
STCYOLO: Subway Tunnel Crack Detection Model with Complex Scenarios


Abstract
1. Introduction
- (1)
- Based on object detection
- (2)
- Based on semantic segmentation
- (1)
- The interior of tunnels may be subject to shadow effects from lighting, impacting the visibility of cracks, causing some cracks to be obscured or blurred, thereby increasing the difficulty of crack extraction.
- (2)
- Interpolation operations during the upsampling process may lead to the loss or blurring of information about minor cracks, resulting in the inability to effectively reconstruct these small cracks.
- (1)
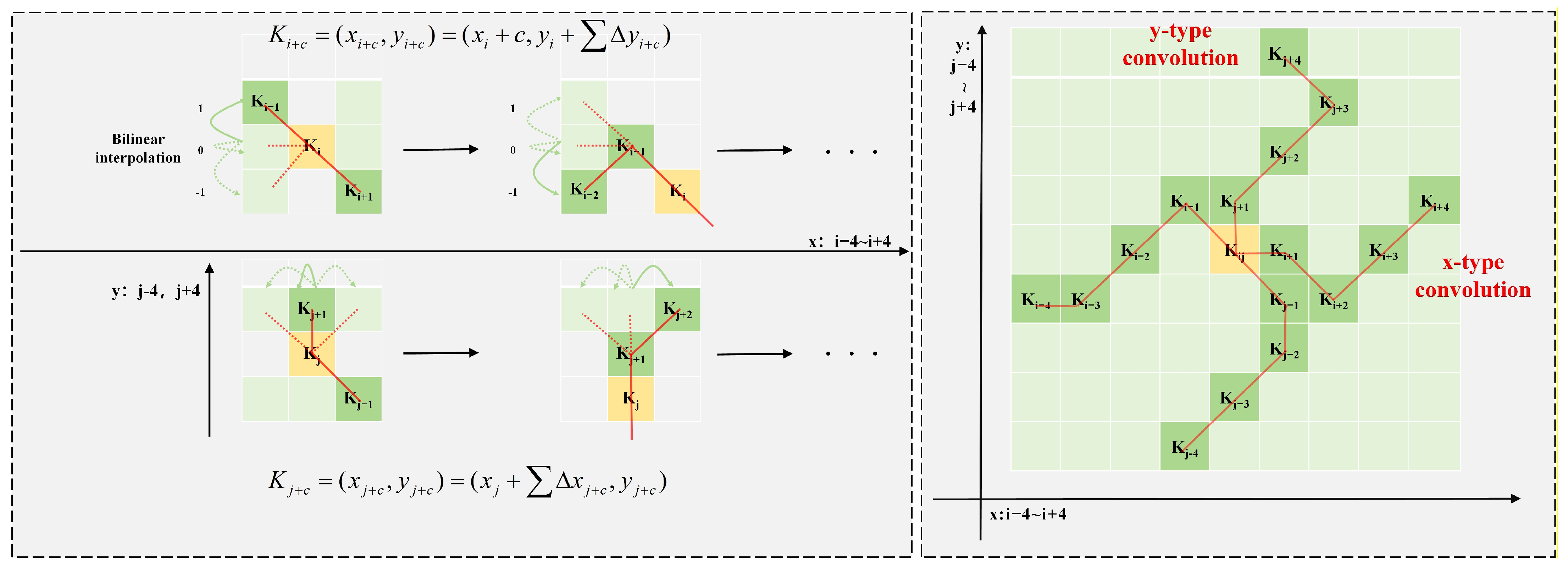
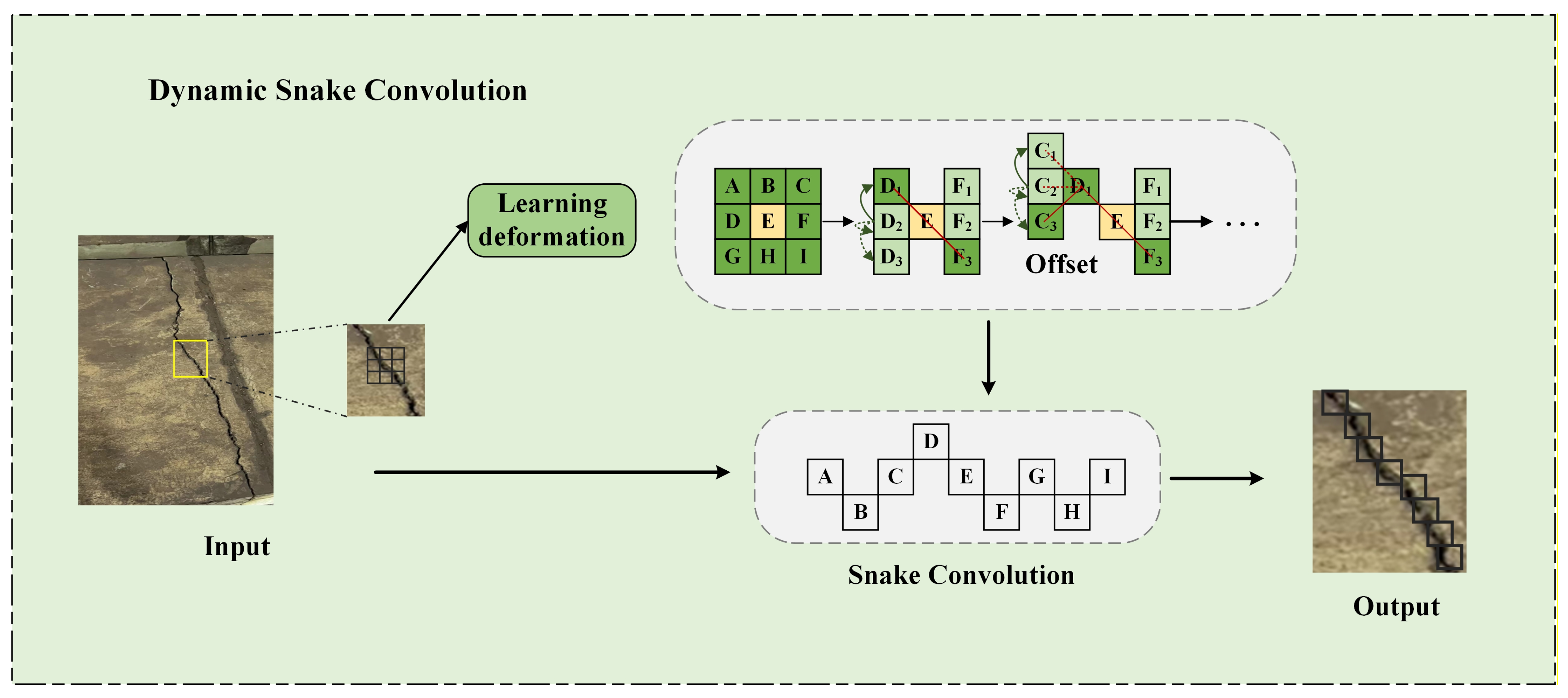
- Given the elongated structure of cracks, this paper proposes the introduction of the dynamic snake convolution method to enhance sensitivity to crack structures, better conform to and capture these structures, and improve crack detection performance.
- (2)
- A TCU method is proposed, which, compared to traditional upsampling methods, can more effectively retain the features of minor cracks, avoiding the loss of important information during the upsampling process.
- (3)
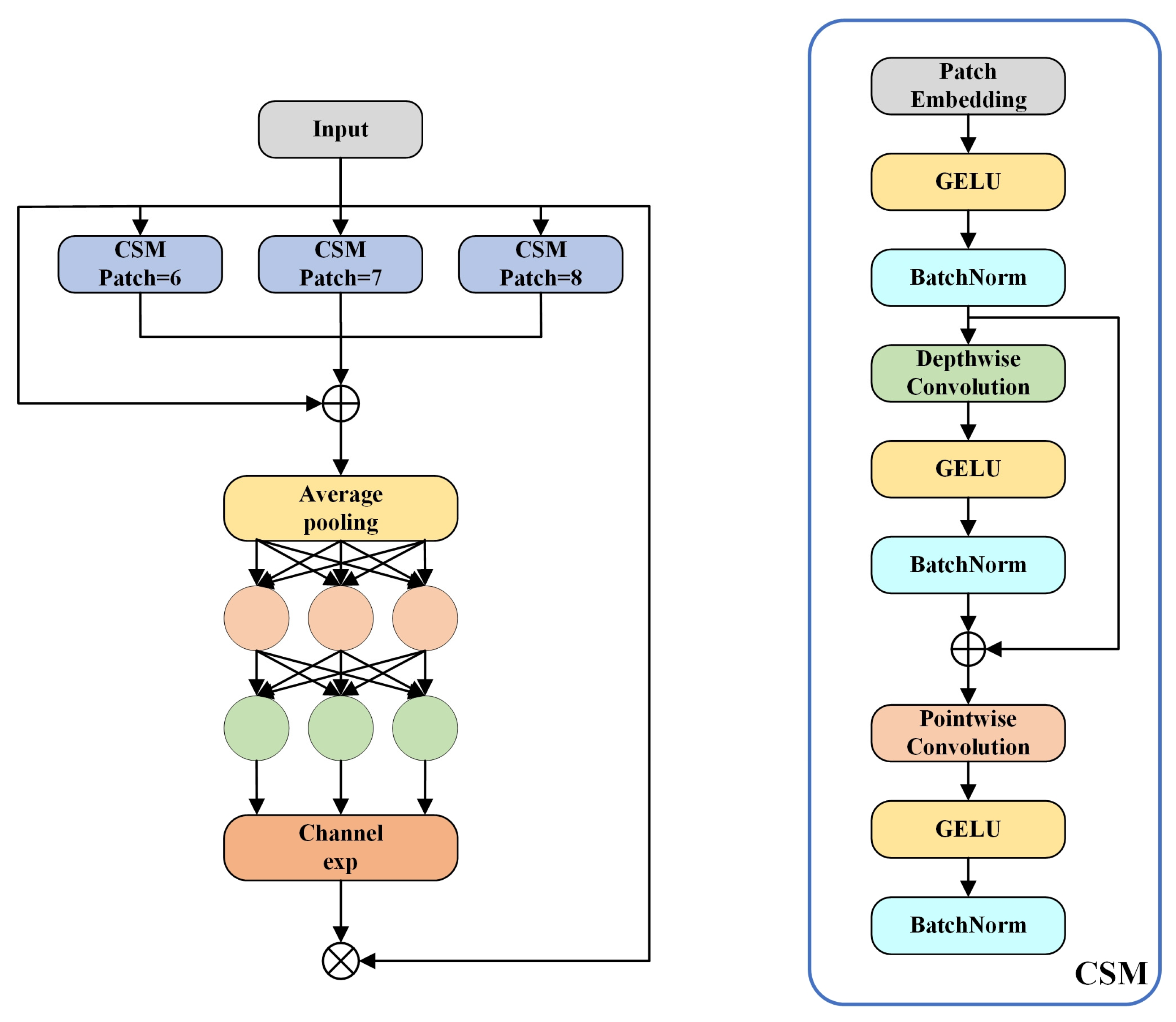
- A head with SOAA is proposed, enabling it to effectively handle scenarios where cracks are obscured by shadows.
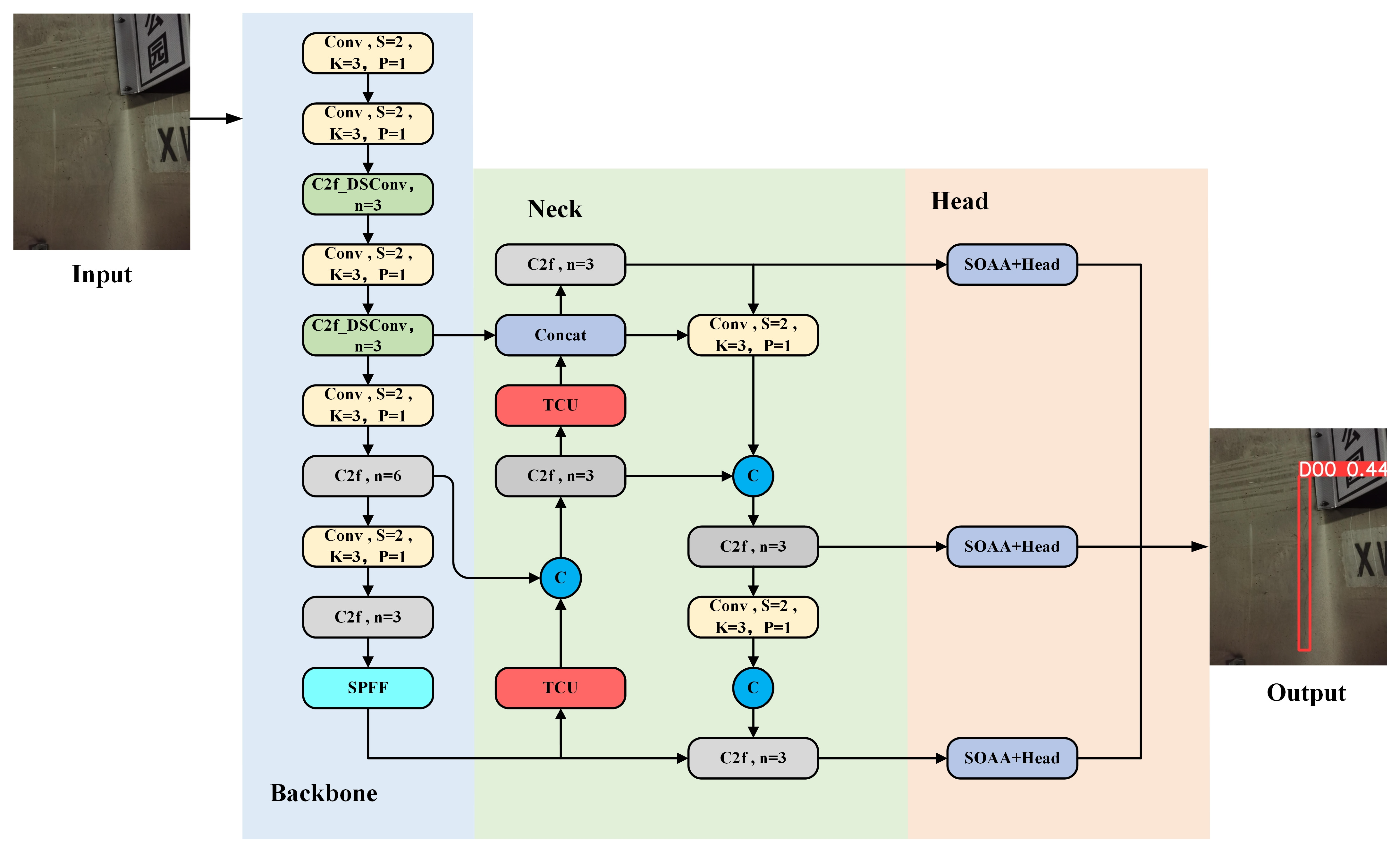
2. Methodology
2.1. Dynamic Snake Convolution
2.2. Tiny Crack Upsampling Algorithm
2.3. Shadow Occlusion-Aware Attention Mechanism
3. Experiments and Results
3.1. Experimental Data
3.2. Experimental Parameter Setting
3.3. Model Comparison
3.4. Ablation Experiment
4. Discussion
4.1. The Complexity of the Model
4.2. Dataset
4.3. The Shortcomings of the SOAA Module
4.4. The Shortcomings of the TCU Module
5. Conclusions
- (1)
- Adding different models result in a complex model structure and increased computational complexity. Especially in scenarios with high real-time requirements, this may lead to a bottleneck.
- (2)
- The model may have a high dependence on specific training data, and the current data distribution may not fully match the actual application scenario, which may affect the performance of the model.
- (3)
- The SOAA module may mainly focus on detecting cracks in shadows, but cracks may still be obscured or blurred in areas of extremely low brightness or strong reflection.
- (4)
- The TCU module may focus on improving the detection capability of small cracks, but at the same time, this may lead to an increase in the false detection rate.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yang, H.; Xu, X. Intelligent Crack Extraction Based on Terrestrial Laser Scanning Measurement. Meas. Control 2020, 53, 416–426. [Google Scholar] [CrossRef]
- Liu, D.; Deng, Y.; Yang, F.; Xu, G. Nondestructive Testing for Crack of Tunnel Lining Using GPR. J. Cent. S. Univ. Technol. 2005, 12, 120–124. [Google Scholar] [CrossRef]
- White, J.; Hurlebaus, S.; Shokouhi, P.; Wimsatt, A. Use of Ultrasonic Tomography to Detect Structural Impairment in Tunnel Linings: Validation Study and Field Evaluation. Transp. Res. Rec. J. Transp. Res. Board 2014, 2407, 20–31. [Google Scholar] [CrossRef]
- Gong, Q.; Zhu, L.; Wang, Y.; Yu, Z. Automatic Subway Tunnel Crack Detection System Based on Line Scan Camera. Struct. Control Health Monit. 2021, 28, e2776. [Google Scholar] [CrossRef]
- Li, C.; Xu, P.; Niu, L.; Chen, Y.; Sheng, L.; Liu, M. Tunnel Crack Detection Using Coarse-to-fine Region Localization and Edge Detection. WIREs Data Min. Knowl. Discov. 2019, 9, e1308. [Google Scholar] [CrossRef]
- Jiang, F.; Wang, G.; He, P.; Zheng, C.; Xiao, Z.; Wu, Y. Application of Canny Operator Threshold Adaptive Segmentation Algorithm Combined with Digital Image Processing in Tunnel Face Crevice Extraction. J. Supercomput. 2022, 78, 11601–11620. [Google Scholar] [CrossRef]
- Ba, Y.; Zuo, J.; Jia, Z. Image Filtering Algorithms for Tunnel Lining Surface Cracks Based on Adaptive Median-Gaussian. In Proceedings of the ICTE 2019; American Society of Civil Engineers, Chengdu, China, 13 January 2020; pp. 849–853. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper With Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Xue, Y.; Li, Y. A Fast Detection Method via Region-Based Fully Convolutional Neural Networks for Shield Tunnel Lining Defects. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 638–654. [Google Scholar] [CrossRef]
- Zhou, Z.; Zhang, J.; Gong, C.; Wu, W. Automatic Tunnel Lining Crack Detection via Deep Learning with Generative Adversarial Network-Based Data Augmentation. Undergr. Space 2023, 9, 140–154. [Google Scholar] [CrossRef]
- Li, D.; Xie, Q.; Gong, X.; Yu, Z.; Xu, J.; Sun, Y.; Wang, J. Automatic Defect Detection of Metro Tunnel Surfaces Using a Vision-Based Inspection System. Adv. Eng. Inform. 2021, 47, 101206. [Google Scholar] [CrossRef]
- Juan, S.; Long-Xi, H.; Hui-Ping, L. Tunnel Lining Multi-Defect Detection Based on an Improved You Only Look Once Version 7 Algorithm. IEEE Access 2023, 11, 125171–125184. [Google Scholar] [CrossRef]
- Dai, Q.; Xie, Y.; Xu, J.; Xia, Y.; Sheng, C.; Tian, C.; Ou, W. Tunnel Crack Identification Based on Improved YOLOv5. In Proceedings of the 2022 7th International Conference on Automation, Control and Robotics Engineering (CACRE), Xi’an, China, 14–16 July 2022; pp. 302–307. [Google Scholar]
- Ren, Y.; Huang, J.; Hong, Z.; Lu, W.; Yin, J.; Zou, L.; Shen, X. Image-Based Concrete Crack Detection in Tunnels Using Deep Fully Convolutional Networks. Constr. Build. Mater. 2020, 234, 117367. [Google Scholar] [CrossRef]
- Li, G.; Ma, B.; He, S.; Ren, X.; Liu, Q. Automatic Tunnel Crack Detection Based on U-Net and a Convolutional Neural Network with Alternately Updated Clique. Sensors 2020, 20, 717. [Google Scholar] [CrossRef] [PubMed]
- Liao, J.; Yue, Y.; Zhang, D.; Tu, W.; Cao, R.; Zou, Q.; Li, Q. Automatic Tunnel Crack Inspection Using an Efficient Mobile Imaging Module and a Lightweight CNN. IEEE Trans. Intell. Transp. Syst. 2022, 23, 15190–15203. [Google Scholar] [CrossRef]
- Zhou, Q.; Qu, Z.; Li, Y.-X.; Ju, F.-R. Tunnel Crack Detection With Linear Seam Based on Mixed Attention and Multiscale Feature Fusion. IEEE Trans. Instrum. Meas. 2022, 71, 5014711. [Google Scholar] [CrossRef]
- Zhou, Z.; Zheng, Y.; Zhang, J.; Yang, H. Fast Detection Algorithm for Cracks on Tunnel Linings Based on Deep Semantic Segmentation. Front. Struct. Civ. Eng. 2023, 17, 732–744. [Google Scholar] [CrossRef]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable ConvNets V2: More Deformable, Better Results. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9308–9316. [Google Scholar]
- Qi, Y.; He, Y.; Qi, X.; Zhang, Y.; Yang, G. Dynamic Snake Convolution Based on Topological Geometric Constraints for Tubular Structure Segmentation. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 6070–6079. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Keypoint Triplets for Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6568–6577. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 10778–10787. [Google Scholar]
- Li, Y.; Sun, S.; Song, W.; Zhang, J.; Teng, Q. CrackYOLO: Rural Pavement Distress Detection Model with Complex Scenarios. Electronics 2024, 13, 312. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Typology | Parameters |
|---|---|
| Initial learning rate | 1 × 10−5 |
| Batch size | 8 |
| Optimizer | Adam |
| Epoch | 300 |
| Metric | EfficientDet | CenterNet | DETR | YOLOV8 | CrackYOLO | STCYOLO |
|---|---|---|---|---|---|---|
| Precision (%) | 67.32 | 68.89 | 74.35 | 76.74 | 77.34 | 79.39 |
| Recall (%) | 63.33 | 66.15 | 71.71 | 73.95 | 74.26 | 76.30 |
| F score (%) | 65.13 | 68.63 | 73.22 | 75.62 | 75.77 | 78.64 |
| mAP (%) | 67.22 | 69.11 | 74.65 | 75.98 | 76.97 | 78.83 |
| GFLOPs (G) | 46.99 | 70.22 | 208.92 | 81.50 | 79.30 | 78.20 |
| Baseline | C2f_DSConv | TCU | SOAA | mAP (%) | GFLOPs (G) |
|---|---|---|---|---|---|
| ✓ | 75.98 | 79.30 | |||
| ✓ | 76.22 | 80.70 | |||
| ✓ | 76.84 | 79.70 | |||
| ✓ | 77.92 | 75.20 | |||
| ✓ | ✓ | ✓ | 78.83 | 78.20 |
| Baseline | 1 | 2 | 3 | 4 | mAP (%) | GFLOPs (G) |
|---|---|---|---|---|---|---|
| ✓ | 75.98 | 79.30 | ||||
| ✓ | 76.07 | 80.00 | ||||
| ✓ | ✓ | 76.22 | 80.70 | |||
| ✓ | ✓ | ✓ | 76.24 | 81.70 | ||
| ✓ | ✓ | ✓ | ✓ | 76.25 | 82.20 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Li, H.; Song, W.; Zhang, J.; Shi, M. STCYOLO: Subway Tunnel Crack Detection Model with Complex Scenarios. Information 2025, 16, 507. https://doi.org/10.3390/info16060507
Zhang J, Li H, Song W, Zhang J, Shi M. STCYOLO: Subway Tunnel Crack Detection Model with Complex Scenarios. Information. 2025; 16(6):507. https://doi.org/10.3390/info16060507
Chicago/Turabian StyleZhang, Jia, Hui Li, Weidong Song, Jinhe Zhang, and Miao Shi. 2025. "STCYOLO: Subway Tunnel Crack Detection Model with Complex Scenarios" Information 16, no. 6: 507. https://doi.org/10.3390/info16060507
APA StyleZhang, J., Li, H., Song, W., Zhang, J., & Shi, M. (2025). STCYOLO: Subway Tunnel Crack Detection Model with Complex Scenarios. Information, 16(6), 507. https://doi.org/10.3390/info16060507