
Large Language Models in Medical Chatbots: Opportunities, Challenges, and the Need to Address AI Risks



Abstract

1. Introduction
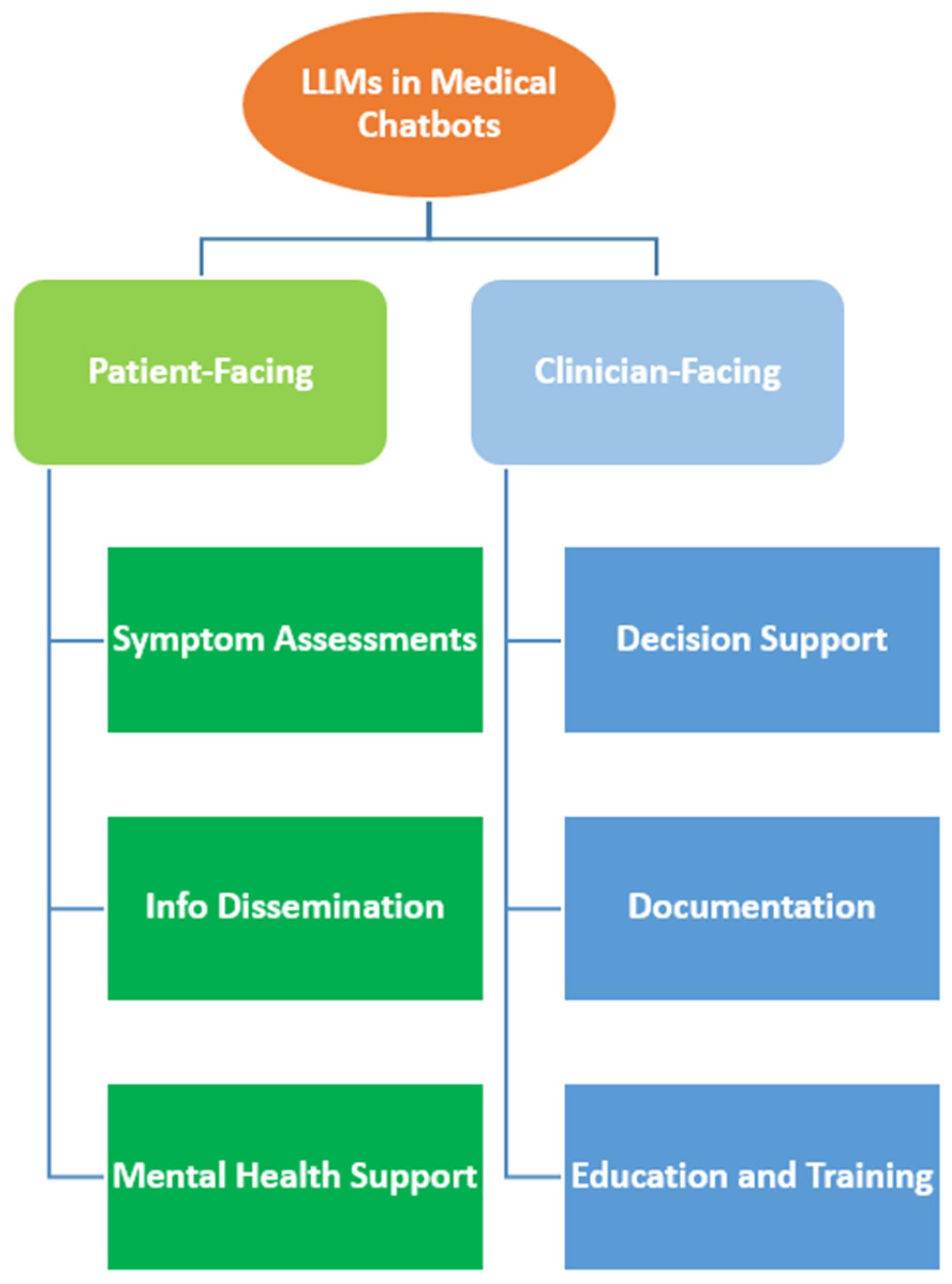
2. Applications of LLMs in Medical Chatbots
2.1. Patient-Facing Applications
2.2. Clinician-Facing Applications
2.3. Applications in Rare Disease Diagnosis and Treatment
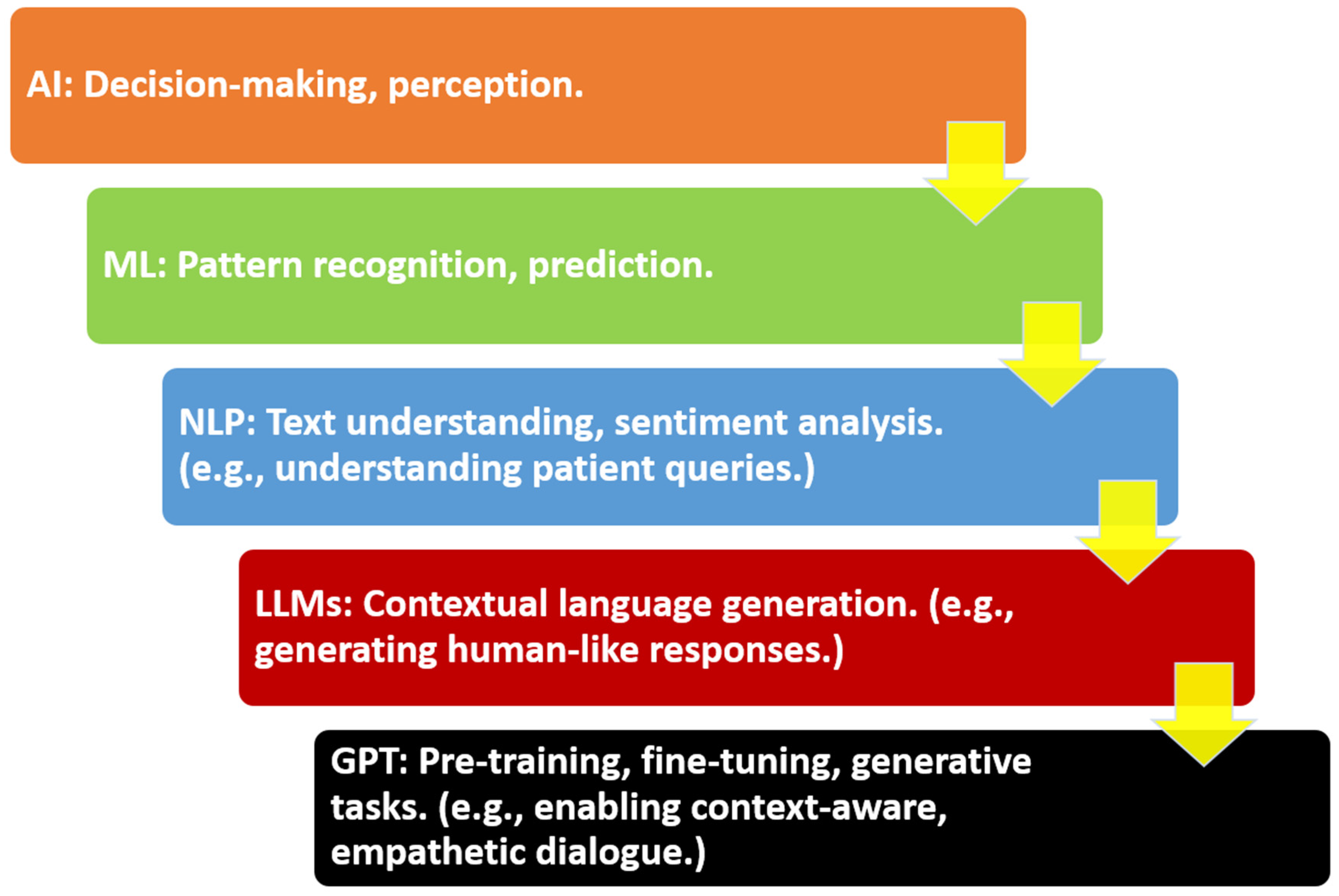
3. Core Technologies and Architectures
3.1. Overview of LLMs
3.2. Fine-Tuning and Prompt Engineering
3.3. Model Evaluation and Limitations
4. Benefits and Opportunities
User Acceptance and Trust in LLM-Powered Medical Chatbots
5. Challenges, Limitations, and AI Risk Mitigations
5.1. Accuracy and Hallucination
5.2. Bias and Fairness
5.3. Data Privacy and Security
6. Evaluation and Benchmarking
6.1. Existing Benchmarks
6.2. Human-in-the-Loop Evaluation
6.3. Real-World Trials and Pilots
7. Ethical, Legal, and Regulatory Considerations
7.1. Ethical Issues
7.2. Legal Accountability
7.3. Regulatory Governance
8. Future Directions Incorporating AI Risk Management into LLMs
8.1. Model Improvements
8.2. Human–AI Collaboration Paradigms
8.3. Integration with Health Systems
8.4. Privacy-Preserving Approaches
8.5. Policy and Governance
9. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| AI | artificial intelligence |
| BERT | Bidirectional Encoder Representations from Transformers |
| BLEU | Bilingual Evaluation Understudy |
| CC BY | Creative Commons Attribution |
| CPT | Current Procedural Terminology |
| DOAJ | Directory of Open Access Journals |
| EHR | electronic health record |
| FDA | U.S. Food and Drug Administration |
| FL | federated learning |
| GAI | generative artificial intelligence |
| GDPR | General Data Protection Regulation |
| GPT | generative pretrained transformer |
| HIPAA | Health Insurance Portability and Accountability Act |
| HITL | human-in-the-loop |
| ICD | International Classification of Diseases |
| LLM | large language model |
| METEOR | Metric for Evaluation of Translation with Explicit ORdering |
| MHRA | Medicines and Healthcare products Regulatory Agency |
| ML | machine learning |
| NLP | natural language processing |
| PaLM | Pathways Language Model |
| PHI | protected health information |
| RLHF | Reinforcement Learning from Human Feedback |
| ROUGE | Recall-Oriented Understudy for Gisting Evaluation |
| SaMD | Software as a Medical Device |
| SOAP | Subjective, Objective, Assessment, Plan |
| TLA | Three Letter Acronym |
| USMLE | United States Medical Licensing Examination |
References
- Hindelang, M.; Sitaru, S.; Zink, A. Transforming health care through chatbots for medical history-taking and future directions: Comprehensive systematic review. JMIR Med. Inform. 2024, 12, e56628. [Google Scholar] [CrossRef] [PubMed]
- Xu, L.; Sanders, L.; Li, K.; Chow, J.C. Chatbot for health care and oncology applications using artificial intelligence and machine learning: Systematic review. JMIR Cancer 2021, 7, e27850. [Google Scholar] [CrossRef] [PubMed]
- Weizenbaum, J. ELIZA—A computer program for the study of natural language communication between man and machine. Commun. ACM 1966, 9, 36–45. [Google Scholar] [CrossRef]
- Siddique, S.; Chow, J.C. Machine learning in healthcare communication. Encyclopedia 2021, 1, 220–239. [Google Scholar] [CrossRef]
- Locke, S.; Bashall, A.; Al-Adely, S.; Moore, J.; Wilson, A.; Kitchen, G.B. Natural language processing in medicine: A review. Trends Anaesth. Crit. Care 2021, 38, 4–9. [Google Scholar] [CrossRef]
- Babu, A.; Boddu, S.B. Bert-based medical chatbot: Enhancing healthcare communication through natural language understanding. Explor. Res. Clin. Soc. Pharm. 2024, 13, 100419. [Google Scholar] [CrossRef]
- Chow, J.C.; Wong, V.; Li, K. Generative pre-trained transformer-empowered healthcare conversations: Current trends, challenges, and future directions in large language model-enabled medical chatbots. BioMedInformatics 2024, 4, 837–852. [Google Scholar] [CrossRef]
- Huo, B.; Boyle, A.; Marfo, N.; Tangamornsuksan, W.; Steen, J.P.; McKechnie, T.; Lee, Y.; Mayol, J.; Antoniou, S.A.; Thirunavukarasu, A.J.; et al. Large language models for chatbot health advice studies: A systematic review. JAMA Netw. Open 2025, 8, e2457879. [Google Scholar] [CrossRef]
- Chow, J.C. Artificial intelligence in radiotherapy and patient care. In Artificial Intelligence in Medicine; Springer: Cham, Switzerland, 2021; pp. 1–13. [Google Scholar]
- Chakraborty, C.; Pal, S.; Bhattacharya, M.; Dash, S.; Lee, S.S. Overview of chatbots with special emphasis on artificial intelligence-enabled ChatGPT in medical science. Front. Artif. Intell. 2023, 6, 1237704. [Google Scholar] [CrossRef]
- Harris, E. Large language models answer medical questions accurately, but can’t match clinicians’ knowledge. JAMA 2023, 330, 792–794. [Google Scholar] [CrossRef]
- Chow, J.C.; Sanders, L.; Li, K. Impact of ChatGPT on medical chatbots as a disruptive technology. Front. Artif. Intell. 2023, 6, 1166014. [Google Scholar] [CrossRef] [PubMed]
- Bengio, Y.; Hinton, G.; Yao, A.; Song, D.; Abbeel, P.; Darrell, T.; Harari, Y.N.; Zhang, Y.Q.; Xue, L.; Shalev-Shwartz, S.; et al. Managing extreme AI risks amid rapid progress. Science 2024, 384, 842–845. [Google Scholar] [CrossRef] [PubMed]
- Denecke, K.; May, R.; LLM Health Group; Rivera Romero, O. Potential of Large Language Models in Health Care: Delphi Study. J. Med. Internet Res. 2024, 26, e52399. [Google Scholar] [CrossRef]
- Chandel, A. Healthcare chatbot using SVM & decision tree. Trends Health Inform. 2025, 2, 10–17. [Google Scholar]
- Singhal, K.; Tu, T.; Gottweis, J.; Sayres, R.; Wulczyn, E.; Amin, M.; Hou, L.; Clark, K.; Pfohl, S.R.; Cole-Lewis, H.; et al. Toward expert-level medical question answering with large language models. Nat. Med. 2025, 31, 943–950. [Google Scholar] [CrossRef]
- Liu, Z.; Hou, Z.; Di, Y.; Yang, K.; Sang, Z.; Xie, C.; Yang, J.; Liu, S.; Wang, J.; Li, C.; et al. Infi-Med: Low-resource medical MLLMs with robust reasoning evaluation. arXiv 2025, arXiv:2505.23867. [Google Scholar]
- Chow, J.C.; Sanders, L.; Li, K. Design of an educational chatbot using artificial intelligence in radiotherapy. AI 2023, 4, 319–332. [Google Scholar] [CrossRef]
- Kumar, M. AI-driven healthcare chatbots: Enhancing access to medical information and lowering healthcare costs. J. Artif. Intell. Cloud Comput. 2023, 2, 2–5. [Google Scholar] [CrossRef]
- Zhang, S.; Song, J. A chatbot-based question and answer system for the auxiliary diagnosis of chronic diseases based on large language model. Sci. Rep. 2024, 14, 17118. [Google Scholar] [CrossRef]
- Rebelo, N.; Sanders, L.; Li, K.; Chow, J.C. Learning the treatment process in radiotherapy using an artificial intelligence–assisted chatbot: Development study. JMIR Form. Res. 2022, 6, e39443. [Google Scholar] [CrossRef]
- Shiferaw, M.W.; Zheng, T.; Winter, A.; Mike, L.A.; Chan, L.N. Assessing the accuracy and quality of artificial intelligence (AI) chatbot-generated responses in making patient-specific drug-therapy and healthcare-related decisions. BMC Med. Inform. Decis. Mak. 2024, 24, 404. [Google Scholar] [CrossRef] [PubMed]
- Lawrence, H.R.; Schneider, R.A.; Rubin, S.B.; Matarić, M.J.; McDuff, D.J.; Bell, M.J. The opportunities and risks of large language models in mental health. JMIR Ment. Health 2024, 11, e59479. [Google Scholar] [CrossRef] [PubMed]
- Vagwala, M.K.; Asher, R. Conversational artificial intelligence and distortions of the psychotherapeutic frame: Issues of boundaries, responsibility, and industry interests. Am. J. Bioeth. 2023, 23, 28–30. [Google Scholar] [CrossRef] [PubMed]
- Kovacek, D.; Chow, J.C. An AI-assisted chatbot for radiation safety education in radiotherapy. IOP SciNotes 2021, 2, 034002. [Google Scholar] [CrossRef]
- Seo, J.; Choi, D.; Kim, T.; Cha, W.C.; Kim, M.; Yoo, H.; Oh, N.; Yi, Y.; Lee, K.H.; Choi, E. Evaluation framework of large language models in medical documentation: Development and usability study. J. Med. Internet Res. 2024, 26, e58329. [Google Scholar] [CrossRef]
- Hager, P.; Jungmann, F.; Holland, R.; Bhagat, K.; Hubrecht, I.; Knauer, M.; Vielhauer, J.; Makowski, M.; Braren, R.; Kaissis, G.; et al. Evaluation and mitigation of the limitations of large language models in clinical decision-making. Nat. Med. 2024, 30, 2613–2622. [Google Scholar] [CrossRef]
- Li, L.; Zhou, J.; Gao, Z.; Hua, W.; Fan, L.; Yu, H.; Hagen, L.; Zhang, Y.; Assimes, T.L.; Hemphill, L.; et al. A scoping review of using large language models (LLMs) to investigate electronic health records (EHRs). arXiv 2024, arXiv:2405.03066. [Google Scholar]
- Simmons, A.; Takkavatakarn, K.; McDougal, M.; Dilcher, B.; Pincavitch, J.; Meadows, L.; Kauffman, J.; Klang, E.; Wig, R.; Smith, G.; et al. Extracting international classification of diseases codes from clinical documentation using large language models. Appl. Clin. Inform. 2025, 16, 337–344. [Google Scholar] [CrossRef]
- Ong, J.; Kedia, N.; Harihar, S.; Vupparaboina, S.C.; Singh, S.R.; Venkatesh, R.; Vupparaboina, K.; Bollepalli, S.C.; Chhablani, J. Applying large language model artificial intelligence for retina international classification of diseases (ICD) coding. J. Med. Artif. Intell. 2023, 6, 1166014. [Google Scholar] [CrossRef]
- Chow, J.C.; Wong, V.; Sanders, L.; Li, K. Developing an AI-assisted educational chatbot for radiotherapy using the IBM Watson assistant platform. Healthcare 2023, 11, 2417. [Google Scholar] [CrossRef]
- Brügge, E.; Ricchizzi, S.; Arenbeck, M.; Keller, M.N.; Schur, L.; Stummer, W.; Holling, M.; Lu, M.H.; Darici, D. Large language models improve clinical decision making of medical students through patient simulation and structured feedback: A randomized controlled trial. BMC Med. Educ. 2024, 24, 1391. [Google Scholar] [CrossRef] [PubMed]
- Schumacher, E.; Naik, D.; Kannan, A. Rare Disease Differential Diagnosis with Large Language Models at Scale: From Abdominal Actinomycosis to Wilson’s Disease. arXiv 2025, arXiv:2502.15069. [Google Scholar]
- Yuan, S.; Bai, Z.; Xu, M.; Yang, F.; Gao, Y.; Yu, H. ChatGPT-assisted clinical decision-making for rare genetic metabolic disorders: A preliminary case-based study. Front. Genet. 2023, 14, 1212495. [Google Scholar]
- Gao, C.A.; Howard, F.M.; Markov, N.S.; Dyer, E.C.; Ramesh, S.; Luo, Y.; Pearson, A.T. Comparing scientific abstracts generated by ChatGPT to original abstracts using an artificial intelligence output detector, plagiarism detector, and blinded human reviewers. NPJ Digit. Med. 2023, 6, 75. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. Available online: https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf (accessed on 24 June 2025).
- Dauphin, Y.N.; Fan, A.; Auli, M.; Grangier, D. Language modeling with gated convolutional networks. In Proceedings of the International Conference on Machine Learning 2017, Sydney, Australia, 11–15 August 2017; pp. 933–941. [Google Scholar]
- Alto, V. Modern Generative AI with ChatGPT and OpenAI Models: Leverage the Capabilities of OpenAI’s LLM for Productivity and Innovation with GPT3 and GPT4; Packt Publishing Ltd.: Birmingham, UK, 2023. [Google Scholar]
- Koroteev, M.V. BERT: A review of applications in natural language processing and understanding. arXiv 2021, arXiv:2103.11943. [Google Scholar]
- Anil, R.; Dai, A.M.; Firat, O.; Johnson, M.; Lepikhin, D.; Passos, A.; Shakeri, S.; Taropa, E.; Bailey, P.; Chen, Z.; et al. Palm 2 technical report. arXiv 2023, arXiv:2305.10403. [Google Scholar]
- Luo, R.; Sun, L.; Xia, Y.; Qin, T.; Zhang, S.; Poon, H.; Liu, T.Y. BioGPT: Generative pre-trained transformer for biomedical text generation and mining. Brief. Bioinform. 2022, 23, bbac409. [Google Scholar] [CrossRef]
- Tu, T.; Azizi, S.; Driess, D.; Schaekermann, M.; Amin, M.; Chang, P.C.; Carroll, A.; Lau, C.; Tanno, R.; Ktena, I.; et al. Towards Generalist Biomedical AI. NEJM AI 2024, 1, AIoa2300138. [Google Scholar] [CrossRef]
- Yang, X.; Chen, A.; PourNejatian, N.; Shin, H.C.; Smith, K.E.; Parisien, C.; Compas, C.; Martin, C.; Flores, M.G.; Zhang, Y.; et al. Gatortron: A large clinical language model to unlock patient information from unstructured electronic health records. arXiv 2022, arXiv:2203.03540. [Google Scholar]
- Ross, E.; Kansal, Y.; Renzella, J.; Vassar, A.; Taylor, A. Supervised fine-tuning LLMs to behave as pedagogical agents in programming education. arXiv 2025, arXiv:2502.20527. [Google Scholar]
- Hao, S.; Duan, L. Online learning from strategic human feedback in LLM fine-tuning. In Proceedings of the ICASSP 2025 IEEE International Conference on Acoustics, Speech and Signal Processing, Hyderabad, India, 6–11 April 2025; pp. 1–5. [Google Scholar]
- Chaddad, A.; Jiang, Y.; He, C. OpenAI ChatGPT: A potential medical application. In Proceedings of the 2023 IEEE International Conference on E-Health Networking, Application & Services (Healthcom), Chongqing, China, 15–17 December 2023; pp. 210–215. [Google Scholar]
- Lee, U.; Jung, H.; Jeon, Y.; Sohn, Y.; Hwang, W.; Moon, J.; Kim, H. Few-shot is enough: Exploring ChatGPT prompt engineering method for automatic question generation in English education. Educ. Inf. Technol. 2024, 29, 11483–11515. [Google Scholar] [CrossRef]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Ichter, B.; Xia, F.; Chi, E.H.; Le, Q.V.; Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. Adv. Neural Inf. Process. Syst. 2022, 35, 24824–24837. [Google Scholar]
- Chauhan, S.; Daniel, P. A comprehensive survey on various fully automatic machine translation evaluation metrics. Neural Process. Lett. 2023, 55, 12663–12677. [Google Scholar] [CrossRef]
- Gilson, A.; Safranek, C.W.; Huang, T.; Socrates, V.; Chi, L.; Taylor, R.A.; Chartash, D. How does ChatGPT perform on the United States Medical Licensing Examination (USMLE)? JMIR Med. Educ. 2023, 9, e45312. [Google Scholar] [CrossRef]
- Zhou, Y.; Liu, X.; Ning, C.; Wu, J. Multifaceteval: Multifaceted evaluation to probe LLMs in mastering medical knowledge. arXiv 2024, arXiv:2406.02919. [Google Scholar]
- Jin, Q.; Dhingra, B.; Liu, Z.; Cohen, W.W.; Lu, X. PubmedQA: A dataset for biomedical research question answering. arXiv 2019, arXiv:1909.06146. [Google Scholar]
- Cheng, N.; Yan, Z.; Wang, Z.; Li, Z.; Yu, J.; Zheng, Z.; Tu, K.; Xu, J.; Han, W. Potential and limitations of LLMs in capturing structured semantics: A case study on SRL. In International Conference on Intelligent Computing; Springer: Singapore, 2024; pp. 50–61. [Google Scholar]
- Chow, J.C.; Li, K. Developing effective frameworks for large language model–based medical chatbots: Insights from radiotherapy education with ChatGPT. JMIR Cancer 2025, 11, e66633. [Google Scholar] [CrossRef]
- Yang, R.; Tan, T.F.; Lu, W.; Thirunavukarasu, A.J.; Ting, D.S.; Liu, N. Large language models in health care: Development, applications, and challenges. Health Care Sci. 2023, 2, 255–263. [Google Scholar] [CrossRef]
- Zhang, W.; Aljunied, M.; Gao, C.; Chia, Y.K.; Bing, L. M3Exam: A multilingual, multimodal, multilevel benchmark for examining large language models. Adv. Neural Inf. Process. Syst. 2023, 36, 5484–5505. [Google Scholar]
- Razafinirina, M.A.; Dimbisoa, W.G.; Mahatody, T. Pedagogical alignment of large language models (LLM) for personalized learning: A survey, trends and challenges. J. Intell. Learn. Syst. Appl. 2024, 16, 448–480. [Google Scholar] [CrossRef]
- Abd-Alrazaq, A.; AlSaad, R.; Alhuwail, D.; Ahmed, A.; Healy, P.M.; Latifi, S.; Aziz, S.; Damseh, R.; Alabed Alrazak, S.; Sheikh, J. Large language models in medical education: Opportunities, challenges, and future directions. JMIR Med. Educ. 2023, 9, e48291. [Google Scholar] [CrossRef] [PubMed]
- Yang, Z.; Wang, D.; Zhou, F.; Song, D.; Zhang, Y.; Jiang, J.; Lin, F.; Liang, J.; Chen, E.M.; Li, F.; et al. Understanding natural language: Potential application of large language models to ophthalmology. Asia-Pac. J. Ophthalmol. 2024, 13, 100085. [Google Scholar] [CrossRef] [PubMed]
- Sabanayagam, C.; Banu, R.; Lim, C.; Tham, Y.C.; Cheng, C.Y.; Tan, G.; Ekinci, E.; Sheng, B.; McKay, G.; Shaw, J.E.; et al. Artificial intelligence in chronic kidney disease management: A scoping review. Theranostics 2025, 15, 4566. [Google Scholar] [CrossRef]
- Mulukuntla, S. Digital Health Literacy: Empowering Patients in the Era of Electronic Medical Records. EPH Int. J. Med. Health Sci. 2020, 6, 23–24. [Google Scholar]
- De Busser, B.; Roth, L.; De Loof, H. The role of large language models in self-care: A study and benchmark on medicines and supplement guidance accuracy. Int. J. Clin. Pharm. 2024, 1–10. [Google Scholar] [CrossRef]
- Kohler, A.; Tingstrom, P.; Jaarsma, T.; Nilsson, S. Patient empowerment and general self-efficacy in patients with coronary heart disease: A cross-sectional study. BMC Fam Pract. 2018, 19, 76. [Google Scholar]
- McAllister, M.; Dunn, G.; Payne, K.; Davies, L.; Todd, C. Patient empowerment: The need to consider it as a measurable patient-reported outcome for chronic conditions. BMC Health Serv. Res. 2012, 12, 157. [Google Scholar] [CrossRef]
- Lin, C.; Kuo, C.F. Roles and potential of large language models in healthcare: A comprehensive review. Biomed. J. 2025, 100868. [Google Scholar] [CrossRef]
- Dagli, M.M.; Ghenbot, Y.; Ahmad, H.S.; Chauhan, D.; Turlip, R.; Wang, P.; Welch, W.C.; Ozturk, A.K.; Yoon, J.W. Development and validation of a novel AI framework using NLP with LLM integration for relevant clinical data extraction through automated chart review. Sci. Rep. 2024, 14, 26783. [Google Scholar] [CrossRef]
- Kowalski, M.; Johnson, T.; Lee, J.; Patel, S.; Smith, A.; Davis, R.; Nguyen, L.; Thompson, B.; Martinez, C.; Chen, Y.; et al. Implementation of an All-Day Artificial Intelligence–Based Triage System in the Emergency Department. Mayo Clin. Proc. 2022, 97, 1234–1245. [Google Scholar] [CrossRef]
- Nuance Communications. DAX Copilot to Automate the Creation of Clinical Documentation, Reduce Physician Burnout, and Expand Access to Care Deployed Enterprise-Wide at Stanford Health Care. Nuance Newsroom, 11 March 2024. Available online: https://news.nuance.com/2024-03-11-DAX-Copilot-to-Automate-the-Creation-of-Clinical-Documentation,-Reduce-Physician-Burnout,-and-Expand-Access-to-Care-Deployed-Enterprise-Wide-at-Stanford-Health-Care (accessed on 16 June 2025).
- RTB AI. LLM Cost Explained: How to Estimate the Price of Using Large Language Models. RTB AI Blog, 2024. Available online: https://www.rtb-ai.com/post/how-to-estimate-the-cost-of-using-a-large-language-model (accessed on 16 June 2025).
- Sun, X.; Ma, R.; Zhao, X.; Li, Z.; Lindqvist, J.; El Ali, A.; Bosch, J.A. Trusting the Search: Unraveling Human Trust in Health Information from Google and ChatGPT. arXiv 2024, arXiv:2403.09987. [Google Scholar]
- Rezaeian, O.; Asan, O.; Bayrak, A.E. The Impact of AI Explanations on Clinicians’ Trust and Diagnostic Accuracy in Breast Cancer. arXiv 2024, arXiv:2412.11298. [Google Scholar] [CrossRef] [PubMed]
- Branley-Bell, D.; Talbot, C.V. Exploring the Impact of Chatbot Design on Trust and Engagement in Mental Health Support. JMIR Ment. Health 2021, 8, e23429. [Google Scholar]
- Chin, H.; Song, H.; Baek, G.; Jung, C. The Potential of Chatbots for Emotional Support and Promoting Mental Well-Being in Different Cultures: Mixed Methods Study. J. Med. Internet Res. 2023, 25, e46901. [Google Scholar] [CrossRef]
- Aljamaan, F.; Temsah, M.H.; Altamimi, I.; Al-Eyadhy, A.; Jamal, A.; Alhasan, K.; Mesallam, T.A.; Farahat, M.; Malki, K.H. Reference hallucination score for medical artificial intelligence chatbots: Development and usability study. JMIR Med. Inform. 2024, 12, e54345. [Google Scholar] [CrossRef] [PubMed]
- Johri, S.; Jeong, J.; Tran, B.A.; Schlessinger, D.I.; Wongvibulsin, S.; Barnes, L.A.; Zhou, H.Y.; Cai, Z.R.; Van Allen, E.M.; Kim, D.; et al. An evaluation framework for clinical use of large language models in patient interaction tasks. Nat. Med. 2025, 31, 77–86. [Google Scholar] [CrossRef]
- Wu, S.; Zhao, S.; Yasunaga, M.; Huang, K.; Cao, K.; Huang, Q.; Ioannidis, V.; Subbian, K.; Zou, J.Y.; Leskovec, J. STaRK: Benchmarking LLM retrieval on textual and relational knowledge bases. Adv. Neural Inf. Process. Syst. 2024, 37, 127129–127153. [Google Scholar]
- Ohde, J.W.; Rost, L.M.; Overgaard, J.D. The burden of reviewing LLM-generated content. NEJM AI 2025, 2, AIp2400979. [Google Scholar] [CrossRef]
- Menz, B.D.; Kuderer, N.M.; Bacchi, S.; Modi, N.D.; Chin-Yee, B.; Hu, T.; Rickard, C.; Haseloff, M.; Vitry, A.; McKinnon, R.A.; et al. Current safeguards, risk mitigation, and transparency measures of large language models against the generation of health disinformation: Repeated cross-sectional analysis. BMJ 2024, 384, e078538. [Google Scholar] [CrossRef]
- Chustecki, M. Benefits and risks of AI in health care: Narrative review. Interact. J. Med. Res. 2024, 13, e53616. [Google Scholar] [CrossRef] [PubMed]
- Yeo, Y.H.; Peng, Y.; Mehra, M.; Samaan, J.; Hakimian, J.; Clark, A.; Suchak, K.; Krut, Z.; Andersson, T.; Persky, S.; et al. Evaluating for evidence of sociodemographic bias in conversational AI for mental health support. Cyberpsychol. Behav. Soc. Netw. 2025, 28, 44–51. [Google Scholar] [CrossRef] [PubMed]
- Tan, D.N.H.; Tham, Y.-C.; Koh, V.; Loon, S.C.; Aquino, M.C.; Lun, K.; Cheng, C.-Y.; Ngiam, K.Y.; Tan, M. Evaluating chatbot responses to patient questions in the field of glaucoma. Front. Med. 2024, 11, 1359073. [Google Scholar] [CrossRef] [PubMed]
- Chhikara, G.; Sharma, A.; Ghosh, K.; Chakraborty, A. Few-shot fairness: Unveiling LLM’s potential for fairness-aware classification. arXiv 2024, arXiv:2402.18502. [Google Scholar]
- Ito, N.; Kadomatsu, S.; Fujisawa, M.; Fukaguchi, K.; Ishizawa, R.; Kanda, N.; Kasugai, D.; Nakajima, M.; Goto, T.; Tsugawa, Y. The Accuracy and Potential Racial and Ethnic Biases of GPT-4 in the Diagnosis and Triage of Health Conditions: Evaluation Study. JMIR Med. Educ. 2023, 9, e47532. [Google Scholar] [CrossRef]
- Arnason, T.J.; Mirza, K.M.; Lilley, C.M. Assessing the Impact of Race, Sexual Orientation, and Gender Identity on USMLE Style Questions: Preliminary Results of a Randomized Controlled Trial. Am. J. Clin. Pathol. 2023, 160 (Suppl. S1), S64–S65. [Google Scholar] [CrossRef]
- Rawat, R.; McBride, H.; Nirmal, D.; Ghosh, R.; Moon, J.; Alamuri, D.; O’Brien, S.; Zhu, K. DiversityMedQA: Assessing Demographic Biases in Medical Diagnosis using Large Language Models. arXiv 2024, arXiv:2409.01497. [Google Scholar]
- Rathod, V.; Nabavirazavi, S.; Zad, S.; Iyengar, S.S. Privacy and security challenges in large language models. In Proceedings of the 2025 IEEE 15th Annual Computer Communication Workshop Conference (CCWC), Las Vegas, NV, USA, 6–8 January 2025; pp. 00746–00752. [Google Scholar]
- Feretzakis, G.; Verykios, V.S. Trustworthy AI: Securing sensitive data in large language models. AI 2024, 5, 2773–2800. [Google Scholar] [CrossRef]
- Srinivasan, A.; Patil, R. Navigating the challenges and opportunities of AI and LLM integration in cloud computing. Baltic Multidiscip. Res. Lett. J. 2025, 2, 8–15. [Google Scholar]
- Siemens, W.; von Elm, E.; Binder, H.; Böhringer, D.; Eisele-Metzger, A.; Gartlehner, G.; Hanegraaf, P.; Metzendorf, M.-I.; Mosselman, J.-J.; Nowak, A.; et al. Opportunities, challenges and risks of using artificial intelligence for evidence synthesis. BMJ Evid.-Based Med. 2025. [Google Scholar] [CrossRef]
- Khan, Z.Y.; Hussain, F.K.; Kurniawan, D. Communication Efficiency and Non-Independent and Identically Distributed Data Challenge in Federated Learning: A Systematic Mapping Study. Appl. Sci. 2024, 14, 2720. [Google Scholar] [CrossRef]
- Xu, H.; Zhang, J.; Xu, Y.; Liu, Z.; Ding, S.; Zhang, Y. FedVCK: Non-IID Robust and Communication-Efficient Federated Learning via Valuable Condensed Knowledge for Medical Image Analysis. arXiv 2024, arXiv:2412.18557. [Google Scholar]
- Karimireddy, S.P.; Kale, S.; Mohri, M.; Reddi, S.; Stich, S.U.; Suresh, A.T. SCAFFOLD: Stochastic Controlled Averaging for Federated Learning. J. Mach. Learn. Res. 2020, 21, 1–62. [Google Scholar]
- Yao, Z.; Zhang, Z.; Tang, C.; Bian, X.; Zhao, Y.; Yang, Z.; Wang, J.; Zhou, H.; Jang, W.S.; Ouyang, F.; et al. MedQA-CS: Benchmarking large language models clinical skills using an AI-SCE framework. arXiv 2024, arXiv:2410.01553. [Google Scholar]
- Srinivasan, V.; Jatav, V.; Chandrababu, A.; Sharma, G. On the performance of an explainable language model on PubMedQA. arXiv 2025, arXiv:2504.05074. [Google Scholar]
- Wu, X.; Zhao, Y.; Zhang, Y.; Wu, J.; Zhu, Z.; Zhang, Y.; Ouyang, Y.; Zhang, Z.; Wang, H.; Lin, Z.; et al. MedJourney: Benchmark and evaluation of large language models over patient clinical journey. Adv. Neural Inf. Process. Syst. 2024, 37, 87621–87646. [Google Scholar]
- Ch’en, P.Y.; Day, W.; Pekson, R.C.; Barrientos, J.; Burton, W.B.; Ludwig, A.B.; Jariwala, S.P.; Cassese, T. GPT-4 generated answer rationales to multiple choice assessment questions in undergraduate medical education. BMC Med. Educ. 2025, 25, 333. [Google Scholar] [CrossRef] [PubMed]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL), Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar]
- Van Veen, M.; Saavedra, J.; Wang, K. Clinical Text Summarization with LLM-Based Evaluation. Stanford University CS224N Final Report, 2024. Available online: https://web.stanford.edu/class/cs224n/final-reports/256989380.pdf (accessed on 16 June 2025).
- Schroeder, N.L.; Davis Jaldi, C.; Zhang, S. Large Language Models with Human-In-The-Loop Validation for Systematic Reviews. arXiv 2025, arXiv:2501.11840. [Google Scholar]
- Drori, I.; Te’eni, D. Human-in-the-loop AI reviewing: Feasibility, opportunities, and risks. J. Assoc. Inf. Syst. 2024, 25, 98–109. [Google Scholar] [CrossRef]
- Kumar, S.; Datta, S.; Singh, V.; Datta, D.; Singh, S.K.; Sharma, R. Applications, challenges, and future directions of human-in-the-loop learning. IEEE Access 2024, 12, 75735–75760. [Google Scholar] [CrossRef]
- Turner, P.; Kushniruk, A.; Nohr, C. Are we there yet? Human factors knowledge and health information technology–the challenges of implementation and impact. Yearb. Med. Inform. 2017, 26, 84–91. [Google Scholar] [CrossRef] [PubMed]
- Vismara, L.A.; McCormick, C.E.; Shields, R.; Hessl, D. Extending the parent-delivered Early Start Denver Model to young children with fragile X syndrome. J. Autism Dev. Disord. 2019, 49, 1250–1266. [Google Scholar] [CrossRef]
- Mayo Clinic Press. AI in Healthcare: The Future of Patient Care and Health Management; Mayo Clinic Press Healthy Aging: Rochester, MN, USA, 2023; Available online: https://mcpress.mayoclinic.org/healthy-aging/ai-in-healthcare-the-future-of-patient-care-and-health-management/ (accessed on 16 May 2025).
- Stanford HAI. Large Language Models in Healthcare: Are We There Yet? Stanford HAI News, 2023. Available online: https://hai.stanford.edu/news/large-language-models-healthcare-are-we-there-yet (accessed on 16 May 2025).
- Plaza, B.C. Data sources (LLM) for a clinical decision support model (SSDC) using a healthcare interoperability resources (HL7-FHIR) platform for an ICU ecosystem. Prim. Sci. Med. Public Health 2024, 5, 3–12. [Google Scholar]
- Nazi, Z.A.; Peng, W. Large language models in healthcare and medical domain: A review. Informatics 2024, 11, 57. [Google Scholar] [CrossRef]
- Markus, A.F.; Kors, J.A.; Rijnbeek, P.R. The Role of Explainability in Creating Trustworthy Artificial Intelligence for Health Care: A Comprehensive Survey of the Terminology, Design Choices, and Evaluation Strategies. arXiv 2020, arXiv:2007.15911. [Google Scholar] [CrossRef]
- Bharati, S.; Mondal, M.R.H.; Podder, P. A Review on Explainable Artificial Intelligence for Healthcare: Why, How, and When? arXiv 2023, arXiv:2304.04780. [Google Scholar] [CrossRef]
- Ong, J.C.L.; Ning, Y.; Liu, M.; Ma, Y.; Liang, Z.; Singh, K.; Chang, R.T.; Vogel, S.; Lim, J.C.W.; Tan, I.S.K.; et al. Regulatory Science Innovation for Generative AI and Large Language Models in Health and Medicine: A Global Call for Action. arXiv 2025, arXiv:2502.07794. [Google Scholar]
- U.S. Food and Drug Administration. Artificial Intelligence/Machine Learning (AI/ML)-Based Software as a Medical Device (SaMD) Action Plan. FDA 2021. Available online: https://www.fda.gov/media/145022/download (accessed on 16 June 2025).
- Meskó, B.; Topol, E.J. The Imperative for Regulatory Oversight of Large Language Models (or Generative AI) in Healthcare. NPJ Digit. Med. 2023, 6, 120. [Google Scholar] [CrossRef]
- Chow, J.C.; Li, K. Ethical considerations in human-centered AI: Advancing oncology chatbots through large language models. JMIR Bioinform. Biotechnol. 2024, 5, e64406. [Google Scholar] [CrossRef]
- Ge, Z.; Huang, H.; Zhou, M.; Li, J.; Wang, G.; Tang, S.; Zhuang, Y. WorldGPT: Empowering LLM as multimodal world model. In Proceedings of the 32nd ACM International Conference on Multimedia, Melbourne, VIC, Australia, 28 October–1 November 2024; pp. 7346–7355. [Google Scholar]
- Li, C.; Wong, C.; Zhang, S.; Usuyama, N.; Liu, H.; Yang, J.; Naumann, T.; Poon, H.; Gao, J. Llava-med: Training a large language-and-vision assistant for biomedicine in one day. Adv. Neural Inf. Process. Syst. 2023, 36, 28541–28564. [Google Scholar]
- Koleilat, T.; Asgariandehkordi, H.; Rivaz, H.; Xiao, Y. Medclip-samv2: Towards universal text-driven medical image segmentation. arXiv 2024, arXiv:2409.19483. [Google Scholar]
- Jeong, C. Fine-tuning and utilization methods of domain-specific LLMs. arXiv 2024, arXiv:2401.02981. [Google Scholar]
- Liu, F.; Zhou, H.; Gu, B.; Zou, X.; Huang, J.; Wu, J.; Li, Y.; Chen, S.S.; Hua, Y.; Zhou, P.; et al. Application of large language models in medicine. Nat. Rev. Bioeng. 2025, 3, 445–464. [Google Scholar] [CrossRef]
- Lee, S.; Youn, J.; Kim, H.; Kim, M.; Yoon, S.H. CXR-LLaVA: A Multimodal Large Language Model for Interpreting Chest X-Ray Images. Radiology 2024, 303, 11339. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Wu, Z.; Agarwal, D.; Sun, J. MedCLIP: Contrastive Learning from Unpaired Medical Images and Text. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP), Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 3726–3738. [Google Scholar]
- Li, J.; Zhou, Z.; Lyu, H.; Wang, Z. Large language models-powered clinical decision support: Enhancing or replacing human expertise? Intell. Med. 2025, 5, 1–4. [Google Scholar] [CrossRef]
- Rajashekar, N.C.; Shin, Y.E.; Pu, Y.; Chung, S.; You, K.; Giuffrè, M.; Chan, C.E.; Saarinen, T.; Hsiao, A.; Sekhon, J.S.; et al. Human-algorithmic interaction using a large language model-augmented artificial intelligence clinical decision support system. In Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 11–16 May 2024; pp. 1–20. [Google Scholar]
- Chow, J.C. Quantum computing and machine learning in medical decision-making: A comprehensive review. Algorithms 2025, 18, 156. [Google Scholar] [CrossRef]
- Nguyen, Q.N.; Sidorova, A.; Torres, R. User interactions with chatbot interfaces vs. menu-based interfaces: An empirical study. Comput. Hum. Behav. 2022, 128, 107093. [Google Scholar] [CrossRef]
- Dutta, N.; Dhar, D. Investigating usability of conversational user interfaces for integrated system-physical interactions: A medical device perspective. Int. J. Hum. Comput. Interact. 2025, 41, 271–304. [Google Scholar] [CrossRef]
- Chen, T.L.; Kuo, C.H.; Chen, C.H.; Chen, H.S.; Liu, Y.H. Development of an intelligent hospital information chatbot and evaluation of its system usability. Enterp. Inf. Syst. 2025, 19, 2464746. [Google Scholar] [CrossRef]
- Yin, R.; Neyens, D.M. Examining how information presentation methods and a chatbot impact the use and effectiveness of electronic health record patient portals: An exploratory study. Patient Educ. Couns. 2024, 119, 108055. [Google Scholar] [CrossRef]
- Vasileiou, M.V.; Maglogiannis, I.G. The health chatbots in telemedicine: Intelligent dialog system for remote support. J. Healthc. Eng. 2022, 2022, 4876512. [Google Scholar] [CrossRef]
- Kurniawan, M.H.; Handiyani, H.; Nuraini, T.; Hariyati, R.T.; Sutrisno, S. A systematic review of artificial intelligence-powered (AI-powered) chatbot intervention for managing chronic illness. Ann. Med. 2024, 56, 2302980. [Google Scholar] [CrossRef]
- Li, J. Security implications of AI chatbots in health care. J. Med. Internet Res. 2023, 25, e47551. [Google Scholar] [CrossRef] [PubMed]
- Jalali, N.A.; Hongsong, C. Comprehensive framework for implementing blockchain-enabled federated learning and full homomorphic encryption for chatbot security system. Clust. Comput. 2024, 27, 10859–10882. [Google Scholar] [CrossRef]
- Kanter, G.P.; Packel, E.A. Health care privacy risks of AI chatbots. JAMA 2023, 330, 311–312. [Google Scholar] [CrossRef]
- Azam, A.; Naz, Z.; Khan, M.U. PharmaLLM: A medicine prescriber chatbot exploiting open-source large language models. Hum. Cent. Intell. Syst. 2024, 4, 527–544. [Google Scholar] [CrossRef]
- Lee, H.; Kang, J.; Yeo, J. Medical specialty recommendations by an artificial intelligence chatbot on a smartphone: Development and deployment. J. Med. Internet Res. 2021, 23, e27460. [Google Scholar] [CrossRef]
- Zhu, L.; Mou, W.; Luo, P. Ensuring safety and consistency in artificial intelligence chatbot responses. JAMA Oncol. 2024, 10, 1597. [Google Scholar] [CrossRef]
- Osifowokan, A.S.; Agbadamasi, T.O.; Adukpo, T.K.; Mensah, N. Regulatory and legal challenges of artificial intelligence in the US healthcare system: Liability, compliance, and patient safety. World J. Adv. Res. Rev. 2025, 25, 949–955. [Google Scholar] [CrossRef]
- Warraich, H.J.; Tazbaz, T.; Califf, R.M. FDA perspective on the regulation of artificial intelligence in health care and biomedicine. JAMA 2025, 333, 241–247. [Google Scholar] [CrossRef]
- Hey, C.; Hunter, A.; Muller, M.; Le Roux, N.; Bennett, S.; Moulon, I.; Simoens, S.; Eichler, H.-G. A future European scientific dialogue regulatory framework: Connecting the dots. Clin. Ther. 2024, 46, 293–299. [Google Scholar] [CrossRef] [PubMed]
- Palaniappan, K.; Lin, E.Y.; Vogel, S. Global regulatory frameworks for the use of artificial intelligence (AI) in the healthcare services sector. Healthcare 2024, 12, 562. [Google Scholar] [CrossRef] [PubMed]
- Pham, T. Ethical and legal considerations in healthcare AI: Innovation and policy for safe and fair use. R. Soc. Open Sci. 2025, 12, 241873. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Challenge/Risk | Mitigation Strategies | References |
|---|---|---|---|
| Accuracy and Hallucination | Generation of factually incorrect, unsupported, or misleading medical content. | Integration of fact-checking modules, linkage to verified medical knowledge bases, uncertainty quantification (e.g., confidence scores). | [74,75,76,77,78,79] |
| Bias and Fairness | Unequal performance and discriminatory outputs due to training data biases (e.g., race, gender, SES). | Dataset curation, diverse demographic representation, model auditing, use of model cards and fairness-aware training methods. | [80,81,82,83,84,85] |
| Data Privacy and Security | Risk of PHI leakage through prompts or logs; vulnerability in cloud deployments. | Federated learning, differential privacy, local deployment, encryption, and access controls. | [86,87,88,89,90,91,92] |
| Focus Area | Future Directions and Innovations | References |
|---|---|---|
| Model Improvements | - Integration of multimodal capabilities to process both text and clinical images (e.g., LLaVA-Med, MedCLIP). - Emphasis on domain-specific pretraining using curated medical datasets (e.g., MIMIC-IV, PubMed, UpToDate) to enhance contextual accuracy and clinical relevance. | [114,115,116,117,118,119,120] |
| Human–AI Collaboration | - Reframing LLMs as clinical copilots that support, rather than replace, healthcare professionals. - Development of interactive interfaces to allow clinicians to query, edit, and validate AI outputs in real time, fostering trust and transparency in clinical workflows. | [121,122,123,124,125] |
| System Integration | - Embedding chatbots within EHR platforms for context-aware assistance (e.g., retrieving patient history, generating documentation). - Use in telemedicine and chronic care for documentation, follow-up, and personalized patient engagement. | [126,127,128,129] |
| Privacy-Preserving Methods | - Adoption of federated learning to train models without centralizing sensitive data. - Use of differential privacy to minimize re-identification risks. - Development of on-device LLMs for secure, localized model deployment in hospitals and on personal devices. | [130,131,132,133,134] |
| Policy and Governance | - Establishing technical standards, validation protocols, and reporting requirements for AI in healthcare. - Regulatory bodies (e.g., FDA, EMA, MHRA) are beginning to respond but require LLM-specific guidance. - Need for international governance frameworks. | [135,136,137,138,139,140] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chow, J.C.L.; Li, K. Large Language Models in Medical Chatbots: Opportunities, Challenges, and the Need to Address AI Risks. Information 2025, 16, 549. https://doi.org/10.3390/info16070549
Chow JCL, Li K. Large Language Models in Medical Chatbots: Opportunities, Challenges, and the Need to Address AI Risks. Information. 2025; 16(7):549. https://doi.org/10.3390/info16070549
Chicago/Turabian StyleChow, James C. L., and Kay Li. 2025. "Large Language Models in Medical Chatbots: Opportunities, Challenges, and the Need to Address AI Risks" Information 16, no. 7: 549. https://doi.org/10.3390/info16070549
APA StyleChow, J. C. L., & Li, K. (2025). Large Language Models in Medical Chatbots: Opportunities, Challenges, and the Need to Address AI Risks. Information, 16(7), 549. https://doi.org/10.3390/info16070549