
Aerial Imagery Redefined: Next-Generation Approach to Object Classification


Abstract
1. Introduction
2. Related Work
2.1. Advancements in Aerial Imagery and ML
2.2. Challenges in Aerial Imagery Classification
2.2.1. Evaluation Metrics
2.2.2. Challenging Aspects of the Competition
Rare Labels
Imbalanced Data
Train–Validation–Test Split
Label Diversity
2.3. Accessed Datasets
2.4. The xView Dataset: Objects in Context in Overhead Imagery
2.5. DOTA-v1.5: Dataset for Object deTection in Aerial Images
2.6. The iSAID Dataset: Instance Segmentation in Aerial Images Dataset
2.7. COWC: Cars Overhead with Context
2.8. VisDrone
3. The COFGA Dataset
3.1. Dataset Details
- Class—This category contains only two instances: ‘large vehicle’ and ‘small vehicle’, according to the vehicle’s measurements.
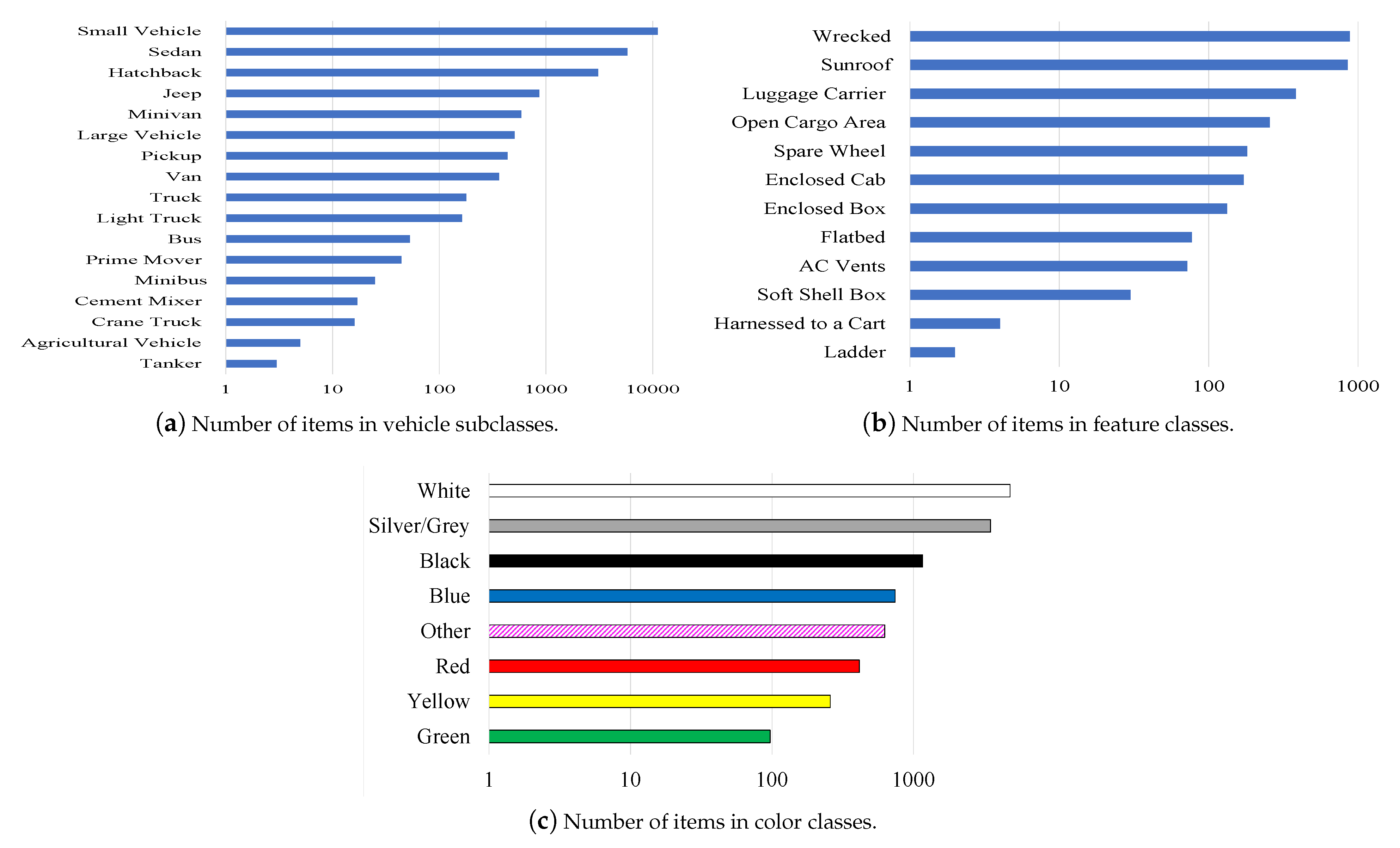
- Subclass—‘small vehicles’ and ‘large vehicles’ are divided according to their kind or designation. ‘Small vehicles’ are divided into ‘sedan’, ‘hatchback’, ‘minivan’, ‘van’, ‘pickup truck’, ‘jeep’, and ‘public vehicle’. ‘Large vehicles’ are divided into ‘truck’, ‘light truck’, ‘cement mixer’, ‘dedicated agricultural vehicle’, ‘crane truck’, ‘prime mover’, ‘tanker’, ‘bus’, and ‘minibus’ (Figure 2a and Figure 3a).Figure 3a describes the distribution of the vehicle subclasses within the dataset, showing how often specific categories, such as ‘sedan’, ‘hatchback’, ‘minivan’, ‘truck’, etc., are met. Although we did not select vehicle type as one of the analysis options, this visualization helps comprehend the proportion of various types of vehicles in this dataset and its diversity.
- Features—This category addresses the identification of each vehicle’s unique features. The features tagged in the ‘small vehicle’ category are ‘sunroof’, ‘luggage carrier’, ‘open cargo area’, ‘enclosed cab’, ‘wrecked’, and ‘spare wheel’. The features tagged in the ‘large vehicle’ category are ‘open cargo area’, ‘ac vents’, ‘wrecked’, ‘enclosed box’, ‘enclosed cab’, ‘ladder’, ‘flatbed’, ‘soft shell box’, and ‘harnessed to a cart’ (Figure 2b and Figure 3c).Figure 3b shows the dispersion of the distinctive vehicle characteristics obtained in the dataset, such as ‘sunroof’, ‘luggage carrier’, ‘flatbed’, and ‘spare wheel’. This figure indicates that the current dataset is very detailed in capturing specific features that enable it to be classified with high granularity.
- Object perceived color—Identification of the vehicle’s color as would be used by the human analyst to describe the vehicle: ‘White’, ‘Silver/Gray’, ‘Black’, ‘Blue’, ‘Red’, ‘Yellow’, ‘Green’, and ’Other’ (Figure 2c and Figure 3c). Figure 3c shows the perceived vehicle color distribution where the options are ‘White’, ‘Black’, ‘Blue’, ‘Red’, and others. This graph de-emphasizes the wide variety of color annotations available in the dataset and their suitability in tasks susceptible to image appearance for object recognition and categorization.
3.2. Annotation Procedure
3.2.1. Phase 1: Initial Labeling
3.2.2. Phase 2: Fine-Grained Features Labeling
3.3. Dataset Statistics
3.3.1. Inter- and Intra-Subclass Correlation
3.3.2. Pixel Area of Objects from Different Subclasses
3.4. Dataset Innovation and Impact
4. Comparing Datasets
5. MAFAT Challenge
- A public test set that included 896 objects. This test set was used to calculate the score shown on the public leaderboard during the public phase of the competition.
- A private test set that included 1743 objects. This test set was used to calculate the final score, shown on the private leaderboard that was used for final judging.
- Noise, which included 9240 objects and was automatically tagged by the detection algorithm we used on the images in the test set. These objects were not tagged by us and were not used to compute the submission score. We added these objects as distractors to reduce the likelihood of a competitor winning this challenge by cheating through manually tagging the test set.
5.1. Evaluation Metric
5.2. Challenging Aspects of the Competition
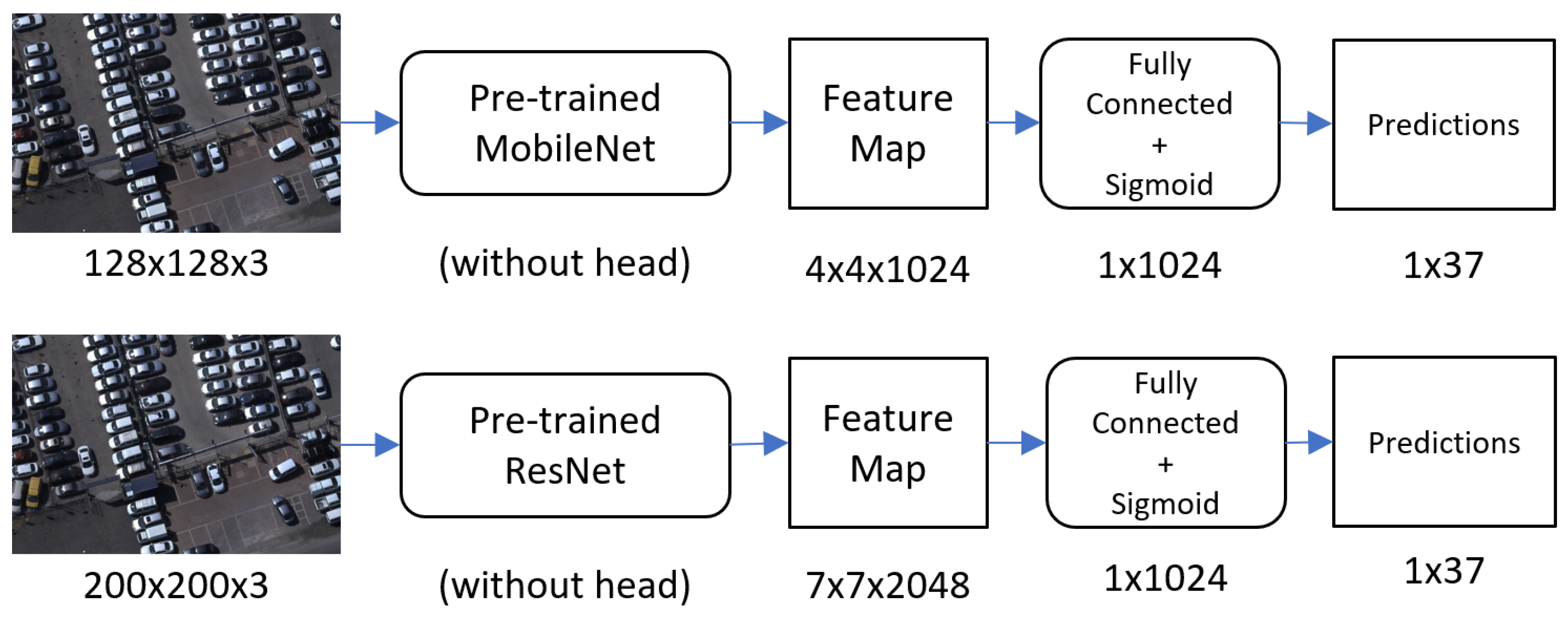
5.3. Network Architectures and Model Details
5.4. Notable Solutions
5.4.1. Baseline Model (mAP: 0.60)
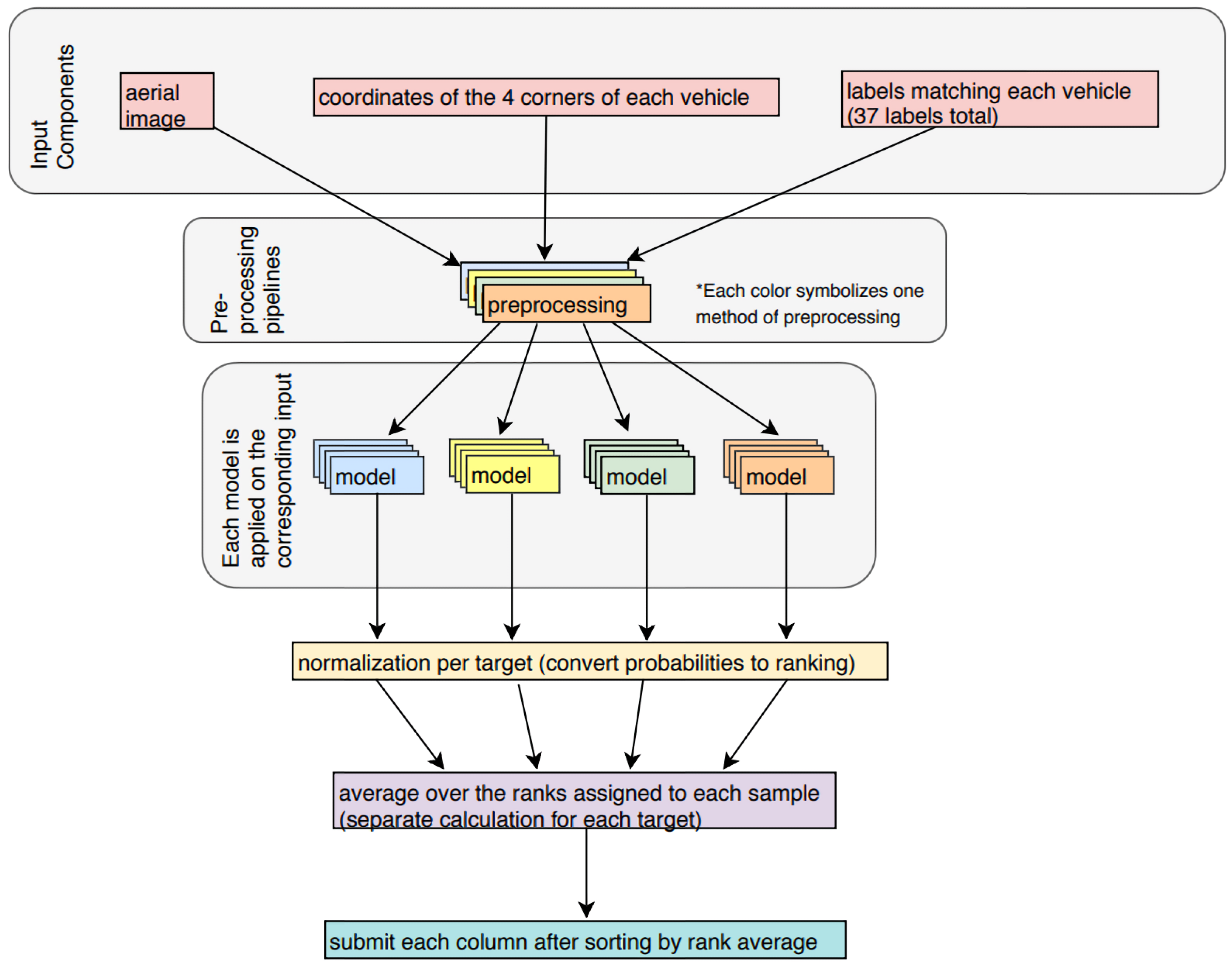
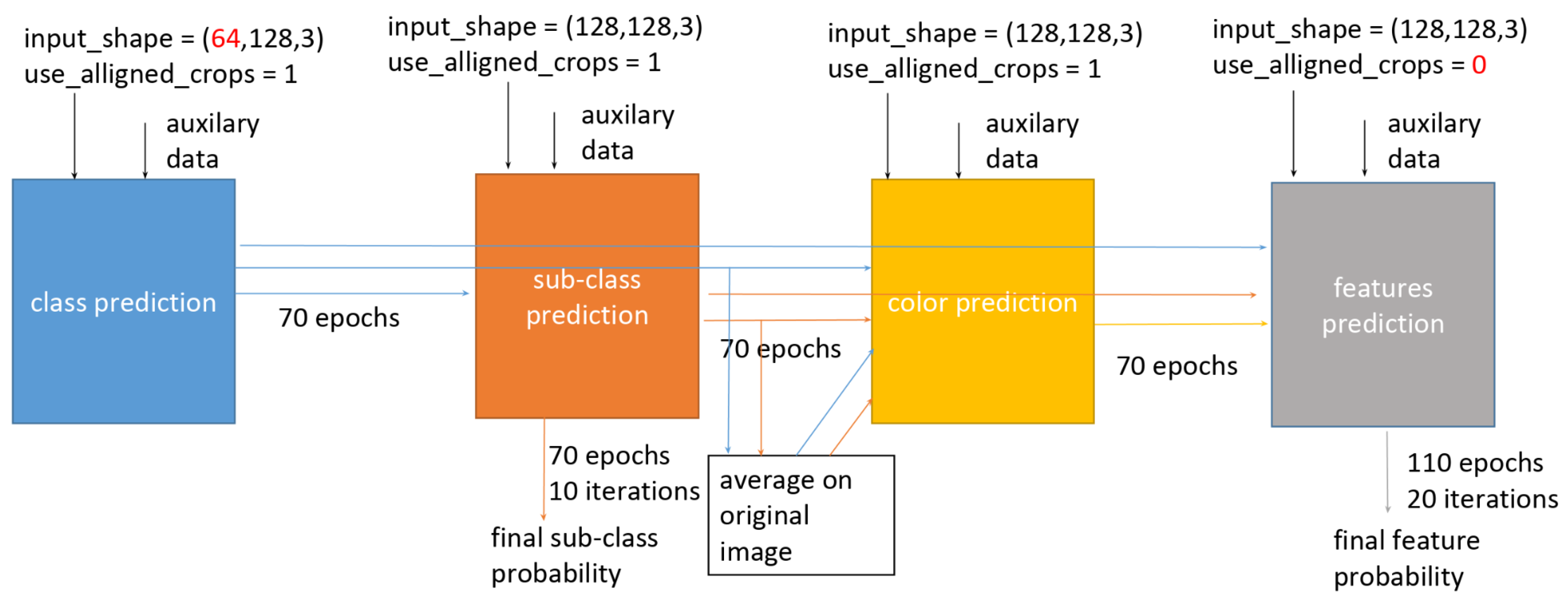
5.4.2. First Place: SeffiCo—Team MMM (mAP: 0.6271)
- Trained a very large number of different models (hundreds) by using as many differentiating mechanisms as possible, such as bagging, boosting, different architectures, different preprocessing techniques, and different augmentation techniques.
- Clustered the trained models into different groups by using the k-means clustering algorithm on their predictions. This stage aimed to generate dozens of model clusters in such a way that the models in the same cluster were more similar to each other than to those in the other clusters, ensuring diversity between the clusters.
- Picked the best representative models from each cluster.
- Grouped the representative models into an integrated model by averaging their logits.
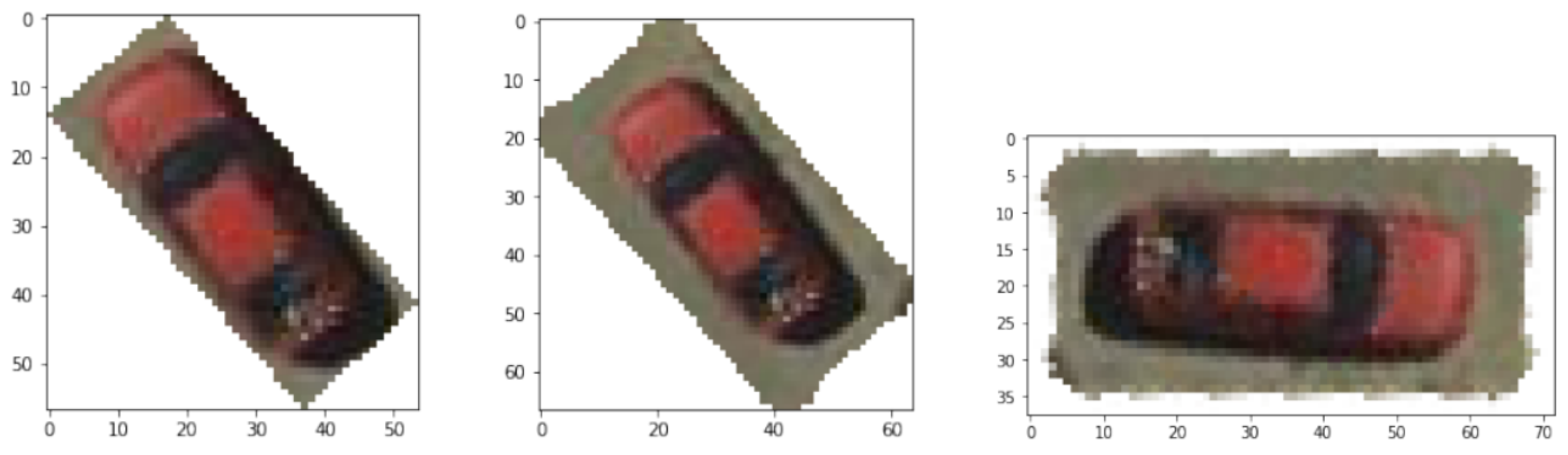
- Cropping—The first step was to crop the vehicles from the image, using the coordinates from the provided input data; but, after observing the data, it was noticeable that the area around the vehicles could reveal information about the vehicles’ properties (spatial context). Each vehicle was cropped with an additional padding of five pixels from the surrounding area (Figure 7).
- Rotation—The vehicles in the images were not oriented in any single direction, which added complexity to the problem. To solve this challenge, the model used the fact that the length of a vehicle was longer than its width, and this fact was used to rotate the cropped image and align the larger edge with the horizontal axis.
- Color Augmentation—Converting the images from RGB (Red–Green–Blue channels) to HSV (Hue–Saturation–Value) and swapping color channels were methods used to gather more color data (Figure 8).
- Squaring—Most existing CNN architectures require a fixed-sized square image as input; hence, an additional zero padding was added to each cropped image on the narrower side, and then the image was resized to fit the specific size of each architecture (79, 124, 139, and 224 pixels), similarly to [47].
- Online—Finally, online data augmentation was performed in the training process, using the Imgaug library.
5.4.3. Yonatan Wischnitzer (mAP: 0.5984)
5.5. Model Analysis and Interpretability
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| Acronym | Full Form |
| AI | Artificial Intelligence |
| AP | Average Precision |
| AUC | Area Under Curve |
| BB | Bounding Box |
| CNN | Convolutional Neural Network |
| COFGA | Classification of Objects for Fine-Grained Analysis |
| COWC | Cars Overhead With Context |
| CPM | Centroid Pixel Map |
| DOTA | Dataset for Object deTection in Aerial images |
| GCD | Generalized Category Discovery |
| GSD | Ground Sample Distance |
| HSV | Hue–Saturation–Value |
| IMOD | Israel Ministry of Defense |
| iSAID | Instance Segmentation in Aerial Images Dataset |
| JPG/JPEG | Joint Photographic Experts Group |
| LiDAR | Light Detection and Ranging |
| MAFAT | Administration for the Development of Weapons and Technological Infrastructure |
| mAP | mean Average Precision |
| ML | Machine Learning |
| NASNet | Neural Architecture Search Network |
| RGB | Red–Green–Blue |
| SSL | Self-Supervised Learning |
| SVM | Support Vector Machine |
| TIFF | Tagged Image File Format |
| UAV | Unmanned Aerial Vehicle |
| xView | Objects in Context in Overhead Imagery Dataset |
| YOLO | You Only Look Once |
References
- Teixeira, I.; Morais, R.; Sousa, J.; Cunha, A. Deep learning models for the classification of crops in aerial imagery: A review. Agriculture 2023, 13, 965. [Google Scholar] [CrossRef]
- Lamprey, R.H.; Keigwin, M.; Tumwesigye, C. A high-resolution aerial camera survey of Uganda’s Queen Elizabeth Protected Area improves detection of wildlife and delivers a surprisingly high estimate of the elephant population. bioRxiv 2023. [Google Scholar] [CrossRef]
- Gadiraju, K.; Vatsavai, R. Remote sensing based crop type classification via deep transfer learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 4699–4712. [Google Scholar] [CrossRef]
- Zhou, Y.; Zhu, H.; Zhang, Y.; Liang, S.; Wang, Y.; Yang, W. Generalized category discovery in aerial image classification via slot attention. Drones 2024, 8, 160. [Google Scholar] [CrossRef]
- Ferraz, M.A.J.; Barboza, T.O.C.; Arantes, P.D.S.; Von Pinho, R.G.; Santos, A.F.D. Integrating satellite and uav technologies for maize plant height estimation using advanced machine learning. Agriengineering 2024, 6, 20–33. [Google Scholar] [CrossRef]
- Miao, Z.; Yu, S.X.; Landolt, K.L.; Koneff, M.D.; White, T.P.; Fara, L.J.; Hlavacek, E.J.; Pickens, B.A.; Harrison, T.J.; Getz, W.M. Challenges and solutions for automated avian recognition in aerial imagery. Remote Sens. Ecol. Conserv. 2023, 9, 439–453. [Google Scholar] [CrossRef]
- Rosser, J.I.; Tarpenning, M.S.; Bramante, J.T.; Tamhane, A.; Chamberlin, A.J.; Mutuku, P.S.; De Leo, G.A.; Ndenga, B.; Mutuku, F.; LaBeaud, A.D. Development of a trash classification system to map potential aedes aegypti breeding grounds using unmanned aerial vehicle imaging. Environ. Sci. Pollut. Res. 2024, 31, 41107–41117. [Google Scholar] [CrossRef]
- Yamada, T.; Massot-Campos, M.; Prügel-Bennett, A.; Pizarro, O.; Williams, S.; Thornton, B. Guiding labelling effort for efficient learning with georeferenced images. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 593–607. [Google Scholar] [CrossRef] [PubMed]
- Sirisha, M.; Sudha, S.V. An advanced object detection framework for uav imagery utilizing transformer-based architecture and split attention module: Pvsamnet. Trait. Du Signal 2023, 40, 1661–1672. [Google Scholar] [CrossRef]
- Han, T.; Dong, Q.; Sun, L. Senselite: A yolo-based lightweight model for small object detection in aerial imagery. Sensors 2023, 23, 8118. [Google Scholar] [CrossRef]
- Chang, J.; He, X.; Li, P.; Tian, T.; Cheng, X.; Qiao, M.; Zhou, T.; Zhang, B.; Chang, Z.; Fan, T. Multi-scale attention network for building extraction from high-resolution remote sensing images. Sensors 2024, 24, 1010. [Google Scholar] [CrossRef] [PubMed]
- Hancock, J.; Khoshgoftaar, T.M.; Johnson, J. Evaluating Classifier Performance with Highly Imbalanced Big Data. J. Big Data 2023, 10, 42. [Google Scholar] [CrossRef]
- Valicharla, S.K.; Li, X.; Greenleaf, J.; Turcotte, R.M.; Hayes, C.J.; Park, Y. Precision Detection and Assessment of Ash Death and Decline Caused by the Emerald Ash Borer Using Drones and Deep Learning. Plants 2023, 12, 798. [Google Scholar] [CrossRef] [PubMed]
- Mdegela, L.; Municio, E.; Bock, Y.D.; Mannens, E.; Luhanga, E.T.; Leo, J. Extreme Rainfall Events Detection Using Machine Learning for Kikuletwa River Floods in Northern Tanzania. Preprint 2023. [Google Scholar] [CrossRef]
- Ma, Y.; Lv, H.; Ma, Y.; Wang, X.; Lv, L.; Liang, X.; Wang, L. Advancing Preeclampsia Prediction: A Tailored Machine Learning Pipeline for Handling Imbalanced Medical Data (Preprint). Preprint 2024. [Google Scholar] [CrossRef]
- Salau, A.O.; Markus, E.D.; Assegie, T.A.; Omeje, C.O.; Eneh, J.N. Influence of Class Imbalance and Resampling on Classification Accuracy of Chronic Kidney Disease Detection. Math. Model. Eng. Probl. 2023, 10, 48–54. [Google Scholar] [CrossRef]
- Lokanan, M. Exploring Resampling Techniques in Credit Card Default Prediction. Preprint 2024. [Google Scholar] [CrossRef]
- Cabezas, M.; Diez, Y. An Analysis of Loss Functions for Heavily Imbalanced Lesion Segmentation. Sensors 2024, 24, 1981. [Google Scholar] [CrossRef]
- Zhao, M.; Cheng, Y.; Qin, X.; Yu, W.; Wang, P. Semi-Supervised Classification of PolSAR Images Based on Co-Training of CNN and SVM with Limited Labeled Samples. Sensors 2023, 23, 2109. [Google Scholar] [CrossRef]
- Ngo, B.H.; Lam, B.T.; Nguyen, T.H.; Dinh, Q.V.; Choi, T.J. Dual Dynamic Consistency Regularization for Semi-Supervised Domain Adaptation. IEEE Access 2024, 2, 36267–36279. [Google Scholar] [CrossRef]
- Özbay, Y.; Kazangirler, B.Y.; Özcan, C.; Pekince, A. Detection of the Separated Endodontic Instrument on Periapical Radiographs Using a Deep Learning-based Convolutional Neural Network Algorithm. Aust. Endod. J. 2023, 10, 037502. [Google Scholar] [CrossRef] [PubMed]
- Pardàs, M.; Anglada-Rotger, D.; Espina, M.; Marqués, F.; Salembier, P. Stromal Tissue Segmentation in Ki67 Histology Images Based on Cytokeratin-19 Stain Translation. J. Med. Imaging 2023, 10, 037502. [Google Scholar] [CrossRef] [PubMed]
- Li, K.; Duggal, R.; Chau, D.H. Evaluating Robustness of Vision Transformers on Imbalanced Datasets (Student Abstract). Proc. AAAI Conf. Artif. Intell. 2023, 37, 16252–16253. [Google Scholar] [CrossRef]
- Gholami, S.; Scheppke, L.; Kshirsagar, M.; Wu, Y.; Dodhia, R.; Bonelli, R.; Leung, I.; Sallo, F.B.; Muldrew, A.; Jamison, C.; et al. Self-Supervised Learning for Improved Optical Coherence Tomography Detection of Macular Telangiectasia Type 2. JAMA Ophthalmol. 2024, 142, 226–233. [Google Scholar] [CrossRef] [PubMed]
- Wu, W. Enhanced Few-Shot Learning for Plant Leaf Diseases Recognition. J. Comput. Electron. Inf. Manag. 2023, 11, 26–28. [Google Scholar] [CrossRef]
- Zong, N.; Su, S.; Zhou, C. Boosting Semi-supervised Learning Under Imbalanced Regression via Pseudo-labeling. Concurr. Comput. Pract. Exp. 2024, 36, e8103. [Google Scholar] [CrossRef]
- Chen, S. A study on the application of contrastive learning in the brain-computer interface of motor imagery. In Proceedings of the Sixth International Conference on Advanced Electronic Materials, Computers, and Software Engineering (AEMCSE 2023), Shenyang, China, 21–23 April 2023; SPIE: St. Bellingham, WA, USA, 2023; Volume 12787, pp. 400–405. [Google Scholar]
- Ronan, R.; Tarabanis, C.; Chinitz, L.; Jankelson, L. Brugada ECG Detection with Self-Supervised VICReg Pre-Training: A Novel Deep Learning Approach for Rare Cardiac Diseases. medRxiv 2024. [Google Scholar] [CrossRef]
- Huang, J.; Yang, X.; Zhou, F.; Li, X.; Zhou, B.; Song, L.; Ivashov, S.; Giannakis, I.; Kong, F.; Slob, E. A Deep Learning Framework Based on Improved Self-supervised Learning for Ground-penetrating Radar Tunnel Lining Inspection. Comput.-Aided Civ. Infrastruct. Eng. 2023, 39, 814–833. [Google Scholar] [CrossRef]
- Mamidi, I.S.; Dunham, M.E.; Adkins, L.K.; McWhorter, A.J.; Fang, Z.; Banh, B.T. Laryngeal Cancer Screening During Flexible Video Laryngoscopy Using Large Computer Vision Models. Ann. Otol. Rhinol. Laryngol. 2024, 133, 720–728. [Google Scholar] [CrossRef]
- Dabbiru, L.; Goodin, C.; Carruth, D.; Boone, J. Object detection in synthetic aerial imagery using deep learning. In Proceedings of the Autonomous Systems: Sensors, Processing, and Security for Ground, Air, Sea, and Space Vehicles and Infrastructure 2023, Orlando, FL, USA, 2–4 May 2023; SPIE: St. Bellingham, WA, USA, 2023; Volume 12540, p. 1254002. [Google Scholar]
- Ferreira, R.E.P.; Lee, Y.J.; Dórea, J.R. Using Pseudo-Labeling to Improve Performance of Deep Neural Networks for Animal Identification. Sci. Rep. 2023, 13, 13875. [Google Scholar] [CrossRef]
- Wu, G.; Eastwood, C.; Sapiro, N.; Cheligeer, C.; Southern, D.A.; Quan, H.; Xu, Y. Achieving High Inter-Rater Reliability in Establishing Data Labels: A Retrospective Chart Review Study. BMJ Open Qual. 2024, 13, e002722. [Google Scholar] [CrossRef]
- Chowdhury, M.M.; Ayon, R.S.; Hossain, M.S. Diabetes Diagnosis through Machine Learning: Investigating Algorithms and Data Augmentation for Class Imbalanced BRFSS Dataset. medRxiv 2023. [Google Scholar] [CrossRef]
- Thadajarassiri, J.; Hartvigsen, T.; Gerych, W.; Kong, X.; Rundensteiner, E.A. Knowledge Amalgamation for Multi-Label Classification via Label Dependency Transfer. Proc. AAAI Conf. Artif. Intell. 2023, 37, 9980–9988. [Google Scholar] [CrossRef]
- Hussein, H.I.; Anwar, S.A.; Ahmad, M.I. Imbalanced Data Classification Using SVM Based on Improved Simulated Annealing Featuring Synthetic Data Generation and Reduction. Comput. Mater. Contin. 2023, 75, 547–564. [Google Scholar] [CrossRef]
- Breskuvienė, D.; Dzemyda, G. Categorical Feature Encoding Techniques for Improved Classifier Performance When Dealing with Imbalanced Data of Fraudulent Transactions. Int. J. Comput. Commun. Control 2023, 18. [Google Scholar] [CrossRef]
- Cysneiros Aragão, M.V.; de Freitas Carvalho, M.; de Morais Pereira, T.; de Figueiredo, F.A.P.; Mafra, S.B. Enhancing AutoML Performance for Imbalanced Tabular Data Classification: A Self-Balancing Pipeline. Artifical Intell. Rev. 2024. [Google Scholar] [CrossRef]
- Lam, D.; Kuzma, R.; McGee, K.; Dooley, S.; Laielli, M.; Klaric, M.; Bulatov, Y.; McCord, B. xView: Objects in Context in Overhead Imagery. arXiv 2018, arXiv:1802.07856. [Google Scholar]
- Xia, G.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.J.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-scale Dataset for Object Detection in Aerial Images. arXiv 2017, arXiv:1711.10398. [Google Scholar]
- Zamir, S.W.; Arora, A.; Gupta, A.; Khan, S.H.; Sun, G.; Khan, F.S.; Zhu, F.; Shao, L.; Xia, G.; Bai, X. iSAID: A Large-scale Dataset for Instance Segmentation in Aerial Images. arXiv 2019, arXiv:1905.12886. [Google Scholar]
- Mundhenk, T.N.; Konjevod, G.; Sakla, W.A.; Boakye, K. A Large Contextual Dataset for Classification, Detection and Counting of Cars with Deep Learning. arXiv 2016, arXiv:1609.04453. [Google Scholar]
- Zhu, P.; Wen, L.; Bian, X.; Ling, H.; Hu, Q. Vision Meets Drones: A Challenge. arXiv 2018, arXiv:1804.07437. [Google Scholar]
- Lin, T.; Goyal, P.; Girshick, R.B.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. arXiv 2017, arXiv:1708.02002. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Girshick, R.B.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. arXiv 2013, arXiv:1311.2524. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. arXiv 2015, arXiv:1512.00567. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. arXiv 2016, arXiv:1610.02357. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning Transferable Architectures for Scalable Image Recognition. arXiv 2017, arXiv:1707.07012. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Method | Categories | Granularity | Images | GSD | Objects | Vehicles |
|---|---|---|---|---|---|---|---|
| DOTA 1.5 | oriented BB | 16 | 1 | 2806 | 15 | 471,438 | ~380 K |
| xView | horizontal BB | 60 | 2 | 1127 | 30 | ~1 M | ~280 K |
| COWC | Centroid Pixel Map | 1 | 1 | 2418 | 15 | 37,716 | 37,716 |
| iSAID | polygon segmentation | 15 | 1 | 2806 | 15 | 655,451 | ~380 K |
| COFGA | oriented BB | 37 | 4 | 2104 | 5–15 | 14,256 | 14,256 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dahan, E.; Aviv, I.; Diskin, T. Aerial Imagery Redefined: Next-Generation Approach to Object Classification. Information 2025, 16, 134. https://doi.org/10.3390/info16020134
Dahan E, Aviv I, Diskin T. Aerial Imagery Redefined: Next-Generation Approach to Object Classification. Information. 2025; 16(2):134. https://doi.org/10.3390/info16020134
Chicago/Turabian StyleDahan, Eran, Itzhak Aviv, and Tzvi Diskin. 2025. "Aerial Imagery Redefined: Next-Generation Approach to Object Classification" Information 16, no. 2: 134. https://doi.org/10.3390/info16020134
APA StyleDahan, E., Aviv, I., & Diskin, T. (2025). Aerial Imagery Redefined: Next-Generation Approach to Object Classification. Information, 16(2), 134. https://doi.org/10.3390/info16020134