
Stroke Detection in Brain CT Images Using Convolutional Neural Networks: Model Development, Optimization and Interpretability



Abstract

1. Introduction
- Develop a CNN model tailored for stroke detection in CT images.
- Evaluate performance using metrics like accuracy, precision, recall, F1-score, and area under the receiver operating characteristic curve (AUC-ROC).
- Enhance interpretability via explainability techniques to build clinical trust.
- Optimize the model through hyperparameter tuning for maximal efficiency.
- A computationally efficient model (20.1 M parameters, 76.79 MB memory) tailored for real-time stroke detection, outperforming hybrid models like in memory efficiency.
- The first-of-its-kind application of LIME, occlusion sensitivity, and saliency maps to explain stroke predictions in CT imaging.
- Rigorous testing on 9900 images from multi-center sources, addressing a critical gap in prior works.
2. Related Works
2.1. Deep Learning Approaches for Stroke Detection
2.1.1. Single-Stage Models
2.1.2. Multi-Stage Models
2.2. Model Optimization and Interpretability
2.3. Clinical Integration and Validation
2.4. GAP Analysis
- Data Limitations: Many existing models rely on relatively small and often homogeneous datasets, which can hinder their ability to generalize across diverse populations and clinical settings [14]. This study addresses data limitations by incorporating a larger and more diverse dataset (2501 images for training/validation and 9900 images for testing), enhancing the model’s capacity to generalize across different stroke types and imaging qualities. By expanding the dataset, this study aims to improve the model’s generalizability, which is crucial for ensuring accurate stroke detection across a variety of clinical environments and imaging conditions.
- While related studies [11,12] utilized datasets of 6650 and 2501 images, respectively, this study enhances generalizability through external validation on 9900 CT images from diverse institutions. Though the training dataset (2501 images) is smaller, the external validation set is 10x larger than [11], which ensures robustness across heterogeneous imaging protocols and stroke subtypes. This approach addresses a key gap in prior works, such as overreliance on single-center data.
- Model Complexity and Efficiency: High computational costs can limit the practical use of complex models such as ResNet50 in real-time clinical settings [15]. This study aims to optimize the CNN architecture through hyperparameter tuning to achieve maximal efficiency, reducing computational complexity while maintaining accuracy for real-time stroke detection. The proposed model reduces computational complexity through optimized architecture design, achieving high performance with significantly fewer operations compared to more complex models such as in [11]. While the model’s external accuracy (89.73%) trails state-of-the-art benchmarks, its streamlined architecture (20 M parameters) ensures practicality for real-time use, addressing a key clinical need. These optimizations enable real-time inference on standard clinical hardware, addressing a critical barrier to AI adoption in stroke care.
- Segmentation and Localization: While stroke detection accuracy is improving, the precise segmentation and localization of ischemic lesions remain a challenge [16]. Accurate segmentation of the ischemic core is crucial for guiding clinical decision-making. This study will focus on developing a CNN-based model tailored for stroke detection in CT images, with the goal of achieving high accuracy in ischemic stroke localization.
- Interpretability and Clinical Trust: Many deep learning models lack transparency, limiting their acceptance in clinical practice [17]. This study will enhance the interpretability of the CNN model using explainability techniques, thereby building clinical trust by providing clear visual explanations for stroke predictions.
- Real-World Validation: Although existing models have shown potential in controlled settings, their validation in real-world clinical environments is often limited [18]. This study aims to evaluate the performance of the CNN model using key metrics such as accuracy, precision, recall, F1-score, and AUC-ROC, ensuring its reliability and effectiveness for real-world clinical use.
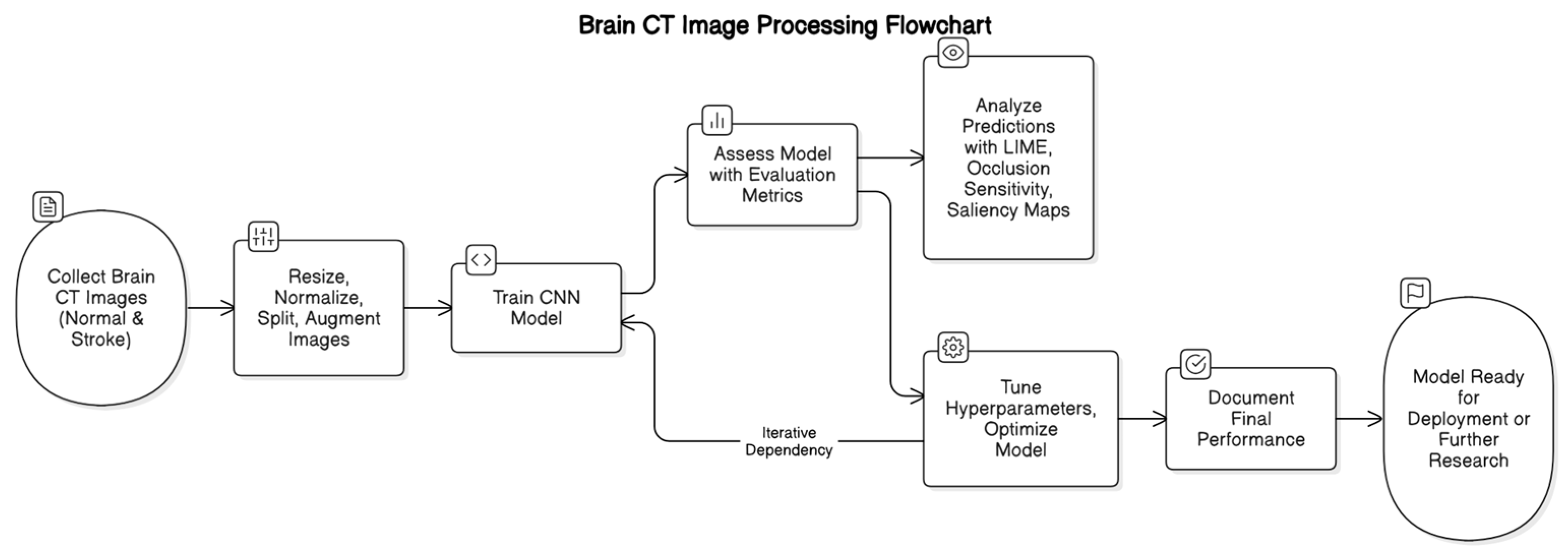
3. Materials and Methods
3.1. Data Collection and Preprocessing
3.1.1. Dataset Description
3.1.2. Preprocessing Pipeline
- Image Resizing: All images were resized to a uniform dimension of 256 × 256 pixels using bilinear interpolation [19]. This standardization ensures consistency across all samples while preserving critical anatomical features, which is crucial for accurate stroke detection by the CNN.
- Normalization: Pixel values were normalized to the range [0, 1] by dividing by 255 [20]. This normalization step accelerates the convergence of the model during training by scaling the input features to a standard range.
- Data Splitting: The dataset was partitioned into three subsets: training (80%), validation (10%), and testing (10%). This split ensures that the model is trained on a substantial portion of the data, while separate validation and test sets provide unbiased evaluations of its performance [21].
- Data Augmentation: To enhance the model’s generalization capabilities and mitigate overfitting, data augmentation techniques were applied to the training set. These techniques included rotation, width and height shifts, shear, zoom, and horizontal flipping. By introducing variability in the training data, the model becomes more robust to unseen data.
- o
- Rotation: For an angle θ, the rotation matrix is
- o
- Translation (Shifting): For a shift in the x and y directions by δx and δy, respectively:
- o
- Scaling (Zooming): To scale an image by a factor s, the scaling matrix is:
3.2. Model Development
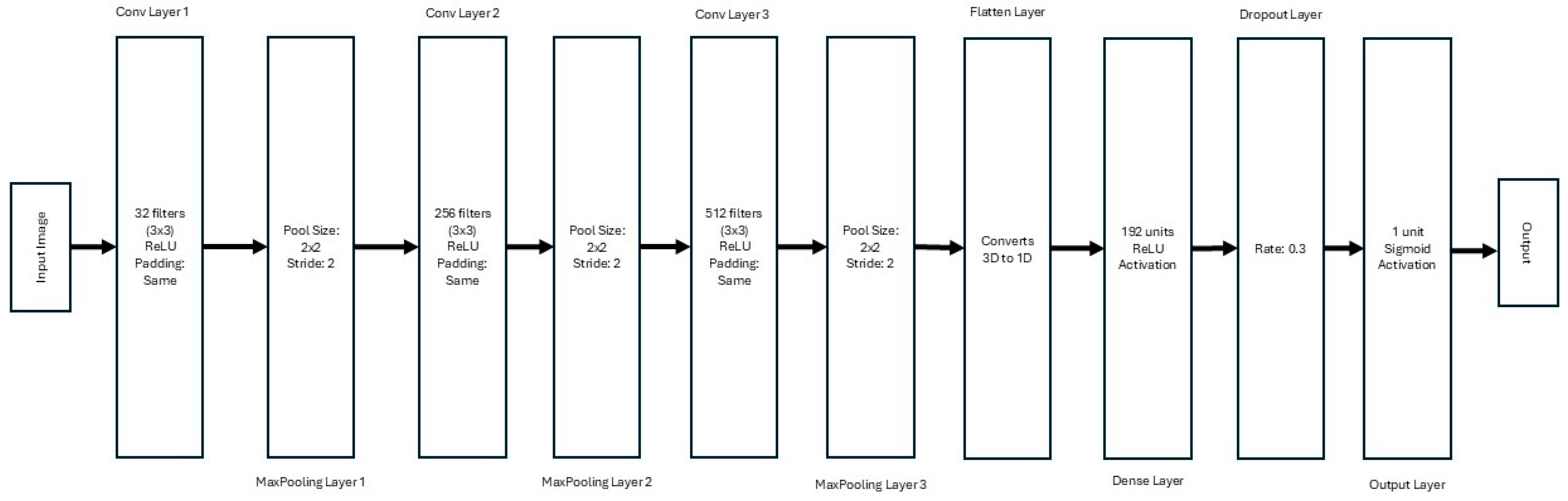
3.2.1. Architecture Design
- Convolutional Blocks:
- o
- First Block: 32 filters with a kernel size of 3 × 3, using the ReLU activation function and ‘same’ padding, followed by a 2 × 2 max-pooling layer.
- o
- Second Block: 256 filters with a kernel size of 3 × 3, ReLU activation, and ‘same’ padding, followed by a 2 × 2 max-pooling layer.
- o
- Third Block: 512 filters with a kernel size of 3 × 3, ReLU activation, and ‘same’ padding, followed by a 2 × 2 max-pooling layer.
- Dense Layers: A flattened layer converts the 3D output of the convolutional layers into a 1D vector. This is followed by a dense layer with 192 units and ReLU activation. A dropout layer with a rate of 0.3 is included to prevent overfitting.
- Output Layer: The final layer consists of a single neuron with sigmoid activation, enabling binary classification for stroke detection.
3.2.2. Hyperparameter Optimization and Fine-Tuning
- Convolutional Layer Filters: The number of filters in each convolutional layer was varied to explore different levels of feature extraction granularity. The search range included values of 32, 64, 96, 128, 160, 192, 224, and 256 filters for the first, second, and third convolutional layers, respectively. This parameter directly influences the model’s capacity to learn hierarchical features from the input images.
- Learning Rate: The learning rate of the Adam optimizer was tuned to ensure efficient convergence during training. The search space included values of 0.0001, 0.0005, and 0.001. An appropriate learning rate balances the speed of convergence and the stability of the training process.
- Dropout Rate: To mitigate overfitting, the dropout rate in the dense layers was optimized. The search range included values of 0.2, 0.3, 0.4, and 0.5. Dropout randomly deactivates a fraction of neurons during training, forcing the network to learn redundant representations and improving generalization.
- Dense Layer Units: The number of units in the dense layer was varied to explore different levels of model complexity. The search range included values of 64, 128, 192, and 256 units. This parameter affects the model’s ability to learn complex mappings from features to output predictions.
- Convolutional Filters: 32 (Layer 1), 256 (Layer 2), 512 (Layer 3);
- Learning Rate: 0.0005;
- Dropout Rate: 0.3;
- Dense Units: 192.
3.2.3. Training Procedure
- α is the learning rate;
- mt is the first moment estimate (mean of gradients);
- vt is the second moment estimate (variance of gradients);
- ϵ is a small constant to prevent division by zero.
3.2.4. Baseline Models
- Xception: It is an extension of the Inception architecture, introducing depthwise separable convolutions. This allows for more efficient processing, reducing the number of parameters while maintaining high accuracy. The architecture consists of 36 convolutional layers, and it has been shown to perform exceptionally well in image classification tasks. We trained the Xception model with the same dataset, preprocessing steps, and training procedure as the proposed CNN.
- ResNet50: It is a deep residual network that includes 50 layers and employs residual connections to address the vanishing gradient problem during training. The key advantage of ResNet50 is its ability to train deeper networks effectively, preserving information across many layers. This model was selected as a benchmark due to its widespread use in a variety of image recognition tasks and its demonstrated capability to achieve high accuracy in medical image classification.
- AlexNet: It is one of the earliest deep CNN architectures and is known for its breakthrough performance in the 2012 ImageNet competition. It consists of eight layers, including five convolutional layers and three fully connected layers. Although older compared to the other models in this study, AlexNet remains a significant baseline for medical imaging tasks due to its simplicity and historical importance in CNN development.
- VGG16: It is known for its simplicity and depth and has 16 layers (13 convolutional layers and 3 fully connected layers). The VGG architecture is characterized by its use of small 3 × 3 filters and a relatively uniform architecture, which allows for deeper networks. VGG16 has been a staple in the computer vision community and serves as a reliable benchmark for comparing more complex architectures.
3.3. Model Evaluation
3.3.1. Evaluation Metrics
3.3.2. Validation Strategy
- Cross-Validation: 5-fold cross-validation was implemented to ensure robustness. The dataset was partitioned into five folds, with each fold serving as the validation set once while the remaining data were used for training.
- Test Set Assessment: The final model was evaluated on an unseen test set to estimate real-world performance. The test set comprised 200 images (10% of the dataset).
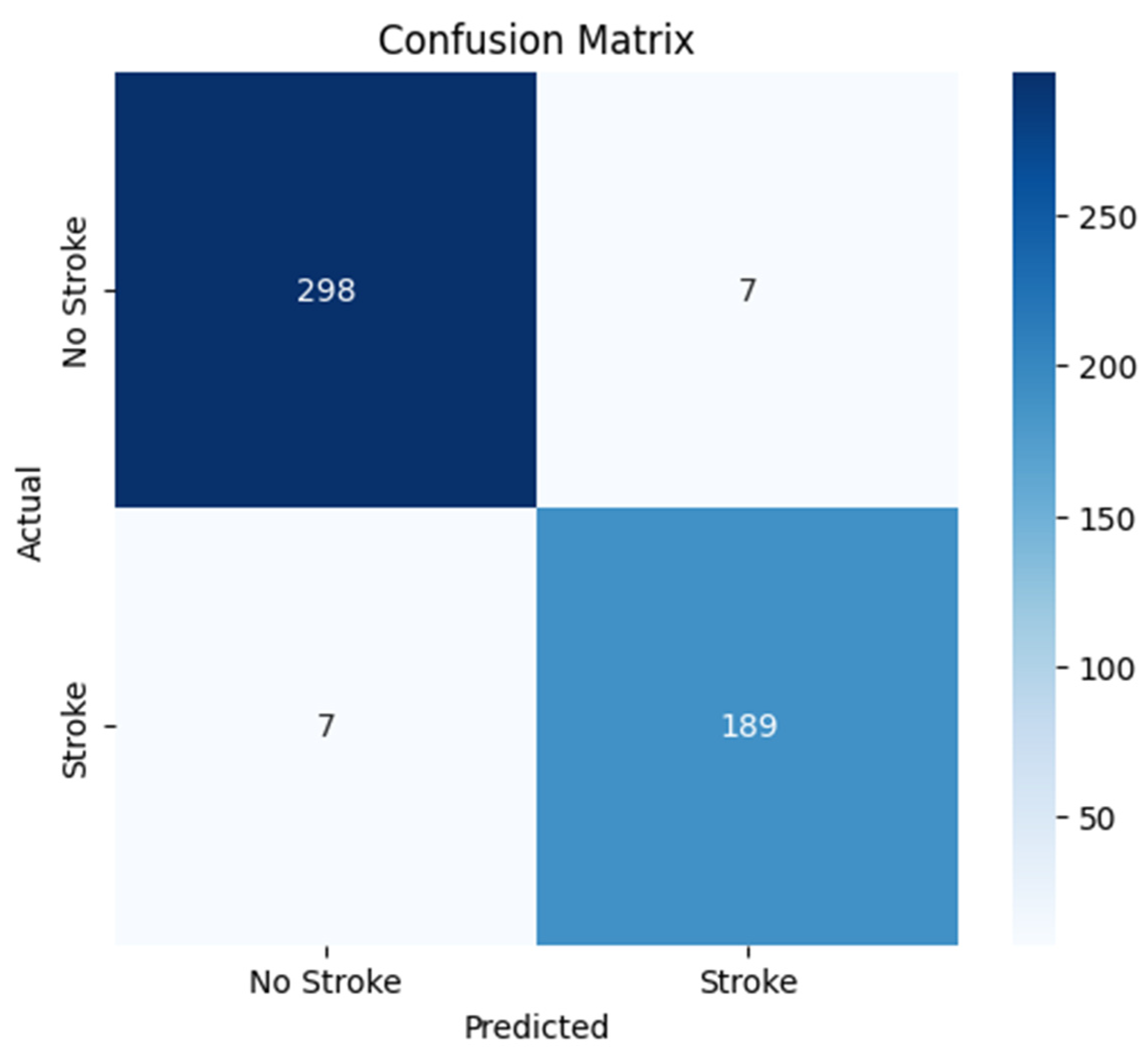
- Confusion Matrix: A confusion matrix was generated to analyze class-specific performance, providing insights into the model’s ability to correctly classify “Stroke” and “Normal” images.
3.3.3. Quantitative Performance Metrics
3.3.4. Results and Comparison with Baseline Models
3.4. Qualitative Model Explanations
3.4.1. LIME (Local Interpretable Model-Agnostic Explanations)
- xk is the feature value (superpixel) for the perturbed image;
- wk is the weight of the feature in the linear model;
- K is the number of features (superpixels).
| Algorithm 1: LIME for Stroke Detection |
| Input: CT image I, trained CNN model CNN_stroke, segmentation superpixels S, and number of perturbations N. Output: Interpretability map highlighting critical regions for “Stroke” prediction.
|
3.4.2. Occlusion Sensitivity
| Algorithm 2: Occlusion Sensitivity for Stroke Detection in CT Images |
| Input: CT Image (I), Trained CNN Model (CNN_stroke), Occlusion Patch Size. Output: Occlusion Heatmap (H) Highlighting Critical Regions.
|
3.4.3. Saliency Maps
| Algorithm 3: Gradient-based Saliency Maps for Stroke Detection |
| Input: CT Image (I), Trained CNN Model (CNN_stroke). Output: Saliency Map (S) Highlighting Pixel-wise Contributions to Predictions.
|
3.4.4. Findings
4. Results
4.1. Model Evaluation Metrics
4.2. Confusion Matrix Analysis
4.3. Cross-Validation Results
- Cross-validation accuracy (79.29 ± 1.2%) estimates generalizability across diverse data subsets.
- Hold-out validation accuracy (97.2%) reflects optimized performance on a fixed subset used for hyperparameter tuning.
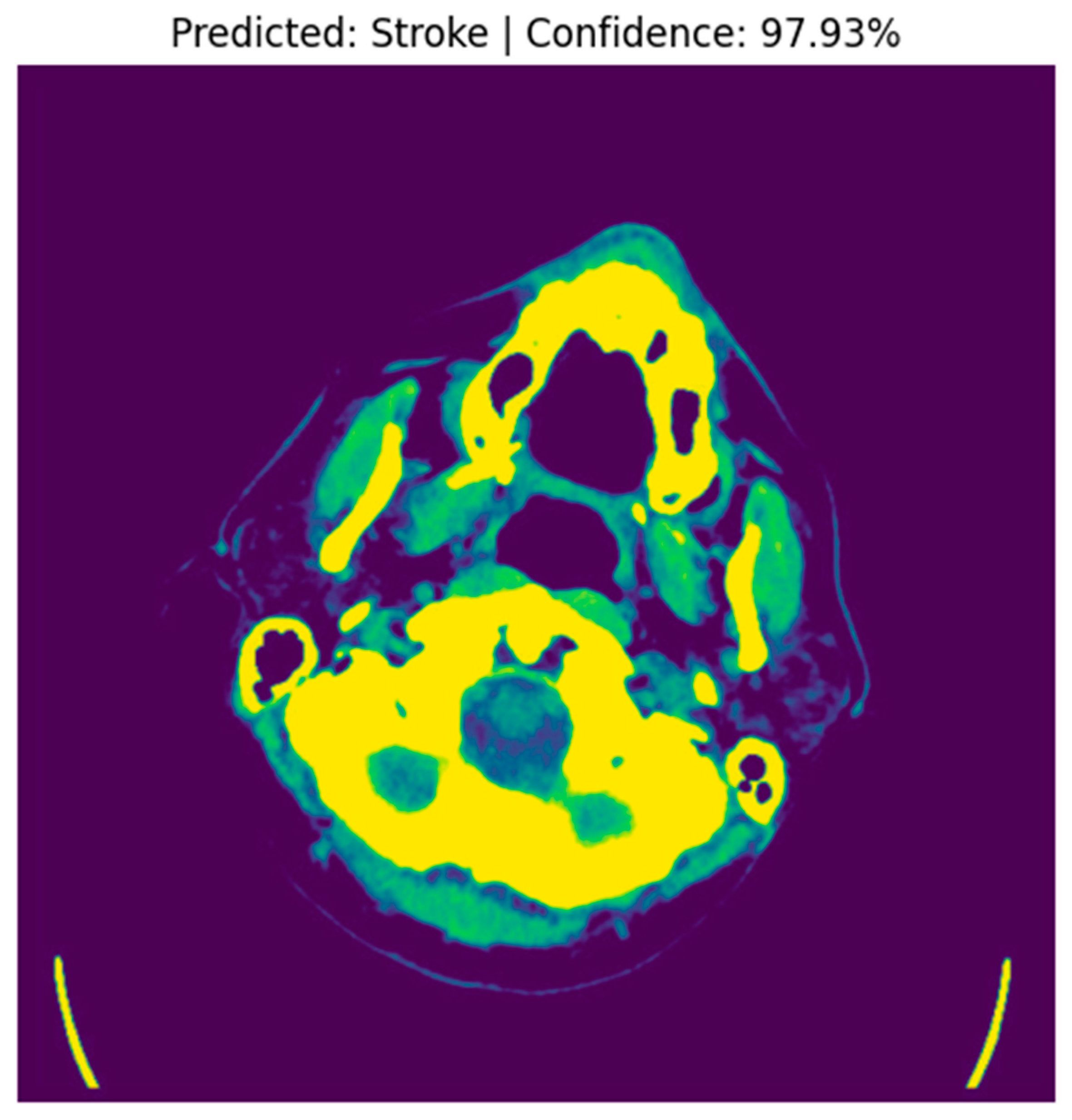
4.4. Stroke Prediction Visualization
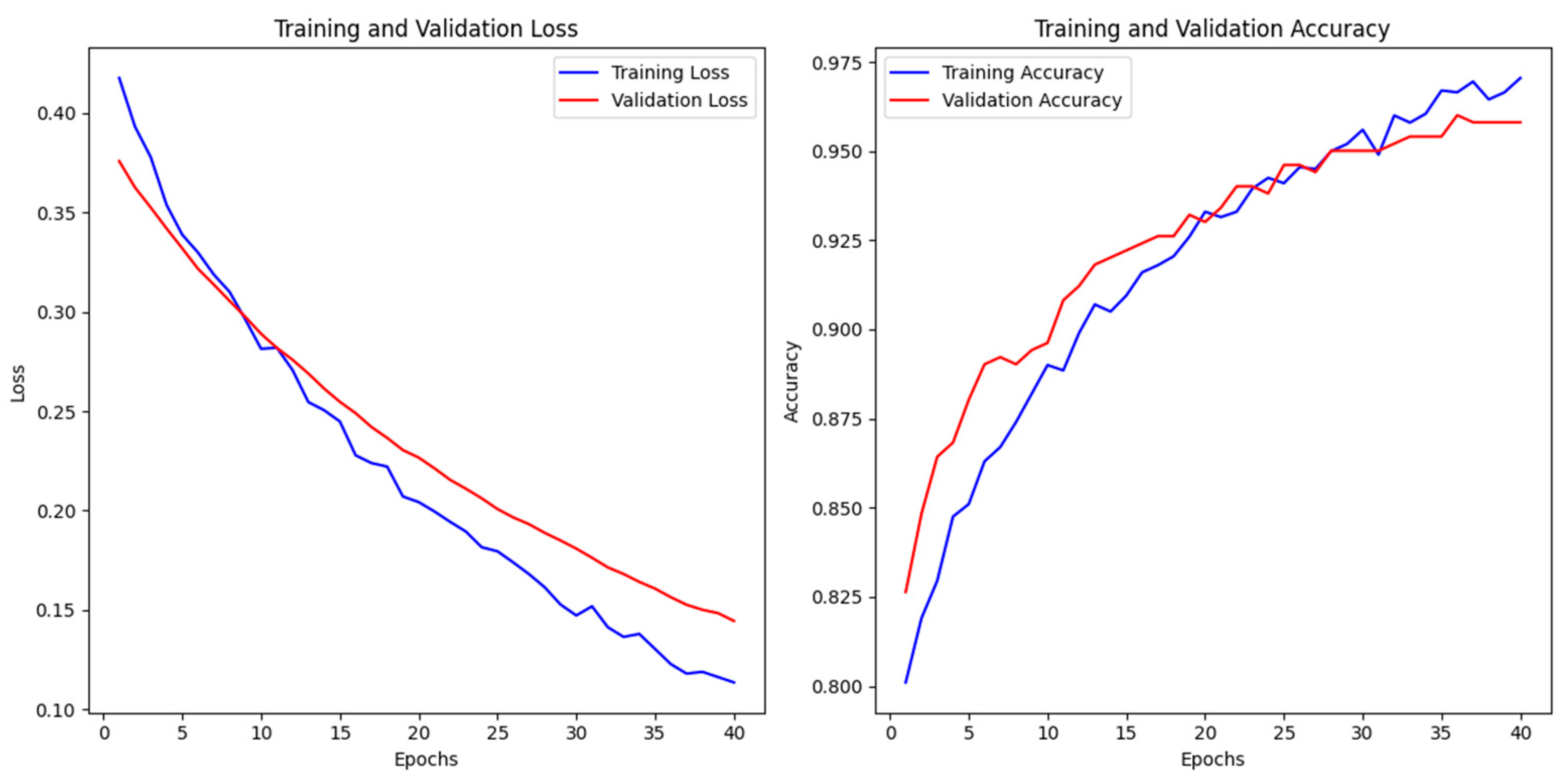
4.5. Model Performance and Convergence
4.5.1. Training Dynamics and Generalization
- Loss Behavior: The loss curves exhibit a steady decline, suggesting that the model converged effectively without abrupt fluctuations or divergence.
- Accuracy Improvement: A continuous increase in accuracy values throughout training highlights the model’s capacity to learn complex patterns while preserving generalization.
4.5.2. Comparison with Baseline Models
4.6. Interpretability Analysis
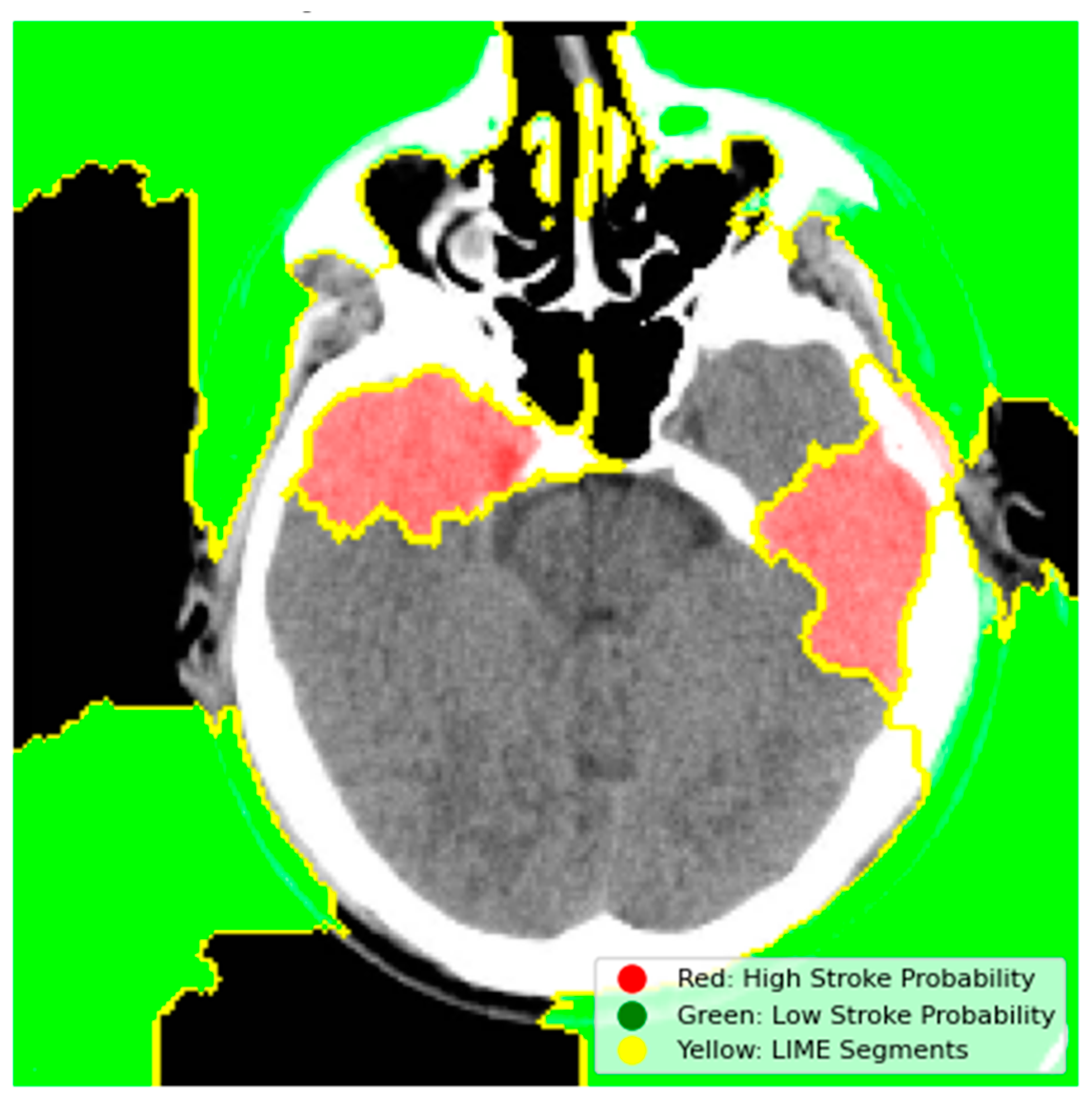
4.6.1. Model Explainability Using LIME
- Red Regions (High Stroke Probability): These areas, highlighted in red, represent regions where the model detected features strongly associated with stroke, such as hyperdense hemorrhagic lesions or ischemic hypoperfusion. The red regions in the left hemisphere, for instance, correspond to the hyperdense clot, a key indicator of a hemorrhagic stroke.
- Green Regions (Low Stroke Probability): Green areas indicate regions with minimal influence on stroke prediction, typically healthy brain tissue or non-stroke-related anatomy.
- Yellow Outlines (LIME Segments): The image is divided into superpixels marked by yellow boundaries. LIME perturbs these segments to assess their impact on the model’s prediction. By masking and observing the changes in the prediction, LIME identifies the critical regions that drive the model’s decision-making process.
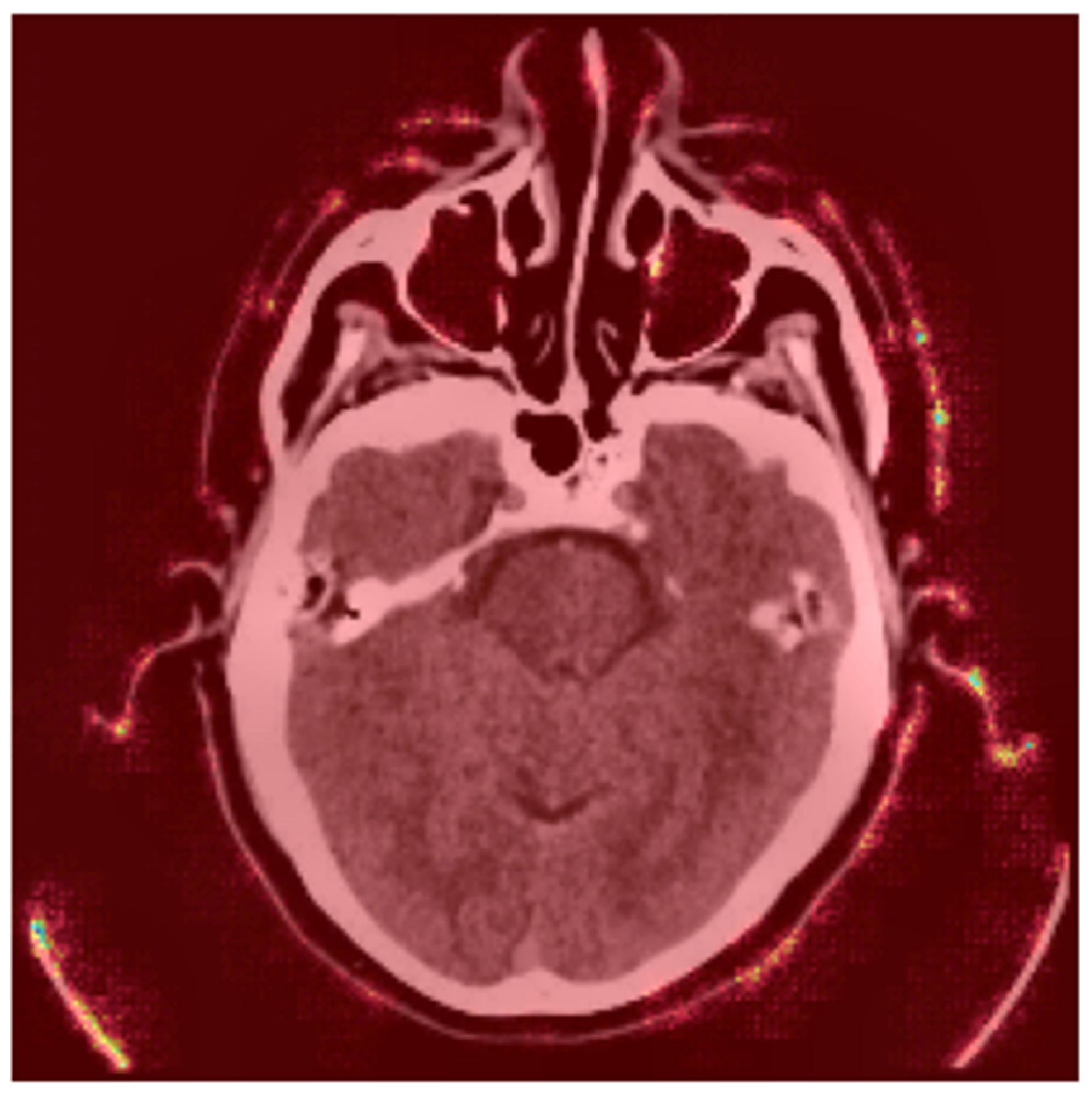
4.6.2. Occlusion Sensitivity Mapping
- Bright Yellow/Red Areas (High Occlusion Impact): These regions indicate that occluding them significantly reduces the model’s prediction probability. For example, the hyperdense clot in the left hemisphere (red) is critical for the model’s decision, as its occlusion leads to a substantial drop in the predicted stroke probability. This aligns with clinical expectations, as hyperdense regions are indicative of hemorrhagic strokes.
- Blue/Purple Areas (Low Occlusion Impact): These regions have minimal influence on the model’s prediction. For instance, the background or non-brain tissue areas (blue) do not affect the stroke classification when occluded, confirming that the model focuses on anatomically relevant regions [24].
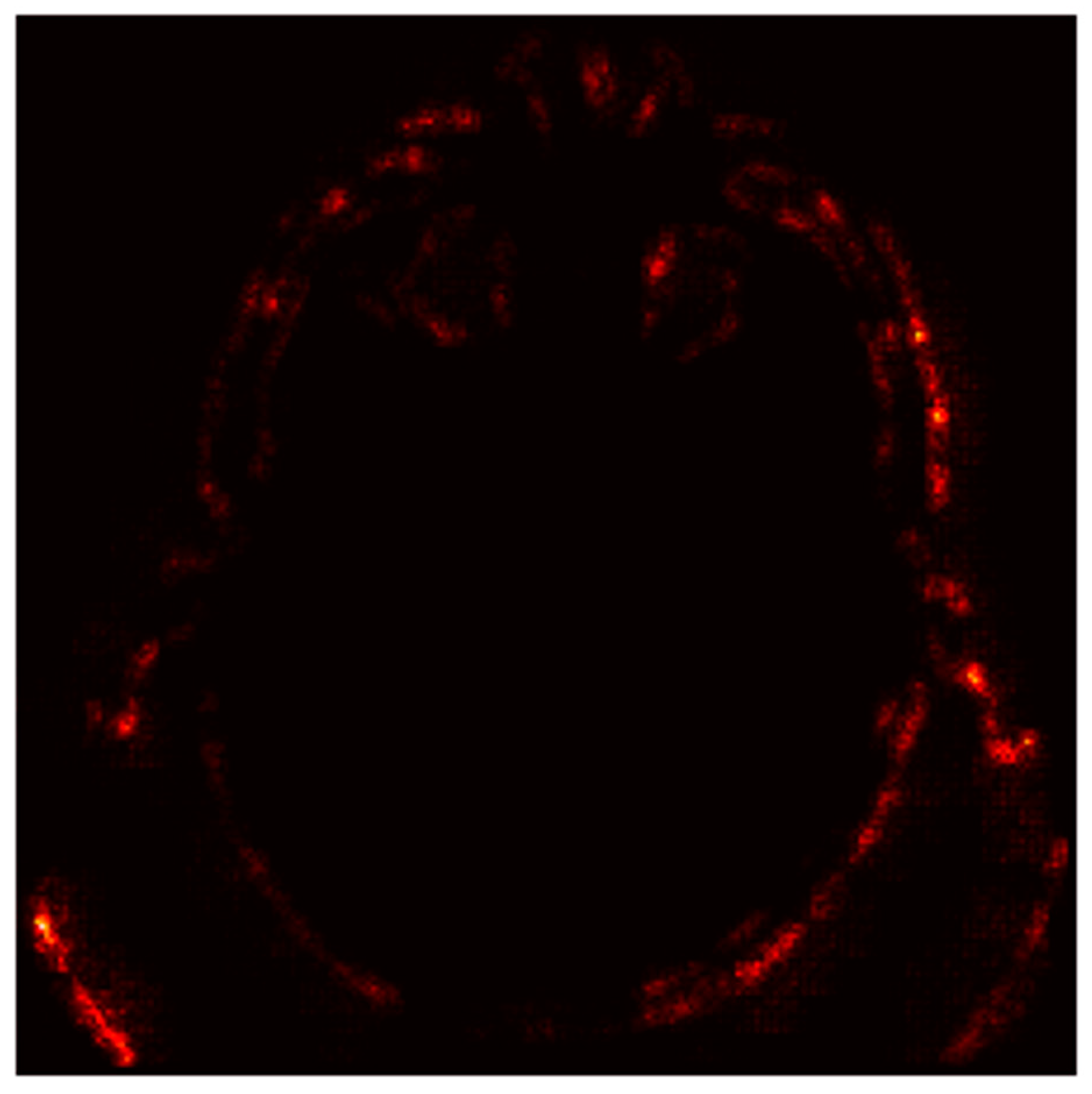
4.6.3. Gradient-Based Saliency Maps
- Red Areas: These regions, such as the hyperdense clot in the left hemisphere, are critical for the “Stroke” prediction. The model assigns high importance to these areas, aligning with clinical expectations that hyperdense regions indicate hemorrhagic strokes.
- Green/Blue Areas: These regions have minimal impact on the prediction, indicating that the model focuses on specific anatomical features rather than the entire image.
- Bright Spots (High Gradients): These regions correspond to areas where small changes in pixel values significantly alter the model’s output. For instance, the hyperdense clot (bright spots) is highlighted as a critical region for the “Stroke” prediction.
- Dark Regions (Low Gradients): These areas, such as the background or non-stroke-related anatomy, have little to no impact on the prediction, confirming the model’s focus on stroke-prone regions.
4.7. Computational Complexity Analysis
4.8. External Dataset Performance
- Variability in slice thickness, contrast settings, and reconstruction algorithms across imaging centers may introduce domain shifts, reducing model robustness. For instance, hyperdense stroke regions in high-contrast scans from one institution might appear less distinct in low-contrast scans from another.
- The external dataset likely includes underrepresented stroke subtypes (e.g., lacunar infarcts, early ischemic changes) that were insufficiently represented in the training data. Lacunar strokes, characterized by small lesion sizes (<15 mm), may evade detection due to the model’s focus on larger, hyperacute lesions.
- Differences in patient demographics (e.g., age and comorbidities like cerebral atrophy) between the training and external datasets could skew feature relevance. Older patients with brain atrophy, for example, may exhibit altered tissue contrast, confounding stroke detection.
5. Discussion
5.1. Performance Evaluation
5.2. Role of Data Preprocessing and Augmentation
5.3. Hyperparameter Optimization
5.4. Interpretability and Clinical Applicability
5.5. Limitations and Future Work
- Domain Adaptation Techniques
- o
- Adversarial Training: Implement domain-adversarial neural networks (DANNs) to minimize distribution gaps between institutional datasets.
- o
- Style Transfer: Use CycleGAN to harmonize imaging styles (e.g., contrast, noise levels) across centers while preserving anatomical features.
- o
- Batch Normalization: Integrate instance normalization layers to reduce sensitivity to protocol-specific intensity variations.
- Metadata Integration: Incorporate scanner metadata (e.g., manufacturer, kVp, slice thickness) as auxiliary inputs during training to improve adaptability to protocol differences.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mainali, S.; Darsie, M.E.; Smetana, K.S. Machine Learning in Action: Stroke Diagnosis and Outcome Prediction. Front. Neurol. 2021, 12, 734345. [Google Scholar] [CrossRef] [PubMed]
- Bathla, G.; Ajmera, P.; Mehta, P.M.; Benson, J.C.; Derdeyn, C.P.; Lanzino, G.; Agarwal, A.; Brinjikji, W. Advances in Acute Ischemic Stroke Treatment: Current Status and Future Directions. Am. J. Neuroradiol. AJNR 2023, 44, 750–758. [Google Scholar] [CrossRef] [PubMed]
- Zhao, X.; Wang, L.; Zhang, Y.; Han, X.; Deveci, M.; Parmar, M. A review of convolutional neural networks in computer vision. Artif. Intell. Rev. 2024, 57, 99. [Google Scholar] [CrossRef]
- Altamirano-Gomez, G.; Gershenson, C. Quaternion Convolutional Neural Networks: Current Advances and Future Directions. Adv. Appl. Clifford Algebras 2024, 34, 42. [Google Scholar] [CrossRef]
- Abedi, V.; Avula, V.; Chaudhary, D.; Shahjouei, S.; Khan, A.; Griessenauer, C.J.; Li, J.; Zand, R. Prediction of Long-Term Stroke Recurrence Using Machine Learning Models. J. Clin. Med. 2021, 10, 1286. [Google Scholar] [CrossRef]
- Kim, J.; Olaiya, M.T.; De Silva, D.A.; Norrving, B.; Bosch, J.; De Sousa, D.A.; Christensen, H.K.; Ranta, A.; Donnan, G.A.; Feigin, V.; et al. Global stroke statistics 2023: Availability of reperfusion services around the world. Int. J. Stroke 2024, 19, 253–270. [Google Scholar] [CrossRef]
- Selamat, S.N.S.; Che Me, R.; Ahmad Ainuddin, H.; Salim, M.S.F.; Ramli, H.R.; Romli, M.H. The Application of Technological Intervention for Stroke Rehabilitation in Southeast Asia: A Scoping Review with Stakeholders Consultation. Front. Public Health 2022, 9, 783565. [Google Scholar] [CrossRef]
- Babutain, K.; Hussain, M.; Aboalsamh, H.; Al-Hameed, M. Deep Learning-enabled Detection of Acute Ischemic Stroke using Brain Computed Tomography Images. Int. J. Adv. Comput. Sci. Appl. 2021, 12, 52. [Google Scholar] [CrossRef]
- Barman, A.; Inam, M.E.; Lee, S.; Savitz, S.; Sheth, S.; Giancardo, L. Determining Ischemic Stroke From CT-Angiography Imaging Using Symmetry-Sensitive Convolutional Networks. In Proceedings of the 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), Venice, Italy, 8–11 April 2019; pp. 1873–1877. [Google Scholar] [CrossRef]
- Wu, G.; Chen, X.; Lin, J.; Wang, Y.; Yu, J. Identification of invisible ischemic stroke in noncontrast CT based on novel two-stage convolutional neural network model. Med. Phys. 2021, 48, 1262–1275. [Google Scholar] [CrossRef]
- Yalçin, S. Hybrid Convolutional Neural Network Method for Robust Brain Stroke Diagnosis and Segmentation. Balk. J. Electr. Comput. Eng. 2022, 10, 410–418. [Google Scholar] [CrossRef]
- Tahyudin, I.; Prabuwono, A.S.; Dianingrum, M.; Pandega, D.M.; Winarto, E.; Nazwan; Rozak, R.’A.; Lestari, P.; Tikaningsih, A. ResNet-CBAM in Medical Imaging: A High-Accuracy Tool for Stroke Detection from CT Scans. In Proceedings of the 8th International Conference on Information Technology, Information Systems and Electrical Engineering (ICITISEE), Yogyakarta, Indonesia, 29–30 August 2024; pp. 551–556. [Google Scholar] [CrossRef]
- Ostmeier, S.; Axelrod, B.; Verhaaren, B.F.J.; Christensen, S.; Mahammedi, A.; Liu, Y.; Pulli, B.; Li, L.; Zaharchuk, G.; Heit, J.J. Non-inferiority of deep learning ischemic stroke segmentation on non-contrast CT within 16-hours compared to expert neuroradiologists. Sci. Rep. 2023, 13, 16153–16159. [Google Scholar] [CrossRef] [PubMed]
- Ostojic, D.; Lalousis, P.A.; Donohoe, G.; Morris, D.W. The challenges of using machine learning models in psychiatric research and clinical practice. Eur. Neuropsychopharmacol. 2024, 88, 53–65. [Google Scholar] [CrossRef]
- Xiao, D.; Zhu, F.; Jiang, J.; Niu, X. Leveraging natural cognitive systems in conjunction with ResNet50-BiGRU model and attention mechanism for enhanced medical image analysis and sports injury prediction. Front. Neurosci. 2023, 17, 1273931. [Google Scholar] [CrossRef]
- Rahman, A.; Chowdhury, M.E.H.; Ibne Wadud, M.S.; Sarmun, R.; Mushtak, A.; Zoghoul, S.B.; Al-Hashimi, I. Deep learning-driven segmentation of ischemic stroke lesions using multi-channel MRI. Biomed. Signal Process. Control 2025, 105, 107676. [Google Scholar] [CrossRef]
- Fehr, J.; Citro, B.; Malpani, R.; Lippert, C.; Madai, V.I. A trustworthy AI reality-check: The lack of transparency of artificial intelligence products in healthcare. Front. Digit. Health 2024, 6, 1267290. [Google Scholar] [CrossRef]
- Hua, D.; Petrina, N.; Young, N.; Cho, J.; Poon, S.K. Understanding the factors influencing acceptability of AI in medical imaging domains among healthcare professionals: A scoping review. Artif. Intell. Med. 2024, 147, 102698. [Google Scholar] [CrossRef] [PubMed]
- Saifullah, S.; Drezewski, R. Enhanced Medical Image Segmentation using CNN based on Histogram Equalization. In Proceedings of the 2nd International Conference on Applied Artificial Intelligence and Computing (ICAAIC), Salem, India, 4–6 May 2023; pp. 121–126. [Google Scholar] [CrossRef]
- Disci, R.; Gurcan, F.; Soylu, A. Advanced Brain Tumor Classification in MR Images Using Transfer Learning and Pre-Trained Deep CNN Models. Cancers 2025, 17, 121. [Google Scholar] [CrossRef]
- Dewage, K.A.K.W.; Hasan, R.; Rehman, B.; Mahmood, S. Enhancing Brain Tumor Detection Through Custom Convolutional Neural Networks and Interpretability-Driven Analysis. Information 2024, 15, 653. [Google Scholar] [CrossRef]
- Mahmood, S.; Hasan, R.; Hussain, S.; Adhikari, R. An Interpretable and Generalizable Machine Learning Model for Predicting Asthma Outcomes: Integrating AutoML and Explainable AI Techniques. World 2025, 6, 15. [Google Scholar] [CrossRef]
- Aminu, M.; Ahmad, N.A.; Mohd Noor, M.H. COVID-19 detection via deep neural network and occlusion sensitivity maps. Alex. Eng. J. 2021, 60, 4829–4855. [Google Scholar] [CrossRef]
- Afshar, P.; Hashembeiki, S.; Khani, P.; Fatemizadeh, E.; Rohban, M.H. IBO: Inpainting-Based Occlusion to Enhance Explainable Artificial Intelligence Evaluation in Histopathology. arXiv 2024, arXiv:2408.16395. [Google Scholar] [CrossRef]
- Szczepankiewicz, K.; Popowicz, A.; Charkiewicz, K.; Nałęcz-Charkiewicz, K.; Szczepankiewicz, M.; Lasota, S.; Zawistowski, P.; Radlak, K. Ground truth based comparison of saliency maps algorithms. Sci. Rep. 2023, 13, 16887. [Google Scholar] [CrossRef] [PubMed]
- Daidone, M.; Ferrantelli, S.; Tuttolomondo, A. Machine learning applications in stroke medicine: Advancements, challenges, and future prospectives. Neural Regen. Res. 2024, 19, 769–773. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Architecture | Dataset Size | Accuracy | Key Contribution |
|---|---|---|---|---|
| [8] | ResNet50 | 130+ | 87.20% (slice) | Pre-trained models for slice classification and tissue segmentation. |
| [9] | Symmetry-sensitive CNN | 217 | 90.1% | Novel model leveraging hemisphere symmetry for stroke detection. |
| Study | Architecture | Dataset Size | Accuracy | Key Contribution |
|---|---|---|---|---|
| [10] | Two-stage CNN (U-Net + ResNet) | 277 | 85.71–91.89% | Cascaded structure combining global and local information for stroke detection. |
| [11] | Hybrid CNN (C-Net + INet) | 6650 | 99.54% | Combining C-Net and INet architectures for improved accuracy. |
| Study | Architecture Modification | Dataset Size | Accuracy | Key Contribution |
|---|---|---|---|---|
| [12] | ResNet-CBAM | 2501 | 95% | Incorporating CBAM for improved feature attention in stroke detection. |
| [13] | 3D CNN (nnUNet) | 232 | 0.46–0.47 (Dice) | Optimized model for ischemic core segmentation comparable to expert radiologists. |
| Study | Multi-Center Validation | Control Group | Key Contribution |
|---|---|---|---|
| [10] | Yes | Yes | Multi-center experiments demonstrating robustness across different datasets. |
| [13] | Yes | Yes | Non-inferiority of DL model compared to expert radiologists in segmentation. |
| Metric | Value |
|---|---|
| Accuracy | 97.2% |
| Precision | 96% |
| Recall | 96% |
| F1-Score | 96% |
| AUC-ROC | 0.98 |
| Fold | Validation Accuracy |
|---|---|
| Fold 1 | 80.24% |
| Fold 2 | 80.60% |
| Fold 3 | 78.80% |
| Fold 4 | 79.79% |
| Fold 5 | 76.99% |
| Mean ± SD | 79.29 ± 1.2% |
| Epoch | Training Loss | Validation Loss | Training Accuracy (%) | Validation Accuracy (%) |
|---|---|---|---|---|
| 0 | 0.4 | 0.38 | 80 | 85 |
| 5 | 0.3 | 0.35 | 85 | 87.5 |
| 10 | 0.25 | 0.3 | 90 | 90 |
| 15 | 0.2 | 0.25 | 92.5 | 92.5 |
| 20 | 0.18 | 0.22 | 94 | 93 |
| 25 | 0.16 | 0.2 | 95 | 94 |
| 30 | 0.14 | 0.18 | 96 | 95 |
| 35 | 0.12 | 0.16 | 96.5 | 95.5 |
| 40 | 0.1 | 0.15 | 97.05 | 95.81 |
| Model | Test Accuracy | Test Loss | Precision (0) | Precision (1) | Recall (0) | Recall (1) | F1-Score (0) | F1-Score (1) | Macro Avg Precision | Macro Avg Recall | Macro Avg F1-Score | Weighted Avg Precision | Weighted Avg Recall | Weighted Avg F1-Score |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Fine-Tuned | 97.05% | 0.1136 | 99% | 93% | 96% | 96% | 96% | 96% | 95% | 96% | 96% | 96% | 96% | 96% |
| Xception | 95.62% | 0.1032 | 99% | 90% | 94% | 99% | 96% | 94% | 95% | 96% | 95% | 96% | 96% | 96% |
| ResNet50 | 94.02% | 0.2084 | 97% | 90% | 93% | 96% | 95% | 93% | 93% | 94% | 94% | 94% | 94% | 94% |
| AlexNet | 45.42% | 1.1414 | 66% | 43% | 13% | 90% | 22% | 58% | 54% | 52% | 40% | 56% | 45% | 37% |
| VGG16 | 93.63% | 0.1378 | 94% | 93% | 97% | 86% | 95% | 89% | 93% | 91% | 92% | 94% | 94% | 94% |
| Model | Total Parameters | Trainable Parameters | Non-Trainable Parameters | Optimizer Parameters | Memory Usage (MB) |
|---|---|---|---|---|---|
| Xception | 20,994,729 | 20,940,201 | 54,528 | - | 80.09 |
| ResNet50 | 23,720,961 | 23,667,841 | 53,120 | - | 90.49 |
| AlexNet | 58,290,945 | 58,288,193 | 2752 | - | 222.36 |
| VGG16 | 21,170,497 | 6,455,809 | 14,714,688 | - | 80.76 |
| Our Model | 20,130,565 | 6,291,841 | 1,255,040 | 12,583,684 | 76.79 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abdi, H.; Sattar, M.U.; Hasan, R.; Dattana, V.; Mahmood, S. Stroke Detection in Brain CT Images Using Convolutional Neural Networks: Model Development, Optimization and Interpretability. Information 2025, 16, 345. https://doi.org/10.3390/info16050345
Abdi H, Sattar MU, Hasan R, Dattana V, Mahmood S. Stroke Detection in Brain CT Images Using Convolutional Neural Networks: Model Development, Optimization and Interpretability. Information. 2025; 16(5):345. https://doi.org/10.3390/info16050345
Chicago/Turabian StyleAbdi, Hassan, Mian Usman Sattar, Raza Hasan, Vishal Dattana, and Salman Mahmood. 2025. "Stroke Detection in Brain CT Images Using Convolutional Neural Networks: Model Development, Optimization and Interpretability" Information 16, no. 5: 345. https://doi.org/10.3390/info16050345
APA StyleAbdi, H., Sattar, M. U., Hasan, R., Dattana, V., & Mahmood, S. (2025). Stroke Detection in Brain CT Images Using Convolutional Neural Networks: Model Development, Optimization and Interpretability. Information, 16(5), 345. https://doi.org/10.3390/info16050345