1. Introduction
In the actual context of a dynamic and evolving real estate market, the ability to accurately predict property prices is important for subjects like investors, homebuyers, and policymakers. Understanding how property prices are formed aids investors in making informed decisions about purchasing and selling properties. Policymakers use knowledge of price formation to develop regulations that stabilize the housing market to avoid bubbles and crashes, which can have wide-reaching economic impacts. In fact, rapid increases or decreases in housing prices can signal an overheating or underperforming economy, respectively, and they can be used as indicators of economic health. By studying real estate price formation, stakeholders can gain insights into the interactions between demand, supply, economic factors, and expectations that determine property prices. Urban planners and local governments study real estate price trends to make decisions about development, infrastructure investments, and housing affordability programs. The dynamics behind price formation can reveal whether the housing market is efficient or if there are distortions that need to be addressed. Banks and other lenders rely on accurate housing price information to manage risks in mortgage lending and to set appropriate borrowing limits [
1].
Regression analysis is utilized to ascertain the extent to which each feature contributes individually to house pricing. An analysis of the housing market and housing price assessment literature reveals two predominant research trends: the application of the hedonic-based regression approach, termed the hedonic pricing model (HPM), and the employment of artificial intelligence (AI) approaches for establishing house price forecasting models. A range of hedonic-based approaches have been employed to investigate the correlation between house prices and their associated effective housing attributes. A comparison of the results of previous studies indicated that the AI technique performed better at forecasting property values than the HPM approach. Machine learning (ML) is a powerful AI approach for predicting property prices and understanding the mechanisms that drive price formation in real estate markets [
2]. In particular, ML is a computational method that uses fundamental concepts in computer science in combination with statistics, probability, and optimization to make predictions and improve performance for a given task. ML can be categorized into two types: supervised and unsupervised. In supervised ML, the method receives a dataset with labeled data, making it the most common approach for classification and regression problems. In contrast, unsupervised ML involves data that are not labeled. The overarching objective of ML is to facilitate the creation of efficient and accurate predictions, with two common objectives being classification and regression [
3].
The use of ML algorithms provides several advantages; because factors affecting house prices are constantly changing, the developed models can be adapted to new data, making them suitable for dynamic markets and leading to more efficient behaviors of buyers, sellers, investors, and policymakers in their decision-making processes. Unlike traditional valuation methods, such as those based on cyclical capitalization [
4], machine learning allows for the detection of complex, non-linear patterns and adaptive modeling in the presence of market uncertainty and low transparency [
5]. There are several ML algorithms commonly used for predicting and analyzing real estate prices. Each of them has different strengths, and the choice of the most suitable can depend on the specific attributes of the dataset, the complexity of the modeling task, computational resources, and the level of interpretability required. Data scientists may often test a range of models and use techniques like cross-validation to determine which algorithm performs the best for their specific scenario. For example, linear regression is one of the simplest algorithms and determines the relationship between a dependent variable (e.g., property price) and one or more independent variables (e.g., square footage, bedrooms, etc.) using a linear function [
6]. It is easy to be understood and interpreted, but it may not capture complex relationships. Other machine learning algorithms integrate classification and regression for modeling non-linear relationships for finding the hyperplane that best fits the data, as well as handling non-linear relationships using kernel functions, like the support vector machines [
7]. Therefore, if the linear regression can be a starting point for understanding relationships in the data, the Random Forest can better capture complex relationships. Support vector machines can be particularly effective when the data have a clear margin of separation. Neural networks, especially deep learning models, are powerful for large datasets with complex patterns, but they require greater computational resources and expertise to train and interpret [
8].
However, regardless of the algorithm employed, the accuracy and interpretability of machine learning models are deeply influenced by how the input data are preprocessed. In this context, normalization techniques play a crucial role, especially in regression modeling, where subtle changes in data scale can significantly affect model behavior and output. Although few articles provide unambiguous operational guidelines on the “uses” of standardization techniques, the following are well-documented in the literature:
Standardization techniques influence the information transmitted to models (e.g., [
9,
10]);
The choice of technique may improve or compromise the interpretability of results, particularly in contexts where the semantic meaning of variables is important, such as in economic and social models;
Different techniques meet different objectives, such as precision, robustness, threshold detection, noise reduction, relative comparison, etc.
This research investigates the impact of six different normalization techniques on the prediction of house prices using a machine-learning-based regression model. The research question addressed in this study is the following: “To what extent do different normalization techniques affect both the statistical reliability and the interpretability of regression models used to predict house prices?”. In order to understand this issue, the analysis is carried out on a heterogeneous dataset consisting of 117 housing prices (as dependent variables) and six extrinsic real estate variables reflecting the social, economic, and environmental characteristics of urban areas in the city of Rome (Italy). Evolutionary Polynomial Regression (EPR), a multivariate supervised regression model, is applied to each normalized dataset. By comparing the statistical accuracy and functional relationships of the resulting models, the study identifies which normalization techniques provide the most robust and interpretable results.
This work contributes to the field of information processes by addressing how the mathematical transformation of variables—through their normalization—affects the structure and the interpretability of the data in urban valuation models. The study responds to the growing need for epistemologically aware data practices in applied machine learning, particularly in socio-economic domains, such as housing market analysis. Even though normalization is usually a mere technical step in statistical modeling, in real estate, its implications are far beyond fixing a scale. For real estate professionals and urban analysts running regression models for forecasting and decision making, the choice of normalization procedure may change the apparent role of explanatory variables and the believability of their relationship with house prices. This paper addresses a need for lessening the chasm between statistical modeling and housing market insights and calls for a scrutiny of the data processing choices not only with respect to statistical integrity but, indeed, with respect to narrative intelligibility.
The reminder of the paper is structured as follows.
Section 2 provides a review of the literature on machine-learning-based regression models;
Section 3 provides a description of the selected normalization techniques, the sample of real estate data, and the applied ML (i.e., the EPR method) features;
Section 4 relates to the results;
Section 5 discusses the obtained results; and
Section 6 outlines the conclusion and futures insights of the research.
2. Application of Normalization Techniques in the Context of Machine Learning Algorithms and the Real Estate Market
The performance of ML models varies based on many factors, such as the methods of normalization preprocessing. It is not only a technique that is used to convert raw data into a clean dataset, as it also enhances the performance of the analysis. There are dozens of normalization methods in the literature, and no one is the most suitable for all situations. The characteristics of the problem, the predictive task, or the requirements and assumptions of the ML model can guide the choice of an adequate normalization method. Rayu et al. [
11] establish that the utilization of these techniques boosts performance by 5–10% in general.
Jo [
12] studied the effectiveness of normalization preprocessing of big data to the support vector machine (SVM) as the ML method. Three normalization methods—Simple Feature Scaling, Min-Max, and Z-score—are applied to the SVM for the performance comparison, and the Min-Max normalization method is preferred to the other ones. Pandey and Jain [
13] use Z-score and Min-Max as normalization methods for the K-Nearest Neighbors algorithm, a non-parametric method for classification and regression. The average accuracy came out to be 88.0925% for Min-Max normalization and 78.5675% for Z-score normalization. Cabello-Solorzano [
14] studied the impact of three normalization techniques, namely, Min-Max, Z-score, and Unit Normalization, on the accuracy of ML algorithms in order to enhance accuracy in problem solving. The results reveal that a few algorithms are virtually unaffected by whether normalization is used or not, regardless of the applied normalization technique.
Eren [
2] presents how the ML methods perform with their original values and how the methods react when StandardScaler or MinMaxScaler is used on the dataset for predicting property prices and sale velocities in the real estate market. Zou et al. [
15] explore the impact of air pollution on housing prices through an ML approach. The dataset is normalized by using the Min-Max technique for the implementation of the gradient boosting decision tree. Baldominos et al. [
16] see the impacts of the use of normalization in the median average error for the different ML techniques considered. Normalization does not have an impact on the ensembles of regression trees, K-Nearest Neighbors, and support vector regression. The only case in which normalization makes a difference is when using a multi-layer perceptron; the median average error increases when normalization (max value) is used. This is contrary to the common belief that normalization is often considered a good practice to prevent numerical instability when training the neural network, but the perceptron is not competitive when compared to other ML techniques in the problem of real estate price prediction. Ekberg and Johansson [
17] compare different ML methods’ capability to predict housing prices in the Stockholm city housing market and include a comparison between Random Forest, K-Nearest-Neighbor Regression, and a neural network implementation. The Min-Max scaler is applied to Random Forest implementation, resulting in the one with the best performance. Mu et al. [
18] employ Z-score normalization with SVM, least squares support vector machine (LSSVM), and partial least squares (PLS) methods to forecast home values. Muralidharan et al. [
19] predict the assessed prices of residential properties by applying ML algorithms (decision trees and Artificial Neural Networks) for the real estate market of Boston. The analyzed numerical data are transformed using Min-Max normalization. Avanijaa [
20] proposes a model for house price prediction that assists both buyer and seller. The XGBoost regression algorithm is proposed by normalizing the considered data with the employment of the Z-score technique. Farahzadi et al. [
21] try to identify the best model of housing price forecasting using five ML algorithms: the Neighbor Regression Algorithm (KNNR), the Support Vector Regression Algorithm (SVR), the Random Forest Regression Algorithm (RFR), the Extreme Gradient Boosting Regression Algorithm (XGBR), and the Long Short-Term Memory Neural Network Algorithm. The Min-Max normalization method is performed on the housing dataset to obtain the final and error-free version.
In conclusion, the literature highlights the significant but variable impact of normalization techniques on the performance of ML algorithms, particularly in the context of house price forecasting. Although methods like Min-Max and Z-score normalization often improve model accuracy, their effectiveness is not uniform across algorithms and applications. Moreover, some techniques may even introduce bias or reduce interpretability in certain cases, as observed with neural networks or ensemble methods [
22]. This variability underlines the need for a specific assessment of the context of standardization strategies. Authors, such as Floridi [
23], Bishop [
24], and Domingos [
25], suggest that preprocessing (including normalization) is not neutral, because it defines the semantic conditions under which a machine learning model learns. So, it is legitimate—and questionable—to reflect on which transformation is more consistent with the objective of knowledge or operation. For these reasons, the present study contributes by offering a comparative assessment of six important normalization techniques within a set of real estate data, applying the Evolutionary Polynomial Regression model to discover how these techniques affect both the statistical accuracy and the interpretative structure of house price forecasts. This approach not only fills a gap in existing research but also provides practical guidance for analysts, policymakers, and urban planners who wish to apply sound and meaningful ML models to the valuation of urban assets.
4. Results
The iterative application of the EPR-ML method is carried out with the same settings for each of the normalized study samples processed. In particular, the EPR is implemented with a statical regression (not lag), no inner function f selected, a maximum number of equation terms equal to nine, and a set of exponents belonging to the range (0, 0.5,1, 1.5, 2). The exponent equal to 1 means that the model considers the variable in its original form, the exponent equal to 0 means that no variable is considered, the exponent equal to 2 means it is elevated to the square, and, if it is equal to 0.5, it makes the square root.
The models generated by the EPR method for each elaboration (normalization technique employment) are reported in
Table 2.
The statistical significance of the obtained models is very high for all (CoD > 92.00). Only for the Z-score non-monotonic normalization is the CoD slightly lower, but it still gives a good statistical significance of the results. For the max value (or maximum absolute scaling) normalization the CoD of the selected model, no. 27 is the highest one, followed by model no. 31 of the mean value’s normalization (CoD = 93.05).
As can be seen in
Table 2, the models are characterized by a different set of explanatory variables. In most cases, all of them are present in the model, except for the presence of degraded neighborhoods [Ad] that is missing in the model of the Min-Max technique. Also, the level of maintenance conditions of buildings [De] is excluded by the generated results for the models of Min-Max and Z-score non-monotonic techniques. The level of social disease [Ds] is not taken into account in the model of the standard deviation technique. Instead, the resident population variable [Po] is excluded from the Z-score non-monotonic chosen model. In
Table 3, a synthesis of the included and/or excluded independent variables for each normalization technique’s model is shown.
As correctly observed in the literature [
36,
37,
38,
39], normalization is carried out on independent variables; therefore, it does not alter the regression algorithm, nor does it affect the calculation of the coefficient of determination (R
2), and it does not change the sign of the coefficients. However, in the case of the non-linear and adaptive EPR method, which constructs the shape of the equation as a function of the input data, normalization can have a substantial impact on the final result. Although the algorithm remains formally unchanged, normalization does the following:
It changes the distribution and variance of independent variables;
It alters the correlations between variables;
It influences the probability that some variables are selected in the early stages of the evolutionary algorithm;
It can lead to the selection of different combinations of terms and powers;
It therefore produces different final equations, with potentially different R2.
In other words, normalization does not change the structure of the algorithm, but it affects its adaptive behavior within user-defined boundaries. This effect is not an anomaly but a systemic feature of non-linear data-driven models, such as EPR, neural networks, or boosting.
Table 4 below summarizes these differences, distinguishing the expected behavior in linear models from that observable in adaptive models.
5. Discussion
The study of the effects of normalization techniques on the regression’s results can be performed by analyzing three main aspects: (i) the type of functional relationship with the dependent variable, (ii) the trend, and (iii) behavior interpretation. The first aspect led to the identification of (i) increasing and/or decreasing, (ii) linear positive and/or negative, and (iii) non-linear or quadratic functional relationships between the property price and each independent variable admissible. The importance of this aspect relates to four issues: consistency of results, interpretability, robustness of the model, and generalizability. Standardization techniques can change the distribution of independent variables and thus alter their impact on house prices. If the functional relationship between price and an independent variable changes significantly after normalization, it is necessary to understand whether the change is real or an artefact of data transformation. In other words, it is essential to know whether the normalization process is fattening the outliers or distorting the variables. If the form of the functional relationship is altered by standardization, the economic and urban significance of the variables may be compromised, making it difficult to draw practical conclusions and interpretations. In addition, some normalization techniques may lead to the exclusion of significant variables, affecting the robustness of the regression model and the number of variables selected. If a normalization technique reduces the variance of a variable to make it statistically irrelevant to the regression, this variable could be automatically excluded from the model (as in Min-Max scaling for variables with very small ranges). Identifying the nature of the functional relationship helps to understand whether a variable has been excluded because it is actually irrelevant or because normalization has altered its information. Correct identification of the functional relationship therefore helps to select the most appropriate normalization technique to maintain the validity of the forecasts.
Trend identification allows us to understand how independent variables influence the price of real estate. When comparing six different normalizations, it is important to check that the relationship between the exogenous variable and the price remains constant in direction and strength. If one normalization technique drastically changes the slope of the functional relationship compared to the others, this may indicate that it is altering the economic significance of the variable. This is essential to ensure that the results obtained after standardization are consistent with market reality. If per capita income has a positive and increasing relationship with price in all normalization techniques except one (e.g., Z-score non-monotonic), which instead shows a non-linear trend with an initial fall and then a rise, this means that this technique has introduced bias into the model. Trend (slope) analysis makes it possible to identify the standardization techniques that accentuate or attenuate the effects of variables, thus helping to select the most appropriate method according to the objective of the study.
Finally, the analysis of the interpretation of the behavior between the dependent and independent variables has practical implications for policymakers, investors, and planners. If the model leads to misinterpretations of the relationships between variables, decisions based on these results may be wrong. For example, if the model suggests that housing density is always negative for property values, this could lead to policies that limit the construction of new units. However, if a different standardization technique shows that the relationship becomes positive beyond a certain threshold, then it may make sense to promote urban densification strategies. The interpretation of the behavior of the variable helps to choose the technique of normalization that best preserves the economic logic of the phenomenon studied. In
Table 5,
Table 6,
Table 7,
Table 8,
Table 9 and
Table 10, all of the three mentioned aspects of regression results are discussed for each of the independent variables and normalization techniques.
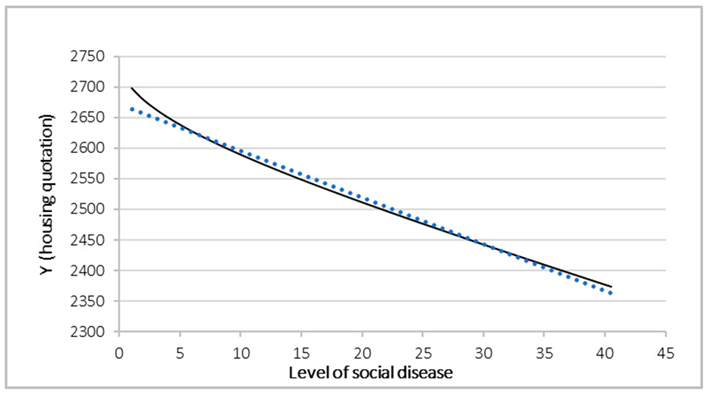
The majority of the techniques demonstrate a negative relationship between social distress and real estate value, which is consistent with the expected economic dynamics. However, with the exception of the standard deviation technique, which indicates an increase in real estate values as social unrest escalates, the remaining techniques exhibit an initial phase where social distress does not exert a negative influence (or even promotes a slight increase in prices), followed by a phase of marked decline beyond a critical threshold. These techniques have the potential to accentuate the significance of critical thresholds, thereby rendering the model more susceptible to variations in data. Conversely, mean value, Z-score non-monotonic and max value scaling techniques have been observed to confirm a consistent decline in real estate prices with an increase in social distress. These techniques appear to be the most reliable in representing a constant devaluation without emphasizing critical thresholds. The standard deviation scaling technique, which alternates the effect of the relationship, has been observed to demonstrate a growing trend, with an increase in price concomitant with an increase in social discomfort. However, it is important to note that this technique may distort the scale of the data, reversing the sign of the relationship. Standard deviation scaling has also been observed to change the ranking of observations, giving more weight to extreme values, leading to an inversion of the relationship between social distress and real estate price. This has resulted in a disproportionate amplification of the weight of observations with high social discomfort, distorting the relationship between variables. This effect could be particularly pronounced in specific markets, such as areas experiencing high social distress that are subject to speculative investment or gentrification processes. In such cases, an increase in prices may be observed despite the associated degradation. Consequently, mean value and max value scaling are considered the most reliable options. However, if the analysis aims to identify a critical threshold, Min-Max scaling and sum show threshold effects in social distress.
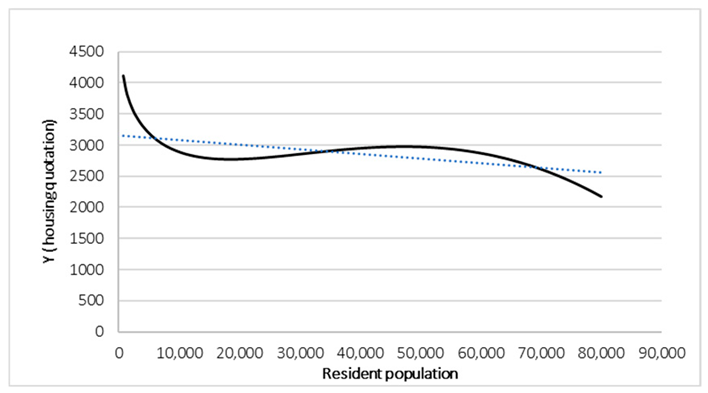
All techniques indicate that property values tend to decrease with an increase in the resident population, albeit with discrepancies in the mode of this devaluation. Min-Max, mean value, max value, and standard deviation demonstrate a pronounced initial devaluation, followed by a stabilization phase and then a slight descent in high density areas. Sum scaling exhibits a reverse U-shaped trend, suggesting that moderate housing density may be associated with higher property values prior to a subsequent devaluation. Min-Max scaling, mean value scaling, max value scaling, and standard deviation scaling demonstrate a rapid devaluation in the initial population levels, followed by a stabilization phase. Notably, Min-Max and standard deviation scaling exhibit a slight decline in the final phase, suggesting a negative impact of high density. Conversely, mean value and max value scaling show a sharper stabilization, indicating the potential for high density areas to maintain stable prices. Sum scaling is the only technique that shows an initial increase in real estate value in sparsely populated areas, followed by a gradual decline of over 30,000 inhabitants. This normalization emphasizes the threshold effect, highlighting the optimal value of housing density before devaluation. It is evident that there are discrepancies in the behavior of the more than the 60,000 resident population under consideration. Min-Max and standard deviation demonstrate a recovery in the devaluation of the subjects, suggesting that urban congestion could potentially impact property value. Conversely, mean value and max value show greater stabilization, indicating that, under these normalizations, high density is not inherently detrimental. Conversely, sum scaling demonstrates a progressive decline without a discernible stabilization phase, underscoring the adverse relationship between housing density and real estate value. In conclusion, mean value scaling and max value scaling emerge as the most reliable for a constant and predictable depreciation, while sum scaling is more suitable as it exhibits the U-shaped behavior. When the objective is to emphasize the impact of high density on final devaluation, Min-Max scaling and standard deviation scaling prove to be more sensitive in areas with over 60,000 inhabitants.
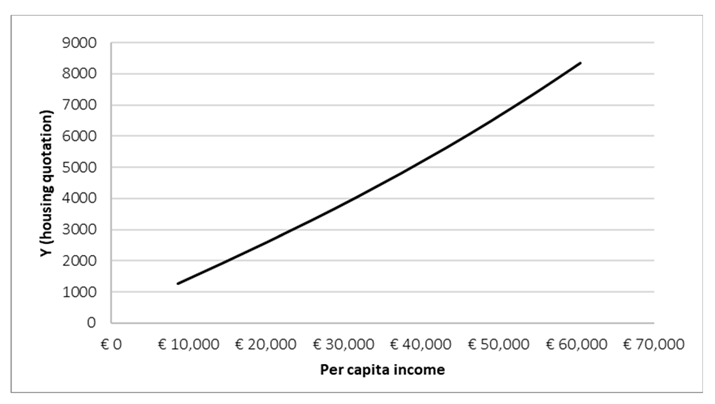
The majority of the techniques indicate a positive correlation between per capita income and property value, though the specific patterns of growth and acceleration vary across techniques. Notably, Z-score non-monotonic demonstrates an initial decrease, followed by a recovery in the final phase. The overall positive correlation between per capita income and real estate value is substantiated; however, the influence of per capita income on real estate growth exhibits variations in its implementation across different techniques of normalization. The Z-score non-monotonic normalization may have accentuated an initial rebalancing effect that is not evident in other techniques. Sum scaling is the sole technique that demonstrates a perfectly linear relationship between per capita income and real estate value, suggesting that it may be the most suitable normalization method if one aims to model a linear behavior devoid of threshold or acceleration effects. However, it is noteworthy that per capita income may exerts a limited impact in the nascent stages of economic development, yet it becomes increasingly significant as the economy matures. Conversely, mean value, max value, and standard deviation scaling demonstrate an escalating relationship with progressive acceleration. It is conceivable that the effect of the per capita income is not invariably positive and that critical thresholds exist: Min-Max scaling may emphasize a threshold beyond which further increases in the per capita income do not have a strong impact on real estate growth; Z-score non-monotonic might suggest that in less developed economies the per capita income could initially reduce property values, and then support them at a later stage. In summary, the demonstration of linear growth can be achieved through the utilization of sum scaling. The role of the rising of per capita income on real estate values is illustrated by mean value, max value or standard deviation scaling. Finally, potential threshold or saturation effects are emphasized by Min-Max scaling (saturation) or Z-score non-monotonic (initial inversion phase).
The majority of the techniques examined demonstrated a positive correlation between green spaces and property value, though variations in growth rate and saturation effects were observed. Notably, Z-score non-monotonic exhibited an initially decreasing relationship, followed by a slight recovery in the final phase. The overall conclusion of the study suggests a positive relationship between green spaces and real estate value. Conversely, Min-Max scaling, mean value scaling, and sum scaling demonstrate a reverse U-shaped relationship, indicating that green spaces exert a positive effect up to a certain threshold, beyond which they can potentially have a neutral or negative impact. These normalizations underscore an optimal threshold between green and real estate value. Max value scaling and standard deviation scaling reveal a steady growth in real estate value with an increase in green. Z-score non-monotonic, on the other hand, demonstrates an initial devaluation, followed by a subsequent reversal. This standardization is particularly useful in exploring the potential non-uniformity of the impact of green spaces, suggesting the existence of critical thresholds.
All techniques confirm that urban degradation exerts a negative effect on real estate prices, albeit with variations in the rate of devaluation and perception of the initial impact. Only Z-score non-monotonic demonstrates a more pronounced initial phase of devaluation, suggesting that the market reacts more strongly to early deterioration increments. Z-score may emphasize a stronger initial impact, while sum, max, and standard deviation show a more uniform effect. Conversely, mean value scaling, Z-score non-monotonic, max value scaling and standard deviation scaling demonstrate a steadily decreasing and constant relationship, rendering them more suitable for demonstrating stable and predictable effects. Z-score non-monotonic, in particular, exhibits a pronounced devaluation in the initial stages of degradation, making it a valuable technique for analyzing the market’s sensitivity to early signs of deterioration. Max value scaling and standard deviation scaling maintain higher real estate values than other normalizations, making them more appropriate for scenarios where the objective is to preserve disparities between more and less degraded areas.
All techniques demonstrate that the deterioration of buildings has a negative impact on real estate prices, but with changes in the depreciation rate. Only sum scaling shows an initial devaluation followed by a recovery for higher degradation levels, while max value scaling emphasizes the maximum value for buildings in intermediate condition. Mean value scaling and standard deviation scaling show a weakly decreasing and constant relationship. Sum scaling suggests that buildings in poor condition may be subject to speculation and renovation, keeping their value higher than expected. Maximum value scaling is predicated on the premise that the market favors properties that require only minor interventions and thus places a greater emphasis on the maximum value for buildings in moderate condition. In order to analyze the effect of real estate speculation or market behavior in relation to buildings with different conditions of deterioration, it is recommended that these normalization be utilized.
Table 11 summarizes the main functional effects, trend behavior and potential applications of each normalization technique, based on the empirical results obtained through the EPR modeling. The comparison highlights how each transformation affects the model’s ability to detect, represent and interpret relationships between input variables and property values. As can be seen, the results clearly reveal that the normalization method has both statistical and model interpretability implications. Each normalization technique results in the induction of different sets of variables, alters the functional form of the input–output relationships, and in certain cases even flips the sign of the impact. For instance, normalization techniques such as Z-score non-monotonic or standard deviation induce non-monotonic or complex relationships, which make interpretation difficult. Conversely, Min-Max or max value scaling tend to maintain the natural meaning and sign of the coefficients. Therefore, normalization affects not only the numerical output of regression, but also the semantic one—by modifying the explanation of the phenomenon and perhaps the perceived importance of the variables.
6. Conclusions
The present study constitutes an analytical investigation into real estate price valuations through machine-learning-based regression. In order to explore the extent to which different normalization techniques affect both the statistical reliability and the interpretability of regression models used to predict house prices, the study examines the impact of six data normalization techniques on the results of regression analyses.
This research is of particular relevance to decision makers and public administrations, who rely on forecasting models to adopt informed strategies regarding building accessibility programs, infrastructure investments, and sustainable urban development. The identification of the correct normalization methodology is therefore essential to ensure sound forecasts, avoiding distortions that could lead to erroneous decisions in the field of urban planning and housing policies. This is the first step of a generalized approach. It should pointed out that although this study was carried out on a specific urban environment—the city of Rome—and uses a dataset derived from 117 local real estate areas, its aim is not to build a prediction model for this single city but to identify the effect of different normalization procedures on the functional relationships and the interpretative consistency of regression models when dealing with real estate data. The use of the EPR method in conjunction with diversified normalization techniques is suggested as a general methodological approach with the possibility of extension to other urban systems and datasets. Even though the empirical results are context-specific, the logical structure and the sensitivity patterns identified are probably generic and may be found in numerous types of urban evaluative applications. In terms of scalability, it is important to note that this analysis is based on area-level data aggregated at the level of urban areas. Although this level of aggregation allows for the emergence of patterns that are significant in terms of socio-economic and spatial indicators, the results should not be directly interpreted at the level of individual properties. However, the observed effects of normalization on the regression output, in particular on the selection of variables and the functional form, are not necessarily related to scale. Therefore, the methodological insights provided in this work can be adapted to more disaggregated or larger datasets, as long as similar model structures and configurations are used.
The primary conclusions of the study demonstrated that the impact of social degradation on real estate value exhibited a negative relationship in the majority of standardized analyses, with certain techniques, such as standard deviation scaling, indicating a potential mitigation or even reversal effect. The investigation further revealed that the influence of the resident population exhibited varied trends across different standardization techniques. Some techniques exhibited a negative linear relationship, while others suggested an intermediate maximum value, indicating the possibility of a threshold effect in urban dynamics. The per capita income output demonstrated a positive relationship with property value across all normalization techniques, though with variations in the growth slope. The presence of green spaces exhibited a favorable impact on property value; however, certain normalizations highlighted a critical threshold beyond which the effect may diminish. The deterioration of buildings exhibited varied relationships with the technique employed, with some normalization confirming a progressive devaluation, while others exhibited U or U-shaped effects. This suggests that buildings in moderate condition may possess the lowest value. The results for sum normalization show very small variation in functional relationships, particularly for variables such as degraded neighborhoods (Ad) and building condition (De). Regression curves appear to be nearly horizontal, indicating that the transformation reduces the data expressiveness and hides potential non-linearities. This confirms that sum normalization, while good for comparative weighting, is not so good for detecting threshold effects or intensity-based patterns in real estate valuations models. Generalizing: although some variables may already be expressed on a scale between 0 and 1, normalization can be applied uniformly to all predictors to ensure experimental comparability between techniques. However, we recognize that the decision to normalize should ideally take into account the intrinsic properties of each variable, including its theoretical limits and empirical distribution. These findings suggest that in non linear, adaptive models—such as EPR, but also neural networks, gradient boosting, XGBoost, SVM con kernel RBF, k-NN, k-means, symbolic regression engines—the preprocessing phase is not a neutral operation. Instead, it could influence interpretability, the model structure and statistical performance itself. Generalizing this insight could be valuable in broader applications of machine learning to urban data and valuation studies.
Although the results obtained provide important insights, it is important to recognize some limitations that could affect the interpretation and generalizability of the results.
- (i)
The study focuses exclusively on the urban area of the city of Rome. Although this is a very complex and representative city, the results may not be directly transferable to other urban realities with different socio-economic and morphological characteristics;
- (ii)
The use of the EPR method, while offering advantages in terms of interpretability, may not capture functional relationships that the use of other machine learning approaches could provide;
- (iii)
Some of the data used are from official sources updated to 2021. Subsequent socio-economic changes may not be reflected in the results, which may affect their relevance.