1. Introduction
Gen-AI tools built on large language models (LLMs), led by ChatGPT, have rapidly emerged over the last couple of years [
1]. These tools present both opportunities and challenges for the entire academic community, including students and teachers. For students, the main opportunities are improving their ability to write reports of high quality, and becoming more efficient when undertaking writing tasks. The challenge is to ensure that students develop their writing capabilities and not just rely on a tool. Students need to ensure that the writing reflects their own voices. A secondary challenge is using Gen-AI resources ethically.
For teachers, the challenge is to develop new ways of teaching while preserving academic integrity. Teachers need to be aware of the capabilities of Gen-AI tools and learn to create assignments that develop the capabilities of students. There have been some initial methods for recognizing when writing is from a Gen-AI tool, such as [
2], but no definitive method exists for determining whether or not a student’s work submitted for an assignment involved writing by a Gen-AI tool. Teachers need to be able to advise students on how to use Gen-AI tools effectively. All stakeholders including students, teachers and educational institutions need to ensure that the use of Gen-AI tools is transparent and governed by clear and reasonable policies. In general, academics should teach communication skills as well as discipline-specific skills. Students need to learn research methods and writing.
If used well, Gen-AI tools can help increase the quality of students’ work, and improve the efficiency of assessments. Students will be able to complete more complex tasks in shorter time. If used poorly, Gen-AI tools can lead to an explosion of mediocrity and loss of skills for students [
3]. Many papers have discussed the strengths and limitations of ChatGPT and other Gen-AI tools. Examples are [
1,
2,
4]. In this paper, we advocate learning how to use such systems to improve student performance and learning.
The primary objective of this paper is to help international students with academic writing, though we believe that the guidance that can be derived from using Gen-AI tools concerning the nuance of expressions can also be valuable for native English speaking students. We use the term international student to denote students whose native language is not English. Sometimes such students are called non-native English speaking students or ESL students, for English as a Second Language. For simplicity, we use the term international students throughout the paper.
Writing is a key communication skill needed by students who are embarking on academic study and/or tackling university life. It is also important for professional careers [
5]. Speaking is another essential communication skill but discussing it is beyond the scope of this paper. We believe that Gen-AI tools offer valuable assistance for helping international students with writing tasks, because they can quickly generate first drafts and help students overcome the intimidating Blank Page Syndrome [
6]. These drafts can provide a starting point or a skeleton for their work.
Students may benefit from using Gen-AI tools for the following reasons. International students in academic settings often face significant challenges (especially in project-based subjects) in both comprehending and expressing ideas that are complex [
7]. Before the advent of generative AI models like ChatGPT, international students relied on tools such as Google Translate and DeepL to help them navigate complex academic content. Because people feel more comfortable with processing information in their native language, a common approach is translating reading materials or assignment specifications into their native language, resulting in all the thinking and written work being carried out in their native language. The finished work will be translated back into English for submission. However, traditional translation tools have limitations, such as they typically perform mechanical translations solely based on dictionary definitions, failing to account for abstract concepts or contextual nuances [
8]. This may result in students struggling not only to understand assignment requirements but also to articulate their own ideas clearly and accurately.
With generative AI tools, international students now have access to a more dynamic and efficient way of engaging with academic content. Instead of relying solely on traditional translation tools, students can use generative AI to first summarise complex texts, helping them grasp the core ideas more quickly. Through interactive conversations with an AI tool, students can have confusions clarified, such as contextual ambiguities or highly specialised academic terminology and vocabulary, which can be particularly challenging for international students. As a result, students have an opportunity to save time on Googling and asking questions on forums unfriendly to beginners, resulting in a more in-depth understanding in academic materials. In this way, the Gen-AI tool acts not only as a means for summarising information but also as a sophisticated search engine, capable of offering tailored explanations and context-driven insights.
Unlike traditional search engines, generative AI models potentially offer ongoing, context-aware conversations, retaining the context of previous interactions to create a more coherent and iterative learning experience. This is particularly valuable when students encounter complex, technical topics, as the AI can provide detailed explanations and simplify difficult concepts. Essentially, generative AI functions as a personalised, interactive learning assistant, helping students bridge the gap between understanding abstract academic material and expressing their ideas effectively. This not only significantly reduces the time spent searching for answers online where relevant information may not always be immediately available or may require waiting for others to respond. The tools also deliver customised, real-time solutions to questions.
This paper is organised as follows. The next section discusses our approach to helping international students find their voice. We then describe the exercises we developed.
Section 4 contains a discussion where we look at previous work on helping international students with writing. We include recommendations for students on how to use Gen-AI tools more effectively. The final section concludes the paper.
2. Method
There are three underlying research questions in this paper that are interconnected. What are the actual capabilities of Gen-AI tools, setting aside the common hype around them? This is especially relevant given the variety of Gen-AI tools. With the mixture of free and paid tools, there may be financial factors determining what Gen-AI tools students should use. How can educators guide students to use Gen-AI tools most effectively? How can educators and students share insights about using Gen-AI tools? Overall, this paper aims to explore effective strategies for helping international students utilise current AI technologies to improve their academic writing while maintaining their unique voice and adhering to academic integrity standards.
This paper takes a non-standard methodological approach to answer the research questions. We primarily take a qualitative approach. A series of writing exercises were undertaken by students. Their experiences were reported and then analysed for insight. No thematic analysis was undertaken as the goal was to share insights rather than analyse the reported experiences.
There was also a degree of opportunism involved. Performing one writing exercise suggested a new one to perform. And comparisons were hard to make as the tools kept evolving. Discussing how to use Gen-AI tools is a moving target as there are continual efforts to improve the quality of output generated by Gen-AI tools. Indeed, Gen-AI tools have improved significantly since we started our research in the second half of 2024. We believe the insights gleaned are valuable more broadly. It is a matter for future research to repeat the exercises we developed with a wider cohort of students. When we started, we were unsure what we would discover. Because of what we learned, we persisted and describe our results as a series of insights as laid out in the Discussion section.
We addressed the research questions by conducting a series of writing exercises using Gen-AI tools for specific writing tasks. The results were discussed and analysed each week over a period of four months. Initial meetings were weekly but became more sporadic after the teaching semester finished. Specific insights are shared in
Section 3.
More discussion of the validity of our approach is given in
Section 4.
We repeated two of the exercises with a cohort of Chinese computer science students in their final year of an undergraduate computing degree who had a study tour hosted by the first author. The insights were useful in designing exercises for the visiting students. The insights from the writing exercises for the two cohorts of students were remarkably similar. Due to the nature of the experiences, it is appropriate to report on the results qualitatively. It would be possible to perform a quantitative study with a precise question, but performing such a study is beyond the scope of the current paper. We believe it is important to share qualitative insights in the fast-moving landscape of using Gen-AI tools.
Let us explain the background of this paper. The rationale for the project is rooted in the academic experience of the first author. He has read numerous reports over the past thirty years from international students. It is often a struggle to understand what is being said. More importantly, from a teaching perspective, it is difficult to determine whether a student understands a concept but lacks the ability to express it in English, or misunderstands it. This is known from many studies on teaching English to international students over many years [
7,
9,
10,
11]. As grammar checkers such as Grammarly have improved, some of English expression difficulties can be mitigated. Students should be expected to write effectively. Indeed, good communication skills are a requirement for most professional jobs.
The emergence of Gen-AI tools has changed the experience of creating and assessing reports. ChatGPT was the first Gen-AI tool used extensively for writing reports. Other tools such as Claude and Llama 3 quickly followed, which can also be used for writing tasks. It makes sense for international students to use such tools to write reports. However, it creates a new problem for teachers to navigate, namely, whether the student has independently completed the work.
In an undergraduate capstone project subject (IT Project, University of Melbourne. Available at:
https://handbook.unimelb.edu.au/2023/subjects/comp30022, accessed on 1 March 2025) taught in 2023, the first author created an exercise where students needed to reflect on their project experience. They were explicitly allowed to use Gen-AI tools as long as they were transparent about their use. He read over 300 reflection reports, most of which were from non-native English speakers. Reading the reports was insightful and the experience directly influenced this paper.
Overall, the reports written with the assistance of Gen-AI tools were easier and quicker to read. However, there were two major problems that were connected. One was that the reports largely sounded the same. It was hard to distill students’ unique experiences, a phenomenon being increasingly understood. Prakhar Mehrotra’s article “ChatGPT and the Magnet of Mediocrity” [
3] discusses how AI-generated content, such as by ChatGPT, tends to be derivative and mediocre. Mehrotra illustrates this by stating that while ChatGPT can generate competent blog posts or articles, it lacks the originality and creative flair that human writers can bring to their work, such as in the creation of new narrative structures or interesting ideas. The second problem concerns the authenticity of the experience being reported. There were at least ten reports that compared the experience of leading a software team to being a conductor of an orchestra. The gist of the comparison was that it was necessary to get diverse instruments/people to work together and coordinate them effectively. Clearly, ten people did not come up with the analogy independently. Furthermore, why was the analogy even appropriate in the first place? Did the students who used this analogy even have experience being in an orchestra? Could the reader relate to such an experience? On reflection, it was not an appropriate analogy. It did not reflect the student’s voice. There were also several analogies comparing leading a software team to being the captain of a boat on the seas. The same issue of authenticity exists.
In reading the reflections, the first author wanted to hear students’ voices, which were largely getting lost in the use of Gen-AI tools. He proposed a research project topic on how students can find their voice when writing reflective reports using Gen-AI tools. The second and third authors volunteered to undertake the project and conducted the initial exercises, the results of which are described here. The fourth author joined the project for later stages of analysis. Consequently, the exercises are skewed towards computing students, but we believe the insights are more generally applicable.
The second, third and fourth authors are international IT students studying computing at the University of Melbourne who wish to improve both their writing skills and the use of Gen-AI tools. Communication can be an issue for international students [
12]. While the focus is on exercises which are meaningful for IT students due to the experience and expertise of the authors, we believe that the insights shared are more broadly applicable.
3. Results
As the project began, we undertook weekly writing exercises. An exact list of the exercises is available from the authors. Weekly meetings were very efficient and beneficial. Discussion of the outcomes was insightful for all the authors. These insights are shared in this section. As mentioned in
Section 2, our study methodology is non-standard, and there is room for a more systematic and controlled study on a larger cohort of students in the future. However, in our opinion, it nevertheless is valuable to report our current results, as Gen-AI tools continue to evolve.
Our results are presented as a series of analyses of writing exercises. We mention to which research question the writing exercise pertains. Each exercise description states what was produced in the writing exercise, followed by insights gained by the authors while discussing the writing. The research team effectively followed the metacognitive strategies of monitoring and evaluation [
13,
14] as discussed further in
Section 4.
3.1. Exercise 1: Writing Personal Reflections with AI Assistance
The first exercise we undertook set the scene. A simplified reflective report was proposed. Students were asked to write 100 words about what they had learned during their undergraduate studies. The participants were asked to take three different approaches to write the simplified reflection.
Independent writing: Participants independently authored their responses without external assistance.
AI-assisted writing: Participants used ChatGPT to polish self-written responses in approach 1.
AI-generated content: Participants relied on ChatGPT to generate the responses entirely based on prompts provided.
This exercise pertains to the following two research questions: How can educators guide students to use Gen-AI tools most effectively? Second, how can educators and students share insights about using Gen-AI tools?
The exercise was conducted by two of the authors and some of their friends. Twelve students overall undertook the exercise. They were given a week to respond. ChatGPT was used for the exercise due to its high popularity in the student community. It is a mainstream LLM with the most paid monthly active users on the market, as of 2024.
The three versions of the simplified reflective report of each of the participants were discussed at our second weekly meeting. The student authors gave a qualitative summary of the changes introduced by ChatGPT. The consensus was that the ChatGPT version sounded more “formal” than the initial response. The sense of formality was due to both choice of words and sentence structure. All of the changes that were made by ChatGPT were discussed, considering whether they accurately represented the intention of the author. The consensus was that ChatGPT often struggled to capture subtle semantic nuances, resulting in deviations from the original ideas it aimed to express. All authors agreed it was helpful to discuss all of this together and this discussion was a valuable learning exercise.
An interesting example of nuance that was extensively discussed was triggered by the following response (approach 1): “The first thing that I learned is to be brave”. After being refined (approach 2) by ChatGPT, it became the following: “First, I’ve learned the importance of bravery”. The revised version, while grammatically correct, altered the original tone. The phrase “to be brave” is more personal and direct, whereas the refined version sounded more abstract and detached, which is less suitable for a personal reflection. Interestingly, this distinction would not have been initially apparent to the student authors.
Another issue we identified was a tendency towards over-boasting. For example, when students used modest and humble expressions such as acquired the skill or capable of doing, the Gen-AI tools often replaced these terms with more exaggerated ones such as comprehensively or swiftly extract vital information. The AI-generated responses would describe outcomes in a more confident and affirmative manner, which often misrepresented the student’s original intention. Specific examples include the following:
Know replaced by Master.
Use replaced by Leverage.
More replaced by Significantly.
Are prepared replaced by Well prepared.
Capable of doing replaced by Have a good command of.
Have developed replaced by Gain a deep understanding of.
Have learned replaced by Have gained proficiency.
This overconfidence in language use can distort students’ intended meaning and tone, jeopardising students’ academic integrity in academic writing, where modesty and accuracy are priorities.
We were able to extract more significant findings from the refined responses (approach 3). Participants may “lose their voice” after responses are refined. Firstly, international students may have a limited ability to determine the semantic and contextual appropriateness of word choices in English, especially when thesauruses are suggested by LLMs. For instance, a response mentioned the participant’s ability to utilise some academic resources provided by the university to improve their academic performance. In the refined response, the word utilise was replaced with leverage. It may not be challenging for a native English speaker to determine the inappropriateness of using leverage based on years of experience of using English. However, many international students may fail to realise implications of this word choice. Additionally, the fact that Gen-AI tools tend to write in an overconfident tone and choose more advanced words (regardless of appropriateness) may create an illusion for international students that Gen-AI tools are professional in writing, yielding excessive trust in their abilities.
Interestingly, as we were writing this paper, the grammar checker provided by the LaTeX editor we used, Overleaf, became a focus of attention. We discussed its suggestions and realised that we did not want to automatically accept its suggested changes because the changes could change the tone. It was not solely an issue of correcting grammar.
An interesting case in point was the suggestion to change the phrase “excel in” to “excel at”. This prompted an interesting discussion and Internet search as to which was the correct usage. There was no clear answer, and the international students were exposed to a subtlety in the English language that would not have been apparent if the change had been automatically accepted. Indeed, discussions about points of language were consistently insightful and do not come about in standard feedback on assignments.
Another change concerned whether to use collected responses or responses collected. To explain the subtle difference between these phrases: “Collected responses” functions as an adjective phrase where “collected” modifies responses, suggesting responses that have been gathered or assembled. “Responses collected” is a past tense verb phrase indicating the action of collecting responses. It often appears in constructions like “the number of responses collected” or “responses collected during the survey”. Both are grammatically correct but serve slightly different functions in a sentence. “Collected responses were analysed” is appropriate. The responses collected showed interesting trends. The above explanation was edited using Claude 3.5 Sonnet, which then asked “Would you like me to provide some example sentences to illustrate the difference in usage?”.
Here is another interesting little subtlety. For the posting “Definitely something <person1> and <person2> need to refer to”, the grammar checker suggested adding a comma after “Definitely”: “Definitely, something <person1> and <person2> need to refer to”. The “corrected” version has the tone changed, as “Definitely” in the former sentence described the extent of certainty, while “Definitely” in the latter sentence was simply an exclamation. However, it would be hard for an international student not to accept the change as they may not appreciate the subtle distinction.
We conducted a similar exercise six months later with a group of Chinese students visiting on a study tour. The students were asked to write 100 words about their impressions of Melbourne, and then to refine their writing with a Gen-AI tool. We compared their initial efforts to the refined efforts. While grammar was improved and spelling mistakes eliminated, the Gen-AI tools changed the language, making it more forceful and adding impressions that the students may not have had.
All the students benefited from the discussion and seeing the consistent over-boastful writing produced by the Gen-AI tools. In addition, the students noticed the use of words with which they were unfamiliar such as “breathtaking” which appeared in multiple refinements. One notable refinement was the addition of the word “mesmerising,” a word which none of the students knew the meaning of. It was explained that it is not good practice to use such words.
3.2. Exercise 2: Comparing Gen-AI Tools
The landscape of Gen-AI tools is diverse, with many options such as ChatGPT, Claude, Meta AI, etc., each possessing unique strengths and limitations. A list of Gen-AI tools and the corresponding LLMs used in this research is given in
Appendix A.
Heartened by the discussions stemming from analysing the responses to the first exercise, we were encouraged to undertake more exercises. One of the respondents in the first exercise had used a different Gen-AI tool. The modifications were different. We were all curious as to how effective the various Gen-AI tools were, and the research question we were considering was as follows: “What are the capabilities of Gen-AI tools?” Detailed information about the LLMs we used is provided in
Table A1.
Based on the responses of the survey in exercise 1, the second exercise sought to explore the qualities (including credibility, semantic consistency and answer integrity) of generated texts from various Gen-AI tools. The question for which a response was requested was as follows: “Why do I need to understand and learn artificial intelligence, and why is artificial intelligence important?” Participants in the exercise were asked to write a 200-word response to this question.
We experimented with multiple Gen-AI tools. We received responses from the question and then refined the responses using three different LLMs: ChatGPT-4, Claude 3.5 Sonnet, and Llama 3 with the same prompt: “refine it”. A complete set of the responses are available on request.
By comparing the generated results from different LLMs with same prompt, we found that performance and output quality could be significantly affected by technical limitations, such as token limits and the maximum context length, also referred to as the context window. For instance, ChatGPT-4’s maximum token limit is 4096 tokens, while Claude 3.5’s is 8132 tokens and Llama 3 even supports 128k tokens. The token limit difference can significantly impact the performance when dealing with larger contexts. ChatGPT-4 tended to omit instructions or generate truncated responses when longer prompts were provided, whereas Claude 3.5 and Llama 3 128k handled the same prompts better because of their larger token capacities. In our exercises, Claude 3.5 Sonnet stands out for its ability to conduct literature reviews and follow complex instructions due to its strong contextual handling capabilities. Claude 3.5’s token limit and context length far exceed those of GPT-4, allowing it to process and output long texts without losing critical information. This became particularly evident during long-text testing, where GPT-4 occasionally struggled to fully read and process extended inputs, whereas Claude 3.5 was able to handle the entire context effectively.
ChatGPT-4 is often preferred for its balanced performance across a wide range of academic tasks, benefiting from its fine-tuned contextual awareness and general-purpose adaptability. During Ian’s internship, he experimented with connecting these three models to an Agent for executing complex instruction sets. The results showed that GPT-4 outperformed the other models in terms of precision in executing specific instructions, making it the most suitable choice for tasks requiring exact follow-through.
Meanwhile, Llama 3, though newer, is optimised for token efficiency, allowing it to handle longer-form writing tasks with less computational overhead. According to a study by Novita AI, Llama 3 70B can be up to 50 times cheaper and 10 times faster than GPT-4 when used through cloud API providers [
15]. This makes it particularly advantageous for tasks that require processing large amounts of data or generating long-form content without excessive computational costs. These differences in performance, context-sensitivity and task specialisation make it more complex for students to choose the right model for their specific writing needs. Effectively utilising each model’s strengths while compensating for its limitations further complicates the process of matching the right tool to the task at hand.
During the discussion, the first author shared a response he had received from ChatGPT 3.5 to the following prompt: “Write a 100-word description of the fire at my father’s paint factory when I was 9”.
The response was the following: “When you were nine, a blazing inferno engulfed your father’s paint factory, painting the sky with hues of fiery orange and billowing smoke. Flames danced voraciously, consuming the structure, while the acrid scent of burning chemicals filled the air. Panic gripped the scene as firefighters battled tirelessly, their efforts highlighted by flickering red and blue lights. Amidst the chaos, memories of your father’s hard work and dedication mingled with fear for his safety. Despite the devastation, the community rallied, offering support and solidarity. The aftermath left an indelible mark, a testament to resilience and the fragility of human endeavour”.
The report is well written, but it is not an account of the fire. How could it be, as it has no details of the actual fire? ChatGPT generated an essay about a (fictional) memory, rather than describing a memory. They are not the same thing.
Interestingly, we entered the same prompt to Claude and received a more suitable response. Claude responded that it could not give a memory about the fire. However, it could give a 100-word description about a fire, which was a much better and useful response.
The discussions surrounding this exercise suggest that when students refine their prompts using Gen-AI tools, they should carefully consider the trade-offs between tool capacity and task requirements, especially when engaging in long-form or detailed writing. This led to the next exercise.
3.3. Exercise 3: Prompt Tuning Insights
In the third exercise, we built on the results of the second exercise and conducted further experiments. This time, we compared different prompt structures and tested multiple Gen-AI tools to assess how well they could handle personal writing tasks. Again, we were addressing the research question of how students should learn how to use the Gen-AI tools.
Our motivation stemmed from observing in previous exercises that the level of detail in prompts influenced the balance between creativity and standardisation in AI-generated responses. The Gen-AI tools used in this exercise remained the same, but the prompts ranged from simple instructions to more detailed ones that included personal background, writing context, and even bullet points. The three prompt structures we used were as follows:
Minimal context: The original question plus “refine it”.
Moderately detailed context: The original question plus “refine it and check grammar while keeping the same tone”.
Highly detailed context: The original question plus “refine it as a paragraph, academic writing, as an undergraduate student, major in CS, University of Melbourne, 200-words, answering ‘Why do I need to understand and learn artificial intelligence, and why is artificial intelligence important?’”.
We conducted more tests using multiple LLMs (ChatGPT-4o, Claude 3.5 Sonnet, Llama 3 70B) and tested each of the three prompts under controlled conditions. There were ten participants in this experiment, largely consisting of students majoring in computer science, ensuring a consistent background to allow for meaningful comparisons. For each prompt, the AI-generated responses were collected, grouped by prompt type, and then analysed for the following:
Relevance: The degree to which the response addresses the prompt.
Diversity: The linguistic, structural and content variation between responses.
Tone Preservation: The degree to which the response retains the distinctive tone and style implied by the original question.
By comparing the responses generated from different prompt styles and Gen-AI tools, we identified several key issues:
Our findings indicate that while detailed prompts can improve relevance and specificity, they also increase the risk of generating uniform and predictable responses. Comprehensively, the more detailed the prompt, the more uniform and standardised the responses became. For example, when the prompt explicitly mentioned the student’s background as “a CS student at the University of Melbourne”, ChatGPT-4o tended to produce highly similar responses across different participants.
Here are two notable sets of similar generated paragraphs:
- Set 1
paragraph 1
As an undergraduate student majoring in Computer Science at the University of Melbourne, understanding and learning artificial intelligence (AI) is crucial for both my academic and professional development.
paragraph 2
As an undergraduate student majoring in Computer Science at the University of Melbourne, I recognise the critical importance of understanding and learning artificial intelligence (AI).
- Set 2
paragraph 3
Understanding and learning artificial intelligence (AI) is crucial for several reasons, particularly from the perspective of an undergraduate student majoring in Computer Science at the University of Melbourne.
paragraph 4
Understanding and learning artificial intelligence (AI) is essential for me as an undergraduate student majoring in Computer Science at the University of Melbourne, as it aligns with both my personal interests and future career aspirations.
In the two sets of examples above, it is obvious that when given enough detailed information as a prompt, ChatGPT-4o is more likely to translate or paraphrase the prompt than to totally refine it based on the information provided by the prompt. Thus, with the same prompt, ChatGPT-4o will likely produce very similar generated content.
Similarly, if detailed bullet points were provided in the prompt, the AI would incorporate all of them into the response, often without much variation. This raises concerns in contexts like a classroom where many students may use similar prompts.
In such cases, responses could become repetitive. For instance, if most students identify as computer science students, ChatGPT might consistently generate phrases such as “version control systems” or other highly specific technical terms, which would lead to homogeneity in responses. This is problematic, as the goal of academic writing is to encourage original thoughts and varied perspectives.
We found that simpler prompts such as “refine it” or “check its grammar and keep the same tone” were preferred when students were writing personal reflections. These instructions allowed them to maintain control over their writing while enhancing their English fluency without losing their voice.
3.4. Exercise 4: Summarisation Ability of LLMs
We used ChatGPT-4o and Claude 3.5 Sonnet to test Gen-AI tools’ performance in different scenarios where international students face challenges. We observed that Gen-AI tools perform better on summarising content in very specific contexts, rather than generating content for open-ended questions in general contexts.
To begin with, we simulated a scenario that can challenge many international students—reading and understanding long assignment specifications. We collected many undergraduate-level computer science assignment specifications from the University of Melbourne, cleansed the text via removing irrelevant content such as headers and footers, and supplied them to both Gen-AI tools as the context with a prompt “Summarise it”. As a result, they successfully extracted the main points from the specifications in a straightforward and accurate manner. Minor errors did exist, such as ChatGPT-4o made an assumption that the total mark of an assignment was 100, while the specifications never explicitly stated so. We then gave a more challenging scenario: “I am an international student struggling to understand this specs, the deadline is approaching, and I don’t even know where to start”. ChatGPT-4o and Claude 3.5 Sonnet were both capable of accurately identifying the implementation priorities and extracting the grading emphases, and gave proper advice on earning the most essential marks in a time-sensitive manner. The advice was articulated concisely in bullet points, with subheadings such as “Immediate steps to take” and “Technical must-haves”, minimising the effort required to navigate through the information. At the end, both Gen-AI tools offered further assistance by asking “Let me know if you need help with specific coding tasks!” or “Would you like specific guidance on where to begin with either the UML design or the code implementation?”.
We also tested Gen-AI tools’ ability to assist with GRE (Graduate Record Examinations) questions, such as questions requiring the extraction of main ideas from given reading materials, which are typically several passages. These passages consist of substantial information with an incredible number of details, and are written in a clear structure. Using such reading materials to assess Gen-AI tools’ summarisation capabilities conveniently provides an accurate way to identify and uncover potential issues, such as oversimplification, confusion of subjects, incorrect chronological order, etc. For testing, we randomly selected three long passages from GRE reading comprehension questions which appeared in actual exams. Both ChatGPT-o1 and Claude 3.5 Sonnet showed tendencies towards simple restatements, where the AI merely paraphrased the original text rather than gathering and synthesising information scattered around. Additionally, ChatGPT-o1 occasionally presented information “made out of thin air”, generating details that were not present in the original passage. For example, for the following sentence extracted from an actual exam question:
Original: Recently, an unusually high number of dolphins have been found dead from infectious diseases, and most of these had abnormally high tissue concentrations of certain compounds that, even in low concentrations, reduce dolphins’ resistance to infection. The only source of these compounds in the dolphins’ environment is boat paint. Therefore, since dolphins rid their bodies of the compounds rapidly once exposure ceases, their mortality rate should decline rapidly if such boat paints are banned.
ChatGPT-o1’s summary: A recent surge in dolphin deaths from infectious diseases has been linked to elevated concentrations of infection-weakening compounds in their tissues (Made out of thin air: The original article did not mention the recent increase in concentrations of toxic compounds). These chemicals come exclusively from boat paint. Because dolphins quickly eliminate these substances once exposure stops, prohibiting the use of such paints should rapidly lower their death rates.
Meanwhile, Claude 3.5 Sonnet sometimes failed to provide a comprehensive summary, omitting essential information. Overall, these Gen-AI tools are not yet fully reliable as reading assistants, and we still need to manually verify the accuracy via referring to the original text.
In contrast, both ChatGPT-4o and Claude 3.5 Sonnet performed worse on open-ended questions with broad contexts. For instance, we attempted to seek career advice such as “What would a career as a data science engineer be like”. The responses were relatively too general and they simply repeated information that could be easily found on the internet. An analogy could be the following: if the previous “a struggling student coping with the approaching deadline” situation was provided, instead of advising on which specific tasks to prioritise and implementation steps to follow, suggestions such as “calm down and meditate yourself”, “make sure that you read the assignment specs thoroughly” and “reviewing the lecture content and the learning materials would help” were given. In the real world, if an open-ended question with a broad context is asked, the person being asked may seek more background information to better understand the intention and provide a more tailored response. However, both ChatGPT-4o and Claude 3.5 Sonnet provided general responses without asking any follow-up questions for clarification.
To verify the integrity and reliability of LLMs, we collected more than 20 assignment specifications from 11 computer science subjects at the University of Melbourne, converted them into the Markdown format with redundant text (such as headers and page numbers) cleansed, summarised these specifications using LLMs, and evaluated and compared the results using metrics such as Semantic Similarity, Bert Score, ROUGE-1 (n-grams), ROUGE-2, and ROUGE-L Scores, adopting and modifying the metrics used by a group of researchers to study [
16]. Semantic Similarity measures the semantic closeness between the generated and original text, indicating the extent of meaning preservation. BERT Score evaluates the contextual and semantic alignment using BERT embeddings, providing measurements in precision, recall, and F1 scores. ROUGE-1 and ROUGE-2 calculate the overlap of unigrams and bigrams, reflecting lexical coverage and local coherence. ROUGE-L assesses global structure similarity based on the LCS (longest common subsequence). These metrics allow for a multidimensional analysis of the summary’s quality, combining lexical and semantic perspectives.
We used ChatGPT-4o and Claude 3.5 Sonnet as test objects and employed 4 different prompts to test the summary output of the LLMs:
“Summarise this”.
“Summarise in detail”.
“I am a student and my assignment is due soon, but I don’t have time to read everything thoroughly. Please summarise this and extract the key points.”
“I am a student and I am struggling with figuring out where to start, while the deadline is approaching. Could you give me some hints on what to do?”
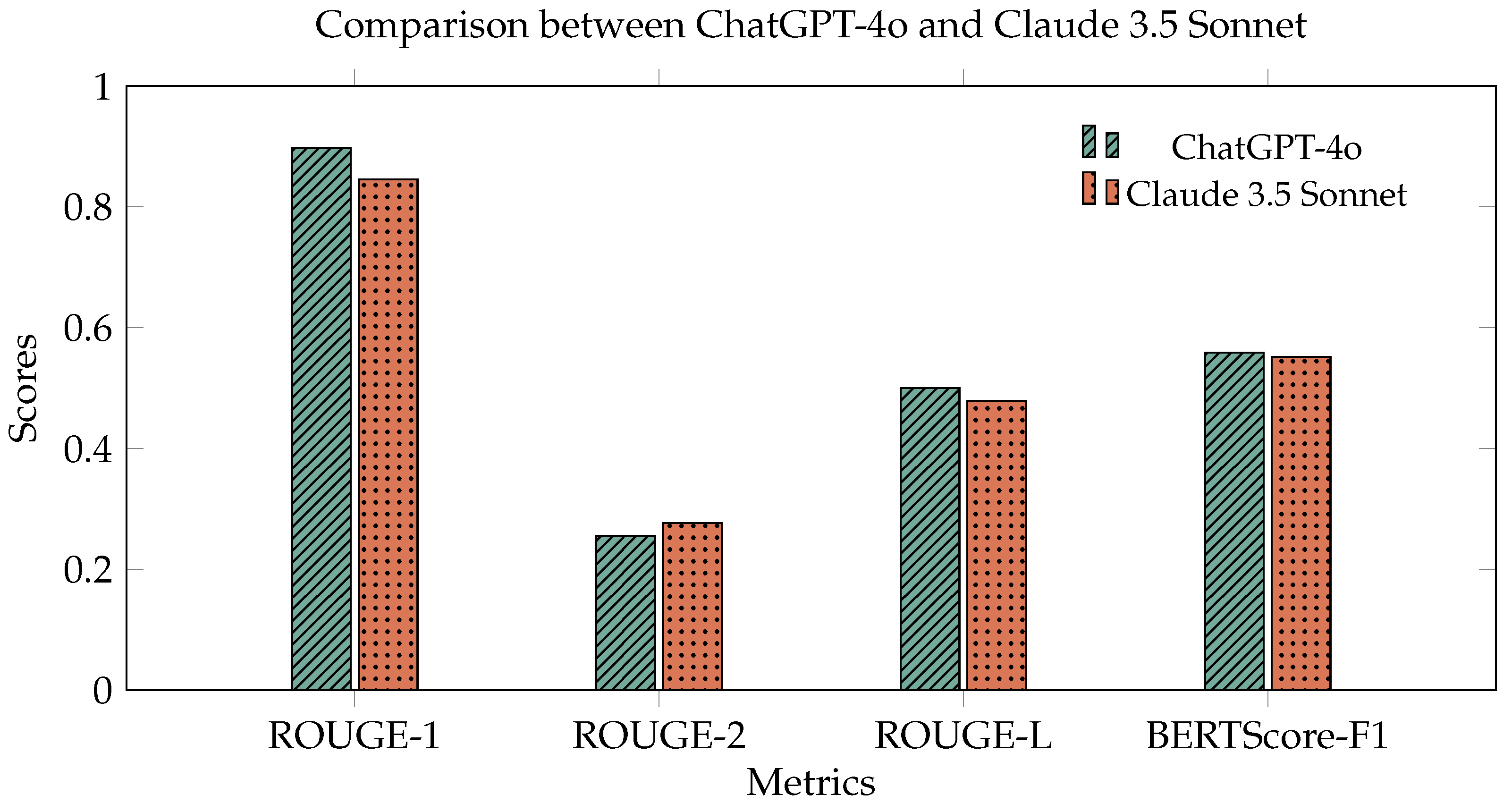
We used BLEU and ROUGE as metrics to evaluate the summary accuracy and compare different models and prompt variations. The results are given in
Table 1, and visualised in
Figure 1.
According to the experimental data, ChatGPT-4o and Claude 3.5 Sonnet performed almost equally in summarisation, especially in keyword extraction and semantic information retention (as indicated by high ROUGE-1 and BERTScore metrics), and were capable of general tasks. However, their ability to retain local coherence and global structure, indicated by ROUGE-2 and ROUGE-L scores, needs improvement, especially when dealing with complex logical relationships or highly structured content. In general, LLMs are suitable for quickly generating summaries, but for summarisation tasks that require high precision and complex semantics, we cannot rely solely on LLMs.
We also presented a summarisation exercise to the visiting Chinese students who repeated the first exercise. The students were asked to summarise three articles and compare them with summaries that Gen-AI generated. We have not performed a detailed analysis. However, the quality of the GEN-AI generated summaries varied. For technical articles, sometimes the summaries were effectively just jargon. Also, student-driven summaries varied markedly in length, depending on the context of what was being summarised. The Gen-AI summaries were more standard. We intend to carry out more work on summaries in future work.
To further understand summarisation ability, we asked ChatGPT-4o and Claude 3.5 Sonnet to summarise an article by the first author [
17]. Both LLMs produced coherent summaries. The accuracy of the summaries and their coherence were a surprise to the first author.
4. Discussion
The overall objective of our research is to provide strategies for students to use Gen-AI tools for a variety of writing tasks, while maintaining academic standards, ensuring academic integrity, and preserving students’ unique voices. The exercises described in this work show potential for improving the use of Gen-AI tools by international students for academic writing. We now discuss how this work fits in a broader context.
4.2. Ethical Considerations
There are certainly ethical considerations when it comes to using Gen-AI tools. Universities worldwide are struggling with the questions of how to introduce Gen-AI and what restrictions to implement. Our research has taken the pragmatic position that students are using these tools, motivating us to give them guidance on how to use these tools better.
There are also concerns about bias in Gen-AI tools, stemming from the material on which they are trained. We are aware of such concerns, but they did not impact this research. Again, we focused on pragmatically giving students guidance on how to use existing tools. Some discussion of ethics and bias arose in our weekly discussion, but it did not significantly impact our reported observations.
Here are some qualitative reflections on ethics. Regarding the issue of bias in generative AI, we are all aware of cultural and linguistic differences, as well as various types of bias caused by imbalance and incompleteness in training datasets, in addition to problems such as plagiarism and fabrication. All AI-generated content involved in our paper has been reviewed manually to ensure that these issues were avoided.
In terms of ethical concerns, our paper clearly states that all use of AI tools should follow the principles of transparency and accountability for the generated content. We understand how to adhere to standards of academic integrity and avoid unethical behaviours that may result from the inappropriate use of AI tools. We recognise that generative AI may reflect cultural, linguistic or racial biases during content generation, largely due to imbalanced training data. For English as Second Language speakers, this could lead to misleading expressions and academic risks. In our paper, we clearly emphasise that AI tools must be used transparently and responsibly in academic contexts, and any usage must be disclosed to avoid academic misconduct due to unauthorised assistance. Furthermore, we remain cautious about the potential risks of plagiarism, fabricated content and fake citations caused by over-reliance on AI, and we stress the importance of applying critical thinking when reviewing AI outputs.
Arpin and Rahmat investigated students’ use of metacognitive writing strategies at their university in Malaysia [
14], and were interested in possible differences in writing strategies by gender. While an interesting and important issue, we did not consider gender in our studies. We believe the insights gleaned about using the tools we reported in the previous section are independent of gender. Investigating gender differences is a topic for further research and is beyond the scope of this paper.
Intellectual Property Ownership is an ethical concern. Considering the fact that international students may face challenges in written expression, we did use large language models during the writing process to polish and optimise the original text of this paper. However, we can ensure that the structure, ideas, viewpoints and analytical process of the paper were entirely developed by the students and the professor, which guarantees the originality of the content and therefore establishes clear intellectual property ownership. In addition, the AI-generated content used in our research was used solely for evaluation and comparative analysis and was not included in the final version of the paper. As such, our work complies with academic institutions’ definitions and requirements regarding intellectual property.






{kind=link}