This section describes the proposed approach in two parts, the first part describes the U-net network model in detail, and the second part presents the improved model proposed in this paper.
3.1. Proposed U-Net
The U-Net segmentation network is renowned for its high precision, concise structure, and superior overall performance [
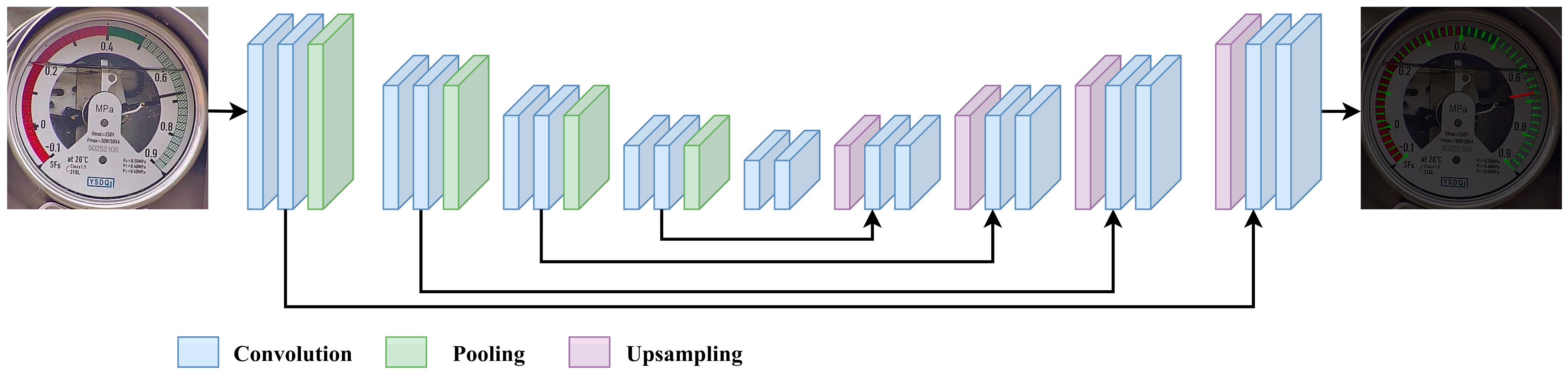
12]. Its architecture primarily consists of two core components: the encoder and the decoder, as illustrated in
Figure 1. The encoder is composed of a series of convolutional layers, pooling layers, and activation functions, which are responsible for extracting image features. The decoder, on the other hand, integrates low-level features from the backbone network with high-level features through upsampling operations and skip connections, thereby improving the segmentation of fine details. With its symmetric encoder-decoder structure, the U-Net network effectively extracts multi-scale features from images. Its unique skip connection mechanism is particularly effective in recovering image details, making it widely used in the segmentation of small-sample medical images.
Despite its remarkable performance in tasks such as medical image segmentation, the U-Net architecture still has several limitations. First, the conventional convolutions used in the encoder can extract features but have limited ability to capture multi-scale information in images. This makes it difficult to effectively handle complex textures and structures within images. Second, traditional upsampling methods in the decoder may lead to the loss of detail information, thereby affecting segmentation accuracy. Additionally, although the skip connections in U-Net can preserve spatial information to some extent, the efficiency of feature fusion is still insufficient when dealing with complex images, which may result in discontinuities in the segmentation outcomes.
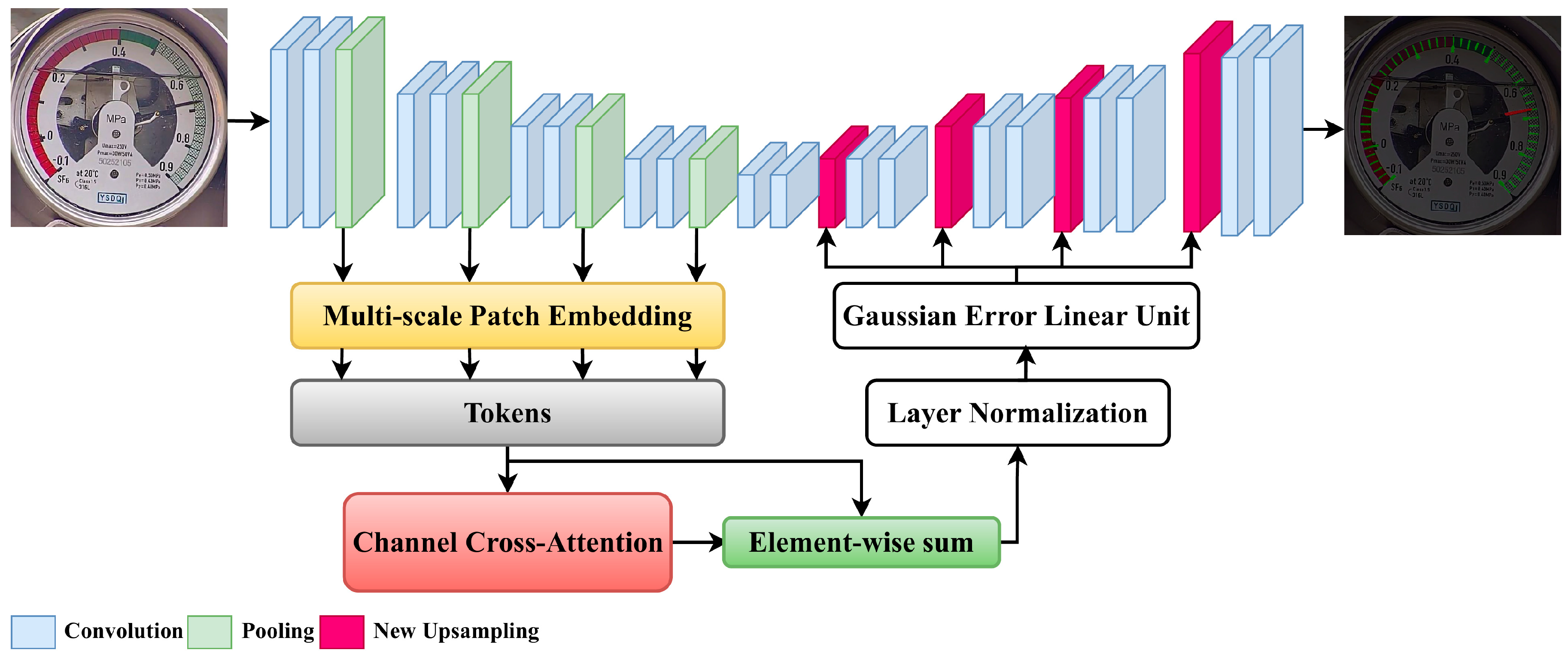
To address these limitations of the original U-Net, the following optimizations have been made to the network architecture in this study. First, conventional convolutions in the encoder are replaced with wavelet convolutions. Wavelet convolutions leverage the advantages of multi-scale analysis to more effectively extract details and structural information from images, thereby enhancing the richness and expressiveness of features. Second, the SimAM module is introduced in the upsampling stage [
13]. By adaptively enhancing important information and suppressing redundant information in feature maps, the SimAM module can effectively mitigate the loss of detail information during upsampling and improve the accuracy of segmentation results. Furthermore, a Channel Cross-Attention (CCA) [
14] module is embedded in the intermediate part of the model. The CCA module dynamically adjusts channel weights to focus on features that are more critical for the segmentation task, further improving the efficiency of feature fusion and segmentation performance. The improved network architecture is illustrated in
Figure 2.
Replacing traditional convolutions with WTConv (Wavelet Transform-based Convolution) provides a sophisticated alternative for enhancing the receptive field within convolutional neural networks. This approach efficiently broadens the receptive field with a logarithmic increase in the number of trainable parameters relative to the size of the field, thereby circumventing the issue of over-parameterization. WTConv not only augments the network’s ability to capture multi-frequency responses but also bolsters its robustness against image corruptions and enhances its propensity for shape recognition, all while maintaining computational efficiency and ease of integration into existing CNN frameworks. The improvement in the upsampling stage is illustrated in
Figure 3.
3.1.1. Integrate Cross-Channel Attention Mechanism
In this work, the Cross-Channel Attention (CCA) module plays a crucial role in improving feature representation by capturing dependencies across channels at multiple scales within the encoder, specifically in the context of the U-Net architecture. U-Net’s structure, known for its encoder-decoder design, facilitates feature extraction at various scales through the encoder and connects these features to the decoder via skip connections. When applied to complex image segmentation tasks (e.g., dial images with small objects, intricate backgrounds, and noise), the CCA module helps in addressing the semantic gap, thereby enhancing feature fusion. The standard skip connections in U-Net, while useful, may lead to the loss of important semantic information. The CCA module, by modeling cross-channel dependencies, allows for more efficient fusion of low-level and high-level features, addressing the semantic gap and improving overall segmentation quality.
The extracted feature patches are passed through a 1 × 1 depthwise convolution to project them into 1D representations. Depthwise convolution is effective in capturing local information while reducing computational complexity, making it ideal for use in attention mechanisms. The resulting feature blocks are then flattened into queries (Q), keys (K), and values (V), which will be used in subsequent computations.
The extracted feature patches are then passed through 1×1 depthwise convolution to project them into a 1D form. Depthwise convolutions are particularly suited for attention mechanisms as they preserve local information with minimal computational overhead. After this transformation, the patches are flattened and turned into queries (Q), keys (K), and values (V), which are the primary components used in the attention mechanism.
In the cross-channel attention computation, a dot-product operation is performed, calculating the similarity between the queries (Q) and keys (K). Then, a Softmax function is applied to normalize the attention weights, ensuring that they sum to 1. These weights represent the importance of each channel, and they are used to perform a weighted summation of the values (V), resulting in enhanced feature representations.
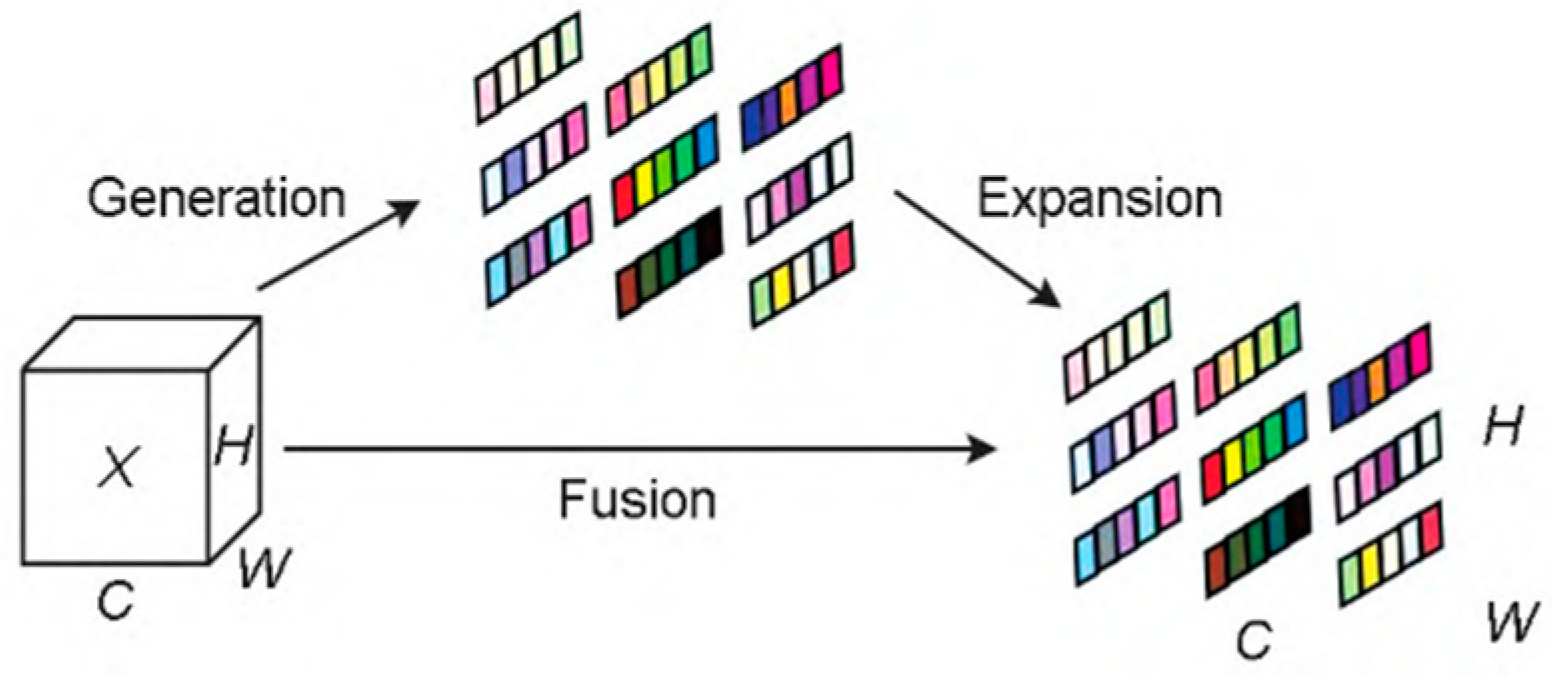
The central idea behind the CCA module is its ability to model global dependencies across channels from different scales. The attention mechanism, through the dot-product and Softmax function, calculates the relationship between queries and keys, thereby capturing long-range dependencies between channels. This process minimizes the semantic gap between the encoder and decoder, optimizes feature fusion, and enables better representation of critical information at multiple scales. To clearly demonstrate how the CCA module works, refer to
Figure 4, which illustrates the structure and information flow of the CCA module. The figure shows how queries, keys, and values interact and highlights the process of capturing cross-channel dependencies, as well as how effective connections are made between features at different scales.
To better illustrate the function of the CCA module,
Figure 4 depicts its structure and the flow of information. The figure demonstrates how the queries, keys, and values interact to capture cross-channel dependencies and establishes how the features from multiple scales are connected to improve segmentation.
Our CCA module implementation uses depthwise separable convolutions to project queries, keys, and values in order to reduce computational complexity. CCA is applied at four levels of the U-Net, with feature dimensions of 64, 128, 256, and 512, respectively, and a single-head attention mechanism at each level. The input features are first spatially compressed through a 28 × 28 adaptive average pooling, then the channel-wise relationships are computed via a dot-product attention mechanism. Finally, the attention output is fused with the original features through a residual connection. The hyperparameters of the CCA module are shown in
Table 1.
3.1.2. Incorporate an Adaptive Attention Mechanism
To better segment fine pointers and scales within the dial, the model’s feature extraction capabilities must be enhanced. Attention mechanisms help the network focus on the pointer and scale regions of the dial, thereby improving target segmentation accuracy. By incorporating the SimAM attention mechanism into the decoder structure, the network is enabled to adaptively focus on the pointer targets, further enhancing segmentation performance.
SimAM calculates the importance of each neuron through a process involving linear transformation and spatial suppression, as illustrated in
Figure 5. Inspired by principles from neuroscience, SimAM offers a novel attention approach that avoids adding parameters. Unlike traditional attention mechanisms, which operate along either the channel or spatial dimensions, SimAM generates 3D attention weights that consider both spatial and channel information simultaneously. This is achieved through an energy function that quantifies the importance of each neuron within the feature map. By minimizing this energy function, SimAM efficiently assigns higher importance to neurons that show distinct activity compared to surrounding neurons, a concept rooted in spatial suppression from neuroscience. This approach not only reduces computational overhead but also allows the model to focus on the most informative features, improving attention across multiple dimensions of the feature map.
The energy function has a fast closed-form solution, enabling SimAM to compute the attention weights efficiently without adding extra parameters. The implementation typically involves global average pooling (GAP), variance calculation, and weight computation based on the energy function. Overall, SimAM effectively introduces an attention mechanism through a simple, parameter-free approach, boosting the network’s performance and efficiency. Simultaneously, integrating wavelet convolution with this attention mechanism further demonstrates its advantages.
In this study, I integrated this parameter-free attention module at the front end of the upsampling stage in the U-Net architecture and introduced an efficient channel attention mechanism after upsampling. This dual-attention enhancement strategy not only optimizes the representation of feature maps and improves the accuracy and robustness of image segmentation but also maintains the network’s computational efficiency due to its lightweight nature. It provides an excellent solution for image processing that is both high-performing and low-resource-consuming. The architecture is shown in
Figure 5.
The energy function is defined to measure the importance of each neuron based on its separability from other neurons within the same channel:
where
and
represent the linear transformations of the target neuron
t and other neurons
in the feature map
. Here,
and
are predefined labels for the target and other neurons, respectively.
M = H ×
W denotes the total number of neurons in a single channel, and
and
are the weight and bias parameters of the linear transformation.
The final energy value for each neuron is computed as:
where
and
represent the mean and variance of the neurons in the same channel, excluding the target neuron
t. The energy
is a measure of how distinct the target neuron t is from the other neurons in the channel. A lower energy value indicates that the neuron is more distinctive and thus more important for the task. The term
in the denominator measures the squared difference between the target neuron and the mean of the channel, which reflects the neuron’s deviation from the average. The term
in the denominator accounts for the variance of the channel, which represents the spread of the neuron values. The λ in this module is a hyperparameter, and in this study, λ is set to 0.0001.
The importance of each neuron is inversely proportional to its energy value, denoted as
. The refined feature map is obtained by scaling the original feature map using the computed attention weights:
where
is the matrix containing all
values, and ⊙ denotes element-wise multiplication.
3.1.3. Replacing Traditional Convolution with Wavelet Convolution
In traditional convolutional neural networks, increasing the kernel size to capture a larger receptive field often results in an exponential increase in the number of parameters, which leads to over-parameterization. To address this, we propose using Wavelet Convolution (WTConv) as an alternative to traditional convolutions, enabling more efficient receptive field expansion while maintaining relatively low parameter count.
WTConv integrates the advantages of the Wavelet Transform (WT) by decomposing the input image into multiple frequency bands, processing each band separately using smaller kernels. This method allows the network to efficiently capture both low- and high-frequency features without a significant increase in computational cost. The key advantage of WTConv lies in its ability to handle multi-scale features more effectively compared to traditional convolution.
To improve computational efficiency, depthwise separable convolution is combined with WTConv. Depthwise convolution is applied to each frequency component independently, followed by pointwise convolution to integrate the features. The resulting operation is:
where
represents the convolution kernel applied to each frequency component, and
and
are the low-frequency and high-frequency components, respectively. The wavelet convolution operates on each component independently, ensuring efficient feature extraction across multiple frequency bands.
represents the depthwise convolution operation.
Wavelet Convolution (WTConv) offers significant advantages over traditional convolution methods. While traditional convolutions increase the receptive field by enlarging the kernel size, leading to exponential growth in the number of parameters, WTConv achieves larger receptive fields in a more parameter-efficient manner by leveraging wavelet decomposition. This method scales the receptive field logarithmically with kernel size, which reduces the computational burden. Additionally, WTConv decomposes the input into multiple frequency bands, enabling the simultaneous capture of both low- and high-frequency features, whereas traditional convolution typically focuses on high-frequency components. This multi-frequency approach enhances the model’s ability to extract detailed and robust features across different scales, making it particularly beneficial for tasks that require comprehensive feature extraction. Furthermore, WTConv retains spatial resolution, unlike Fourier-based methods, making it especially suitable for tasks like segmentation that rely on preserving fine spatial details. By using smaller convolution kernels applied to each frequency component, WTConv also significantly reduces the computational cost compared to traditional large-kernel convolutions, ensuring both efficiency and scalability.
In summary, Wavelet Convolution (WTConv) offers several advantages over traditional convolutional methods, including more efficient receptive field expansion, the ability to handle multi-frequency features, and enhanced computational efficiency. These properties make WTConv particularly suitable for tasks requiring robust feature extraction across different scales, such as segmentation. We demonstrate the effectiveness of WTConv through experimental results, showing improved segmentation accuracy. By replacing traditional convolutions with WTConv, we achieve better performance and maintain a manageable model complexity.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}