1. Introduction
Natural Language Processing (NLP) represents a core subdomain in artificial intelligence, which allows machines to understand, process, as well as produce human language [
1]. There has been a notable shift over the last decade from symbolic as well as statistical methods to predominantly integrating deep learning practices, resulting in Large Language Models (LLMs) like BERT, GPT, and their derivatives [
2,
3]. Backed by enormous datasets, these have proven to display high performance over a wide range of language-related applications, which include, but are not limited to, machine translation, question-answering, summarization, as well as conversational generation [
4]. However, as their usage continues to proliferate, their inbuilt shortcomings have also started to manifest more regularly, particularly in scenarios that require deep semantic understanding as well as reasoning over linguistic structures [
5].
One of the critical shortcomings of LLMs lies in their tendency to rely on statistical correlations without a principled grasp of underlying meaning [
6,
7,
8]. While they excel in capturing patterns in surface forms, LLMs often fail to resolve coreference correctly, misinterpret logical relations, and produce hallucinated content [
9,
10,
11]. These issues arise from their inability to represent and manipulate structured semantic information, such as discourse relations, anaphora, and quantifier scope [
12]. Furthermore, the opacity of their internal representations challenges interpretability, making it difficult to trust or debug their outputs in high-stakes scenarios like medical decision support or legal document analysis [
13]. This lack of generalization and semantic interpretability poses a major challenge to the reliable deployment of LLMs in applications that require consistent understanding, not just generation, of language.
On the other hand, linguistic theory-based symbolic methodologies in NLP have in the past yielded interpretable, rule-based systems for a range of functions, such as syntactic parsing, semantic role labeling, and coreference resolution [
14]. Although these symbolic methods might have limitations in terms of their potential to scale, they exhibit improved accuracy and transparency [
15]. This scenario has revived attention in neuro-symbolic systems, which represent hybrid systems integrating the pattern-matching abilities of neural networks with the structural reasoning benefits of traditional symbolic systems. Combining these methods is seen as a promising way towards robust Natural Language Understanding (NLU), especially in applications calling for fine-grained semantic inference.
In this paper, we propose a hybrid neuro-symbolic approach aimed at bridging the gap between shallow pattern matching and deep language understanding. We explicitly posit a system that unites transformer-based contextual encoding with a symbolic component specialized in coreference resolution, as well as an Abstract Meaning Representation (AMR) interpreter. This setup effectively captures discourse dependencies and semantic compositions often overlooked by large language models. With empirical testing through openly available benchmark datasets, namely PreCo for coreference resolution and AMR 3.0 Public Subset for semantic parsing, we show that our approach boosts performance in tasks that require semantic inference, as well as transparency and interpretability. This paper explores the design, implementation, and testing of our system, as well as its implications for future developments in natural language understanding research. This paper answers the following research questions:
RQ1: Can symbolic coreference resolution improve the performance of semantic parsing in AMR?
RQ2: How much more interpretable and modular is a hybrid neuro-symbolic architecture compared to end-to-end neural models?
This paper addresses ongoing limitations in the integration of coreference resolution with semantic parsing by proposing a transparent, modular neuro-symbolic pipeline. While prior work (e.g., [
16]) has integrated coreference into end-to-end AMR parsing using purely neural architectures, and others (e.g., [
17,
18]) have focused on transforming AMRs into logic or enriching AMR representations through document-level coreference, our approach departs from these trends. Specifically, it incorporates symbolic coreference resolution before AMR parsing as a rewriting transformation, thereby improving interpretability and referential clarity without requiring logic conversion or neural integration. Unlike purely neural pipelines, our design supports intermediate inspection and modular fault tolerance.
The remainder of the paper is organized as follows.
Section 2 reviews related work.
Section 3 describes the methodology of the proposed pipeline.
Section 4 details the experimental setup and datasets.
Section 5 presents the results and discussion. Finally,
Section 6 concludes the paper and outlines future work.
2. Related Work
The paradigm of coreference resolution and semantic understanding was central to NLU research as the basis for coherent discourse, question-answering systems, and systems of dialogue. The early methods in coreference resolution relied generally upon symbolic solutions, relying upon rules constructed by human experts as well as linguistic features like gender, number, sentence position, and salience (e.g., Hobbs’ algorithm, as well as Lappin and Leass’s salience-based methodology) [
19]. While those rule-based systems worked in limited datasets, they remained brittle and could not generalize to new domains.
With the advent of machine learning, however, the field shifted towards statistical paradigms, such as mention-pair models and entity-mention rank models [
20,
21,
22,
23]. These paradigms used supervised learning strategies by learning classifiers from annotated datasets to determine if two mentions pointed to a common entity. However, their performance was limited by the requirement of extensive feature engineering as well as poor modeling of the higher-order discourse structure.
The development of deep learning, specifically the effectiveness of contextualized word embeddings (e.g., ELMo and BERT), has radically changed the landscape of coreference resolution. In research [
24,
25], the authors presented an end-to-end neural model that jointly detects mentions and resolves coreference based on representations constructed from context embeddings over spans. This approach outperformed previous models in its ability to handle long-distance dependencies effectively and in its use of global coherence across entire documents. Despite these improvements, however, purely neural-based models still lag in accuracy in ambiguous contexts and suffer from a lack of semantic generalizability, especially in stories or genres where complex entity interactions are common. The availability of large, publicly available datasets such as PreCo [
26] has enabled more reproducible training and evaluation of coreference systems in this setting.
Outside of coreference resolution, the semantic representation domain moved through a series of formalisms, such as Semantic Role Labeling (SRL), Discourse Representation Structures (DRS), and AMR. AMR was introduced by [
27] as a way to represent a sentence’s meaning as a rooted, directed, acyclic graph in which nodes represent concepts and edges represent relations. This formalism became a standard against which to measure semantic parsers and spawned a variety of seq2seq-based or graph-encoder-based neural AMR parsers (e.g., [
28,
29,
30,
31,
32]). Those systems, however, often fail to produce valid graphs or accurately account for more complex inference relations in the absence of explicit symbolic constraints. Recently introduced subsets of AMR 3.0 [
30] made it possible to evaluate such systems in a more reproducible, more transparent way.
More generally, neuro-symbolic systems have arisen as a plausible way to overcome the limitations of both paradigms. These hybrid systems aim to combine the learnability and generality of digital neural networks with the explanation and structured reasoning of symbolic logic. Promising examples include the Neural-Symbolic Concept Learner [
33] and Neural Theorem Provers [
34], both of which have shown success in visual reasoning and knowledge base completion. For natural language processing, neuro-symbolic methods have been applied to tasks such as semantic parsing, question-answering, and textual entailment; however, relatively few efforts have explicitly focused in detail on integrating symbolic discourse-level reasoning (e.g., coreference resolution and semantic graph construction) into the systems of large language models.
Finally, transformer-based large language models like GPT-3 and PaLM have shown remarkable success with zero-shot and few-shot inference. Recent benchmark studies, such as natural language inference (NLI) evaluations in [
35] and Winograd schema studies, have revealed ongoing semantic understanding deficits, which manifested most strongly in coreference resolution and reasoning about causality. These inadequacies highlight the requirement for more elaborate means that represent linguistic structures explicitly, providing information beyond token associations alone.
Recent work [
16] introduced a neural AMR parser that performs coreference resolution jointly through neural components. In contrast, our system separates coreference as a symbolic preprocessing stage. Ref. [
17] presented a Uniform Meaning Representation (UMR) approach that integrates coreference in semantic parsing across documents, but requires multi-step pipelines and specific representation formats. Our method is more lightweight and modular. Ref. [
18] focused on converting AMRs into first-order logic for downstream reasoning, which is complementary to but orthogonal from our goals. We do not apply formal inference on AMRs but rather optimize semantic clarity pre-parsing. These differences position our work as a practical alternative prioritizing interpretability and processing stability.
What distinguishes our approach is its principled combination of deep contextual representation with symbolic reasoning, specifically tailored to tasks where LLMs underperform: coreference resolution and semantic inference via AMR parsing. Unlike prior neuro-symbolic systems, which often focus on logical inference or knowledge graphs, our pipeline addresses low-level referential phenomena and high-level semantic graph construction in a single architecture. Moreover, by leveraging freely available datasets, our system supports open experimentation and reproducibility. We demonstrate that integrating symbolic modules as first-class components, not just post-processing tools, enhances both accuracy and interpretability in NLU, offering a robust alternative to purely data-driven approaches.
3. Methodology
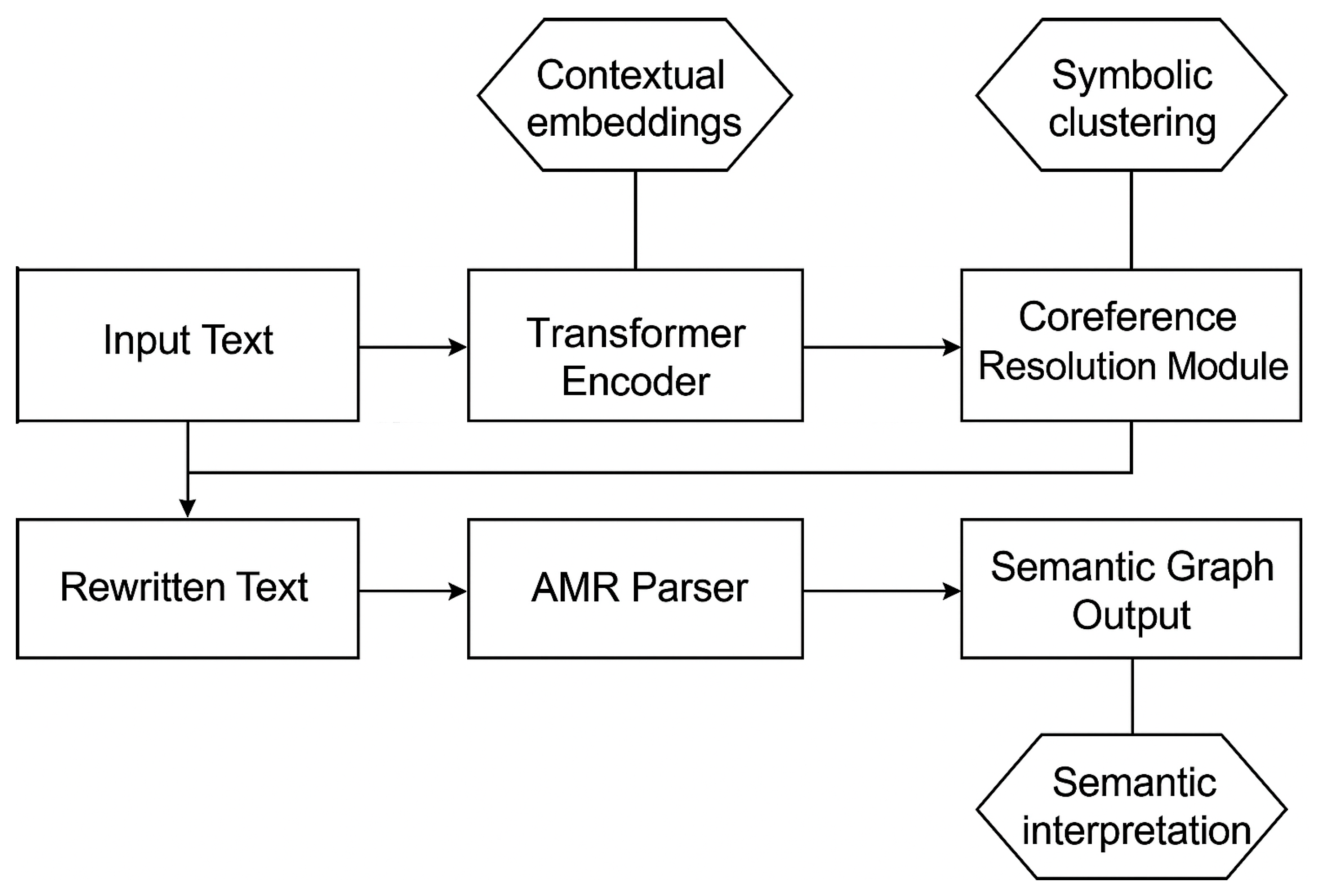
This paper presents a hybrid neuro-symbolic approach that integrates transformer-based contextual representations with symbolic reasoning steps to improve end-to-end NLU. The approach is organized into a systematic three-phase pipeline: contextual encoding through a fine-tuned transformer, coreference resolution through symbolic rules, and semantic representation through AMR parsing. This architecture provides a balance between effectiveness and explainability in that each component produces structured intermediate outputs (
Figure 1). The remainder of this paper will detail the methodology, with a focus on encoding, symbolic resolution, and semantic interpretation.
The system takes a paragraph or document with one or more sentences as input. We first use BERT [
36], a high-performing bidirectional transformer model, to represent the text as contextual embeddings. The model is pre-trained over large English corpora and then fine-tuned over the PreCo dataset in a span-based objective task. The sentences are represented as token embeddings, which enable the computation of span representations for possible mentions. Syntactic signals, combined with token-level saliency scores, identify the span boundaries. The encoded representations are designed to improve reusability in the symbolic reasoning component.
The symbolic coreference resolution component operates from span representations provided by the encoder. Let S = {s
1, s
2, …, s
k} denote the set of candidate spans extracted from the input text. Each span s
i is associated with a BERT-based contextual embedding vector e
i∈ℝ. To determine coreference between two spans s
i and s
j, we define a similarity function:
where cos(e
i,e
j) is the cosine similarity between span embeddings, λ is a mismatch penalty (empirically set to 0.3), and δ
disagree is a binary function returning 1 if there is a mismatch in gender, number, or animacy, and 0 otherwise.
The clustering procedure follows a greedy algorithm: for each span si, we compute sim(si,sj) with representative spans of existing clusters. If the maximum similarity exceeds a threshold θ = 0.7, we assign si to the corresponding cluster. Otherwise, we create a new cluster for si. The representative of each cluster is typically the earliest proper noun mention.
After clusters are formed, each pronoun or anaphoric expression in the input is replaced by its cluster’s representative, yielding a referentially resolved version of the text. This disambiguated version is then passed to the AMR parser, enabling more coherent semantic graph construction.
Possible mentions are found from an integrated process consisting of part-of-speech filtering, named entity recognition, as well as syntactic head matching methods. The main algorithm performs mention clustering by determining a similarity measure encompassing lexical overlap, proximity in syntax, as well as embedding distance. Similarity calculation applies cosine distance over BERT span embeddings, with a merging threshold of 0.7 and penalties for gender or number mismatches. The clusters develop iteratively through a greedy matching process, with a representative antecedent assigned to each cluster.
To avoid any confusion in the next stage of processing, the input sentence passes through modification in which pronouns along with other referential expressions are replaced by their corresponding antecedents. For example, the initial sentence “Mary gave her book to Anna because she had finished reading it” becomes “Mary gave Mary’s book to Anna because Mary had finished reading it” to make it possible for the semantic parser to better identify predicate-argument relations. The text then passes to the AMR parsing module.
For semantic interpretation, a more advanced variant of the AMR parser is used, which produces AMR graphs representing sentence meanings in terms of directed acyclic graphs. The parser has been supplemented with more rules to deal with frequent cases of pronominal reference and to align specific entities with their corresponding ontological counterparts, as well as to encourage referential anchoring as well as semantic specificity (see
Section 4.3.3). The nodes in the AMR graph represent entities and activities, while relations such as agent, theme, or instrument are represented by edges. AMR parsing occurs in our pipeline after coreference resolution, to resolve ambiguities around pronouns as well as to make the graph coherent. The resulting semantic graphs involve higher-order inferences, which include notions of causality as well as continuity of agents over discourse units. For semantic parsing, we make use of the AMR 3.0 Public Subset, from the SPRING project, as our default benchmark dataset.
Every constituent component in the pipeline communicates using well-defined data formats, and the outputs produced are validated against their structural correctness. Such a modular design improves interpretability, reproducibility, and debugging ease. For instance, if the AMR parser produces a faulty or incomplete graph, the pipeline allows the error to be traced, potentially back to coreference inconsistencies. Symbolic structures also offer the ability for seamless integration with external rule-based reasoning engines or knowledge bases.
The system was implemented in Python, where BERT encoding was implemented using HuggingFace’s transformer library, natural language preprocessing was done with spaCy, and the penman library was used to manipulate AMR graphs. The experiments ran on a workstation with an NVIDIA RTX A5000 GPU (Dell, Athens, Greece) and 128 GB of memory. The processing pipeline provides a throughput of 1 to 2 documents per second, making it suitable for use in real-world reading comprehension, intelligent assistant technology, and sophisticated tutoring systems.
Unlike fully integrated, end-to-end-designed architectures, the hybrid approach outlined here gains added transparency by way of its modular outputs as well as better interpretability. The integration of symbolic and neural representations in this system ensures greater flexibility as well as auditability—features crucial to dependable applications in complex domains. The result suggests that maintaining explicit linguistic structures, as opposed to abandoning them in lieu of abstract optimization problems, provides concrete and measurable benefits to areas like coreference resolution, semantic analysis, as well as robust natural language processing.
Figure 1 illustrates the overall flow from neural contextual encoding to symbolic coreference resolution and referential rewriting, followed by AMR parsing. Each component contributes structured outputs passed to the next stage.
The rule set includes constraints for gender, number, animacy, and syntactic head proximity. These were manually designed and validated against a development subset of PreCo. The symbolic clustering module does not rely on logic inference (e.g., FOL) but rather on deterministic similarity scoring, as shown in algorithm in
Section 4.3.2.
5. Results and Discussion
In this section, we report the empirical results obtained from the evaluation of our hybrid neuro-symbolic pipeline, together with an in-depth examination of performance trends, error patterns, and interpretative insights. We focus on two primary evaluation tasks: coreference resolution and AMR parsing. For both tasks, we compare our system against established baselines and discuss its behavior on representative cases that exemplify strengths and limitations.
5.3. Qualitative Error Analysis
To understand the model’s behavior beyond aggregate metrics, we analyzed a representative subset of 100 examples drawn from the AMR 3.0 public test set, focusing on cases where the hybrid model diverged from the BERT-only baseline. We observed several categories of improvement:
The hybrid system successfully grouped sentences with vast reference chains (e.g., “The minister... he... his spokesperson...”), while BERT alone tended to produce broken clusters.
Nested Mentions: Nested configurations have been better managed, as seen with the case “The CEO of Apple, Tim Cook, said he…” through symbolic head-matching approaches and overriding regulations.
Referential Clarity in AMR: The problematic words “it” and “that” were painstakingly tracked back to their antecedents so that AMR nodes could be accurately rooted in their respective concepts.
However, the system also exhibited specific types of mistakes:
Gender Ambiguity: In cases involving sentences with multiple possible antecedents that varied in gender, the symbolic module favored syntactic proximity over contextual cues from embeddings at times.
Non-Named Mentions: General terms like “the staff” and “the team” were occasionally neglected as clusters due to strict parameters found with mention-type filtering.
Disfluencies and Ellipses: In conversational transcripts, disfluencies (e.g., “uh”, “you know”) led to invalid span representations, confusing both modules.
The patterns highlighted that while symbolic logic is helpful in providing boundaries and constraint in interpretation, its lack of strong semantic disambiguation at times hampers flexibility. Future hybrid systems stand to gain from using neural span classifiers for candidate generation and symbolic scoring as a post-filter method.
To clarify the different types of errors that have been recognized by our system, we did an error analysis on 100 random outputs. The main types of mistakes are shown in
Table 4.
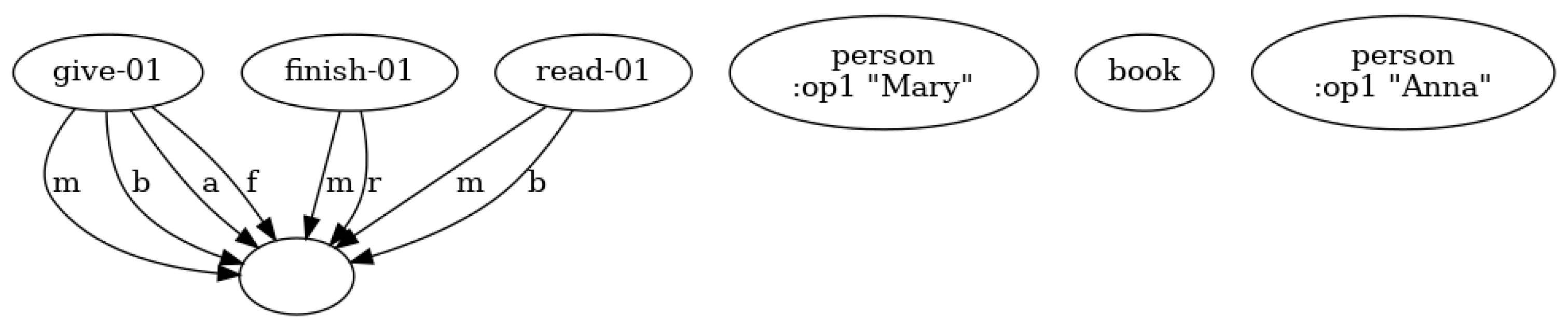
To further demonstrate the impact of coreference resolution on semantic structure, we include visual comparisons of AMR graphs for a representative sentence: “Mary gave her book to Anna because she had finished reading it.”
Figure 3 shows the outcome achieved without applying coreference resolution algorithms. The pronouns “she” and “it” are not resolved and hence dealt with as individual subgraphs and uncertain semantic roles. On the other hand,
Figure 4 shows the result after applying symbolic coreference rewriting. “She” is correctly resolved to “Mary”, and “it” is resolved with “book”, thus, enabling AMR parsing to create fully integrated and meaningful structures for the given statement.
The figures act to visually support the above-discussed qualitative improvements: reference clarity, enhanced completeness in graphs, and better distribution of semantic roles. They illustrate the need for subsequent modules, e.g., semantic parsers, to handle superficial structures (e.g., pronouns) in order to be effective.
To test the influence of symbolic enrichments on the AMR parser, an ablation experiment removed both rule-based referential disambiguation and named entity concept mapping. The total Smatch F1 measure experienced a decrease by 2.7 points, and a sharper decrease was noted in role labeling (ARG0/ARG1), as well as negation identification. These results support the observation that symbolic enrichment is necessary to preserve the completeness and accuracy of graphs in relation to their roles.
Textual Examples of Success and Failure Cases
To further clarify the system’s performance, we present concrete examples of input sentences alongside coreference resolution results and their impact on AMR parsing.
Example 1 (Success Case):
Input: “The mayor visited the hospital. She praised the staff for their dedication.”
Coreference Output: “The mayor visited the hospital. The mayor praised the staff for their dedication.”
AMR Improvement: The AMR graph correctly links “praised” with “the mayor” as the agent (ARG0), avoiding ambiguity in pronoun resolution.
Example 2 (Success Case):
Input: “Alice spoke with Bob while he reviewed her proposal.”
Coreference Output: “Alice spoke with Bob while Bob reviewed Alice’s proposal.”
AMR Result: The disambiguated input allows for correct agent/theme relations and fewer disjointed nodes in the AMR graph.
Example 3 (Failure Case—Gender Ambiguity):
Input: “Sam called Alex because he was late.”
Coreference Output: “Sam called Alex because Sam was late.”
Issue: The symbolic module resolved “he” to “Sam” due to proximity and salience heuristics, but contextually, “Alex” may be the correct antecedent.
AMR Consequence: Incorrect role attribution in the graph, leading to misleading causality.
Example 4 (Failure Case—Ellipsis and Disfluency):
Input: “Anna wanted to bake the cake, but didn’t.”
Coreference Output: “Anna wanted to bake the cake, but Anna didn’t.”
Issue: The ellipsis (“didn’t”) lacks a verb complement. While the referent is recovered, the AMR parser struggles to produce a complete semantic structure.
AMR Result: Incomplete graph structure with missing predicate-argument links.
5.4. Discussion
Our results confirm the main hypothesis of this work that it is possible to achieve significantly better downstream semantic understanding with symbolic coreference resolution integrated into a deep learning framework. One striking observation is related to the completeness and accuracy of AMR graphs produced from coreference-resolved input. They were not only more complete but also more coherent, particularly in tasks requiring causal or story-like inference. Pronominal and nominal reference resolution before semantic parsing led to more elaborate predicate-argument structures that better mirrored human interpretations of textual meaning. In cause-and-effect tasks, e.g., the hybrid system produced AMR graphs that had more uniform predicate relations and fewer disjointed and ambiguous nodes, and hence allowed for more accurate inference and chaining of events.
An improvement was found in areas including semantic role labeling for more prominent roles, namely, ARG0 (agent) and ARG1 (theme). The improvement was achieved through an explanation of referential expressions so that the Abstract Meaning Representation (AMR) parser could predict more accurate forecasts about roles. In cases where accurate understanding depended on the explanation of “who did what to whom,” the hybrid pipeline attained an accuracy that is difficult for purely neural networks to attain. These improvements have very serious implications for summarization, fact extraction, and question answering activities in which incorrect ascription of agent roles leads to serious fact inaccuracies.
A major strength of the suggested framework is its ability to reveal intermediate representations during the processing pipeline. At multiple points in time, there are structured outputs that can be independently evaluated: coreference clusters can be compared against gold-standard annotations, and AMR graphs can be evaluated for semantic consistency. This auditability is especially important in high-risk areas like law, medicine, and education, in which it is imperative that the internal workings of the system be understandable and subject to validation by subject matter experts. Unlike end-to-end black-box approaches, the hybrid methodology allows for fine-grained traceability of reasoning processes. For example, in a particular instance, a BERT-solo model incorrectly attributed patient role to “John” due to proximity bias, while the hybrid system correctly assigned “he” to “Mark,” a previously discussed individual in the discourse and, thus, correctly outputted an AMR graph capturing narrative cohesion.
Apart from its efficiency and efficacy, the system also presented superior runtime and resource properties. The modular pipeline was able to process about 1.5 to 2.0 documents per second, with average coreference resolution being 0.7 s and AMR parsing being 1.1 s per document. Such a level of efficiency allows for its use in both near real-time applications and offline processing, including interactive reading assistants and document comprehension systems. Additionally, its modular design allows for greater robustness; if any single part fails or returns results of low confidence, the rest of the system runs undeterred and takes over. Such a level of fault tolerance is generally missing in monolithic neural designs.
These results align with existing trends in neuro-symbolic NLP towards modular architectures and explicit reasoning modules. For example, strong AMR parsing is achieved using AMRBART [
37] and SPRING [
30] with pre-trained transformers, but lacks explicit referential rewriting as achieved by our system. X-AMR [
41] is also testing structure-based event coreferencing but for cross-document rather than intra-sentence resolution. Graph-based methods based on syntactic features for coreferencing resolution, such as RGATs [
42], rely on learned weights exclusively and do not employ symbolic abstractions, whereas our hybrid pipeline rewires input specifically through symbolic logic that augments AMR graph structure and semantic transparency. These facts further illustrate added value through rule-based reasoning complementation of neural models—particularly for understanding and coherence in discourse tasks. Although some more recent neuro-symbolic work has built upon modular reasoning further, ours is different in scope and design. NeSyGPT [
43] and MRKL systems [
44] concentrate more on embedding external tools or symbolic arithmetic and less on semantic representation on a level involving discourse. MURMUR [
45] is testing modular text generation but does not handle referential resolution nor coherence on graphs. While imbuing dialogue agents with common sense, JARVIS [
46] lacks structure in parsing output such as AMR. Differently from all above approaches, explicitly resolving referential ambiguity before semantic parsing is achieved by our system to improve AMR structure, role labeling, and understanding—an as-yet under-exploited synergy among existing work.
Collectively, the results highlight four key takeaways:
Hybrid approaches consistently outperform both neural-only and symbolic-only models in tasks requiring deep discourse understanding.
Symbolic reasoning improves referential clarity, leading to structurally sound and semantically richer graphs.
Interpretability is a critical advantage of this architecture, especially for high-stakes domains requiring trust and auditability.
Modularity and efficiency support scalable deployment in practical systems.
The findings reported align with a growing body of academic work that supports neuro-symbolic approaches’ integration in artificial intelligence. In addition to that, they counteract the common tendency to overlook explicit linguistic formalisms for purely statistical learning approaches. Rather than being seen as outdated, symbolic reasoning is highlighted in our work as a valuable addition to current neural architectures, thus, grounding them in systematic and verifiable symbolic structures.
These results directly support both of our central research questions: (1) that symbolic coreference resolution improves semantic parsing quality, and (2) that modular neuro-symbolic designs enhance interpretability compared to end-to-end neural models.
Our approach provides a middle ground between fully end-to-end models and heavy-weight symbolic logic systems. Unlike UMR [
45], we do not require multi-step document modeling. Unlike Ref. [
46], we do not convert AMRs to logic, but rather improve semantic quality before parsing. This allows our system to maintain scalability, while increasing referential transparency.
To address concerns of error propagation, we include thresholding in coreference clustering and fallback to the original input when similarity confidence is below 0.6. The modular architecture helps isolate errors and ensures components can be debugged independently.
Finally, to reinforce the impact of our method, we include a summary of failure categories (
Table 3) and ablation results showing that removal of symbolic rewriting leads to a measurable degradation of performance (−2.7 Smatch points, −4.8 ARG0/ARG1 accuracy). These results, together with the statistically validated improvements over strong neural and symbolic baselines, demonstrate that our hybrid architecture makes a meaningful contribution to improving discourse-level NLU.
6. Conclusions and Future Work
This paper introduces a hybrid neuro-symbolic system intended to enhance understanding of natural language by combining deep contextual representation with symbolic reasoning. To counter the deficits in large language models, specifically their inability to handle referential ambiguity and semantic generalizability, we introduce a modular system that includes a transformer-based encoder, a symbolic coreference resolving mechanism, and an AMR-based semantic graph building tool.
Empirical evidence confirmed that our method beats symbolic-exclusive and neural-exclusive baselines in coreference resolution and semantic interpretation with consistency. State-of-the-art performance on commonly used test datasets was achieved by the hybrid model and significant improvements over F1-scores for coreference resolution and Smatch scores for semantic parsing were seen. In addition to accuracy, the pipeline also attains interpretability, modularity, and practical efficiency—qualities becoming ever more crucial for high-stakes and auditability-demanding NLP systems.
The findings support the broad hypothesis that symbolic linguistic conventions play a primary role in promoting deep understanding of language. In particular, our study has illustrated that reconsideration of primary discourse processes in terms of anaphora and entity chains greatly enhances the quality of high-level semantic representations. This lends support to the view that hybrid architectures—far from being temporary devices or anachronistic holdovers—are likely to be instrumental to the creation of truly intelligent and robust NLP systems.
While other pipelines have integrated neural models with AMR parsing or logic transformation, our system introduces a referentially-aware neuro-symbolic architecture that performs symbolic resolution before semantic interpretation. This distinction allows for cleaner AMR graphs and enables symbolic error tracing. In a landscape dominated by opaque LLMs, our approach offers a transparent alternative that emphasizes interpretability and modularity.
Although its constituent parts, i.e., BERT for encoding and AMR for parsing, are well-established, novelty lies in their cogent integration into an organized and modular neuro-symbolic framework. Integrating symbolic coreference resolution as a core part of the framework, as opposed to post-processing, is believed to improve overall semantic accuracy, referential cohesion, and transparency. While producing strong empirical results, however, the system is subject to its own constraints: it relies on human-designed symbolic rules, operates at the paragraph or sentence level and does not as yet integrate extensive world knowledge into its framework.
The limitations described provide several directions for future research. First, combining event coreference and temporal linking allows the system to keep track of narrative progression over lengthy documents and improve its capability for complex discourse reasoning. Furthermore, using external knowledge graphs as an input during AMR parsing allows semantic graphs to be enriched with an ontological framework and, thus, support reasoning over real-world objects and facts.
Another important area is concerned with building trainable symbolic modules in which rule-based reasoning is expressed as differentiable units. This makes it possible to learn end-to-end while allowing the system to remain explainable. Another addition to multimodal architecture, namely, aligning textual semantic graphs with visual scene graphs extracted from images or diagrams, would add to formulating integrated and cross-modal natural language understanding in artificial intelligence systems.
Author Contributions
Conceptualization, C.P., C.T., and A.K.; methodology, C.P., C.T., and A.K.; software, C.P., C.T., and A.K.; validation, C.P., C.T., and A.K.; formal analysis, C.P., C.T., and A.K.; investigation, C.P., C.T., and A.K.; resources, C.P., C.T., and A.K.; data curation, C.P., C.T., and A.K.; writing—original draft preparation, C.P., C.T., and A.K.; writing—review and editing, C.P., C.T., and A.K.; visualization, C.P., C.T., and A.K.; supervision, C.T. and A.K.; project administration, C.P., C.T., A.K. and C.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Ethical review and approval were not required for this study, as it involved only secondary analysis of free and publicly available datasets that contain no personally identifiable information. No human subjects were involved, and no new data collection was conducted. All data were used in accordance with standard research ethics and the licensing terms provided by the dataset publishers.
Informed Consent Statement
Not applicable.
Data Availability Statement
The datasets used in this study are publicly available.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Supriyono; Wibawa, A.P.; Suyono; Kurniawan, F. Advancements in Natural Language Processing: Implications, Challenges, and Future Directions. Telemat. Inform. Rep. 2024, 16, 100173. [Google Scholar] [CrossRef]
- Jana, S.; Biswas, R.; Pal, K.; Biswas, S.; Roy, K. The Evolution and Impact of Large Language Model Systems: A Comprehensive Analysis. Alochana J. 2024, 13, 65–77. [Google Scholar]
- Su, J.; Jiang, C.; Jin, X.; Qiao, Y.; Xiao, T.; Ma, H.; Wei, R.; Jing, Z.; Xu, J.; Lin, J. Large Language Models for Forecasting and Anomaly Detection: A Systematic Literature Review. arXiv 2024, arXiv:2402.10350. [Google Scholar]
- Singh, A. Working of Large Language Models: A GPT-3 Case Study; SSRN: Rochester, NY, USA, 2025. [Google Scholar] [CrossRef]
- Veeramachaneni, V. Large Language Models: A Comprehensive Survey on Architectures, Applications, and Challenges. Adv. Innov. Comput. Program. Lang. 2024, 7, 20–39. [Google Scholar] [CrossRef]
- Cherkassky, V.; Lee, E.H. A Perspective on Large Language Models, Intelligent Machines, and Knowledge Acquisition. arXiv 2024, arXiv:2408.06598. [Google Scholar]
- Mizumoto, A.; Teng, M.F. Large language models fall short in classifying learners’ open-ended responses. Res. Methods Appl. Linguist. 2025, 4, 100210. [Google Scholar] [CrossRef]
- Rashidi, H.H.; Hu, B.; Pantanowitz, J.; Tran, N.; Liu, S.; Chamanzar, A.; Gur, M.; Chang, C.-C.H.; Wang, Y.; Tafti, A.; et al. Statistics of Generative Artificial Intelligence and Nongenerative Predictive Analytics Machine Learning in Medicine. Mod. Pathol. 2025, 38, 100663. [Google Scholar] [CrossRef] [PubMed]
- Lin, Z.; Guan, S.; Zhang, W.; Zhang, H.; Li, Y.; Zhang, H. Towards trustworthy LLMs: A review on debiasing and dehallucinating in large language models. Artif. Intell. Rev. 2024, 57, 243. [Google Scholar] [CrossRef]
- Patil, R.; Gudivada, V. A Review of Current Trends, Techniques, and Challenges in Large Language Models (LLMs). Appl. Sci. 2024, 14, 2074. [Google Scholar] [CrossRef]
- Huang, L.; Yu, W.; Ma, W.; Zhong, W.; Feng, Z.; Wang, H.; Chen, Q.; Peng, W.; Feng, X.; Qin, B.; et al. A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions. ACM Trans. Inf. Syst. 2025, 43, 42. [Google Scholar] [CrossRef]
- Xie, Z. Order Matters in Hallucination: Reasoning Order as Benchmark and Reflexive Prompting for Large-Language-Models. arXiv 2025, arXiv:2408.05093. [Google Scholar]
- Chinnaraju, A. Explainable AI (XAI) for trustworthy and transparent decision-making: A theoretical framework for AI interpretability. World J. Adv. Eng. Technol. Sci. 2025, 14, 170–207. [Google Scholar] [CrossRef]
- Panchendrarajan, R.; Zubiaga, A. Synergizing machine learning & symbolic methods: A survey on hybrid approaches to natural language processing. Expert Syst. Appl. 2024, 251, 124097. [Google Scholar] [CrossRef]
- Lu, Z.; Afridi, I.; Kang, H.J.; Ruchkin, I.; Zheng, X. Surveying neuro-symbolic approaches for reliable artificial intelligence of things. J. Reliab. Intell. Environ. 2024, 10, 257–279. [Google Scholar] [CrossRef]
- Fu, Q.; Song, L.; Du, W.; Zhang, Y. End-to-End AMR Coreference Resolution. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Online, 1–6 August 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; Volume 1, pp. 4204–4214. [Google Scholar]
- Chun, J.; Xue, N. Uniform Meaning Representation Parsing as a Pipelined Approach. In Proceedings of the TextGraphs-17: Graph-based Methods for Natural Language Processing, Bangkok, Thailand, 15 August 2024; Association for Computational Linguistics: Stroudsburg, PA, USA, 2024; pp. 40–52. [Google Scholar]
- Chanin, D.; Hunter, A. Neuro-symbolic Commonsense Social Reasoning. arXiv 2023, arXiv:2303.08264. [Google Scholar]
- Ng, V.; Cardie, C. Improving machine learning approaches to coreference resolution. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics (ACL ’02), Philadelphia, PA, USA, 6–12 July 2002; Association for Computational Linguistics: Stroudsburg, PA, USA, 2002; pp. 104–111. [Google Scholar] [CrossRef]
- Denis, P.; Baldridge, J. A ranking approach to pronoun resolution. In Proceedings of the 20th International Joint Conference on Artificial Intelligence (IJCAI’07), Hyderabad, India, 6–12 January 2007; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2007; pp. 1588–1593. [Google Scholar]
- Zhang, R.; dos Santos, C.N.; Yasunaga, M.; Xiang, B.; Radev, D. Neural Coreference Resolution with Deep Biaffine Attention by Joint Mention Detection and Mention Clustering. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; Volume 2, pp. 102–107. [Google Scholar]
- Zhu, Y.; Peng, S.; Pradhan, S.; Zeldes, A. Incorporating Singletons and Mention-based Features in Coreference Resolution via Multi-task Learning for Better Generalization. In Proceedings of the 13th International Joint Conference on Natural Language Processing and the 3rd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics, Bali, Indonesia, 1–4 November 2023; Association for Computational Linguistics: Stroudsburg, PA, USA, 2023; Volume 2, pp. 121–130. [Google Scholar]
- Sukthanker, R.; Poria, S.; Cambria, E.; Thirunavukarasu, R. Anaphora and coreference resolution: A review. Inf. Fusion 2020, 59, 139–162. [Google Scholar] [CrossRef]
- Lee, K.; He, L.; Lewis, M.; Zettlemoyer, L. End-to-end Neural Coreference Resolution. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2017; Association for Computational Linguistics: Stroudsburg, PA, USA, 2017; pp. 188–197. [Google Scholar]
- Lee, K.; He, L.; Zettlemoyer, L. Higher-Order Coreference Resolution with Coarse-to-Fine Inference. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; Volume 2, pp. 687–692. [Google Scholar]
- Chen, H.; Fan, Z.; Lu, H.; Yuille, A.; Rong, S. PreCo: A Large-scale Dataset in Preschool Vocabulary for Coreference Resolution. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 172–181. [Google Scholar]
- Banarescu, L.; Bonial, C.; Cai, S.; Georgescu, M.; Griffitt, K.; Hermjakob, U.; Knight, K.; Koehn, P.; Palmer, M.; Schneider, N. Abstract Meaning Representation for Sembanking. In Proceedings of the 7th Linguistic Annotation Workshop & Interoperability with Discourse, Sofia, Bulgaria, 8–9 August 2013; Association for Computational Linguistics: Stroudsburg, PA, USA, 2013; pp. 178–186. [Google Scholar]
- Konstas, I.; Iyer, S.; Yatskar, M.; Choi, Y.; Zettlemoyer, L. Neural AMR: Sequence-to-Sequence Models for Parsing and Generation. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; Association for Computational Linguistics: Stroudsburg, PA, USA, 2017; Volume 1, pp. 146–157. [Google Scholar]
- Zhang, S.; Ma, X.; Duh, K.; Van Durme, B. AMR Parsing as Sequence-to-Graph Transduction. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 80–94. [Google Scholar]
- Bevilacqua, M.; Blloshmi, R.; Navigli, R. One SPRING to Rule Them Both: Symmetric AMR Semantic Parsing and Generation without a Complex Pipeline. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; Volume 35, pp. 12564–12573. [Google Scholar] [CrossRef]
- Cai, D.; Lam, W. AMR Parsing via Graph-Sequence Iterative Inference. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 1290–1301. [Google Scholar]
- Xu, D.; Li, J.; Zhu, M.; Zhang, M.; Zhou, G. Improving AMR Parsing with Sequence-to-Sequence Pre-training. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 2501–2511. [Google Scholar]
- Mao, J.; Gan, C.; Kohli, P.; Tenenbaum, J.B.; Wu, J. The Neuro-Symbolic Concept Learner: Interpreting Scenes, Words, and Sentences From Natural Supervision. arXiv 2019, arXiv:1904.12584. [Google Scholar]
- Wang, H.; Xin, H.; Zheng, C.; Li, L.; Liu, Z.; Cao, Q.; Huang, Y.; Xiong, J.; Shi, H.; Xie, E.; et al. LEGO-Prover: Neural Theorem Proving with Growing Libraries. arXiv 2023, arXiv:2310.00656. [Google Scholar]
- McCoy, R.T.; Pavlick, E.; Linzen, T. Right for the Wrong Reasons: Diagnosing Syntactic Heuristics in Natural Language Inference. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 3428–3448. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; Volume 1, pp. 4171–4186. [Google Scholar]
- Bai, X.; Chen, Y.; Zhang, Y. Graph Pre-training for AMR Parsing and Generation. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland, 22–27 May 2022; Association for Computational Linguistics: Stroudsburg, PA, USA, 2022; Volume 1, pp. 6001–6015. [Google Scholar]
- Martinelli, G.; Barba, E.; Navigli, R. Maverick: Efficient and Accurate Coreference Resolution Defying Recent Trends. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, Bangkok, Thailand, 11–16 August 2024; Association for Computational Linguistics: Stroudsburg, PA, USA, 2024; Volume 1, pp. 13380–13394. [Google Scholar]
- Martínez Lorenzo, A.C.; Huguet Cabot, P.L.; Navigli, R. AMRs Assemble! Learning to Ensemble with Autoregressive Models for AMR Parsing. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, Toronto, BC, Canada, 9–14 July 2023; Association for Computational Linguistics: Stroudsburg, PA, USA, 2023; Volume 2, pp. 1595–1605. [Google Scholar]
- Groschwitz, J.; Cohen, S.; Donatelli, L.; Fowlie, M. AMR Parsing is Far from Solved: GrAPES, the Granular AMR Parsing Evaluation Suite. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–10 December 2023; Association for Computational Linguistics: Stroudsburg, PA, USA, 2023; pp. 10728–10752. [Google Scholar]
- Ahmed, S.R.; Baker, G.A.; Judge, E.; Reagan, M.; Wright-Bettner, K.; Palmer, M.; Martin, J.H. Linear Cross-document Event Coreference Resolution with X-AMR. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), Torino, Italy, 20–25 May 2024; ELRA and ICCL: The Hague, The Netherlands, 2024; pp. 10517–10529. [Google Scholar]
- Meng, Y.; Pan, X.; Chang, J.; Wang, Y. RGAT: A Deeper Look into Syntactic Dependency Information for Coreference Resolution. In Proceedings of the 2023 International Joint Conference on Neural Networks (IJCNN), Gold Coast, Australia, 18–23 June 2023; IEEE: New York, NY, USA, 2023; pp. 1–8. [Google Scholar] [CrossRef]
- Cunnington, D.; Law, M.; Lobo, J.; Russo, A. The Role of Foundation Models in Neuro-Symbolic Learning and Reasoning. In Neural-Symbolic Learning and Reasoning: 18th International Conference, NeSy 2024, Barcelona, Spain, September 9–12, 2024, Proceedings, Part I; Springer-Verlag: Berlin/Heidelberg, Germany, 2024; pp. 84–100. [Google Scholar] [CrossRef]
- Karpas, E.; Abend, O.; Belinkov, Y.; Lenz, B.; Lieber, O.; Ratner, N.; Shoham, Y.; Bata, H.; Levine, Y.; Leyton-Brown, K.; et al. MRKL Systems: A Modular, Neuro-Symbolic Architecture that Combines Large Language Models, External Knowledge Sources and Discrete Reasoning. arXiv 2022, arXiv:2205.00445. [Google Scholar]
- Saha, S.; Yu, X.; Bansal, M.; Pasunuru, R.; Celikyilmaz, A. MURMUR: Modular Multi-Step Reasoning for Semi-Structured Data-to-Text Generation. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2023, Toronto, BC, Canada, 9–14 July 2023; Association for Computational Linguistics: Stroudsburg, PA, USA, 2023; pp. 11069–11090. [Google Scholar]
- Zheng, K.; Zhou, K.; Gu, J.; Fan, Y.; Wang, J.; Di, Z.; He, X.; Wang, X.E. JARVIS: A Neuro-Symbolic Commonsense Reasoning Framework for Conversational Embodied Agents. arXiv 2022, arXiv:2208.13266. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).









{kind=link}
{kind=link}
{kind=link}
{kind=link}