
ORAN-HAutoscaling: A Scalable and Efficient Resource Optimization Framework for Open Radio Access Networks with Performance Improvements

Abstract
1. Introduction
- Introducing ORAN-HAutoscaling, a dynamic framework for managing and supporting large numbers of xApps, rApps, and dApps while optimizing CPU and latency.
- Conducting a comprehensive data collection study to assess the impact of a large number of xApps, CPU resource sharing, and scaling on latency and inference times, creating a data-driven latency model for optimization.
- Implementing ORAN-HAutoscaling and conducting extensive experiments on an ORAN-compliant testbed, comparing it with traditional FlexRIC solutions. The results show that ORAN-HAutoscaling efficiently manages scaling, maintains latency thresholds, and achieves high CPU utilization.
2. Problem Statement
3. Related Work
4. ORAN-HAutoscaling: Scalable Framework ORAN Architecture
- (1)
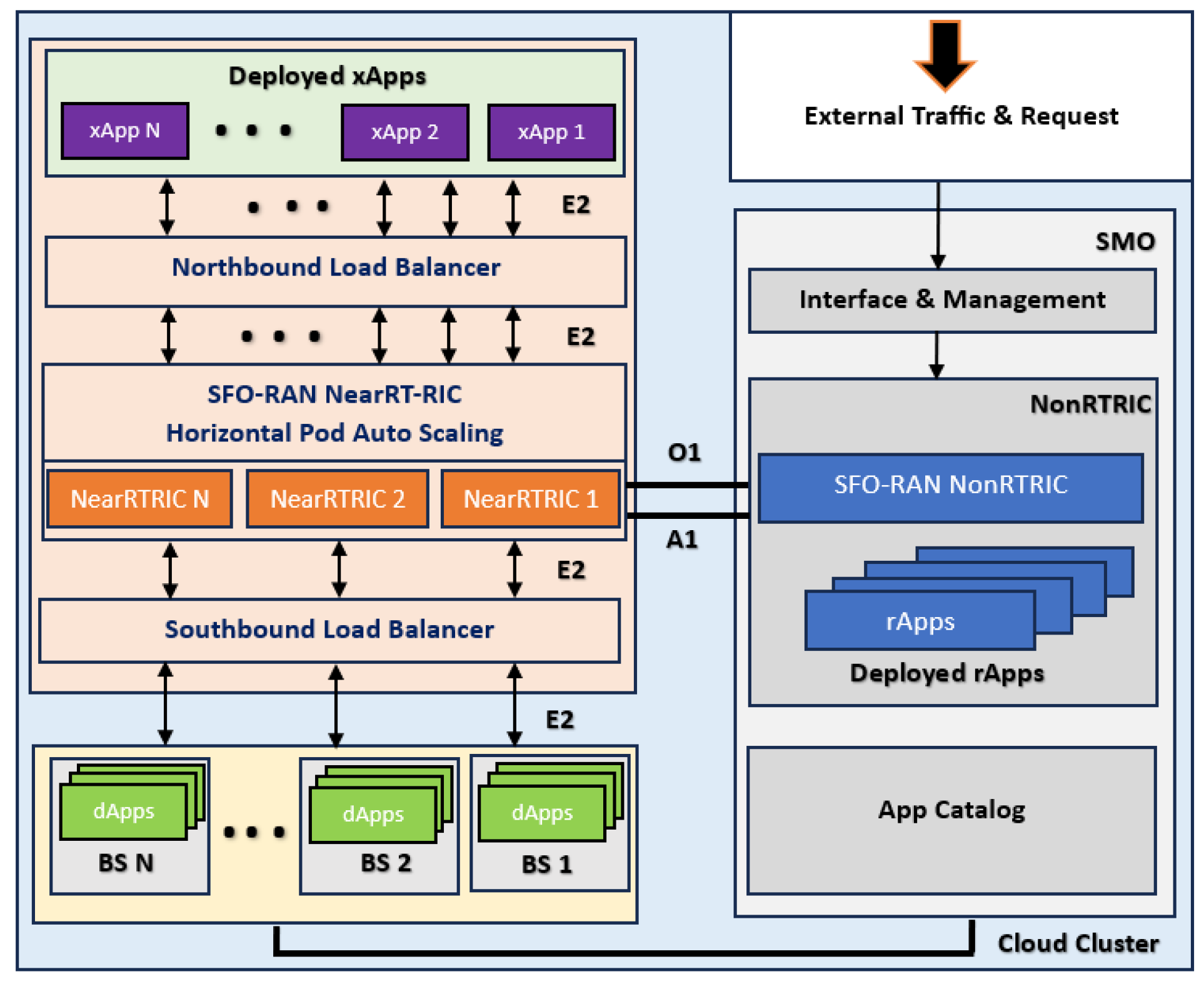
- Request handling: The SMO layer receives xApp deployment requests and forwards them to the SFORAN to check the xApp catalog for the availability.
- (2)
- xApp profiling and benchmarking: If the xApp does not exist in the catalog and does not have an app descriptor, it is profiled and benchmarked by deploying on an idle worker node to know its performance requirements. With descriptors defined in xApps, the SFORAN calculates the right allocation policy according to the collected APIs and metrics.
- (3)
- xApp Deployment: The SFORAN deployment engine retrieves the necessary xApp from the catalog, allocates it to the available node, taking into account latency constraints and resource availability, and then balances the load allocation of it to the near-RTRIC pods.
- (4)
- Resource allocation: The SFORAN automatically adjusts the number of near-RTRIC pods based on CPU usage and latency to ensure proper resource utilization.
- (5)
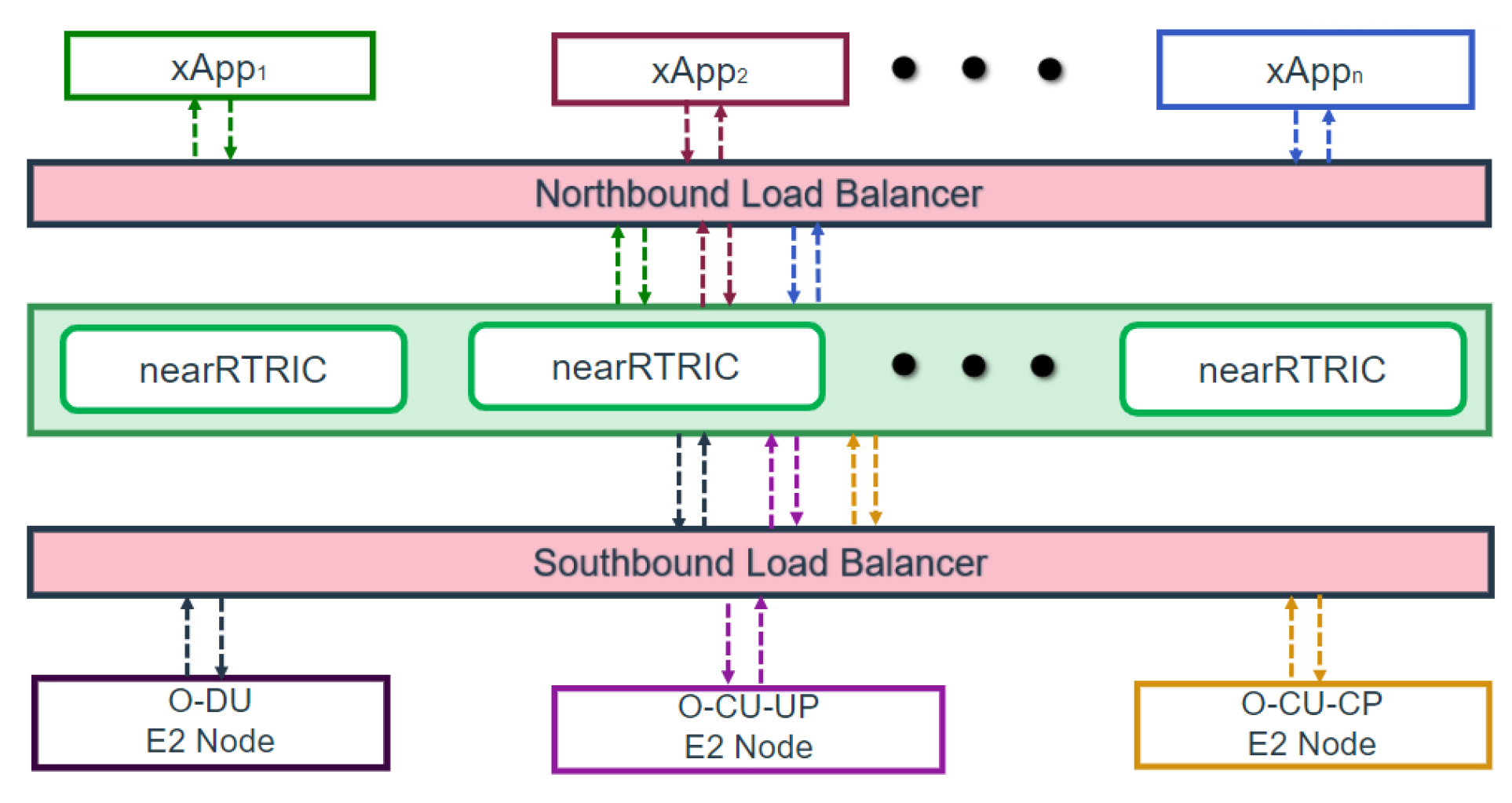
- Latency and resource monitoring: Kubernetes periodically report run-time latency and resource usage metrics to the SFORAN control interface, which feeds back into the optimization loop for further resource adjustments. We have implemented the load balancer service type at northbound and southbound to support the scalability. The high-level view and communication between the different components are presented in the Figure 6.
5. System Model and Terminology
5.1. ORAN High-Traffic Applications
5.2. External Tenant Requests
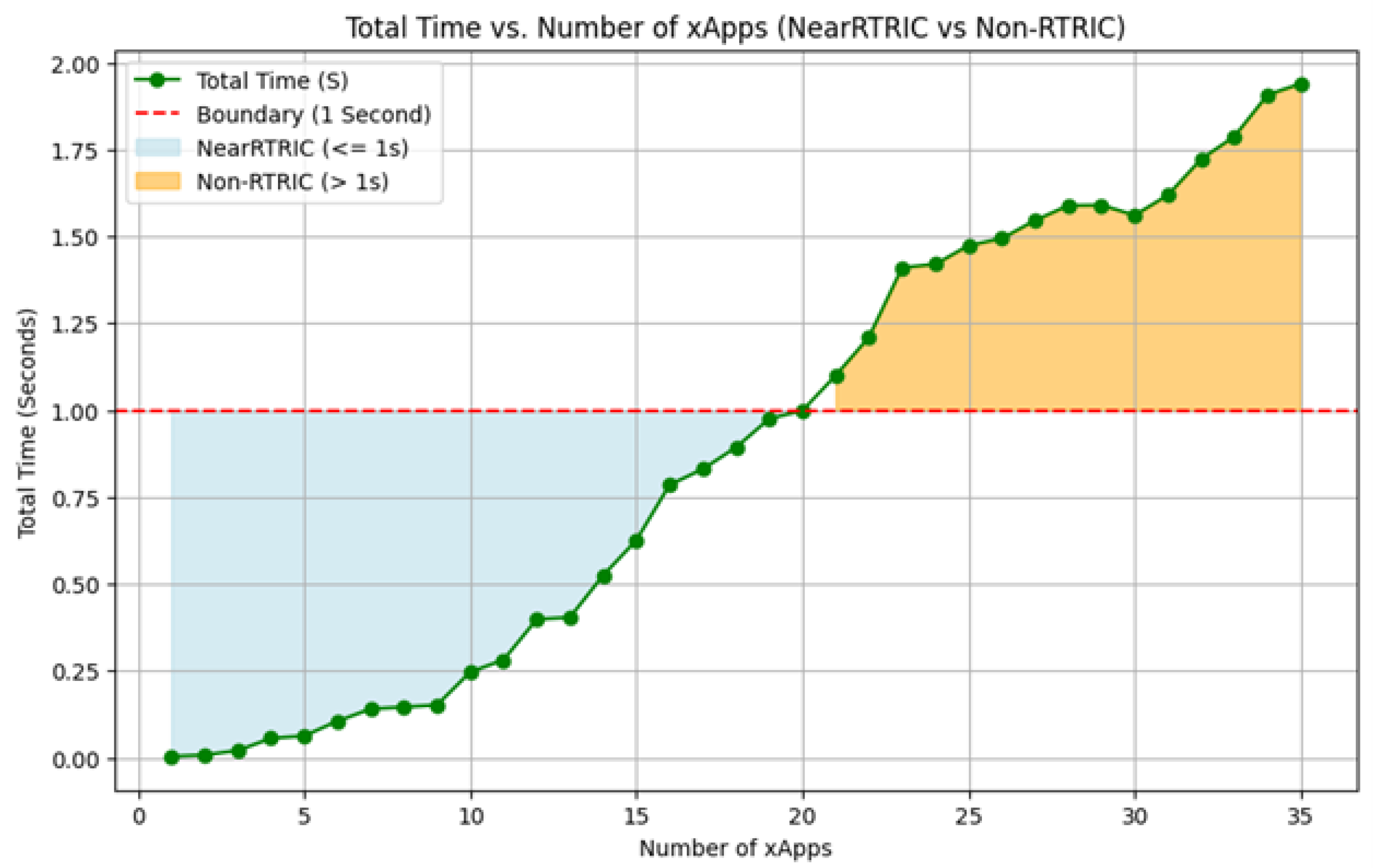
6. Total Time (Latency and ML Inference) and CPU Metrics Model for ORAN Applications
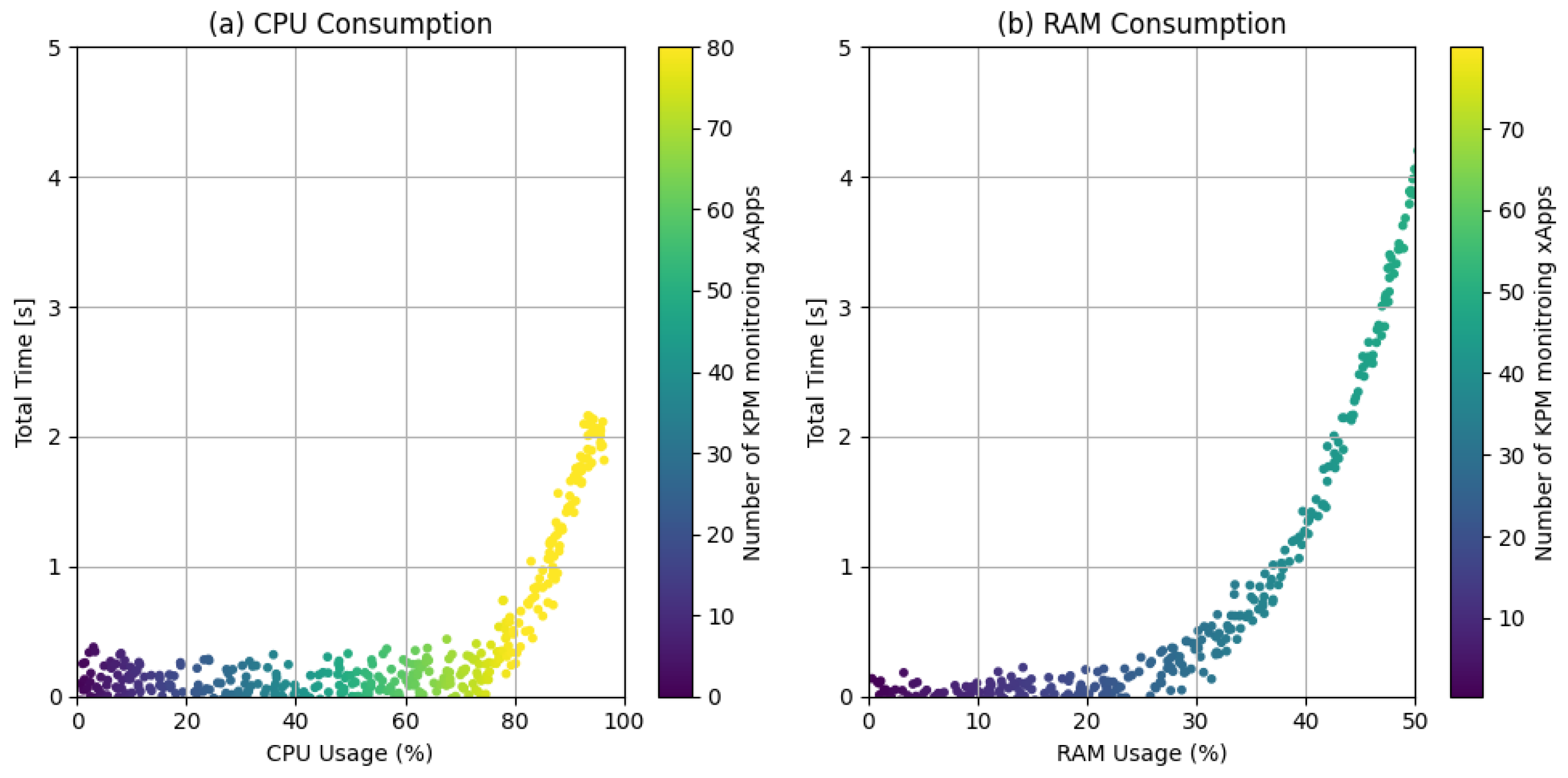
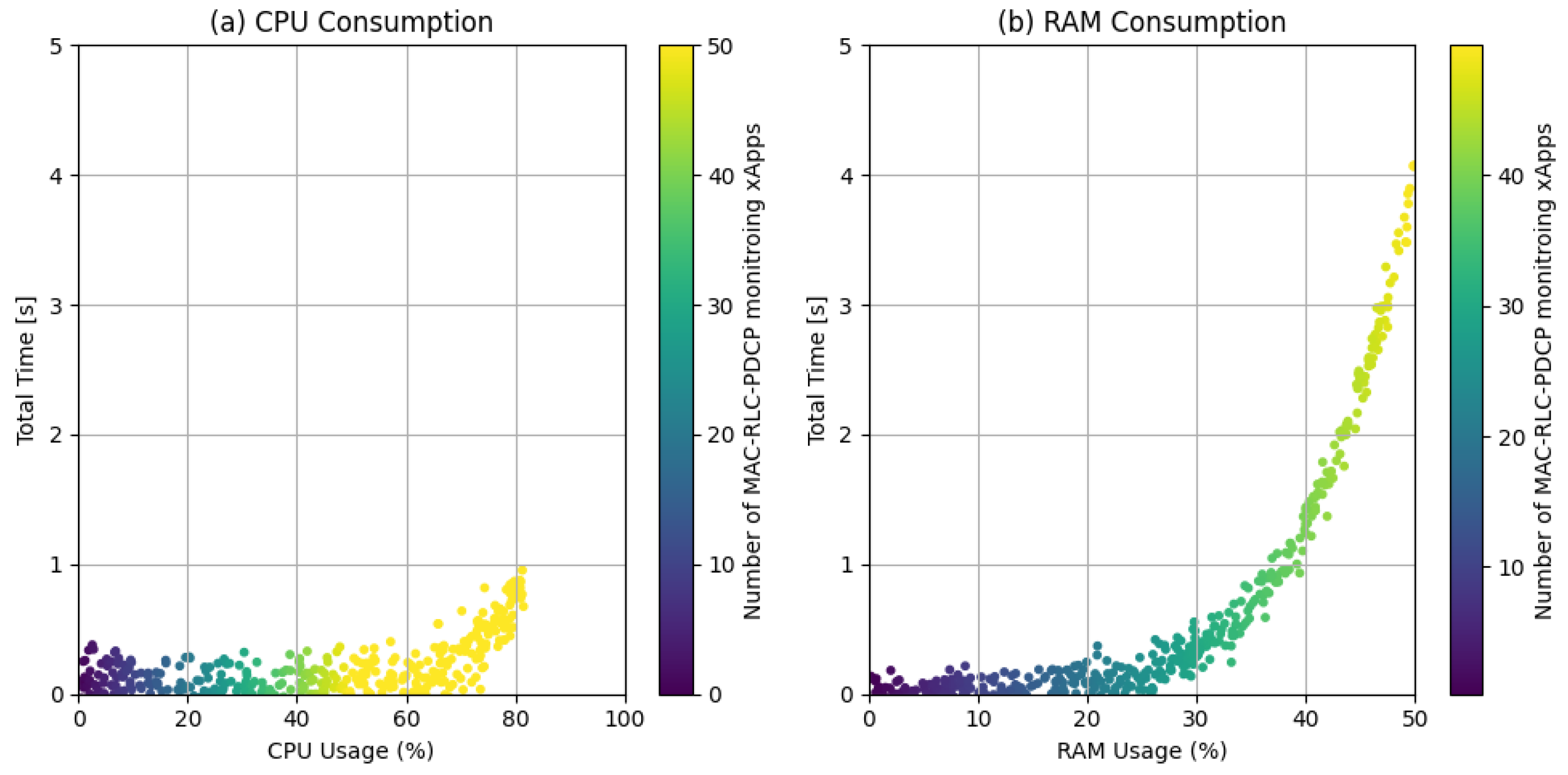
6.1. Inference Time Profiling
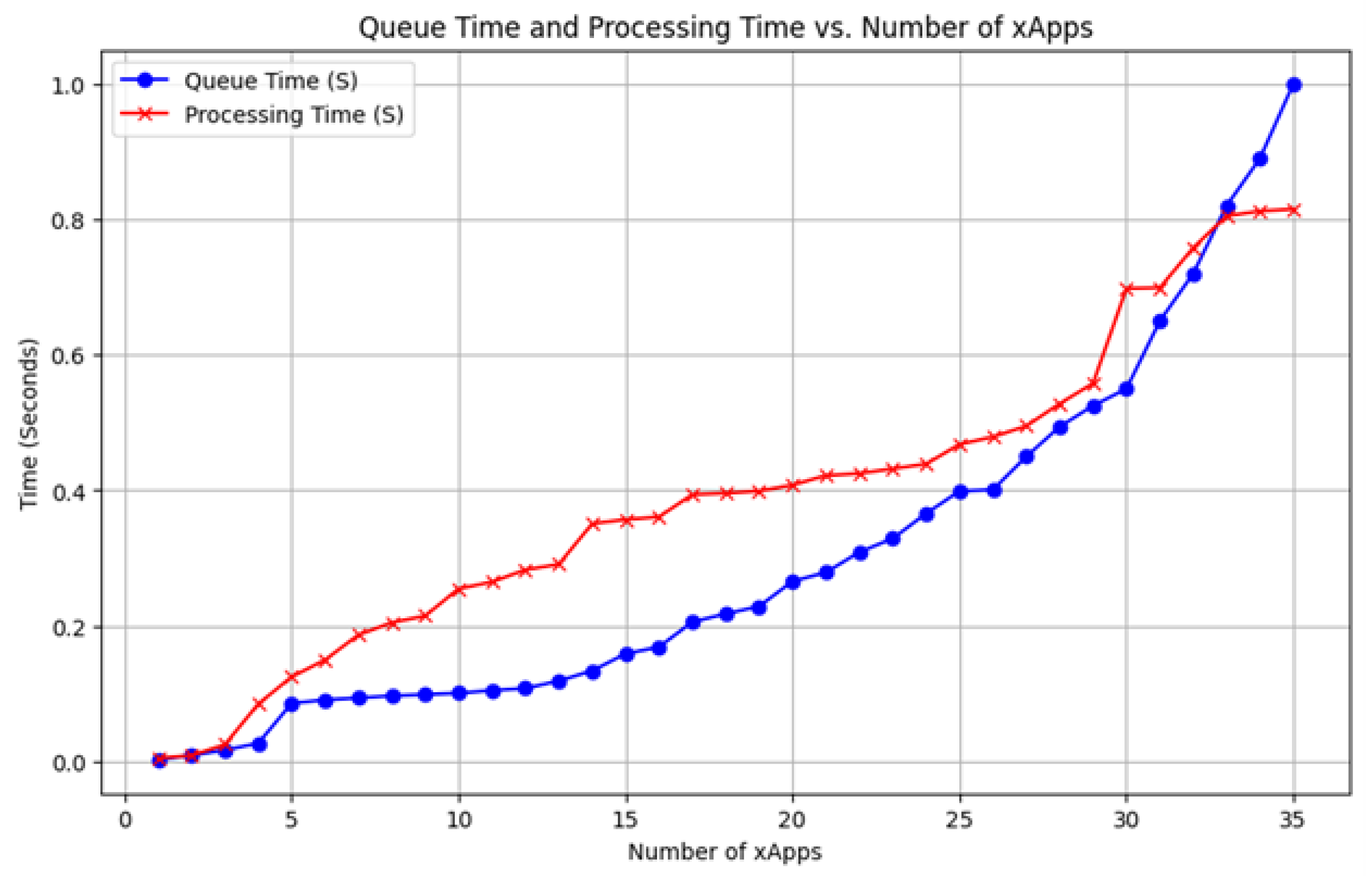
- Queuing time , which is the time taken for the xApp to process the input after it reaches the E2 termination point on the Near-RTRIC.
- Execution time , which represents the time taken to generate the output once the input is processed.
- Inference time , which is the total time for processing the input and producing the output.
6.2. Latency Model
7. Objective Function Design
7.1. Queueing Theory Model (M/M/c Queue)
7.2. Control Theory: Proportional Integral Derivative (PID) Controller
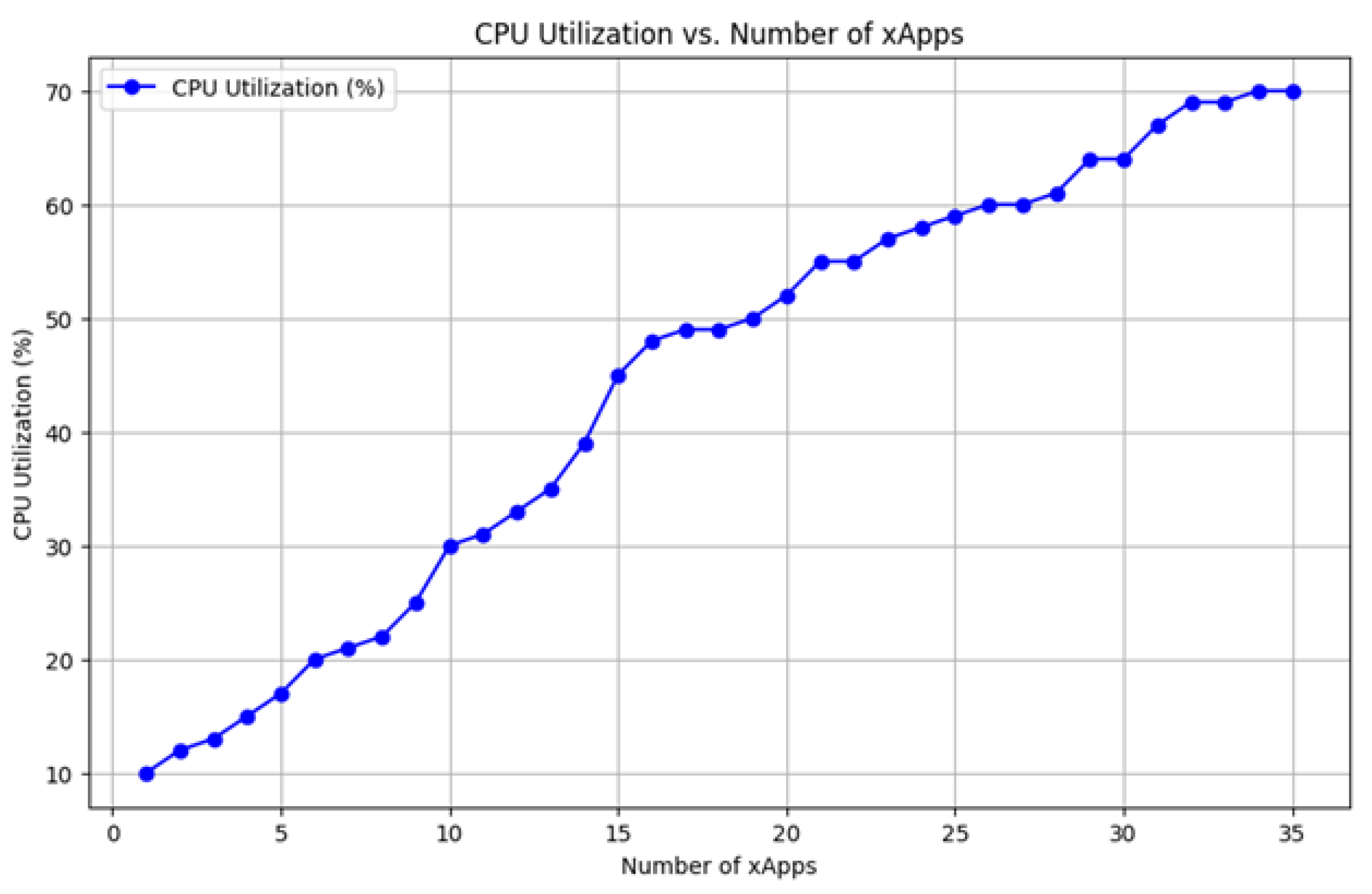
7.3. CPU Scaling Conditions
- Scale-up condition: When CPU utilization exceeds 80%, a new pod is added to handle the increased load:
- Scale-down condition: If CPU utilization stays idle (below a threshold) for 180 s, a pod is removed, but at least one pod must always remain active:
7.4. Combined Metric
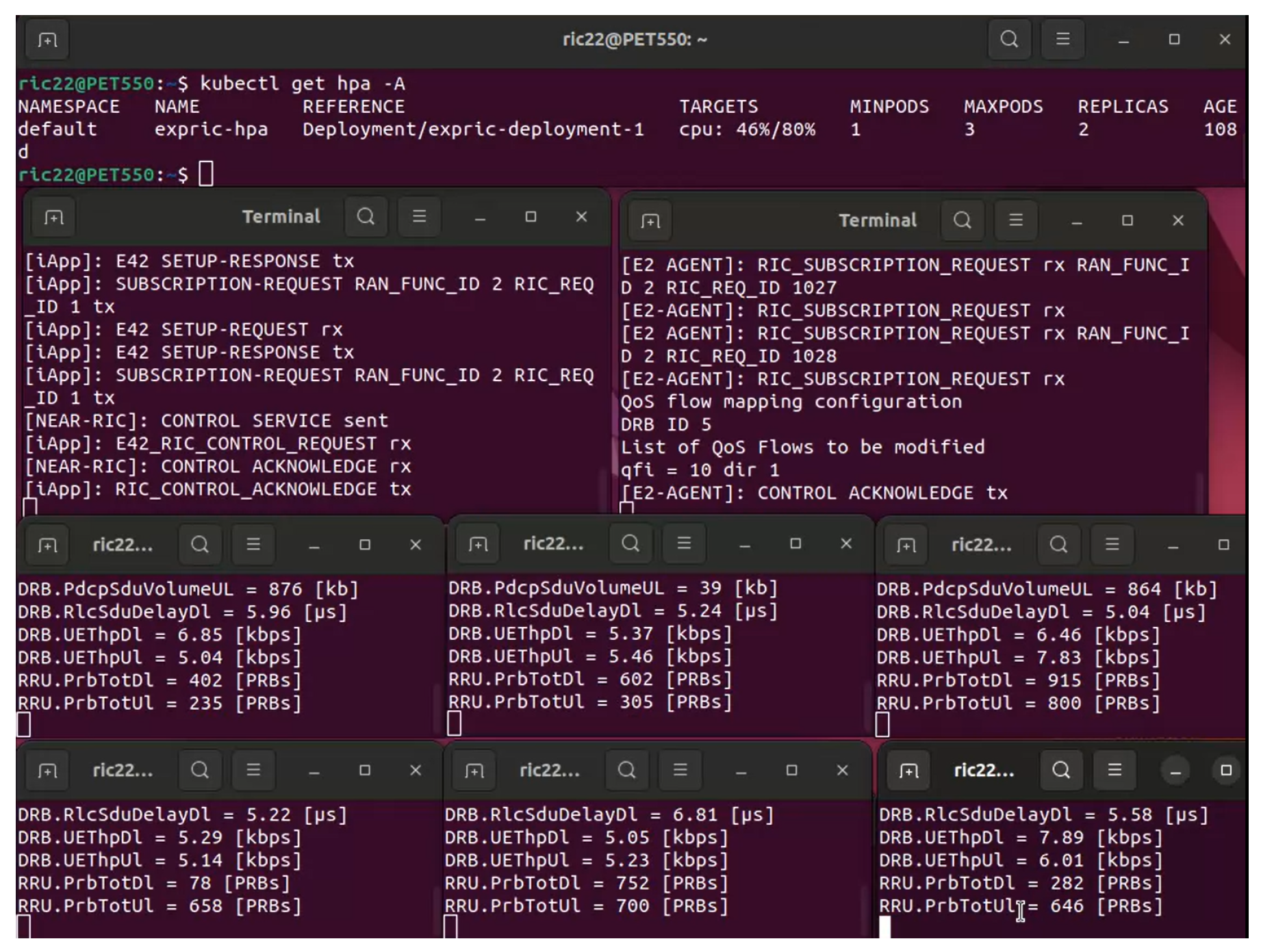
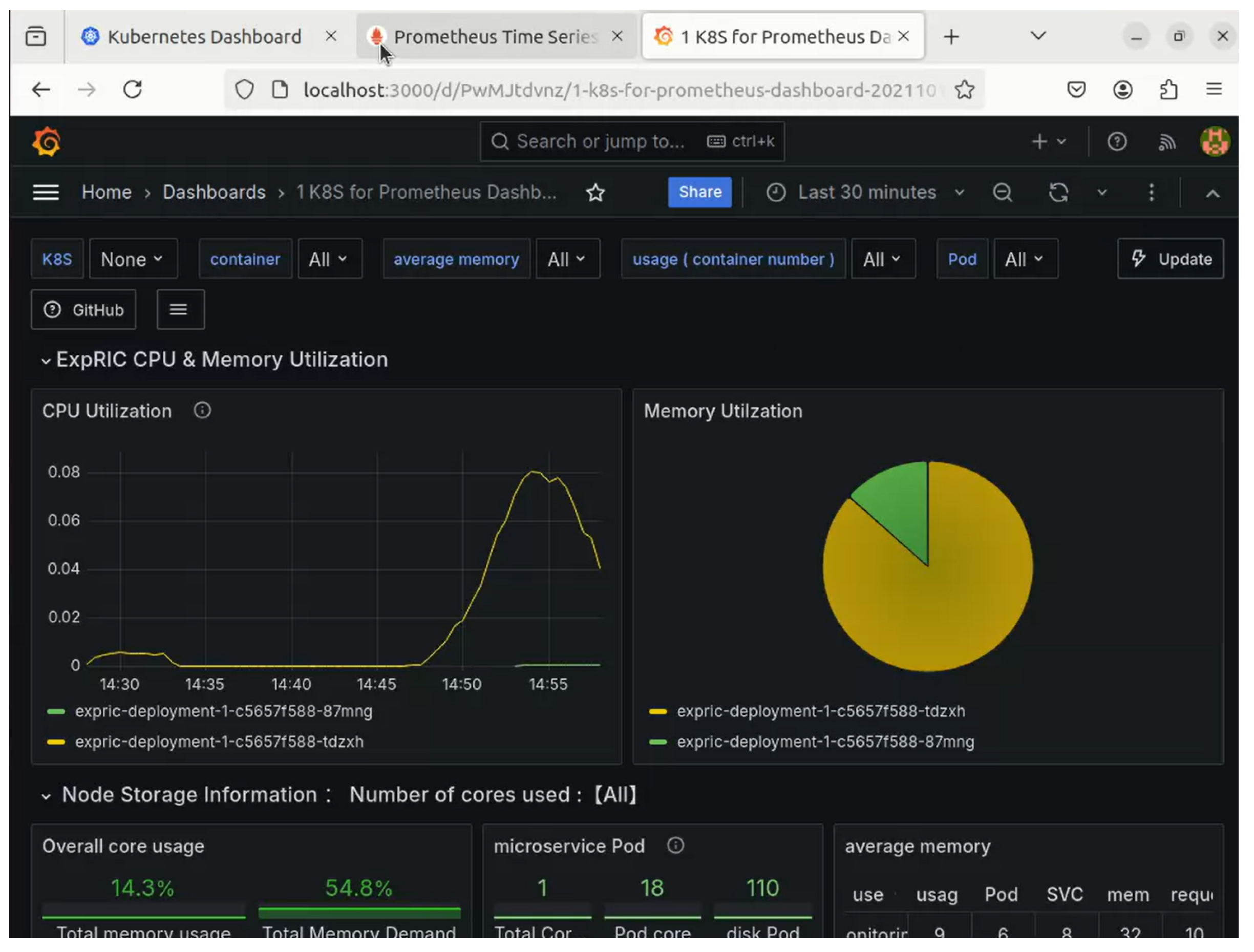
7.5. Integration with Prometheus and Kubernetes APIs
7.6. Monitoring Performance Metrics
7.7. Load Balancer with Bull and Bear
7.7.1. Bull State (Normal Operation)
7.7.2. Bear State (Scaling Up)
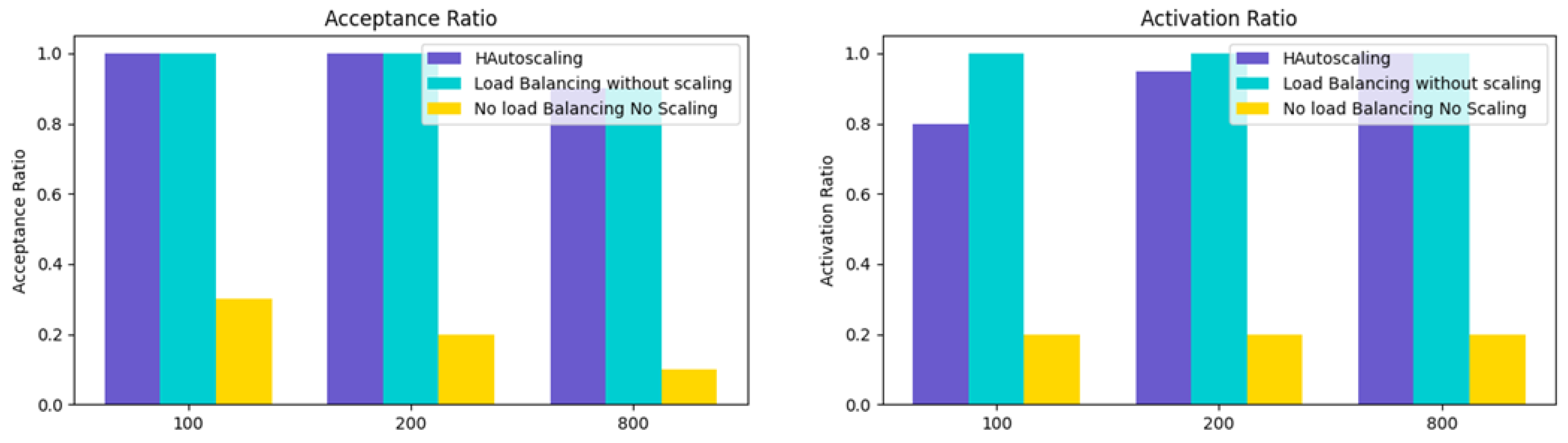
8. Performance Evaluation
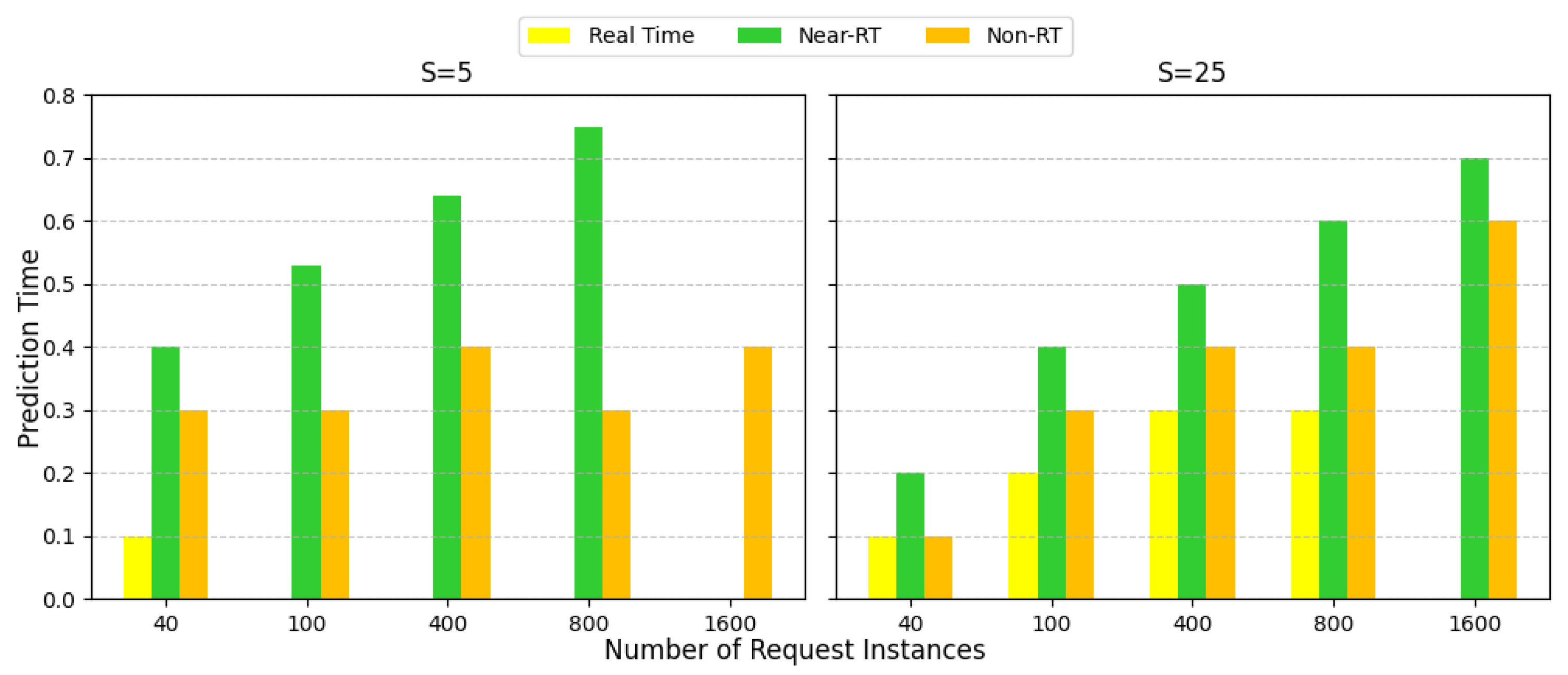
9. Experimental Results
10. Reflection
11. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
References
- Garcia-Saavedra, A.; Costa-Pérez, X. ORAN: Disrupting the Virtualized RAN Ecosystem. IEEE Commun. Stand. Mag. 2021, 5, 96–103. [Google Scholar]
- 3GPP. Study on New Radio Access Technology: Radio Access Architecture and Interfaces. In 3rd Generation Partnership Project (3GPP); 3GPP: Sophia Antipolis, France, 2017; TR 38.801 V14.0.0. [Google Scholar]
- Mimran, D.; Bitton, R.; Kfir, Y.; Klevansky, E.; Brodt, O.; Lehmann, H.; Elovici, Y.; Shabtai, A. Evaluating the Security of Open Radio Access Networks. arXiv 2022, arXiv:2201.06080. [Google Scholar]
- Klement, F.; Katzenbeisser, S.; Ulitzsch, V.; Krämer, J.; Stanczak, S.; Utkovski, Z.; Bjelakovic, I.; Wunder, G. Open or Not Open: Are Conventional Radio Access Networks More Secure and Trustworthy than Open-RAN? arXiv 2022, arXiv:2204.12227. [Google Scholar]
- Cho, J.Y.; Sergeev, A. Secure Open Fronthaul Interface for 5G Networks. In Proceedings of the 16th International Conference on Availability, Reliability and Security, Vienna, Austria, 17–20 August 2021; Ser. ARES 2021. Association for Computing Machinery: New York, NY, USA, 2021. [Google Scholar] [CrossRef]
- IEEE Std 802.1AE-2018; IEEE Standard for Local and Metropolitan area networks-Media Access Control (MAC) Security; Revision of IEEE Std 802.1AE-2006. IEEE: Piscataway, NJ, USA, 2018; pp. 1–239.
- O-RAN ALLIANCE Security Focus Group. Study on Security for Near Real Time RIC and xApps. In ORAN Alliance e.V., Technical Specification v01.00; ORAN Alliance e.V.: Alfter, Germany, 2022. [Google Scholar]
- Shen, C.; Xiao, Y.; Ma, Y.; Chen, J.; Chiang, C.-M.; Chen, S.; Pan, Y. Security Threat Analysis and Treatment Strategy for ORAN. In Proceedings of the 2022 24th International Conference on Advanced Communication Technology (ICACT), Pyeong Chang, Republic of Korea, 13–16 February 2022; pp. 417–422. [Google Scholar]
- Cao, J.; Ma, M.; Li, H.; Ma, R.; Sun, Y.; Yu, P.; Xiong, L. A Survey on Security Aspects for 3GPP 5G Networks. IEEE Commun. Surv. Tutorials 2020, 22, 170–195. [Google Scholar]
- Saad, W.; Bennis, M.; Chen, M. A vision of 6G wireless systems: Applications, trends, technologies, and open research problems. IEEE Netw. 2019, 34, 134–142. [Google Scholar]
- Atya, A.O.F.; Qian, Z.; Krishnamurthy, S.V.; Porta, T.L.; McDaniel, P.; Marvel, L. Malicious Co-residency on the Cloud: Attacks and Defense. In Proceedings of the IEEE INFOCOM 2017-IEEE Conference on Computer Communications, Atlanta, GA, USA, 1–4 May 2017; pp. 1–9. [Google Scholar]
- Gao, X.; Steenkamer, B.; Gu, Z.; Kayaalp, M.; Pendarakis, D.; Wang, H. A Study on the Security Implications of Information Leakages in Container Clouds. IEEE Trans. Dependable Secur. Comput. 2021, 18, 174–191. [Google Scholar]
- Wang, Z.; Yang, R.; Fu, X.; Du, X.; Luo, B. A Shared Memory based Cross-VM Side Channel Attacks in IaaS Cloud. In Proceedings of the 2016 IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), San Francisco, CA, USA, 10–14 April 2016; pp. 181–186. [Google Scholar]
- Hardt, D. The OAuth 2.0 Authorization Framework. RFC Editor, RFC 6749. October 2012. Available online: https://www.rfc-editor.org/info/rfc6749 (accessed on 14 December 2024).
- Jones, M.; Hardt, D. The OAuth 2.0 Authorization Framework: Bearer Token Usage. RFC Editor, RFC 6750. October 2012. Available online: https://www.rfc-editor.org/info/rfc6750 (accessed on 14 December 2024).
- Jones, N.S.M.; Bradley, J. JSON Web Token (JWT). RFC Editor, RFC 7519. May 2015. Available online: https://datatracker.ietf.org/doc/html/rfc7519 (accessed on 14 December 2024).
- Microsoft. Sidecar Pattern- Azure Architecture Center. June 2022. Available online: https://docs.microsoft.com/en-us/azure/architecture/patterns/sidecar (accessed on 26 June 2022).
- Github-Pistacheio/Pistache: A High-Performance REST Toolkit Written in C++. Available online: https://github.com/pistacheio/pistache (accessed on 27 June 2022).
- OpenAPI Generator. Available online: https://openapi-generator.tech/ (accessed on 5 June 2022).
- Kim, B.; Sagduyu, Y.E.; Davaslioglu, K.; Erpek, T.; Ulukus, S. Channel-aware adversarial attacks against deep learning-based wireless signal classifiers. IEEE Trans. Wirel. Commun. 2020, 21, 3868–3880. [Google Scholar]
- Joda, R.; Pamuklu, T.; Iturria-Rivera, P.E.; Erol-Kantarci, M. Deep Reinforcement Learning-Based Joint User Association and CU–DU Placement in ORAN. IEEE Trans. Netw. Serv. Manag. 2022, 19, 4097–4110. [Google Scholar] [CrossRef]
- Li, P.; Thomas, J.; Wang, X.; Khalil, A.; Ahmad, A.; Inacio, R.; Kapoor, S.; Parekh, A.; Doufexi, A.; Shojaeifard, A.; et al. RLOps: Development Life-Cycle of Reinforcement Learning Aided Open RAN. IEEE Access 2022, 10, 113808–113826. [Google Scholar] [CrossRef]
- Korrai, P.; Lagunas, E.; Sharma, S.K.; Chatzinotas, S.; Bandi, A.; Ottersten, B. A RAN resource slicing mechanism for multiplexing of eMBB and URLLC services in OFDMA based 5G wireless networks. IEEE Access 2020, 8, 45674–45688. [Google Scholar]
- Azimi, Y.; Yousefi, S.; Kalbkhani, H.; Kunz, T. Applications of Machine Learning in Resource Management for RAN-Slicing in 5G and Beyond Networks: A Survey. IEEE Access 2022, 10, 106581–106612. [Google Scholar] [CrossRef]
- Polese, M.; Bonati, L.; D’oro, S.; Basagni, S.; Melodia, T. Understanding O-RAN: Architecture, interfaces, algorithms, security, and research challenges. IEEE Commun. Surv. Tutorials 2023, 25, 1376–1411. [Google Scholar]
- Hung, C.-F.; Chen, Y.-R.; Tseng, C.-H.; Cheng, S.-M. Security threats to xApps access control and E2 interface in O-RAN. IEEE Open J. Commun. Soc. 2024, 5, 1197–1203. [Google Scholar]
- Song, J.; Kovács, I.Z.; Butt, M.; Steiner, J.; Pedersen, K.I. Intra-RAN Online Distributed Reinforcement Learning For Uplink Power Control in 5G Cellular Networks. In Proceedings of the 2022 IEEE 95th Vehicular Technology Conference: (VTC2022-Spring), Helsinki, Finland, 19–22 June 2022; pp. 1–7. [Google Scholar] [CrossRef]
- Yungaicela-Naula, N.M.; Sharma, V.; Scott-Hayward, S. Misconfiguration in O-RAN: Analysis of the impact of AI/ML. Comput. Netw. 2024, 247, 110455. [Google Scholar]
- Azari, M.M.; Solanki, S.; Chatzinotas, S.; Kodheli, O.; Sallouha, H.; Colpaert, A.; Montoya, J.F.M.; Pollin, S.; Haqiqatnejad, A.; Mostaani, A.; et al. Evolution of Non-Terrestrial Networks From 5G to 6G: A Survey. IEEE Commun. Surv. Tutorials 2022, 24, 2633–2672. [Google Scholar] [CrossRef]
- Kumar, S. Exp_fric, [GitLab Repository]. Available online: https://gitlab.surrey.ac.uk/sk4sunil/exp_fric (accessed on 22 February 2025).
- Xu, H.; Sun, X.; Yang, H.H.; Guo, Z.; Liu, P.; Quek, T.Q.S. Fair Coexistence in Unlicensed Band for Next Generation Multiple Access: The Art of Learning. In Proceedings of the ICC 2022–IEEE International Conference on Communications, Seoul, Republic of Korea, 16–20 May 2022; pp. 2132–2137. [Google Scholar] [CrossRef]
- Zhang, C.; Nguyen, K.K.; Cheriet, M. Joint Routing and Packet Scheduling For URLLC and eMBB traffic in 5G ORAN. In Proceedings of the ICC 2022—IEEE International Conference on Communications, Seoul, Republic of Korea, 16–20 May 2022; pp. 1900–1905. [Google Scholar] [CrossRef]
- Ramezanpour, K.; Jagannath, J. Intelligent zero trust architecture for 5G/6G networks: Principles, challenges, and the role of machine learning in the context of O-RAN. Comput. Netw. 2022, 217, 109358. [Google Scholar] [CrossRef]
- Sedar, R.; Kalalas, C.; Alonso-Zarate, J.; Vázquez-Gallego, F. Multi-domain Denial-of-Service Attacks in Internet-of-Vehicles: Vulnerability Insights and Detection Performance. In Proceedings of the 2022 IEEE 8th International Conference on Network Softwarization (NetSoft), Milan, Italy, 27 June–1 July 2022; pp. 438–443. [Google Scholar] [CrossRef]
- Stafford, V. Zero trust architecture. NIST Spec. Publ. 2020, 800, 207. [Google Scholar]
- Sen, N. Intelligent Admission and Placement of ORAN Slices Using Deep Reinforcement Learning. In Proceedings of the 2022 IEEE 8th International Conference on Network Softwarization (NetSoft), Milan, Italy, 27 June–1 July 2022; pp. 307–311. [Google Scholar] [CrossRef]
- Pham, C.; Fami, F.; Nguyen, K.K.; Cheriet, M. When RAN Intelligent Controller in ORAN Meets Multi-UAV Enable Wireless Network. IEEE Trans. Cloud Comput. 2022, 11, 2245–2259. [Google Scholar] [CrossRef]
- Liang, X.; Shetty, S.; Tosh, D.; Kamhoua, C.; Kwiat, K.; Njilla, L. ProvChain: A blockchain-based data provenance architecture in cloud environment with enhanced privacy and availability. In Proceedings of the 2017 17th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (CCGRID), Madrid, Spain, 14–17 May 2017; pp. 468–477. [Google Scholar]
- Abedin, S.F.; Mahmood, A.; Tran, N.H.; Han, Z.; Gidlund, M. Elastic ORAN Slicing for Industrial Monitoring and Control: A Distributed Matching Game and Deep Reinforcement Learning Approach. IEEE Trans. Veh. Technol. 2022, 71, 10808–10822. [Google Scholar] [CrossRef]
- Polese, M.; Bonati, L.; D’Oro, S.; Basagni, S.; Melodia, T. ColORAN: Developing Machine Learning-based xApps for Open RAN Closed-loop Control on Programmable Experimental Platforms. IEEE Trans. Mob. Comput. 2022, 22, 5787–5800. [Google Scholar] [CrossRef]
- Peng, Z.; Zhang, Z.; Kong, L.; Pan, C.; Li, L.; Wang, J. Deep Reinforcement Learning for RIS-Aided Multiuser Full-Duplex Secure Communications with Hardware Impairments. IEEE Internet Things J. 2022, 9, 21121–21135. [Google Scholar] [CrossRef]
- Jordan, E. The Ultimate Guide to Open RAN: Open RAN Intelligent Controller (RIC)—Part 1; The Fast Mode: Petaling Jaya, Malaysia, 2024. [Google Scholar]
- Tran, T.D.; Nguyen, K.-K.; Cheriet, M. Joint Route Selection and Content Caching in ORAN Architecture. In Proceedings of the 2022 IEEE Wireless Communications and Networking Conference (WCNC), Austin, TX, USA, 10–13 April 2022; pp. 2250–2255. [Google Scholar] [CrossRef]
- Huang, J.; Yang, Y.; Gao, Z.; He, D.; Ng, D.W.K. Dynamic Spectrum Access for D2D-Enabled Internet of Things: A Deep Reinforcement Learning Approach. IEEE Internet Things J. 2022, 9, 17793–17807. [Google Scholar] [CrossRef]
- Richard, J. Open RAN—Understanding the Architecture and Deployment; HackMD: Hsinchu, Taiwan, 2021; Available online: https://hackmd.io/@jonathanrichard/HJp1cvYeO (accessed on 1 December 2024).
- Faisal, K.M.; Choi, W. Machine Learning Approaches for Reconfigurable Intelligent Surfaces: A Survey. IEEE Access 2022, 10, 27343–27367. [Google Scholar] [CrossRef]
- Polese, M.; Bonati, L.; D’Oro, S.; Basagni, S.; Melodia, T. Understanding O-RAN: Architecture, Interfaces, Algorithms, Security, and Research Challenges. arXiv 2022, arXiv:2202.01032. [Google Scholar]
- Alwarafy, A.; Abdallah, M.; Çiftler, B.S.; Al-Fuqaha, A.; Hamdi, M. The Frontiers of Deep Reinforcement Learning for Resource Management in Future Wireless HetNets: Techniques, Challenges, and Research Directions. IEEE Open J. Commun. Soc. 2022, 3, 322–365. [Google Scholar] [CrossRef]
- Abdalla, A.S.; Upadhyaya, P.S.; Shah, V.K.; Marojevic, V. Toward Next Generation Open Radio Access Networks: What O-RAN Can and Cannot Do! IEEE Netw. 2022, 36, 206–213. [Google Scholar] [CrossRef]
- Kim, E.; Choi, H.-H.; Kim, H.; Na, J.; Lee, H. Optimal Resource Allocation Considering Non-Uniform Spatial Traffic Distribution in Ultra-Dense Networks: A Multi-Agent Reinforcement Learning Approach. IEEE Access 2022, 10, 20455–20464. [Google Scholar] [CrossRef]
- Nomikos, N.; Zoupanos, S.; Charalambous, T.; Krikidis, I. A Survey on Reinforcement Learning-Aided Caching in Heterogeneous Mobile Edge Networks. IEEE Access 2022, 10, 4380–4413. [Google Scholar] [CrossRef]
- Brik, B.; Boutiba, K.; Ksentini, A. Deep Learning for B5G Open Radio Access Network: Evolution, Survey, Case Studies, and Challenges. IEEE Open J. Commun. Soc. 2022, 3, 228–250. [Google Scholar]
- Cao, Y.; Lien, S.-Y.; Liang, Y.-C.; Chen, K.-C.; Shen, X. User Access Control in Open Radio Access Networks: A Federated Deep Reinforcement Learning Approach. IEEE Trans. Wirel. Commun. 2022, 21, 3721–3736. [Google Scholar] [CrossRef]
- Addad, R.A.; Dutra, D.L.C.; Taleb, T.; Flinck, H. AI-Based Network-Aware Service Function Chain Migration in 5G and Beyond Networks. IEEE Trans. Netw. Serv. Manag. 2022, 19, 472–484. [Google Scholar] [CrossRef]
- Peng, M.; Sun, Y.; Li, X.; Mao, Z.; Wang, C. Recent Advances in Cloud Radio Access Networks: System Architectures, Key Techniques, and Open Issues. IEEE Commun. Surv. Tutorials 2016, 18, 2282–2308. [Google Scholar] [CrossRef]
- Ayala-Romero, J.A.; Garcia-Saavedra, A.; Gramaglia, M.; Costa-Pérez, X.; Banchs, A.; Alcaraz, J.J. vrAIn: Deep Learning Based Orchestration for Computing and Radio Resources in vRANs. IEEE Trans. Mob. Comput. 2022, 21, 2652–2670. [Google Scholar] [CrossRef]
- Orhan, O.; Swamy, V.N.; Tetzlaff, T.; Nassar, M.; Nikopour, H.; Talwar, S. Connection Management xAPP for ORAN RIC: A Graph Neural Network and Reinforcement Learning Approach. In Proceedings of the 2021 20th IEEE International Conference on Machine Learning and Applications (ICMLA), Pasadena, CA, USA, 13–16 December 2021; pp. 936–941. [Google Scholar] [CrossRef]
- Open Networking Foundation. Software-Defined Networking (SDN) Definition. Available online: https://opennetworking.org/sdn-definition/ (accessed on 21 December 2022).
- Lee, H.; Jang, Y.; Song, J.; Yeon, H. ORAN AI/ML Workflow Implementation of Personalized Network Optimization via Reinforcement Learning. In Proceedings of the 021 IEEE Globecom Workshops (GC Wkshps), Madrid, Spain, 7–11 December 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Bauer, A.; Lesch, V.; Versluis, L.; Ilyushkin, A.; Herbst, N.; Kounev, S. Chamulteon: Coordinated Auto-Scaling of Micro-Services. In Proceedings of the 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS), Dallas, TX, USA, 7–10 July 2019. [Google Scholar]
- Mao, M.; Humphrey, M. Auto-scaling to minimize cost and meet application deadlines in cloud workflows. In Proceedings of the 2011 International Conference for High Performance Computing, Networking, Storage and Analysis (SC’11), Seattle, WA, USA, 12–18 November 2011; Article No. 49. pp. 1–12. [Google Scholar] [CrossRef]
- Arabnejad, V.; Bubendorfer, K.; Ng, B. Dynamic multi-workflow scheduling: A deadline and cost-aware approach for commercial clouds. Future Gener. Comput. Syst. 2019, 100, 98–108. [Google Scholar] [CrossRef]
- Shahin, A.A. Automatic Cloud Resource Scaling Algorithm based on Long Short-Term Memory Recurrent Neural Network. Int. J. Adv. Comput. Sci. Appl. (IJACSA) 2016, 7, 201–207. [Google Scholar] [CrossRef]
- Das, S.; Li, F.; Narasayya, V.R.; König, A.C. Automated Demand-driven Resource Scaling in Relational Database-as-a-Service. In Proceedings of the SIGMOD/PODS’16: International Conference on Management of Data, San Francisco, CA, USA, 26 June–1 July 2016; Microsoft Research: Redmond, WA, USA, 2016. [Google Scholar]
- Rimedolabs. O-RAN Near Real-Time RIC. Available online: https://rimedolabs.com/blog/o-ran-near-real-time-ric/ (accessed on 24 January 2025).
- Golkarifard, M.; Jin, Y. Dynamic VNF Placement, Resource Allocation and Traffic Engineering with Proactive Demand Prediction. arXiv 2021, arXiv:2104.12345, 12345. [Google Scholar]
- Chetty, S.B.; Nag, A.; Al-Tahmeesschi, A.; Wang, Q.; Canberk, B.; Marquez-Barja, J.; Ahmadi, H. Optimized Resource Allocation for Cloud-Native 6G Networks: Zero-Touch ML Models in Microservices-based VNF Deployments. arXiv 2024, arXiv:2410.06938v1. [Google Scholar] [CrossRef]
- Tran, N.P.; Delgado, O.; Jaumard, B. Proactive Service Assurance in 5G and B5G Networks: A Closed-Loop Algorithm for End-to-End Network Slicing. arXiv 2024, arXiv:2404.01523v1. [Google Scholar]
- D’Oro, S.; Bonati, L.; Polese, M.; Melodia, T. OrchestRAN: Network Automation through Orchestrated Intelligence in the Open RAN. arXiv 2022, arXiv:2201.05632. [Google Scholar]
- Lo Schiavo, L.; Garcia-Aviles, G.; Garcia-Saavedra, A.; Gramaglia, M.; Fiore, M.; Banchs, A.; Costa-Perez, X. CloudRIC: Open Radio Access Network (O-RAN) Virtualization with Shared Heterogeneous Computing. In Proceedings of the 30th Annual International Conference on Mobile Computing and Networking, Washington, DC, USA, 18–22 November 2024; ACM MobiCom ’24. pp. 558–572. [Google Scholar] [CrossRef]
- Dai, J.; Li, L.; Safavinejad, R.; Mahboob, S.; Chen, H.; Ratnam, V.V. O-RAN-Enabled Intelligent Network Slicing to Meet Service-Level Agreement (SLA). IEEE Trans. Mob. Comput. 2024, 24, 890–906. [Google Scholar]
- Chen, Y.; Wang, X. Deep Learning-Based Forecasting Model for Network Slice Scaling. IEEE Trans. Netw. Serv. Manag. 2022, 18, 456–468. [Google Scholar]
- Patel, R.; Gupta, S. Markov Decision Process-Based Predictive Autoscaling in Cloud-Native Environments. ACM Trans. Auton. Adapt. Syst. 2021, 16, 23–38. [Google Scholar]
- Zhang, L.; Kim, H. Reinforcement Learning for Real-Time Resource Scaling in ORAN. Proc. IEEE INFOCOM 2023, 1015–1024. [Google Scholar]
- Smith, B.; Lee, J. OpenStack Tacker: Policy-Based Scaling for VNFs. IEEE Cloud Comput. 2022, 9, 78–85. [Google Scholar]
- Capone, A.; D’Elia, S.; Filippini, I.; Zangani, M. Measurement-based energy consumption profiling of mobile radio networks. In Proceedings of the 2015 IEEE 1st International Forum on Research and Technologies for Society and Industry Leveraging a Better Tomorrow (RTSI), Turin, Italy, 16–18 September 2015; pp. 127–131. [Google Scholar] [CrossRef]
- Bonati, L. Softwarized Approaches for the Open RAN of NextG Cellular Networks. Ph.D. Thesis, Northeastern University, Boston, MA, USA, 2022. [Google Scholar] [CrossRef]
- Nguyen, H.; Brown, T. Unikernels for Lightweight Virtualization in Edge Computing. ACM Comput. Surv. 2023, 55, 1–27. [Google Scholar]
- Lopez, D.; Martinez, F. Comparing Kubernetes with ETSI MANO for Network Function Orchestration. Proc. IEEE NFV-SDN 2022, 223–230. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Deployment YAML (expric-deployment.yaml) | |
| replicas | 1 |
| containerPort (1) | 36,421 |
| containerPort (2) | 36,422 |
| imagePullPolicy | IfNotPresent |
| requests.cpu | 100 m |
| requests.memory | 128 Mi |
| limits.cpu | 600 m |
| limits.memory | 1500 Mi |
| selector.app | expric |
| ports.protocol | SCTP |
| Horizontal Pod Autoscaler YAML (expric-hpa.yaml) | |
| scaleTargetRef.apiVersion | apps/v1 |
| scaleTargetRef.kind | Deployment |
| scaleTargetRef.name | expric-deployment-1 |
| minReplicas | 1 |
| maxReplicas | 3 |
| targetCPUUtilizationPercentage | 80% |
| idleTimeBeforeScaleDown | 180 s |
| Server (S) | Max xApp | Avg Latency (ms) | CPU Uti. (%) |
|---|---|---|---|
| 5 | 800 | 250 | 60 |
| 10 | 1200 | 350 | 70 |
| 15 | 1400 | 500 | 80 |
| 25 | 1600 | 700 | 90 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kumar, S. ORAN-HAutoscaling: A Scalable and Efficient Resource Optimization Framework for Open Radio Access Networks with Performance Improvements. Information 2025, 16, 259. https://doi.org/10.3390/info16040259
Kumar S. ORAN-HAutoscaling: A Scalable and Efficient Resource Optimization Framework for Open Radio Access Networks with Performance Improvements. Information. 2025; 16(4):259. https://doi.org/10.3390/info16040259
Chicago/Turabian StyleKumar, Sunil. 2025. "ORAN-HAutoscaling: A Scalable and Efficient Resource Optimization Framework for Open Radio Access Networks with Performance Improvements" Information 16, no. 4: 259. https://doi.org/10.3390/info16040259
APA StyleKumar, S. (2025). ORAN-HAutoscaling: A Scalable and Efficient Resource Optimization Framework for Open Radio Access Networks with Performance Improvements. Information, 16(4), 259. https://doi.org/10.3390/info16040259