
Greedy Prefetch for Reducing Off-Chip Memory Accesses in Convolutional Neural Network Inference


Abstract

1. Introduction
- We introduce a greedy prefetch method that leverages data repetition in the Activation Matrix, allowing for flexible determination of the prefetching route based on on-chip memory size, thereby expanding the applicability of this method.
- We propose a comprehensive solution from both software and hardware perspectives, with the core being the Greedily Scheduling Algorithm, Chunk-Replacing Process, and Chunk-Converting Process. By utilizing the prefetching route derived from software to drive the operation of hardware; this reduces off-chip memory accesses and enhances system efficiency.
- We also compared greedy prefetch method with other methods aimed at optimizing off-chip memory accesses, and experimental results demonstrate that our method excels in reducing off-chip memory accesses. Our deployment strategy outperforms recent works, reducing average off-chip bandwidth by 67.5% and achieving a maximum improvement of 1.98 times in data reuse.
2. The Related Works
2.1. Optimizations for Reducing Off-Chip Memory Accesses
2.2. Prefetching Methods for CNN Accelerators
3. The Part of Software
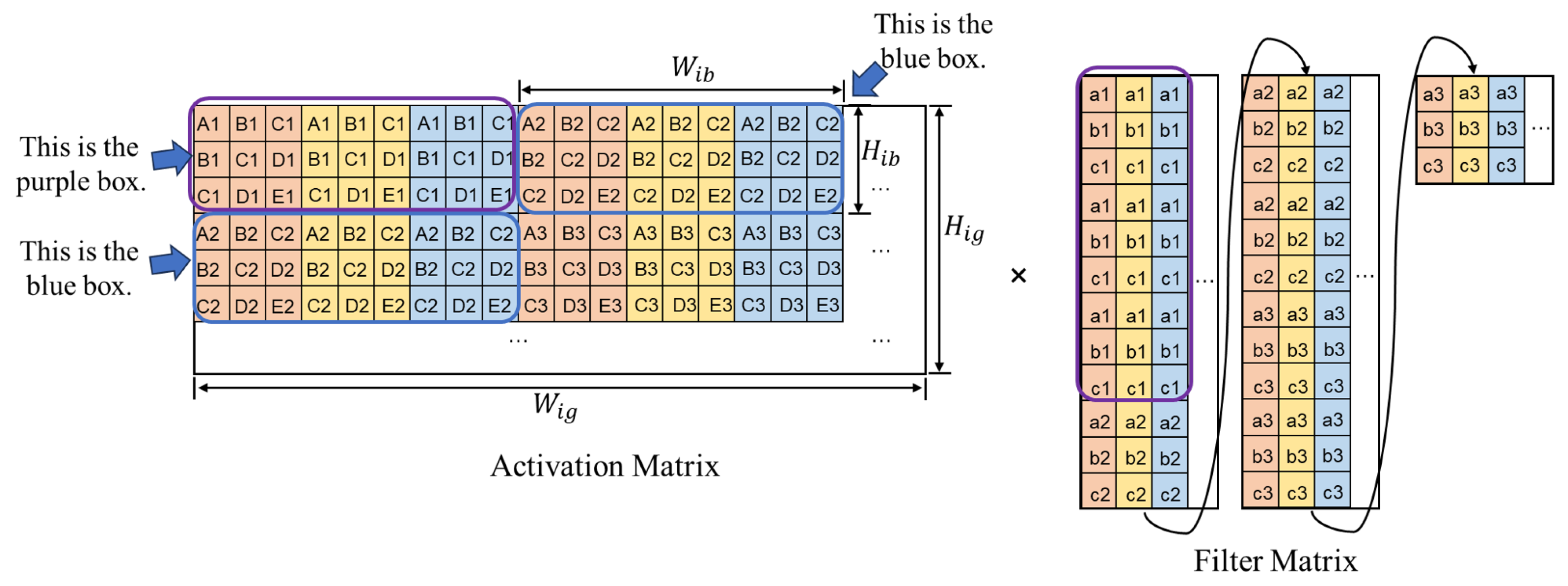
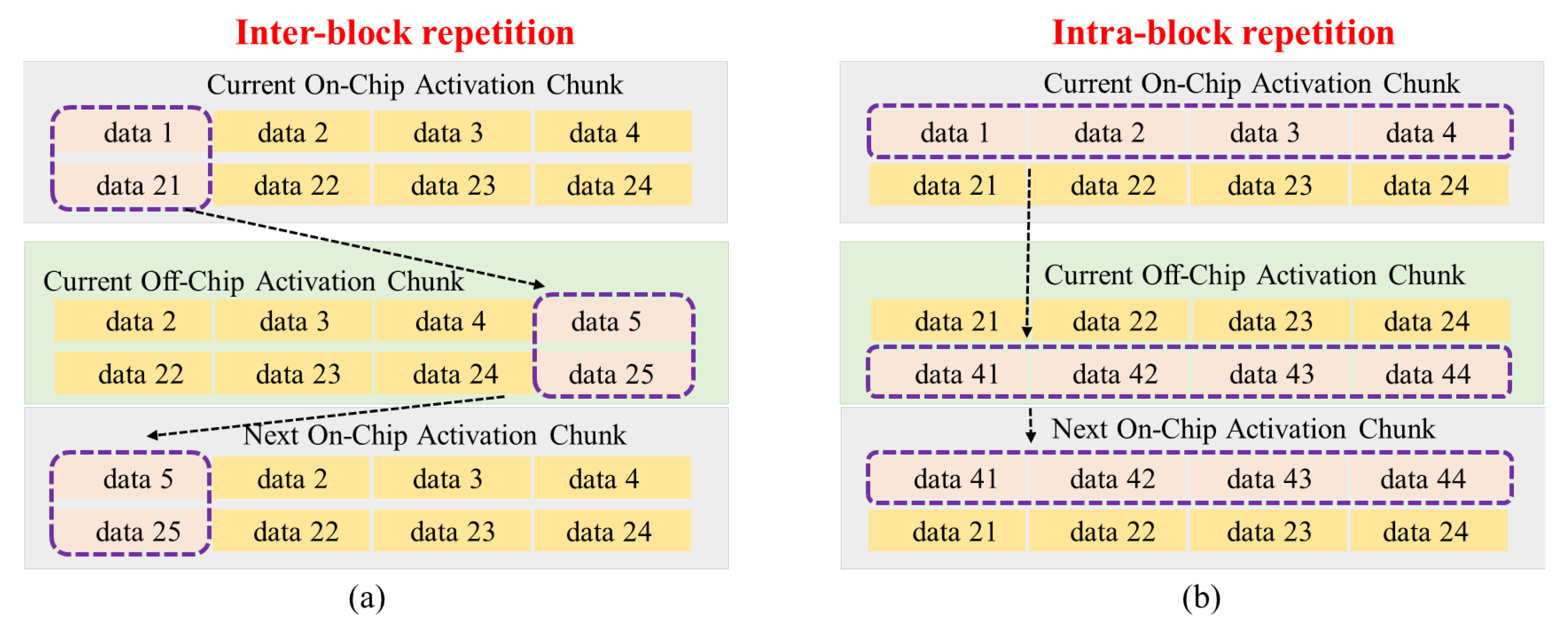
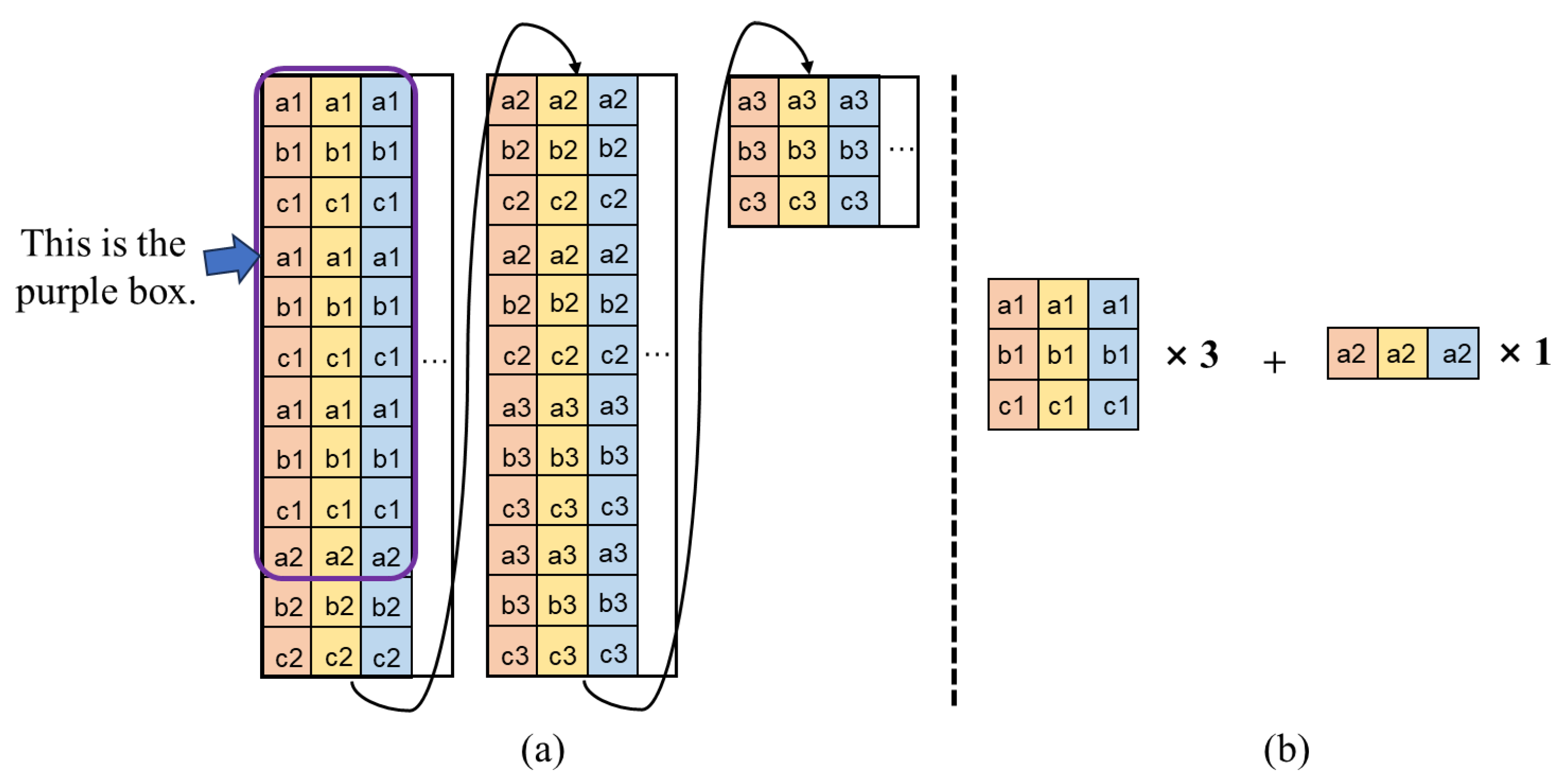
3.1. Data Repetition and Chunk Partition
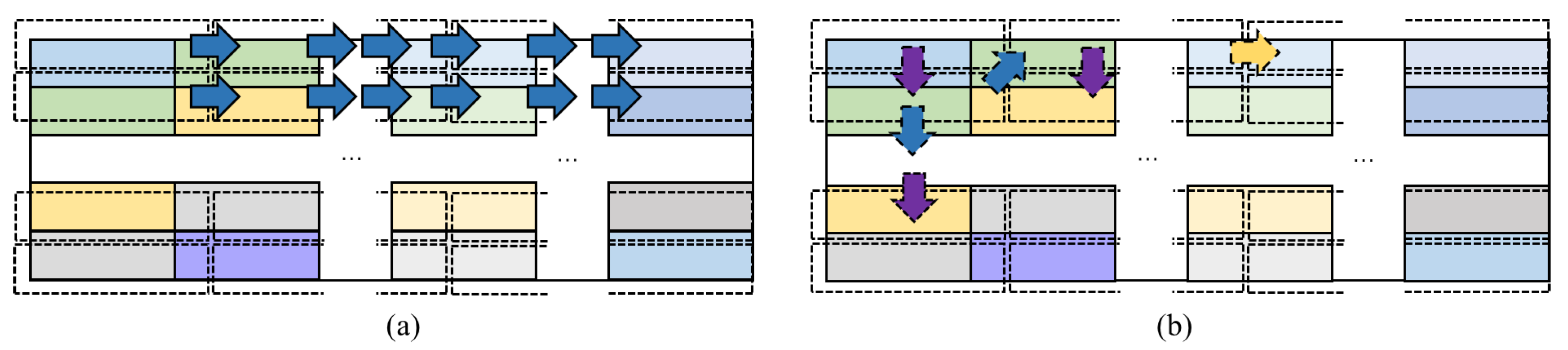
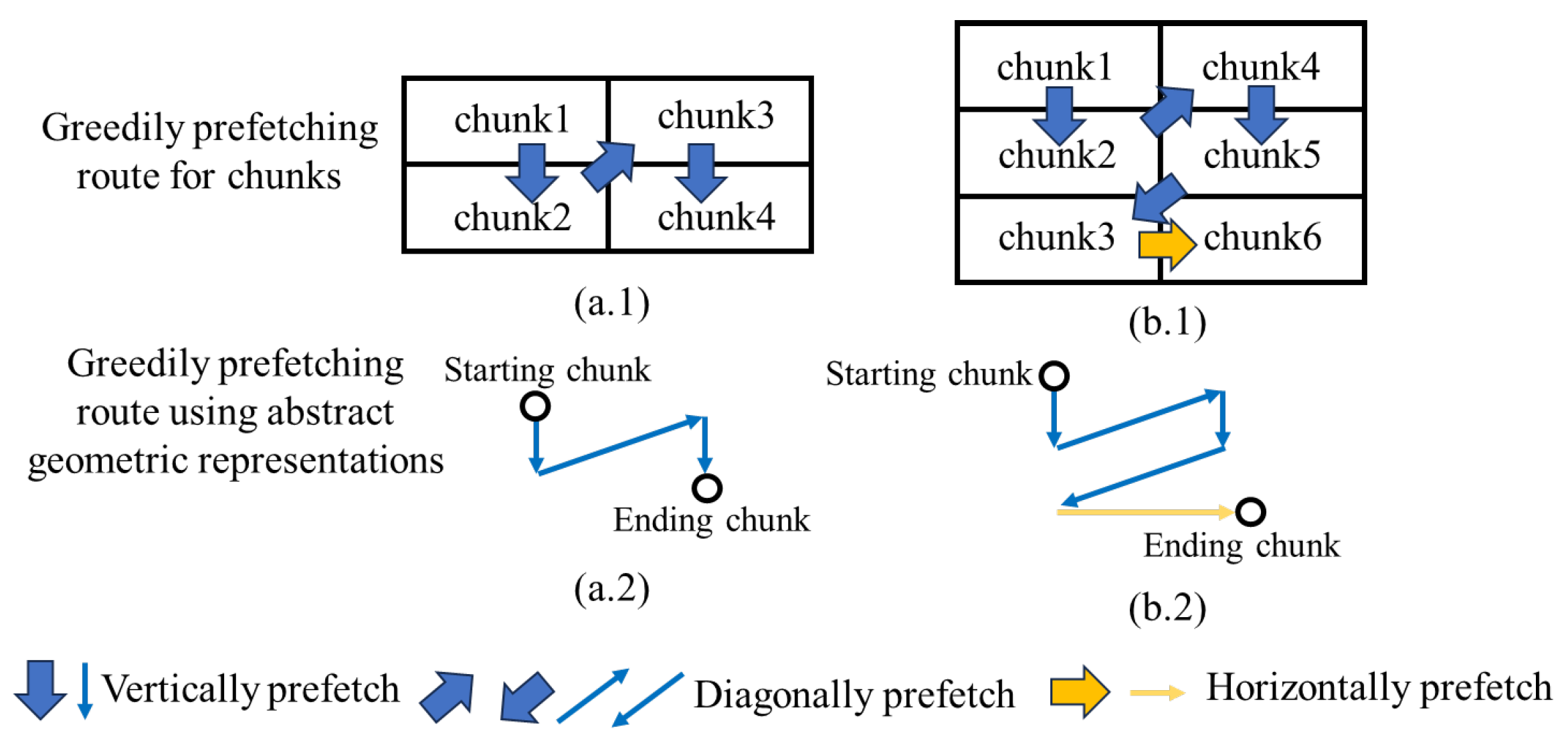
3.2. Prefetching Directions and Data Reuse
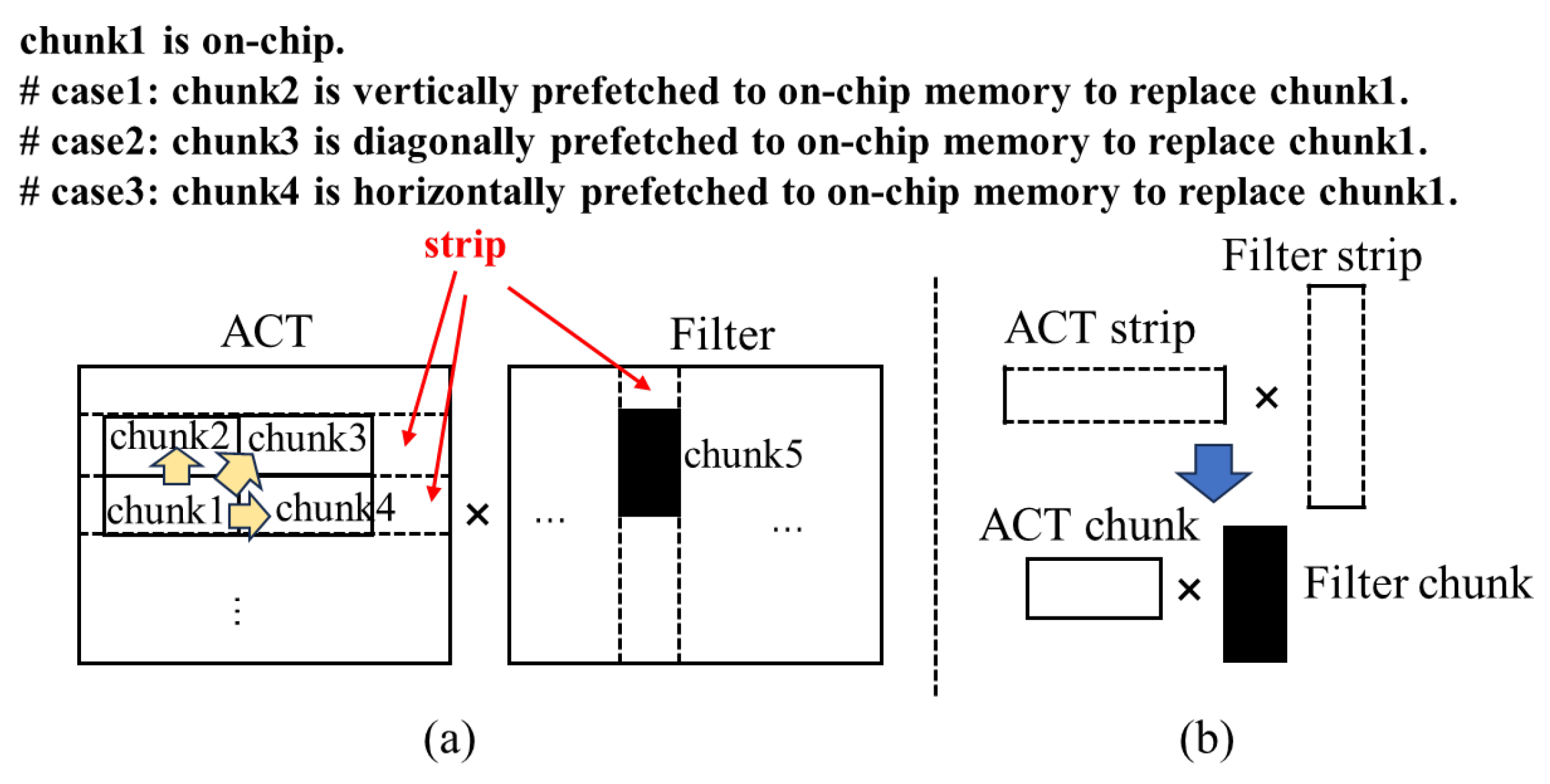
3.3. Greedily Scheduling Algorithm
3.3.1. Greedily Scheduling Algorithm for Activation
| Algorithm 1 Details of the Greedily Scheduling Algorithm for Activation. |
| Require: Height of Activation Chunk Matrix H, Width of Activation Chunk Matrix W |
| Ensure: Repetition Matrix |
| # Step 1. Fill the D. |
| for to W do |
| for to H do |
| # Find the repetitive data in each two chunks. |
| # Fill the number of repetitive data in D. |
| end for |
| end for |
| Ensure: Prefetching Route R, Chunk set , Set of converting index , Converting index , Set of replacing index , Replacing index , Current Off-Chip Activation Chunk , Current On-Chip Activation Chunk |
| # Step 2. Find the R, Sc, and Sr. |
| # Append c0 to R , delete c0 in C, and |
| while C do |
| # Find the maximal number of repetition in neighboring off-chip |
| chunks according to D. |
| # Find the off-chip chunk Cmax with maximal repetition for . |
| # Find the of non-repetitive data between Cmax and . |
| # Transform the Cmax into Next On-Chip Activation Chunk Cnmax. |
| # Find the between Cmax and Cnmax . |
| # Append Cmax to R and delete Cmax in C. |
| # and . |
| # Append to and . |
| # Append to and . |
| end while |
3.3.2. Greedily Scheduling Algorithm for Filter
| Algorithm 2 Details of the Greedily Scheduling Algorithm for the filter. |
| Require: Height of Filter Chunk H, Width of Filter Chunk W, Filter Chunk |
| Ensure: Set of reused convolution kernel data , Starting data , Set of repetition counts |
| , Directory of reused convolution kernel data |
| # Task: Find the above variables. |
| for to H do |
| for to W do |
| # If (h, w) is not in , then append (h, w) as a key to . |
| Otherwise, do not append (h, w) to . |
| # Find the value of (h, w) in and value ← value + 1. |
| end for |
| end for |
| # Select the keys of and append keys to . |
| # Select the values of , filter out distinct values, and append values to . |
4. The Part of Hardware
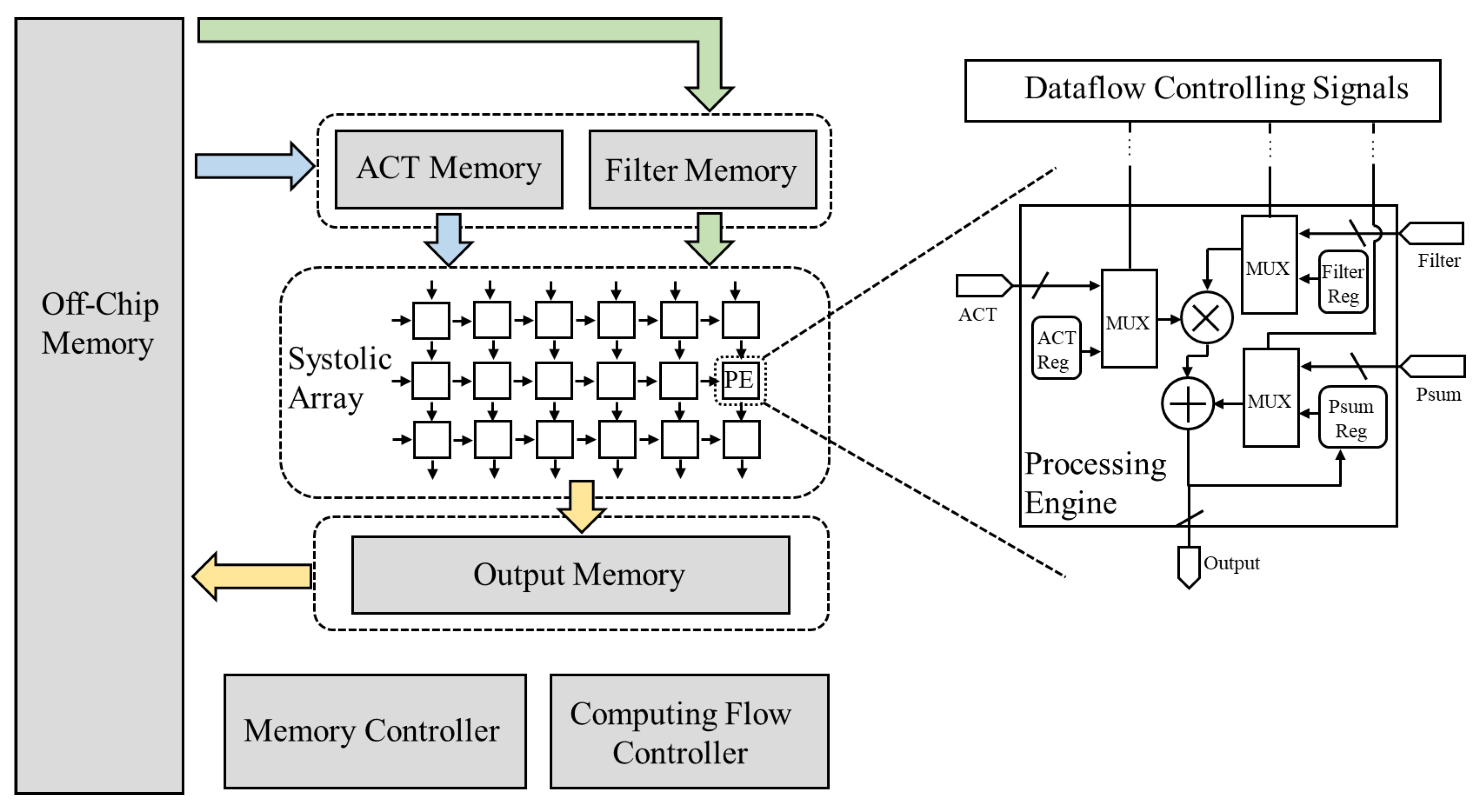
4.1. Architecture
4.2. Chunk-Replacing Process
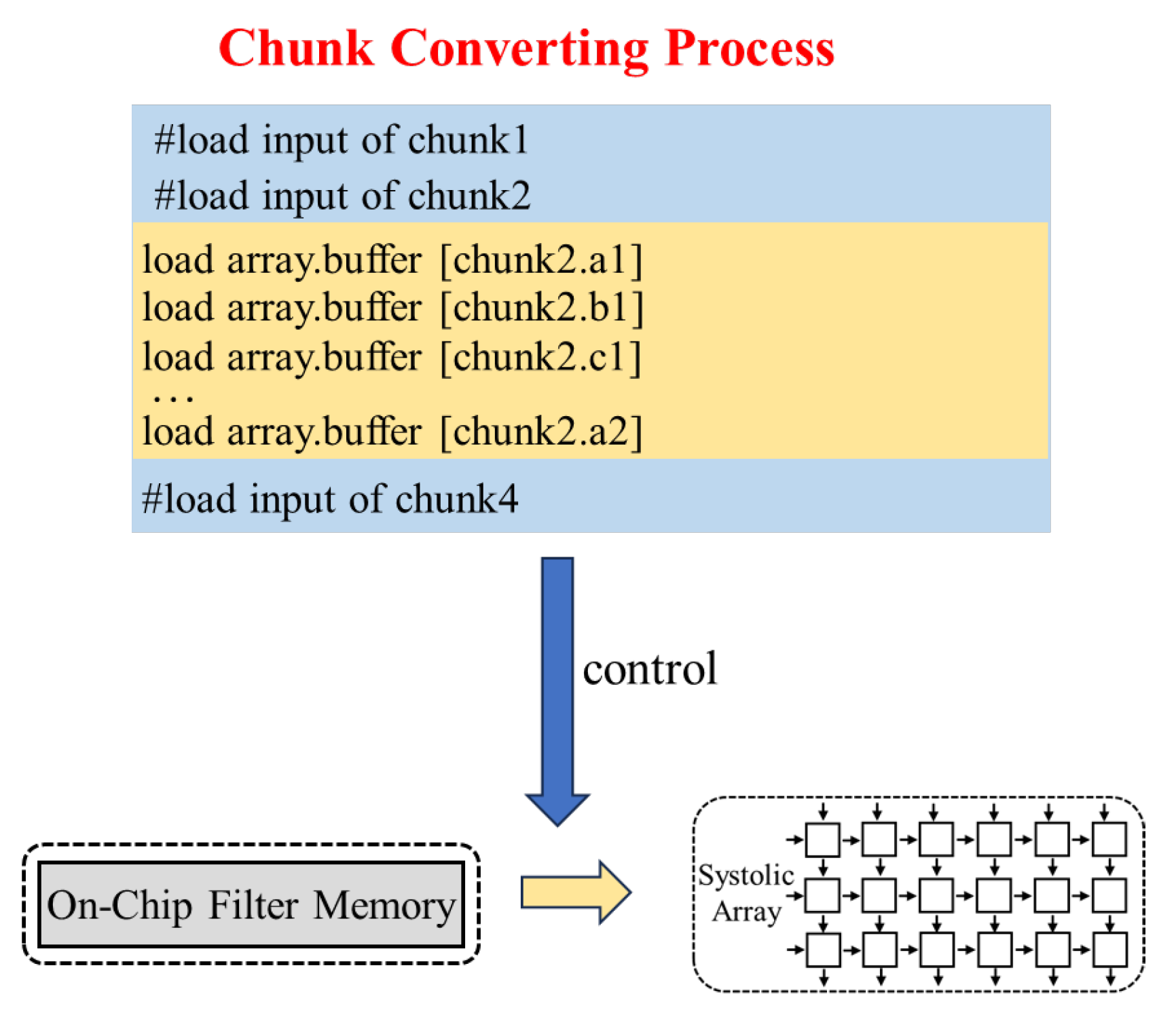
4.3. Chunk-Converting Process
4.3.1. Chunk-Converting Process for Activation
4.3.2. Chunk-Converting Process for Filter
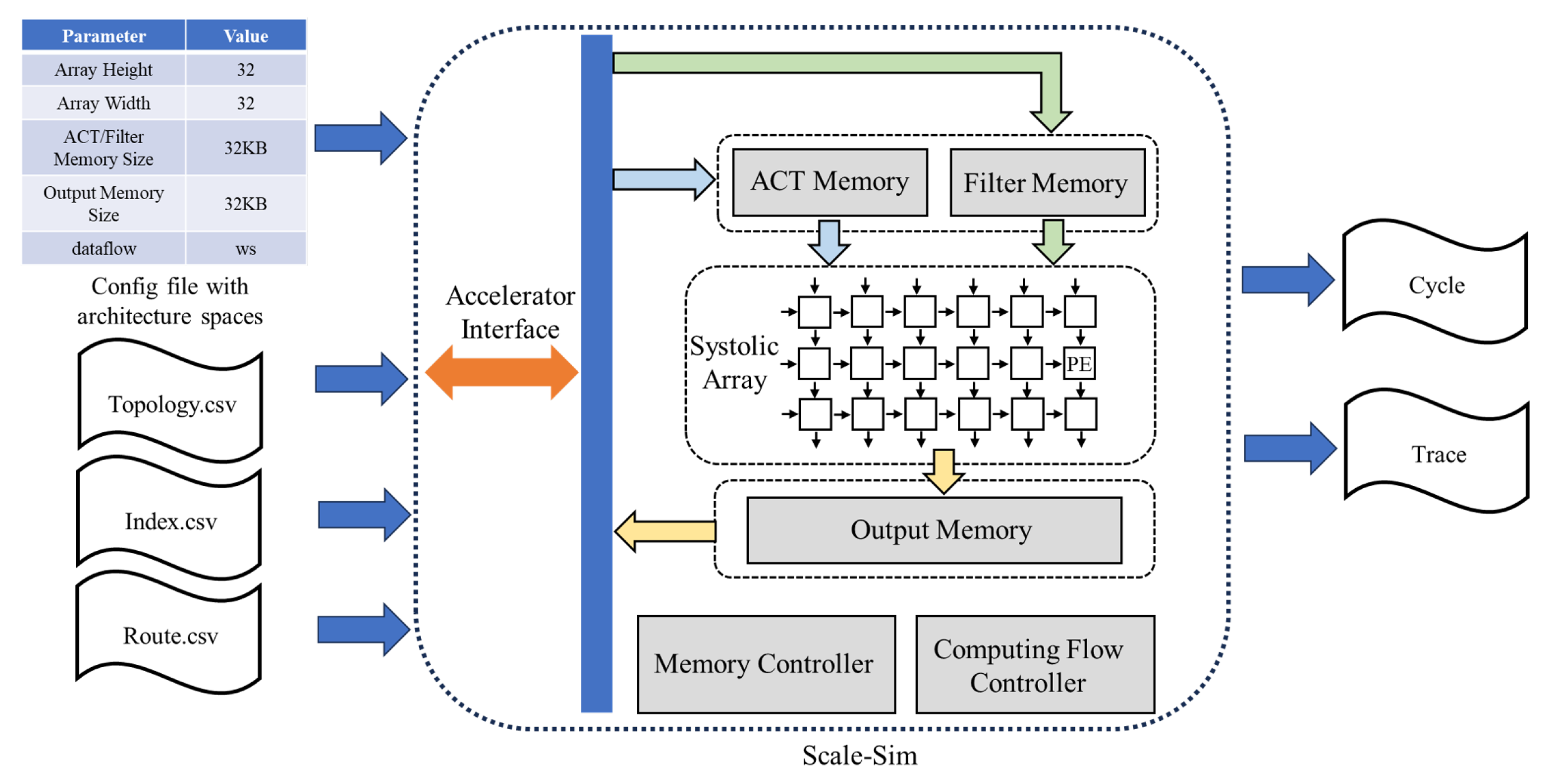
5. Implementation
6. Results
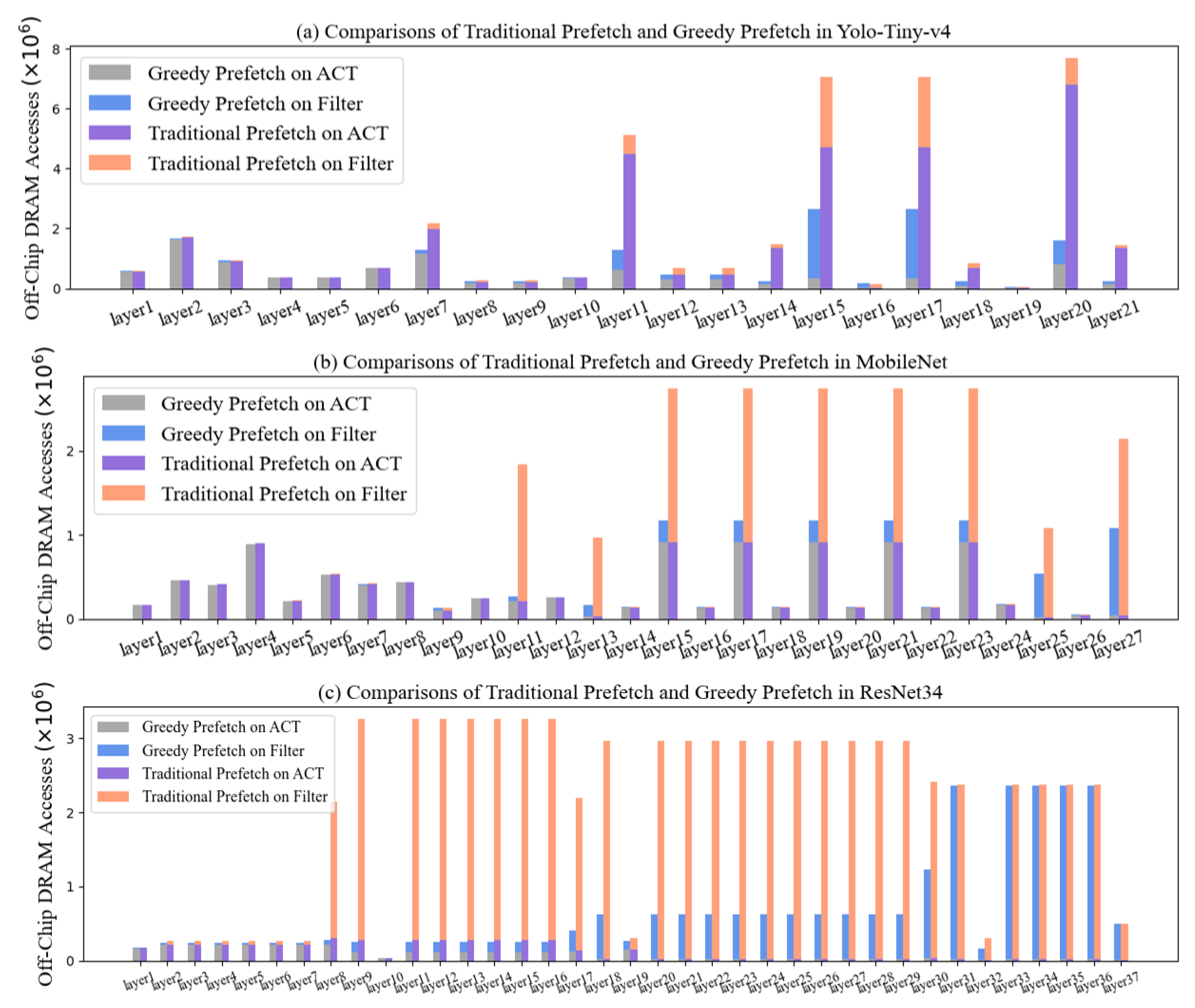
6.1. The Effectiveness of Greedy Prefetch
6.1.1. The Off-Chip Memory Accesses of Greedy Prefetch
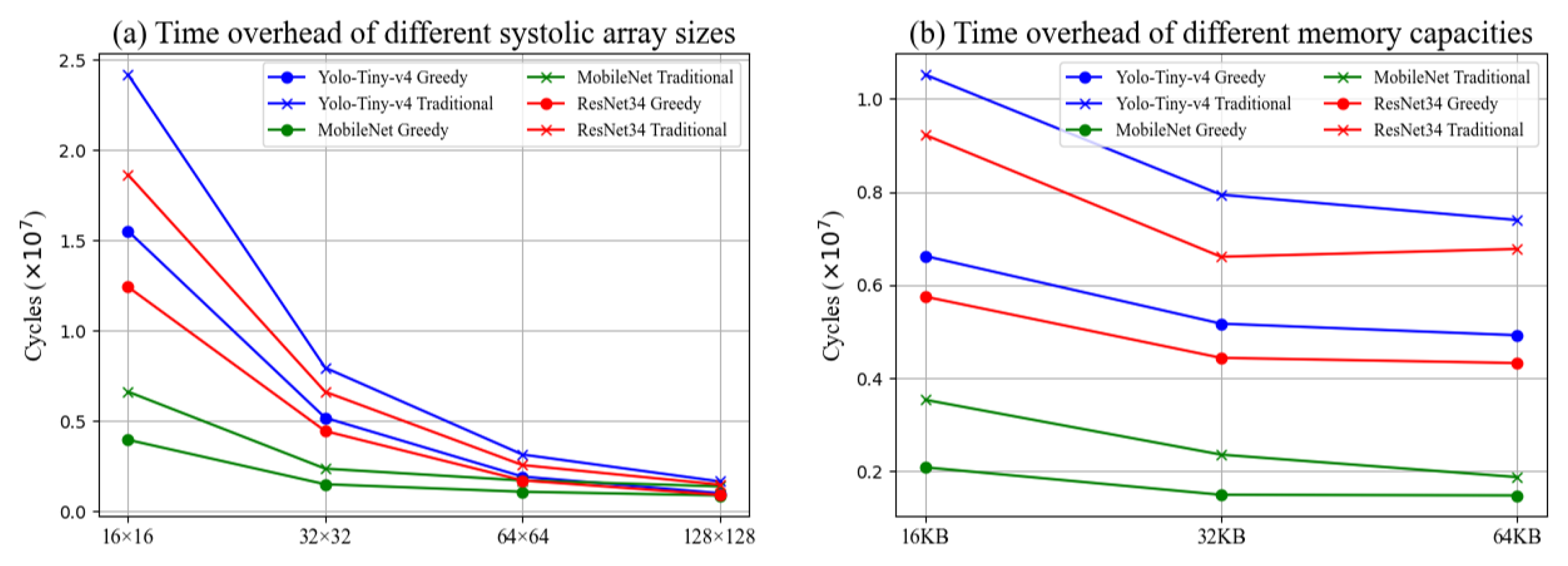
6.1.2. The Time Overhead of Greedy Prefetch
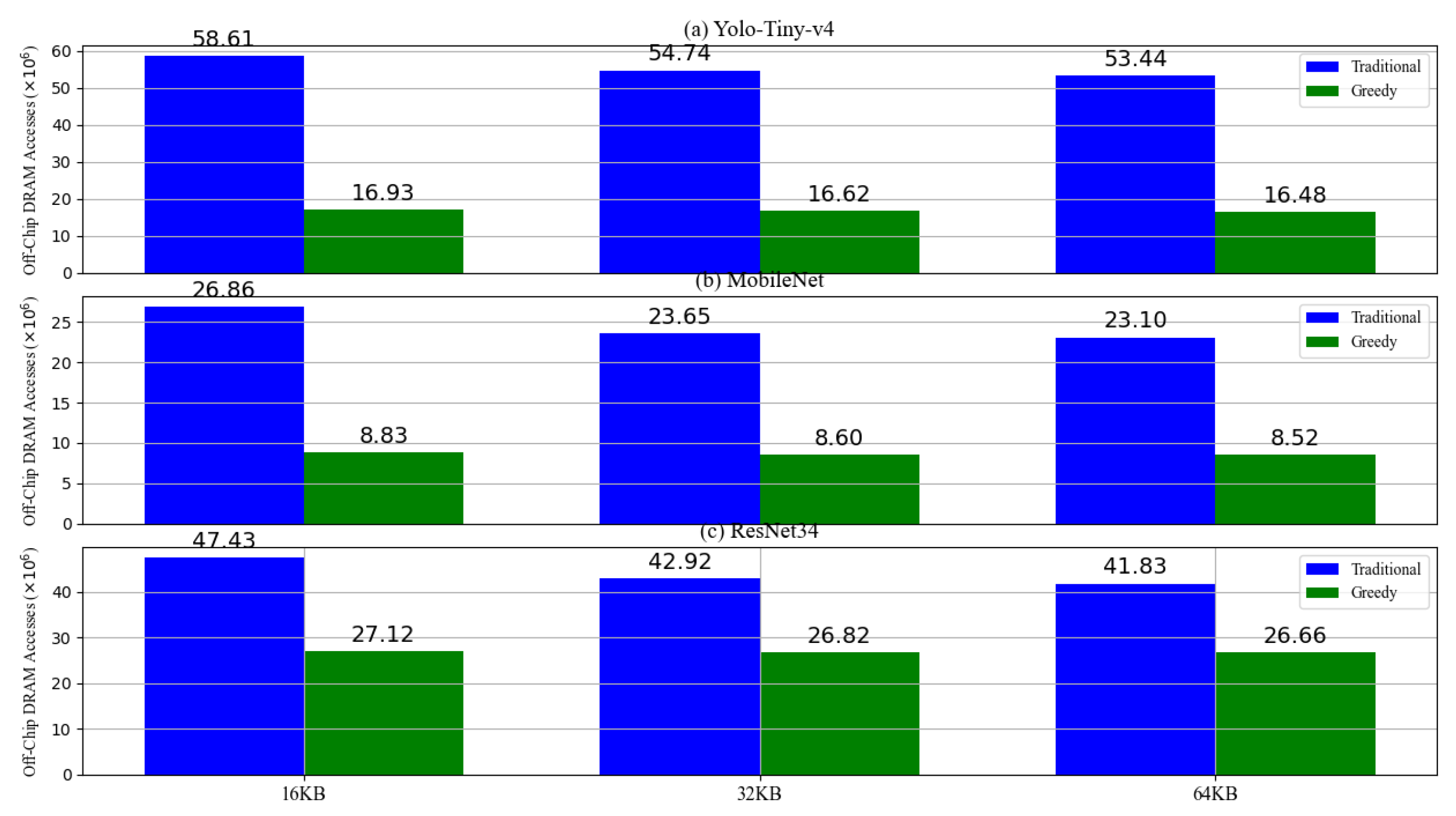
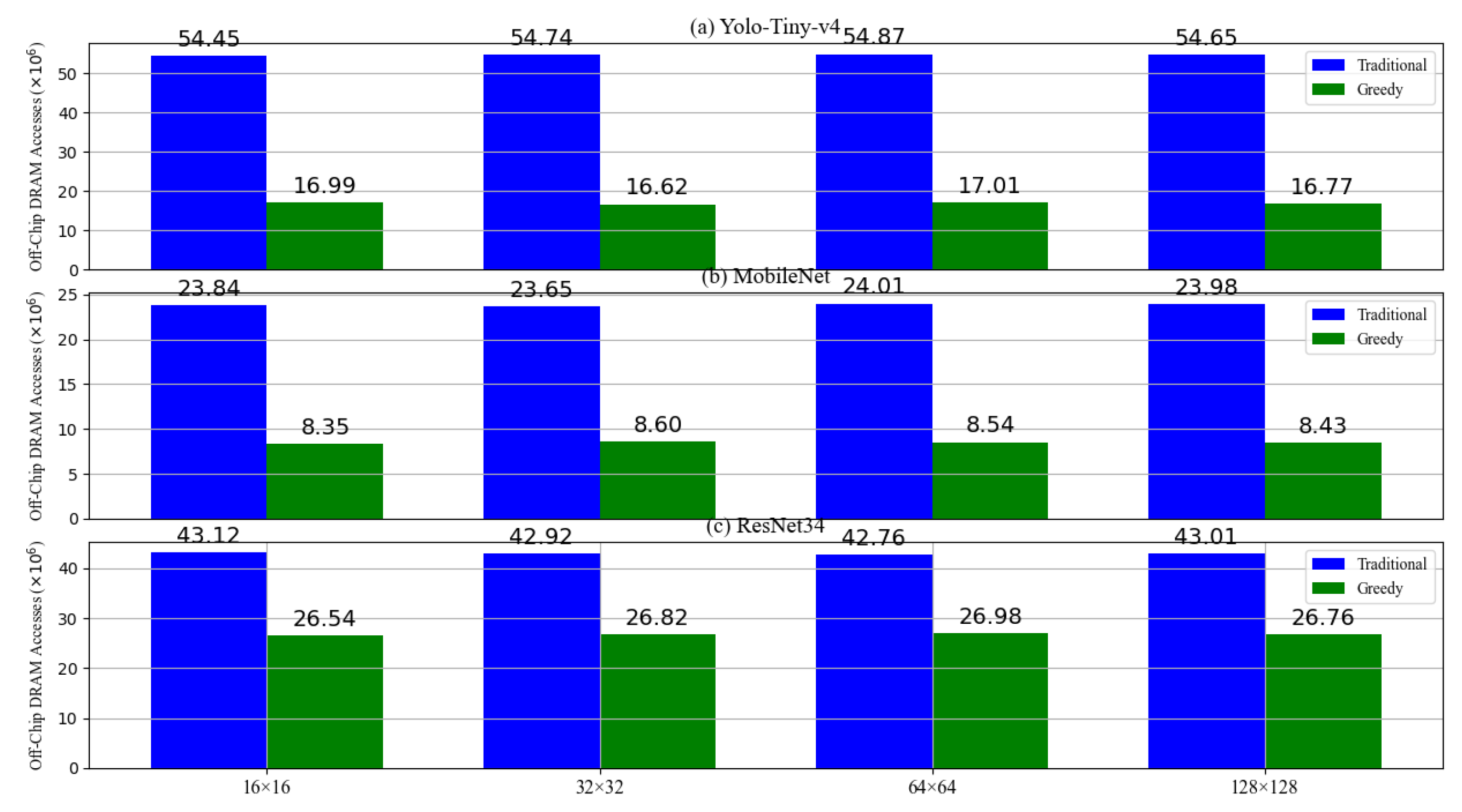
6.2. Comparison with Other Optimizations
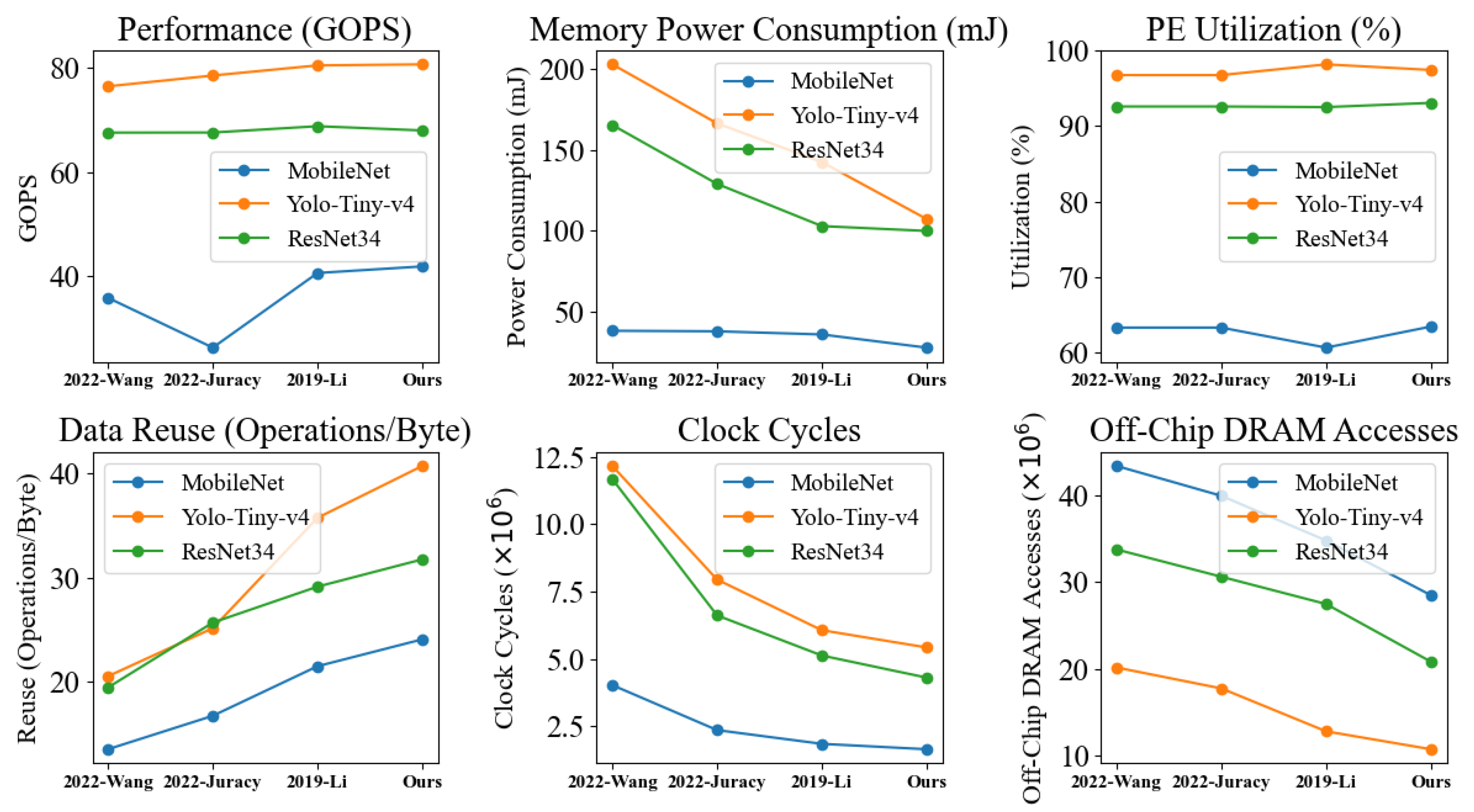
6.3. Comparison with Recent Works
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ashtiani, F.; Geers, A.J.; Aflatouni, F. An on-chip photonic deep neural network for image classification. Nature 2022, 606, 501–506. [Google Scholar] [CrossRef]
- Chen, K.; Chen, B.; Liu, C.; Li, W.; Zou, Z.; Shi, Z. Rsmamba: Remote sensing image classification with state space model. IEEE Geosci. Remote Sens. Lett. 2024, 21, 8002605. [Google Scholar] [CrossRef]
- Lu, S.; Zhang, M.; Huo, Y.; Wang, C.; Wang, J.; Gao, C. SSUM: Spatial–Spectral Unified Mamba for Hyperspectral Image Classification. Remote Sens. 2024, 16, 4653. [Google Scholar] [CrossRef]
- Yeh, C.H.; Lin, C.H.; Kang, L.W.; Huang, C.H.; Lin, M.H.; Chang, C.Y.; Wang, C.C. Lightweight deep neural network for joint learning of underwater object detection and color conversion. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 6129–6143. [Google Scholar] [CrossRef]
- Chen, Q.; Liu, Z.; Zhang, Y.; Fu, K.; Zhao, Q.; Du, H. RGB-D salient object detection via 3D convolutional neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), Vancouver, BC, Canada, 2–9 February 2021; pp. 1063–1071. [Google Scholar]
- Li, X.; Deng, J.; Fang, Y. Few-shot object detection on remote sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5601614. [Google Scholar] [CrossRef]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Chen, J. Detrs beat yolos on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 17–21 June 2024; pp. 16965–16974. [Google Scholar]
- Cheng, T.; Song, L.; Ge, Y.; Liu, W.; Wang, X.; Shan, Y. Yolo-world: Real-time open-vocabulary object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 17–21 June 2024; pp. 16901–16911. [Google Scholar]
- Rios, M.; Ponzina, F.; Levisse, A.; Ansaloni, G.; Atienza, D. Bit-line computing for CNN accelerators co-design in edge AI inference. IEEE Trans. Emerg. Topics Comput. 2023, 11, 358–372. [Google Scholar] [CrossRef]
- Pham, N.S.; Suh, T. Optimization of Microarchitecture and Dataflow for Sparse Tensor CNN Accelerator. IEEE Access 2023, 11, 108818–108832. [Google Scholar] [CrossRef]
- Kim, V.H.; Choi, K.K. A reconfigurable CNN-based accelerator design for fast and energy-efficient object detection system on mobile FPGA. IEEE Access 2023, 11, 59438–59445. [Google Scholar] [CrossRef]
- Zhou, Y.; Yang, M.; Guo, C.; Leng, J.; Liang, Y.; Chen, Q.; Zhu, Y. Characterizing and demystifying the implicit convolution algorithm on commercial matrix-multiplication accelerators. In Proceedings of the 2021 IEEE International Symposium on Workload Characterization (IISWC), San Jose, CA, USA, 31 October–4 November 2021; pp. 214–225. [Google Scholar]
- Umuroglu, Y.; Fraser, N.J.; Gambardella, G.; Blott, M.; Leong, P.; Jahre, M.; Vissers, K. Finn: A framework for fast, scalable binarized neural network inference. In Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays (FPGA), Monterey, CA, USA, 26–28 February 2017; pp. 65–74. [Google Scholar]
- Islam, M.N.; Shrestha, R.; Chowdhury, S.R. Energy-Efficient and High-Throughput CNN Inference Engine Based on Memory-Sharing and Data-Reusing for Edge Applications. IEEE Trans. Circuits Syst. I Reg. Pap. 2024, 71, 3189–3202. [Google Scholar] [CrossRef]
- Wang, C.; Wang, Z.; Li, S.; Zhang, Y.; Shen, H.; Huang, K. EWS: An Energy-Efficient CNN Accelerator with Enhanced Weight Stationary Dataflow. IEEE Trans. Circuits Syst. II Express Briefs 2024, 71, 3478–3482. [Google Scholar] [CrossRef]
- Weerasena, H.; Mishra, P. Revealing CNN architectures via side-channel analysis in dataflow-based inference accelerators. ACM Trans. Embedded Comput. Syst. 2024, 23, 1–25. [Google Scholar] [CrossRef]
- Chen, Y.H.; Krishna, T.; Emer, J.S.; Sze, V. Eyeriss: An energy-efficient reconfigurable accelerator for deep convolutional neural networks. IEEE J. Solid-State Circuits 2016, 52, 127–138. [Google Scholar] [CrossRef]
- Wang, X.; Tian, T.; Zhao, L.; Wu, W.; Jin, X. Exploration of balanced design in resource-constrained edge device for efficient CNNs. IEEE Trans. Circuits Syst. II Express Briefs 2022, 69, 4573–4577. [Google Scholar] [CrossRef]
- Jouppi, N.P.; Young, C.; Patil, N.; Patterson, D.; Agrawal, G.; Bajwa, R.; Bates, S.; Bhatia, S.; Boden, N.; Borchers, A.; et al. In-Datacenter Performance Analysis of a Tensor Processing Unit. ACM J. Emerg. Technol. Comput. Syst. 2017, 45, 1–12. [Google Scholar]
- Kim, M.; Seo, J.S. An energy-efficient deep convolutional neural network accelerator featuring conditional computing and low external memory access. IEEE J. Solid-State Circuits 2020, 56, 803–813. [Google Scholar] [CrossRef]
- Juracy, L.R.; Amory, A.M.; Moraes, F.G. A comprehensive evaluation of convolutional hardware accelerators. IEEE Trans. Circuits Syst. II Express Briefs 2022, 70, 1149–1153. [Google Scholar] [CrossRef]
- Du, Z.; Fasthuber, R.; Chen, T.; Ienne, P.; Li, L.; Luo, T.; Feng, X.; Chen, Y.; Temam, O. ShiDianNao: Shifting Vision Processing Closer to the Sensor. In Proceedings of the 42nd Annual International Symposium on Computer Architecture (ISCA), Portland, OR, USA, 13–17 June 2015; pp. 92–104. [Google Scholar]
- Shao, Z.; Chen, X.; Du, L.; Chen, L.; Du, Y.; Zhuang, W.; Wei, H.; Xie, C.; Wang, Z. Memory-Efficient CNN Accelerator Based on Interlayer Feature Map Compression. In Proceedings of the IEEE International Symposium on Circuits and Systems (ISCAS), Sapporo, Japan, 27–30 May 2022; pp. 668–681. [Google Scholar]
- Li, H.; Bhargava, M.; Whatmough, P.N.; Wong, H.S.P. On-chip memory technology design space explorations for mobile deep neural network accelerators. In Proceedings of the 56th Annual Design Automation Conference (DAC), Las Vegas, NV, USA, 3–7 June 2019; pp. 1–6. [Google Scholar]
- Chen, T.; Moreau, T.; Jiang, Z.; Zheng, L.; Yan, E.; Shen, H.; Cowan, M.; Wang, L.; Hu, Y.; Ceze, L.; et al. TVM: An Automated End-to-End Optimizing Compiler for Deep Learning. In Proceedings of the 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI), Carlsbad, CA, USA, 8–10 October 2018; pp. 578–594. [Google Scholar]
- Yang, X.; Pu, J.; Rister, B.B.; Bhagdikar, N.; Richardson, S.; Kvatinsky, S.; Horowitz, M. A systematic approach to blocking convolutional neural networks. arXiv 2016, arXiv:1606.04209. [Google Scholar]
- Parashar, A.; Raina, P.; Shao, Y.S.; Chen, Y.H.; Ying, V.A.; Mukkara, A.; Venkatesan, R.; Khailany, B.; Keckler, S.W.; Emer, J. Timeloop: A Systematic Approach to DNN Accelerator Evaluation. In Proceedings of the 2019 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), Portland, OR, USA, 16–20 March 2019; pp. 304–315. [Google Scholar]
- Li, Z.; Gao, M. KAPLA: Pragmatic Representation and Fast Solving of Scalable NN Accelerator Dataflow. arXiv 2023, arXiv:2306.15676. [Google Scholar]
- Samajdar, A.; Joseph, J.M.; Zhu, Y.; Whatmough, P.; Mattina, M.; Krishna, T. A systematic methodology for characterizing scalability of DNN accelerators using Scale-Sim. In Proceedings of the 2020 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), Portland, OR, USA, 29 March–2 April 2020; pp. 58–68. [Google Scholar]
- Wang, Z.; Jiménez, D.A.; Xu, C.; Sun, G.; Xie, Y. Adaptive placement and migration policy for an STT-RAM-based hybrid cache. In Proceedings of the 2014 IEEE 20th International Symposium on High Performance Computer Architecture (HPCA), Orlando, FL, USA, 15–19 February 2014; pp. 13–24. [Google Scholar]
- Muñoz-Martínez, F.; Abellán, J.L.; Acacio, M.E.; Krishna, T. Stonne: Enabling cycle-level microarchitectural simulation for dnn inference accelerators. In Proceedings of the 2021 IEEE International Symposium on Workload Characterization (IISWC), Storrs, CT, USA, 7–9 November 2021; pp. 201–213. [Google Scholar]
- Mei, L.; Houshmand, P.; Jain, V.; Giraldo, S.; Verhelst, M. ZigZag: Enlarging joint architecture-mapping design space exploration for DNN accelerators. IEEE Trans. Comput. 2021, 70, 1160–1174. [Google Scholar] [CrossRef]
- Mei, L.; Liu, H.; Wu, T.; Sumbul, H.E.; Verhelst, M.; Beigne, E. A uniform latency model for dnn accelerators with diverse architectures and dataflows. In Proceedings of the 2022 Design, Automation & Test in Europe Conference & Exhibition (DATE), Antwerp, Belgium, 14–23 March 2022; pp. 220–225. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Effectively Fetch Data | Effectively Use Memory | Effectively Compute | |
|---|---|---|---|
| Method | Traditional Prefetch (Loop Block) [17,18,25,29,30] Greedy Prefetch | Memory Allocation [23] NVM Substitution [24] | Input Stationary [21] Weight Stationary [19,22] Output Stationary [20] Hybrid Stationary [21] |
| 2022-Wang | 2022-Juracy | 2019-Li | Ours | |
|---|---|---|---|---|
| Systolic Array | IS | HS | HS | HS |
| Memory Allocation | MF | MF | MF | MA |
| On-chip Memory | SRAM 32 KB | SRAM 32 KB | MRAM 101 KB | MRAM 101 KB |
| Prefetch Method | TP | TP | TP | GP |
| 2021-STONE | 2021-Zigzag | 2022-Mei | 2024-Weerasena | Ours | ||
|---|---|---|---|---|---|---|
| Dataflow | WS with SA | RS with SA | Boardcast | OS with SA | HS with SA | HS with SA |
| Prefetch Method | traditional | traditional | traditional | traditional | greedy | greedy |
| Memory | 108 KB GlobalB 0.5 GB HBM2 | 32 KB L1C 2 MB L2C | 28 KB register | 108 KB GlobalB 0.5 GB HBM2 | 32 KB A/F Buffer 32 KB O Buffer | 32 KB A/F Buffer 32 KB O Buffer |
| 32 KB WeightB | ||||||
| 64 KB InputB | ||||||
| 16 64 KB GlobalB | ||||||
| Array Scale | 256 | (224) | (1024) | 256 | (1024) | (256) |
| Off-Chip DRAM Accesses | 25.00M@AlexNet | - | 0.70M@DNN (10 layers) | - | 16.62M@Yolo-Tiny-v4 | 16.99M@Yolo-Tiny-v4 |
| 8.60M@MobileNet | 8.35M@MobileNet | |||||
| 26.82M@ResNet34 | 26.54M@ResNet34 | |||||
| 31.29M@AlexNet | 31.06M@AlexNet | |||||
| Clock Cycles | 8.50M@AlexNet 7.00M@MobileNet 70.00M@VGG-16 | 8.04M@AlexNet 1.75M@MobileNet | 0.61M@DNN (10 layers) | 40.61M@AlexNet | 5.17M@Yolo-Tiny-v4 | 15.51M@Yolo-Tiny-v4 |
| 1.49M@MobileNet | 3.95M@MobileNet | |||||
| 4.43M@ResNet34 | 12.42M@ResNet34 | |||||
| 10.42M@AlexNet | 28.43M@AlexNet | |||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, D.; Chen, L. Greedy Prefetch for Reducing Off-Chip Memory Accesses in Convolutional Neural Network Inference. Information 2025, 16, 164. https://doi.org/10.3390/info16030164
Yang D, Chen L. Greedy Prefetch for Reducing Off-Chip Memory Accesses in Convolutional Neural Network Inference. Information. 2025; 16(3):164. https://doi.org/10.3390/info16030164
Chicago/Turabian StyleYang, Dengtian, and Lan Chen. 2025. "Greedy Prefetch for Reducing Off-Chip Memory Accesses in Convolutional Neural Network Inference" Information 16, no. 3: 164. https://doi.org/10.3390/info16030164
APA StyleYang, D., & Chen, L. (2025). Greedy Prefetch for Reducing Off-Chip Memory Accesses in Convolutional Neural Network Inference. Information, 16(3), 164. https://doi.org/10.3390/info16030164