Abstract
The image style transfer task aims to apply the style characteristics of a reference image to a content image, generating a new stylized result. While many existing methods focus on designing feature transfer modules and have achieved promising results, they often overlook the entanglement between content and style features after transfer, making effective separation challenging. To address this issue, we propose a Dual-Branch Decoupled Image Style Transfer Network (DBDST-Net) to better disentangle content and style representations. The network consists of two branches: a Content Feature Decoupling Branch, which captures fine-grained content structures for more precise content separation, and a Style Feature Decoupling Branch, which enhances sensitivity to style-specific attributes. To further improve the decoupling performance, we introduce a dense-regressive loss that minimizes the discrepancy between the original content image and the content reconstructed from the stylized output, thereby promoting the independence of content and style features while enhancing image quality. Additionally, to mitigate the limited availability of style data, we employ the Stable Diffusion model to generate stylized samples for data augmentation. Extensive experiments demonstrate that our method achieves a better balance between content preservation and style rendering compared to existing approaches.
1. Introduction
Image style transfer is a fascinating research topic with broad application value. It achieves stylized rendering by enabling the transfer of visual effects from reference style images onto content images, and has attracted significant attention in both industry and the art community. The core challenge of style transfer lies in effectively analyzing specific styles along with their texture characteristics and designing corresponding transfer strategies. Traditional texture synthesis-based approaches [1,2,3,4,5] can generate vivid stylized images, but have notable limitations in that they typically support only single-style processing and struggle to extract high-level semantic texture features from images. Therefore, generating high-quality stylized results requires the clear disentanglement of content and style features from a given image.
With the rapid development of deep learning in recent years, Convolutional Neural Networks (CNNs) have been widely applied to image style transfer, yielding promising results. Gatys et al. [6] first introduced a deep learning-based style transfer method that extracts image features through a pretrained network and constructs a corresponding optimization model for style transfer. However, this process is complex and computationally intensive. To improve efficiency, various fast style transfer methods [7,8,9,10,11,12] have been proposed. Although these approaches significantly reduce computational cost, most focus on designing efficient transfer modules in the second stage [13,14,15,16], while often neglecting effective feature disentanglement in the initial stage. As a result, feature entanglement frequently occurs. This entanglement degrades the resulting generation quality, especially since most methods rely on a shared pretrained encoder, making it difficult to extract independent content and style representations.
To address these limitations, this paper proposes a novel Dual-Branch Decoupled Image Style Transfer Network (DBDST-Net). Unlike existing methods that rely heavily on pretrained encoders to separately extract content and style features, DBDST-Net places greater emphasis on the initial feature decoupling stage. It introduces two specifically designed branches: a Content Decoupling Branch and a Style Decoupling Branch. In the former, a content attention mechanism is introduced to allow the network to focus more precisely on each pixel, particularly in regions rich in structural information, which enables more accurate content feature extraction; in the latter, a style attention mechanism is employed to emphasize stylistic representations across different regions, facilitating more accurate style feature extraction.
To enhance the network’s decoupling capability, the final stylized image is passed through a U-shaped encoder–decoder to reconstruct an image containing only content information. A dense-regressive loss is then designed to measure the discrepancy between this reconstructed image and the original content image, further promoting the separation of style components in the generated output. This approach improves DBDST-Net’s feature disentanglement ability, effectively mitigating feature entanglement. To address the limited availability of style images in specific domains, the LoRA [17] technique is employed to fine-tune the Stable Diffusion model in order to augment the style dataset.
- Due to the limited availability of data, this work builds upon Stable Diffusion and leverages the LoRA technique for fine-tuning, producing a model that can consistently generate the required dataset in scenarios featuring elements of Chinese culture.
- To address the difficulty of clearly separating content and style features in existing methods, a Dual-Branch Decoupled Image Style Transfer Network (DBDST-Net) is proposed. In the content feature decoupling branch, a Content Feature Attention Extractor module is designed to effectively focus on the detailed information of the content image, enabling more accurate extraction of content features. In the style feature decoupling branch, the proposed Style Feature Attention Extractor module helps the model to place greater attention on the color and shape of the image, enhancing the effectiveness of style feature extraction.
- To enhance the decoupling capability of DBDST-Net, a loss function called the dense-regressive loss is proposed. This loss measures the difference between the original content image and the content image regressed from the stylized result, effectively optimizing the decoupling performance of the dual-branch structure.
- Extensive experiments show that DBDST-Net can effectively separate content and style features, generating high-quality stylized images.
2. Related Work
2.1. Diffusion Models
Diffusion models are probabilistic deep generative models that have demonstrated outstanding capabilities in generating samples with high fidelity and diversity. A typical diffusion model [18] consists of two stages: a forward process that progressively adds Gaussian noise to the input data, and a reverse process that reconstructs the original input from the noise. To date, diffusion models have been widely applied to various generative modeling tasks [19,20], among which the most relevant to our work is conditional image synthesis, particularly text-to-image generation. Ramesh et al. proposed unCLIP (DALLE-2) [20], which uses a prior model to generate CLIP-based image embeddings from textual conditions, followed by a diffusion-based decoder to generate images conditioned on those embeddings. Wang et al. [19] proposed a framework based on CLIP and diffusion models for content-style disentanglement, which achieves interpretable and controllable style transfer by explicitly extracting content information while implicitly learning style features. Their method outperforms existing approaches and provides new insights into content-style disentanglement, demonstrating the potential of diffusion models in this field. Inspired by this research, we design a controllable LDM-based Chinese-style generation model capable of producing images with specific content and style according to user input. Kang et al. [21] proposed a method that distills complex multi-step diffusion models into a single-step conditional Generative Adversarial Network (GAN), significantly improving the image generation speed. Through this distillation approach, the generated image quality remains comparable to that of traditional diffusion models while increasing the generation speed by approximately 30 times.
2.2. Style Transfer
Image style transfer aims to achieve the transformation of image styles by applying the style of one image to another. Traditional style transfer methods typically involve analyzing the style and texture features of the target image and constructing corresponding models based on that analysis. Meier [1] proposed a brushstroke-based rendering model that was able to achieve oil painting-style transfer effects. Hertzmann et al. [2] introduced image analogies for style transformation. Efros and Leung [3] applied Markov models and pixel-based filling strategies to realize style transfer. Wei [4] combined texture synthesis techniques with vectorization methods to accelerate the synthesis process. Han et al. [5] proposed a multi-scale texture synthesis algorithm to enable texture transfer at different scales. The algorithm introduced by Ashikhmin [22] performed well in style transfer tasks involving natural scenes. Although these traditional methods achieve style transfer to a certain extent, they still face several limitations; most methods support only single-style transfer, and can struggle to extract high-level texture features from images.
With the development of deep learning, image style transfer methods have gradually shifted toward leveraging deep neural networks to learn specific styles and apply them to other images. Zhu et al. [23] proposed the CycleGAN network, an unsupervised learning model that effectively addressed the limitations of traditional methods through a cycle consistency mechanism. The emergence of Deep Convolutional Generative Adversarial Networks (DCGAN) successfully combines Convolutional Neural Networks (CNNs) with Generative Adversarial Networks (GANs), offering new perspectives for style transfer tasks. Based on this, the CartoonGAN model [24] was introduced, targeting the unique textures and artistic expressions of cartoon styles. It incorporated a newly designed network architecture and loss functions along with an image initialization phase to effectively achieve cartoon-style image transformation. Although CartoonGAN has achieved some success, its stylized results lack strong cartoon characteristics and the content preservation of the original image is insufficient; in addition, it has relatively high memory demands. To address these issues, the AnimeGAN model [12] was proposed in 2020, introducing three new loss functions and a lightweight generator to improve style transfer performance. In 2021, AnimeGANv2 was released; this new version further optimized the generator to reduce high-frequency artifacts in the output and lower the model’s parameter count. Inspired by the pyramid structure, Lin et al. proposed a novel feed-forward network called the Laplacian Pyramid Network [25] which is capable of real-time high-quality style synthesis with excellent overall performance. In 2022, Deng et al. [11] introduced transformers into image style transfer for the first time, proposing a scale-invariant Content-Aware Positional Encoding (CAPE) which significantly mitigated the content representation bias found in traditional neural style transfer methods. Li et al. [26] incorporated LoRA into Stable Diffusion and employed region masks generated by FastSAM to achieve localized style transfer. This approach accurately applies style features to designated regions while preserving the original content in other areas, thereby enhancing the balance between style representation and content preservation.
3. Proposed Method
3.1. Overall Architecture
To more clearly separate content and style information and thereby generate higher-quality stylized images, this paper proposes a novel Dual-Branch Decoupled Image Style Transfer Network (DBDST-Net). The overall architecture is illustrated in Figure 1.
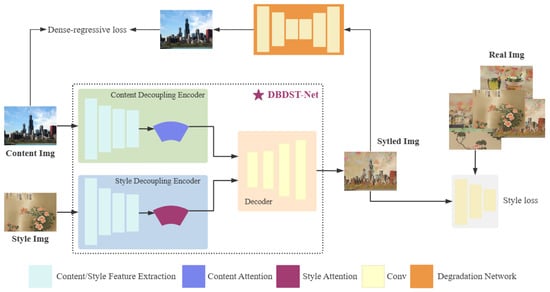
Figure 1.
Overall architecture of DBDST-Net.
As shown in the figure, DBDST-Net adopts a dual-branch design. First, given an input content image and style image , the content and style features and are respectively extracted through content-decoupling and style-decoupling encoders. Then, and are fed into the decoder to reconstruct the stylized image . Finally, the degradation network is used to restore to the original content image .
3.2. Feature Decoupling Encoder
To address the feature entanglement problem existing in current models, this paper proposes a Feature Decoupling Encoder (FDE), the overall structure of which is illustrated in Figure 2. In the Content and Style Decoupling Encoder, multiple Feature Extraction Modules (FEMs) are first employed for multi-level feature extraction, along with repeated downsampling operations to capture multi-scale semantic features. Inspired by [27], a hybrid decoupling strategy is adopted to separate the spatial and channel dimensions. Additionally, large convolutional kernels are introduced to expand the receptive field, allowing for the modeling of long-range spatial dependencies. The specific process is described as follows:
where represents the input content or style image, denotes a depthwise convolution with a kernel size of 9, refers to the activation function, is a pointwise convolution with a kernel size of 1, and indicates the normalization function.
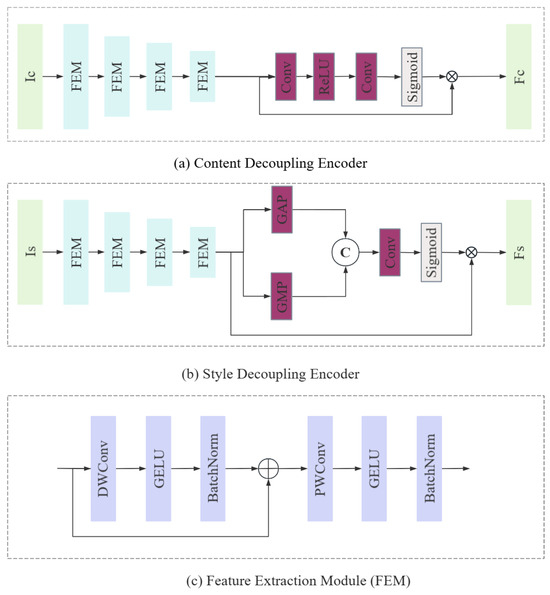
Figure 2.
Overall architecture of the feature decoupling encoder.
To further disentangle the content features more clearly, a content attention mechanism is introduced in the Content Decoupling Encoder. This mechanism assigns different weights to each pixel, highlighting key content information in the image to achieve effective content feature separation. The detailed process is as follows:
where is the content feature extracted during the feature extraction stage, is a convolutional layer with a kernel size of 3, is the activation function, is the decoupled content feature, and · is element-wise multiplication.
To further enhance the separation of style features, this paper introduces a style attention mechanism in the Style Decoupling Encoder. This mechanism compresses the feature maps along the channel dimension using Global Average Pooling (GAP) and Max Average Pooling (MAP) operations to generate a two-dimensional spatial attention map. A convolutional layer is then applied to extract features and assign different weights to different regions, emphasizing prominent color variation patterns. This mechanism aligns well with the nature of style features, which focus heavily on color transitions, making it particularly effective for style feature extraction. The detailed process is as follows:
where is the style feature extracted during the feature extraction stage, is the global average pooling, is the max average pooling, is the feature concatenation operation, and is the decoupled style feature.
3.3. Loss Function
3.3.1. Style Loss Function
Based on the optimization method proposed in [28], this paper combines the rEMD loss with the commonly used mean variance loss as a component of the style loss. Specifically, given an input image, its multi-level feature vector set is first extracted through the encoder . The rEMD loss is then used to measure the distance between the feature distributions of the style image and generated image . The specific calculation process is as follows:
where denotes the cosine distance and where and are used to calculate the mean and covariance of the feature vectors, respectively.
3.3.2. Content Loss Function
For the content loss, this paper adopts the normalized perceptual loss and similarity loss proposed in [28] for computation. The specific calculation process is as follows:
where denotes the operation of normalizing the features F along the channel axis, represents the entry of the self-similarity matrix , and is the cosine similarity of .
3.3.3. Dense-Regressive Loss Function
Inspired by [12], this paper proposes a loss function called the dense-regressive loss in order to improve the effectiveness of content and style feature decoupling in DBDST-Net. This loss is used to measure the difference between the original content image and the style-transferred image after style features have been separated through a specific network. This approach effectively separates style features from the style-transferred image, further enhancing the decoupling ability of the network. The specific calculation process is as follows:
where represents the width and height of the anchor region, denotes the edge coordinate position, and represents the color value.
4. Dataset
We selected the COCO and DIV2K datasets as content image sets for model training and testing. DIV2K is a high-resolution image dataset containing 2000 high-quality images from varied scenes such as cities, natural landscapes, animals, and more. The resolution of these images is 1080p (1920 × 1080) or higher, which is suitable for training and evaluating high-resolution image style transfer algorithms. The COCO dataset is a large-scale dataset for general image recognition, segmentation, and annotation, covering a wide variety of objects and complex scenes in daily life. Its images are rich in content, featuring various semantic objects along with their contextual information, which makes it ideal for training tasks that require strong content representation capabilities.
To address the lack of style datasets covering specific scenes, for this paper we constructed two style datasets, called Chinese-painting-flower and Chinese-landscape-painting, which are used as the source of style images during model training and optimization. The Latent Diffusion Model (LDM) [29] is an important research breakthrough in diffusion modeling within low-dimensional latent spaces. Due to the lower dimensionality of the latent space, LDM maintains high image synthesis quality while offering reduced training computational cost and faster inference speed. For this paper, we selected the Stable Diffusion generative model based on the LDM algorithm as the base architecture and fine-tuned it using the LoRA method, enabling the model to reliably generate multiple images with the same style based on keyword prompts. These images were used to expand the Chinese-style image datasets for style transfer, with the overall structure shown in Figure 3. Specifically, given an input image , the image is first mapped to a latent vector through an encoder E. This latent vector z is then decoded by a decoder D to generate the corresponding image. Meanwhile, the input text x is projected into an intermediate representation by a domain-specific text encoder , which is subsequently fed into the intermediate layers of the denoising network through a cross-attention mechanism. This guides the image generation process, bringing the results into better alignment with the semantics of the input text.
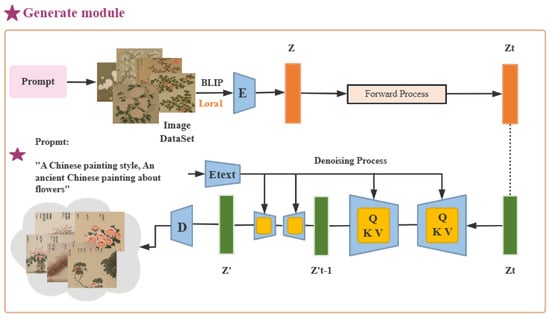
Figure 3.
Overall architecture of the generation module.
To better control the style of the generated paintings while preserving the performance of the original base model, we fine-tuned the generative model using Low-Rank Adaptation (LoRA), as illustrated in Figure 4. Before training the LoRA model, 50 Chinese-style images with consistent style were collected. These images were then automatically cropped and preprocessed using the BLIP model to extract their main content information. This approach automatically generates a new text description for each training image, enabling unified annotation of the training dataset and effectively assisting the model in learning the target style. During the training phase, the weights w of the pretrained model are kept frozen and only the low-rank matrices A and B are trained. Finally, when saving the model, only these two low-rank matrix components need to be stored, significantly reducing storage overhead. The training process is as follows:
where d is the input, Q is the pretrained weight of the generated model, A and B are both low-rank matrices, and r is the rank, representing the incremental weight after fine-tuning.
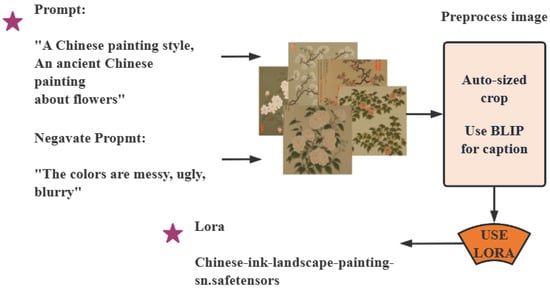
Figure 4.
Training process of the LoRA model.
5. Experiments
5.1. LoRA Experiments
To investigate the impact of different parameters in the LoRA model on image generation performance, this section employs the X/Y/Z Plot script to conduct comparative analysis under various parameter combinations, as shown in Figure 5. This allows for an intuitive comparison of how different parameter settings affect image quality. The X type, Y type, and Z type are used to specify the types of parameters to be compared. After selecting the corresponding types, specific values need to be set in the value field. Taking the UNet weight parameter as an example, this paper sets three values: 1.0, 0.85, and 0.7. Experimental results show that as the number of training steps increases, the quality of the generated images improves steadily, with more detailed features emerging. It is worth noting that increasing the number of training steps significantly enhances both the visual quality and detail richness of the generated images.

Figure 5.
Generation performance of the LoRA model.
5.2. Style Transfer Experiments
5.2.1. User Preference Result
To investigate the preferences of different demographic groups for the results generated by various algorithms, a user study was conducted involving 100 participants from four age groups (5–10, 18–23, 30–35, and 52–57 years of age) and five professional backgrounds (freelancers, programmers, designers, students, and photographers). Specifically, 15 percent of participants were aged 5–10, 35 percent were 18–23, 30 percent were 30–35, and 20 percent were 52–57. In terms of occupations, students and programmers each accounted for 25 percent, freelancers for 5 percent, designers for 15 percent, and photographers for 20 percent. As shown in Figure 6, six algorithms were selected for comparison with the proposed model: AdaIN, AnimeGANv2, PhotoWCT2, Lapstyle, CAP-VSTNet, and CCLAP. During the study, we selected five pairs of images from the two Chinese-style datasets, including both style images and content images , along with stylized images generated by the seven different methods. A total of 35 style transfer results were presented, from which participants were asked to select the seven images they considered to have the best visual quality and provide their feedback. Experimental results indicated that the algorithm proposed in this paper performed the best in terms of overall image quality generation.
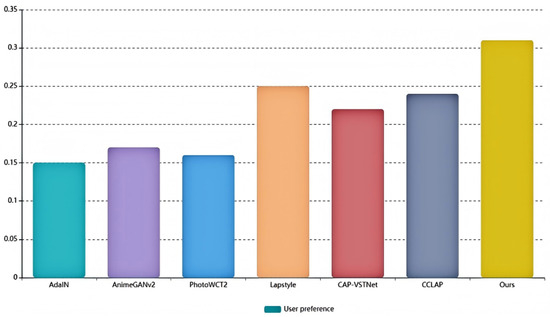
Figure 6.
The plot resulting from the User Study.
5.2.2. Quantitative Comparison of Style Transfer
To compare and analyze the performance of different style transfer methods, this section selects four representative evaluation metrics: Structural Similarity Index Measure (SSIM), Gram loss, content similarity before and after style transfer, and style similarity. SSIM assesses image similarity based on luminance, contrast, and structural information, with values ranging from 0 to 1 — higher values indicate greater similarity. Gram loss measures the mean squared error between the Gram matrices of feature maps from two images, capturing differences in style such as texture and color distribution. Content similarity is computed as the L2 distance between high-level feature representations of the content and generated images, extracted from a pretrained network (e.g., VGG), reflecting the preservation of content structure. Style similarity quantifies the difference between the Gram matrices of the generated and style images, evaluating the accuracy of style feature transfer. Together, these metrics provide a comprehensive assessment of a model’s performance across multiple dimensions, including structural preservation, style representation, content consistency, and style disentanglement. The quantitative results are summarized in Table 1, highlighting the overall performance of each method under these criteria and offering both theoretical and empirical support for subsequent model analysis and optimization. The ↑ and ↓ arrows indicate whether higher or lower values are preferred for each metric, respectively. Bold values denote the best performance, while underlined values indicate the second-best.

Table 1.
Quantitative comparison.
For intuitive comparison, this section additionally selects three different styles for testing, as shown in Figure 7. The figure displays three pairs of content images and style images along with the resulting stylized images. Among the different comparison methods, AdaIN, AnimeGANv2, Lapstyle, and CAP-VATNet were selected and compared subjectively with the model proposed in this paper. From the results, it is evident that the model proposed in this paper performs better in terms of style transfer effects and content preservation. Notably, it is able to maintain the integrity of content edges and avoid the feature entanglement phenomenon between content and style seen in other algorithms.

Figure 7.
Rendering of the style transfer experiment.
5.2.3. Inference Time
This section describes style transfer experiments conducted on images with FHD, 2K, and 4K resolutions, along with their recorded GPU inference times and the results of comparative tests. The experimental results are shown in Table 2.
Table 2.
Inference time.
5.2.4. Ablation Study
In addition, we designed a series of ablation experiments to validate the effectiveness of each module in the model. The experiments were evaluated on the COCO dataset and the results are shown in Table 3. Analyzing the optimization effects of the style loss and content loss functions further demonstrates the effectiveness of each module. The experimental results indicate that smaller and faster decreases in the loss lead to better optimization ability on the part of the model. Table 3 presents the specific impact of each module on the model’s performance.
Table 3.
Ablation study on basic components.
From the above experimental results, it can be observed that the style loss decreases from 5.854 to 3.450 when the model incorporates the proposed dense-regressive loss, while the content loss decreases from 6.324 to 5.187. When the dense-regressive loss is used while also replacing conventional convolutions with FEM, the style loss drops to 1.633 and the content loss decreases to 2.326. Additionally incorporating the decoupling encoder results in further reduction of the style loss and content loss to 0.480 and 1.037, respectively.
6. Conclusions
With the increasing demand for images in daily life, research on image understanding and representation has become increasingly important, and application scenarios for style transfer are growing. However, one major issue that needs to be addressed in current image style transfer methods is the interference between content and style information in the transferred image. This issue arises because most existing methods use the same network to simultaneously process both the content and style images, leading to information interference. As a result, there is a feature entanglement of content and style regions, and some areas of the transferred image become blurry. To better address this issue, in this paper we propose a Dual-Branch Decoupled Image Style Transfer Network (DBDST-Net) that uses a Feature Decoupling Encoder to clearly separate content and style features. Additionally, we introduces a degradation loss function to optimize the decoupling effect of the entire network. To address the issue of missing style data in specific scenarios, the Stable Diffusion model is used as the base model, which is then complemented by LoRA to stably generate a batch of images with the same style. Extensive experiments demonstrate the effectiveness of our proposed DBDST-Net. Future research could include the design of a universal style transfer method to enable conversion between different styles.
Author Contributions
Conceptualization, N.S. and Y.P.; methodology, N.S., J.Z., and J.W.; data curation, N.S. and Y.L.; writing—original draft preparation, N.S. and J.W.; writing—review and editing, J.Z., Y.L., and Y.P.; supervision and project administration, J.W., Y.L., and Y.P. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Natural Science Foundation of China (62272040, 62201525, 61972050, 62172005) and the Fundamental Research Funds for the Central Universities (CUC24QT08).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Conflicts of Interest
Author Na Sun was employed by the company GraphOrigin (Beijing) Technology. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Meier, B.J. Painterly rendering for animation. In Proceedings of the 23rd Annual Conference on Computer Graphics and Interactive Techniques, New Orleans, LA, USA, 4–9 August 1996; pp. 477–484. [Google Scholar]
- Hertzmann, A.; Jacobs, C.E.; Oliver, N.; Curless, B.; Salesin, D.H. Image analo-gies. In Proceedings of the 28th Annual Conference on Computer Graphics Andinteractive Techniques, Los Angeles, CA, USA, 12–17 August 2001; pp. 327–340. [Google Scholar]
- Efros, A.A.; Leung, T.K. Texture synthesis by nonparametric sam- pling. In Proceedings of the 7th IEEE International Conference on Computer Vision, Kerkyra (Corfu), Greece, 20–27 September 1999; pp. 1033–1038. [Google Scholar]
- Wei, L.Y.; Levoy, M. Fast texture synthesis using treestructured vector quantiza- tion. In Proceedings of the 27th Annual Conference on Computer Graphics and Interactive Techniques, New Orleans, LA, USA, 23–28 July 2000; pp. 479–488. [Google Scholar]
- Han, C.; Risser, E.; Ramamoorthi, R.; Grinspun, E. Multiscale texture synthesis. In Proceedings of the ACM SIGGRAPH 2008, Los Angeles, CA, USA, 11–15 August 2008; pp. 1–8. [Google Scholar]
- Gatys, L.; Ecker, A.S.; Bethge, M. Texture synthesis using convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 7–12 December 2015; pp. 262–270. [Google Scholar]
- Johnson, J.; Alahi, A.; Li, F.-F. Perceptual losses for real-time style transfer and super- resolution. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 694–711. [Google Scholar]
- Ulyanov, D.; Lebedev, V.; Vedaldi, A.; Lempitsky, V. Texture networks: Feed-forward synthesis of textures and stylized images. In Proceedings of the International Conference on Machine Learning (ICML), New York, NY, USA, 19–24 June 2016; pp. 1349–1357. [Google Scholar]
- Jing, Y.; Liu, X.; Ding, Y.; Wang, X.; Ding, E.; Song, M.; Wen, S. Dynamic instance normalization for arbitrary style transfer. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 4369–4376. [Google Scholar]
- Zhang, Y.; Tang, F.; Dong, W.; Huang, H.; Ma, C.; Lee, T.Y.; Xu, C. A unified arbitrary style transfer framework via adaptive contrastive learning. ACM Trans. Graph. 2023, 42, 1–16. [Google Scholar] [CrossRef]
- Deng, Y.; Tang, F.; Dong, W.; Ma, C.; Pan, X.; Wang, L.; Xu, C. StyTr2: Image Style Transfer with Transformers. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2021; pp. 11316–11326. [Google Scholar]
- Chen, J.; Liu, G.; Chen, X. AnimeGAN: A novel lightweight GAN for photo animation. In Artificial Intelligence Algorithms and Applications: 11th International Symposium, ISICA 2019, Guangzhou, China, November 16–17, 2019; Revised Selected Papers 11; Springer: Singapore, 16 November 2020; pp. 242–256. [Google Scholar]
- Wang, Z.; Zhao, L.; Zuo, Z.; Li, A.; Chen, H.; Xing, W.; Lu, D. MicroAST: Towards super-fast ultra-resolution arbitrary style transfer. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 2742–2750. [Google Scholar]
- Ruta, D.S.; Gilbert, A.; Collomosse, J.P.; Shechtman, E.; Kolkin, N. Neat: Neural artistic tracing for beautiful style transfer. arXiv 2023, arXiv:2304.05139. [Google Scholar]
- Park, D.Y.; Lee, K.H. Arbitrary style transfer with style-attentional networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 5880–5888. [Google Scholar]
- Zhang, Y.; Tang, F.; Dong, W.; Huang, H.; Ma, C.; Lee, T.Y.; Xu, C. Domain enhanced arbitrary image style transfer via contrastive learning. In Proceedings of the ACM SIGGRAPH 2022 Conference Proceedings, Vancouver, BC, Canada, 8–11 August 2022; pp. 1–8. [Google Scholar]
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. Lora: Low-rank adaptation of large language models. ICLR 2022, 1, 3. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. In Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 6840–6851. [Google Scholar]
- Wang, Z.; Zhao, L.; Xing, W. Stylediffusion: Controllable disentangled style transfer via diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision., Paris, France, 2-6 October 2023; pp. 7677–7689. [Google Scholar]
- Ramesh, A.; Dhariwal, P.; Nichol, A.; Chu, C.; Chen, M. Hierarchical text-conditional image generation with clip latents. arXiv 2022, arXiv:2204.06125. [Google Scholar]
- Kang, M.; Zhang, R.; Barnes, C.; Paris, S.; Kwak, S.; Park, J.; Shechtman, E.; Zhu, J.Y.; Park, T. Distilling diffusion models into conditional gans. In European Conference on Computer Vision; Springer Nature: Cham, Switzerland, 2024; pp. 428–447. [Google Scholar]
- Ashikhmin, M. Synthesizing natural textures. In Proceedings of the 2001 Symposium on Interactive 3D Graphics, Research Triangle Park, NC, USA, 19–21 March 2001; pp. 217–226. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar]
- Chen, Y.; Lai, Y.K.; Liu, Y.J. CartoonGAN: Generative Adversarial Networks for Photo Carbonization. In Proceedings of the IEEE/CVF Conference on Computer Vision & Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Lin, T.; Ma, Z.; Li, F.; He, D.; Li, X.; Ding, E.; Wang, N.; Li, J.; Gao, X. Drafting and Revision: Laplacian Pyramid Network for Fast High-Quality Artistic Style Transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021. [Google Scholar] [CrossRef]
- Li, S. Diffstyler: Diffusion-based localized image style transfer. arXiv 2024, arXiv:2403.18461. [Google Scholar]
- Trockman, A.; Kolter, J.Z. Patches are all you need? arXiv 2022, arXiv:2201.09792. [Google Scholar]
- Kolkin, N.; Salavon, J.; Shakhnarovich, G. Style transfer by relaxed optimal transport and self-similarity. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 10051–10060. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 10684–10695. [Google Scholar]
- Huang, X.; Belongie, S. Arbitrary style transfer in real-time with adaptive instance normalization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1501–1510. [Google Scholar]
- Yoo, J.; Uh, Y.; Chun, S.; Kang, B.; Ha, J.W. Photorealistic Style Transfer via Wavelet Trans- forms. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar] [CrossRef]
- Wen, L.; Gao, C.; Zou, C. CAP-VSTNet: Content affinity preserved versatile style transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 18300–18309. [Google Scholar]
- Wang, Z.; Zhang, J.; Ji, Z.; Bai, J.; Shan, S. Cclap: Controllable chinese landscape painting generation via latent diffusion model. In Proceedings of the 2023 IEEE International Conference on Multimedia and Expo (ICME), Brisbane, QLD, Australia, 10–14 July 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 2117–2122. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).