
An Ensemble Framework for Text Classification


Abstract

1. Introduction
- To define a new general, domain-agnostic ensemble framework for text classification;
- To validate the applicability of the framework;
- To evaluate the effectiveness of combining classifiers’ knowledge against base classifiers and state-of-the-art (SotA) methods on several text classification datasets, and especially the effectiveness of combining knowledge from different data sections.
2. Related Work
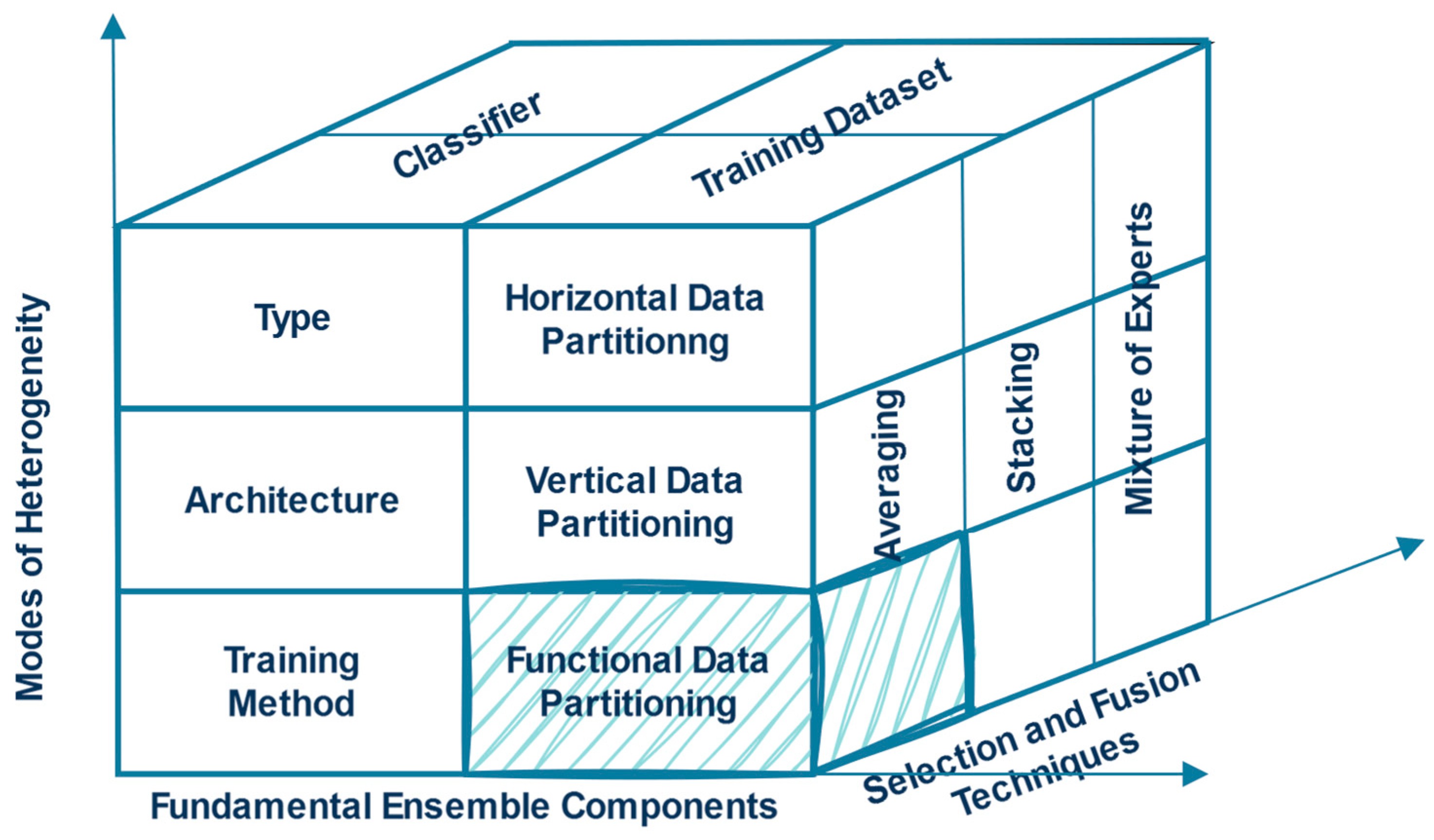
3. An Ensemble Framework for Text Classification
- Dimension 1: Fundamental Ensemble Components
- The training dataset is the training samples providing labeled ground truth pairs of inputs and expected outputs.
- The base classifiers are the learning models trained on the given training dataset.
- Dimension 2: Modes of Heterogeneity
- Dimension 2.a: Different training datasets—Data Heterogeneity
- The horizontal data partitioning creates different training datasets by resampling the entire training dataset into dataset partitions (also called bootstraps). By repeating the copying of random samples, representative new datasets are formed that resemble the population of the initial dataset. This is a statistical method for deriving robust estimates of population parameters like mean.
- The vertical data partitioning creates different training datasets by using various features of the original data, such as other modalities, e.g., the text and the accompanied graphics; different sections or metadata, e.g., the title’s and the main body’s text; or other data representations, e.g., TF-IDF and word embeddings.
- The functional data partitioning forms different training datasets using any function that splits the original data into subparts, e.g., different data partitions split the data based on the publication date or the labels.
- Dimension 2.b: Different base classifiers—Classifier Heterogeneity
- The type of the base classifier can be a traditional ML or a DL classification algorithm. Recently, a classification head/layer has been added at the end of a pre-trained LLM to predict the final label.
- The architecture of the base classifier can vary in several aspects, such as the type of network architecture, the number of layers/nodes, the number of filters, the loss function, the learning rate, the dropout rate, the weight initializations, and other hyper-parameters, e.g., the batch size, the number of epochs, etc.
- The training method of the base classifier can be a single or multi-label training method. Classifiers can be trained using the primary label or all available labels regardless of whether they are evaluated for a single label or for multiple labels. In the case of multi-label training, the labels can be represented as multi-hot encoded vectors or probability vectors [29].
- Dimension 3: Selection and Fusion Techniques
- The averaging techniques are score aggregation techniques that calculate the score based on a number of evidence types, e.g., voting, or simple data fusion algorithms, e.g., mean, medium, etc. A summary of different averaging techniques can be found in [30].
- The meta-learning techniques involve a meta-learning stage. The most common meta-learning techniques are stacking and the mixture of experts:
- In stacking, a meta-classifier is trained on features that are the outputs of base classifiers to learn how to combine their predictions best.
- In the mixture of experts, an expert classifier is trained on a sub-task and then a gating model is developed that learns which expert classifier to trust each time based on the input.
4. Homogeneous vs. Heterogeneous Ensembles
4.1. Homogeneous Approach
- Horizontal data partitioning—Bagging technique. A well-known ensemble learning technique, named Bagging [31], is used for creating different subsets of the training dataset, called bootstraps, resampling randomly, usually with replacement, the entire training dataset.
- Horizontal data partitioning—Adaboost technique. Another ensemble learning technique to create different subsets of the training dataset is the boosting technique. AdaBoost [32], one of the most well-known boosting techniques, prioritizes misclassified samples during the resampling of the entire training dataset to form sequential base classifiers.
- Vertical data partitioning—sections. The training datasets consist of different sections/metadata, e.g., the title, the abstract, the detailed description or main body, etc. These sections can be used to train different base classifiers.
- Functional data partitioning—label’s representation. A promising technique further described in [33] is to split the training dataset based on the labels’ frequency. Different subsets of the training dataset are formed with samples having high-represented and/or low-represented labels. The threshold under/over for which a code is considered high- or low-represented can be set from 100 to 500 training samples depending on the dataset’s size and labels’ distribution.
4.2. Heterogeneous Approach
- The type ofthe base classifier. Base classifiers may differ in the learning model. For example, different classification algorithms, such as RNN, CNN, or BERT, can be leveraged.
- The architecture of the base classifier. Base classifiers may differ how they structure the network architecture, with myriads of parameters available to differentiate their predictive behavior.
- The training method of the base classifier. Base classifiers can be trained by having as a target the primary category or the combined list of primary and secondary categories assigned by annotators [29]. For example, in patent test collections, such as the CLEFIP-0.54M and WIPO-alpha, the assigned classification codes have different priorities. The main classification code is the primary code of a patent document since it will be later classified and searched with this code. Secondary classification codes, called further, are also assigned to a patent document that corresponds to other relevant features of the invention that are not the most representative of the essential prior art, but they are still considered useful. Base classifiers can be trained in these datasets using the main or all classification codes. There are more origins of heterogeneity, e.g., classification codes can be represented as a multi-hot encoding or probability distribution vector. The probabilities can be evenly or unevenly assigned to categories based on additional annotator information, such as confidence and disagreement [29].
5. Data Collections
5.1. CLEFIP-0.54M
5.2. WIPO-Alpha
5.3. USPTO-2M
5.4. Web of Science (WOS-5736, WOS-11967, and WOS-46985)
5.5. EURLEX57K
6. Evaluate the Applicability of the Ensemble Framework
6.1. Experimental Methodology in the CLEFIP-0.54M Dataset
6.1.1. Base Classifier
6.1.2. Design Details of Homogeneous Ensemble Classifiers
- Horizontal data partitioning—Bagging technique: Random resampling is used to create the different training datasets, while the number of base classifiers varies from 3 to 5 and to 7.
- Horizontal data partitioning—Adaboost technique: Weights are set to concentrate on training samples that have been classified incorrectly. The number of sequential base classifiers varies from 3 to 5 and to 7 and their final prediction is taken by adding the weighted prediction of every classifier.
- Vertical data partitioning—sections: In addition to the abstract, we use the title, description, and claims sections of the patent document to train different base classifiers.
- Functional data partitioning—labels’ representation. Two base classifiers are created: one that is trained on patent documents of high-represented classification codes and one that is trained on patent documents of low-represented classification codes. The threshold under which a code is considered low-represented is set to 500 patent documents after an initial exploration of the accuracy attained as the patent frequency of codes increases.
6.1.3. Design Details of Heterogeneous Ensemble Classifiers
- The type of the base classifier. Different base classifiers are used in addition to a Bi-LSTM classifier. We use a bidirectional GRU (Bi-GRU), an LSTM, and a GRU classifier with similar network architectures. Details of the DL models can be found in [9].
- The architecture of the base classifier. Classifiers may differ in many ways concerning the network architecture. In this experiment, classifiers differ in the number of hidden units they use, adding another base classifier with 200 units.
- The training method of the base classifier. In the case of a heterogeneous ensemble using a different training method for base classifiers, these are trained to target either the main (i.e., single-label training method) or all IPC classification codes (i.e., multi-label training method). For the representation of all IPC classification codes, a greater probability of 0.6 is assigned to the main classification code, while the remaining probability of 0.4 is evenly distributed among all other IPC classification codes, i.e., further classification codes. For example, if there are 4 IPC classification codes (1 main and 3 further), they are assigned a probability of 0.6, 1.33, 1.33, and 1.33, respectively. In these cases, the Kullback–Leibler (KL) divergence loss is used instead of the categorical cross-entropy.
6.1.4. Combination Method
6.2. Results in the CLEFIP-0.54M Dataset
7. Evaluate the Effectiveness of Ensemble Systems
7.1. Experimental Methodology for Comparisons with SotA
7.2. Results for Comparisons with SotA
8. Discussion
8.1. Document Classification
8.2. Efficiency vs. Complexity
9. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Grawe, M.F.; Martins, C.A.; Bonfante, A.G. Automated patent classification using word embedding. In Proceedings of the 2017 16th IEEE International Conference on Machine Learning and Applications (ICMLA), Cancun, Mexico, 18–21 December 2017; pp. 408–411. [Google Scholar]
- Xiao, L.; Wang, G.; Zuo, Y. Research on patent text classification based on word2vec and LSTM. In Proceedings of the 2018 11th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 8–9 December 2018; Volume 1, pp. 71–74. [Google Scholar]
- Li, S.; Hu, J.; Cui, Y.; Hu, J. DeepPatent: Patent classification with convolutional neural networks and word embedding. Scientometrics 2018, 117, 2. [Google Scholar] [CrossRef]
- Risch, J.; Krestel, R. Domain-specific word embeddings for patent classification. Data Technol. Appl. 2019, 53, 108–122. [Google Scholar] [CrossRef]
- Lee, J.-S.; Hsiang, J. Patent classification by fine-tuning BERT language model. World Pat. Inf. 2020, 61, 101965. [Google Scholar] [CrossRef]
- Pujari, S.C.; Friedrich, A.; Strötgen, J. A multi-task approach to neural multi-label hierarchical patent classification using transformers. In Advances in Information Retrieval: 43rd European Conference on IR Research, ECIR 2021, Virtual Event, 28 March–1April 2021, Proceedings, Part I 43; Springer International Publishing: Cham, Switzerland, 2021; pp. 513–528. [Google Scholar]
- Zhou, Z.-H.; Wu, J.; Tang, W. Ensembling neural networks: Many could be better than all. Artif. Intell. 2002, 137, 239–263. [Google Scholar] [CrossRef]
- Benites, F.; Malmasi, S.; Zampieri, M. Classifying patent applications with ensemble methods. arXiv 2018, arXiv:1811.04695. [Google Scholar]
- Kamateri, E.; Stamatis, V.; Diamantaras, K.; Salampasis, M. Automated Single-Label Patent Classification using Ensemble Classifiers. In Proceedings of the 2022 14th International Conference on Machine Learning and Computing (ICMLC), Guangzhou, China, 18–21 February 2022; pp. 324–330. [Google Scholar]
- Hong, Z.; Wenzhen, J.; Guocai, Y. An effective text classification model based on ensemble strategy. J. Phys. Conf. Ser. 2019, 1229, 012058. [Google Scholar] [CrossRef]
- Kamateri, E.; Salampasis, M.; Diamantaras, K. An ensemble framework for patent classification. World Pat. Inf. 2023, 75. [Google Scholar] [CrossRef]
- Minaee, S.; Kalchbrenner, N.; Cambria, E.; Nikzad, N.; Chenaghlu, M.; Gao, J. Deep learning—Based text classification: A comprehensive review. ACM Comput. Surv. (CSUR) 2021, 54, 1–40. [Google Scholar] [CrossRef]
- Sun, X.; Li, X.; Li, J.; Wu, F.; Guo, S.; Zhang, T.; Wang, G. Text Classification via Large Language Models. arXiv 2023, arXiv:2305.08377. [Google Scholar]
- Mohammed, A.; Kora, R. A novel effective ensemble deep learning framework for text classification. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 8825–8837. [Google Scholar] [CrossRef]
- Mohammed, A.; Kora, R. A comprehensive review on ensemble deep learning: Opportunities and challenges. J. King Saud Univ.-Comput. Inf. Sci. 2023, 35, 757–774. [Google Scholar] [CrossRef]
- Larkey, L.S.; Croft, W.B. Combining classifiers in text categorization. In Proceedings of the 19th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Zurich, Switzerland, 18–22 August 1996; pp. 289–297. [Google Scholar]
- Boroš, M.; Maršík, J. Multi-label text classification via ensemble techniques. Int. J. Comput. Commun. Eng. 2012, 1, 62–65. [Google Scholar] [CrossRef]
- Anderlucci, L.; Guastadisegni, L.; Viroli, C. Classifying textual data: Shallow, deep and ensemble methods. arXiv 2019, arXiv:1902.07068. [Google Scholar]
- Dong, Y.-S.; Han, K.-S. A comparison of several ensemble methods for text categorization. In Proceedings of the 2004 IEEE International Conference on Services Computing (SCC), Shanghai, China, 15–18 September 2004; pp. 419–422. [Google Scholar]
- Gangeh, M.J.; Kamel, M.S.; Duin, R.P. Random subspace method in text categorization. In Proceedings of the 2010 20th International Conference on Pattern Recognition (ICPR), Istanbul, Turkey, 23–26 August 2010; pp. 2049–2052. [Google Scholar]
- Xia, R.; Zong, C.; Li, S. Ensemble of feature sets and classification algorithms for sentiment classification. Inf. Sci. 2011, 181, 1138–1152. [Google Scholar] [CrossRef]
- Jurek, A.; Bi, Y.; Wu, S.; Nugent, C. A survey of commonly used ensemble-based classification techniques. Knowl. Eng. Rev. 2014, 29, 551–581. [Google Scholar] [CrossRef]
- Xu, C.; Tao, D.; Xu, C. A survey on multi-view learning. arXiv 2013, arXiv:1304.5634. [Google Scholar]
- Gonçalves, C.A.; Vieira, A.S.; Gonçalves, C.T.; Camacho, R.; Iglesias, E.L.; Diz, L.B. A novel multi-view ensemble learning architecture to improve the structured text classification. Information 2022, 13, 283. [Google Scholar] [CrossRef]
- Kumar, V.; Minz, S. Multi-view ensemble learning: An optimal feature set partitioning for high-dimensional data classification. Knowl. Inf. Syst. 2015, 49, 1–59. [Google Scholar] [CrossRef]
- Hu, X. Using rough sets theory and database operations to construct a good ensemble of classifiers for data mining applications. In Proceedings of the 2001 IEEE International Conference on Data Mining, San Jose, CA, USA, 29 November–2 December 2001; pp. 233–240. [Google Scholar]
- Kuncheva, L.I.; Whitaker, C.J. Measures of diversity in classifier ensembles and their relationship with the ensemble accuracy. Mach. Learn. 2003, 51, 181–207. [Google Scholar] [CrossRef]
- Brown, G.; Wyatt, J.; Harris, R.; Yao, X. Diversity creation methods: A survey and categorisation. Inf. Fusion 2004, 6, 5–20. [Google Scholar] [CrossRef]
- Wu, B.; Li, Y.; Mu, Y.; Scarton, C.; Bontcheva, K.; Song, X. Don’t waste a single annotation: Improving single-label classifiers through soft labels. In Findings of the Association for Computational Linguistics: EMNLP 2023; Association for Computational Linguistics: Singapore, 2023; pp. 5347–5355. [Google Scholar]
- Paltoglou, G.; Salampasis, M.; Satratzemi, M. Simple adaptations of data fusion algorithms for source selection. In Proceedings of the 31th European Conference on Information Retrieval, Toulouse, France, 6–9 April 2009; pp. 497–508. [Google Scholar]
- Freund, Y.; Schapire, R.E. Experiments with a new boosting algorithm. In Proceedings of the 13th International Conference on International Conference on Machine Learning, ICML’96, Bari, Italy, 3–6 July 1996; Volume 96, pp. 148–156. [Google Scholar]
- Bühlmann, P. Bagging, boosting and ensemble methods. In Handbook of Computational Statistics; Springer: Berlin/Heidelberg, Germany, 2012; pp. 985–1022. [Google Scholar]
- Kamateri, E.; Salampasis, M. Ensemble Method for Classification in Imbalanced Patent Data. In Proceedings of the 4th Workshop on Patent Text Mining and Semantic Technologies (PatentSemTech 2023 in Conjunction with SIGIR 23), Taipei, Taiwan, 27 July 2023. [Google Scholar]
- CLEFIP-0.54M. Available online: https://github.com/ekamater/CLEFIP-0.54M (accessed on 18 October 2024).
- USPTO-2M. Available online: https://github.com/JasonHoou/USPTO-2M (accessed on 18 October 2024).
- Haghighian Roudsari, A.; Afshar, J.; Lee, W.; Lee, S. PatentNet: Multi-label classification of patent documents using deep learning based language understanding. Scientometrics 2021, 127, 207–231. [Google Scholar] [CrossRef]
- Kowsari, K.; Brown, D.; Heidarysafa, M.; Jafari Meimandi, K.; Gerber, M.; Barnes, L. Web of Science Dataset. Mendeley Data. 2018. V6. Available online: https://data.mendeley.com/datasets/9rw3vkcfy4/6 (accessed on 18 October 2024).
- Chalkidis, I.; Fergadiotis, M.; Malakasiotis, P.; Androutsopoulos, I. Large-Scale Multi-Label Text Classification on EU Legislation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL 2019), Florence, Italy, 28 July–2 August 2019. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Zhang, X.; Zhao, J.; LeCun, Y. Character-level convolutional networks for text classification. Adv. Neural Inf. Process. Syst. 2015, 28, 649–657. [Google Scholar]
- Kowsari, K.; Brown, D.E.; Heidarysafa, M.; Meimandi, K.J.; Gerber, M.S.; Barnes, L.E. Hdltex: Hierarchical deep learning for text classification. In Proceedings of the 2017 16th IEEE International Conference on Machine Learning and Applications (ICMLA), Cancun, Mexico, 18–21 December 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 364–371. [Google Scholar]
- Fall, C.J.; Törcsvári, A.; Benzineb, K.; Karetka, G. Automated categorization in the international patent classification. ACM SIGIR Forum 2003, 37, 10–25. [Google Scholar] [CrossRef]
- Abdelgawad, L.; Kluegl, P.; Genc, E.; Falkner, S.; Hutter, F. Optimizing neural networks for patent classification. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases; Springer International Publishing: Cham, Switzerland, 2019; pp. 688–703. [Google Scholar]
- Aroyehun, S.T.; Angel, J.; Majumder, N.; Gelbukh, A.; Hussain, A. Leveraging label hierarchy using transfer and multi-task learning: A case study on patent classification. Neurocomputing 2021, 464, 421–431. [Google Scholar] [CrossRef]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the 32th International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical attention networks for document classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1480–1489. [Google Scholar]
- Mullenbach, J.; Wiegreffe, S.; Duke, J.; Sun, J.; Eisenstein, J. Explainable prediction of medical codes from clinical text. arXiv 2018, arXiv:1802.05695. [Google Scholar]
- Gao, S.; Alawad, M.; Young, M.T.; Gounley, J.; Schaefferkoetter, N.; Yoon, H.J.; Wu, X.-C.; Durbin, E.B.; Doherty, J.; Stroup, A.; et al. Limitations of transformers on clinical text classification. IEEE J. Biomed. Health Inform. 2021, 25, 3596–3607. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Document Type | Task(s) | #Labels | #Train/Test |
|---|---|---|---|---|
| CLEFIP-0.54M | Patent documents | Single and multi-label | 731 main and 810 main and further | 487,018/54,113 |
| WIPO-alpha | Patent documents | Single and multi-label | 451 main and 633 main and further | 46,324/28,926 |
| USPTO-2M * | Patent documents | Multi-label | 544 | 1,947,223/49,888 |
| WOS-5736 WOS-11967 WOS-46985 | Scientific publications | Single-label | 11 35 134 | 5162/574 10,770/1197 42,286/4699 |
| EURLEX57K | Legislative documents | Multi-label | ~4.2K | 45,000/6000 |
| Bagging Technique | Adaboost Technique | |||||
|---|---|---|---|---|---|---|
| Base classifier #1 | 61.74% | 61.93% | 61.83% | 63.73% | 63.86% | 63.73% |
| Base classifier #2 | 62.08% | 61.78% | 61.86% | 61.98% | 62.14% | 61.98% |
| Base classifier #3 | 62.01% | 61.74% | 62.03% | 62.05% | 61.79% | 62.01% |
| Base classifier #4 | 61.92% | 61.89% | 62.16% | 62.02% | ||
| Base classifier #5 | 62.09% | 61.94% | 61.75% | 61.82% | ||
| Base classifier #6 | 61.97% | 62.19% | ||||
| Base classifier #7 | 61.93% | 61.88% | ||||
| Ensemble | 64.85% | 65.70% | 65.90% | 65.31% | 65.76% | 66.07% |
| Improvement | 2.91% | 3.81% | 3.98% | 2.72% | 3.42% | 3.84% |
| Sections | |
|---|---|
| Base classifier #1 trained on titles | 59.58% |
| Base classifier #2 trained on abstracts | 63.76% |
| Base classifier #3 trained on descriptions | 66.46% |
| Base classifier #4 trained on claims | 64.56% |
| Ensemble | 70.54% |
| Improvement | 6.95% |
| Labels’ Representation | |
|---|---|
| Base classifier #1 trained on low-represented labels | 9.37% (65.72%) |
| Base classifier #2 trained on high-represented labels | 63.91% (68.02%) |
| Ensemble | 68.15% |
| Improvement | 4.39% |
| Type | Architecture | Training Method | |||
|---|---|---|---|---|---|
| Bi-LSTM Bi-GRU | 63.76% 63.45% | Bi-LSTM—100 units | 63.76% | Single-label training method | 63.76% |
| LSTM | 63.08% | Bi-LSTM—200 units | 64.21% | Multi-label training method | 63.37% |
| GRU | 63.41% | ||||
| Ensemble | 65.90% | Ensemble | 65.59% | Ensemble | 65.38% |
| Improvement | 2.48% | Improvement | 1.61% | Improvement | 1.82% |
| Method | Accuracy of Ensemble Systems (ES) | Accuracy of Ensemble of ES | Improvement | ||||
|---|---|---|---|---|---|---|---|
| Title | Abstract | Description | Claims | ||||
| Homogeneous | Bagging technique | 61.31% | 65.90% | 68.36% | 66.38% | 70.80% | +7.04% |
| Adaboost technique | 61.38% | 66.07% | 68.67% | 66.65% | 70.93% | +7.17% | |
| Labels’ representation | 62.46% | 68.15% | 71.10% | 68.88% | 75.15% | +11.39% | |
| Heterogeneous | Type | 62.21% | 66.34% | 68.94% | 66.91% | 71.19% | +7.43% |
| Architecture | 61.56% | 65.59% | 68.06% | 66.43% | 71.57% | +7.81% | |
| Training method | 60.43% | 65.38% | 67.69% | 65.86% | 70.70% | +6.94% | |
| Method | WOS-5736 | WOS-11967 | WOS-46985 | |
|---|---|---|---|---|
| Accuracy | Accuracy | Accuracy | ||
| SotA | CNN [40] | 70.46% | 83.29% | 88.68% |
| RNN [40] | 72.12% | 83.96% | 89.46% | |
| HDLTex [41] | 76.58% | 86.07% | 90.93% | |
| Ensemble (Sections) | 79.17% | 82.79% | 90.24% | |
| Base Classifiers (Bi-LSTM) | Keywords | 53.69% | 69.26% | 70.56% |
| Abstract | 76.04% | 75.36% | 89.72% | |
| Method | Top 1 vs. Main | Top 1 vs. Main + Further | Top 3 vs. Main | |
|---|---|---|---|---|
| SotA | Bi-GRU [4] | 49% | - | - |
| CNN [43] | 55.02% | - | - | |
| Bi-GRU [44] | 53.76% | 62.65% | 76.97% | |
| Ensemble (Sections) | 58.36% | 67.90% | 82.41% | |
| Base Classifiers (Bi-LSTM) | Title | 44.77% | 53.28% | 68.50% |
| Abstract | 50.18% | 60.06% | 75.72% | |
| Description | 54.07% | 63.32% | 78.74% | |
| Claims | 50.26% | 58.99% | 74.79% | |
| Method | P@1 | R@1 | F1@1 | |
|---|---|---|---|---|
| SotA | PatentBERT [5] | 80.61% | 54.33% | 64.91% |
| DeepPatent [3] | 73.88% | - | - | |
| PatentNet XLNet [36] | 86% | 42.9% | 57.2% | |
| Ensemble (Sections) | 80.16% | 41.71% | 54.87% | |
| Base Classifiers (Bi-LSTM) | Title | 70.64% | 36.76% | 48.36% |
| Abstract | 77.20% | 40.18% | 52.85% | |
| Concat. title and abstract | 79.02% | 41.12% | 54.09% | |
| Method | P@1 | P@5 | R@1 | R@5 | |
|---|---|---|---|---|---|
| SotA | BiGRU-ATT [45] | 89.90% | 65.40% | 20.40% | 68.50% |
| HAN [46] | 89.40% | 64.30% | 20.30% | 67.50% | |
| BIGRU-LWAN [47] | 90.70% | 66.10% | 20.50% | 69.20% | |
| BERT-BASE [38] | 92.20% | 68.70% | 20.90% | 71.90% | |
| Ensemble (Sections) | 89.07% | 64.78% | 17.60% | 64.02% | |
| Base classifiers (Bi-LSTM) | Title | 84.83% | 61.37% | 16.77% | 60.65% |
| Header | 85.35% | 61.29% | 16.87% | 60.57% | |
| Recitals | 83.10% | 60.21% | 16.43% | 59.50% | |
| Main body | 81.45% | 59.94% | 16.10% | 59.23% | |
| Attachments | 52.67% | 38.42% | 10.41% | 37.97% | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kamateri, E.; Salampasis, M. An Ensemble Framework for Text Classification. Information 2025, 16, 85. https://doi.org/10.3390/info16020085
Kamateri E, Salampasis M. An Ensemble Framework for Text Classification. Information. 2025; 16(2):85. https://doi.org/10.3390/info16020085
Chicago/Turabian StyleKamateri, Eleni, and Michail Salampasis. 2025. "An Ensemble Framework for Text Classification" Information 16, no. 2: 85. https://doi.org/10.3390/info16020085
APA StyleKamateri, E., & Salampasis, M. (2025). An Ensemble Framework for Text Classification. Information, 16(2), 85. https://doi.org/10.3390/info16020085