2. Related Work
The rule-based parser introduced earlier [
6,
7] is designed to extract syntactic and grammatical relationships between words in arbitrary sentences. To achieve this, the parser constructs a highly structured parsing graph. Traditional parsing approaches such as dependency parsing [
8] or constituent parsing [
10] follow the Robinson Axioms [
11] and create tree structures. The Robinson Axioms define the structural properties of such parse trees as follows: (1) these trees possess a single root, typically corresponding to the verb of the main clause; (2) all other words in the sentence are hierarchically dependent on either this root or another word within the tree; (3) each word can have only one direct dependency, ensuring that the tree remains acyclic.
In contrast, our method employs a capsular graph structure and violates these Axioms, for instance, our graphs can have many roots—one for each clause—as described in an earlier paper [
6]. This capsular structure enables the extraction of grammatical relationships between every word pair in a sentence, whereas tree structures in dependency and constituent parsing typically capture relationships only between directly dependent words.
Natural language inherently contains ambiguities, which pose challenges for the syntactic analysis. As demonstrated in a previous publication [
7], common dependency or constituent parsers do not fully address these ambiguities. The parsing solutions generated by these tools rely on statistical methods and neural networks, often providing the most statistically probable interpretation of an ambiguity, which is not necessarily the correct one.
In
Section 3, we detail how the rule-based parser constructs a comprehensive network of word-to-word relationships and stores these relationships in a database. While these word-to-word relationships share similarities with syntactic dependency networks produced by dependency parsers, they differ in several key aspects. For context, we briefly describe syntactic dependency networks and their usage for corpus linguistics. Additionally, we describe the features of texts commonly used to detect AI-generated texts.
2.1. Syntactic Dependency Networks
A syntactic dependency network [
9] represents the syntactic and grammatical relationships between the words within the sentences of a comprehensive corpus. Each sentence in the corpus is analyzed using a parser, typically a dependency parser [
8], which extracts the grammatical relationships between words based on the resulting parse structure. The parse structure for dependency parsing takes the form of a tree constructed in accordance with the Robinson Axioms. For example,
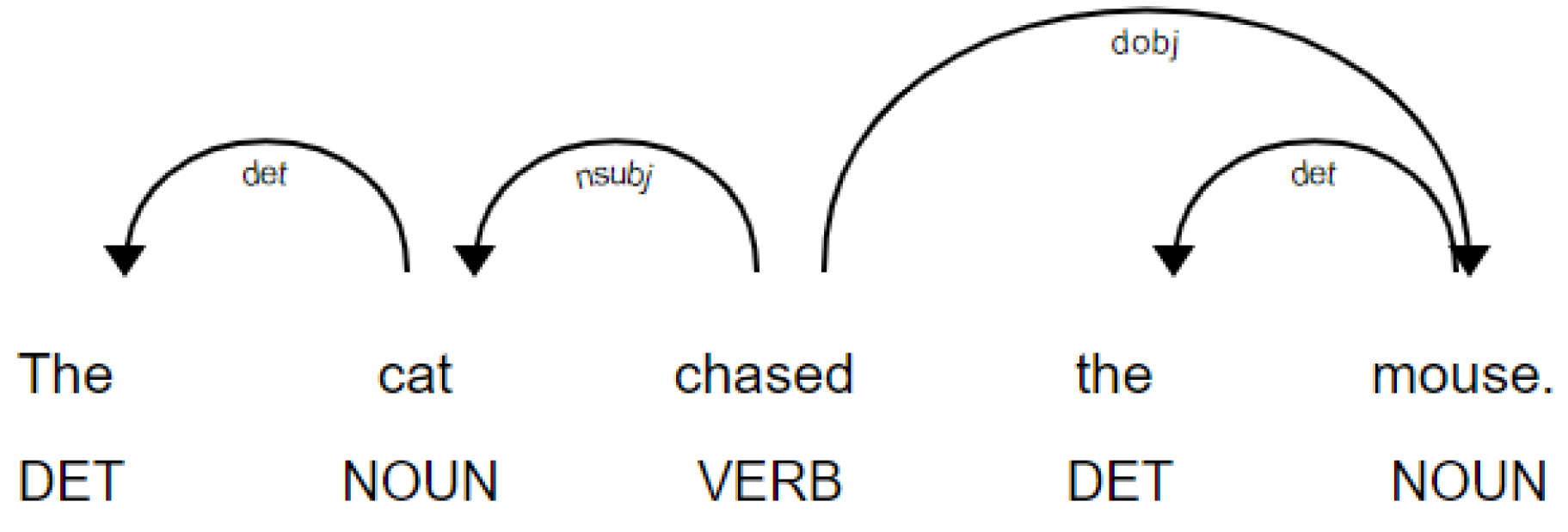
Figure 1 illustrates the dependency parse for the following sentence:
In this parse tree, the verb of the main clause, “chased”, serves as the root, with all other words either directly or indirectly dependent on it. Specifically, the nouns “cat” and “mouse” directly depend on the root, while the determiners “the” depend on their respective nouns. The dependencies are labeled with tags such as “nsubj” (nominal subject), “dobj” (direct object), and “det” (determiner) to indicate the nature of the grammatical relationship between the words. Excluding determiners, which are high-frequency words with limited semantic value, two primary relationships can be extracted from this sentence:
chased - nsubj -> cat;
chased - dobj -> mouse.
Here, “nsubj” refers to “nominal subject”, indicating that “cat” is the subject of the verb “chased”, while “dobj” denotes “the direct object”, indicating that “mouse” is the direct object of the verb. These two relationships, along with similar relationships from other sentences in the corpus, are stored as part of the syntactic dependency network.
In most cases, the same relationship appears multiple times throughout the corpus. Two primary approaches can be employed to address this repetition. First, the relationships can be treated as binary, meaning they are included in the syntactic dependency network if they occur at least once in the corpus. Alternatively, the relationships can be assigned a weight, where the weight reflects the frequency of occurrence of that relationship within the corpus.
Typically, only direct dependencies between words are stored in the database. For instance, in the example sentence above, only the direct dependencies between the verb “chased” and the nouns “cat” and “mouse” are recognized. No relationship is established between the nouns “cat” and “mouse”, even though they are both nouns within the same sentence. However, it is also possible, though less common, to establish indirect relationships between words that do not directly depend on one another. This can be achieved by determining the shortest path between the two words in the parse tree and storing a representation of this path in the database.
3. Methods
In two previous publications [
6,
7], we introduced a novel rule-based method for natural language parsing, which we tailored to the German language. This parser operates solely through deterministic rules, deliberately avoiding statistical methods during the parsing process.
In this study, we utilized our parser to analyze datasets comprising hundreds or thousands of sentences to gain insights into the grammatical characteristics of a given text or corpus. Although our parser operates exclusively on a rule-based approach, statistical data can be extracted from the parsing results of sentence collections. In this paper, we leverage this statistical data to determine the origin of a text or corpus. To ensure that statistical analysis provides reliable results, the corpus must contain a sufficiently large number of sentences (see
Section 4.3), usually several hundred sentences. However, increasing the number of sentences beyond this threshold does not enhance the detection accuracy, as the statistical data reach saturation at approximately three hundred sentences.
Statistical data are generated by examining correlations among words within the parsed sentences. After parsing each sentence, the program constructs pairs of distinct words from the sentence and identifies a grammatical relationship for each pair, which is referred to as a “grammatical bridge”. For a sentence containing N words, this approach yields grammatical bridges (including punctuation), all of which are stored in a database for subsequent analysis.
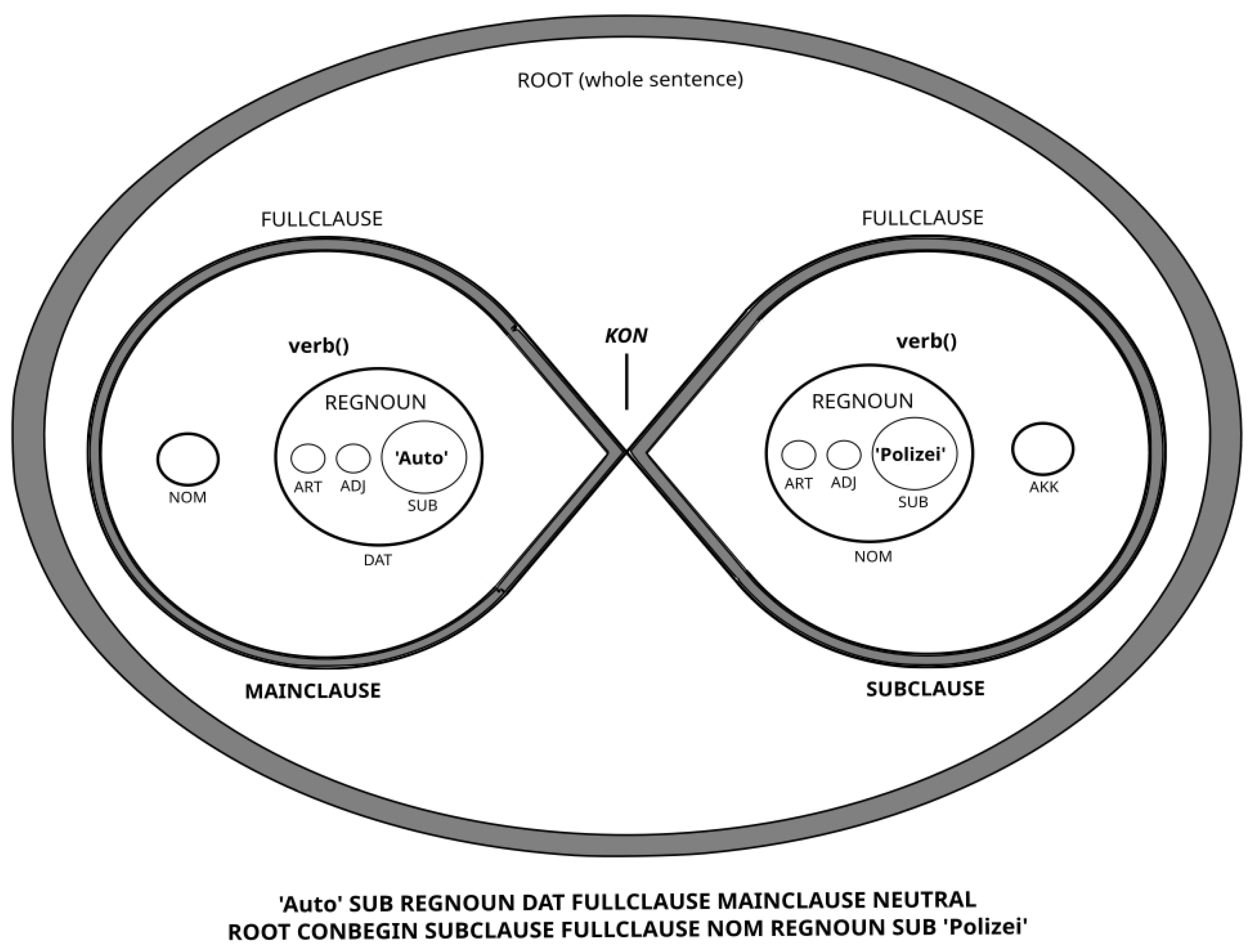
Unlike traditional dependency parsers that generate parse trees, our parser operates using “bubbles”—containers for various linguistic elements, such as words, phrases, or clauses—as detailed in two previous publications [
6,
7]. According to our framework, each linguistic element occurs in exactly one superordinated bubble, enabling the use of this nested bubble structure to identify keywords for the unique grammar bridges.
A grammar bridge is a string that links two words within a sentence. These connected words serve as the endpoints of the string, while intermediate keywords are derived from the nested bubble structure of the sentence. The connection is established by identifying the shortest path between the two words, which traverses several bubbles. The construction of the grammar bridges is described in detail in
Appendix A.
The grammatical bridges identified within a large corpus of sentences constitute a database that bears similarities to a syntactic dependency network produced by a dependency parser (see
Section 2.1). As outlined in the previous publication [
7], our rule-based parser provides grammatically richer information regarding words and their grammatical relationships. For instance, a dependency parser does not determine the grammatical cases of nouns within a sentence. Furthermore, we demonstrated in the previous publication [
7] that while neural parsers resolve ambiguities by selecting the most likely solution, our parser disambiguates these cases explicitly, offering a more precise interpretation.
A notable distinction is that grammatical bridges link every word pair within a sentence, whereas syntactic dependency networks only connect words that are directly dependent on one another. In general, it is possible to find the shortest path between two words within a parse tree generated by a dependency parser, as is done for grammatical bridges. To the authors’ best knowledge, none of the existing methods adequately captures hypothetically longer implicit dependencies spanning multiple words.
3.2. Percentage of Parsed Sentences
The analyses of the text consists of several steps. Prior to parsing, some sentences are filtered out due to factors such as the presence of non-standard characters or grammatical errors, which prevents the parser from successfully analyzing the sentence. In the following, we provide a breakdown of the reasons for non-parsed sentences, noting that the relative proportions of these reasons remain consistent regardless of whether the corpus contains thousands or millions of sentences.
The first filtering criterion pertains to the presence of characters that our parser is currently unable to process. Specifically, 1.0% of the sentences contained unknown characters, while 21.3% included punctuation marks that the parser cannot yet handle. At present, the parser is limited to processing only periods (.) and commas (,), as these punctuation marks are essential for constructing complex sentence structures.
The second filtering criterion concerns the presence of words that are not found in the Morphy lexicon [
19]. Such words are interpreted as proper names, and all instances of these “proper names” that are not capitalized are excluded from further processing. This accounted for 5.2% of all sentences.
The third filtering criterion addresses grammatically incorrect sentences, primarily resulting from errors in sentence tokenization. Some of these errors can be identified before parsing, for instance, in sentences missing a verb. A total of 5.3% of the sentences were filtered out for grammatical incorrectness before parsing.
Following the application of these filtering criteria, 77.2% of the sentences remained available for parsing. Of this subset, the parser successfully processed 54.5%, which are 42.1% of the initial number of sentences. The primary reason for unsuccessful parsing is an “interpretation explosion” caused by an excessive number of proper names within sentences. News articles and Wikipedia entries often contain numerous proper names, which, in the current version of our parser, are handled in a rudimentary manner. Since the parser lacks specific information about these proper names beyond recognizing them as nouns, it assumes every possible grammatical case for them, leading to an exponential increase in interpretations. If the number of possible interpretations exceeds a preselected cutoff value (512 in this study), the parsing process is terminated.
The current study focuses on substantive–substantive relationships to determine the origin of a text by relating substantives with certain cases (see
Section 4.1). However, for most proper names, the case cannot be determined unambiguously, and therefore, a relation between a proper name and another substantive regarding their two cases is ambiguous. This leads to an exclusion of this relationship from the statistics (see
Appendix A.5) because solely biunique relations are incorporated in the analysis. Therefore, texts with few proper names, unlike news or Wikipedia articles, would lead to reliable statistics with less needed sentences because more substantive–substantive relationships can be gained from less sentences.
Due to the parser’s ongoing development, large-scale parsing on the order of millions or billions of sentences on a supercomputer has not yet been conducted. Currently, we let the parser process one million sentences of a news corpus of the Wortschatz Leipzig [
18]—a workload that can be completed in under 12 h on a single multi-core CPU (12th Gen Intel(R) Core(TM) i5-1235U), utilizing all ten cores in parallel.
3.6. The Eight Grammatical Markers
Grammatical bridges have two endpoints, which are the two words that are grammatically connected by the bridge and represented by a string. It is possible to truncate these endpoint words, thereby creating a truncated bridge that connects word classes and highlights the grammatical relationship between them expressed by the intermediate keywords. When applied to a whole corpus, these truncated bridges reveal the grammatical characteristics present within the corpus. The cumulative analysis of all truncated bridges indicates the frequency of specific grammatical bridges, offering a method for distinguishing between different corpora.
Any truncated bridge may serve as a marker for corpus linguistics, but for statistical reliability, we focused exclusively on those that were frequent across all corpora.
Table 1 specifically presents the truncated bridges between two substantives, limiting the analysis to the frequency of substantive connections within the corpora. While other frequently occurring bridges might also reveal significant differences between the corpora, an examination of these is reserved for future research.
The displayed grammatical markers in
Table 1 follow a systematic pattern. The first three bridges (first group) represent connections between pairs of independent (i.e., not enumerated) nominative, accusative, and dative objects. For instance, the sentence
contains exactly one subject “the government”, one direct object “financial support”, and one indirect object “the company”. The parser constructs three grammatical bridges from this sentence, one for each substantive pair. Each of these bridges exemplifies one of the first three markers.
The next two bridges (second group) account for the connections between two independent accusative objects and two independent dative objects, respectively. For instance, the sentence
includes two independent indirect objects: “the researchers” and “for their study”. Among other syntactic relations, the parser links these two dative objects and constructs a bridge between them, serving as an example of the second group of markers.
The final three bridges (third group) capture cases in which nominative, accusative, or dative objects are connected within an enumeration. A corresponding example is the following sentence:
Here, the direct object “the evidence and the witness statements” constitutes an enumeration of substantives. In this case, the parser links the individual elements within the enumeration, forming a bridge that exemplifies the third group of markers.
To demonstrate the number of markers that can be extracted from a corpus, we analyzed the GPT-4o corpus, which comprises 2605 sentences (see
Section 3.1). Prior to parsing, 632 sentences were excluded. Of the remaining 1973 sentences, the parser successfully processed 1062. In total, 7337 truncated, unambiguously determined bridges were identified, neglecting the ambiguous bridges (see
Appendix A.5). Among these, 319 bridges connect two substantives. This study focuses on eight specific bridges within this subset, which are referred to as markers.
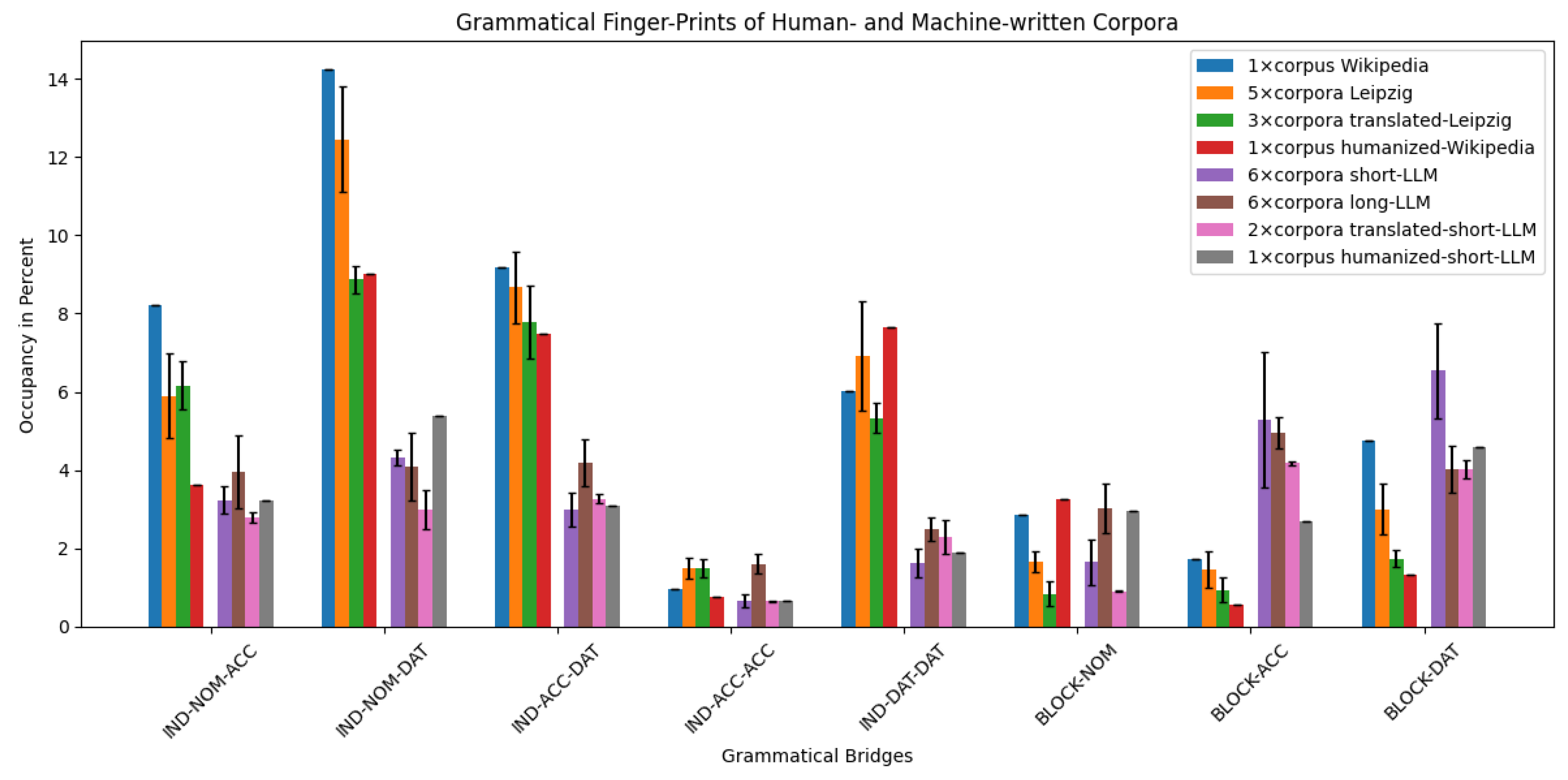
Table 2 presents the occurrences of these eight marker bridges within the 1062 successfully parsed sentences.
Another 311 bridges were found, which connect two substantives; however, the eight markers were the bridges with the most occurrences. To make the occurrences of the markers comparable, we normalized the occurrences by the total number of all occurrences of all 319 substantive bridges. The 319 different substantive bridges include 3222 occurrences in total; therefore, the occurrences in
Table 2 were divided by this number:
5. Discussion
The present study focused on analyzing the grammatical differences between human-written and machine-generated corpora, as well as the effects of translating the corpora to other languages and the effect of humanizing the corpora by special software. The analyses was made using a novel method for parsing natural language sentences we introduced in two previous publications [
6,
7]. This method is entirely rule-based, relying solely on German grammar and avoiding the use of statistical models or neural networks. This approach contrasts with common techniques such as dependency parsing, which relies on statistical models and generates parses for any sequence of words, regardless of whether the sequence is meaningful or not (as we show in [
6]). Conversely, our parser may reject sentences that are grammatically incorrect.
At its current developmental stage, the parser successfully parsed approximately 42.1% of real-world sentences, such as those found in the Wortschatz Leipzig corpus [
18]. This is sufficient to extract the syntactic and semantic properties of entire corpora containing thousands, millions, or even billions of sentences. The parsing results are stored in a database that represents word-to-word relationships. Such databases are typically referred to as syntactic dependency networks (SDNs), which are often constructed using a dependency parser. However, our database offers three key advantages over conventional SDNs:
Disambiguation: To provide a grammatical analyses of the corpora, our parser stores word relationships that are unambiguously determined. Dependency parsers typically resolve ambiguities by selecting the most probable solution, whereas our approach includes even less likely solutions if they can be definitively determined (we show this in [
7]).
Connectivity: While SDNs connect only directly dependent words, our parser establishes connections between every pair of words in a sentence by identifying the shortest path within the parsing structure, which we call here grammatical bridges.
Informational Depth: SDNs provide limited grammatical information. As we demonstrated earlier in [
7], dependency parse trees capture only a fraction of the grammatical structures present in German sentences. For instance, they do not explicitly identify main and subordinate clauses or the grammatical cases of nouns. In contrast, our parser constructs a unique parsing structure that differs fundamentally from conventional parse trees and violates the Robinson Axioms, which underlie such trees. Thus, it determines every grammatical case distinguishable within German grammar, thereby offering a much richer representation of the sentence structure.
In this study, we focused specifically on relationships between substantives, temporarily disregarding other types of relationships. Among the substantive–substantive relationships, we concentrated on the eight most frequently occurring ones, such as the relationships between the sentence subject and the direct or indirect objects. We called them grammatical markers. Using these markers, we could distinguish whether two corpora stem from the same or different origin.
We have analyzed corpora from two distinct origins, human-written and machine-generated, by counting the marker frequencies of substantive–substantive relationships. The human-written corpora were sourced from the Wortschatz Leipzig and Wikipedia, while the machine-written corpora were generated by six different large language models (LLMs) from OpenAI [
1], including the older GPT-3.5 model and the more recent o1-preview model. Our analysis revealed differences in the marker frequencies between human and machine origin texts. Specifically, human-written texts consistently exhibited higher frequencies of nominative–dative, accusative–dative, and dative–dative object pairs, whereas the machine-generated texts showed a greater prevalence of enumerations involving accusative and dative objects. These differences were consistent regardless of the length of the LLM generated texts.
These findings were also consistent when the corpora underwent certain transformations prior to parsing. We investigated whether the specific natural language of the corpus affects the markers, focusing on German, English, and French. Some Wortschatz Leipzig corpora are written in English and French, and we used an LLM to generate descriptions of Wikipedia terms also in these languages. As our parser is designed for German, we translated all foreign-language corpora into German using DeepL [
20], performing sentence-by-sentence translations before parsing. Our findings demonstrated that the original language did not influence the markers, as the relationships between nouns remained consistent across translations.
Additionally, we analyzed the impact of post-processing LLM generated corpora to make them appear more human-like. This AI humanization process involves modifying sentences to make them more emotional or subjective, often in an effort to deceive AI detectors. We have shown that the grammar stayed unchanged during the humanization process. This indicates that AI detectors should concentrate on the grammar used instead of concentrating on subjectivity or emotionality of the texts.
The analysis was constrained by two primary factors, both of which contributed to an increased number of required sentences for determining the origin of texts. First, the parser, in its current state of development, successfully processed approximately 42.1% of German sentences. This parsing rate remained consistent across both human-written and AI-generated texts and was not influenced by sentence complexity. We assume that this does not introduce bias into the analysis, specifically, that the parser does not systematically exclude sentences with distinct grammatical structures.
As demonstrated in
Section 4.3, a minimum of 128 parsed sentences was necessary to obtain statistically reliable markers. Consequently, the original text must contain approximately 300 sentences, which is a number significantly higher than the typical length of most texts. Thus, improving the parsing rate is essential for the practical application of this method in real-world scenarios.
The second limiting factor concerns the removal of incorrect sentence interpretations. Our analysis exclusively considered substantive relationships that are unambiguously determined, meaning all possible interpretations of a given sentence exhibit the same relationship. However, the parser identified three times as many relationships overall, many of which were ambiguous. Eliminating these incorrect interpretations increases the proportion of unambiguous relations, and reducing ambiguity by a factor of three would decrease the required number of sentences to fewer than 50.
For most practical applications, the required number of sentences must be reduced to fewer than 50, as many documents in fields such as education and journalism are shorter than this threshold. In education, for instance, students typically write essays consisting of only a few dozen sentences. By applying our software, educators could analyze these essays to assess whether AI assistance was used, even if the text has been humanized by AI. Similarly, in journalism, an increasing number of news articles are generated by AI without being explicitly labeled as such, potentially compromising the quality and authenticity of information. If an article is sufficiently long, editorial offices and readers could use our method to verify whether it was human-written.
In contrast, documents in science and law are typically extensive, containing a sufficient number of sentences for reliable analysis. However, these fields frequently use foreign words and specialized terminology, which our parser can recognize if such terms are included in the underlying lexicon. The current lexicon, Morphy [
19], may not be comprehensive enough in this regard. Moreover, legal texts often employ specialized sentence structures that may differ from the grammatical patterns observed in both human-written and machine-generated texts. In such cases, the reference corpora for human-written and machine-generated texts should be specifically tailored to legal discourse, and the set of grammatical features used for analysis may need to be adjusted accordingly.
The identification of AI-generated content becomes more challenging when only certain portions of a text are AI-generated. In these cases, we hypothesize that the grammatical statistics of the text would fall between those of purely human-written and purely AI-generated texts.
Conventional AI detection techniques, such as those proposed by Opara et al. (2024) [
12], Alamleh et al. (2023) [
13], and Guo et al. (2024) [
15], primarily rely on easily extractable textual features, such as emotional tone or subjectivity. These methods typically involve counting specific words or identifying recurring patterns within the text. However, because such features are straightforward to modify, AI systems can readily alter them through techniques like humanization.
In contrast, our approach relies on features that require a complete parsing of sentences. Given that all analyzed large language models (LLMs), regardless of whether they are older or more recent, exhibit consistent grammatical properties, we posit that these properties are characteristic of machine-generated writing. While it may be possible to instruct an LLM to emulate human-like grammar, doing so would fundamentally alter the model’s writing style. Post-processing an existing text to retrospectively modify its grammar could also be feasible, but it presents significant challenges. Specifically, ensuring that the original content remains unchanged while modifying the syntactic structure, particularly the occurrence of nouns and their syntactic relationships, would be difficult to achieve.
In this study, we compared two corpora based on the cosine similarity of their grammatical feature vectors. If the cosine similarity between a given corpus and a machine-generated corpus is higher than that between the given corpus and a human-written corpus, the given corpus can be classified as machine-generated. However, we did not currently compute confidence scores for these classifications, which would be crucial for practical applications. Additionally, we have not yet evaluated the reliability of our method in comparison to other AI-based detection mechanisms. These limitations will be addressed as the method is further refined for real-world implementation.
Future research will aim to extend the parser’s capabilities to encompass all grammatically correct German sentences rather than only a subset. In combination with the reduction in false interpretations of sentences, the sentences needed for an AI detection would reduce significantly. Furthermore, integrating the strengths of both rule-based and neural methodologies appears to be a promising direction for future developments.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}