
A Generative AI-Empowered Digital Tutor for Higher Education Courses

 , , ,
, , ,
Abstract
1. Introduction
2. Review of Related Work
- Large Language Models (LLMs): Large language models (LLMs) are a category of artificial intelligence systems that use vast amounts of textual data to generate human-like responses [26]. These models are trained on diverse data sources and can understand and answer questions based on provided input. A common method for adapting LLMs for specific tasks is by carefully crafting the input prompts to guide the model’s output without altering the underlying model. This approach is known as prompt engineering and it is particularly useful with closed source commercial LLMs such as OpenAI’s GPT series, Anthropic’s Claude, Google’s Gemini, and others [27].
- Retrieval-Augmented Generation (RAG): Retrieval-Augmented Generation (RAG) [14] is a method that combines two techniques: information retrieval and language generation. In this method, given a query, the system first retrieves relevant documents or data from a specific corpus (such as the course materials in TAUDT) and then uses an LLM to generate a coherent response based on that retrieved information. RAG is particularly suitable for systems like TAUDT, where cost and accuracy are important considerations. By retrieving only the most relevant pieces of information before querying the LLM, the system minimizes unnecessary processing and improves the accuracy of the generated response. An essential component of RAG is embeddings, which are numerical representations of text that capture its semantics, so that texts with similar embeddings have similar meanings. By converting both the query and the database content into embeddings, the system can efficiently match queries with relevant content, ensuring that only the pertinent sections of the course material are retrieved.
- Frameworks for Developing LLM-Based Applications: Developing LLM-based applications like TAUDT often requires integrating multiple AI functions, such as handling prompts, managing data retrieval, as well as interacting with external systems. Several frameworks have been designed to simplify this process. Common examples include LangChain, LlamaIndex, Haystack and others, all of which offer tools to build applications that connect LLMs with data sources like databases and APIs. Langchain is used in the development of TAUDT [28].
3. User Interaction with the TAUDT System
3.1. Teaching Staff Interaction
3.2. Student Interaction
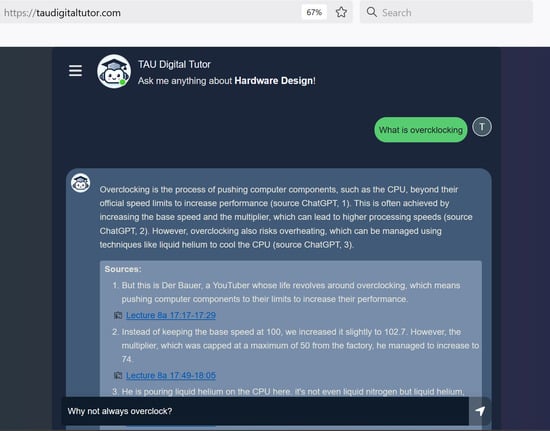
- Example: To better illustrate the interaction flow between a student and TAUDT, consider the scenario depicted in Figure 1. A student is reviewing lecture materials from the “Computer Architecture” course. While watching a recorded lecture, the student hears a term, “overclocking”, which she does not recall. She pauses the video and types the question, “What is overclocking?”, into the TAUDT interface. The system searches through the lecture materials, finding relevant segments in the course video which explain the concept and responding with a concise summary. The answer explains that overclocking is a method to increase the CPU’s clock’s speed (pointing to Sources 1 and 2—two specific points in the course video where this information is described), a process that may potentially cause the CPU to overheat (pointing to Source 3). The student wants to dive deeper to understand how such overheating may be avoided; hence, she asks a follow-up question, “What are some ways to avoid this risk?”. TAUDT’s response here includes two cooling methods that were mentioned in class (sources 1 and 2) and three additional ones suggested by ChatGPT. Observe that distinguishing the answer parts originating from the course material vs. ChatGPT enables critical reading—the student can easily follow and examine the links to the supporting course extracts, while exercising further caution for information provided by ChatGPT only.
4. System Architecture and Technical Design
- Frontend User Interface Layer: The frontend provides students with an intuitive user interface (UI) to submit questions, view responses, and manage conversations. Each interaction is associated with a specific course, ensuring that answers remain contextually relevant.
- Data Storage Layer: This layer manages course materials and user data and includes two corresponding databases. Course materials are split into chunks (e.g., course video intervals, sections of transcribed material, etc.), each of which is processed into a numerical vector representation, a process known as embedding [30], and the embedding vector is stored in a database. This embedding vector will be later used by the system’s RAG for the retrieval of the chunks most relevant for the student query. Student interaction histories are stored in another database for efficient query-time context management, as described below. All student ID’s are annonimized to fully preserve users’ privacy.
- Backend Processing Layer: The backend query processor constitutes the heart of the system, and its functionality is detailed in what follows. It manages the processing of user queries and includes modules for preprocessing, routing, query refinement, and response synthesis. This layer also handles the interaction with the two databases and external services like LLMs.
4.1. Input Handling and Rephrasing
4.2. Query Classification
4.3. Data Retrieval
- Course Knowledge LLM: The course knowledge LLM is prompted to further refine the retrieval and retain a subset of the chunks which appear contextually most relevant for generating a query’s answer.
- General Knowledge LLM: The general knowledge LLM, on the other hand, is prompted to generate a new virtual chunk which contains the LLM answer to the question. In the generation of this virtual chunk, the LLM is instructed to utilize both the retrieved chunks of the course materials and its own general knowledge as well as supplement, if needed, the course-specific data with additional context, examples, or related concepts. For instance, consider our running example where the student asks for ways to avoid CPU overheating. The general knowledge LLM may respond with a virtual chunk that includes some of the methods described in class, but it may also include additional, broader industry practices not mentioned there (e.g., the possibility of gradually increasing the clock speed or system monitoring). As another example, if a student asks, ’Can you give me an example of [a concept or calculation]?’, and an example was not directly presented in class, the general knowledge LLM can provide a relevant example that complements the course material.
4.4. Response Merging
4.5. Answer Delivery and Feedback Handling
4.6. Technological Stack
5. System Setup
- Agreement Score: An answer consists of two parts: a textual reply and a set of references. The Agreement Score evaluates the textual response, measuring how closely TAUDT’s output aligns with the lecturers, providing an indication of how well the system mimics expert responses.
- Reference Score: This metric assesses the similarity between the system’s retrieved references and the ground-truth references provided by the teaching staff.
- Groundedness Score: This metric measures the extent to which TAUDT’s textual answers are based on the listed references, ensuring that responses are grounded in the relevant content retrieved during the query processing.
- Question-Answer Relevance Score: This metric gauges how well TAUDT’s responses address the student query, ensuring their relevance.
- Chunk number: To determine the number k of course chunks to be retrieved in the retrieval step.
- Chunk size: To optimize the granularity of the retrieved content.
- Embedding model selection: To identify the text embedding model that best captures the course material’s semantics.
- LLM model selection: To choose the most appropriate LLM model for different stages of the query-processing pipeline.
6. Pilot Study
6.1. Study Setup and Execution
6.2. Results
- Student Engagement and Usage The digital tutor experienced substantial adoption and use throughout the semester. Of the 100 enrolled students, 78 actively used the system at least once, collectively submitting 2107 queries. Among these users, 74.36% returned for multiple sessions, showcasing consistent engagement with the tool as a valuable learning resource.
- Query Types Using an LLM-based classification, the queries were categorized into six primary types:
- Concept Clarification (50%): Students sought explanations or definitions of specific terms, concepts, or principles covered in the course.
- Problem-Solving Requests (13%): Students requested assistance with calculations, procedural tasks, or problem-solving approaches.
- Follow-Up Questions (12%): These inquiries built on prior responses, asking for additional details, clarifications, or variations.
- Example Requests (12%): Students asked for illustrative examples to better understand a topic or method.
- Non-Actionable Interactions (8%): Casual exchanges (e.g., “hello,” “thank you”) or unrelated queries.
- Administrative Queries (5%): Course logistics, such as lesson schedules or overall structure (We note that administrative information is uploaded to the system when it is provided in the form of accompanying documents (e.g., PDF) or in the lecture transcript. Either way it is included in the RAG and retrieved from there).
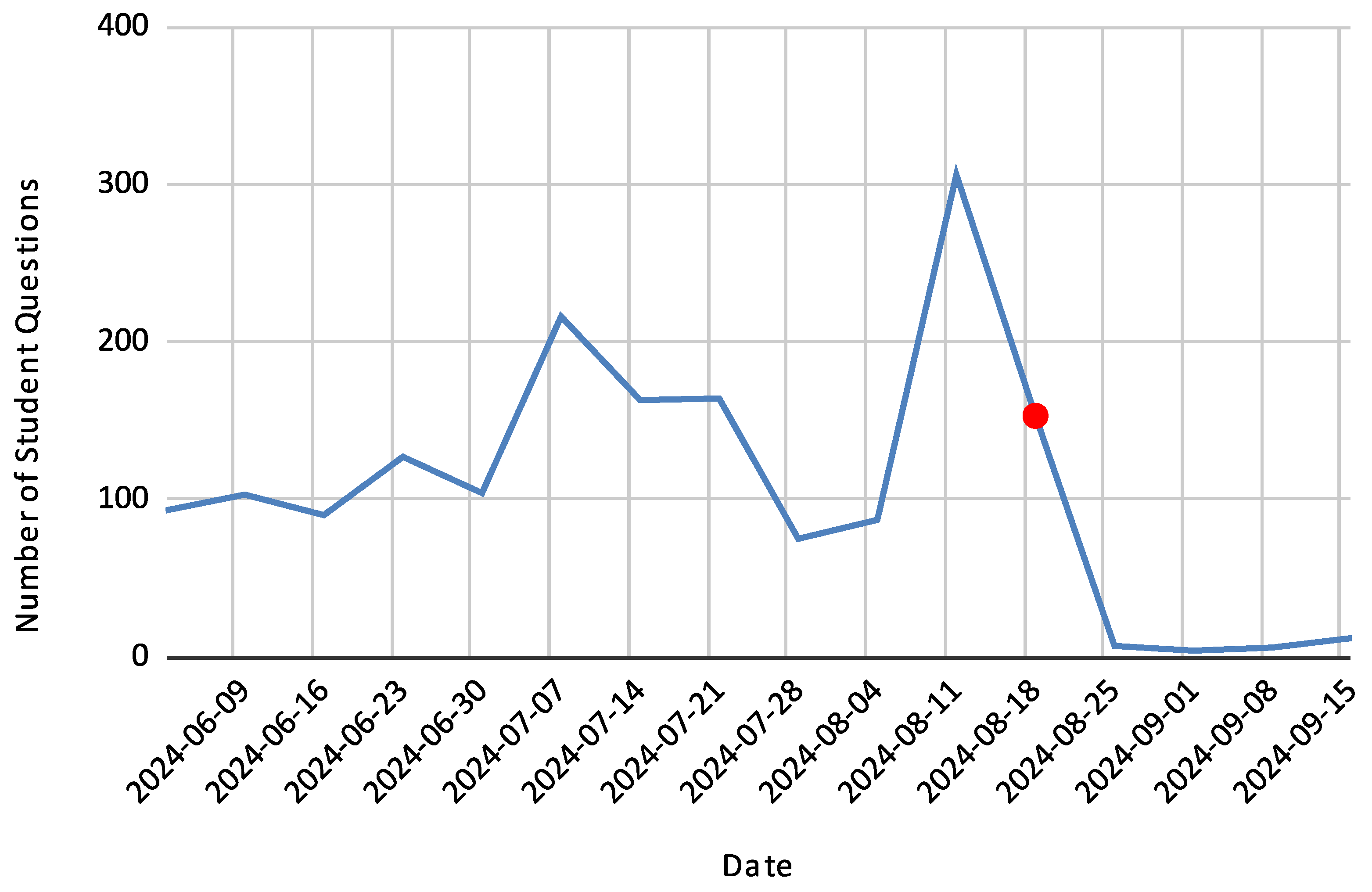
- System Performance The system answered 78.69% of submitted queries successfully, with the success rate improving steadily over the semester, reaching 90% during the critical exam preparation period (Figure 4). The average response time was 11.63 s. The remaining 21.31% of queries failed for various reasons. An analysis of failure types revealed the following breakdown:
- Failed to Match Quotes in Response Generation Phase (85.39% of errors):This error occurs when the response formatter fails to correctly align the generated answer with specific references from the course materials. Namely, it cannot match the quotes in the answer to the original retrieved chunks. (This may happen due to a lack of direct quotes, formatting inconsistencies, mismatches between the generated text and retrieved sources, etc.)
- Failed Processing Sources (12.13%): Issues arose when source documents could not be processed, typically due to parsing or mapping challenges.
- Failed to Extract Content in Curation Phase (1.12%): This reflected difficulties in finding relevant material for vague or ambiguous questions.
- Quote Pipeline Miscellaneous Errors (0.90%): General errors in the content processing pipeline that could not be categorized further.
- Failed Reordering Quotes (0.45%): Errors occurred when reordering quotes for logical flow or sequence in the response.
- Student Feedback Of the feedback received, 62.86% was positive, with an upward trend in satisfaction as new features were introduced, reflecting general satisfaction with the tool. Detailed comments were submitted in 78.20% of interactions, offering constructive input for refinement. Key themes included the following:
- Content Relevance: Students occasionally noted that answers did not fully address their queries or were unrelated to the topic.
- Completeness: Some students requested more detailed explanations or additional context.
- Technical Issues: Reports of system errors, such as timeouts or inability to generate responses, were noted.
- Usability Suggestions: Students proposed features to enhance the user experience, such as improved formatting (e.g., breaking complex answers into bullet points) or additional system functionality.
7. Discussion and Conclusions
- System Logs for Insights: The potential of leveraging system logs extends beyond improving the platform itself. By analyzing these logs, educators could identify common student challenges and refine their teaching strategies accordingly [33].
- Human–Platform Interactions: Future work should focus on optimizing the interactions between students, teachers, and the TAUDT platform. Clearly defining the roles of human participants in this digital ecosystem is crucial for maintaining balance and maximizing benefits [12].
- Promoting Interactive Learning: By framing the TAUDT platform not only as a tool for solving problems but also as a means to actively involve students in the learning process, its impact could be further amplified [34].
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial intelligence |
| TAUDT | Tel Aviv University Digital Tutor |
| LLM | Large language model |
| RAG | Retrieval-augmented generation |
| API | Application programming interface |
| UI | User interface |
| NLP | Natural language processing |
References
- Knobloch, J.; Kaltenbach, J.; Bruegge, B. Increasing student engagement in higher education using a context-aware Q&A teaching framework. In Proceedings of the 40th International Conference on Software Engineering: Software Engineering Education and Training, Gothenburg, Sweden, 30 May–1 June 2018; pp. 136–145. [Google Scholar]
- Zylich, B.; Viola, A.; Toggerson, B.; Al-Hariri, L.; Lan, A. Exploring automated question answering methods for teaching assistance. In Proceedings of the Artificial Intelligence in Education: 21st International Conference, AIED 2020, Ifrane, Morocco, 6–10 July 2020; Proceedings, Part I 21. Springer: Berlin/Heidelberg, Germany, 2020; pp. 610–622. [Google Scholar]
- Sajja, R.; Sermet, Y.; Cwiertny, D.; Demir, I. Platform-independent and curriculum-oriented intelligent assistant for higher education. Int. J. Educ. Technol. High. Educ. 2023, 20, 42. [Google Scholar] [CrossRef]
- Liu, X.; Pankiewicz, M.; Gupta, T.; Huang, Z.; Baker, R.S. A Step Towards Adaptive Online Learning: Exploring the Role of GPT as Virtual Teaching Assistants in Online Education. Preprint 2024. [Google Scholar] [CrossRef]
- Sajja, R.; Sermet, Y.; Cikmaz, M.; Cwiertny, D.; Demir, I. Artificial intelligence-enabled intelligent assistant for personalized and adaptive learning in higher education. Information 2024, 15, 596. [Google Scholar] [CrossRef]
- Sumanth, N.S.; Priya, S.V.; Sankari, M.; Kamatchi, K. AI-Enhanced Learning Assistant Platform. In Proceedings of the IEEE 2024 International Conference on Inventive Computation Technologies (ICICT), Lalitpur, Nepal, 24–26 April 2024; pp. 846–852. [Google Scholar]
- Google Developers Blog. How It’s Made: Exploring AI x Learning Through Shiffbot, an AI Experiment Powered by the Gemini API. 2024. Available online: https://app.daily.dev/posts/how-it-s-made—exploring-ai-x-learning-through-shiffbot-an-ai-experiment-powered-by-the-gemini-api-8z3etgmsk (accessed on 24 November 2024).
- Poe. Poe-Fast, Helpful AI Chat. 2024. Available online: https://poe.com/ (accessed on 24 November 2024).
- OpenAI. Introducing GPTs. 2024. Available online: https://openai.com/index/introducing-gpts/?utm_source=chatgpt.com (accessed on 24 November 2024).
- CustomGPT. CustomGPT: Build Your Own AI-Powered Chatbot. 2024. Available online: https://customgpt.ai/?fpr=justin10&gad_source=1&gclid=CjwKCAiA9IC6BhA3EiwAsbltOHu_zAqo9IYsS6Bok9tgNKVM-7WszdypEsoIphVAtmBf6y7T_p5-ChoCooUQAvD_BwE (accessed on 24 November 2024).
- Azamfirei, R.; Kudchadkar, S.R.; Fackler, J. Large language models and the perils of their hallucinations. Crit. Care 2023, 27, 120. [Google Scholar] [CrossRef] [PubMed]
- Te’eni, D.; Yahav, I.; Zagalsky, A.; Schwartz, D.; Silverman, G.; Cohen, D.; Mann, Y.; Lewinsky, D. Reciprocal human-machine learning: A theory and an instantiation for the case of message classification. Manag. Sci. 2023, 1–26. [Google Scholar] [CrossRef]
- Rehman, A.U.; Mahmood, A.; Bashir, S.; Iqbal, M. Technophobia as a Technology Inhibitor for Digital Learning in Education: A Systematic Literature Review. J. Educ. Online 2024, 21, n2. [Google Scholar] [CrossRef]
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.t.; Rocktäschel, T.; et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Adv. Neural Inf. Process. Syst. 2020, 33, 9459–9474. [Google Scholar] [CrossRef]
- Perkins, M. Academic Integrity considerations of AI Large Language Models in the post-pandemic era: ChatGPT and beyond. J. Univ. Teach. Learn. Pract. 2023, 20, 1–26. [Google Scholar] [CrossRef]
- Liu, H.; Liu, C.; Belkin, N.J. Investigation of users’ knowledge change process in learning-related search tasks. Proc. Assoc. Inf. Sci. Technol. 2019, 56, 166–175. [Google Scholar] [CrossRef]
- Akgun, S.; Greenhow, C. Artificial intelligence in education: Addressing ethical challenges in K-12 settings. AI Ethics 2022, 2, 431–440. [Google Scholar] [CrossRef] [PubMed]
- Ewing, G.; Demir, I. An ethical decision-making framework with serious gaming: A smart water case study on flooding. J. Hydroinform. 2021, 23, 466–482. [Google Scholar] [CrossRef]
- Neumann, M.; Rauschenberger, M.; Schön, E.M. “We need to talk about ChatGPT”: The future of AI and higher education. In Proceedings of the 2023 IEEE/ACM 5th International Workshop on Software Engineering Education for the Next Generation (SEENG), Melbourne, Australia, 16 May 2023; pp. 29–32. [Google Scholar]
- Lee, H. The rise of ChatGPT: Exploring its potential in medical education. Anat. Sci. Educ. 2024, 17, 926–931. [Google Scholar] [CrossRef] [PubMed]
- Huang, J.; Saleh, S.; Liu, Y. A review on artificial intelligence in education. Acad. J. Interdiscip. Stud. 2021, 10, 206. [Google Scholar] [CrossRef]
- Crompton, H.; Song, D. The potential of artificial intelligence in higher education. Rev. Virtual Univ. Católica Del Norte 2021, 62, 1–4. [Google Scholar] [CrossRef]
- Jensen, L.X.; Buhl, A.; Sharma, A.; Bearman, M. Generative AI and higher education: A review of claims from the first months of ChatGPT. High. Educ. 2024, 1–17. [Google Scholar] [CrossRef]
- Essel, H.B.; Vlachopoulos, D.; Tachie-Menson, A.; Johnson, E.E.; Baah, P.K. The impact of a virtual teaching assistant (chatbot) on students’ learning in Ghanaian higher education. Int. J. Educ. Technol. High. Educ. 2022, 19, 57. [Google Scholar] [CrossRef]
- Tack, A.; Piech, C. The AI Teacher Test: Measuring the Pedagogical Ability of Blender and GPT-3 in Educational Dialogues. In Proceedings of the 15th International Conference on Educational Data Mining, Durham, UK, 24–27 July 2022; pp. 522–529. [Google Scholar] [CrossRef]
- Kasneci, E.; Seßler, K.; Küchemann, S.; Bannert, M.; Dementieva, D.; Fischer, F.; Gasser, U.; Groh, G.; Günnemann, S.; Hüllermeier, E.; et al. ChatGPT for good? On opportunities and challenges of large language models for education. Learn. Individ. Differ. 2023, 103, 102274. [Google Scholar] [CrossRef]
- Caffagni, D.; Cocchi, F.; Barsellotti, L.; Moratelli, N.; Sarto, S.; Baraldi, L.; Baraldi, L.; Cornia, M.; Cucchiara, R. The Revolution of Multimodal Large Language Models: A Survey. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2024, Bangkok, Thailand, 11–16 August 2024; pp. 13590–13618. [Google Scholar] [CrossRef]
- Wikipedia Contributors. LangChain. 2024. Available online: https://en.wikipedia.org/wiki/LangChain?utm_source=chatgpt.com (accessed on 28 November 2024).
- TAUDT-Team. TAUDT Tutorial. 2025. Available online: https://www.youtube.com/watch?v=lC2bCnEv5X0 (accessed on 13 March 2025).
- Wikipedia Contributors. Word Embedding—Wikipedia. The Free Encyclopedia. 2024. Available online: https://en.wikipedia.org/wiki/Word_embedding (accessed on 27 December 2024).
- Es, S.; James, J.; Espinosa-Anke, L.; Schockaert, S. RAGAS: Evaluation Framework for Retrieval-Augmented Generation Systems. 2023. Available online: https://docs.ragas.io/en/stable/ (accessed on 13 March 2025).
- Biases, W. Weights & Biases: Machine Learning Experiment Tracking. 2020. Available online: https://wandb.ai (accessed on 3 December 2024).
- Hase, A.; Kuhl, P. Teachers’ use of data from digital learning platforms for instructional design: A systematic review. Educ. Technol. Res. Dev. 2024, 72, 1925–1945. [Google Scholar] [CrossRef]
- Doherty, K.; Doherty, G. Engagement in HCI: Conception, Theory and Measurement. ACM Comput. Surv. 2019, 51, 99. [Google Scholar] [CrossRef]
- Field, J. Lifelong Learning and the New Educational Order; Trentham Books: Stoke-on-Trent, UK, 2000. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Name | Release Date |
|---|---|
| Launch | 3 June 2024 |
| Conversational chat | 3 July 2024 |
| Upgraded embedding model | 6 July 2024 |
| General knowledge from ChatGPT | 14 August 2024 |
| Question classifier | 21 August 2024 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Reicher, H.; Frenkel, Y.; Lavi, M.J.; Nasser, R.; Ran-milo, Y.; Sheinin, R.; Shtaif, M.; Milo, T. A Generative AI-Empowered Digital Tutor for Higher Education Courses. Information 2025, 16, 264. https://doi.org/10.3390/info16040264
Reicher H, Frenkel Y, Lavi MJ, Nasser R, Ran-milo Y, Sheinin R, Shtaif M, Milo T. A Generative AI-Empowered Digital Tutor for Higher Education Courses. Information. 2025; 16(4):264. https://doi.org/10.3390/info16040264
Chicago/Turabian StyleReicher, Hila, Yarden Frenkel, Maor Juliet Lavi, Rami Nasser, Yuval Ran-milo, Ron Sheinin, Mark Shtaif, and Tova Milo. 2025. "A Generative AI-Empowered Digital Tutor for Higher Education Courses" Information 16, no. 4: 264. https://doi.org/10.3390/info16040264
APA StyleReicher, H., Frenkel, Y., Lavi, M. J., Nasser, R., Ran-milo, Y., Sheinin, R., Shtaif, M., & Milo, T. (2025). A Generative AI-Empowered Digital Tutor for Higher Education Courses. Information, 16(4), 264. https://doi.org/10.3390/info16040264