp. 64–68. [Google Scholar]
- Mao, W.; Wang, W.; Dou, Z.; Li, Y. Fire recognition based on multi-channel convolutional neural network. Fire Technol. 2018, 54, 531–554. [Google Scholar] [CrossRef]
- Namozov, A.; Im Cho, Y. An efficient deep learning algorithm for fire and smoke detection with limited data. Adv. Electr. Comput. Eng. 2018, 18, 121–128. [Google Scholar] [CrossRef]
- Luo, Y.; Zhao, L.; Liu, P.; Huang, D. Fire smoke detection algorithm based on motion characteristic and convolutional neural networks. Multimed. Tools Appl. 2018, 77, 15075–15092. [Google Scholar] [CrossRef]
- Jocher, G.; Chaurasia, A.; Qiu, J. YOLOv5 by Ultralytics. 2023. Available online: https://docs.ultralytics.com/models/yolov5/ (accessed on 1 June 2025).
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Qiu, J. YOLOv8 by Ultralytics. 2023. Available online: https://docs.ultralytics.com/models/yolov8/ (accessed on 1 June 2025).
- Ren, J.F.; Xiong, W.H.; Wu, Z.H.; Jiang, M. Fire detection and identification based on improved YOLOv3. Comput. Syst. Appl. 2019, 28, 171–176. [Google Scholar]
- Pi, J.; Liu, Y.; Li, J. Research on lightweight forest fire detection algorithm based on YOLOv5s. J. Graph. 2023, 44, 26–32. [Google Scholar]
- Li, C.; Zhu, B.; Chen, G.; Li, Q.; Xu, Z. Intelligent Monitoring of Tunnel Fire Smoke Based on Improved YOLOX and Edge Computing. Appl. Sci. 2025, 15, 2127. [Google Scholar] [CrossRef]
- Zheng, H.; Duan, J.; Dong, Y.; Liu, Y. Real-time fire detection algorithms running on small embedded devices based on MobileNetV3 and YOLOv4. Fire Ecol. 2023, 19, 31. [Google Scholar] [CrossRef]
- Talaat, F.M.; ZainEldin, H. An improved fire detection approach based on YOLO-v8 for smart cities. Neural Comput. Appl. 2023, 35, 20939–20954. [Google Scholar] [CrossRef]
- Li, J.; Ye, J. Edge-YOLO: Lightweight infrared object detection method deployed on edge devices. Appl. Sci. 2023, 13, 4402. [Google Scholar] [CrossRef]
- Cao, J.T.; Qin, Y.Y.; Ji, X.F. Review on video based flame detection algorithm. J. Data Acquis. Process. 2020, 35, 35–52. [Google Scholar]
- Wang, S.; He, Y.; Yang, H.; Wang, K.; Wang, J. Video smoke detection using shape, color and dynamic features. J. Intell. Fuzzy Syst. 2017, 33, 305–313. [Google Scholar] [CrossRef]
- Ye, S.; Bai, Z.; Chen, H.; Bohush, R.; Ablameyko, S. An effective algorithm to detect both smoke and flame using color and wavelet analysis. Pattern Recognit. Image Anal. 2017, 27, 131–138. [Google Scholar] [CrossRef]
- Chi, R.; Lu, Z.M.; Ji, Q.G. Real-time multi-feature based fire flame detection in video. IET Image Process. 2017, 11, 31–37. [Google Scholar] [CrossRef]
- Han, X.F.; Jin, J.S.; Wang, M.J.; Jiang, W.; Gao, L.; Xiao, L.-P. Video fire detection based on Gaussian Mixture Model and multi-color features. Signal Image Video Process. 2017, 11, 1419–1425. [Google Scholar] [CrossRef]
- Alamgir, N.; Nguyen, K.; Chandran, V.; Boles, W. Combining multi-channel color space with local binary co-occurrence feature descriptors for accurate smoke detection from surveillance videos. Fire Saf. J. 2018, 102, 1–10. [Google Scholar] [CrossRef]
- Gong, F.; Li, C.; Gong, W.; Li, X.; Yuan, X.; Ma, Y.; Song, T. A Real-Time Fire Detection Method from Video with Multifeature Fusion. Comput. Intell. Neurosci. 2019, 2019, 1939171. [Google Scholar] [CrossRef]
- He, A.; Chen, M. Video fire detection based on multi-feature fusion. Softw. Trib. 2020, 19, 198–203. [Google Scholar]
- Kim, B.; Lee, J. A video-based fire detection using deep learning models. Appl. Sci. 2019, 9, 2862. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zaremba, W.; Sutskever, I.; Vinyals, O. Recurrent neural network regularization. arXiv 2014, arXiv:1409.2329. [Google Scholar]
- Thomson, W.; Bhowmik, N.; Breckon, T.P. Efficient and compact convolutional neural network architectures for non-temporal real-time fire detection. In Proceedings of the 2020 19th IEEE International Conference on Machine Learning and Applications (ICMLA), Virtual Event, 14–17 December 2020; pp. 136–141. [Google Scholar]
- Muhammad, K.; Ahmad, J.; Baik, S.W. Early fire detection using convolutional neural networks during surveillance for effective disaster management. Neurocomputing 2018, 288, 30–42. [Google Scholar] [CrossRef]
- Muhammad, K.; Ahmad, J.; Lv, Z.; Bellavista, P.; Yang, P.; Baik, S.W. Efficient deep CNN-based fire detection and localization in video surveillance applications. IEEE Trans. Syst. Man Cybern. Syst. 2018, 49, 1419–1434. [Google Scholar] [CrossRef]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Li, X.J.; Zhang, D.S.; Sun, L.L. Light flame detection method based on CNN in complex scene. Pattern Recognit. Artif. Intell. 2021, 34, 415–422. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Yu, L.; Liu, J. Flame image recognition algorithm based on improved Mask R-CNN. Comput. Eng. Appl. 2020, 56, 194–198. [Google Scholar]
- Aslan, S.; Güdükbay, U.; Töreyin, B.U.; Cetin, A.E. Deep convolutional generative adversarial networks based flame detection in video. arXiv 2019, arXiv:1902.01824. [Google Scholar]
- Xu, G.; Zhang, Y.; Zhang, Q.; Lin, G.; Wang, Z.; Jia, Y.; Wang, J. Video smoke detection based on deep saliency network. Fire Saf. J. 2019, 105, 277–285. [Google Scholar] [CrossRef]
- Lin, G.; Zhang, Y.; Xu, G.; Zhang, Q. Smoke detection on video sequences using 3D convolutional neural networks. Fire Technol. 2019, 55, 1827–1847. [Google Scholar] [CrossRef]
- Wu, S.; Guo, C.; Yang, J. Using PCAand one-stage detectors for real-time forest fire detection. J. Eng. 2020, 2020, 383–387. [Google Scholar] [CrossRef]
- Xu, R.; Lin, H.; Lu, K.; Cao, L.; Liu, Y. A forest fire detection system based on ensemble learning. Forests 2021, 12, 217. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Ghosh, R.; Kumar, A. A hybrid deep learning model by combining convolutional neural network and recurrent neural network to detect forest fire. Multimed. Tools Appl. 2022, 81, 38643–38660. [Google Scholar] [CrossRef]
- Gong, X.; Hu, H.; Wu, Z.; He, L.; Yang, L.; Li, F. Dark-channel based attention and classifier retraining for smoke detection in foggy environments. Digit. Signal Process. 2022, 123, 103454. [Google Scholar] [CrossRef]
- de Venâncio, P.V.A.B.; Campos, R.J.; Rezende, T.M.; Lisboa, A.C.; Barbosa, A.V. A hybrid method for fire detection based on spatial and temporal patterns. Neural Comput. Appl. 2023, 35, 9349–9361. [Google Scholar] [CrossRef]
- Chaoxia, C.; Shang, W.; Zhang, F. Information-guided flame detection based on faster R-CNN. IEEE Access 2020, 8, 58923–58932. [Google Scholar] [CrossRef]
- Wu, H.; Wu, D.; Zhao, J. An intelligent fire detection approach through cameras based on computer vision methods. Process Saf. Environ. Prot. 2019, 127, 245–256. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2018–2026. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.; Yoon, Y.; Kim, I. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-Local Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Dosovitskiy, A.; Springenberg, J.; Riedmiller, M.; Brox, T. Image Transformer. In Proceedings of the 35th International Conference on Machine Learning (ICML), Stockholm, Sweden, 10–15 July 2020. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Padilla, R.; Netto, S.L.; da Silva, E.A. A Comparative Analysis of Object Detection Metrics with a Companion Open-Source Toolkit. Electronics 2020, 10, 279. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J. Yolov10: Real-time end-to-end object detection. Adv. Neural Inf. Process. Syst. 2024, 37, 107984–108011. [Google Scholar]
- Cao, X.; Su, Y.; Geng, X.; Wang, Y. YOLO-SF: YOLO for fire segmentation detection. IEEE Access 2023, 11, 111079–111092. [Google Scholar] [CrossRef]
- Geng, X.; Han, X.; Cao, X.; Su, Y.; Shu, D. YOLOV9-CBM: An improved fire detection algorithm based on YOLOV9. IEEE Access 2025, 13, 19612–19623. [Google Scholar] [CrossRef]
- Khanam, R.; Hussain, M. Yolov11: An overview of the key architectural enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]
- Tian, Y.; Ye, Q.; Doermann, D. Yolov12: Attention-centric real-time object detectors. arXiv 2025, arXiv:2502.12524. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SAPM | FAWM | SOFEM | mAP (%) | Smoke_mAP50 (%) | Fire_mAP50 (%) |
|---|---|---|---|---|---|
| - | - | - | 72.17 | 70.74 | 73.61 |
| ✓ | - | - | 72.63 | 66.81 | 78.46 |
| - | ✓ | - | 72.42 | 67.04 | 77.80 |
| - | - | ✓ | 72.21 | 67.84 | 76.59 |
| ✓ | ✓ | - | 73.91 | 75.38 | 72.44 |
| ✓ | - | ✓ | 73.40 | 79.08 | 67.72 |
| - | ✓ | ✓ | 73.54 | 68.36 | 78.73 |
| ✓ | ✓ | ✓ | 75.09 | 70.91 | 79.28 |
| Spatial Domain | Frequency Domain | mAP (%) | Smoke_mAP50 (%) | Fire_mAP50 (%) |
|---|---|---|---|---|
| - | - | 72.17 | 70.74 | 73.61 |
| ✓ | - | 73.32 | 68.36 | 78.29 |
| - | ✓ | 73.25 | 68.39 | 78.12 |
| ✓ | ✓ | 75.09 | 70.91 | 79.28 |
| Method | mAP (%) | Smoke_mAP50 (%) | Fire_mAP50 (%) | FPS |
|---|---|---|---|---|
| YOLOv5 [6] | 65.05 | 61.06 | 69.04 | 36 |
| YOLOX [52] | 71.95 | 66.22 | 77.67 | 33 |
| YOLOv7 [8] | 72.17 | 70.74 | 73.61 | 41 |
| YOLOv8 [9] | 71.81 | 72.82 | 70.80 | 39 |
| YOLOv10 [53] | 72.00 | 70.80 | 73.19 | 45 |
| YOLO-SF [54] | 70.31 | 68.60 | 72.02 | 15 |
| YOLOv9-CBM [55] | 69.99 | 67.05 | 72.93 | 23 |
| YOLOv11 [56] | 71.17 | 70.71 | 71.63 | 43 |
| YOLOv12 [57] | 69.22 | 68.30 | 70.41 | 29 |
| YOLO-MFD | 73.91 | 75.38 | 72.44 | 35 |
| Method | mAP (%) | Smoke_mAP50 (%) | Fire_mAP50 (%) |
|---|---|---|---|
| YOLOv5 [6] | 59.14 | 56.39 | 61.89 |
| YOLOX [52] | 64.48 | 60.55 | 68.41 |
| YOLOv7 [8] | 65.93 | 60.99 | 70.87 |
| YOLOv8 [9] | 66.38 | 61.82 | 70.94 |
| YOLOv10 [53] | 66.15 | 60.66 | 71.64 |
| YOLO-SF [54] | 61.54 | 57.60 | 65.48 |
| YOLOv9-CBM [55] | 65.11 | 63.74 | 66.48 |
| YOLOv11 [56] | 66.37 | 61.25 | 71.49 |
| YOLOv12 [57] | 60.85 | 58.73 | 62.97 |
| YOLO-MFD | 67.59 | 65.28 | 69.90 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mo, F.; Liu, S.; Wu, S.; Chen, R.; Song, T. YOLO-MFD: Object Detection for Multi-Scenario Fires. Information 2025, 16, 620. https://doi.org/10.3390/info16070620
Mo F, Liu S, Wu S, Chen R, Song T. YOLO-MFD: Object Detection for Multi-Scenario Fires. Information. 2025; 16(7):620. https://doi.org/10.3390/info16070620
Chicago/Turabian StyleMo, Fuchuan, Shen Liu, Sitong Wu, Ruiyuan Chen, and Tiecheng Song. 2025. "YOLO-MFD: Object Detection for Multi-Scenario Fires" Information 16, no. 7: 620. https://doi.org/10.3390/info16070620
APA StyleMo, F., Liu, S., Wu, S., Chen, R., & Song, T. (2025). YOLO-MFD: Object Detection for Multi-Scenario Fires. Information, 16(7), 620. https://doi.org/10.3390/info16070620