1. Introduction
In a fast-paced innovation and intellectual property era, it has become crucial to develop tools and techniques to make use of a plethora of information found in patent documents. Patents not only grant exclusive rights to the inventors but also help provide information on trailblazing technology and innovations, and the most recent advancements across a wide array of fields [
1]. There is an ever-increasing demand for invention and innovation with the advancement in technology. This has led to a sharp increase in patent applications being filed every year, prompting the demand for robust and efficient patent retrieval systems [
2].
The main focus of patent retrieval, which is considered a subcategory of information retrieval, is to respond to specific search requests by extracting relevant patent documents from a huge patent database [
3]. Patent searches are vital to fulfil the essential functions of these patent systems [
4]. The patent retrieval process comprises the search, retrieval, and analysis of patent documents. In a patent application’s lifecycle, patent retrieval plays a pivotal role. From the early stages of invention disclosure and prior art searching to the ongoing stages of prosecution, enforcement, and maintenance, the extraction of relevant patent data and documents is needed. To make sure that patent applications are unique and inventive, the applications have to pass through a comprehensive scrutiny process. Required patent searches must be conducted for this purpose. Likewise, when disputes arise between patent owners and claimed infringers, the alleged infringers re-evaluate the awarded patents to determine their legal validity which also involves an array of patent searches [
5].
Patent retrieval searches have transformed substantially over the years, evolving from conventional Boolean and keyword-based approaches to advanced context-based approaches facilitated by deep learning (DL) and natural language processing (NLP). The Boolean logic-based information retrieval (IR) method treats documents as groups of words and states queries as Boolean expressions that mingle terms using operators such as AND, OR, and NOT [
6]. Boolean search is limited since it cannot factor in the complexity of patent language; instead, it only reflects upon strict term matching without taking synonyms or contextual nuances into consideration. This may lead to important information oversights [
6,
7,
8]. On the other hand, keyword-based patent search involves the input of specific terms to create a query, with the challenge of figuring out how many keywords to use to avoid results that are too broad or too narrow, which could affect the accuracy of the analysis and cause bias [
9]. The term “contextual searches” refers to search techniques that examine the relationships, meaning and broader context of the searched-for item. Contextual searches leverage advanced methods, such as transformer models like Bidirectional Encoder Representations from Transformers (BERT) and semantic analysis to comprehend the context and relationships within the patent documents. Contextual retrieval improves accuracy in patent information retrieval by identifying the user’s needs (search context) and adjusting the search process accordingly. This increases the effectiveness and adaptability of Intelligent Retrieval Systems (IRSs), streamlines the patent search process, and boosts performance [
10].
This research study draws its inspiration from references [
4,
11]. The authors of the former research provided a dataset on patent examinations at the European Patent Office (EPO), in which text passages classified as general state-of-the-art ‘A’ and ‘X’ for specific relevance were used by the authors to match patent claims. The authors observed that the challenging nature of the task is apparent, with a 54% test set accuracy standard BERT model struggling to identify complex linguistic patterns, legal jargon, and patent-specific language [
11]. The latter study produced a BERT training method for associating patent descriptions with its claims to effectively identify novelty-threatening content in other patents or non-patent literature [
4]. However, when working with large datasets, the computational cost of training BERT on lengthy descriptions can lead to significant processing overhead, which can affect the model’s scalability and efficiency [
12].
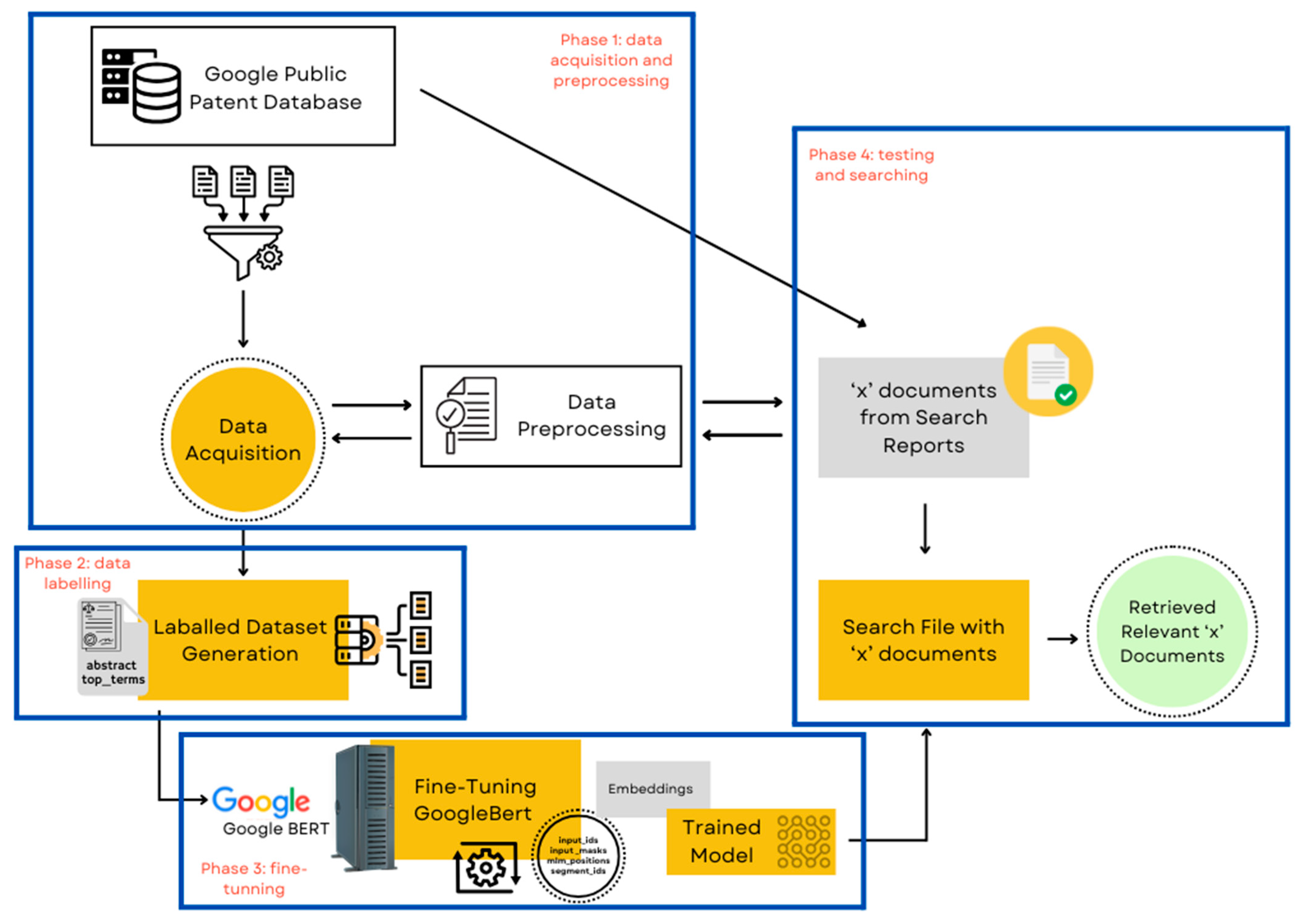
In light of this, we suggest a prior art search method that leverages the abstract of patent documents and sets of relevant search terms both sourced from the Google Public Patent Database to locate relevant articles associated with a given patent document. Combining abstracts with commonly searched terms takes advantage of the comprehensive context that abstracts provide along with the specificity of search terms, making information retrieval more relevant and precise. The suggested approach operates on the premise that the search terms contained in a patent document act as a key to that particular innovation.
According to the proposed methodology, when searching for prior art for a given patent application, the existing patent is considered prior art if the abstract of the given invention matches the search terms of the existing patent. First, we generate a dataset by the concatenation of abstracts and search term sets. Next, the obtained dataset is used to fine-tune BERT for the patents model [
13]. Finally, we train the model to recognize prior art for a specific patent document. To test our approach, similar to in reference [
4], search reports are utilized to determine whether our method can find referenced ‘x’ documents in search reports. The following are the main contributions of this study:
Aid prior art exploration: This approach assists in finding prior art that was unknown to the applicant, attorney, and examiner. This approach can reduce the overall patent processing timespan by completing the prior art phase efficiently and accurately.
Utilization of BERT (Bidirectional Encoder Representations from Transformers) for patents: The proposed method utilizes BERT for patents, which tackles patent-specific terminologies and legal jargon, hence improving the efficiency and accuracy of patent analysis, retrieval, and decision-making processes.
Enhanced results: Outperformed [
4] by attaining an F1 score of 0.94 and successfully identifying multiple relevant patent documents.
In addition to the above-mentioned contributions, the suggested approach generates a dataset that reduces the computation complexity because, in comparison to the claims and description of the invention, abstract and top terms are computationally light. This will help to efficiently process large databases containing millions of patent documents.
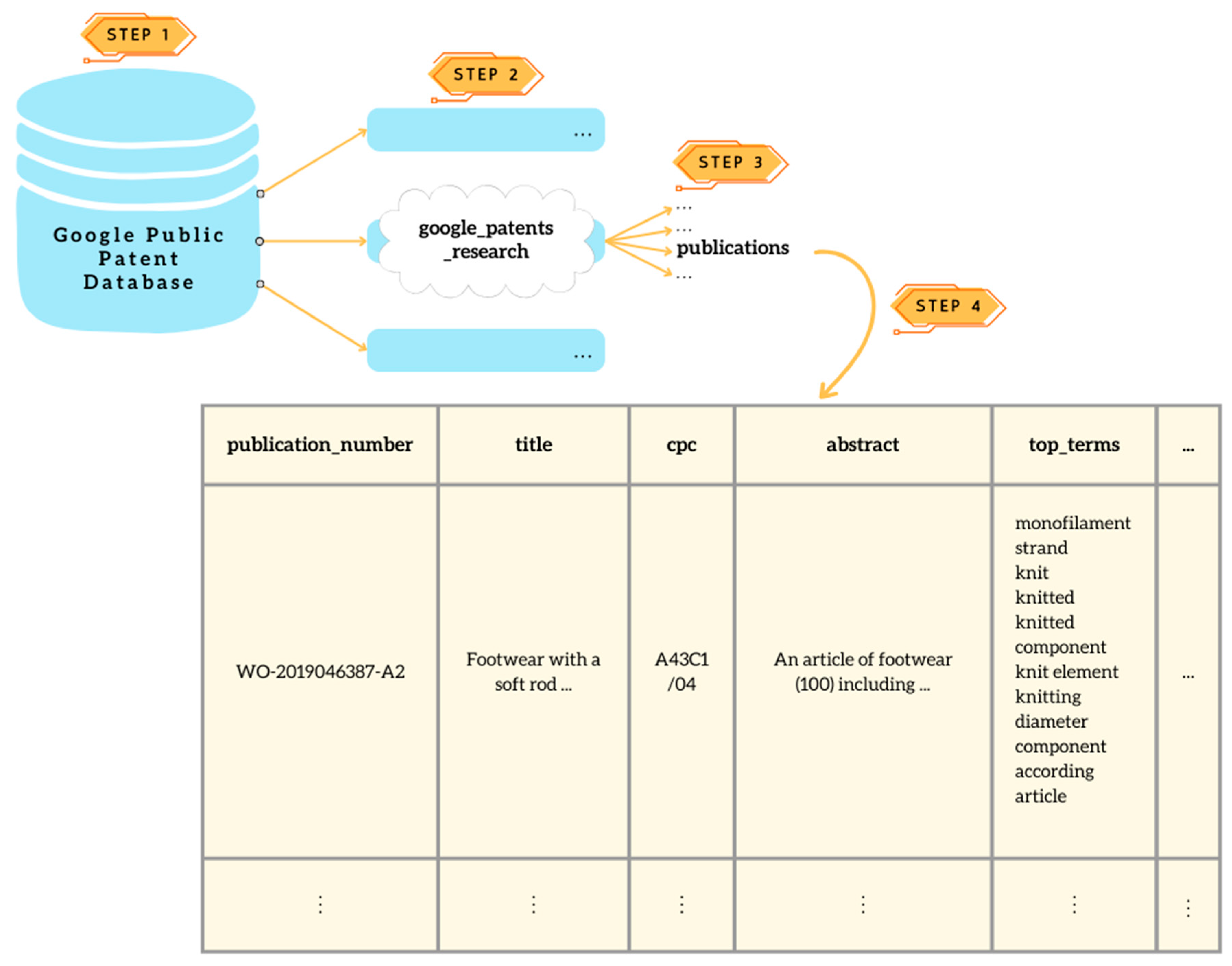
Moreover, the described search methodology is simple and adaptable yet robust in comparison to the existing methodologies. Furthermore, the proposed approach utilizes Google’s public patent database for training, testing, and verification purposes which enables the exploration of patents from a multitude of jurisdictions, providing a thorough picture of creative advancements made worldwide. It encompasses over 87 million full-text patents from 17 different patent offices worldwide, including the European Patent Office (EPO) and the United States Patent and Trademark Office (USPTO).
The subsequent sections of the paper are organized as follows:
Section 2 provides a comprehensive review of the existing literature, providing insights into the current knowledge landscape.
Section 3 presents our proposed approach and various components including the procedures utilized for data collection, data pre-processing, the methodology for data annotation and generation of the labelled dataset, and the utilization and fine-tuning of the transformer model.
Section 4 explains the experimental setup in detail and gives a detailed investigation of our findings and results.
Section 5 concludes the paper by summarizing key findings and talking about future research directions.
2. Related Works
Patents are intricate legal documents that can range in length, follow stringent formal semantic and syntactic patterns, and frequently use both common and specialist acronyms and domain-specific terms [
14,
15,
16]. Patent examiners perform a prior art search on these complicated documents to evaluate the novelty, non-obviousness, and patentability of filed patent applications. Even for well-trained patent examiners, finding related prior work is a challenging and time-consuming task [
11], with a significant chance that important documents are being overlooked [
17,
18].
Automating patent search and using the capabilities of deep learning and natural learning processing can boost the performance of the prior art search process, leading to faster and more precise identification of relevant prior art documents [
4,
19]. However, automating this task is challenged by patent-specific language, which incorporates legal terminologies and specialized language. As a result, deep learning methods inside the patent domain now incorporate patent-specific word embeddings [
20]. Word embeddings are low-dimensional compact vector representations of words that give us the ability to transform words into numerical vectors, and this conversion enables us to measure and manipulate the semantic significance of words through mathematical operations [
21].
Traditional word embedding methods, such as word2vec and Glove, produce universal word embeddings by first creating a large vocabulary based on distinctive terms in the documents [
22]. However, they ignore the context-sensitive meaning of the words. The use of contextual embedding methods, such as ELMo and BERT, allows for the capture of sequence-level semantics by taking into account the complete word order in the documents. In turn, this leads to the creation of various representations for words that have multiple meanings [
2].
Pre-trained natural language processing (NLP) models, such as BERT, GPT-3, or RoBERTa, provide a solid foundation for language comprehension, and fine-tuning makes them excel in particular downstream tasks by letting them use their general language knowledge to address task-specific problems [
23,
24,
25]. For patent classification, pre-trained BERT that has been fine-tuned on a large dataset of USPTO 3M, along with SQL commands, has been shown to outperform the previous state-of-the-art DeepPatent, which uses a convolutional neural network (CNN) and word embedding [
26,
27]. A recent study investigates two ways of improving prior art search: first, by improving end-to-end neural retrieval strategies by adjusting them to patent characteristics, and second, by using machine learning models to solve the result merging problem in federated search. In particular, it presents a gate-based document retrieval strategy that enhances BERT’s effectiveness for patent search by combining BM25 and BERT for improved retrieval performance [
28].
The BERT for Patents model is the first BERT algorithm that is trained on patent text data. Authors in this innovative study [
13] investigate the use of BERT to produce contextual synonyms for patents, which is a significant advancement in the field of natural language processing [
29]. Moreover, Google’s BERT for Patents model has also been utilized for multi-label patent classification on a recently proposed USPTO dataset consisting of 2.8 million patent claims, using machine learning models such as Nave Bayes (NB) and Support Vector Machine (SVM), producing a noticeable improvement of micro-F1 scores [
30]. Furthermore, SEARCHFORMER is a study that refined a patent-specific BERT model on real-world patent examples. The model significantly outperforms baselines in retrospective ranking experiments, signifying its effectiveness in identifying relevant prior art for patent documents [
31]. A recent study introduced an ensemble BERT-based model that integrates four BERT-related models, including BERT for Patents. The authors demonstrated that their proposed model outperforms other traditional models in patent classification and retrieval tasks [
32], highlighting the advantages of integrating multiple transformer-based architectures for enhanced performances.
Machine learning (ML) models are trained and evaluated using labelled data that have been meticulously collected by experts in the field, for specific tasks. Finding sizable, readily available, and well-labelled datasets in the patent domain can be difficult because of the specialized nature of patent documents and the difficult tasks involved in patent analysis. To overcome this data scarcity and close the gap between the development of machine learning solutions in the patent domain and the necessity for labelled data, researchers and organizations frequently create their own training datasets. As a result, a dataset called PatentMatch was introduced, consisting of pairs of text passages in the patent domain that share semantic similarities. It aims to speed up the time-consuming and complex prior art search process for patent examiners with the help of computer-assisted prior art search [
11]. A comparable approach, combining patent claims with their related descriptions using BERT, has been proposed to identify pertinent descriptions for patent novelty [
4]. A re-ranking approach has also been proposed by leveraging Sentence-BERT (SBERT) and BM25 to enhance the understanding of semantic similarity in patent retrieval [
33]. By integrating the contextual embedding capability of SBERT and the lexical matching capability of BM25, the study aimed to enhance the performance of patent retrieval tasks, addressing limitations in conventional keyword-based methods. Another study describes a machine learning (ML) and natural language processing (NLP) method to enhance and automate patent prior art searches [
8]. The process includes creating a dataset, converting patent texts into numerical feature vectors, assessing similarity metrics to automatically identify pertinent prior art, and contrasting the outcomes with cited and patent attorney-identified documents [
8]. The role of AI-driven NLP in patent retrieval is also becoming increasingly important in assisting patent examiners to retrieve relevant patents with higher efficiency and accuracy during prior art searches. BERT-based embeddings have been proven particularly useful in enhancing query interpretation, thereby improving search results by capturing deeper contextual relationships between patent documents [
34].
Patent retrieval for prior art searches is a complex task and the effectiveness of the retrieval results can be measured by various metrics, including recall, precision, Mean Average Precision (MAP), F1-score, and accuracy [
35]. While most studies report only on a subset of these metrics based on their research focus, relatively few studies provide a comprehensive evaluation covering all of the key performance metrics [
35].
This study presents a paradigm that incorporates insights from various approaches. It utilizes the capabilities of the BERT for Patents model which has an extended set of vocabulary tailored specifically for patents and extensively pre-trained on millions of patent documents, which adds a layer of scrutiny to patent content. Moreover, our approach makes use of abstracts of the patent documents instead of claims, which relaxes term specifications in patent documents. Domain-specific fine-tuning of the model is performed using the labelled dataset to optimize our prior art search use case. This approach also focuses on computational efficiency. Our experimental analysis focuses on gauging the performance of our proposed approach based on recall, precision, F1-score, and accuracy.
4. Results and Discussion
This section provides a comprehensive explanation of the steps and methodology employed for conducting experimental investigation. The experiments were performed using Python 3.10.13 on a system equipped with an Intel (X) Xeon(R) Gold 6330 CPU @ 2.00 GHz 28 cores processor and 256 GB random access memory (RAM).
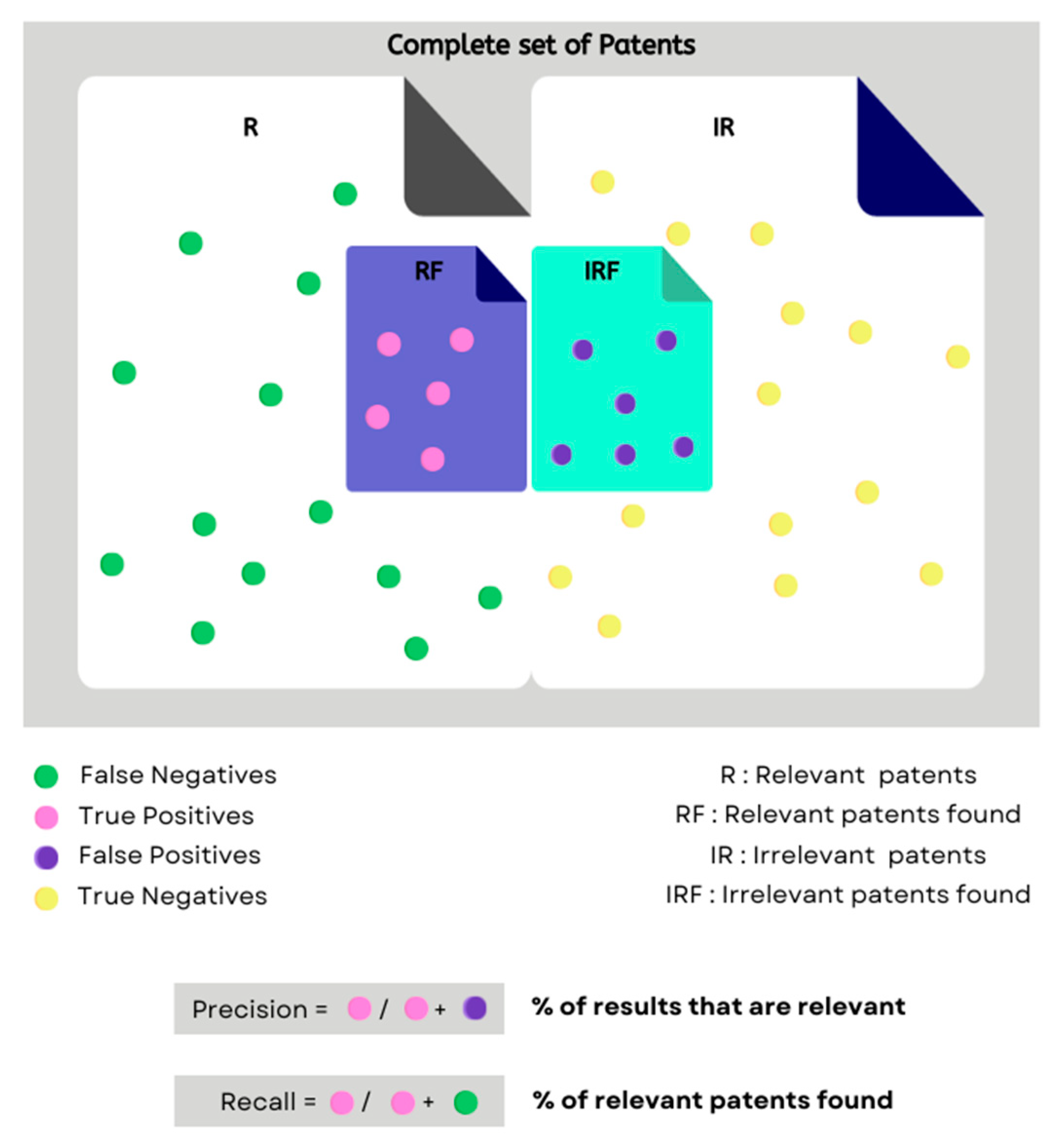
In information retrieval, various evaluation metrics such as precision, recall, and F1 score are commonly used to evaluate the usefulness of the system. Precision assesses the accuracy of the retrieved documents by calculating the ratio of relevant ones among those obtained, while recall evaluates the system’s ability to retrieve all relevant documents from the complete collection [
41]. However, in the context of patent retrieval, where databases include massive amounts of documents, recall is often emphasized to ensure that the search results capture every possibly relevant document, leaving no room for error. Thus, maximizing recall is particularly critical in patent retrieval systems that serve users who need a comprehensive overview of prior art or relevant inventions in a certain technological domain to make informed decisions about the novelty and validity of an invention.
Figure 7 displays the visual breakdown of recall and precision.
The testing set of 100 patent documents resulted in a total of 10,000 text pairs of patent abstracts and top terms. The word embeddings, which were generated using BERT for patents, were used as an input to the classifier, resulting in an accuracy of 94% and an F1 score of 0.94. These results, summarized in
Table 5, demonstrate a significant improvement over baseline approaches. A key limitation of the PatentMatch [
11] study is that it does not report recall, precision and F1 score, making a direct comparison to the proposed method difficult. Similarly, the claims-to-description [
4] study provides only its F1-score, without reporting accuracy, recall and precision. The absence of recall in these studies is particularly notable, as ensuring comprehensive retrieval of relevant prior art is critical in patent searches. On the other hand, the proposed method reports all four key evaluation metrics, with a particular focus on recall, reinforcing its importance in reducing the risk of missing relevant prior art and enhancing retrieval effectiveness for patent examiners.
Additionally, while the reported F1-score of 0.943 is only marginally higher than the 0.93 reported in study [
4], this indicates that the proposed method achieves comparable performance while utilizing a different approach to prior art retrieval. More importantly, since recall is not explicitly reported in [
4], it remains unclear how effectively that approach retrieves all relevant prior art. Furthermore, a notable improvement is observed in accuracy, with PatentMatch [
11] reporting only 54% accuracy, whereas the proposed method achieves 94% accuracy, highlighting a substantial increase in retrieval precision.
Table 6 highlights the outcomes of the second test, which evaluates the prior art search performance of the fine-tuned BERT for Patents model using search reports issued by patent offices. The testing approach follows the same criteria as references [
4,
11], where the objective is to identify ‘X’ documents within a dataset of patent documents, using search reports for validation. The first column lists the patent documents under investigation, whilst the second column lists the corresponding ‘X’ document for each of the patent documents under investigation. The third column shows the top terms extracted from different parts of the ‘X’ patent document, and the final column shows the prior art search result as ‘Relevant’ or ‘Irrelevant’ depending upon how our model identifies the relevance of the given abstract with the matching ‘X’ document top terms.
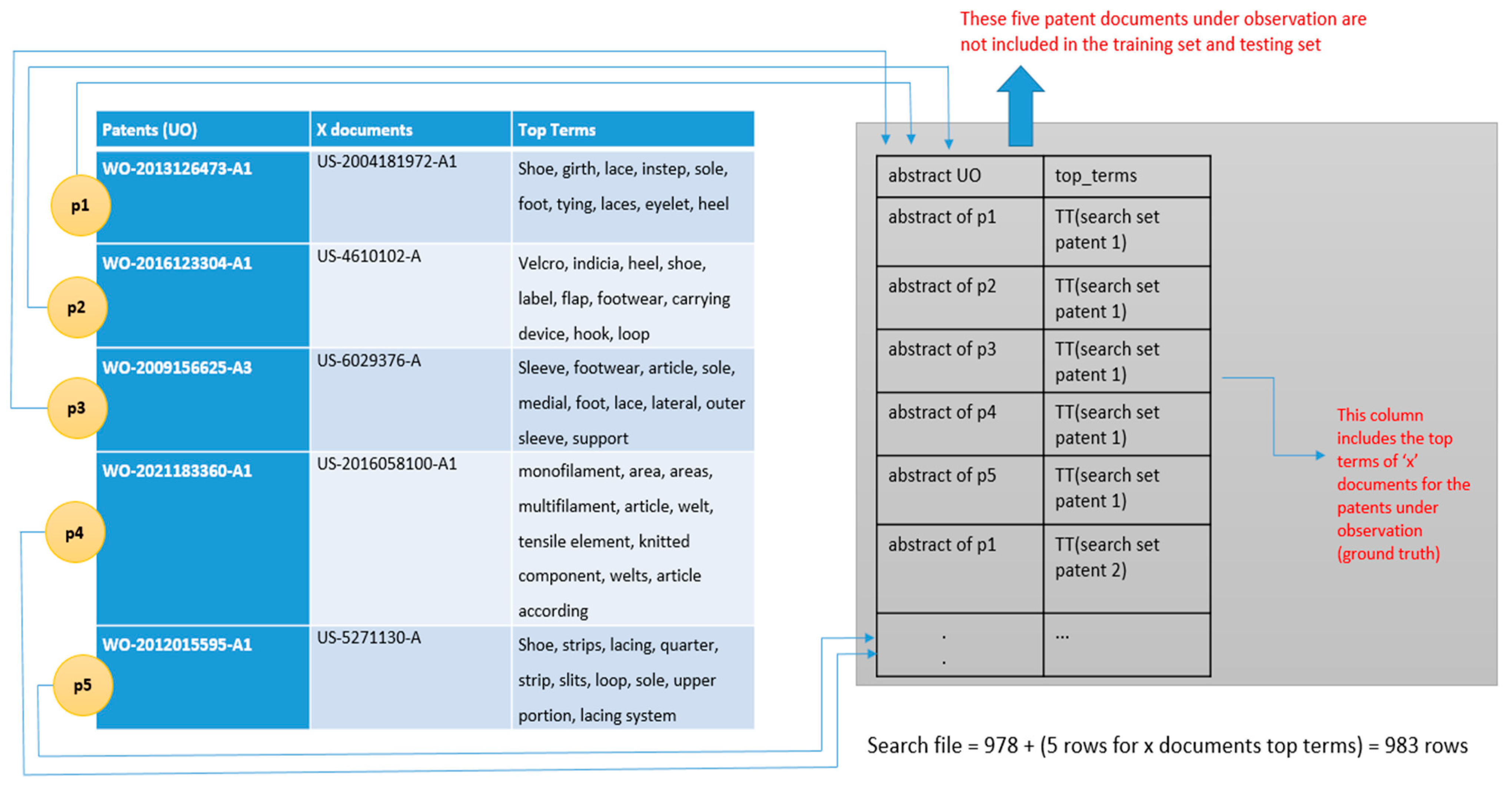
Out of the five patent documents under investigation, two documents were marked ‘Relevant’ by the fine-tuned model. A closer analysis of these two patent documents, i.e., ‘WO-2013126473-A1’ and ‘WO-2012015595-A1’ marked as relevant, reveals that the former and latter documents identified 43 and 39 sets of top terms as highly relevant when compared against 983 sets of top terms. This set of top terms included the top terms of the relevant ‘X’ documents as well. The numbers of top terms marked as relevant were quite high, likely due to the fact that they were extracted from patents belonging to the same classification category of CPC: A43C1/04. Nevertheless, these marked relevant patent documents can help narrow down the prior art search since the examiner will just have to go through an extremely small set of patent documents, thereby making the prior art search much more efficient.
It is noted that the abstract of a patent document does not define the scope of the invention; rather, it explains the invention. On the other hand, the set of top terms comprises key terms extracted from various parts of the patent document, including description, abstract, and claim. Nevertheless, the top terms alone are not enough to define the legal and technical boundaries of the invention. In the case of the patent document under investigation ‘WO-2016123304-A1’, the model should have been identified as relevant to the top terms of ‘X’ patent document ‘US-4610102-A’. This is similar to patent documents under investigation ‘WO-2009156625-A3’ and ‘WO-2021183360-A1’. Nevertheless, the classification of the ‘X’ patent document as ‘irrelevant’ by our fine-tuned BERT for patents could be attributed to the possibility that while the top terms capture the essence of the entire ‘X’ patent document, they might lack the critical relevant terms necessary to align with the abstract of the patent under investigation.
One of the key motivations for this research is the development of effective, open-access search tools for patent examiners and researchers. To assess the effectiveness of such tools, an evaluation test was conducted using Minesoft [
42], a widely used global patent intelligence and search platform that also offers commercial-grade patent search capabilities. To evaluate the effectiveness of Minesoft’s keyword-based retrieval, the abstracts of the five test documents under observation were queried, filtering the search results based on the same CPC classification. For each patent under observation, the top 5000 patent documents ranked by relevance were retrieved. However, none of the retrieved sets contained any of the “x” documents identified in the prior art search. In contrast, the BERT-based model successfully recognized two out of five ‘x’ documents, as summarized in
Table 7.
These findings highlight the potential advantages of the contextual retrieval approach over conventional keyword-based methods, particularly in cases where patent abstracts and search terms exhibit complex semantic relationships that cannot be fully captured by direct keyword matching
Author Contributions
Conceptualization, A.A. and P.E.A.; methodology, A.A., M.A.H. and P.E.A.; validation, A.A., M.A.H., L.C.D.S. and P.E.A.; formal analysis, A.A., M.A.H. and P.E.A.; investigation, A.A. and M.A.H.; resources, A.A. and P.E.A.; data curation, A.A., L.C.D.S. and P.E.A.; writing—original draft preparation, A.A. and P.E.A.; writing—review and editing, A.A., M.A.H. and P.E.A.; visualization, A.A.; supervision, L.C.D.S. and P.E.A.; funding acquisition, P.E.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Universiti Brunei Darussalam grant number UBD/RSCH/1.3/FICBF(b)/2024/023.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author(s).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Suzgun, M.; Melas-Kyriazi, L.; Sarkar, S.; Kominers, S.D.; Shieber, S. The Harvard USPTO Patent Dataset: A Large-Scale, Well-Structured, and Multi-Purpose Corpus of Patent Applications. arXiv 2022, arXiv:2207.04043. [Google Scholar] [CrossRef]
- Roudsari, A.H.; Afshar, J.; Lee, S.; Lee, W. Comparison and Analysis of Embedding Methods for Patent Documents. In Proceedings of the IEEE International Conference on Big Data and Smart Computing (BigComp), Jeju Island, Republic of Korea, 17–20 January 2021. [Google Scholar]
- Shalaby, W.; Zadrozny, W. Patent retrieval: A literature review. Knowl. Inf. Syst. 2019, 61, 631–660. [Google Scholar] [CrossRef]
- Freunek, M.; Bodmer, A. Transformer-Based Patent Novelty Search by Training Claims to Their Own Description. Appl. Econ. Financ. 2021, 8, 37–46. [Google Scholar] [CrossRef]
- Kim, S.; Yoon, B. Patent infringement analysis using a text mining technique based on SAO structure. Comput. Ind. 2021, 125, 103379. [Google Scholar] [CrossRef]
- Muhammad, A. Efficiency of Boolean Search strings for Information Retrieval. Am. J. Eng. Res. (AJER) 2017, 6, 216–222. [Google Scholar]
- Management, C. Boolean Search. 18 November 2023. Available online: https://ceopedia.org/index.php/Boolean_search (accessed on 9 January 2025).
- Helmers, L.; Horn, F.; Biegler, F.; Oppermann, T.; Müller, K.R. Automating the search for a patent’s prior art with a full text similarity search. PLoS ONE 2019, 14, e0212103. [Google Scholar] [CrossRef]
- Lee, J.; Park, S.; Lee, J. A fast and scalable algorithm for prior art search. IEEE Access 2022, 10, 7396–7407. [Google Scholar] [CrossRef]
- Merrouni, Z.A.; Frikh, B.; Ouhbi, B. Toward Contextual Information Retrieval: A Review And Trends. DataProcedia Comput. Sci. 2019, 148, 191–200. [Google Scholar] [CrossRef]
- Risch, J.; Alder, N.; Hewel, C.; Krestel, R. PatentMatch: A Dataset for Matching Patent Claims & Prior Art. arXiv 2020, arXiv:2012.13919. [Google Scholar] [CrossRef]
- Ganesh, P.; Chen, Y.; Lou, X.; Khan, M.; Yang, Y.; Chen, D.; Winslett, M.; Sajjad, H.; Nakov, P. Compressing Large-Scale Transformer-Based Models: A Case Study on BERT. arXiv 2020, arXiv:2002.11985. [Google Scholar] [CrossRef]
- Srebrovic, R. BERT for Patents. Available online: https://github.com/google/patents-public-data/blob/master/models/BERT%20for%20Patents.md (accessed on 9 January 2025).
- Setchi, R.; Spasić, I.; Morgan, J.; Harrison, C.; Corken, R. Artificial intelligence for patent prior art searching. World Pat. Inf. 2021, 64, 102021. [Google Scholar] [CrossRef]
- Silvia Casolaa, A.L. Summarization, Simplification, and Generation: The Case of Patents. Expert Syst. Appl. 2022, 205, 117627. [Google Scholar] [CrossRef]
- Andersson, L.; Lupu, M.; Palotti, J.; Hanbury, A.; Rauber, A. When is the Time Ripe for Natural Language Processing for Patent Passage Retrieval? In Proceedings of the CIKM ’16: Proceedings of the 25th ACM International on Conference on Information and Knowledge Management, Indianapolis, IN, USA, 24–28 October 2016; pp. 1453–1462. [Google Scholar]
- Hannes Jansson, J.N. Using Natural Language Processing to Identify Similar Patent Documents; Department of Computer Science, Lund University: Lund, Sweden, 2020. [Google Scholar]
- Freilich, J. Articles Ignoring Information Quality. FLR Fordham Law Rev. 2021, 89, 2113. [Google Scholar]
- Kang, D.M.; Lee, C.C.; Lee, S.; Lee, W. Patent prior art search using deep learning language model. In Proceedings of the IDEAS ’20: Proceedings of the 24th Symposium on International Database Engineering & Applications, Incheon, Republic of Korea, 12–18 August 2020; pp. 1–5. [Google Scholar]
- Risch, J.; Krestel, R. Domain-Specific Word Embeddings for Patent Classification. Data Technol. Appl. 2019, 53, 108–122. [Google Scholar] [CrossRef]
- Pogiatzis, A. NLP: Contextualized Word Embeddings from BERT. Retrieved from Towards Data Science. 2019. Available online: https://medium.com/towards-data-science/nlp-extract-contextualized-word-embeddings-from-bert-keras-tf-67ef29f60a7b (accessed on 9 January 2025).
- Fang, L.; Luo, Y.; Feng, K.; Zhao, K.; Hu, A. A Knowledge-Enriched Ensemble Method for Word Embedding and Multi-Sense Embedding. IEEE Trans. Knowl. Data Eng. 2022, 35, 5534–5549. [Google Scholar] [CrossRef]
- Humayun, M.A.; Yassin, H.; Shuja, J.; Alourani, A.; Abas, P.E. A transformer fine-tuning strategy for text dialect identification. Neural Comput. Appl. 2023, 35, 6115–6124. [Google Scholar] [CrossRef]
- Kalyan, K.S. A Survey of GPT-3 Family Large Language Models Including ChatGPT and GPT-4. Nat. Lang. Process. J. 2024, 6, 100048. [Google Scholar] [CrossRef]
- Liu, Y.; Naman Goyal, M.O.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar] [CrossRef]
- Lee, J.-S.; Hsiang, J. Patent Classification by Fine-Tuning BERT Language Model. World Pat. Inf. 2020, 61, 101965. [Google Scholar] [CrossRef]
- Li, S.; Hu, J.; Cui, Y.; Hu, J. DeepPatent: Patent classification with convolutional neural networks and word embedding. Scientometrics 2018, 117, 721–744. [Google Scholar] [CrossRef]
- Stamatis, V. End to End Neural Retrieval for Patent Prior Art Search. In Proceedings of Advances in Information Retrieval; Springer: Cham, Switzerland, 2022. [Google Scholar]
- RSrebrovic, R.; Yonamine, J. Leveraging the BERT Algorithm for Patents with TensorFlow and BigQuery. 2020. Available online: https://services.google.com/fh/files/blogs/bert_for_patents_white_paper.pdf (accessed on 9 January 2025).
- Chikkamath, R.; Parmar, V.R.; Otiefy, Y.; Endres, M. Patent Classification Using BERT-for-Patents on USPTO. In Proceedings of the MLNLP ’22: Proceedings of the 2022 5th International Conference on Machine Learning and Natural Language Processing, Sanya, China, 23–25 December 2022; pp. 20–28. [Google Scholar]
- Vowinckel, K.; Hähnke, V.D. SEARCHFORMER: Semantic patent embeddings by siamese transformers for prior art search. World Pat. Inf. 2023, 73, 102192. [Google Scholar] [CrossRef]
- Yu, L.; Liu, B.; Lin, Q.; Zhao, X.; Che, C. Similarity Matching for Patent Documents Using Ensemble BERT-Related Model and Novel Text Processing Method. J. Adv. Inf. Technol. 2024, 15, 446–450. [Google Scholar] [CrossRef]
- Stamatis, V.; Salampasis, M.; Diamantaras, K. A novel re-ranking architecture for patent search. World Pat. Inf. 2024, 78, 102282. [Google Scholar] [CrossRef]
- Chikkamath, R.; Rastogi, D.; Maan, M.; Endres, M. Is your search query well-formed? A natural query understanding for patent prior art search. World Pat. Inf. 2023, 76, 102254. [Google Scholar] [CrossRef]
- Ali, A.; Tufail, A.; De Silva, L.; Abas, P.E. Innovating Patent Retrieval: A Comprehensive Review of Techniques, Trends, and Challenges in Prior Art Searches. Appl. Syst. Innov. 2024, 7, 91. [Google Scholar] [CrossRef]
- Google, I.C.P.S. Google Patents Public Data, I.C.P.S.a. Google, Editor. Available online: https://cloud.google.com/bigquery/ (accessed on 6 January 2025).
- Taylor, E.J.; Inman, M. Looking at Patent Law: Defining the Meaning and Scope of Claims through Claim Construction; Insights from the Lithium Battery Patent Infringement Case. Electrochem. Soc. Interface 2020, 29, 51–57. [Google Scholar] [CrossRef]
- Office, U.I.P. Patent Factsheets: Abstract. IPO, Ed. UK. Available online: www.gov.uk/ipo (accessed on 13 February 2025).
- Lens. How to Read a Patent. Available online: https://support.lens.org/knowledge-base/how-to-read-a-patent/ (accessed on 9 January 2025).
- Kumar, R.; Tripathi, R.C.; Singh, V. Keyword based search and its limitations in the Patent document to secure the idea from its infringement. In Proceedings of the International Conference on Information Security & Privacy (ICISP2015), Nagpur, India, 11–12 December 2015; pp. 439–446. [Google Scholar]
- Pasi Fränti, R.M.-I. Soft precision and recall. Pattern Recognit. Lett. 2023, 167, 115–121. [Google Scholar] [CrossRef]
- Minesoft Origin | Advanced AI Patent Search. 1996 Edition. 2024. Last Updated January 2025. Available online: https://minesoft.com/ (accessed on 9 January 2025).
Figure 1.
Overview of the proposed methodology for prior art search using the Google Public Patent Database.
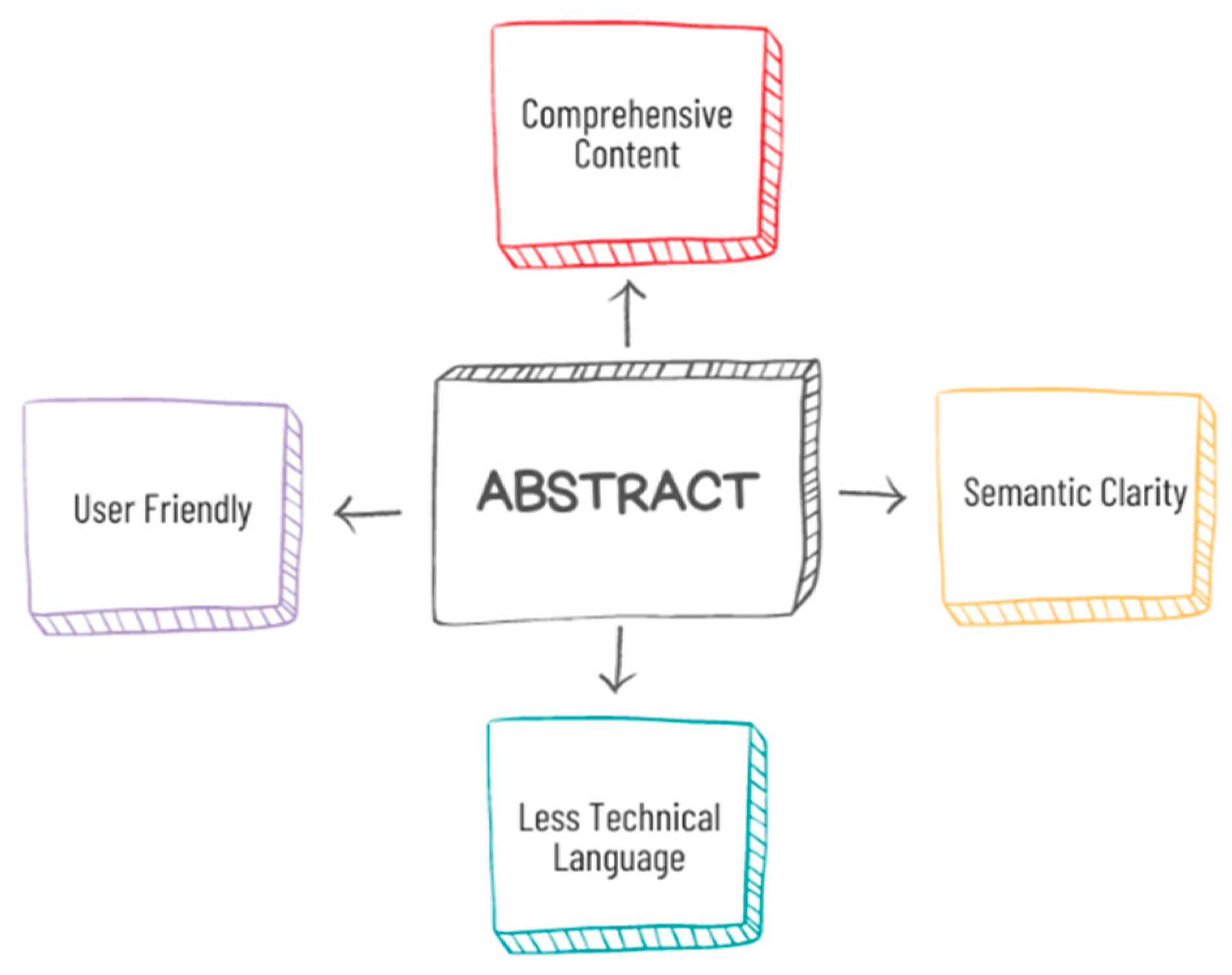
Figure 2.
The positive aspects of the patent’s abstract.
Figure 3.
Overview of the steps involved in retrieving data from the Google Public Patent Database.
Figure 4.
Brief descriptions of the abstract and the set of top terms used in this research.
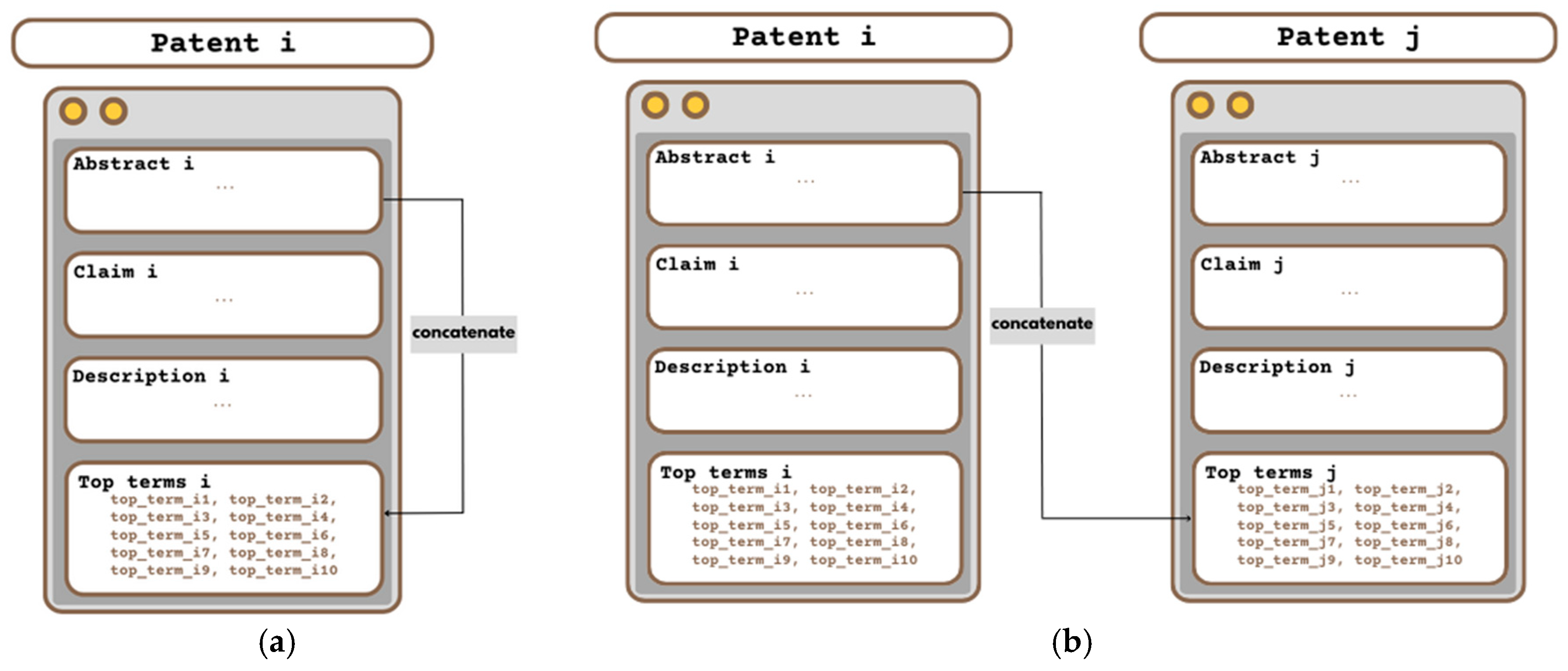
Figure 5.
Examples of elements of set form from abstract and set of top terms that are (a) associated, i.e., , and (b) not associated, i.e., .
Figure 6.
Process of creating the search file.
Figure 7.
Visual breakdown of precision and recall.
Table 1.
Highlights the components that add to the unique nature of the patent’s abstract and claims.
| Claim | Abstract |
|---|
| Extensive content (Scope of the invention) | Comprehensive content (Summarize the invention’s main features and significance) |
| highly specialized terminologies (Legal jargon and technical terms) | Less technical language (Written in a more readable style) |
| Complex (critical role in legal assessments of infringement and validity) | Semantic clarity (Give a clear explanation of the invention’s fundamental idea and goal, making it easier for users to find relevant documents in response to their search query) |
| Domain-specific experts (Require a deeper understanding of the subject matter) | User Friendly (Offer a straightforward starting point for grasping the basic concept of the patent for non-expert users) |
Table 2.
Distribution of records in training, testing, and search sets.
| Training Set | 1076 |
| Testing set | 100 |
| Search set | 978 |
Table 3.
Displays the total number of records in training and testing sets after making the combinations and also shows the label values for each set.
| | Total Records | Abstract and Top Terms Combinations | Label 1 | Label 0 |
|---|
| 1076 | 1,157,776 | 1076 | 1,156,700 |
| 100 | 10,000 | 100 | 9900 |
| 978 + 5 (top terms of ‘X’ documents) | 4915 (each of five ‘UO’ documents mapped to each of 983 top term sets) | - | - |
Table 4.
Patents (UO) and their respective ‘X’ documents (prior art) from the search reports and the top terms of the ‘X’ documents from the Google Public Patent Database.
| Patents (UO) | X Documents | Top Terms of the ‘X’ Patent Documents |
|---|
| WO-2013126473-A1 | US-2004181972-A1 | Shoe, girth, lace, instep, sole, foot, tying, laces, eyelet, heel |
| WO-2016123304-A1 | US-4610102-A | Velcro, indicia, heel, shoe, label, flap, footwear, carrying device, hook, loop |
| WO-2009156625-A3 | US-6029376-A | Sleeve, footwear, article, sole, medial, foot, lace, lateral, outer sleeve, support |
| WO-2021183360-A1 | US-2016058100-A1 | monofilament, area, areas, multifilament, article, welt, tensile element, knitted component, welts, article according |
| WO-2012015595-A1 | US-5271130-A | Shoe, strips, lacing, quarter, strip, slits, loop, sole, upper portion, lacing system |
Table 5.
Comparison of the accuracy and F1 score of baselines versus the proposed approach.
| | Accuracy | Recall | Precision | F1 Score |
|---|
| PatentMatch [11] | 54% | - | - | - |
| Claims-to-descriptions [4] | - | - | - | 0.93 |
| Proposed Abtract_to_top_terms | 94% | 0.9494 | 0.9331 | 0.94 |
Table 6.
Patents (UO) and their respective ‘x’ documents (prior art) from the search reports, the top terms of the ‘x’ documents from the Google Public Patent Database and search results.
| Patents (UO) | X Documents | Top Terms | Search Result |
|---|
| WO-2013126473-A1 | US-2004181972-A1 | Shoe, girth, lace, instep, sole, foot, tying, laces, eyelet, heel | Relevant |
| WO-2016123304-A1 | US-4610102-A | Velcro, indicia, heel, shoe, label, flap, footwear, carrying device, hook, loop | Irrelevant |
| WO-2009156625-A3 | US-6029376-A | Sleeve, footwear, article, sole, medial, foot, lace, lateral, outer sleeve, support | Irrelevant |
| WO-2021183360-A1 | US-2016058100-A1 | monofilament, area, areas, multifilament, article, welt, tensile element, knitted component, welts, article according | Irrelevant |
| WO-2012015595-A1 | US-5271130-A | Shoe, strips, lacing, quarter, strip, slits, loop, sole, upper portion, lacing system | Relevant |
Table 7.
Patents (UO) and their respective ‘x’ documents (prior art) from the search reports, the top terms of the ‘x’ documents from the Google Public Patent Database and search results using Minesoft.
| Patents (UO) * | X Documents | Retrieved X Document ** |
|---|
| WO-2013126473-A1 | US-2004181972-A1 | Not found |
| WO-2016123304-A1 | US-4610102-A | Not found |
| WO-2009156625-A3 | US-6029376-A | Not found |
| WO-2021183360-A1 | US-2016058100-A1 | Not found |
| WO-2012015595-A1 | US-5271130-A | Not found |
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}