
Unveiling XSS Threats: A Bipartite Graph Approach with Ensemble Deep Learning for Enhanced Detection


Abstract
1. Introduction
Statement of Contribution
2. Literature
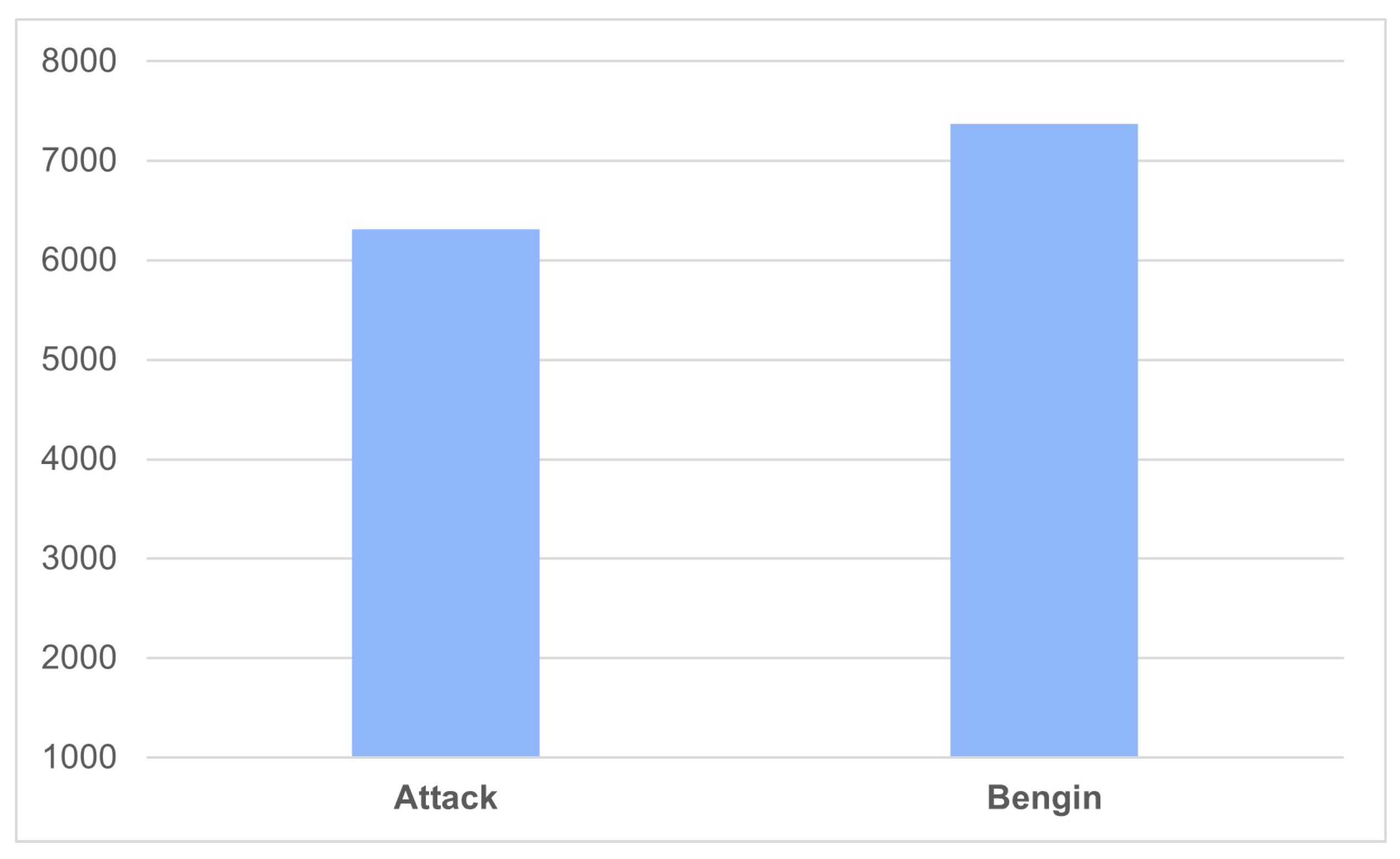
3. Dataset
4. Methods
4.1. The Proposed Model
4.2. Pre-Processing
4.2.1. Removing Noisy Data/Normalization
4.2.2. Decoding
4.2.3. Tokenization
4.3. Feature Extraction
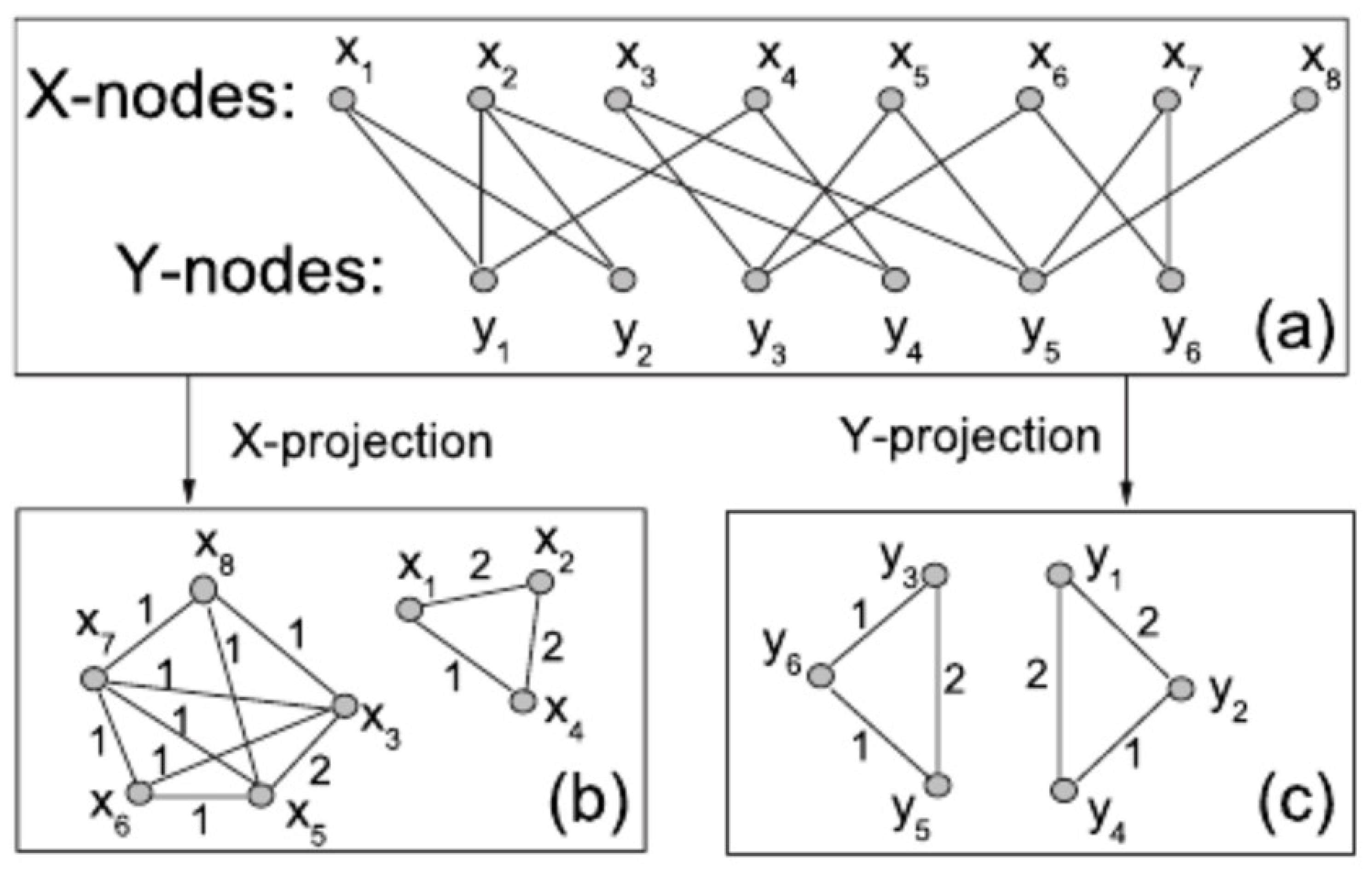
4.3.1. Graph Construction
| Algorithm 1 Constructing a Bipartite Graph from XXS Payloads |
|
4.3.2. Bipartite Graph Projection
Adjacency Matrix of the Bipartite Graph
Projection onto Payloads (P)
Projection onto Words (W)
4.3.3. Embedding Extraction
Word2Vec:
Doc2Vec:
| Algorithm 2 Extracting Features from the Bipartite Graph with Concatenation |
|
4.4. Classification
4.4.1. Machine Learning
4.4.2. DeepLearning
| Algorithm 3 Integrated Ensemble Approach |
|
4.5. Optmization
4.6. Experiment Evaluation
5. Results
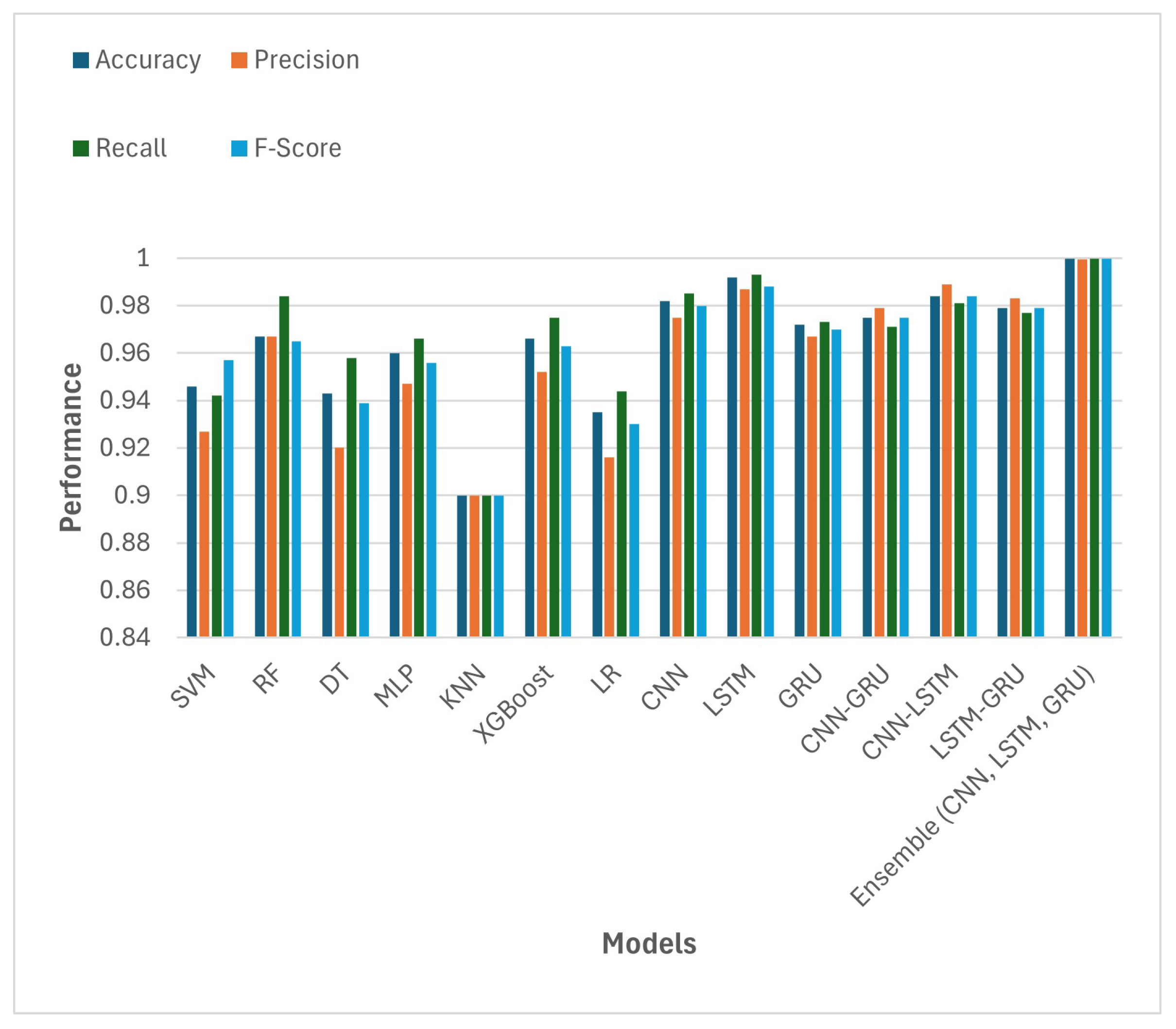
5.1. Evaluation of Different Models
5.2. Comparison with State-of-the-Art Models
6. Discussion
7. Conclusions
Practical Implications of the Bipartite Network for XSS Detection
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tan, X.; Xu, Y.; Wu, T.; Li, B. Detection of reflected XSS vulnerabilities based on paths-attention method. Appl. Sci. 2023, 13, 7895. [Google Scholar] [CrossRef]
- Liu, Z.; Fang, Y.; Huang, C.; Han, J. GraphXSS: An efficient XSS payload detection approach based on graph convolutional network. Comput. Secur. 2022, 114, 102597. [Google Scholar] [CrossRef]
- Liu, Z.; Fang, Y.; Huang, C.; Xu, Y. MFXSS: An effective XSS vulnerability detection method in JavaScript based on multi-feature model. Comput. Secur. 2023, 124, 103015. [Google Scholar] [CrossRef]
- van de Bijl, E.P. Towards Graph-Based Intrusion Detection in Cybersecurity. Master’s Thesis, Vrije Universiteit Amsterdam, Amsterdam, The Netherlands, 2020. [Google Scholar]
- Thajeel, I.K.; Samsudin, K.; Hashim, S.J.; Hashim, F. Machine and deep learning-based xss detection approaches: A systematic literature review. J. King Saud Univ.-Comput. Inf. Sci. 2023, 35, 101628. [Google Scholar] [CrossRef]
- Liu, M.; Zhang, B.; Chen, W.; Zhang, X. A survey of exploitation and detection methods of XSS vulnerabilities. IEEE Access 2019, 7, 182004–182016. [Google Scholar] [CrossRef]
- Kaur, J.; Garg, U.; Bathla, G. Detection of cross-site scripting (XSS) attacks using machine learning techniques: A review. Artif. Intell. Rev. 2023, 56, 12725–12769. [Google Scholar] [CrossRef]
- Sharma, S.; Zavarsky, P.; Butakov, S. Machine learning based intrusion detection system for web-based attacks. In Proceedings of the 2020 IEEE 6th Intl Conference on Big Data Security on Cloud (BigDataSecurity), IEEE Intl Conference on High Performance and Smart Computing, (HPSC) and IEEE Intl Conference on Intelligent Data and Security (IDS), Baltimore, MD, USA, 25–27 May 2020; pp. 227–230. [Google Scholar]
- Alam, F.; Pachauri, S. Comparative study of J48, Naive Bayes and One-R classification technique for credit card fraud detection using WEKA. Adv. Comput. Sci. Technol 2017, 10, 1731–1743. [Google Scholar]
- Yang, W.; Zuo, W.; Cui, B. Detecting malicious URLs via a keyword-based convolutional gated-recurrent-unit neural network. IEEE Access 2019, 7, 29891–29900. [Google Scholar] [CrossRef]
- Munonye, K.; Péter, M. Machine learning approach to vulnerability detection in OAuth 2.0 authentication and authorization flow. Int. J. Inf. Secur. 2022, 21, 223–237. [Google Scholar] [CrossRef]
- Wang, R.; Jia, X.; Li, Q.; Zhang, S. Machine learning based cross-site scripting detection in online social network. In Proceedings of the 2014 IEEE Intl Conf on High Performance Computing and Communications, 2014 IEEE 6th Intl Symp on Cyberspace Safety and Security, 2014 IEEE 11th Intl Conf on Embedded Software and Syst (HPCC, CSS, ICESS), Paris, France, 20–22 August 2014; pp. 823–826. [Google Scholar]
- Kascheev, S.; Olenchikova, T. The detecting cross-site scripting (XSS) using machine learning methods. In Proceedings of the 2020 Global Smart Industry Conference (GloSIC), Chelyabinsk, Russia, 17–19 November 2020; pp. 265–270. [Google Scholar]
- Banerjee, R.; Baksi, A.; Singh, N.; Bishnu, S.K. Detection of XSS in web applications using Machine Learning Classifiers. In Proceedings of the 2020 4th International Conference on Electronics, Materials Engineering & Nano-Technology (IEMENTech), Kolkata, India, 2–4 October 2020; pp. 1–5. [Google Scholar]
- Rathore, S.; Sharma, P.K.; Park, J.H. XSSClassifier: An efficient XSS attack detection approach based on machine learning classifier on SNSs. J. Inf. Process. Syst. 2017, 13, 1014–1028. [Google Scholar] [CrossRef]
- Khan, N.; Abdullah, J.; Khan, A.S. Defending malicious script attacks using machine learning classifiers. Wirel. Commun. Mob. Comput. 2017, 2017, 5360472. [Google Scholar] [CrossRef]
- Alhamyani, R.; Alshammari, M. Machine Learning-Driven Detection of Cross-Site Scripting Attacks. Information 2024, 15, 420. [Google Scholar] [CrossRef]
- Wang, Q.; Li, C.; Wang, D.; Yuan, L.; Pan, G.; Cheng, Y.; Hu, M.; Ren, Y. IGXSS: XSS payload detection model based on inductive GCN. Int. J. Netw. Manag. 2024, 34, e2264. [Google Scholar] [CrossRef]
- Karim, A.; Shahroz, M.; Mustofa, K.; Belhaouari, S.B.; Joga, S.R.K. Phishing detection system through hybrid machine learning based on URL. IEEE Access 2023, 11, 36805–36822. [Google Scholar] [CrossRef]
- Shukla, S.; Misra, M.; Varshney, G. HTTP header based phishing attack detection using machine learning. Trans. Emerg. Telecommun. Technol. 2024, 35, e4872. [Google Scholar] [CrossRef]
- Bacha, N.U.; Lu, S.; Ur Rehman, A.; Idrees, M.; Ghadi, Y.Y.; Alahmadi, T.J. Deploying Hybrid Ensemble Machine Learning Techniques for Effective Cross-Site Scripting (XSS) Attack Detection. Comput. Mater. Contin. 2024, 81, 707. [Google Scholar] [CrossRef]
- Bakır, R.; Bakır, H. Swift Detection of XSS Attacks: Enhancing XSS Attack Detection by Leveraging Hybrid Semantic Embeddings and AI Techniques. Arab. J. Sci. Eng. 2024, 50, 1191–1207. [Google Scholar] [CrossRef]
- Ade, M. A Review of Modern Techniques for Detecting Cross-Site Scripting (XSS) in Web Applications. 2024. Available online: https://www.researchgate.net/publication/384695038_A_Review_of_Modern_Techniques_for_Detecting_Cross-_Site_Scripting_XSS_in_Web_Applications (accessed on 20 December 2024).
- Hannousse, A.; Yahiouche, S.; Nait-Hamoud, M.C. Twenty-two years since revealing cross-site scripting attacks: A systematic mapping and a comprehensive survey. Comput. Sci. Rev. 2024, 52, 100634. [Google Scholar] [CrossRef]
- Rodríguez-Galán, G.; Torres, J. Personal data filtering: A systematic literature review comparing the effectiveness of XSS attacks in web applications vs cookie stealing. Ann. Telecommun. 2024, 79, 763–802. [Google Scholar] [CrossRef]
- Ramoa, L.; Campos, P. Recommendation Systems in E-commerce: Link Prediction in Multilayer Bipartite Networks. In Digital Transformation and Enterprise Information Systems; CRC Press: Boca Raton, FL, USA, 2024; pp. 55–78. [Google Scholar]
- Mokbal, F.M.M.; Dan, W.; Xiaoxi, W.; Wenbin, Z.; Lihua, F. XGBXSS: An extreme gradient boosting detection framework for cross-site scripting attacks based on hybrid feature selection approach and parameters optimization. J. Inf. Secur. Appl. 2021, 58, 102813. [Google Scholar] [CrossRef]
- Gniewkowski, M.; Maciejewski, H.; Surmacz, T.; Walentynowicz, W. Section 2vec: Anomaly detection in HTTP traffic and malicious URLs. In Proceedings of the 38th ACM/SIGAPP Symposium on Applied Computing, Tallinn, Estonia, 27–31 March 2023; pp. 1154–1162. [Google Scholar]
- Gniewkowski, M.; Maciejewski, H.; Surmacz, T.R.; Walentynowicz, W. Http2vec: Embedding of http requests for detection of anomalous traffic. arXiv 2021, arXiv:2108.01763. [Google Scholar]
- Abu, T.N.A.; Doh, K.G. An Analysis of Machine-Learning Feature-Extraction Techniques using Syntactic Tagging for Cross-site Scripting Detection. J. Softw. Assess. Valuat. 2022, 18, 107–118. [Google Scholar]
- de Albuquerque Oliveira, M.C. A Hybrid Machine Learning System for Vulnerability Detection in Web Applications. Master’s Thesis, Universidade de Lisboa, Lisbon, Portugal, 2023. [Google Scholar]
- Rozi, M.F.; Ban, T.; Ozawa, S.; Yamada, A.; Takahashi, T.; Inoue, D. Securing Code with Context: Enhancing Vulnerability Detection through Contextualized Graph Representations. IEEE Access 2024, 12, 142101–142126. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef] [PubMed]
- Dong, Y.; Wang, R.; He, J. Real-time network intrusion detection system based on deep learning. In Proceedings of the 2019 IEEE 10th International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 18–20 October 2019; pp. 1–4. [Google Scholar]
- Chaudhary, P.; Gupta, B.B.; Chang, X.; Nedjah, N.; Chui, K.T. Enhancing big data security through integrating XSS scanner into fog nodes for SMEs gain. Technol. Forecast. Soc. Chang. 2021, 168, 120754. [Google Scholar] [CrossRef]
- Kuppa, K.; Dayal, A.; Gupta, S.; Dua, A.; Chaudhary, P.; Rathore, S. ConvXSS: A deep learning-based smart ICT framework against code injection attacks for HTML5 web applications in sustainable smart city infrastructure. Sustain. Cities Soc. 2022, 80, 103765. [Google Scholar] [CrossRef]
- Maurel, H.; Vidal, S.; Rezk, T. Statically identifying XSS using deep learning. Sci. Comput. Program. 2022, 219, 102810. [Google Scholar] [CrossRef]
- Shahid, W.B.; Aslam, B.; Abbas, H.; Khalid, S.B.; Afzal, H. An enhanced deep learning based framework for web attacks detection, mitigation and attacker profiling. J. Netw. Comput. Appl. 2022, 198, 103270. [Google Scholar] [CrossRef]
- Hochreiter, S. Long Short-term Memory. In Neural Computation; MIT-Press: Cambridge, MA, USA, 1997. [Google Scholar]
- Gao, C.; Yan, J.; Zhou, S.; Varshney, P.K.; Liu, H. Long short-term memory-based deep recurrent neural networks for target tracking. Inf. Sci. 2019, 502, 279–296. [Google Scholar] [CrossRef]
- Guan, D.; Yuan, W.; Lee, Y.K.; Najeebullah, K.; Rasel, M.K. A review of ensemble learning based feature selection. IETE Tech. Rev. 2014, 31, 190–198. [Google Scholar] [CrossRef]
- Ganaie, M.A.; Hu, M.; Malik, A.K.; Tanveer, M.; Suganthan, P.N. Ensemble deep learning: A review. Eng. Appl. Artif. Intell. 2022, 115, 105151. [Google Scholar] [CrossRef]
- Wu, A.; Feng, Z.; Li, X.; Xiao, J. ZTWeb: Cross site scripting detection based on zero trust. Comput. Secur. 2023, 134, 103434. [Google Scholar] [CrossRef]
- Chaudhary, P.; Gupta, B.; Singh, A.K. Adaptive cross-site scripting attack detection framework for smart devices security using intelligent filters and attack ontology. Soft Comput. 2023, 27, 4593–4608. [Google Scholar] [CrossRef]
- Pan, H.; Fang, Y.; Guo, W.; Xu, Y.; Wang, C. Few-shot graph classification on cross-site scripting attacks detection. Comput. Secur. 2024, 140, 103749. [Google Scholar] [CrossRef]
- Luu, G.H.; Duong, M.K.; Pham-Ngo, T.P.; Ngo, T.S.; Nguyen, D.T.; Nguyen, X.H.; Le, K.H. XSShield: A Novel Dataset and Lightweight Hybrid Deep Learning Model for XSS Attack Detection. Results Eng. 2024, 24, 103363. [Google Scholar] [CrossRef]
- Odeh, A.; Taleb, A.A. XSSer: Hybrid deep learning for enhanced cross-site scripting detection. Bull. Electr. Eng. Inform. 2024, 13, 3317–3325. [Google Scholar] [CrossRef]
- Reka, R.; Karthick, R.; Ram, R.S.; Singh, G. Multi head self-attention gated graph convolutional network based multi-attack intrusion detection in MANET. Comput. Secur. 2024, 136, 103526. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Model | Performance |
|---|---|---|
| Kaur et al. [7] | Linear SVM | Accuracy: 95.4%, Recall: 0.951, FPR: 0.111 |
| Sharma et al. [8] | J48, OneR, Naïve Bayes | Best results with J48 |
| Munonye et al. [11] | Gradient Boosting Classifier (GBC) | Accuracy: 0.82, ROC: 0.71 |
| Wang et al. [12] | ADTree + AdaBoost | Precision: 0.941, Recall: 0.939, F-Measure: 0.939 |
| Yang et al. [10] | GRU | Accuracy: 0.996 |
| Kascheev et al. [13] | SVM, Decision Tree, Logistic Regression, Naïve Bayes | Best results with Decision Tree |
| Banerjee et al. [14] | SVM, KNN, Random Forest, Logistic Regression | Random Forest: Low FPR, Good accuracy |
| Rathore et al. [15] | Tree Classifiers (Random Forest, ADTree) | Accuracy: 97.2%, FPR: 0.87 |
| Khan et al. [16] | SVM, KNN, J48, Naïve Bayes | J48: Accuracy: 99.22% |
| Alhamyani et al. [17] | Random Forest, SVM, XGBoost, CNN, MLP | Random Forest: Accuracy: 99.78% |
| Liu et al. [2] | Graph Convolutional Network (GCN) | Accuracy: 0.996 |
| Wang et al. [18] | Inductive GCN (IGXSS) | Outperforms other models |
| Tan et al. [1] | Paths-Attention (PATS) | Accuracy: 90.25%, F1-Score: 81.62% |
| Karim et al. [19] | Hybrid Classifier | Accuracy: 98.12%, F1-Score: 95.89% |
| Bacha et al. [21] | Hybrid Ensemble (DNN, XGBoost, SVM, etc.) | Accuracy: 99.87%, FP: 0.13%, FN: 0.19% |
| Bakir et al. [22] | Word2Vec + USE Embeddings | Improved performance (Accuracy, Recall, F1-score) |
| Parameter | Word2Vec | Doc2Vec |
|---|---|---|
| Vector Size | 200 (common range: 100–300) | 200 (common range: 100–300) |
| Window Size | 5 (common range: 3–10) | 10 (common range: 5–15) |
| Min Count | 1 (to capture rare XSS-related words) | 1 (to capture rare XSS patterns) |
| Algorithm | Skip-Gram | PV-DM (Distributed Memory) |
| Training | Negative Sampling (5–10 samples) | Negative Sampling (5–10 samples) |
| Epochs | 20 (range: 10–50) | 20 (range: 10–50) |
| Learning Rate | 0.025 (range: 0.01–0.05) | 0.025 (range: 0.01–0.05) |
| Workers | 4–8 threads | 4–8 threads |
| Classifier | Hyperparameter Setting |
|---|---|
| RF (Random Forest) |
|
| DT (Decision Tree) |
|
| MLP (Multi-Layer Perceptron) |
|
| SVM (Support Vector Machine) |
|
| LR (Logistic Regression) |
|
| XGBoost |
|
| KNN (K-Nearest Neighbors) |
|
| Classifier | Hyperparameter Setting |
|---|---|
| GRU (Gated Recurrent Unit) |
|
| LSTM (Long Short-Term Memory) |
|
| CNN (Convolutional Neural Network) |
|
| Model | Proposed Feature (Raw + Bipartite) | |||
|---|---|---|---|---|
| Accuracy | Precision | Recall | F-Score | |
| SVM | 0.946 | 0.927 | 0.942 | 0.957 |
| RF | 0.967 | 0.967 | 0.984 | 0.965 |
| DT | 0.943 | 0.92 | 0.958 | 0.939 |
| MLP | 0.96 | 0.947 | 0.966 | 0.956 |
| KNN | 0.90 | 0.90 | 0.90 | 0.90 |
| XGBoost | 0.966 | 0.952 | 0.975 | 0.963 |
| LR | 0.935 | 0.916 | 0.944 | 0.93 |
| CNN | 0.982 | 0.975 | 0.985 | 0.98 |
| LSTM | 0.992 | 0.987 | 0.993 | 0.988 |
| GRU | 0.972 | 0.967 | 0.973 | 0.97 |
| CNN-GRU | 0.975 | 0.979 | 0.971 | 0.975 |
| CNN-LSTM | 0.984 | 0.989 | 0.981 | 0.984 |
| LSTM-GRU | 0.979 | 0.983 | 0.977 | 0.979 |
| Ensemble (CNN, LSTM, GRU) | 0.9997 | 0.9995 | 0.9998 | 0.9997 |
| Reference | Model | Accuracy | Precision | Recall | F-Score |
|---|---|---|---|---|---|
| Mokbal et al. [27] | XGboost | 0.995 | 0.995 | 0.99 | 0.995 |
| Wu et al. [43] | TextCNN | 0.997 | 0.997 | 0.997 | 0.997 |
| Chaudhary et al. [44] | Self-organizing-map (SOM) | 0.9904 | 0.993 | 0.991 | 0.9938 |
| Pan et al. [45] | FSXSS | 0.9 | NA | NA | 0.79 |
| Bach et al. [21] | Stacking ensemble learning | 0.9987 | 0.998 | 0.997 | 0.9987 |
| Bakir et al. [22] | Vanilla NN 2 | 0.9916 | 0.9922 | 0.9899 | 0.9946 |
| Luu et al. [46] | XSShield | 0.9927 | 0.9965 | 0.9561 | 0.9759 |
| Odeh et al. [47] | Hybrid RNN-CNN | 0.967 | 0.977 | 0.956 | 0.967 |
| Proposed model | Bipartite feature + Ensemble classifier | 0.9997 | 0.9995 | 0.9998 | 0.9997 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alorainy, W. Unveiling XSS Threats: A Bipartite Graph Approach with Ensemble Deep Learning for Enhanced Detection. Information 2025, 16, 97. https://doi.org/10.3390/info16020097
Alorainy W. Unveiling XSS Threats: A Bipartite Graph Approach with Ensemble Deep Learning for Enhanced Detection. Information. 2025; 16(2):97. https://doi.org/10.3390/info16020097
Chicago/Turabian StyleAlorainy, Wafa. 2025. "Unveiling XSS Threats: A Bipartite Graph Approach with Ensemble Deep Learning for Enhanced Detection" Information 16, no. 2: 97. https://doi.org/10.3390/info16020097
APA StyleAlorainy, W. (2025). Unveiling XSS Threats: A Bipartite Graph Approach with Ensemble Deep Learning for Enhanced Detection. Information, 16(2), 97. https://doi.org/10.3390/info16020097