1. Introduction
The rapid advancement of Large Language Models (LLMs) has profoundly influenced various domains within software engineering [
1]. These models have demonstrated remarkable capabilities in code generation [
2,
3], software architecture design [
4], and testing automation [
5]. As a fundamental aspect of software engineering, Unified Modeling Language (UML) diagrams have long served as the standard visual notation for capturing both structural and behavioral aspects of software systems [
6]. The integration of LLMs into UML modeling processes represents a significant opportunity to enhance software design practices and education. UML modeling encompasses both syntactic and semantic dimensions [
7,
8]. The syntactic dimension defines the structure and rules governing UML elements [
9], while the semantic dimension explains their intended behavior and meaning, such as how generalization implies inheritance or how messages in sequence diagrams represent method calls. This dual nature of UML modeling presents unique challenges for automation through LLMs, which must accurately capture both the structural correctness and the semantic meaning of the diagrams they generate.
Recent advancements in prompt engineering have significantly enhanced the effectiveness of LLMs for software engineering tasks. Research by Chen et al. [
10] introduced the concept of promptware engineering—a systematic approach for integrating LLMs into various phases of the software development lifecycle. Additional studies have demonstrated how combining fine-tuning and optimized prompting can improve automation in code generation [
11], support safety-critical software development [
12], and generate test cases using intelligent prompt-guided frameworks [
13].
Several studies have explored the capabilities of LLMs in generating UML diagrams [
14,
15]. Despite their impressive ability to convert textual descriptions into UML code, these models continue to struggle with fully understanding all the required system elements and constraints. To address these limitations, researchers have focused on tuning models with domain-specific scenarios [
16,
17], integrating validation techniques, and refining prompt engineering approaches to improve diagramming accuracy. Other studies have investigated improving LLM-assisted UML diagram accuracy through fine-tuning techniques [
18,
19,
20] and integrating domain-specific knowledge into the LLM training process [
21,
22,
23,
24,
25]. Despite these advancements, significant research gaps remain in the evaluation of LLM-generated UML diagrams: Most existing studies focus primarily on basic correctness, neglecting comprehensive metrics that address both completeness and constraint satisfaction. There is insufficient exploration of different prompt engineering approaches, particularly rule-based frameworks that incorporate UML-specific constraints. Few studies have conducted large-scale, multi-university assessments of LLM-generated UML diagrams from a student-centric perspective.
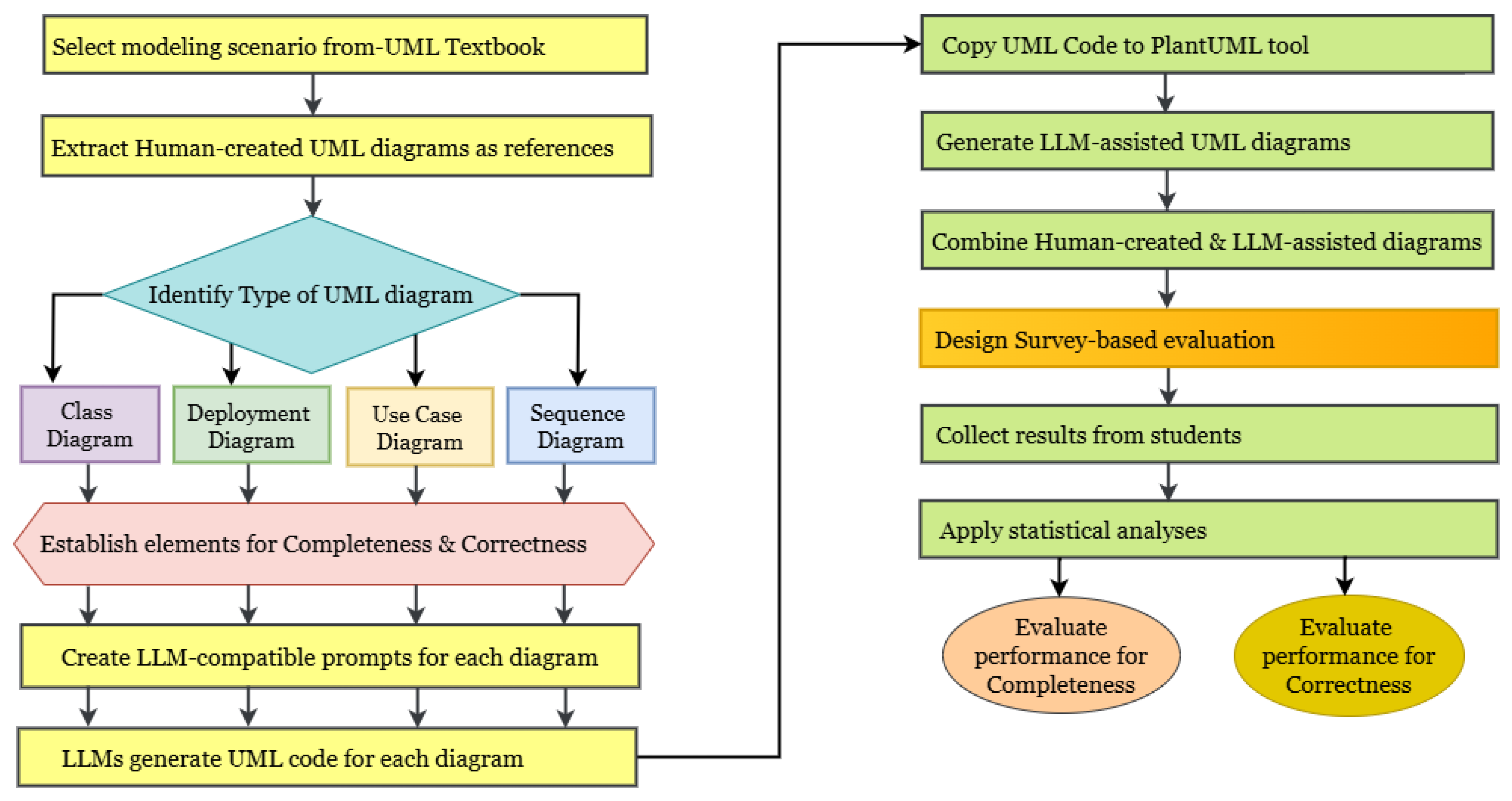
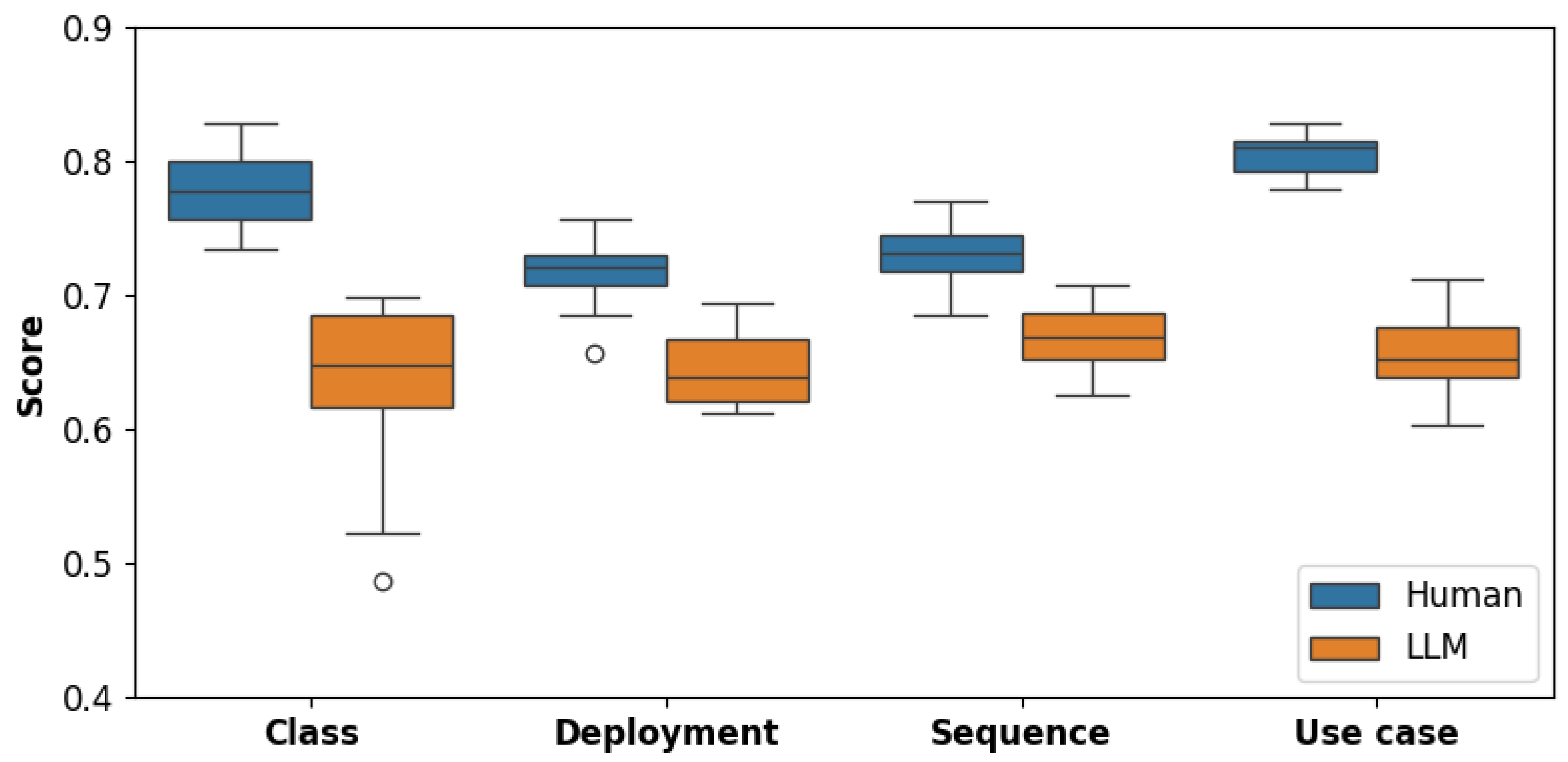
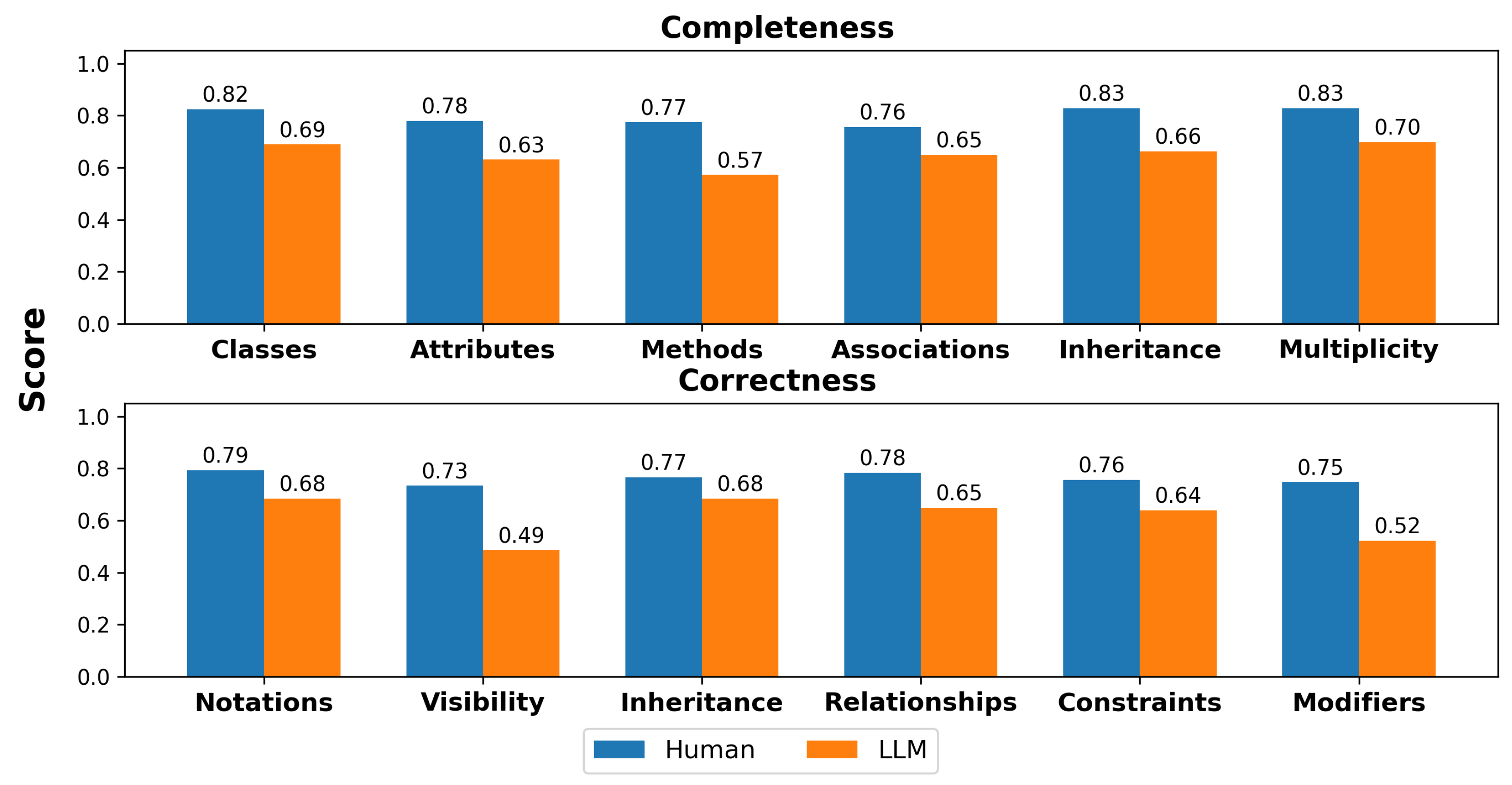
This study addresses these gaps by introducing an empirical evaluation framework for assessing the effectiveness of LLM-assisted UML generation. We integrate scenario-based prompt engineering with cross-diagram evaluation through a survey of 121 computer science and software engineering students from three U.S. institutions: Saint Cloud State University, Southern Illinois University Carbondale, and the University of Wisconsin—Green Bay. Our approach captures student-centric perspectives on both completeness and correctness when comparing LLM-assisted UML diagrams (Class, Deployment, Use Case, and Sequence) with human-created models. The term student-centric refers to an evaluation approach that actively involves students as the primary evaluators of UML diagrams, allowing them to apply their domain knowledge to assess these UML diagrams. This approach aligns with learner-centered educational practices, which emphasize student engagement in the learning process. The study addresses the following research questions:
RQ1: To what extent does an LLM-assisted class diagram match a human-created diagram in terms of completeness and correctness?
RQ2: To what extent does an LLM-assisted deployment diagram match a human-created diagram in terms of completeness and correctness?
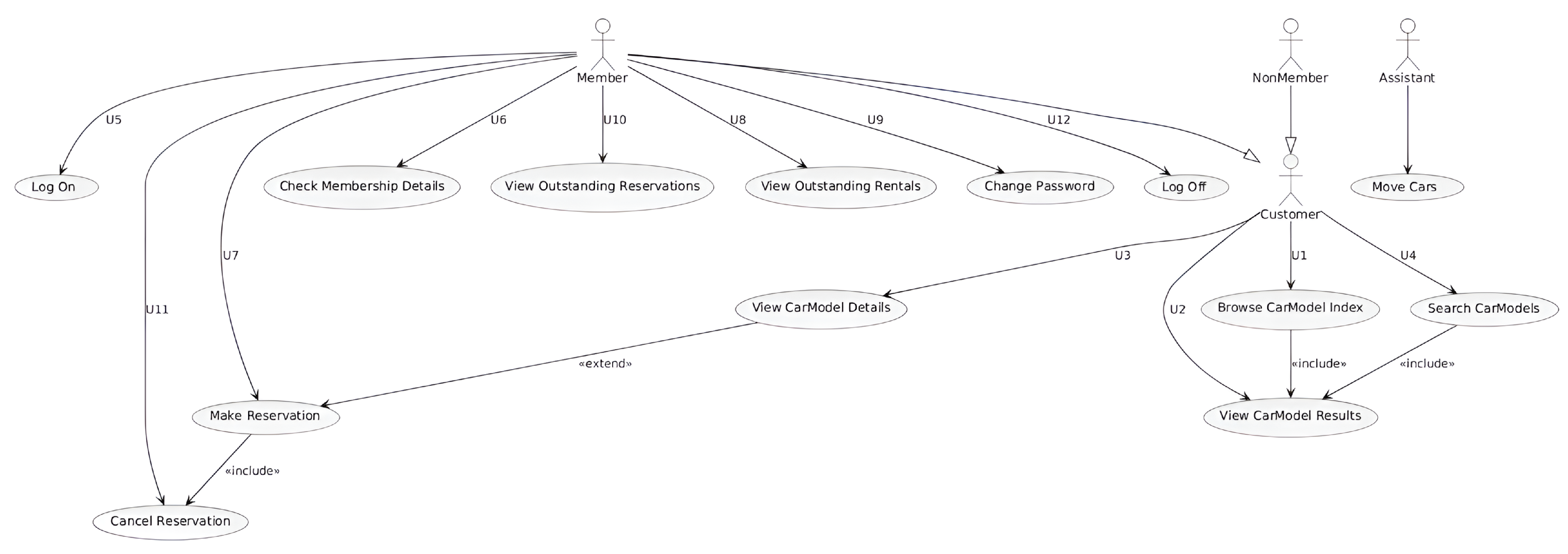
RQ3: To what extent does an LLM-assisted use case diagram match a human-created diagram in terms of completeness and correctness?
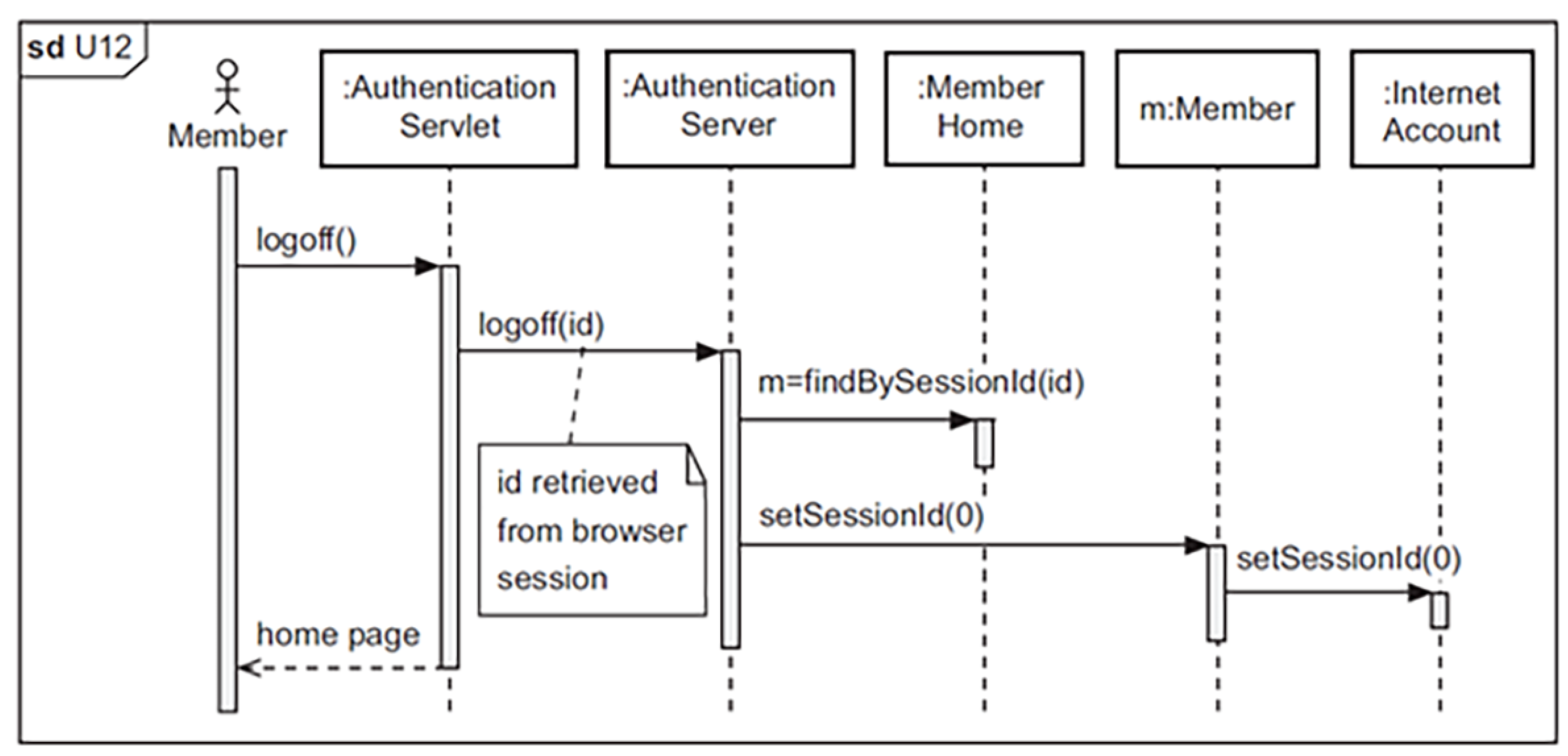
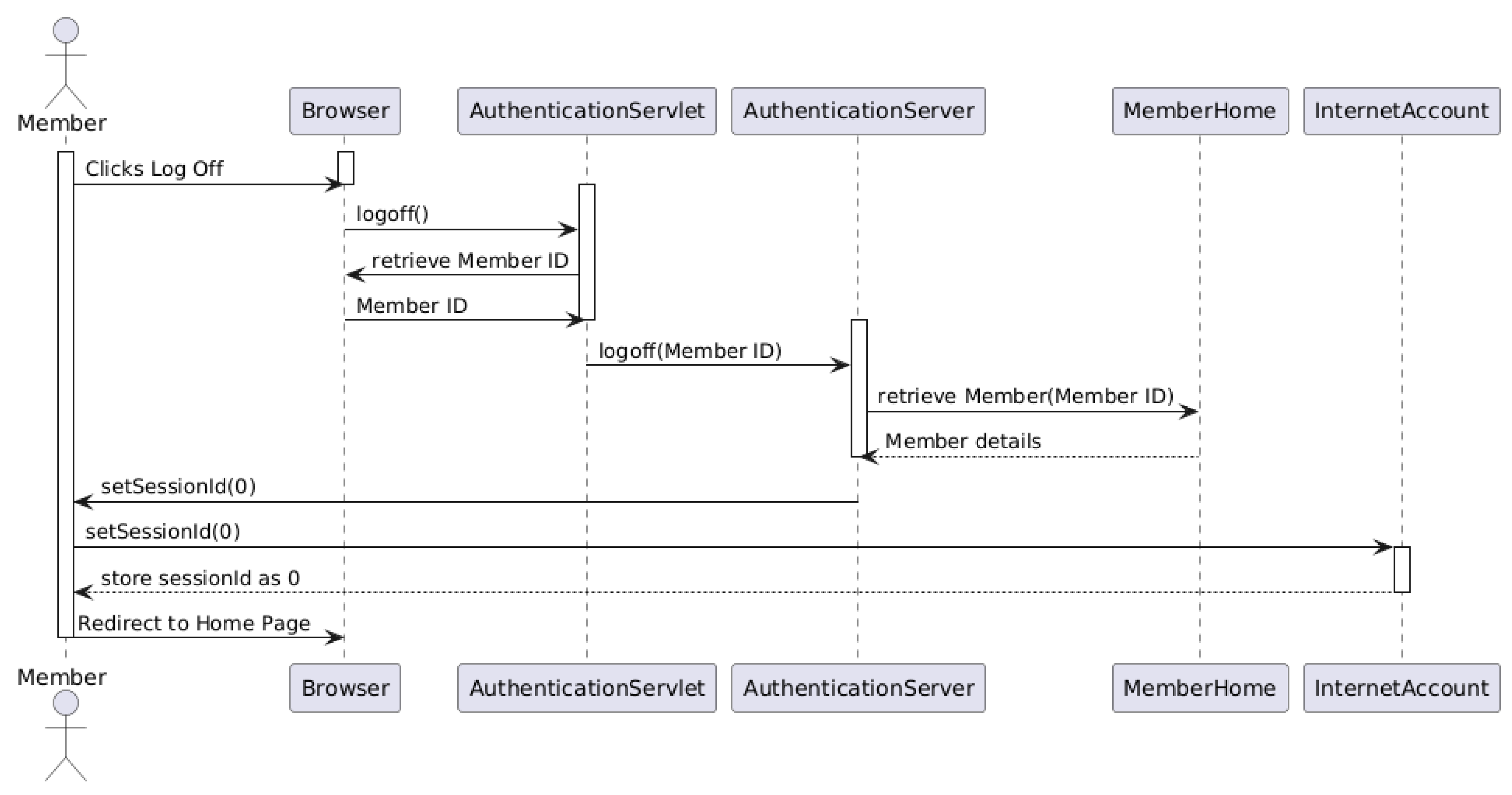
RQ4: To what extent does an LLM-assisted sequence diagram match a human-created diagram in terms of completeness and correctness?
Our contributions include the following:
A novel rule-based validation framework for evaluating LLM-generated UML diagrams, incorporating both completeness ratio (CR) and constraint satisfaction (CS) metrics.
A comprehensive empirical evaluation methodology involving students from multiple universities, providing diverse perspectives on diagram quality.
Statistically validated insights into the current capabilities and limitations of LLMs in generating different types of UML diagrams.
A generalizable model for educational UML assessment with LLMs that can be extended to other modeling contexts and educational settings.
The remainder of this paper is organized as follows:
Section 2 reviews related work on LLMs in software modeling and UML diagram generation.
Section 3 details our methodology, including the rule-based prompt engineering framework and validation algorithms. green
Section 3describes our experimental setup and data collection process.
Section 4 presents our results and statistical analyses.
Section 5 discusses the implications of our findings for software engineering education and practice.
Section 6 addresses threats to validity, and
Section 7 concludes with a summary of contributions and directions for future research.
2. Related Work
LLMs have significantly influenced software modeling, particularly through their ability to automate the generation of UML diagrams.
Recent work has begun to assess the role of LLMs in software modeling tasks. Cámara et al. [
15] investigated ChatGPT 4.1’s effectiveness in generating class diagrams and highlighted limitations in identifying relationships and multiplicities. Unlike our study, their evaluation was limited to one structural diagram type, and lacked a systematic prompt engineering approach. De Vito et al. [
16] introduced ECHO, a co-prompting technique designed to guide ChatGPT in generating Use Case diagrams. While their method improved diagram quality, it focused on a single diagram type, and did not evaluate structural diagrams like Class or Deployment, nor did it include correctness metrics, like we propose. Moreover, Recent advances in ensemble modeling approaches combining CNNs, Bi-LSTM, and transformers have demonstrated significant improvements in text classification tasks, especially in socially sensitive domains [
26].
Herwanto [
17] expanded the application of LLMs beyond UML by automating Data Flow Diagram generation from user stories, illustrating LLMs’ general potential in early software modeling tasks. Our study complements this line of research by focusing on standard UML diagrams and introducing dual evaluation metrics (correctness and completeness).
Chen et al. [
10] evaluated domain modeling performance using different prompt strategies (zero-, one-, and two-shot) across GPT-3.5 and GPT-4. Their analysis found that few-shot methods improved attribute and relationship generation, whereas zero-shot had the lowest recall—a pattern consistent with our findings and prompting strategy. We differ in that we apply prompt engineering rules and evaluate across multiple diagram types, not just entity relationships.
Wang et al. [
27] focused on correctness scoring of Class, Use Case, and Sequence diagrams using few-shot prompting. As discussed in
Section 4.3, their higher Sequence diagram correctness score (74.8%) compared to ours (68.3%) likely results from their iterative refinement process. However, we included completeness as an additional metric, offering a broader assessment than correctness-only analysis.
Conrardy and Cabot [
28] proposed a vision-to-model approach using GPT-4V and Gemini to convert UI screenshots to UML. They reported that GPT-4V outperformed Gemini on this image-to-UML task.
Compared to these prior efforts, our study makes several distinct contributions: (1) we evaluate both structural and behavioral UML diagrams; (2) we introduce automated correctness and completeness validation; and (3) we use a large-scale, student-centered survey across multiple universities to assess human judgments. Many previous studies have focused on one diagram type, used qualitative assessments, or lacked cross-population evaluation—limitations we aim to address.
From the perspective of UML structural diagrams, one study [
28] explored the usage of GPT-4V and Gemini to generate a UML Class model from given images of hand-drawn UML diagrams. Their study compared GPT-4, Gemini Pro, and Gemini Ultra. Based on their findings, GPT-4 provided the best results. The research conducted in [
29] aimed to provide Class diagrams from NL descriptions using GPT-3.5 and GPT-4. Also, the study in [
29] evaluated fully automated domain modeling using GPT-3.5/GPT-4 by exploring three types of shots: zero-shot (no examples), N-shot (1–2 labeled examples), and chain-of-thought (CoT) (step-by-step rationale). The results showed that GPT-4 with one-shot prompting performed best for classes and relationships, while two-shot improved attribute generation. Zero-shot had the lowest recall values (missing elements), and CoT was ineffective for domain modeling. Their findings reveal that LLMs struggle with relationships and modeling. Another research study by [
15] aimed to explore the current capabilities of ChatGPT in performing modeling tasks and help software designers to identify the syntactic and semantic gaps in UML. Nevertheless, these studies captured only the Class diagram.
In terms of UML behavioral diagrams, one study [
14] applied a qualitative approach by investigating how ChatGPT could assist in producing sequence diagrams from 28 Software Requirements Specifications (SRSs) in various problem domains. In addition, the research work in [
16] proposed a co-prompt engineering approach, ECHO, that helped software engineers to efficiently use ChatGPT as an essential LLM to improve the quality of generated Use Case diagrams. Nevertheless, these studies are limited to Sequence or Use Case diagrams.
Considering the exploration of both structural and behavioral UML diagrams, the authors of [
27] designed an experiment involving 45 undergraduate students enrolled in a required modeling course. The findings showed how GPT-3.5 and GPT-4 were able to significantly assist the students in producing three UML models: Class diagrams, Use Case diagrams, and Sequence diagrams. This study addressed only correctness evaluation, and it involved students’ feedback from a single university.
This study attempted to capture both completeness and correctness evaluation for structural (Class and Deployment) and behavioral (Use Case and Sequence) UML diagrams. We used a survey designed to compare LLM-assisted UML diagrams with human-created diagrams based on students perspectives across three different U.S. universities. The proposed approach employs zero-shot prompts with explicit UML constraints and algorithmic validation, which essentially aims to test the ability of GPT-4-turbo in assisting the visualization of the investigated diagrams.
6. Limitations and Future Work
This study exclusively focused on GPT-4-turbo, due to its wide accessibility, strong general reasoning performance, and familiarity to most students participating in the evaluation. While this model provides a robust baseline for evaluating LLM-driven UML diagram generation, we recognize that its single-model scope is a significant limitation. Notably, other leading Large Language Models (LLMs), such as Google Gemini and GitHub 3.4.21 Copilot, offer different capabilities that may influence modeling outcomes.
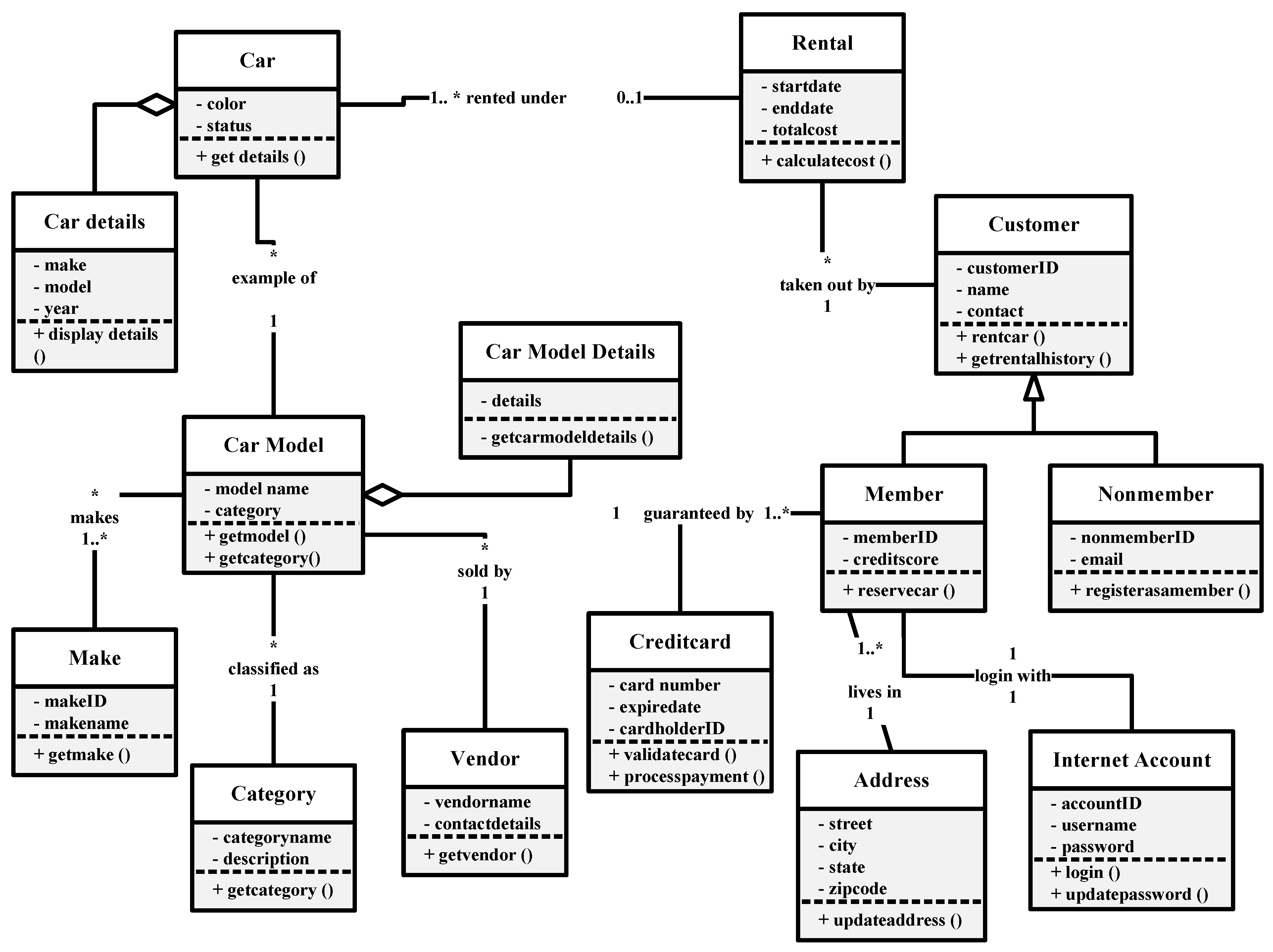
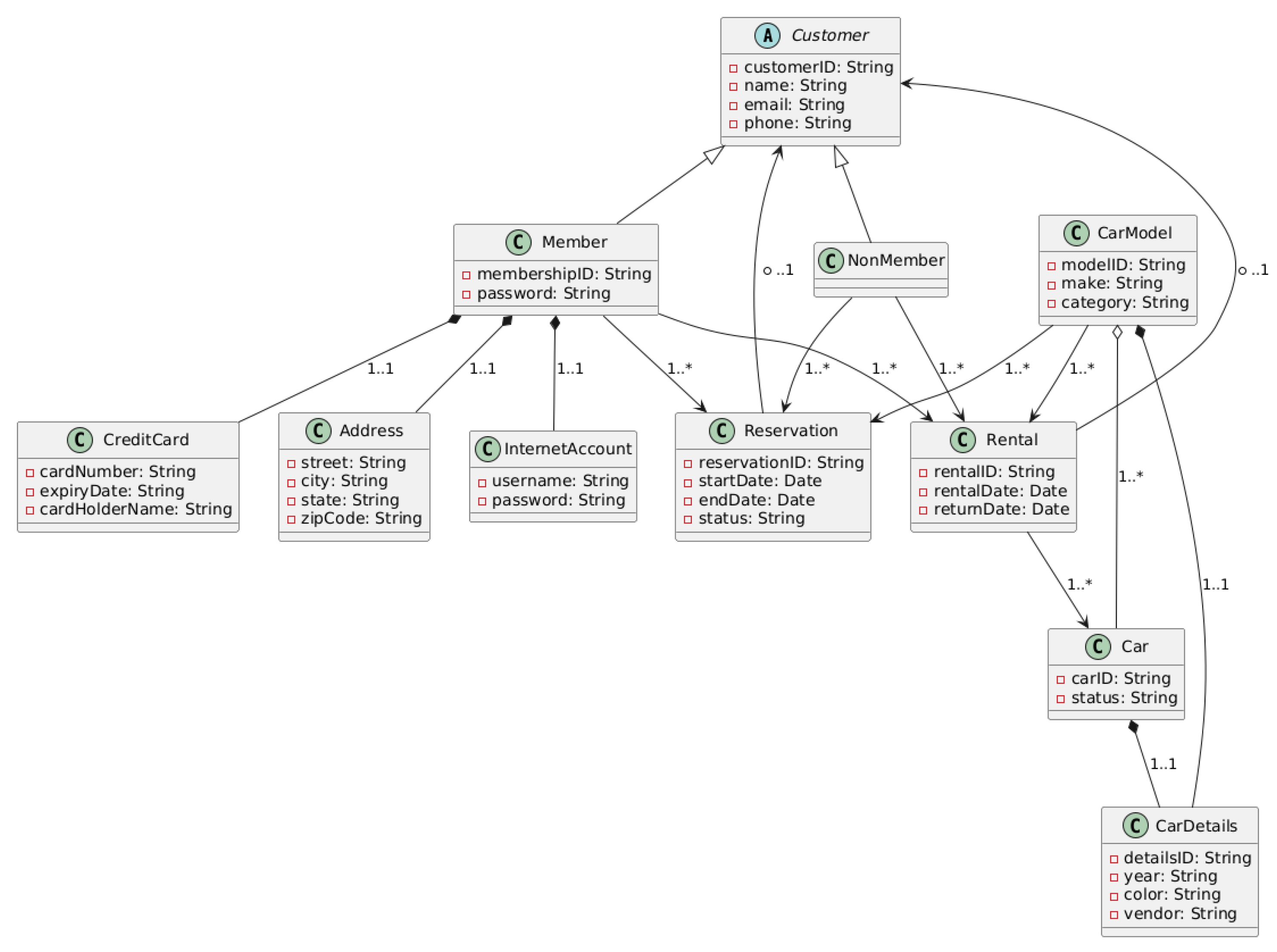
Another key limitation of our study is its reliance on a single problem domain—the iCoot Car Rental System. While this domain is widely used in software engineering education and familiar to most students, focusing exclusively on it restricts the generalizability of our findings. LLMs may exhibit different behavior when tasked with UML modeling for other domains such as healthcare systems, educational platforms, or e-commerce services. As a result, future research should replicate this study across multiple problem domains to assess the consistency of completeness and correctness metrics and to strengthen the external validity of the findings. Cross-domain testing will help to determine whether the performance patterns observed here are model-specific
This study did not include interactive learning tasks. However, we agree that allowing students to refine prompts or correct LLM-generated diagrams could promote deeper learning. We see strong potential in designing future experiments where students actively engage in improving or validating outputs. Also, this study did not explicitly analyze prompt complexity for different UML diagram types, but it offers valuable insights into how varying diagram complexities affect LLM-assisted generation performance. Future research could explore metrics like constraint counts, prompt length, and error types to more systematically measure prompt complexity. An important direction for future research involves the integration of feedback loops and self-correction mechanisms into LLM-based UML diagram generation. Current models like GPT-4-turbo lack the ability to autonomously detect and revise constraint violations, which contributes to the correctness gaps observed in our study.
A further limitation concerns the evaluator population. Our assessment relied on student participants with heterogeneous levels of UML expertise. This diversity introduced potential bias in the evaluation process, as more knowledgeable students may have judged diagrams more rigorously than their less-experienced peers. The inclusion of expert evaluations would deepen the analysis of syntactic and semantic issues in LLM-generated UML diagrams. The current study focuses on student-centric perspectives to assess the pedagogical utility of LLMs in educational settings. However, we acknowledge the value of professional modelers’ insights for a more comprehensive evaluation. To address this, future work will incorporate evaluations from industry professionals and domain experts to establish a more stable benchmark for LLM-generated UML quality. This will also allow us to examine how evaluation criteria vary across levels of UML proficiency.
GitHub Copilot, which is derived from OpenAI’s Codex and optimized for code completion, may handle syntactic structures and technical keywords in UML modeling prompts differently from GPT-4-turbo. In contrast, Gemini is designed to compete directly with GPT-4 across multimodal and reasoning tasks, potentially yielding more accurate or semantically rich outputs. In future work, we plan to replicate this study using Gemini and Copilot to compare their performance across the same UML diagram types and task formulations. A cross-model comparative evaluation will help to clarify whether the trends observed in this study, especially in completeness and correctness metrics, hold across LLMs or are specific to GPT-4-turbo’s architecture and training data.
Finally, GPT-4-turbo was chosen, in part, because it is readily available via open access channels (e.g., ChatGPT) and familiar to most students participating in the evaluation. However, this choice may have inadvertently biased the results in favor of a model that students had had prior exposure to. This trade-off underscores the need for broader LLM benchmarking in future empirical studies.
Automating prompt generation based on requirement documents would enhance scalability. In our future work, we plan to develop a semi-automated or fully automated mechanism using NLP and machine learning techniques. This will help to streamline prompt creation while maintaining completeness and correctness through our existing validation framework. Also, since students evaluated the diagrams without participating in the prompt construction or having access to intermediate steps, it is worthy to measure the cognitive load for participating students. Further, exploring sentiments and attitudes toward LLM-generated diagrams is an important future direction. This evaluation framework holds potential for broader adoption in both educational and industrial contexts.
Author Contributions
Conceptualization, B.A.-A., A.A. and O.M.; Methodology, B.A.-A., A.A. and O.M.; Software, N.S.; Validation, B.A.-A. and A.A.; Formal analysis, B.A.-A., A.A., O.M. and N.S.; Investigation, B.A.-A. and O.M.; Resources, O.M.; Data curation, B.A.-A., A.A., O.M. and N.S.; Writing—original draft, B.A.-A., A.A. and N.S.; Writing—review & editing, N.S.; Supervision, B.A.-A. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
The study was conducted according to the guidelines of the Declaration of Helsinki, and approved by the Institutional Review Board of Office of Research and Sponsored Programs St. Cloud State University (70631957 2025-05-29).
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
Acknowledgments
We gratefully acknowledge the valuable participation of the students who contributed their time and insights to this survey. Their input was instrumental in advancing our research. We also extend our sincere appreciation to the academic staff at Saint Cloud State University, Southern Illinois University Carbondale, and University of Wisconsin—Green Bay for their support, whose collaboration and encouragement made this work possible.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
| LLMs | Large Language Models |
| UML | Unified Modeling Language |
| GPT | Generative Pre-trained Transformer |
| SDLC | Software Development Lifecycle |
| NLP | Natural Language Processing |
| CR | Completeness Ratio |
| CS | Constraint Satisfaction |
| SR | System Requirement |
| SRS | Software Requirements Specification |
References
- Gao, C.; Hu, X.; Gao, S.; Xia, X.; Jin, Z. The Current Challenges of Software Engineering in the Era of Large Language Models. Acm Trans. Softw. Eng. Methodol. 2024, 34, 1–30. [Google Scholar] [CrossRef]
- Liu, J.; Xia, C.S.; Wang, Y.; Zhang, L. Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation. Adv. Neural Inf. Process. Syst. 2023, 36, 21558–21572. [Google Scholar]
- Vaithilingam, P.; Zhang, T.; Glassman, E.L. Expectation vs. experience: Evaluating the usability of code generation tools powered by large language models. In Proceedings of the Chi Conference on Human Factors in Computing Systems Extended Abstracts, New Orleans, LA, USA, 29 April–5 May 2022; pp. 1–7. [Google Scholar]
- Ahmad, A.; Waseem, M.; Liang, P.; Fahmideh, M.; Aktar, M.S.; Mikkonen, T. Towards human-bot collaborative software architecting with chatgpt. In Proceedings of the 27th International Conference on Evaluation and Assessment in Software Engineering, Oulu, Finland, 14–16 June 2023; pp. 279–285. [Google Scholar]
- Zimmermann, D.; Koziolek, A. Automating gui-based software testing with gpt-3. In Proceedings of the 2023 IEEE International Conference on Software Testing, Verification and Validation Workshops (ICSTW), Dublin, Ireland, 16–20 April 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 62–65. [Google Scholar]
- Ozkaya, M.; Erata, F. A survey on the practical use of UML for different software architecture viewpoints. Inf. Softw. Technol. 2020, 121, 106275. [Google Scholar] [CrossRef]
- Gamage, M.Y.L. Automated Software Architecture Diagram Generator Using Natural Language Processing. Bachelor’s Thesis, University of Westminster, Westminster, UK, 2023. [Google Scholar]
- Carvalho, G.; Dihego, J.; Sampaio, A. An integrated framework for analysing, simulating and testing UML models. In Formal Methods: Foundations and Applications, Proceedings of the Brazilian Symposium on Formal Methods, Vitória, Brazil, 4–6 December 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 86–104. [Google Scholar]
- Ambler, S.W. The Elements of UML (TM) 2.0 Style; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- Chen, Z.; Wang, C.; Sun, W.; Yang, G.; Liu, X.; Zhang, J.M.; Liu, Y. Promptware Engineering: Software Engineering for LLM Prompt Development. arXiv 2025, arXiv:2503.02400. [Google Scholar]
- Pornprasit, C.; Tantithamthavorn, C. Fine-tuning and prompt engineering for large language models-based code review automation. Inf. Softw. Technol. 2024, 175, 107523. [Google Scholar] [CrossRef]
- Liu, M.; Wang, J.; Lin, T.; Ma, Q.; Fang, Z.; Wu, Y. An empirical study of the code generation of safety-critical software using llms. Appl. Sci. 2024, 14, 1046. [Google Scholar] [CrossRef]
- Boukhlif, M.; Kharmoum, N.; Hanine, M.; Kodad, M.; Lagmiri, S.N. Towards an Intelligent Test Case Generation Framework Using LLMs and Prompt Engineering. In Proceedings of the International Conference on Smart Medical, IoT & Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2024; pp. 24–31. [Google Scholar]
- Ferrari, A.; Abualhaija, S.; Arora, C. Model Generation from Requirements with LLMs: An Exploratory Study. arXiv 2024, arXiv:2404.06371. [Google Scholar]
- Cámara, J.; Troya, J.; Burgueño, L.; Vallecillo, A. On the assessment of generative AI in modeling tasks: An experience report with ChatGPT and UML. Softw. Syst. Model. 2023, 22, 781–793. [Google Scholar] [CrossRef]
- De Vito, G.; Palomba, F.; Gravino, C.; Di Martino, S.; Ferrucci, F. Echo: An approach to enhance use case quality exploiting large language models. In Proceedings of the 2023 49th Euromicro Conference on Software Engineering and Advanced Applications (SEAA), Durres, Albania, 6–8 September 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 53–60. [Google Scholar]
- Herwanto, G.B. Automating Data Flow Diagram Generation from User Stories Using Large Language Models. In Proceedings of the 7th Workshop on Natural Language Processing for Requirements Engineering, Winterthur, Switzerland, 8 April 2024. [Google Scholar]
- Hou, X.; Zhao, Y.; Liu, Y.; Yang, Z.; Wang, K.; Li, L.; Luo, X.; Lo, D.; Grundy, J.; Wang, H. Large language models for software engineering: A systematic literature review. ACM Trans. Softw. Eng. Methodol. 2024, 33, 1–79. [Google Scholar]
- Hussein, D. Usability of LLMs for Assisting Software Engineering: A Literature Review. Bachelor’s Thesis, Universität Bonn, Bonn, Germany, 2024. [Google Scholar]
- Lorenzo, C. Integrating large language models for real-world problem modelling: A comparative study. In Proceedings of the INTED2024 Proceedings, IATED, Valencia, Spain, 4–6 March 2024; pp. 3262–3272. [Google Scholar]
- Nifterik, S.v. Exploring the Potential of Large Language Models in Supporting Domain Model Derivation from Requirements Elicitation Conversations. Master’s Thesis, Utrecht University, Utrecht, The Netherlands, 2024. [Google Scholar]
- Buchmann, R.; Eder, J.; Fill, H.G.; Frank, U.; Karagiannis, D.; Laurenzi, E.; Mylopoulos, J.; Plexousakis, D.; Santos, M.Y. Large language models: Expectations for semantics-driven systems engineering. Data Knowl. Eng. 2024, 152, 102324. [Google Scholar] [CrossRef]
- Hemmat, A.; Sharbaf, M.; Kolahdouz-Rahimi, S.; Lano, K.; Tehrani, S.Y. Research directions for using LLM in software requirement engineering: A systematic review. Front. Comput. Sci. 2025, 7, 1519437. [Google Scholar] [CrossRef]
- Umar, M.A. Automated Requirements Engineering Framework for Model-Driven Development. Ph.D. Thesis, King’s College, London, UK, 2024. [Google Scholar]
- Vega Carrazan, P.F. Large Language Models Capabilities for Software Requirements Automation. Ph.D. Thesis, Politecnico di Torino, Torino, Italy, 2024. [Google Scholar]
- Al-Shawakfa, E.M.; Alsobeh, A.M.R.; Omari, S.; Shatnawi, A. RADAR#: An Ensemble Approach for Radicalization Detection in Arabic Social Media Using Hybrid Deep Learning and Transformer Models. Information 2025, 16, 522. [Google Scholar] [CrossRef]
- Wang, B.; Wang, C.; Liang, P.; Li, B.; Zeng, C. How LLMs Aid in UML Modeling: An Exploratory Study with Novice Analysts. arXiv 2024, arXiv:2404.17739. [Google Scholar]
- Conrardy, A.; Cabot, J. From Image to UML: First Results of Image Based UML Diagram Generation Using LLMs. arXiv 2024, arXiv:2404.11376. [Google Scholar]
- Chen, K.; Yang, Y.; Chen, B.; López, J.A.H.; Mussbacher, G.; Varró, D. Automated Domain Modeling with Large Language Models: A Comparative Study. In Proceedings of the 2023 ACM/IEEE 26th International Conference on Model Driven Engineering Languages and Systems (MODELS), Västerås, Sweden, 1–6 October 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 162–172. [Google Scholar]
- O’docherty, M. Object-Oriented Analysis & Design; John Wiley & Sons: Hoboken, NJ, USA, 2005. [Google Scholar]
- Alhazeem, E.; Alsobeh, A.; Al-Ahmad, B. Enhancing Software Engineering Education through AI: An Empirical Study of Tree-Based Machine Learning for Defect Prediction. In Proceedings of the 25th Annual Conference on Information Technology Education (SIGITE ’24), Atlanta, GA, USA, 9–12 October 2024; pp. 153–156. [Google Scholar]
- Alsobeh, A.; Woodward, B. AI as a Partner in Learning: A Novel Student-in-the-Loop Framework for Enhanced Student Engagement and Outcomes in Higher Education. In Proceedings of the 24th Annual Conference on Information Technology Education (SIGITE ’23), Wilmington, NC, USA, 11–14 October 2023; pp. 171–172. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}