
Aspect-Based Sentiment Analysis Through Graph Convolutional Networks and Joint Task Learning

 ,
,
Abstract

1. Introduction
- This study presents an innovative aspect-based sentiment analysis model (MTL-GCN) that integrates graph convolutional networks into a joint task learning framework. By introducing a feature-sharing mechanism to promote information interaction between tasks, aspect term extraction is effectively leveraged to provide deep semantic features for the sentiment classification task, thereby improving the overall performance.
- In terms of method design, we redesign the traditional GCN. By introducing the relative positional information of nodes, P-GCNs are proposed, which significantly enhance the modeling capability of syntactic dependencies and focus on the positional information of aspect terms.
- We propose a context feature representation method that combines graph convolutional networks with the multi-head attention mechanism, comprehensively integrating the local and global semantic information within the text.
- Finally, experiments on multiple benchmark datasets validate the superior performance of the proposed model in aspect term extraction and sentiment classification tasks.
2. Related Work
3. Methodology
3.1. Task Definition
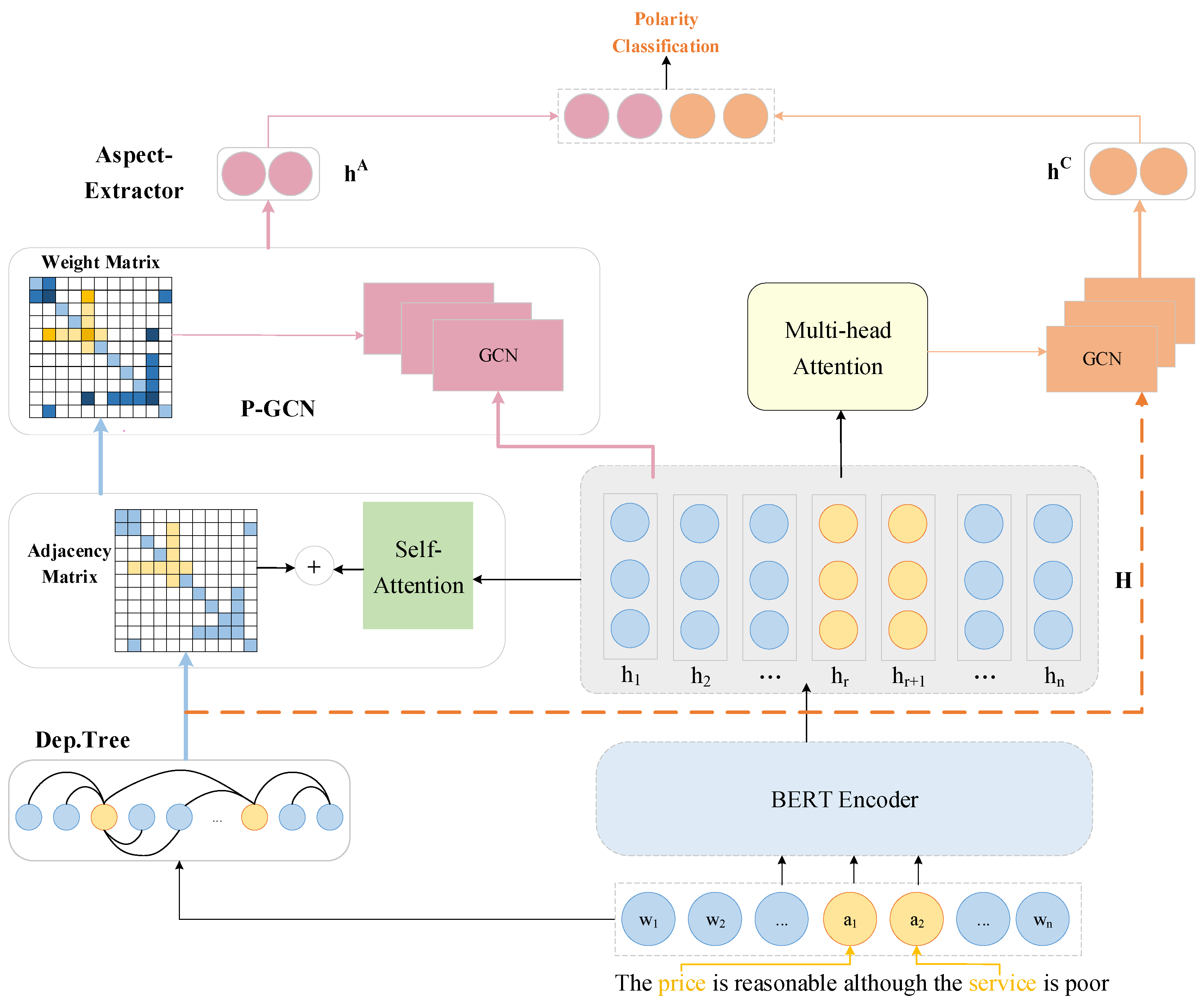
3.2. Overview of the Model Framework
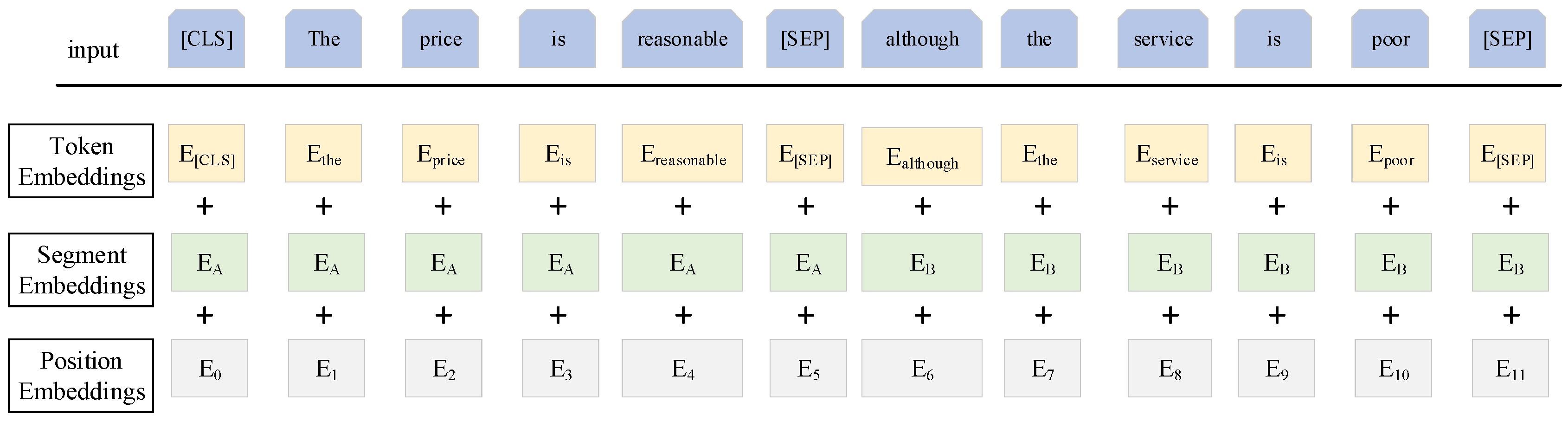
3.3. Context-Encoder
3.4. Aspect Terms Extraction
3.4.1. Construction of the Dependency Tree
3.4.2. Calculation of the Weight Matrix
3.4.3. Position-Focused Graph Convolutional Networks
3.5. Contextual Feature Representation
Multi-Head Attention Mechanism and Graph Convolutional Network
3.6. Sentiment Polarity Classification
3.7. Model Training
4. Experiments
4.1. Datasets and Parameter Settings
4.1.1. Datasets
4.1.2. Experimental Parameter Settings
4.2. Evaluation and Criteria
4.3. Compared Models
4.3.1. Aspect Term Extraction Model
- DTBCSNN [24]: A dependency tree-based stacked convolutional neural network was proposed, which uses conditional random fields (CRFs) to accurately extract aspect terms.
- RAL [25]: A reinforcement learning-based active learning sampling strategy was proposed to optimize the aspect term extraction process, improving extraction efficiency and accuracy.
- LDA [26]: An unsupervised learning method was proposed, which identifies potential topics of user interest and achieves automatic aspect term extraction through the guidance of a small set of seed words.
- DA-DCGCN [10]: A method for aspect term extraction combining dynamic attention mechanism and dense connection graph convolutional network (DA-DCGCN) is proposed.
4.3.2. Aspect Sentiment Classification Model
- DualGCN [27]: A dual graph convolutional network model including SynGCN and SemGCN modules for capturing syntactic structures and semantic connections separately.
- SDGCN-BERT [28]: An ABSA model through graph convolutional networks. By introducing a bi-directional attention mechanism with positional encoding and a GCN module, the model effectively captures sentiment dependencies between multiple aspects in a sentence.
- MHAGCN [21]: A model using hierarchical multi-head attention mechanisms and graph convolutional networks, thoroughly considering syntactic dependencies and combining semantic information to provide deep interaction among aspect terms and context.
- SS-GCN [14]: This model enhances semantic representation for aspect-level sentiment analysis through graph convolutional networks by automatically learning syntactic weight matrices and integrating syntactic and semantic information, thereby capturing aspect sentiment more accurately.
4.3.3. Multi-Task Joint Learning Model
- MNN [29]: Utilizes a unified sequence labeling scheme to define training tasks, simultaneously performing aspect term extraction and sentiment classification.
- LCF-ATEPC [30]: A multi-task learning model for Chinese ABSA that is capable of simultaneously extracting aspect terms and inferring their sentiment polarities.
- MTABSA [16]: Combines aspect term extraction and sentiment polarity classification in a multitask learning framework, leveraging multi-head attention and RGAT to capture key dependency relations and enhance classification performance.
- BLAB [17]: By integrating the AD-BiReGU module into the BERT-LCF framework, aspect term extraction and fine-grained sentiment analysis are performed simultaneously, addressing the limitation of existing models that primarily focus on a single task.
4.4. Main Results
4.5. Ablation Study
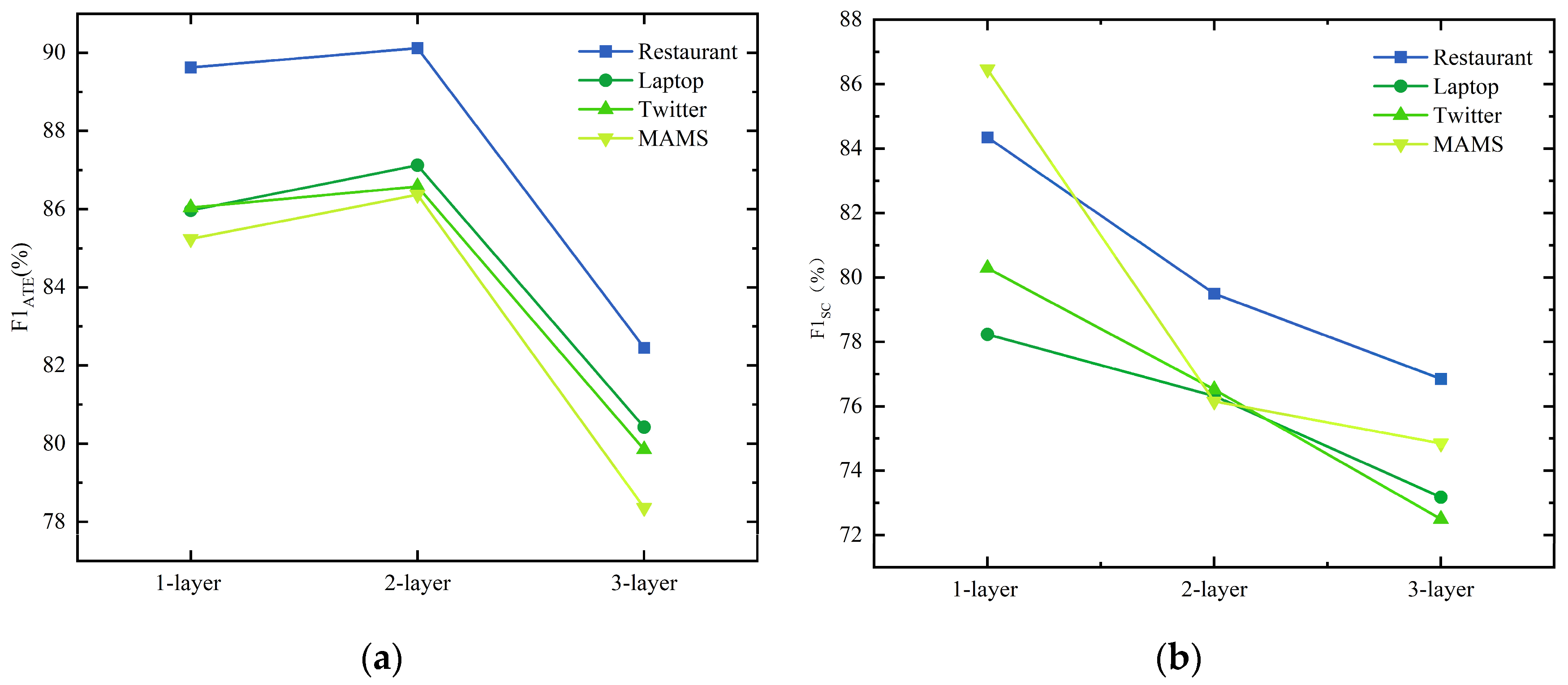
4.6. Impact of GCN Layers
4.7. Visualization of Attention Weights
4.8. Case Study
5. Conclusions and Future Work
5.1. Conclusions
5.2. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| BERT | Bidirectional encoder representations from transformers |
| ATE | Aspect term extraction |
| SC | Sentiment polarity classification |
| RGAT | Relational graph attention network |
| Pos | Positive |
| Neu | Neutral |
| Neg | Negative |
References
- Chen, Z.; Qian, T. Enhancing aspect term extraction with soft prototypes. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 2107–2117. [Google Scholar]
- Liang, S.; Wei, W.; Mao, X.-L.; Wang, F.; He, Z. BiSyn-GAT+: Bi-syntax aware graph attention network for aspect-based sentiment analysis. arXiv 2022, arXiv:2204.03117. [Google Scholar]
- Kenton, J.D.M.-W.C.; Toutanova, L.K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019. [Google Scholar]
- Wang, W.; Pan, S.J.; Dahlmeier, D.; Xiao, X. Coupled multi-layer attentions for co-extraction of aspect and opinion terms. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Yang, Y.; Li, K.; Quan, X.; Shen, W.; Su, Q. Constituency lattice encoding for aspect term extraction. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; pp. 844–855. [Google Scholar]
- Ji, B.; Liu, R.; Li, S.; Tang, J.; Yu, J.; Li, Q.; Xu, W. A BILSTM-CRF method to Chinese electronic medical record named entity recognition. In Proceedings of the 2018 International Conference on Algorithms, Computing and Artificial Intelligence, Sanya China, 21–23 December 2018; pp. 1–6. [Google Scholar]
- Phan, M.H.; Ogunbona, P.O. Modelling context and syntactical features for aspect-based sentiment analysis. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 3211–3220. [Google Scholar]
- Chen, G.; Tian, Y.; Song, Y. Joint aspect extraction and sentiment analysis with directional graph convolutional networks. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; pp. 272–279. [Google Scholar]
- Ma, D.; Li, S.; Wu, F.; Xie, X.; Wang, H. Exploring sequence-to-sequence learning in aspect term extraction. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 3538–3547. [Google Scholar]
- Sun, X.; Mi, Y.; Liu, J.; Li, H. Aspect Term Extraction via Dynamic Attention and a Densely Connected Graph Convolutional Network. In Proceedings of the Pacific Rim International Conference on Artificial Intelligence, Kyoto, Japan, 18–24 November 2024; pp. 383–395. [Google Scholar]
- Luo, F.; Li, C.; Cao, Z. Affective-feature-based sentiment analysis using SVM classifier. In Proceedings of the 2016 IEEE 20th International Conference on Computer Supported Cooperative Work in Design (CSCWD), Nanchang, China, 4–6 May 2016; pp. 276–281. [Google Scholar]
- Das, S.; Kolya, A.K. Sense GST: Text mining & sentiment analysis of GST tweets by Naive Bayes algorithm. In Proceedings of the 2017 Third International Conference on Research in Computational Intelligence and Communication networks (ICRCICN), Kolkata, India, 3–5 November 2017; pp. 239–244. [Google Scholar]
- Zhang, Z.; Zhou, Z.; Wang, Y. SSEGCN: Syntactic and semantic enhanced graph convolutional network for aspect-based sentiment analysis. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Seattle, DC, USA, 10–15 July 2022; pp. 4916–4925. [Google Scholar]
- Chen, J.; Fan, H.; Wang, W. Syntactic and Semantic Aware Graph Convolutional Network for Aspect-based Sentiment Analysis. IEEE Access 2024, 12, 22500–22509. [Google Scholar] [CrossRef]
- Nguyen, H.; Shirai, K. A joint model of term extraction and polarity classification for aspect-based sentiment analysis. In Proceedings of the 2018 10th International Conference on Knowledge and Systems Engineering (KSE), Ho Chi Minh City, Vietnam, 1–3 November 2018; pp. 323–328. [Google Scholar]
- Zhao, G.; Luo, Y.; Chen, Q.; Qian, X. Aspect-based sentiment analysis via multitask learning for online reviews. Knowl.-Based Syst. 2023, 264, 110326. [Google Scholar] [CrossRef]
- Fan, X.; Zhang, Z. A fine-grained sentiment analysis model based on multi-task learning. In Proceedings of the 2024 4th International Symposium on Computer Technology and Information Science (ISCTIS), Xi’an, China, 12–14 July 2024; pp. 157–161. [Google Scholar]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv 2016, arXiv:1609.08144. [Google Scholar]
- Zhao, X.; Peng, H.; Dai, Q.; Bai, X.; Peng, H.; Liu, Y.; Guo, Q.; Yu, P.S. Rdgcn: Reinforced dependency graph convolutional network for aspect-based sentiment analysis. In Proceedings of the 17th ACM International Conference on Web Search and Data Mining, Merida, Mexico, 4–8 March 2024; pp. 976–984. [Google Scholar]
- Hamilton, W.; Ying, Z.; Leskovec, J. Inductive representation learning on large graphs. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Li, X.; Lu, R.; Liu, P.; Zhu, Z. Graph convolutional networks with hierarchical multi-head attention for aspect-level sentiment classification. J. Supercomput. 2022, 78, 14846–14865. [Google Scholar] [CrossRef] [PubMed]
- Jiang, Q.; Chen, L.; Xu, R.; Ao, X.; Yang, M. A challenge dataset and effective models for aspect-based sentiment analysis. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 6280–6285. [Google Scholar]
- Dong, L.; Wei, F.; Tan, C.; Tang, D.; Zhou, M.; Xu, K. Adaptive recursive neural network for target-dependent twitter sentiment classification. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Baltimore, Maryland, 23–25 June 2014; pp. 49–54. [Google Scholar]
- Ye, H.; Yan, Z.; Luo, Z.; Chao, W. Dependency-tree based convolutional neural networks for aspect term extraction. In Proceedings of the Advances in Knowledge Discovery and Data Mining: 21st Pacific-Asia Conference, PAKDD 2017, Jeju, South Korea, 23–26 May 2017; pp. 350–362. [Google Scholar]
- Venugopalan, M.; Gupta, D. A reinforced active learning approach for optimal sampling in aspect term extraction for sentiment analysis. Expert Syst. Appl. 2022, 209, 118228. [Google Scholar] [CrossRef]
- Venugopalan, M.; Gupta, D. An enhanced guided LDA model augmented with BERT based semantic strength for aspect term extraction in sentiment analysis. Knowl.-Based Syst. 2022, 246, 108668. [Google Scholar] [CrossRef]
- Li, R.; Chen, H.; Feng, F.; Ma, Z.; Wang, X.; Hovy, E. Dual graph convolutional networks for aspect-based sentiment analysis. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021; pp. 6319–6329. [Google Scholar]
- Zhao, P.; Hou, L.; Wu, O. Modeling sentiment dependencies with graph convolutional networks for aspect-level sentiment classification. Knowl.-Based Syst. 2020, 193, 105443. [Google Scholar] [CrossRef]
- Wang, F.; Lan, M.; Wang, W. Towards a one-stop solution to both aspect extraction and sentiment analysis tasks with neural multi-task learning. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar]
- Yang, H.; Zeng, B.; Yang, J.; Song, Y.; Xu, R. A multi-task learning model for chinese-oriented aspect polarity classification and aspect term extraction. Neurocomputing 2021, 419, 344–356. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Positive | Negative | Neutral | Total | |
|---|---|---|---|---|---|
| Restaurant 14 * | Train | 2164 | 807 | 637 | 3608 |
| Test | 727 | 196 | 196 | 1119 | |
| Laptop 14 * | Train | 937 | 851 | 455 | 2243 |
| Test | 337 | 128 | 167 | 632 | |
| Train | 1507 | 1528 | 3016 | 6051 | |
| Test | 172 | 169 | 336 | 677 | |
| MAMS | Train | 3380 | 2764 | 5042 | 11,186 |
| valid | 403 | 325 | 604 | 1332 | |
| Test | 400 | 329 | 607 | 1336 | |
| Hyper-Parameters | Value |
|---|---|
| word embedding dimension | 768 |
| batch size | 12 |
| learning rate | 2 × 10−5 |
| training epochs | 20 |
| dropout rate | 0.5 |
| optimizer | Adam |
| Models | Restaurant | Laptop | |
|---|---|---|---|
| F1ATE | F1ATE | F1ATE | |
| DTBCSN (2017) | 83.97 | 75.66 | 75.33 |
| RAL (2022) | 85.63 | 78.67 | 73.61 |
| LDA (2022) | 81.00 | 75.00 | 74.00 |
| DA-DCGCN (2024) | 87.61 | 82.74 | 83.42 |
| MTL-GCN | 89.02 | 84.73 | 86.04 |
| Models | Restaurant | Laptop | ||||
|---|---|---|---|---|---|---|
| Acc | F1SC | Acc | F1SC | Acc | F1SC | |
| SDGCN-BERT (2020) | 83.57 | 76.47 | 81.35 | 78.34 | — | — |
| DualGCN (2021) | 84.27 | 78.08 | 78.48 | 74.47 | 75.92 | 74.29 |
| MHAGCN (2022) | 82.57 | 75.83 | 79.06 | 75.70 | 74.53 | 73.75 |
| SS-GCN (2024) | 82.96 | 74.26 | 75.86 | 71.78 | — | — |
| MTL-GCN | 89.49 | 84.35 | 81.62 | 78.23 | 81.53 | 80.22 |
| Models | Restaurant | Laptop | MAMS | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F1ATE | Acc | F1SC | F1ATE | Acc | F1SC | F1ATE | Acc | F1SC | F1ATE | Acc | F1SC | |
| MNN (2018) | 83.05 | 77.17 | 68.50 | 76.94 | 70.40 | 65.98 | 72.05 | 71.05 | 63.87 | — | — | — |
| LCF-ATEPC (2021) | 88.45 | 86.77 | 80.54 | 83.32 | 80.97 | 77.86 | 85.12 | 76.7 | 74.54 | — | — | — |
| MTABSA (2023) | 87.45 | 86.88 | 81.16 | 81.55 | 80.56 | 77.00 | 87.33 | 76.21 | 74.34 | — | — | — |
| BLAB (2024) | 89.47 | 88.46 | 82.79 | 84.57 | 80.45 | 78.02 | 88.87 | 79.39 | 79.28 | 83.72 | 84.56 | 85.37 |
| MTL-GCN | 89.02 | 89.49 | 84.35 | 84.73 | 81.62 | 78.23 | 86.04 | 81.53 | 80.22 | 85.24 | 86.84 | 86.46 |
| Methods | Restaurant | Laptop | MAMS | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F1ATE | Acc | F1SC | F1ATE | Acc | F1SC | F1ATE | Acc | F1SC | F1ATE | Acc | F1SC | |
| MTL-GCN | 89.02 | 89.49 | 84.35 | 84.73 | 81.62 | 78.23 | 86.04 | 81.53 | 80.22 | 85.24 | 86.84 | 86.46 |
| P-GCN | 83.78 | 85.64 | 79.23 | 81.59 | 77.86 | 73.54 | 80.99 | 76.49 | 76.36 | 81.61 | 82.16 | 83.29 |
| MHA | 87.99 | 87.92 | 82.85 | 83.75 | 80.84 | 77.31 | 84.39 | 79.62 | 78.76 | 84.07 | 85.93 | 84.61 |
| Dep.tree | 85.13 | 86.91 | 80.05 | 82.53 | 78.19 | 76.26 | 83.62 | 79.76 | 78.51 | 82.01 | 84.87 | 84.23 |
| Review Samples | Model | Predicted Label |
|---|---|---|
| The food is uniformly exceptional, with a very capable kitchen that will proudly whip up whatever you feel like eating, whether it’s on the menu or not. Label (Aspect: { food, kitchen, menu } Polarity: {pos, pos, neu}) | MTABSA | Aspect:{ food, kitchen, menu } Polarity:{pos, pos, neg} |
| BLAB | Aspect:{ food, kitchen, menu } Polarity:{pos, pos, neu} | |
| MTL-GCN | Aspect:{ food, kitchen, menu } Polarity: {pos, pos, neu} | |
| The tech guy then said the service center does not do 1-to-1 exchange and I have to direct my concern to the “sales” team, which is the retail shop from which I bought my netbook. Label(Aspect: { tech guy, service center, “sales” team } Polarity: {neu, neg, neg}) | MTABSA | Aspect: { service center, “sales” team } Polarity:{ neg, neu} |
| BLAB | Aspect: { service center, “sales” team } Polarity:{ neg, neg} | |
| MTL-GCN | Aspect: { tech guy, service center, “sales” team } Polarity:{neu, neg, neg} |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, H.; Wang, S.; Qiao, B.; Dang, L.; Zou, X.; Xue, H.; Wang, Y. Aspect-Based Sentiment Analysis Through Graph Convolutional Networks and Joint Task Learning. Information 2025, 16, 201. https://doi.org/10.3390/info16030201
Han H, Wang S, Qiao B, Dang L, Zou X, Xue H, Wang Y. Aspect-Based Sentiment Analysis Through Graph Convolutional Networks and Joint Task Learning. Information. 2025; 16(3):201. https://doi.org/10.3390/info16030201
Chicago/Turabian StyleHan, Hongyu, Shengjie Wang, Baojun Qiao, Lanxue Dang, Xiaomei Zou, Hui Xue, and Yingqi Wang. 2025. "Aspect-Based Sentiment Analysis Through Graph Convolutional Networks and Joint Task Learning" Information 16, no. 3: 201. https://doi.org/10.3390/info16030201
APA StyleHan, H., Wang, S., Qiao, B., Dang, L., Zou, X., Xue, H., & Wang, Y. (2025). Aspect-Based Sentiment Analysis Through Graph Convolutional Networks and Joint Task Learning. Information, 16(3), 201. https://doi.org/10.3390/info16030201