
Biasing Rule-Based Explanations Towards User Preferences


Abstract

1. Introduction
2. Related Works
3. User Preferences
4. Problem Statement
4.1. The CoRIfEE Framework
4.2. CoRIfEE-Coh
4.3. CoRIfEE-Pref
4.4. Terms and Notation
5. Methodology
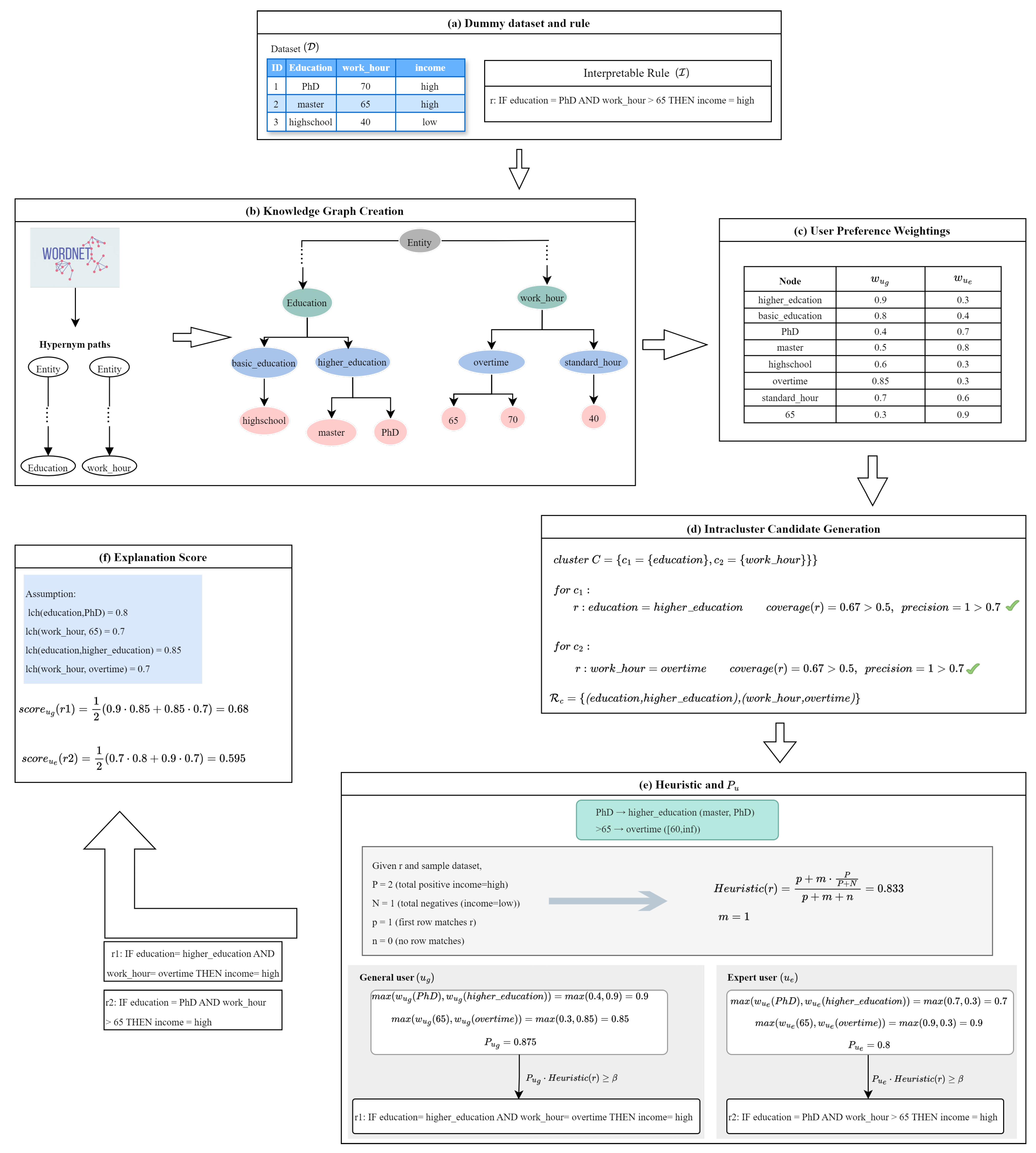
5.1. Defining CoRIfEE-Pref Inputs
- Pool of interpretable models ():A collection of rule-based explanations derived from various interpretable machine learning models, such as random forest or JRIP. The explanations are in an if–then format, making them human-understandable.
- Dataset ():It provides the underlying structured data on which the method operates.
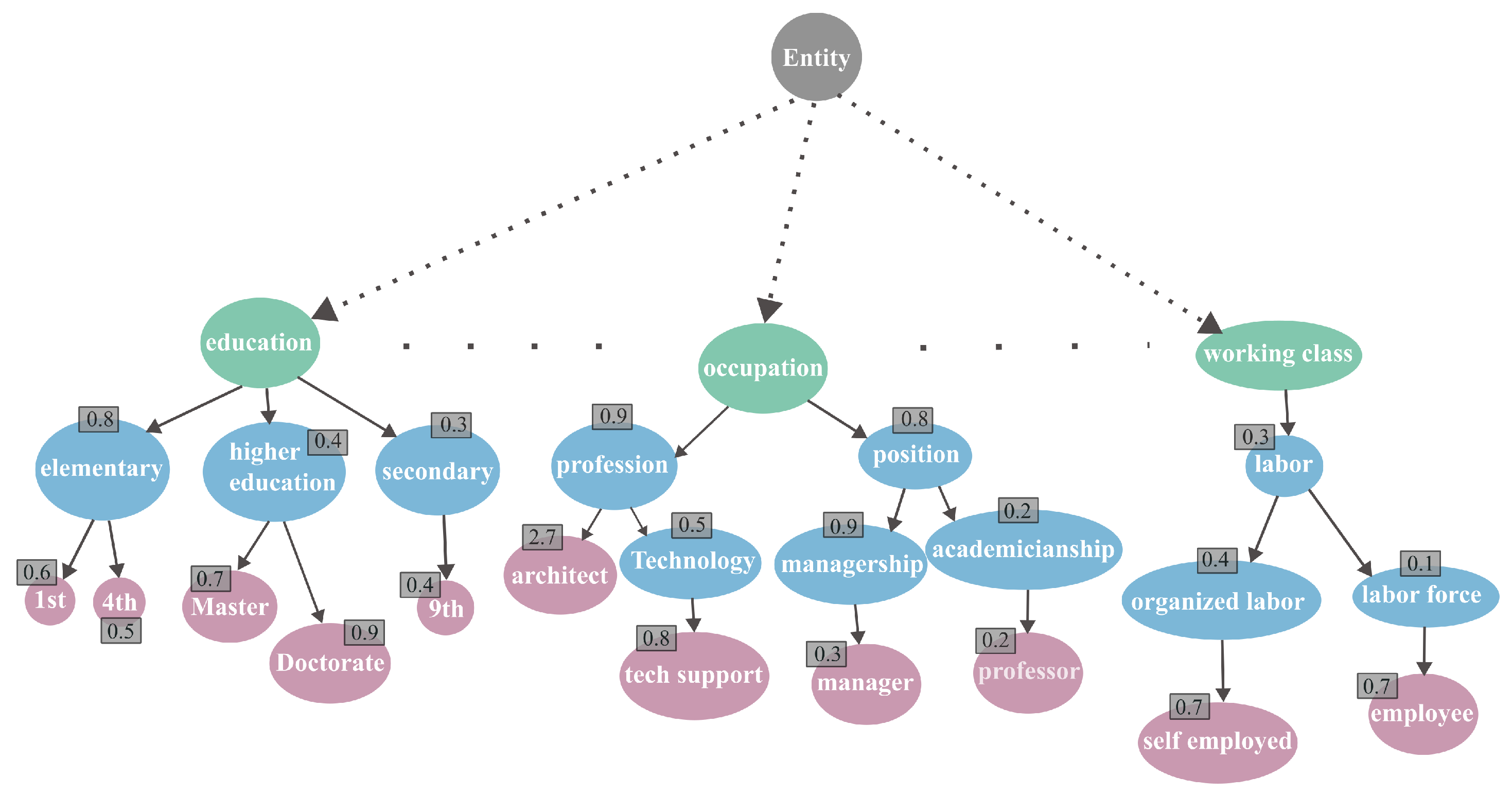
- Knowledge Graph ():A directed label encapsulates the domain’s knowledge.
- User weighting function ():A function defined over the to model users’ preferences and background knowledge. It assigns numerical weight to nodes (concepts) in the that reflects how familiar the concept is to the user. The weights enable the methods to adjust explanations that resonate with user preferences.
5.2. Modeling User Preferences
- General user (), who prioritizes general, abstract concepts.
- Expert user (), who values specific details and precise terminology.
- For the general user (), the selected nodes with the highest weights are “education = higher_education” (0.9) and “work_hour = overtime” (0.85).
- For the expert user , the relevant features with the highest weights are “education = PhD (0.7)” and “work_hour > 65” (0.9).
5.3. User-Customized Explanation Generation
| Algorithm 1 Pseudocode on CoRIfEE-Pref. |
Input: Pool of interpretable models . Input: Knowledge graph Input: Dataset Input: User weighting function . Output: Explanation maximally aligned with user preferences.
|
6. Experimental Evaluation
6.1. Experimental Setup
- Heart Disease consists of medical records related to heart health, used for specifying heart disease.
- Bank Marketing contains information about customer interactions with marketing campaigns, used to predict the success of marketing strategies.
- Water Quality includes measurements of various water quality parameters specifying the cleanliness of water.
- Hepatitis consists of medical records of hepatitis patients, determining whether the patient survives or dies.
- Adult specifies whether a person earns more than 50K per year.
6.2. Quantitative Results
6.3. Qualitative Results
7. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hanif, A.; Beheshti, A.; Benatallah, B.; Zhang, X.; Habiba; Foo, E.; Shabani, N.; Shahabikargar, M. A Comprehensive Survey of Explainable Artificial Intelligence (XAI) Methods: Exploring Transparency and Interpretability. In Proceedings of the Web Information Systems Engineering—WISE 2023; Zhang, F., Wang, H., Barhamgi, M., Chen, L., Zhou, R., Eds.; Springer: Singapore, 2023; pp. 915–925. [Google Scholar]
- Thunki, P.; Reddy, S.R.B.; Raparthi, M.; Maruthi, S.; Babu Dodda, S.; Ravichandran, P. Explainable AI in Data Science—Enhancing Model Interpretability and Transparency. Afr. J. Artif. Intell. Sustain. Dev. 2021, 1, 1–8. [Google Scholar]
- Ribera, M.; Lapedriza, À. Can we do better explanations? A proposal of user-centered explainable AI. In Proceedings of the CEUR Workshop Proceedings, CEUR-WS, Los Angeles, CA, USA, 20 March 2019; Volume 2327. [Google Scholar]
- Doshi-Velez, F.; Kim, B. A Roadmap for a Rigorous Science of Interpretability. arXiv 2017, arXiv:1702.08608. [Google Scholar]
- Ehsan, U.; Tambwekar, P.; Chan, L.; Harrison, B.; Riedl, M.O. Automated rationale generation: A technique for explainable AI and its effects on human perceptions. In Proceedings of the 24th International Conference on Intelligent User Interfaces, New York, NY, USA, 16–20 March 2019; pp. 263–274. [Google Scholar]
- Ehsan, U.; Riedl, M.O. Explainability pitfalls: Beyond dark patterns in explainable AI. Patterns 2024, 5, 100971. [Google Scholar] [CrossRef] [PubMed]
- de Bruijn, H.; Warnier, M.; Janssen, M. The perils and pitfalls of explainable AI: Strategies for explaining algorithmic decision-making. Gov. Inf. Q. 2022, 39, 101666. [Google Scholar] [CrossRef]
- Lai, V.; Zhang, Y.; Chen, C.; Liao, Q.V.; Tan, C. Selective Explanations: Leveraging Human Input to Align Explainable AI. Proc. ACM Hum.-Comput. Interact. 2023, 7, 1–35. [Google Scholar] [CrossRef]
- Xie, Y.; Chen, M.; Kao, D.; Gao, G.; Chen, X.A. CheXplain: Enabling Physicians to Explore and Understand Data-Driven, AI-Enabled Medical Imaging Analysis. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, New York, NY, USA, 25–30 April 2020; pp. 1–13. [Google Scholar]
- Bansal, G.; Wu, T.; Zhou, J.; Fok, R.; Nushi, B.; Kamar, E.; Ribeiro, M.T.; Weld, D. Does the Whole Exceed its Parts? The Effect of AI Explanations on Complementary Team Performance. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, New York, NY, USA, 8–13 May 2021. [Google Scholar]
- Wang, X.; Yin, M. Are Explanations Helpful? A Comparative Study of the Effects of Explanations in AI-Assisted Decision-Making. In Proceedings of the 26th International Conference on Intelligent User Interfaces, New York, NY, USA, 18–21 March 2021; pp. 318–328. [Google Scholar]
- Suffian, M.; Stepin, I.; Alonso-Moral, J.M.; Bogliolo, A. Investigating Human-Centered Perspectives in Explainable Artificial Intelligence. In Proceedings of the CEUR Workshop Proceedings, CEUR-WS, Rome, Italy, 6–9 November 2023; Volume 3518, pp. 47–66. [Google Scholar]
- Ehsan, U.; Wintersberger, P.; Liao, Q.V.; Watkins, E.A.; Manger, C.; Daumé III, H.; Riener, A.; Riedl, M.O. Human-Centered Explainable AI (HCXAI): Beyond Opening the Black-Box of AI. In Proceedings of the Extended Abstracts of the 2022 CHI Conference on Human Factors in Computing Systems, New York, NY, USA, 29 April–5 May 2022. [Google Scholar]
- Ghai, B.; Liao, Q.V.; Zhang, Y.; Bellamy, R.; Mueller, K. Explainable Active Learning (XAL): Toward AI Explanations as Interfaces for Machine Teachers. Proc. ACM Hum.-Comput. Interact. 2021, 4, 1–28. [Google Scholar] [CrossRef]
- Huang, Z.; Yu, H.; Fan, G.; Shao, Z.; Li, M.; Liang, Y. Aligning XAI explanations with software developers’ expectations: A case study with code smell prioritization. Expert Syst. Appl. 2024, 238, 121640. [Google Scholar] [CrossRef]
- Kim, D.; Song, Y.; Kim, S.; Lee, S.; Wu, Y.; Shin, J.; Lee, D. How should the results of artificial intelligence be explained to users?—Research on consumer preferences in user-centered explainable artificial intelligence. Technol. Forecast. Soc. Chang. 2023, 188, 122343. [Google Scholar] [CrossRef]
- Feng, S.; Boyd-Graber, J. Learning to Explain Selectively: A Case Study on Question Answering. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 8372–8382. [Google Scholar]
- Kliegr, T.; Bahník, Š.; Fürnkranz, J. A Review of Possible Effects of Cognitive Biases on Interpretation of Rule-based Machine Learning Models. Artif. Intell. 2021, 295, 103458. [Google Scholar] [CrossRef]
- Fürnkranz, J.; Kliegr, T.; Paulheim, H. On Cognitive Preferences and the Plausibility of Rule-based Models. Mach. Learn. 2020, 109, 853–898. [Google Scholar] [CrossRef]
- Goldstein, D.G.; Gigerenzer, G. The recognition heuristic: How ignorance makes us smart. In Simple Heuristics That Make Us Smart; Gigerenzer, G., Todd, P.M., Group, A.R., Eds.; Oxford University Press: New York, NY, USA, 1999; pp. 37–58. [Google Scholar]
- Goldstein, D.G.; Gigerenzer, G. Models of ecological rationality: The recognition heuristic. Psychol. Rev. 2002, 109, 75. [Google Scholar] [CrossRef] [PubMed]
- Islam, M.R.; Ahmed, M.U.; Barua, S.; Begum, S. A Systematic Review of Explainable Artificial Intelligence in Terms of Different Application Domains and Tasks. Appl. Sci. 2022, 12, 1353. [Google Scholar] [CrossRef]
- Suresh, H.; Gomez, S.R.; Nam, K.K.; Satyanarayan, A. Beyond Expertise and Roles: A Framework to Characterize the Stakeholders of Interpretable Machine Learning and their Needs. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, New York, NY, USA, 8–13 May 2021. [Google Scholar]
- Ehsan, U.; Passi, S.; Liao, Q.V.; Chan, L.; Lee, I.H.; Muller, M.; Riedl, M.O. The Who in XAI: How AI Background Shapes Perceptions of AI Explanations. In Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems, New York, NY, USA, 11–16 May 2024. [Google Scholar]
- The EU Artificial Intelligence Act. Available online: https://www.ey.com/content/dam/ey-unified-site/ey-com/en-gl/services/ai/documents/ey-eu-ai-act-political-agreement-overview-february-2024.pdf (accessed on 2 February 2024).
- Meske, C.; Bunde, E.; Schneider, J.; Gersch, M. Explainable Artificial Intelligence: Objectives, Stakeholders, and Future Research Opportunities. Inf. Syst. Manag. 2022, 39, 53–63. [Google Scholar] [CrossRef]
- Ma, S. Towards Human-centered Design of Explainable Artificial Intelligence (XAI): A Survey of Empirical Studies. arXiv 2024, arXiv:2410.21183. [Google Scholar]
- Naveed, S.; Stevens, G.; Robin-Kern, D. An Overview of the Empirical Evaluation of Explainable AI (XAI): A Comprehensive Guideline for User-Centered Evaluation in XAI. Appl. Sci. 2024, 14, 11288. [Google Scholar] [CrossRef]
- Shin, D. Artificial misinformation. In Exploring Human-Algorithm Interaction Online; Springer: Cham, Switzerland, 2024. [Google Scholar]
- Shin, D. Debiasing AI: Rethinking the Intersection of Innovation and Sustainability; Routledge: London, UK, 2025. [Google Scholar]
- Mishra, S.; Rzeszotarski, J.M. Crowdsourcing and Evaluating Concept-driven Explanations of Machine Learning Models. Proc. ACM Hum.-Comput. Interact. 2021, 5, 1–26. [Google Scholar] [CrossRef]
- Breiman, L. Statistical Modeling: The Two Cultures (with comments and a rejoinder by the author). Stat. Sci. 2001, 16, 199–231. [Google Scholar] [CrossRef]
- Leventi-Peetz, A.; Weber, K. Rashomon Effect and Consistency in Explainable Artificial Intelligence (XAI). In Proceedings of the Future Technologies Conference (FTC); Springer: Cham, Switzerland, 2022; Volume 1, pp. 796–808. [Google Scholar]
- Müller, S.; Toborek, V.; Beckh, K.; Jakobs, M.; Bauckhage, C.; Welke, P. An Empirical Evaluation of the Rashomon Effect in Explainable Machine Learning. In Proceedings of the European Conference on Machine Learning and Knowledge Discovery in Databases (ECML/PKDD): Research Track (Part III), Turin, Italy, 18–22 September 2023; pp. 462–478. [Google Scholar]
- Mahya, P.; Fürnkranz, J. Extraction of Semantically Coherent Rules from Interpretable Models. In Proceedings of the 17th International Conference on Agents and Artificial Intelligence—Volume 1: IAI. INSTICC, SciTePress, Porto, Portugal, 23–25 February 2025; pp. 898–908. [Google Scholar]
- Džeroski, S.; Cestnik, B.; Petrovski, I. Using the m-estimate in Rule Induction. J. Comput. Inf. Technol. 1993, 1, 37–46. [Google Scholar]
- Kelly, M.; Longjohn, R.; Nottingham, K. The UCI Machine Learning Repository. Available online: https://archive.ics.uci.edu (accessed on 22 June 2025).
- Fellbaum, C. WordNet: An Electronic Lexical Database; The MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Fellbaum, C.; Miller, G. Combining Local Context and Wordnet Similarity for Word Sense Identification; MIT Press: Cambridge, MA, USA, 1998; pp. 265–283. [Google Scholar]
- Bona, F.B.D.; Dominici, G.; Miller, T.; Langheinrich, M.; Gjoreski, M. Evaluating Explanations Through LLMs: Beyond Traditional User Studies. arXiv 2024, arXiv:2410.17781. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| (a) High-Level Explanation | (b) Low-Level Explanation |
|---|---|
| If a person consistently prioritizes their physical and mental health, then they are likely to experience improved overall health. | If a person consumes a variety of fruits and vegetables, avoids excessive foods, and drinks plenty of water, then their immune system may strengthen, reducing illnesses like cold and flu. |
| If a person pursues a higher education degree, then he/she is likely to obtain knowledge that contributes to career success. | If a graduate student engages in research, and collaborates in academic papers and projects, he/she is likely to specialized expertise in their field. |
| (a) Medical Expert Prompt | (b) Patient Prompt |
|---|---|
| Imagine you are an experienced cardiologist. | Imagine you are a patient with no formal medical background. |
| On a scale from 0 (not familiar/preferred at all) to 1 (extremely familiar/preferred), rate the given concepts used in diagnosing heart diseases, based on your professional familiarity and practical usefulness. | On a scale from 0 (not familiar/useful at all) to 1 (extremely familiar/useful), rate the given medical concepts in terms of how understandable or meaningful you find them for discussing heart health issues with your doctor. |
| Dataset | User | Explanation | Accuracy | Score |
|---|---|---|---|---|
| Heart Disease | User1 | 0.874 | 0.225 | |
| 0.868 | 0.496 | |||
| 0.846 | 0.230 | |||
| User2 | 0.874 | 0.337 | ||
| 0.868 | 0.397 | |||
| 0.846 | 0.476 | |||
| Bank Marketing | User1 | 0.887 | 0.185 | |
| 0.886 | 0.555 | |||
| 0.884 | 0.404 | |||
| User2 | 0.887 | 0.278 | ||
| 0.886 | 0.517 | |||
| 0.884 | 0.680 | |||
| Water Quality | User1 | 0.633 | 0.270 | |
| 0.629 | 0.525 | |||
| 0.621 | 0.445 | |||
| User2 | 0.633 | 0.279 | ||
| 0.629 | 0.545 | |||
| 0.621 | 0.752 | |||
| Hepatitis | User1 | 0.781 | 0.293 | |
| 0.778 | 0.474 | |||
| 0.761 | 0.460 | |||
| User2 | 0.781 | 0.375 | ||
| 0.778 | 0.538 | |||
| 0.761 | 0.570 | |||
| Adult | User1 | 0.809 | 0.190 | |
| 0.795 | 0.447 | |||
| 0.788 | 0.387 | |||
| User2 | 0.809 | 0.215 | ||
| 0.795 | 0.464 | |||
| 0.788 | 0.602 |
| Dataset | User | Explanation | Mean Score | 95% Confidence Intervals (CI) |
|---|---|---|---|---|
| Heart Disease | 0.233 | [0.2, 0.267] | ||
| User1 | 0.496 | [0.476, 0.516] | ||
| 0.255 | [0.215, 0.295] | |||
| User2 | 0.489 | [0.473, 0.506] | ||
| Bank Marketing | 0.180 | [0.159, 0.200] | ||
| User1 | 0.551 | [0.525, 0.577] | ||
| 0.266 | [0.23, 0.302] | |||
| User2 | 0.643 | [0.614, 0.672] |
| (a) Original Explanation | (b) User1 Explanation |
|---|---|
| class = 1: education = Masters | class = 1: education = higher_education |
| AND occupation = Exec-managerial | AND occupation = managerial |
| AND relationship = Husband | AND relationship = Spouse |
| AND work_time ≥ 59.8 | AND work_time = over_time |
| . | . |
| . | . |
| . | . |
| class = 0: capital_gain < 871.2 | class = 0: capital_gain = low |
| AND race = White | AND race = White |
| AND sex = Female | AND sex = Female |
| AND working_class = Self-emp-inc | AND working_class = labor_force |
| . | . |
| . | . |
| . | . |
| (a) High-Level Explanation | (b) Low-Level Explanation |
|---|---|
| If a person holds a Master’s degree, works as an executive manager, is husband, and works more than 59.8 h/week, (s)he is likely to earn over $50K. | If a person has higher education, holds a management position, has a family, and consistently works overtime, (s)he is likely to earn high income. |
| . | . |
| . | . |
| . | . |
| If a person has capital gain below 871.2, is white and female, and self-employed, (s)he is likely to earn $50K or less. | If a person who is white and female participates in the general workforce, and has low financial gain, (s)he earns low income. |
| . | . |
| . | . |
| . | . |
| (a) Explanation for a Medical Expert | (b)Explanation for a Patient |
|---|---|
| If a patient presents angina, asymptomatic chest pain, ventricular ECG abnormalities, and any measurable ST segment depression, then heart disease is likely. | If you have reported chest discomfort, show signs of irregular heart activity, and test results suggest that your heart may not be getting enough oxygen, you may be at risk of heart disease. |
| . | . |
| . | . |
| . | . |
| If a patient has no history of cardiovascular disease and presents with normal fasting blood glucose, then the heart disease is not likely. | if you have not had any heart problems, and your blood sugar levels are healthy, it is unlikely to have heart disease. |
| . | . |
| . | . |
| . | . |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mahya, P.; Fürnkranz, J. Biasing Rule-Based Explanations Towards User Preferences. Information 2025, 16, 535. https://doi.org/10.3390/info16070535
Mahya P, Fürnkranz J. Biasing Rule-Based Explanations Towards User Preferences. Information. 2025; 16(7):535. https://doi.org/10.3390/info16070535
Chicago/Turabian StyleMahya, Parisa, and Johannes Fürnkranz. 2025. "Biasing Rule-Based Explanations Towards User Preferences" Information 16, no. 7: 535. https://doi.org/10.3390/info16070535
APA StyleMahya, P., & Fürnkranz, J. (2025). Biasing Rule-Based Explanations Towards User Preferences. Information, 16(7), 535. https://doi.org/10.3390/info16070535