





Word Sense Disambiguation for Morphologically Rich Low-Resourced Languages: A Systematic Literature Review and Meta-Analysis

 , ,
, ,  , and
, and
Abstract

1. Introduction
2. Related Work
3. Materials and Methods
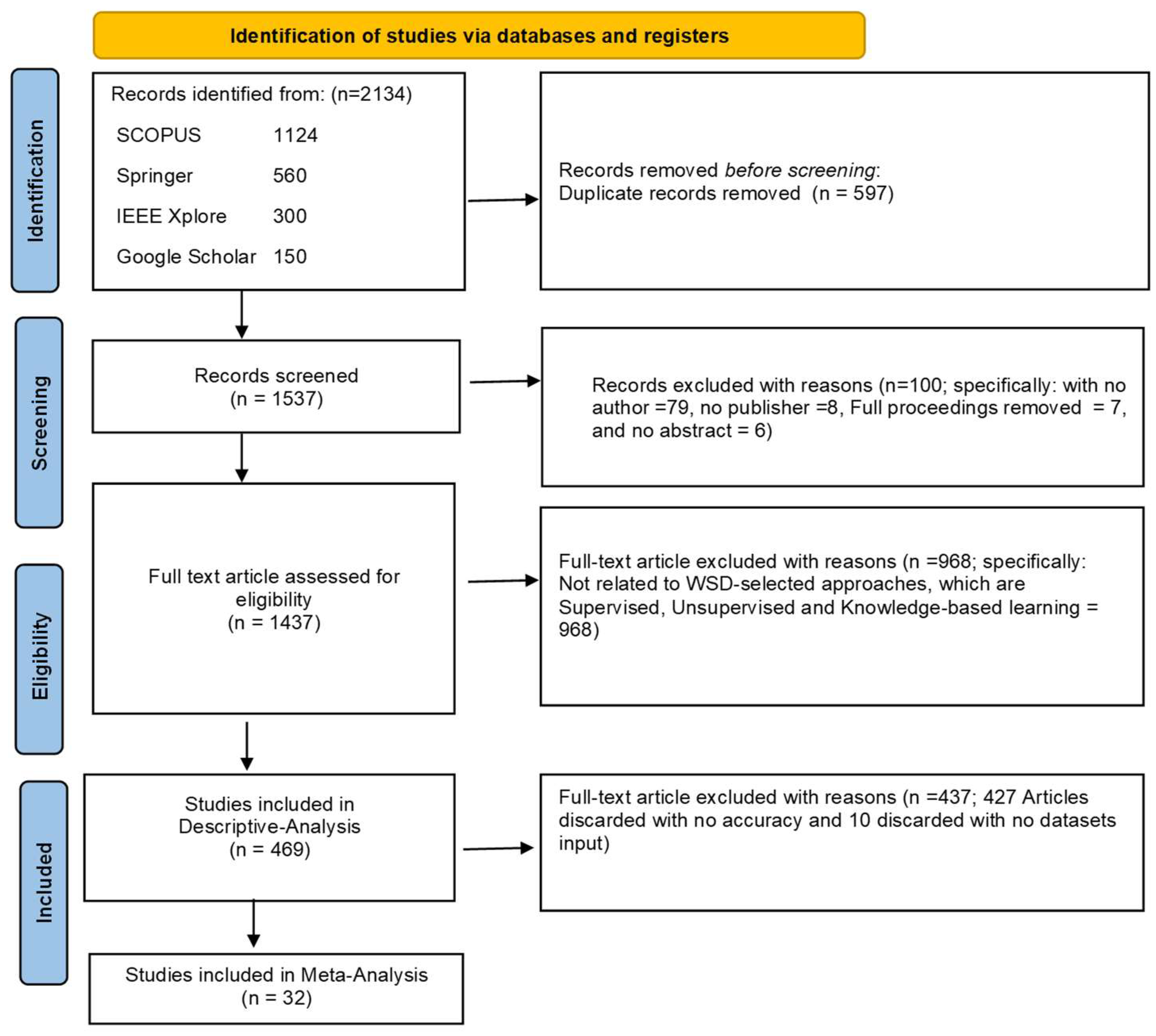
3.1. Search Strategy
3.2. Inclusion Criteria and Exclusion Criteria
3.3. Data Synthesis and Statistical Analysis
4. Results
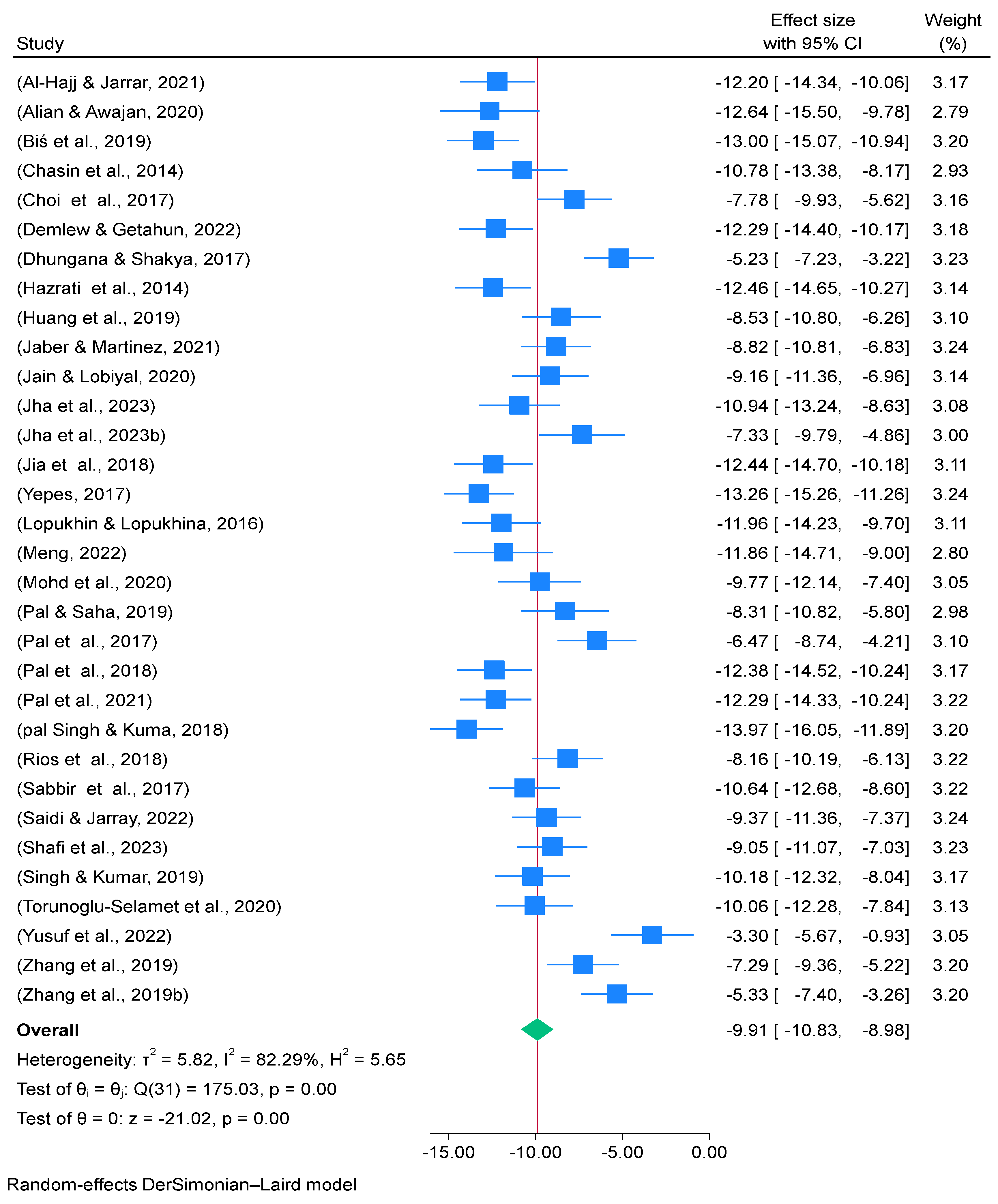
4.1. Meta-Analysis Summary
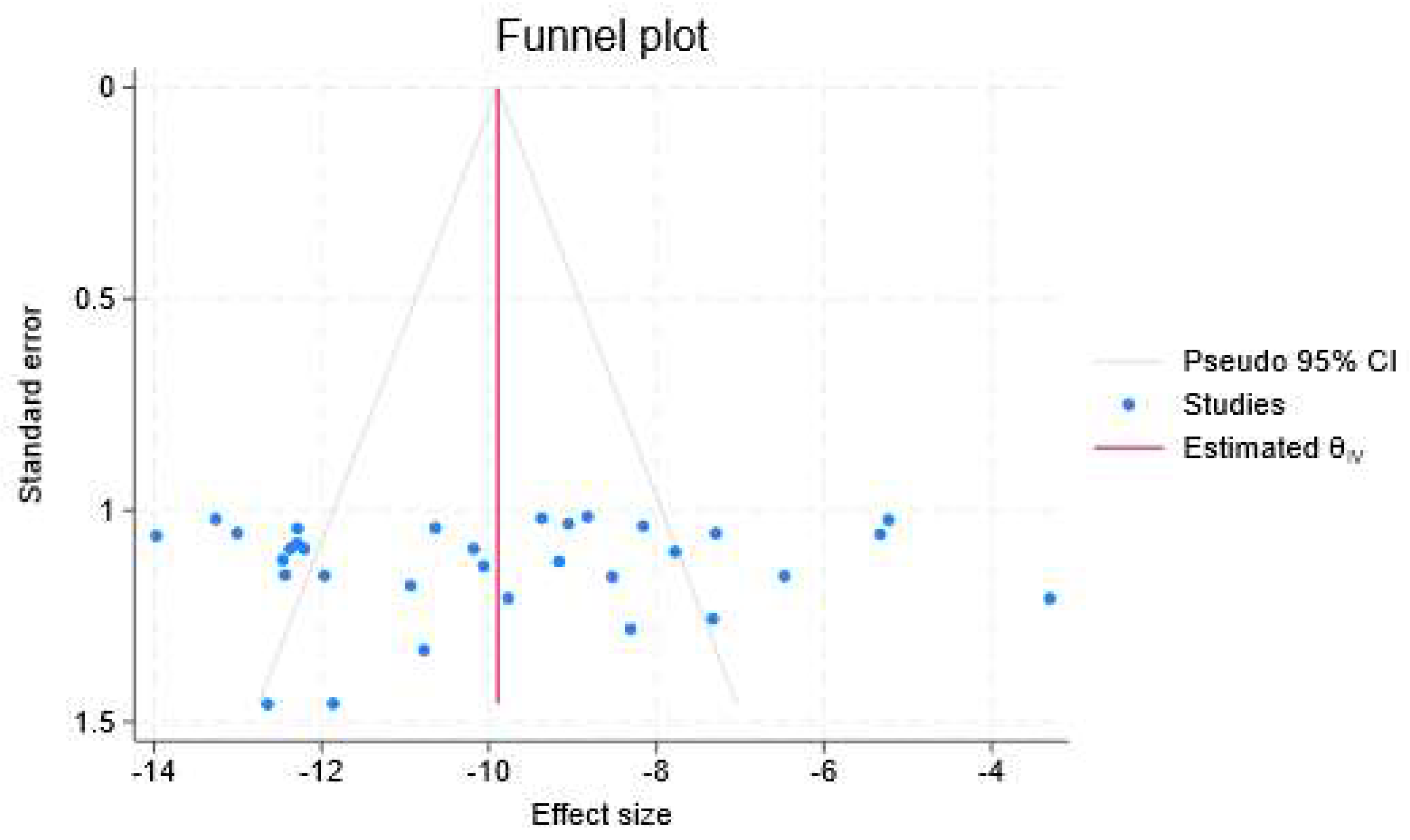
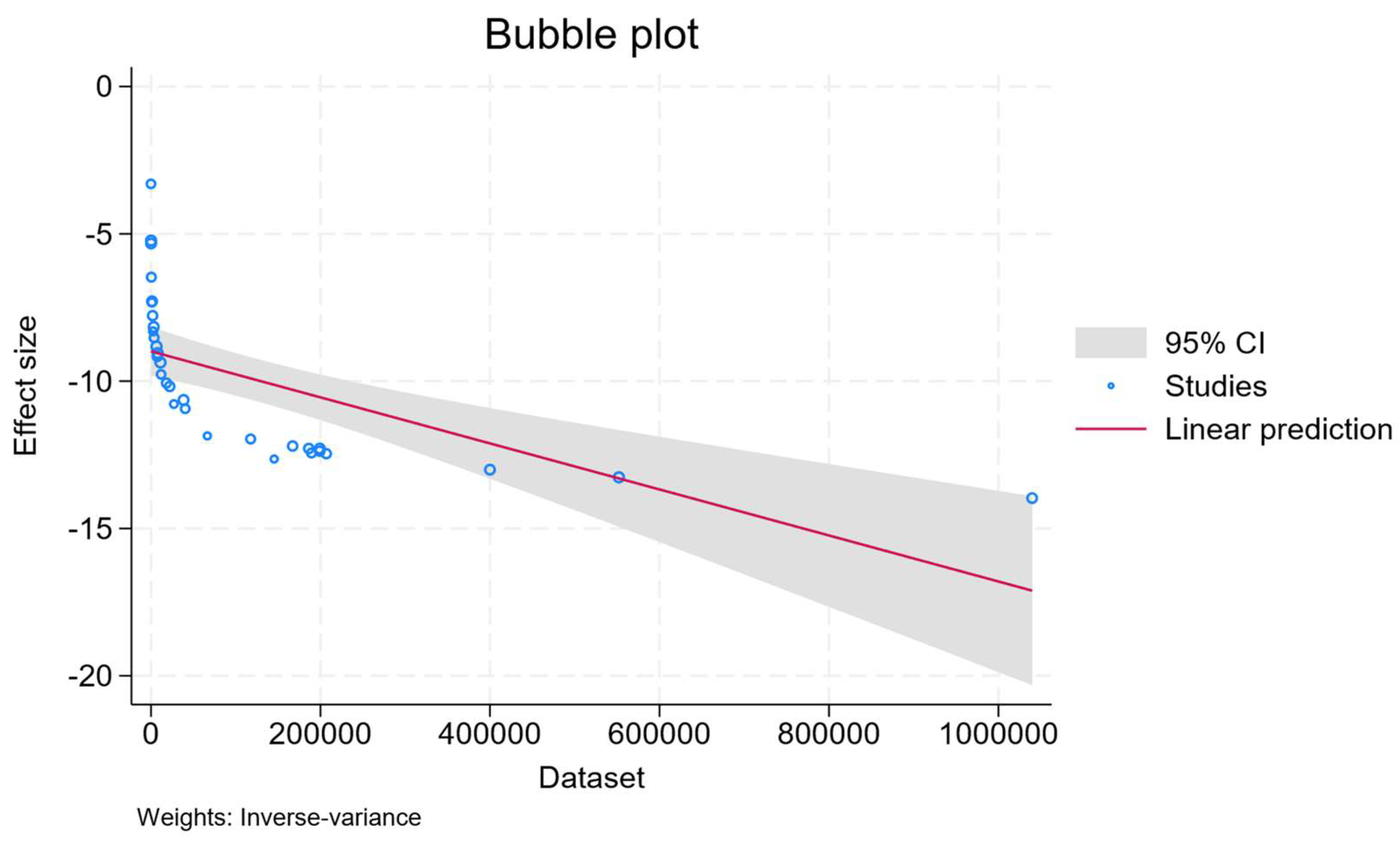
4.2. Publication Bias and Meta-Regression
4.3. Implications of Heterogeneity for WSD Based on Forest Plot in Figure 3
4.4. Significance
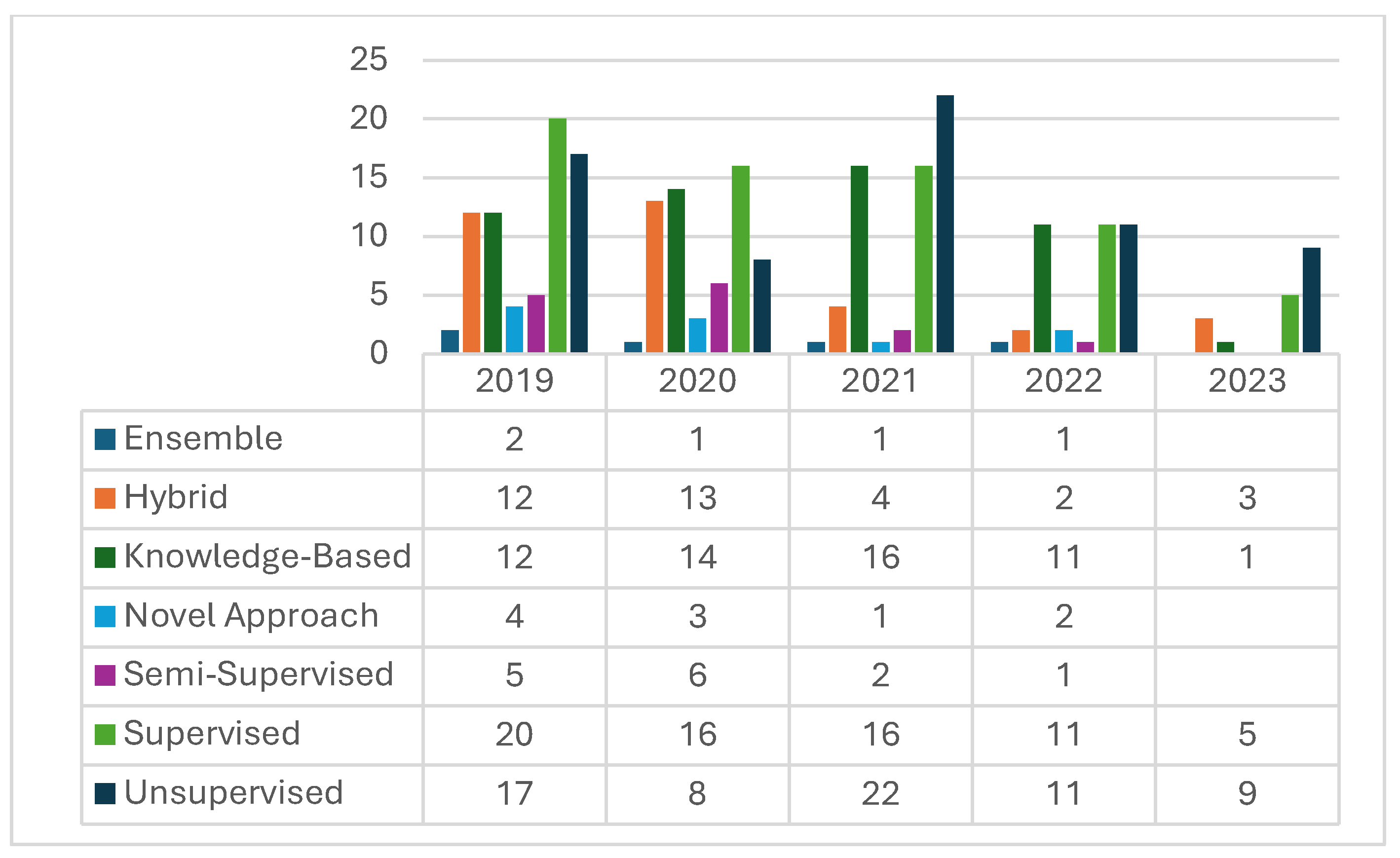
4.5. Descriptive Statistics of Primary Studies
5. Conclusions
- The most popular approaches for WSD for languages with limited resources were the supervised and unsupervised approaches;
- Each study’s sample size for determining the accuracy of the WSD differed greatly. There is a significant negative correlation between the sample size and the WSD method’s accuracy. This emphasizes how important it is to test WSD algorithms with many samples. Furthermore, a significant factor in the heterogeneity was the sample size used to calculate the WSD accuracy. The accuracy of a word sense disambiguation (WSD) approach tends to decline with increasing sample size, according to a substantial negative correlation between the two variables. There could be multiple reasons for a noteworthy inverse relationship between sample size and WSD accuracy, including (1) overfitting and complexity: Greater sample numbers lessen overfitting, but they also increase variability. If the model is not modified to accommodate this complexity, accuracy may suffer. (2) Data quality and diversity: If the model is unable to handle the extra variability, expanding the sample size may result in more noisy or diverse data, which could have a detrimental effect on accuracy. (3) Model adaptation: The accuracy of the WSD approach may be impacted by its unsuitability for larger datasets. (4) Evaluation sensitivity: Accuracy measurements may be impacted by larger datasets, revealing performance problems that are hidden in smaller datasets. Gaining an understanding of these variables can aid in the development of methods, such as improved data preparation, model tuning, and handling of data variability, to increase WSD accuracy with higher sample numbers;
- The study’s conclusions demonstrated the usefulness of the inclusion and exclusion criteria in minimizing bias by revealing the presence of heterogeneity and a negligible publication bias;
- Ultimately, the results of the meta-analysis demonstrated that the effectiveness of the many strategies put forth in the main research that was included was adequate to explore word sense disambiguation strategies for languages with limited resources.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Farouk, G.M.; Ismail, S.S.; Aref, M.M. Transformer-Based Word Sense Disambiguation: Advancements, Impact, and Future Directions. In Proceedings of the 11th IEEE International Conference on Intelligent Computing and Information Systems, ICICIS 2023, Cairo, Egypt, 21–23 November 2023; IEEE: Piscatvey, NJ, USA, 2023; pp. 140–146. [Google Scholar] [CrossRef]
- Srivastav, A.; Tayal, D.K.; Agarwal, N. A Novel Fuzzy Graph Connectivity Measure to Perform Word Sense Disambiguation Using Fuzzy Hindi WordNet. In Proceedings of the 3rd IEEE 2022 International Conference on Computing, Communication, and Intelligent Systems, ICCCIS 2022, Greater Noida, India, 4–5 November 2022; IEEE: Piscatvey, NJ, USA, 2022; pp. 648–654. [Google Scholar] [CrossRef]
- Abdelaali, B.; Tlili-Guiassa, Y. Swarm optimization for Arabic word sense disambiguation based on English pre-trained word embeddings. In Proceedings of the ISIA 2022—International Symposium on Informatics and Its Applications, M’sila, Algeria, 29–30 November 2022; IEEE: Piscatvey, NJ, USA, 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Sert, B.; Elma, E.; Altinel, A.B. Enhancing the Performance of WSD Task Using Regularized GNNs With Semantic Diffusion. IEEE Access 2023, 11, 40565–40578. [Google Scholar] [CrossRef]
- Zhang, C.X.; Shao, Y.L.; Gao, X.Y. Word Sense Disambiguation Based on RegNet With Efficient Channel Attention and Dilated Convolution. IEEE Access 2023, 11, 130733–130742. [Google Scholar] [CrossRef]
- Nascimento, C.H.D.; Garcia, V.C.; Araújo, R.d.A. A Word Sense Disambiguation Method Applied to Natural Language Processing for the Portuguese Language. IEEE Open J. Comput. Soc. 2024, 5, 268–277. [Google Scholar] [CrossRef]
- Gahankari, A.; Kapse, A.S.; Atique, M.; Thakare, V.; Kapse, A.S. Hybrid approach for Word Sense Disambiguation in Marathi Language. In Proceedings of the 2023 4th IEEE Global Conference for Advancement in Technology, GCAT 2023, Bangalore, India, 6–8 October 2023; IEEE: Piscatvey, NJ, USA, 2023; pp. 1–4. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, E.; Koh, Y.S. Supervised Clinical Abbreviations Detection and Normalisation Approach. In Proceedings of the 16th Pacific Rim International Conference on Artificial Intelligence, Proceedings, Part III, Cuvu, Yanuca Island, Fiji, 26–30 August 2019; pp. 691–703. [Google Scholar] [CrossRef]
- Kokane, C.D.; Babar, S.D.; Mahalle, P.N. Word Sense Disambiguation for Large Documents Using Neural Network Model. In Proceedings of the 2021 12th International Conference on Computing Communication and Networking Technologies, ICCCNT 2021, Kharagpur, India, 6–8 July 2021; IEEE: Piscatvey, NJ, USA, 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Boruah, P. A Novel Approach to Word Sense Disambiguation for a Low-Resource Morphologically Rich Language. In Proceedings of the 2022 IEEE 6th Conference on Information and Communication Technology, CICT 2022, Gwalior, India, 18–20 November 2022; IEEE: Piscatvey, NJ, USA, 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Bis, D.; Zhang, C.; Liu, X.; He, Z. Layered Multistep Bidirectional Long Short-Term Memory Networks for Biomedical Word Sense Disambiguation. In Proceedings of the 2018 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Madrid, Spain, 3–6 December 2018; IEEE: Piscatvey, NJ, USA, 2018; pp. 313–320. [Google Scholar] [CrossRef]
- Shafi, J.; Nawab, R.M.A.; Rayson, P. Semantic Tagging for the Urdu Language: Annotated Corpus and Multi-Target Classification Methods. ACM Trans. Asian Low Resour. Lang. Inf. Process. 2023, 22, 175. [Google Scholar] [CrossRef]
- Bakx, G.E. Machine Learning Techniques for Word Sense Disambiguation. Universitat Politµecnica de Catalunya. 2006. Available online: https://www.lsi.upc.edu/~escudero/wsd/06-tesi.pdf (accessed on 27 June 2024).
- Pal, A.R.; Saha, D. Word Sense Disambiguation: A Survey. Int. J. Control Theory Comput. Model. 2015, 5, 1–16. [Google Scholar] [CrossRef]
- Hladek, D.; Stas, J.; Pleva, M.; Ondas, S.; Kovacs, L. Survey of the Word Sense Disambiguation and Challenges for the Slovak Language. In Proceedings of the 17th IEEE International Symposium on Computational Intelligence and Informatics, Budapest, Hungary, 23–26 May 2023; IEEE: Piscatvey, NJ, USA, 2016; pp. 225–230. [Google Scholar] [CrossRef]
- Sarmah, J.; Sarma, S.K. Word Sense Disambiguation for Assamese. In Proceedings of the 2016 IEEE 6th International Conference on Advanced Computing (IACC), Bhimavaram, India, 27–28 February 2016; IEEE: Piscatvey, NJ, USA, 2016; pp. 146–151. [Google Scholar] [CrossRef]
- Zhang, C.; Biś, D.; Liu, X.; He, Z. Biomedical word sense disambiguation with bidirectional long short-term memory and attention-based neural networks. In Proceedings of the International Conference on Bioinformatics and Biomedicine 2018, Madrid, Spain, 3–6 December 2018; IEEE: Piscatvey, NJ, USA, 2019; pp. 1–15. [Google Scholar] [CrossRef]
- Mohd, M.; Jan, R.; Hakak, N. Enhanced Bootstrapping Algorithm for Automatic Annotation of Tweets. Int. J. Cogn. Inform. Nat. Intell. 2021, 14, 35–60. [Google Scholar] [CrossRef]
- Jarray, F.; Saidi, R. Combining Bert Representation and POS Tagger for Arabic Word Sense Disambiguation Combining Bert representation and POS tagger for Arabic Word Sense Disambiguation. Intell. Syst. Des. Appl. ISDA 2021 2023, 418, 1–11. [Google Scholar] [CrossRef]
- Jaber, A.; Martínez, P. Disambiguating Clinical Abbreviations using Pre-trained Word Embeddings. Healthinf 2021, 5, 501–508. [Google Scholar] [CrossRef]
- Rios, A.; Müller, M.; Sennrich, R. The Word Sense Disambiguation Test Suite at WMT18. In Proceedings of the Third Conference on Machine Translation: Shared Task Papers 2018, Belgium, Brussels, 27 July 2018; pp. 588–596. [Google Scholar] [CrossRef]
- Ranjan, A.; Diganta, S.; Naskar, K.S.; Sekhar, N. In search of a suitable method for disambiguation of word senses in Bengali. Int. J. Speech Technol. 2021, 24, 439–454. [Google Scholar] [CrossRef]
- Singh, V.P.; Bhatia, P. Naive Bayes Classifier for Word Sense Disambiguation of Punjabi Language. Malays. J. Comput. Sci. 2018, 31, 188–199. [Google Scholar] [CrossRef]
- Aliwy, A.H.; Taher, H.A. Word Sense Disambiguation: Survey study. J. Comput. Sci. 2019, 15, 1004–1011. [Google Scholar] [CrossRef]
- Ranjan, A.; Diganta, S.; Sekhar, D.N.; Pal, A. Word Sense Disambiguation in Bangla Language Using Supervised Methodology with Necessary Modifi cations. J. Inst. Eng. Ser. B 2018, 99, 519–526. [Google Scholar] [CrossRef]
- Singh, V.P.; Kumar, P. Sense disambiguation for Punjabi language using supervised machine learning techniques. Sādhanā 2019, 44, 2269. [Google Scholar] [CrossRef]
- Jain, G.; Lobiyal, D.K. Word sense disambiguation using implicit information. Nat. Lang. Eng. 2020, 26, 413–432. [Google Scholar] [CrossRef]
- Jha, P.; Agarwal, S.; Abbas, A.; Siddiqui, T.J. A Novel Unsupervısed Graph—Based Algorıthm for Hindi Word Sense Disambiguation. SN Comput. Sci. 2023, 4, 675. [Google Scholar] [CrossRef]
- Chasin, R.; Rumshisky, A.; Uzuner, O.; Szolovits, P. Word sense disambiguation in the clinical domain: A comparison of knowledge-rich and knowledge- poor unsupervised methods. J. Am. Med. Inf. Assoc. 2014, 21, 792–800. [Google Scholar] [CrossRef] [PubMed]
- Jha, P.; Agarwal, S.; Abbas, A.; Siddiqui, T. Comparative Analysis of Path-based Similarity Measures for Word Sense Disambiguation. In Proceedings of the 2023 3rd International conference on Artificial Intelligence and Signal Processing (AISP), Vijayawada, India, 18–20 March 2023; IEEE: Piscatvey, NJ, USA, 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Hou, B.; Qi, F.; Zang, Y.; Zhang, X.; Liu, Z.; Sun, M. Try to Substitute: An Unsupervised Chinese Word Sense Disambiguation Method Based on HowNet. In Proceedings of the COLING 2020—28th International Conference on Computational Linguistics, Proceedings of the Conference, Barcelona, Spain, 8–13 December 2023; International Committee on Computational Linguistics: New York, NY, USA, 2020; pp. 1752–1757. [Google Scholar] [CrossRef]
- Alian, M.; Awajan, A. Sense Inventories for Arabic Texts. In Proceedings of the 21st International Arab Conference on Information Technology (ACIT), Giza, Egypt, 6–8 December 2020; IEEE: Piscatvey, NJ, USA, 2020; pp. 3–6. [Google Scholar] [CrossRef]
- Pal, A.R.; Saha, D.; Naskar, S.K. Word Sense Disambiguation in Bengali: A Knowledge based Approach using Bengali WordNet. In Proceedings of the 2017 Second International Conference on Electrical, Computer and Communication Technologies (ICECCT), Coimbatore, India, 22–24 February 2017; IEEE: Piscatvey, NJ, USA, 2017. [Google Scholar] [CrossRef]
- Meng, F. Word Sense Disambiguation Based on Graph and Knowledge Base. In Proceedings of the 4th EAI International Conference on Robotic Sensor Networks, online, 21–22 November 2022; Springer: Cham, Switzerland, 2022; pp. 31–41. [Google Scholar] [CrossRef]
- Neeraja, K.; Rani, B.P. Approaches for Word Sense Disambiguation: Current State of The Art. Int. J. Electron. Commun. Comput. Eng. 2015, 6, 197–201. Available online: https://www.ijecce.org (accessed on 27 June 2024).
- Arbaaeen, A.; Shah, A. A knowledge-based sense disambiguation method to semantically enhanced NL question for restricted domain. Information 2021, 12, 452. [Google Scholar] [CrossRef]
- Choi, Y.; Wiebe, J.; Mihalcea, R. Coarse-Grained +/−Effect Word Sense Disambiguation for Implicit Sentiment Analysis. IEEE Trans. Affect. Comput. 2017, 8, 471–479. [Google Scholar] [CrossRef]
- Jia, Y.; Li, Y.; Zan, H. Acquiring Selectional Preferences for Knowledge Base. CLSW 2018, 10709, 275–283. [Google Scholar] [CrossRef]
- Godinez, E.V.; Szlávik, Z.; Contempré, E.; Sips, R.J. What do you mean, doctor? A knowledge-based approach for word sense disambiguation of medical terminology. In Proceedings of the 14th International Conference on Health Informatics, Vienna, Austria, 11–13 February 2021; Volume 5, pp. 273–280. [Google Scholar] [CrossRef]
- Popov, A.; Simov, K.; Osenova, P. Know your graph. State-of-the-art knowledge-based WSD. In Proceedings of the International Conference Recent Advances in Natural Language Processing, RANLP, Varna, Bulgaria, 4–6 September 2023; ACL Anthology: Shoumen, Bulgaria, 2019; pp. 949–958. [Google Scholar] [CrossRef]
- Sharma, P.; Joshi, N. Knowledge-Based Method for Word Sense Disambiguation by Using Hindi WordNet. Eng. Technol. Appl. Sci. Res. 2019, 9, 3985–3989. [Google Scholar] [CrossRef]
- Rouhizadeh, H.; Shamsfard, M.; Rouhizadeh, M. Knowledge Based Word Sense Disambiguation with Distributional. In Proceedings of the 10th International Conference on Computer and Knowledge Engineering (ICCKE2020), Mashhad, Iran, 29–30 October 2020; IEEE: Piscatvey, NJ, USA, 2020; pp. 329–335. [Google Scholar] [CrossRef]
- Demlew, G.; Yohannes, D. Resolving Amharic Lexical Ambiguity using Neural Word Embedding. In Proceedings of the 2022 International Conference on Information and Communication Technology for Development for Africa (ICT4DA), Bahir Dar, Ethiopia, 28–30 November 2022; IEEE: Piscatvey, NJ, USA, 2022. [Google Scholar] [CrossRef]
- Fard, M.H.; Fakhrahmad, S.M.; Sadreddini, M. Word Sense Disambiguation based on Gloss Expansion. In Proceedings of the 2014 6th Conference on Information and Knowledge Technology (IKT), Shahrood, Iran, 28–30 May 2014; IEEE: Piscatvey, NJ, USA, 2014; pp. 7–10. [Google Scholar] [CrossRef]
- Sabbir, A.K.M.; Jimeno-yepes, A.; Kavuluru, R. Knowledge-Based Biomedical Word Sense Disambiguation with Neural Concept Embeddings. In Proceedings of the IEEE 17th International Conference on Bioinformatics and Bioengineering (BIBE), Washington, DC, USA, 23–25 October 2017; IEEE: Piscatvey, NJ, USA, 2018; pp. 63–170. [Google Scholar] [CrossRef]
- Dhungana, U.R.; Shakya, S. Word sense disambiguation using PolyWordNet. In Proceedings of the 2016 International Conference on Inventive Computation Technologies (ICICT), Coimbatore, India, 26–27 August 2016; IEEE: Piscatvey, NJ, USA, 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Hari, A.; Kumar, P. WSD based Ontology Learning from Unstructured Text using Transformer. In Procedia Computer Science; Elsevier: Amsterdam, The Netherlands, 2022; pp. 367–374. [Google Scholar] [CrossRef]
- Butnaru, A.M.; Ionescu, R.T. ShotgunWSD 2.0: An Improved Algorithm for Global Word Sense Disambiguation. IEEE Access 2019, 7, 120961–120975. [Google Scholar] [CrossRef]
- Karnik, M.; Mishra, V.; Gaikwad, V.; Wankhede, D.; Chougale, P.; Pophale, V.; Zope, A.; Maski, C. State of the Art Analysis of Word Sense Disambiguation(ICICSD). Int. Conf. Intell. Comput. Sustain. Dev. 2024, 2122, 55–70. [Google Scholar] [CrossRef]
- Al-hajj, M.; Jarrar, M. ArabGlossBERT: Fine-Tuning BERT on Context-Gloss Pairs for WSD. Comput. Lang. 2022, 40–48. [Google Scholar] [CrossRef]
- Yusuf, M.; Surana, P.; Sharma, C. HindiWSD: A Package for Word Sense Disambiguation in Hinglish & Hindi. In Proceedings of the WILDRE-6 Workshop @LREC2020; Girish Nath Jha, A.K.O., Sobha, L., Bali, K., Eds.; European Language Resources Association (ELRA): Marseille, France, 2022; pp. 18–23. Available online: https://aclanthology.org/2022.wildre-1.4/ (accessed on 27 June 2024).
- Gujjar, V.; Mago, N.; Kumari, R.; Patel, S.; Chintalapudi, N.; Battineni, G. A Literature Survey on Word Sense Disambiguation for the Hindi Language. Information 2023, 14, 495. [Google Scholar] [CrossRef]
- Pal, A.R.; Saha, D. Word Sense Disambiguation in Bengali language using unsupervised methodology with modifications. Sadhana 2019, 44, 168. [Google Scholar] [CrossRef]
- Torunoğlu-Selamet, D.; İnceoğlu, A.; Eryiğit, G. Preliminary Investigation on Using Semi-Supervised Contextual Word Sense Disambiguation for Data Augmentation. In Proceedings of the 2020 5th International Conference on Computer Science and Engineering (UBMK), Diyarbakir, Turkey, 9–11 September 2020; IEEE: Piscatvey, NJ, USA, 2020; pp. 4–9. [Google Scholar] [CrossRef]
- Alessio, I.D.; Quaglieri, A.; Burrai, J.; Pizzo, A.; Mari, E.; Aitella, U.; Lausi, G.; Tagliaferri, G.; Cordellieri, P.; Giannini, A.M.; et al. Behavioral sciences ‘Leading through Crisis’: A Systematic Review of Institutional Decision-Makers in Emergency Contexts. Behav. Sci. 2024, 14, 481. [Google Scholar] [CrossRef]
- Page, M.J.; McKenzie, J.E.; Bossuyt, P.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D. The PRISMA 2020 statement: An updated guideline for reporting systematic reviews. BMJ 2021, 372, n71. [Google Scholar] [CrossRef]
- Necula, S.C.; Dumitriu, F.; Greavu-Șerban, V. A Systematic Literature Review on Using Natural Language Processing in Software Requirements Engineering. Electronics 2024, 13, 2055. [Google Scholar] [CrossRef]
- Albaroudi, E.; Mansouri, T.; Alameer, A. A Comprehensive Review of AI Techniques for Addressing Algorithmic Bias in Job Hiring. AI 2024, 5, 383–404. [Google Scholar] [CrossRef]
- Thompson, R.C.; Joseph, S.; Adeliyi, T.T. A Systematic Literature Review and Meta-Analysis of Studies on Online Fake News Detection. Information 2022, 13, 527. [Google Scholar] [CrossRef]
- Iomdin, B.; Lopukhina, A.; Lopukhin, K.; Nosyrev, G. Word sense frequency of similar polysemous words in different languages. In Computational Linguistics and Intellectual Technologies: Proceedings of the International Conference “Dialogue 2016”, Moscow, Russia, 1–4 June 2016; Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; pp. 214–22564742146. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Approach | Model | Accuracy |
|---|---|---|---|
| [20] | Supervised | SVM | 97% |
| [20] | Knowledge-Based | Effect Coarse-Grained | 83% |
| [30] | Unsupervised | Leacock–Chodrow | 72% |
| [19] | Supervised | BERT | 96% |
| [17] | Supervised | BiLSTM | 90 |
| [50] | Transformer Models | Arabic BERT | 84% |
| [28] | Unsupervised | Graph-Based Algorithm | 63% |
| [38] | Knowledge-Based | Selectional Preferences | 75% |
| [18] | Supervised | Bootstrapping | 69% |
| [51] | Knowledge-Based | LESK | 34% |
| [11] | Supervised | BiLSTM | 90% |
| [52] | Supervised | Naïve Bayes | 89% |
| [45] | Supervised | K-Nearest Neighbor | 94% |
| [43] | Supervised + Unsupervised | Distributional Semantic Space | 86% |
| [43] | Unsupervised + Knowledge-Based | PCA and CE | 92% |
| [32] | Unsupervised | Graph-Based | 47% |
| [34,53] | Knowledge-Based | Dependency Disambiguation Graph +Contextual Disambiguation Graph | 47% |
| [25] | Supervised | Baseline Method is Modified (inclusion of Lemmatization and Bootstrapping) | 84% |
| [27] | Unsupervised | Graph-Based | 80% |
| [33] | Knowledge-Based | Maximum Overlap | 75% |
| [26] | Deep Learning | LSTM | 84% |
| [54] | Transformer-based | ELMO | 78% |
| Database | Results | Search Phrase | Notes |
|---|---|---|---|
| SCOPUS | 1124 | Article title, Abstract, keywords ((word sense disambiguation OR “WSD”) OR (“Morphologically rich”) OR (“Low-resourced Languages”)) | extensive database with a broad scope. |
| Springer | 560 | ((“Natural Language Processing”) OR (“Word Embedding”) OR (“Word Vector Space”) OR (“Lexical Ambiguity”) OR (“Polysemy””)) | focused on information technology and computers. |
| IEEE Xplore | 300 | (“Lexical Ambiguity”) OR (“Polysemy”) OR (“Language Models”) OR (“Semantic Space”) OR (“Semantic Similarity”)). | abundant in publications on engineering and technology. |
| Google Scholar | 150 | ((word sense disambiguation OR “WSD”) OR (“Morphologically rich”) OR (“Low-resourced Languages”)) | offers a quick and easy method for searching academic publications in general. |
| Criteria | Decision |
|---|---|
| The predetermined keywords appear throughout the document, or at the very least in the title, keywords, and abstract sections. | Inclusion |
| Publications released in the year 2014 and after. | Inclusion |
| Research article written in the English language. | Inclusion |
| Research articles without WSD-selected approaches, which are Supervised, Unsupervised, and Knowledge-based learning. | Exclusion |
| Research articles without evaluation metrics. | Exclusion |
| Research articles without a corpus or dataset. | Exclusion |
| Articles not written in English, reports published prior to 2024, case reports and series, editorial letters, commentary, opinions, conference abstracts, and dissertations. | Exclusion |
| Meta-Analysis Summary: Random-Effects Model Method: DerSimonian–Laird | |||||||
|---|---|---|---|---|---|---|---|
| Heterogeneity: | tau2 = 5.8194 | I2 (%) = 82.29 | H2 = 5.65 | ||||
| Study (n = 32) | Effect Size | [95% CI] | Weight | ||||
| (Al-Hajj and Jarrar, 2022) | [50] | −12.201 | −14.340 | −10.063 | 3.17 | ||
| (Alian and Awajan, 2020) | [32] | −12.643 | −15.501 | −9.784 | 2.79 | ||
| (Biś et al., 2019) | [17] | −13.005 | −15.071 | −10.939 | 3.20 | ||
| (Chasin et al., 2014) | [29] | −10.777 | −13.384 | −8.169 | 2.93 | ||
| (Choi et al., 2017) | [37] | −7.776 | −9.928 | −5.624 | 3.16 | ||
| (Demlew and Yohannes, 2022) | [43] | −12.286 | −14.399 | −10.172 | 3.18 | ||
| (Dhungana and Shakya, 2017) | [46] | −5.227 | −7.232 | −3.223 | 3.23 | ||
| (Fard et al., 2014) | [44] | −12.462 | −14.652 | −10.272 | 3.14 | ||
| (Huang et al., 2019) | [8] | −8.527 | −10.795 | −6.259 | 3.10 | ||
| (Jaber and Martinez, 2021) | [20] | −8.822 | −10.812 | −6.833 | 3.24 | ||
| (Jain and Lobiyal, 2020) | [27] | −9.162 | −11.359 | −6.965 | 3.14 | ||
| (Jha et al., 2023) | [28] | −10.935 | −13.244 | −8.627 | 3.08 | ||
| (Jha et al., 2023b) | [30] | −7.327 | −9.790 | −4.865 | 3.00 | ||
| (Jia et al., 2018) | [38] | −12.436 | −14.695 | −10.177 | 3.11 | ||
| (Yepes, 2018) | [45] | −13.263 | −15.263 | −11.262 | 3.24 | ||
| (Lopukhin and Lopukhina, 2016) | [60] | −11.963 | −14.226 | −9.700 | 3.11 | ||
| (Meng, 2022) | [34] | −11.858 | −14.714 | −9.002 | 2.80 | ||
| (Mohd et al., 2020) | [18] | −9.770 | −12.137 | −7.403 | 3.05 | ||
| (Pal and Saha, 2019) | [53] | −8.309 | −10.819 | −5.800 | 2.98 | ||
| (Pal et al., 2017) | [33] | −6.470 | −8.735 | −4.205 | 3.10 | ||
| (Pal et al., 2018) | [25] | −12.377 | −14.515 | −10.238 | 3.17 | ||
| (Pal et al., 2017) | [33] | −12.286 | −14.329 | −10.242 | 3.22 | ||
| (Pal Singh and Kuma, 2019) | [26] | −13.971 | −16.049 | −11.893 | 3.20 | ||
| (Rios et al., 2018) | [21] | −8.158 | −10.191 | −6.126 | 3.22 | ||
| (Sabbir et al., 2017) | [45] | −10.639 | −12.680 | −8.598 | 3.22 | ||
| (Saidi and Jarray, 2022) | [19] | −9.367 | −11.364 | −7.370 | 3.24 | ||
| (Shafi et al., 2023) | [12] | −9.049 | −11.071 | −7.027 | 3.23 | ||
| (Singh and Kumar, 2019) | [26] | −10.180 | −12.319 | −8.041 | 3.17 | ||
| (Torunoglu-Selamet et al., 2020) | [54] | −10.062 | −12.281 | −7.844 | 3.13 | ||
| (Yusuf et al., 2022) | [51] | −3.302 | −5.671 | −0.934 | 3.05 | ||
| (Zhang et al., 2019) | [11] | −7.288 | −9.355 | −5.222 | 3.20 | ||
| (Zhang et al., 2019b) | [17] | −5.326 | −7.397 | −3.255 | 3.20 | ||
| Theta | −9.906 | −10.830 | −8.983 | ||||
| Test of theta = 0 | z = −21.02 | Test of homogeneity: Q = chi2(31) = 175.03 | |||||
| Prob > |z| = 0.0000 | |||||||
| Prob > Q = 0.000 | |||||||
| Parameter | Coefficient | Std. Err. | z | p > |z| | [95% Conf. Interval] | |
|---|---|---|---|---|---|---|
| Pubyear | 0.1499619 | 0.2004735 | 0.75 | 0.454 | −0.242959 | 0.5428827 |
| Constant | −312.7112 | 404.7987 | −0.77 | 0.440 | −1106.102 | 480.6797 |
| Parameter | Coefficient | Std. Err. | z | p > |z| | [95% Conf. Interval] | |
|---|---|---|---|---|---|---|
| Dataset | −7.81 × 10−6 | 1.73 × 10−6 | −4.52 | 0.000 | −0.0000112 | −4.43 × 10−6 |
| Constant | −8.987219 | 404.7987 | 0.4182412 | 0.000 | −1106.102 | −8.167481 |
| Studies (n = 36) | Coefficient | [95% Conf. Interval] | |
|---|---|---|---|
| Observed (n = 32) | −9.906 | −10.830 | −8.983 |
| Observed + Imputed (32 + 4) | −9.434 | −10.371 | −8.496 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Masethe, H.D.; Masethe, M.A.; Ojo, S.O.; Giunchiglia, F.; Owolawi, P.A. Word Sense Disambiguation for Morphologically Rich Low-Resourced Languages: A Systematic Literature Review and Meta-Analysis. Information 2024, 15, 540. https://doi.org/10.3390/info15090540
Masethe HD, Masethe MA, Ojo SO, Giunchiglia F, Owolawi PA. Word Sense Disambiguation for Morphologically Rich Low-Resourced Languages: A Systematic Literature Review and Meta-Analysis. Information. 2024; 15(9):540. https://doi.org/10.3390/info15090540
Chicago/Turabian StyleMasethe, Hlaudi Daniel, Mosima Anna Masethe, Sunday Olusegun Ojo, Fausto Giunchiglia, and Pius Adewale Owolawi. 2024. "Word Sense Disambiguation for Morphologically Rich Low-Resourced Languages: A Systematic Literature Review and Meta-Analysis" Information 15, no. 9: 540. https://doi.org/10.3390/info15090540
APA StyleMasethe, H. D., Masethe, M. A., Ojo, S. O., Giunchiglia, F., & Owolawi, P. A. (2024). Word Sense Disambiguation for Morphologically Rich Low-Resourced Languages: A Systematic Literature Review and Meta-Analysis. Information, 15(9), 540. https://doi.org/10.3390/info15090540