


Design, Building and Deployment of Smart Applications for Anomaly Detection and Failure Prediction in Industrial Use Cases


Abstract
1. Introduction
2. Data-Driven Predictive Maintenance
Anomaly Detection and Failure Prediction
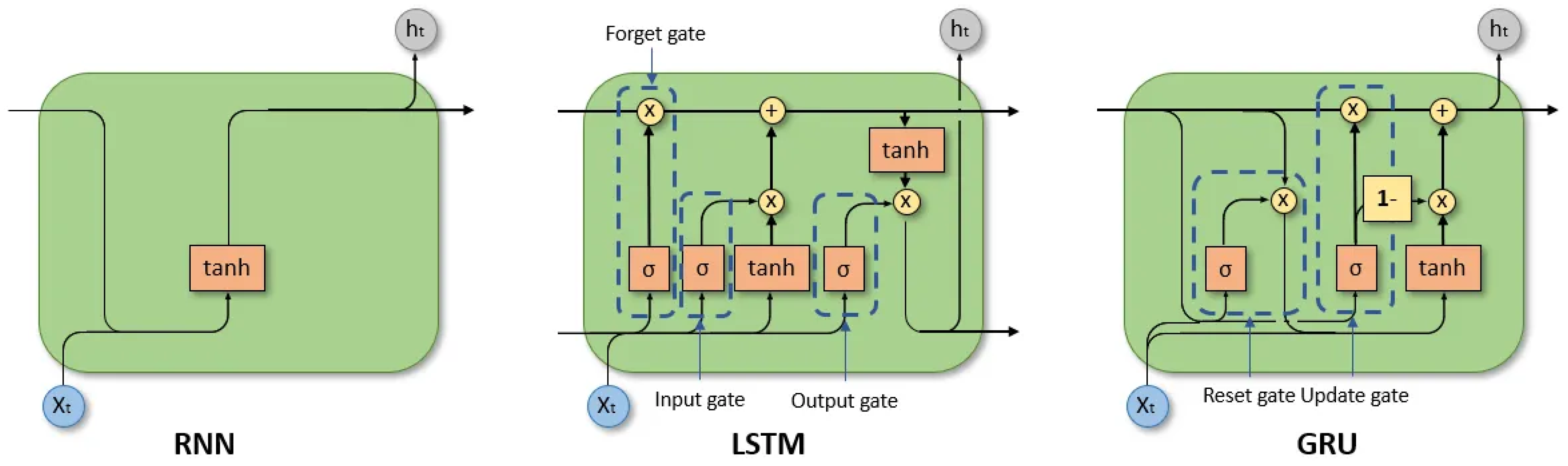
- Recurrent neural networks (RNNs) [21], a type of artificial neural network designed to recognise patterns in sequences of data. Unlike traditional neural networks, RNNs have loops that allow information to persist, making them well-suited for sequential data processing.RNNs have a unique architecture where connections between nodes form a directed cycle. This allows the network to maintain a ’memory’ of previous inputs. The simplest form of RNN can struggle with long-term dependencies due to issues like the vanishing gradient problem, therefore architectures such as long short-term memory (LSTM) and gated recurrent unit (GRU) were created with gate mechanisms to regulate the flow of information and to capture long-term dependencies efficiently. These are used for time-series forecasting, natural language processing (NLP) or recommender systems. Figure 1 shows the structures of the different RNN cells. The simpler RNN cell receives the current time-step and the output from the previous time-step as input, so several time-steps are taken into account for each model prediction. However, these simpler cells face two main problems that affect their ability to capture long-term relationships in the data: vanishing gradient and exploding gradient. The former is caused by gradients rapidly approximating to zero and thus stopping the training process. Whereas the latter is the opposite, gradients grow towards infinity making the training process highly unstable and provoking the appearance of NaN values. To solve these problems, LSTM cells introduce cell states to mitigate the vanishing gradient problem and a three gate system to manage the state. The input gate determines how much of the new information is incorporated into the cell state, the forget gate determines which information is discarded from the cell state and, finally, the output gate determines what information is forwarded. Moreover, GRU cells follow the same principle as LSTM, keeping an internal state or memory, but they are designed using only two gates to improve efficiency. The update gate controls how much from the previous state should be kept and how much of the new information should be included and the reset gate determines how much of the hidden state has to be forgotten.
- Convolutional neural networks [19], a class of deep learning models particularly well-suited for computer vision and natural language processing. They are fully connected feedforward neural networks with convolutional and pooling layers. The former applies a set of filters (or kernels) to the input image, generating feature maps that highlight various characteristics such as edges, textures, and patterns, and the latter reduce the spatial dimensions of the feature maps, typically using operations like max pooling or average pooling, which helps to reduce computational load and to achieve spatial invariance. For time series forecasting and classification, a special type of CNN called a one-dimensional convolutional neural network (1D CNN) is usually employed. This kind of CNN uses one-dimensional filters that convolute only over the time axis (as shown in Figure 2), allowing the identification of temporal patterns in the data.

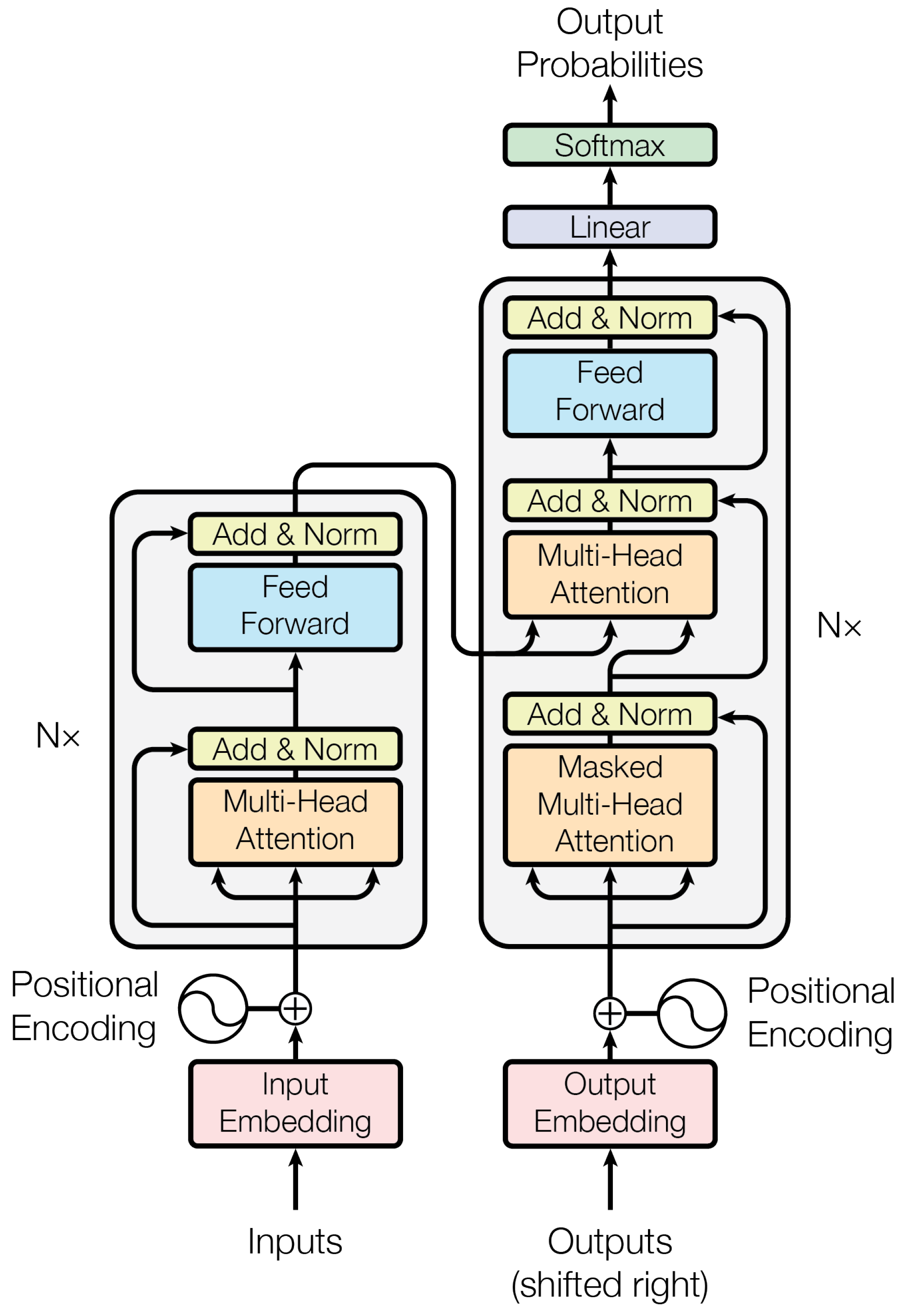
- Generative models, a class of machine learning models that learn to generate new data samples that resemble a given dataset. Unlike discriminative models, which learn the boundary between classes, generative models learn the underlying distribution of the data. There are different types, some of the most relevant are the following: (1) Deep belief networks (DBN) which are hierarchical generative models composed of multiple layers of RBMs (restricted Boltzmann machines) and generally used for unsupervised learning tasks and as feature extractors. (2) Generative adversarial networks (GANs) that consist of two neural networks, the generator and the discriminator, which are trained simultaneously in such way that the generator tries to fool the discriminator, while the discriminator aims to correctly identify the real and generated data. The objective of the generator is to maximise the discriminator’s error rate. (3) Variational autoencoders (VAEs) encode data into a latent space and then decode it back to reconstruct the data. VAEs are particularly popular for tasks like image generation, data representation, and generating new samples that resemble the training data. Finally, (4) transformers, presented in [24], are composed of an encoder and a decoder, each of which is made up of several multi-head self-attention layers and feedforward layers (see Figure 3). These have recently become extremely popular for its use in machine translation and for being the base of well-known large language models (LLMs) such as GPT. However, with some adjustments they can also be applied to temporal and spatial data.
3. Deep Learning Algorithm Comparison: Case Study
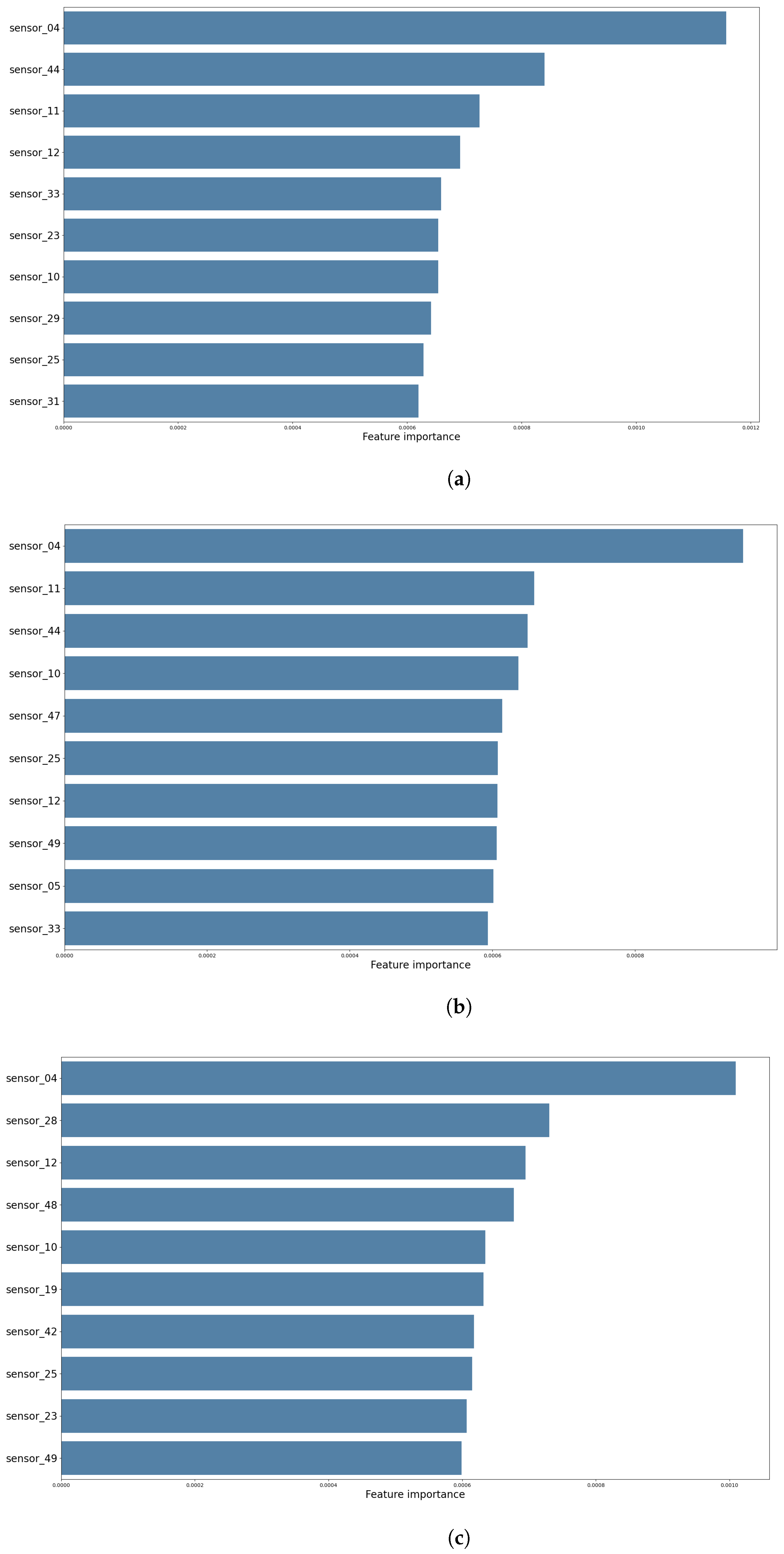
3.1. Feature Selection
3.2. Modelling
3.3. Evaluation Metrics
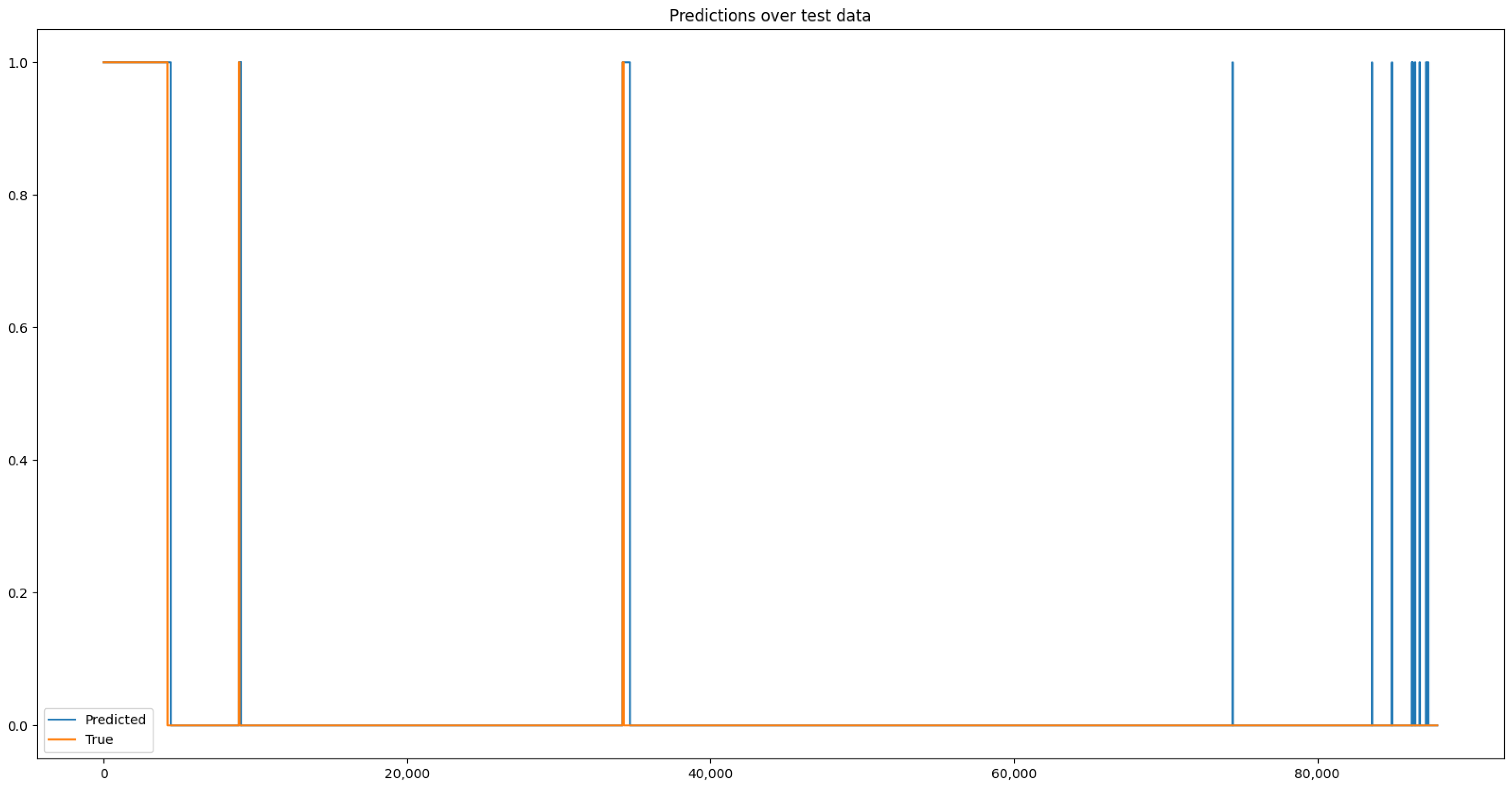
3.4. Results
4. Explaining Water Pump Failures
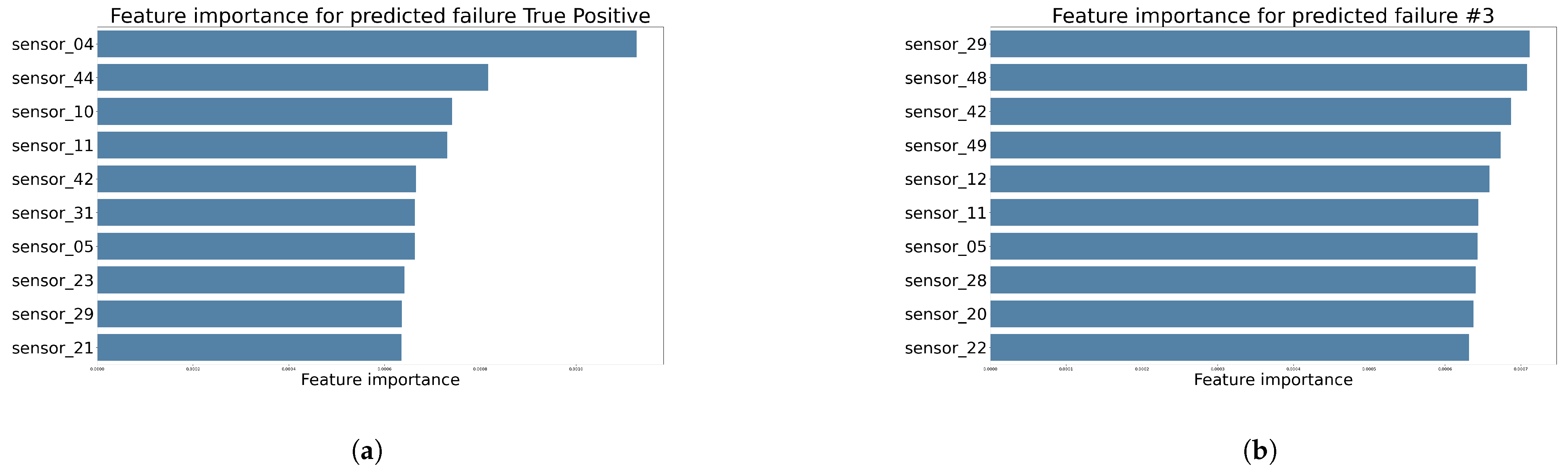
Model Explanations
5. Discussion
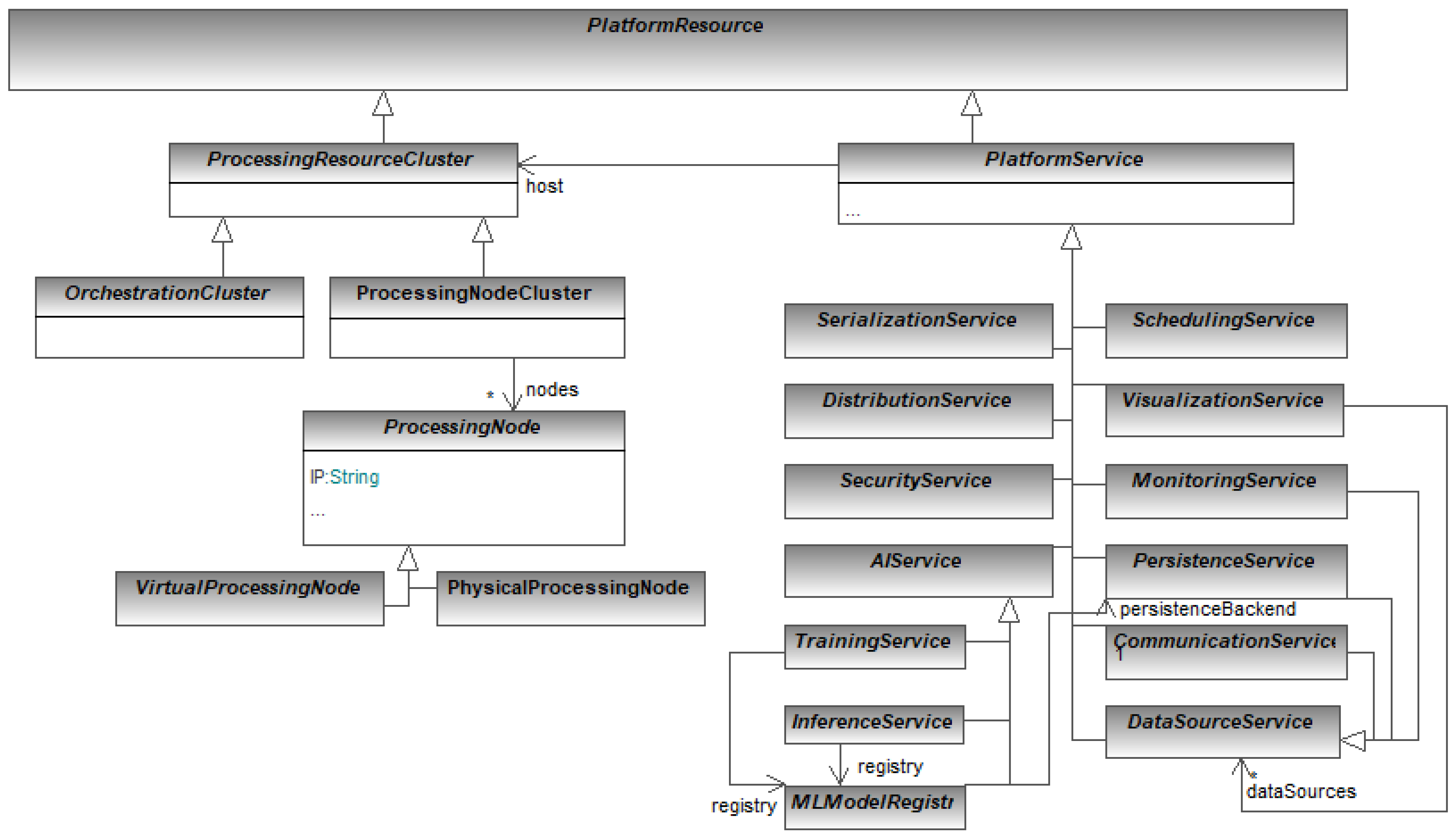
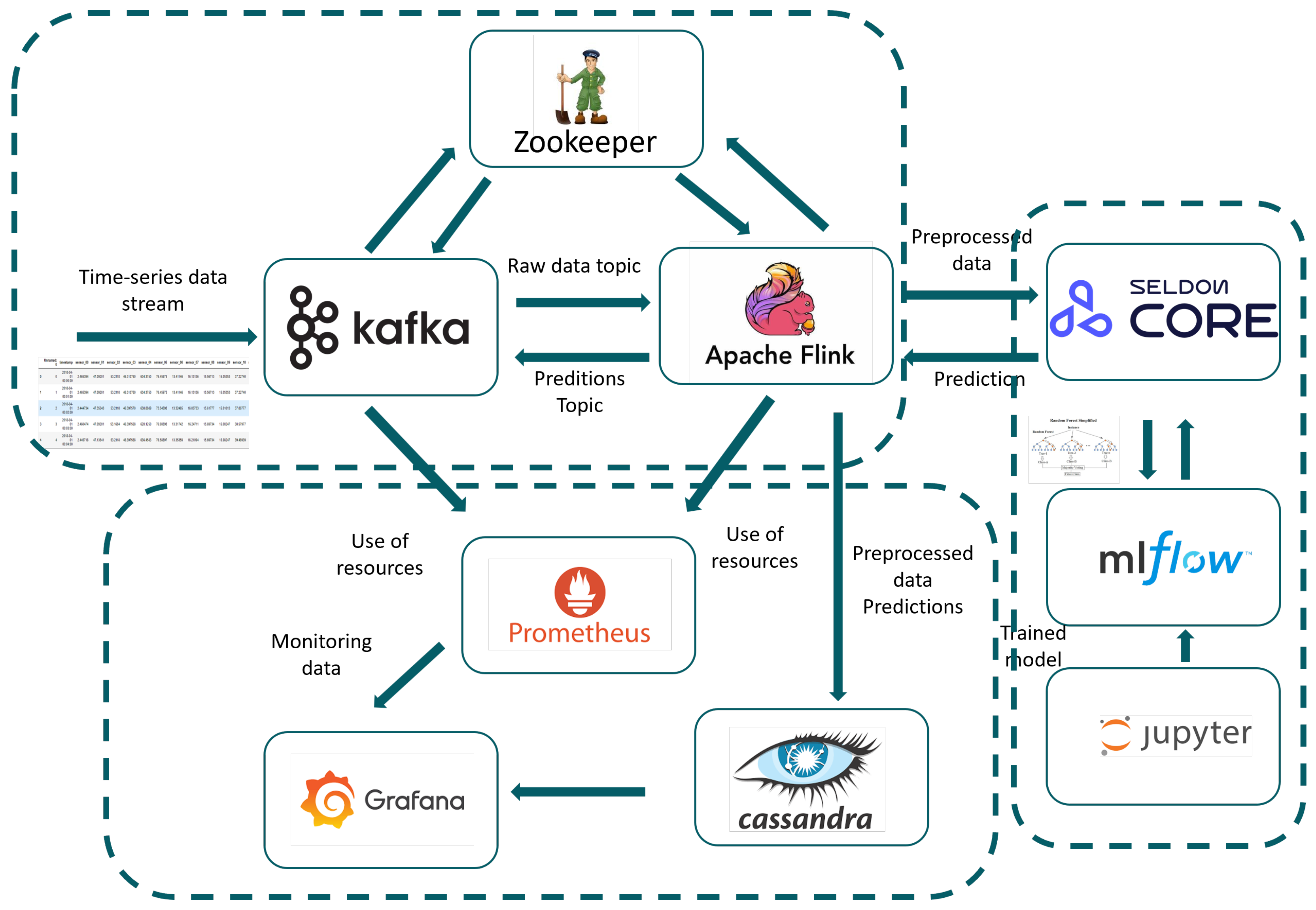
6. Deployment of the Predictive Service
6.1. Data Stream Management Component
6.2. Machine Learning Model Management Component
6.3. Monitoring and Visualisation Component
6.4. Data Flow
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| CNN | Convolutional Neural Networks |
| DBN | Deep Belief Networks |
| FC | Fully Connected |
| GANs | Generative Adversarial Networks |
| GRU | Gated Recurrent Unit |
| LSTM | Long Short-Term Memory networks |
| LR | Learning rate |
| MHA | Multi-Head Attention |
| MlOps | Machine Learning Operations |
| NLP | Natural Language Processing |
| PdM | Predictive Maintenance |
| RBMs | Restricted Boltzmann Machines |
| VAE | Variational Autoencoders |
| XAI | Explainable Artificial Intelligence |
Appendix A
| SENSOR_00 | Motor Casing Vibration |
| SENSOR_01 | Motor Frequency A |
| SENSOR_02 | Motor Frequency B |
| SENSOR_03 | Motor Frequency C |
| SENSOR_04 | Motor Speed |
| SENSOR_05 | Motor Current |
| SENSOR_06 | Motor Active Power |
| SENSOR_07 | Motor Apparent Power |
| SENSOR_08 | Motor Reactive Power |
| SENSOR_09 | Motor Shaft Power |
| SENSOR_10 | Motor Phase Current A |
| SENSOR_11 | Motor Phase Current B |
| SENSOR_12 | Motor Phase Current C |
| SENSOR_13 | Motor Coupling Vibration |
| SENSOR_14 | Motor Phase Voltage AB |
| SENSOR_16 | Motor Phase Voltage BC |
| SENSOR_17 | Motor Phase Voltage CA |
| SENSOR_18 | Pump Casing Vibration |
| SENSOR_19 | Pump Stage 1 Impeller Speed |
| SENSOR_20 | Pump Stage 1 Impeller Speed |
| SENSOR_21 | Pump Stage 1 Impeller Speed |
| SENSOR_22 | Pump Stage 1 Impeller Speed |
| SENSOR_23 | Pump Stage 1 Impeller Speed |
| SENSOR_24 | Pump Stage 1 Impeller Speed |
| SENSOR_25 | Pump Stage 2 Impeller Speed |
| SENSOR_26 | Pump Stage 2 Impeller Speed |
| SENSOR_27 | Pump Stage 2 Impeller Speed |
| SENSOR_28 | Pump Stage 2 Impeller Speed |
| SENSOR_29 | Pump Stage 2 Impeller Speed |
| SENSOR_30 | Pump Stage 2 Impeller Speed |
| SENSOR_31 | Pump Stage 2 Impeller Speed |
| SENSOR_32 | Pump Stage 2 Impeller Speed |
| SENSOR_33 | Pump Stage 2 Impeller Speed |
| SENSOR_34 | Pump Inlet Flow |
| SENSOR_35 | Pump Discharge Flow |
| SENSOR_36 | Pump UNKNOWN |
| SENSOR_37 | Pump Lube Oil Overhead Reservoir Level |
| SENSOR_38 | Pump Lube Oil Return Temp |
| SENSOR_39 | Pump Lube Oil Supply Temp |
| SENSOR_40 | Pump Thrust Bearing Active Temp |
| SENSOR_41 | Motor Non Drive End Radial Bearing Temp 1 |
| SENSOR_42 | Motor Non Drive End Radial Bearing Temp 2 |
| SENSOR_43 | Pump Thrust Bearing Inactive Temp |
| SENSOR_44 | Pump Drive End Radial Bearing Temp 1 |
| SENSOR_45 | Pump non Drive End Radial Bearing Temp 1 |
| SENSOR_46 | Pump Non Drive End Radial Bearing Temp 2 |
| SENSOR_47 | Pump Drive End Radial Bearing Temp 2 |
| SENSOR_48 | Pump Inlet Pressure |
| SENSOR_49 | Pump Temp Unknown |
| SENSOR_50 | Pump Discharge Pressure 1 |
| SENSOR_51 | Pump Discharge Pressure 2 |
References
- Keleko, A.T.; Kamsu-Foguem, B.; Ngouna, R.H.; Tongne, A. Artificial intelligence and real-time predictive maintenance in industry 4.0: A bibliometric analysis. AI Ethics 2022, 2, 553–577. [Google Scholar] [CrossRef]
- Ucar, A.; Karakose, M.; Kırımça, N. Artificial Intelligence for Predictive Maintenance Applications: Key Components, Trustworthiness, and Future Trends. Appl. Sci. 2024, 14, 898. [Google Scholar] [CrossRef]
- Li, Z.; He, Q.; Li, J. A survey of deep learning-driven architecture for predictive maintenance. Eng. Appl. Artif. Intell. 2024, 133, 108285. [Google Scholar] [CrossRef]
- Ali, S.; Abuhmed, T.; El-Sappagh, S.; Muhammad, K.; Alonso-Moral, J.M.; Confalonieri, R.; Guidotti, R.; Del Ser, J.; Díaz-Rodríguez, N.; Herrera, F. Explainable Artificial Intelligence (XAI): What we know and what is left to attain Trustworthy Artificial Intelligence. Inf. Fusion 2023, 99, 101805. [Google Scholar] [CrossRef]
- Wares, S.; Isaacs, J.; Elyan, E. Data stream mining: Methods and challenges for handling concept drift. SN Appl. Sci. 2019, 1, 1412. [Google Scholar] [CrossRef]
- Kumara, I.; Arts, R.; Nucci, D.; Heuvel, W.; Tamburri, D. Requirements and Reference Architecture for MLOps:Insights from Industry. TechRxiv 2022. [Google Scholar] [CrossRef]
- Martínez, P.L.; Dintén, R.; Drake, J.M.; Zorrilla, M.E. A big data-centric architecture metamodel for Industry 4.0. Future Gener. Comput. Syst. 2021, 125, 263–284. [Google Scholar] [CrossRef]
- EN 13306:2010; Maintenance—Maintenance Terminology. CEN/TC 319 EUROPEAN COMMITTEE FOR STANDARDIZATION: Brussels, Belgium, 2010.
- Cinar, Z.; Nuhu, A.A.; Zeeshan, Q.; Korhan, O.; Asmael, M.; Safaei, B. Machine Learning in Predictive Maintenance towards Sustainable Smart Manufacturing in Industry 4.0. Sustainability 2020, 12, 8211. [Google Scholar] [CrossRef]
- Wagner, C.; Hellingrath, B. Implementing Predictive Maintenance in a Company: Industry Insights with Expert Interviews. In Proceedings of the 2019 IEEE International Conference on Prognostics and Health Management (ICPHM), San Francisco, CA, USA, 17–20 June 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Serradilla, O.; Zugasti, E.; Rodriguez, J.; Zurutuza, U. Deep learning models for predictive maintenance: A survey, comparison, challenges and prospects. Appl. Intell. 2022, 52, 10934–10964. [Google Scholar] [CrossRef]
- Al-Said, S.; Findik, O.; Assanova, B.; Sharmukhanbet, S.; Baitemirova, N. Enhancing Predictive Maintenance in Manufacturing: A CNN-LSTM Hybrid Approach for Reliable Component Failure Prediction. In Technology-Driven Business Innovation: Unleashing the Digital Advantage; El Khoury, R., Ed.; Springer: Cham, Switzerland, 2024; Volume 1, pp. 137–153. [Google Scholar] [CrossRef]
- Lei, J.; Liu, C.; Jiang, D. Fault diagnosis of wind turbine based on Long Short-term memory networks. Renew. Energy 2019, 133, 422–432. [Google Scholar] [CrossRef]
- Li, X.; Yu, D.; Søren Byg, V.; Daniel Ioan, S. The development of machine learning-based remaining useful life prediction for lithium-ion batteries. J. Energy Chem. 2023, 82, 103–121. [Google Scholar] [CrossRef]
- Taşcı, B.; Omar, A.; Ayvaz, S. Remaining useful lifetime prediction for predictive maintenance in manufacturing. Comput. Ind. Eng. 2023, 184, 109566. [Google Scholar] [CrossRef]
- Del Buono, F.; Calabrese, F.; Baraldi, A.; Paganelli, M.; Guerra, F. Novelty Detection with Autoencoders for System Health Monitoring in Industrial Environments. Appl. Sci. 2022, 12, 4931. [Google Scholar] [CrossRef]
- Zonta, T.; Costa, C.; Righi, R.; Lima, M.J.; da Trindade, E.S.; Li, G.P. Predictive maintenance in the Industry 4.0: A systematic literature review. Comput. Ind. Eng. 2020, 150, 106889. [Google Scholar] [CrossRef]
- Achouch, M.; Dimitrova, M.; Ziane, K.; Karganroudi, S.S.; Dhouib, R.; Ibrahim, H.; Adda, M. On Predictive Maintenance in Industry 4.0: Overview, Models, and Challenges. Appl. Sci. 2022, 12, 8081. [Google Scholar] [CrossRef]
- Li, Z.; Liu, F.; Yang, W.; Peng, S.; Zhou, J. A Survey of Convolutional Neural Networks: Analysis, Applications, and Prospects. IEEE Trans. Neural Networks Learn. Syst. 2020, 33, 6999–7019. [Google Scholar] [CrossRef]
- Pinciroli Vago, N.O.; Forbicini, F.; Fraternali, P. Predicting Machine Failures from Multivariate Time Series: An Industrial Case Study. Machines 2024, 12, 357. [Google Scholar] [CrossRef]
- Lalapura, V.S.; Amudha, J.; Satheesh, H.S. Recurrent Neural Networks for Edge Intelligence. ACM Comput. Surv. 2021, 54, 1–38. [Google Scholar] [CrossRef]
- Dancker, J. A Brief Introduction to Recurrent Neural Networks—Towardsdatascience.com. Available online: https://towardsdatascience.com/a-brief-introduction-to-recurrent-neural-networks-638f64a61ff4 (accessed on 26 July 2024).
- Shenfield, A.; Howarth, M. A Novel Deep Learning Model for the Detection and Identification of Rolling Element-Bearing Faults. Sensors 2020, 20, 5112. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.u.; Polosukhin, I. Attention is All you Need. In Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Vancouver, BC, Canada, 2017; Volume 30. [Google Scholar]
- Nunes, P.; Santos, J.; Rocha, E. Challenges in predictive maintenance—A review. CIRP J. Manuf. Sci. Technol. 2023, 40, 53–67. [Google Scholar] [CrossRef]
- Kohavi, R. A study of cross-validation and bootstrap for accuracy estimation and model selection. In Proceedings of the 14th International Joint Conference on Artificial Intelligence, San Francisco, CA, USA, 12–14 June 1995; IJCAI’95. Volume 2, pp. 1137–1143. [Google Scholar]
- Baehrens, D.; Schroeter, T.; Harmeling, S.; Kawanabe, M.; Hansen, K.; Müller, K.R. How to explain individual classification decisions. J. Mach. Learn. Res. 2010, 11, 1803–1831. [Google Scholar]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Syst. 2017, 30, 4765–4774. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “ Why should i trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning Deep Features for Discriminative Localization. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Los Alamitos, CA, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar] [CrossRef]
- Sundararajan, M.; Taly, A.; Yan, Q. Axiomatic Attribution for Deep Networks. arXiv 2017, arXiv:1703.01365. [Google Scholar]
- Swathi, Y.; Challa, M. A Comparative Analysis of Explainable AI Techniques for Enhanced Model Interpretability. In Proceedings of the 2023 3rd International Conference on Pervasive Computing and Social Networking (ICPCSN), Salem, India, 19–20 June 2023; pp. 229–234. [Google Scholar] [CrossRef]
- Shapley, L.S. 17. A Value for n-Person Games. In Contributions to the Theory of Games; Kuhn, H.W., Tucker, A.W., Eds.; Princeton University Press: Princeton, NJ, USA, 1953; Volume II, pp. 307–318. [Google Scholar] [CrossRef]
- MarkovML. LIME vs. SHAP: A Comparative Analysis of Interpretability Tools. Available online: https://www.markovml.com/blog/lime-vs-shap (accessed on 2 September 2024).
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. Int. J. Comput. Vis. 2020, 128, 336–359. [Google Scholar] [CrossRef]
- Long, Z.; Fan, S.; Gao, Q.; Wei, W.; Jiang, P. Replacement of Fault Sensor of Cutter Suction Dredger Mud Pump Based on MCNN Transformer. Appl. Sci. 2024, 14, 4186. [Google Scholar] [CrossRef]
- Canziani, A.; Paszke, A.; Culurciello, E. An Analysis of Deep Neural Network Models for Practical Applications. arXiv 2016, arXiv:1605.07678. [Google Scholar]
- Flórez, A.; Rodríguez-Moreno, I.; Artetxe, A.; Olaizola, I.G.; Sierra, B. CatSight, a direct path to proper multi-variate time series change detection: Perceiving a concept drift through common spatial pattern. Int. J. Mach. Learn. Cybern. 2023, 14, 2925–2944. [Google Scholar] [CrossRef]
- Dankwa, O.K.; Mensah, J.S.; Amarfio, E.M.; Amenyah Kove, E.P. Application of Artificial Intelligence to Monitor Leaks from Pumps. Int. J. Res. Innov. Appl. Sci. 2024, IX, 28–34. [Google Scholar] [CrossRef]
- ANN for Water Pump Failure Type Classification. Available online: https://www.kaggle.com/code/vuppalaadithyasairam/ann-for-water-pump-failure-type-classification (accessed on 2 September 2024).
- Pycaret Anomaly Detection Application on Pump. Available online: https://www.kaggle.com/code/dorotheantsosheng/pycaret-anomaly-detection-application-on-pump (accessed on 2 September 2024).
- Anomaly Detection for Time Series Sensor Data. Available online: https://www.kaggle.com/code/pinakimishrads/anomaly-detection-for-time-series-sensor-data (accessed on 2 September 2024).
- 4.0, P.I. Reference Architectural Model Industrie 4.0. 2018. Available online: https://www.plattform-i40.de/PI40/Redaktion/EN/Downloads/Publikation/rami40-an-introduction.html (accessed on 26 July 2024).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| RNN | LSTM | GRU | CNN | Transformer | |
|---|---|---|---|---|---|
| Input size | (27, 60) | ||||
| Output size | (2) | ||||
| No of RNN layers | 2 | 2 | 2 | - | 1 |
| No of RNN cells | 20/20 | 20/12 | 16/16 | - | 10 |
| AF of RNN cells | tanh | tanh | tanh | - | tanh |
| No of CNN layers | - | - | - | 1 | - |
| AF of CNN layers | None | None | None | - | None |
| No of Filters | - | - | - | 16 | - |
| No of MHA layers | - | - | - | - | 1 |
| AF of MHA layers | None | None | None | - | None |
| No of Heads | - | - | - | - | 5 |
| No of FC layers | 1 | 1 | 1 | 1 | 2 |
| AF of FC layers | Softmax | Softmax | Softmax | Softmax | RELU/Softmax |
| No of Cells | 2 | 2 | 2 | 2 | 10/2 |
| Dropout rate | 0.2 | ||||
| Batch size | 32 | ||||
| Epochs | 1000 | ||||
| Optimiser | Adam | ||||
| Learning rate | 0.001 | ||||
| Loss metrics | Binary Crossentropy | ||||
| Model | F1-Score | Training Time (s) | Inference Time (s) |
|---|---|---|---|
| RNN | 0.566 | 191.5 | 0.036195 |
| LSTM | 0.947 | 439.7 | 0.036543 |
| GRU | 0.829 | 294.5 | 0.037423 |
| CNN | 0.915 | 79.87 | 0.035027 |
| Transformer | 0.964 | 602.6 | 0.037204 |
| Model | F1-Score | Training Time (s) |
|---|---|---|
| RNN | 0.985 | 107.2 |
| LSTM | 0.995 | 282 |
| GRU | 0.992 | 191.1 |
| CNN | 0.958 | 21.67 |
| Transformer | 0.988 | 161.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dintén, R.; Zorrilla, M. Design, Building and Deployment of Smart Applications for Anomaly Detection and Failure Prediction in Industrial Use Cases. Information 2024, 15, 557. https://doi.org/10.3390/info15090557
Dintén R, Zorrilla M. Design, Building and Deployment of Smart Applications for Anomaly Detection and Failure Prediction in Industrial Use Cases. Information. 2024; 15(9):557. https://doi.org/10.3390/info15090557
Chicago/Turabian StyleDintén, Ricardo, and Marta Zorrilla. 2024. "Design, Building and Deployment of Smart Applications for Anomaly Detection and Failure Prediction in Industrial Use Cases" Information 15, no. 9: 557. https://doi.org/10.3390/info15090557
APA StyleDintén, R., & Zorrilla, M. (2024). Design, Building and Deployment of Smart Applications for Anomaly Detection and Failure Prediction in Industrial Use Cases. Information, 15(9), 557. https://doi.org/10.3390/info15090557