


Bullying Detection Solution for GIFs Using a Deep Learning Approach



Abstract
1. Introduction
- Created a dataset of bullying GIFs.
- Proposed a model based on the Convolutional Neural Network–Recurrent Neural Network (CNN-RNN) architecture that receives as input the GIFs and generates the classification result at the output (non-bullying or bullying).
- For the feature extractor, we used the DenseNet-121 model that was pre-trained on the ImageNet-1k dataset. The accuracy of our proposed solution is 99%.
2. Related Work
2.1. Text-Based Cyberbullying Detection
2.2. Image-Based Cyberbullying Detection
2.3. Image- and Text-Based Cyberbullying Detection

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Type | ML Algorithms | Benefits | Drawbacks |
|---|---|---|---|
| Text | J48, JRIP, K-nearest neighbors, SVM [32] | Took into account the prevalence of words related to cuss and insult. | The number of instances used for training is small. They did not take into account information related to context. |
| Text | Decision tree, Random Forest, Naive Bayes, SVM [33] | Reported results are good | Considered only content-based features |
| Text | SVM [34] | They utilized as features information related to age and gender. | The obtained results related to precision are not high. |
| Text | Bagging, SGD, Decision Tree, Random Forest, K-Neighbors [35] | Obtained results are good | Their dataset is not balanced. |
| Text | SVM, Logistic Regression, Naive Bayes, Decision Tree, Bagging, Random Forest [36] | Multilingual consideration | Their solution can be applied only to text written in Hinglish. |
| Image and text | Bagging Classifier [41] | They use both textual and visual features for cyberbullying prediction | The training dataset is very small |
| Text | SVM and Neural Network each of them with 2, 3 and 4 Gram [37] | They use TFIDF and sentiment analysis techniques | Considered only content-based features |
| Image | Baseline Model, Factors-only Model, Fine-tuned Pre-trained model, Multimodal Model [39] | They propose a method for the image dataset collection, evaluate 5 state-of-the-art solutions for cyberbullying detection, identify new factors for cyberbullying in images | The dataset is heavily unbalanced: 4719 cyberbullying images and 14,581 for the other category |
| Image and text | Multi-layered CNN model [42] | They use a 2-D representation of both the text and image for the CNN. They use a unified approach that combines both text and image. | Pretty poor results |
| Text | SVM and Logistic Regression [38] | They use TFIDF and sentiment analysis techniques | Considered only content-based features |
| Text and emoji | Bidirectional GRU + CNN + Attention layer [43] | They propose a deep learning model that has high accuracy. | They do not mention the size of the dataset |
| Image and text (Memes) | BERT + ResNet-Feedback and CLIP-CentralNet [40] | Their research brings improvements in terms of accuracy and precision in comparison to other solutions that consider just images or text. | The dataset is unbalanced and the results are pretty poor |
| Image and text | CNN + Binary Particle Swarm Optimization (BPSO) + Random Forest [44] | They use the BPSO algorithm that takes just the most important features. | Pretty poor results |
| Image and text | OpenCV + CNN [45] | They use various Apache technologies for storing and processing data. | They do not mention the accuracy or other performance metrics of the proposed solution. |
| Video | CNN based on EfficientNet-B7 + BiLSTM [46] | Obtained results are good | They do not consider textual or audio features. |
| Video | Generative Adversarial Networks [47] | They utilize Mel-frequency cepstral coefficients to obtain the audio features | The obtained results are poor. |
2.4. Video-Based Harmful Content Detection
2.5. Emoji- and Text-Based Cyberbullying Detection
3. Solution Design and Implementation
3.1. Data Collection and Processing
3.2. Overview of Proposed Approach
3.2.1. Input Preparation
- Read the video frames.
- Take the frames from the video until the maximum number of frames is reached.
- If the number of frames in the video is less than the maximum frame count, then the video is padded with frames filled with zeros.
3.2.2. The Convolutional Neural Network
- Dense Block;
- Transition Block.
- a convolution layer which reduces the number of feature maps (the depth);
- a pooling layer that downsamples the dimension of each feature map by half.
3.2.3. The Recurrent Neural Networks
- represents the current state of the network;
- represents the previous state of the network;
- represents the input of the current state.
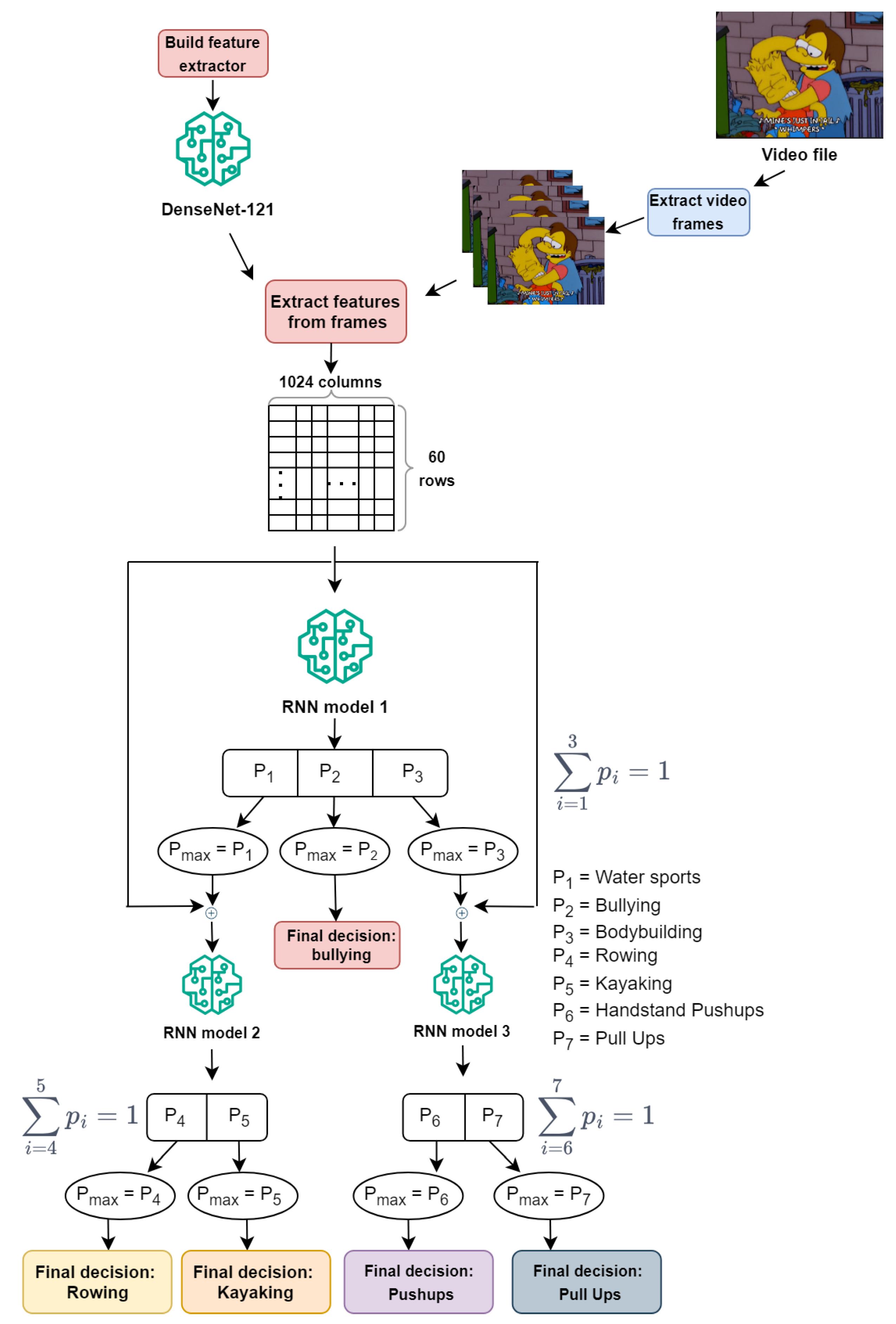
3.2.4. System General Architecture
4. Experimental Results and Analysis
4.1. Experimental Setup
- We have implemented a functionality at the beginning of the program that randomly chooses files from the dataset and puts 80% of them in the directory used for training and 20% of them in the folder used for testing.
- We have used three RNNs instead of one, as the author used. In our scenario, the first RNN is used for classifying a media file into Water sports, Bodybuilding, and bullying categories. If the file belongs to the Water sports category, then the second RNN is utilized to further classify it into Rowing or Kayaking. If the file belongs to the Bodybuilding category, then the third RNN is employed to further classify it into Handstand Pushups or Pull Ups.
- We have decreased the number of pixels from the side of a square that is cropped from the frames of the video. The variable is called IMG_SIZE, and we reduced it from 224 to 169.
- We have used more epochs. Initially, there were 10, but we increased the number to 50.
| Algorithm 1 The pseudocode of our solution. |
|
4.2. Classification Results
5. Limitations
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| BPSO | Binary Particle Swarm Optimization |
| CNN | Convolutional Neural Network |
| CNN-RNN | Convolutional Neural Network–Recurrent Neural Network |
| GIF | Graphics Interchange 67 Format |
| LIWC | Linguistic Inquiry and Word Count |
| ML | Machine Learning |
| RNN | Recurrent Neural Network |
| SVM | Support Vector Machine |
| TF-IDF | Term Frequency–Inverse Document Frequency |
References
- Cassidy, W.; Jackson, M.; Brown, K.N. Sticks and stones can break my bones, but how can pixels hurt me? Students’ experiences with cyber-bullying. Sch. Psychol. Int. 2009, 30, 383–402. [Google Scholar] [CrossRef]
- Blais, J.J.; Craig, W.M.; Pepler, D.; Connolly, J. Adolescents online: The importance of Internet activity choices to salient relationships. J. Youth Adolesc. 2008, 37, 522–536. [Google Scholar] [CrossRef]
- Jackson, L.A.; Von Eye, A.; Biocca, F.A.; Barbatsis, G.; Zhao, Y.; Fitzgerald, H.E. Does home internet use influence the academic performance of low-income children? Dev. Psychol. 2006, 42, 429. [Google Scholar] [CrossRef]
- Mostfa, A.A.; Yaseen, D.S.; Sharkawy, A.N. A Systematic Review of the Event-Driven Activities in Social Applications. SVU-Int. J. Eng. Sci. Appl. 2023, 4, 225–233. [Google Scholar] [CrossRef]
- Li, Q. New bottle but old wine: A research of cyberbullying in schools. Comput. Hum. Behav. 2007, 23, 1777–1791. [Google Scholar] [CrossRef]
- Beran, T.; Li, Q. Cyber-harassment: A study of a new method for an old behavior. J. Educ. Comput. Res. 2005, 32, 265. [Google Scholar]
- Dehue, F.; Bolman, C.; Völlink, T. Cyberbullying: Youngsters’ experiences and parental perception. CyberPsychol. Behav. 2008, 11, 217–223. [Google Scholar] [CrossRef]
- Ybarra, M.L.; Mitchell, K.J. Prevalence and frequency of Internet harassment instigation: Implications for adolescent health. J. Adolesc. Health 2007, 41, 189–195. [Google Scholar] [CrossRef]
- Blais, J.; Craig, W. Chatting, Befriending, and Bullying: Adolescent Internet Experiences and Associated Psychosocial Outcomes. Ph.D. Thesis, Department of Psychology, Queen’s University, Kingston, ON, Canada, 2008. [Google Scholar]
- Vogels, E.A. Teens and Cyberbullying 2022; Pew Research Center: Washington, DC, USA, 2022. [Google Scholar]
- Alhujailli, A.; Karwowski, W.; Wan, T.T.; Hancock, P. Affective and stress consequences of cyberbullying. Symmetry 2020, 12, 1536. [Google Scholar] [CrossRef]
- Rao, T.S.; Bansal, D.; Chandran, S. Cyberbullying: A virtual offense with real consequences. Indian J. Psychiatry 2018, 60, 3–5. [Google Scholar]
- Dinakar, K.; Jones, B.; Havasi, C.; Lieberman, H.; Picard, R. Common sense reasoning for detection, prevention, and mitigation of cyberbullying. ACM Trans. Interact. Intell. Syst. (TiiS) 2012, 2, 1–30. [Google Scholar] [CrossRef]
- Hashmi, M.N.; Kureshi, N. Cyberbullying: Perceptions, Effects and Behaviours among teenagers. J. Strategy Perform. Manag. 2020, 8, 136–141. [Google Scholar]
- Scheithauer, H.; Schultze-Krumbholz, A.; Pfetsch, J.; Hess, M. Types of cyberbullying. Wiley Blackwell Handb. Bullying Compr. Int. Rev. Res. Interv. 2021, 1, 120–138. [Google Scholar]
- Bauman, S. Types of cyberbullying. In Cyberbullying: What Counselors Need to Know; John Wiley & Sons: Hoboken, NJ, USA, 2015; pp. 53–58. [Google Scholar]
- Young, R.; Tully, M. ‘Nobody wants the parents involved’: Social norms in parent and adolescent responses to cyberbullying. J. Youth Stud. 2019, 22, 856–872. [Google Scholar] [CrossRef]
- Smith, P.K.; Mahdavi, J.; Carvalho, M.; Fisher, S.; Russell, S.; Tippett, N. Cyberbullying: Its nature and impact in secondary school pupils. J. Child Psychol. Psychiatry 2008, 49, 376–385. [Google Scholar] [CrossRef] [PubMed]
- Aboujaoude, E.; Savage, M.W.; Starcevic, V.; Salame, W.O. Cyberbullying: Review of an old problem gone viral. J. Adolesc. Health 2015, 57, 10–18. [Google Scholar] [CrossRef] [PubMed]
- Zhu, C.; Huang, S.; Evans, R.; Zhang, W. Cyberbullying among adolescents and children: A comprehensive review of the global situation, risk factors, and preventive measures. Front. Public Health 2021, 9, 634909. [Google Scholar] [CrossRef] [PubMed]
- Huang, N.; Zhang, S.; Mu, Y.; Yu, Y.; Riem, M.M.; Guo, J. Does the COVID-19 pandemic increase or decrease the global cyberbullying behaviors? A systematic review and meta-analysis. Trauma Violence Abus. 2024, 25, 1018–1035. [Google Scholar] [CrossRef]
- Hinduja, S.; Patchin, J.W. School Climate 2.0: Preventing Cyberbullying and Sexting One Classroom at a Time; Corwin Press: Thousand Oaks, CA, USA, 2012. [Google Scholar]
- Tokunaga, R.S. Following you home from school: A critical review and synthesis of research on cyberbullying victimization. Comput. Hum. Behav. 2010, 26, 277–287. [Google Scholar] [CrossRef]
- Dadvar, M.; Trieschnigg, D.; Ordelman, R.; De Jong, F. Improving cyberbullying detection with user context. In Proceedings of the Advances in Information Retrieval: 35th European Conference on IR Research, ECIR 2013, Moscow, Russia, 24–27 March 2013; Proceedings 35. Springer: Berlin/Heidelberg, Germany, 2013; pp. 693–696. [Google Scholar]
- Fati, S.M.; Muneer, A.; Alwadain, A.; Balogun, A.O. Cyberbullying detection on twitter using deep learning-based attention mechanisms and continuous Bag of words feature extraction. Mathematics 2023, 11, 3567. [Google Scholar] [CrossRef]
- Pater, J.A.; Miller, A.D.; Mynatt, E.D. This digital life: A neighborhood-based study of adolescents’ lives online. In Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems, Seoul, Republic of Korea, 18–23 April 2015; pp. 2305–2314. [Google Scholar]
- Wu, D.; Hou, Y.T.; Zhu, W.; Zhang, Y.Q.; Peha, J.M. Streaming video over the Internet: Approaches and directions. IEEE Trans. Circuits Syst. Video Technol. 2001, 11, 282–300. [Google Scholar]
- Seiler, S.J.; Navarro, J.N. Bullying on the pixel playground: Investigating risk factors of cyberbullying at the intersection of children’s online-offline social lives. Cyberpsychol. J. Psychosoc. Res. Cyberspace 2014, 8, 37–52. [Google Scholar] [CrossRef]
- Singh, V.K.; Radford, M.L.; Huang, Q.; Furrer, S. “They basically like destroyed the school one day” On Newer App Features and Cyberbullying in Schools. In Proceedings of the 2017 ACM Conference on Computer Supported Cooperative Work and Social Computing, Portland, OR, USA, 25 February–1 March 2017; pp. 1210–1216. [Google Scholar]
- Mladenović, M.; Ošmjanski, V.; Stanković, S.V. Cyber-aggression, cyberbullying, and cyber-grooming: A survey and research challenges. ACM Comput. Surv. (CSUR) 2021, 54, 1–42. [Google Scholar] [CrossRef]
- Jakubowicz, A. Alt_Right White Lite: Trolling, hate speech and cyber racism on social media. Cosmop. Civ. Soc. Interdiscip. J. 2017, 9, 41–60. [Google Scholar] [CrossRef]
- Reynolds, K.; Kontostathis, A.; Edwards, L. Using machine learning to detect cyberbullying. In Proceedings of the 2011 10th International Conference on Machine Learning and Applications and Workshops, Honolulu, HI, USA, 18–21 December 2011; IEEE: Piscataway, NJ, USA, 2011; Volume 2, pp. 241–244. [Google Scholar]
- Siddhartha, K.; Kumar, K.R.; Varma, K.J.; Amogh, M.; Samson, M. Cyber Bullying Detection Using Machine Learning. In Proceedings of the 2022 2nd Asian Conference on Innovation in Technology (ASIANCON), Ravet, India, 26–28 August 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–4. [Google Scholar]
- Dadvar, M.; de Jong, F.M.; Ordelman, R.; Trieschnigg, D. Improved cyberbullying detection using gender information. In Proceedings of the Proceedings of the Twelfth Dutch-Belgian Information Retrieval Workshop (DIR 2012), Ghent, Belgium, 24 February 2012; Universiteit Gent: Ghent, Belgium, 2012; pp. 23–25. [Google Scholar]
- Jain, V.; Saxena, A.K.; Senthil, A.; Jain, A.; Jain, A. Cyber-bullying detection in social media platform using machine learning. In Proceedings of the 2021 10th International Conference on System Modeling & Advancement in Research Trends (SMART), Moradabad, India, 10–11 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 401–405. [Google Scholar]
- Singla, S.; Lal, R.; Sharma, K.; Solanki, A.; Kumar, J. Machine learning techniques to detect cyber-bullying. In Proceedings of the 2023 5th International Conference on Inventive Research in Computing Applications (ICIRCA), Coimbatore, India, 3–5 August 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 639–643. [Google Scholar]
- Hani, J.; Nashaat, M.; Ahmed, M.; Emad, Z.; Amer, E.; Mohammed, A. Social media cyberbullying detection using machine learning. Int. J. Adv. Comput. Sci. Appl. 2019, 10, 703–707. [Google Scholar] [CrossRef]
- Perera, A.; Fernando, P. Accurate cyberbullying detection and prevention on social media. Procedia Comput. Sci. 2021, 181, 605–611. [Google Scholar] [CrossRef]
- Vishwamitra, N.; Hu, H.; Luo, F.; Cheng, L. Towards understanding and detecting cyberbullying in real-world images. In Proceedings of the 2020 19th IEEE international conference on machine learning and applications (ICMLA), Virtual Event, 14–17 December 2020. [Google Scholar]
- Maity, K.; Jha, P.; Saha, S.; Bhattacharyya, P. A multitask framework for sentiment, emotion and sarcasm aware cyberbullying detection from multi-modal code-mixed memes. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, 11–15 July 2022; pp. 1739–1749. [Google Scholar]
- Singh, V.K.; Ghosh, S.; Jose, C. Toward multimodal cyberbullying detection. In Proceedings of the 2017 CHI Conference Extended Abstracts on Human Factors in Computing Systems, Denver, CO, USA, 6–11 May 2017; pp. 2090–2099. [Google Scholar]
- Kumari, K.; Singh, J.P.; Dwivedi, Y.K.; Rana, N.P. Towards Cyberbullying-free social media in smart cities: A unified multi-modal approach. Soft Comput. 2020, 24, 11059–11070. [Google Scholar] [CrossRef]
- Luo, Y.; Zhang, X.; Hua, J.; Shen, W. Multi-featured cyberbullying detection based on deep learning. In Proceedings of the 2021 16th International Conference on Computer Science & Education (ICCSE), Lancaster, UK, 17–21 August; IEEE: Piscataway, NJ, USA, 2021; pp. 746–751. [Google Scholar]
- Kumari, K.; Singh, J.P.; Dwivedi, Y.K.; Rana, N.P. Multi-modal aggression identification using convolutional neural network and binary particle swarm optimization. Future Gener. Comput. Syst. 2021, 118, 187–197. [Google Scholar] [CrossRef]
- Do, P.; Pham, P.; Phan, T. Some research issues of harmful and violent content filtering for social networks in the context of large-scale and streaming data with Apache Spark. In Recent Advances in Security, Privacy, and Trust for Internet of Things (IoT) and Cyber-Physical Systems (CPS); Chapman and Hall: London, UK, 2020; pp. 249–272. [Google Scholar]
- Yousaf, K.; Nawaz, T. A deep learning-based approach for inappropriate content detection and classification of youtube videos. IEEE Access 2022, 10, 16283–16298. [Google Scholar] [CrossRef]
- Vishal, Y.; Bhaskar, J.U.; Yaswanthreddy, R.; Vyshnavi, C.; Shanti, S. A Novel Approach for Inappropriate Content Detection and Classification of Youtube Videos using Deep Learning. In Proceedings of the 2024 3rd International Conference on Applied Artificial Intelligence and Computing (ICAAIC), Salem, India, 5–7 June 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 539–545. [Google Scholar]
- Feng, J.; Gomez, V. Continual Learning on Facial Recognition Using Convolutional Neural Networks. U.P.B. Sci. Bull. Ser. C 2023, 85, 239–248. [Google Scholar]






| Bodybuilding | Bullying | Water Sports | |
|---|---|---|---|
| Nr. video train | 154 | 80 | 176 |
| Nr. video test | 38 | 20 | 44 |
| Total | 192 | 100 | 220 |
| Kayaking | Rowing | |
|---|---|---|
| Nr. video train | 88 | 88 |
| Nr. video test | 22 | 22 |
| Total | 110 | 110 |
| Pull Ups | Pushups | |
|---|---|---|
| Nr. video train | 80 | 74 |
| Nr. video test | 20 | 18 |
| Total | 100 | 92 |
| Group | Category | No. of Media Files |
|---|---|---|
| Bodybuilding | Handstand Pushups | 100 |
| Pull Ups | 92 | |
| Water sports | Rowing | 110 |
| Kayaking | 110 | |
| Total | - | 412 |
| Class | No. of Media Files |
|---|---|
| Non-bullying | 412 |
| Bullying | 100 |
| Total | 512 |
| Description | Value |
|---|---|
| Activation functions | ReLU, softmax |
| Dropout rate | 0.4 |
| Learning rate | 0.001 |
| Loss function | Sparse categorical crossentropy |
| Optimizer | Adam |
| Epoch | 50 |
| System Type | OS | Architecture | CPU | Memory |
|---|---|---|---|---|
| Virtual Machine | Win. 10 | 64-bit | 4 cores | 4 GB RAM |
| Host | Win. 10 | 64-bit | Intel-i9 | 32 GB RAM |
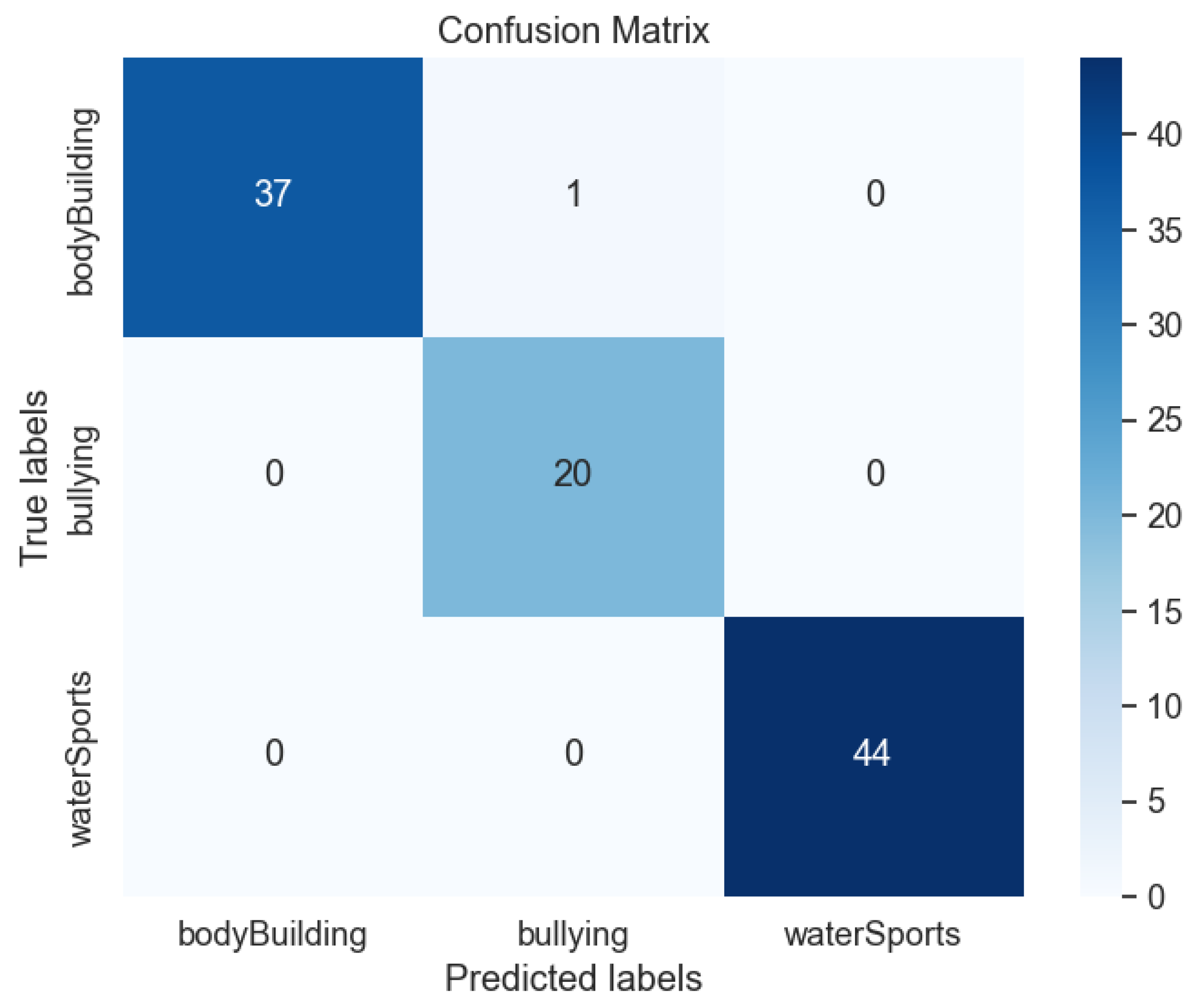
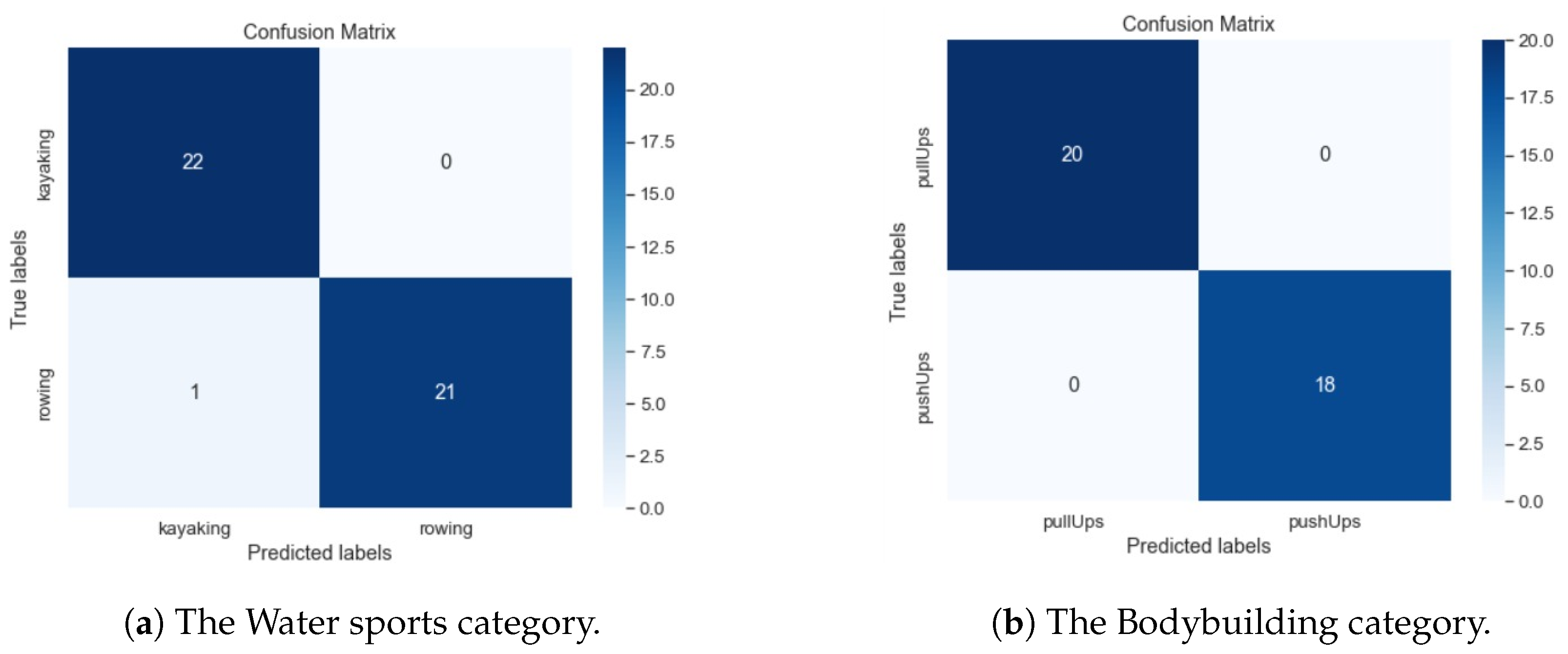
| RNN Model No. | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| Proposed RNN model no. 1 | 99.02% | 95.24% (B) | 100% (B) | 97.56% (B) |
| 100% (BB) | 97.37% (BB) | 98.66% (BB) | ||
| 100% (WS) | 100% (WS) | 100% (WS) | ||
| Proposed RNN model no. 2 | 97.7% | 95.65% (K) | 100% (K) | 97.77% (K) |
| 100% (R) | 95.45% (R) | 97.67% (R) | ||
| Proposed RNN model no. 3 | 100% | 100% (Pull) | 100% (Pull) | 100% (Pull) |
| 100% (Push) | 100% (Push) | 100% (Push) | ||
| Simple RNN | 51.96% | 64% (B) | 80% (B) | 71% (B) |
| 48.39% (K) | 68.18% (K) | 56.61% (K) | ||
| 51.28% (Pull) | 100% (Pull) | 67.8% (Pull) | ||
| 0% (Push) | 0% (Push) | 0% (Push) | ||
| 28.57% (R) | 10% (R) | 14.82% (R) |
| RNN Model Number | Category | Accuracy |
|---|---|---|
| 1 | Bodybuilding | 99.74% |
| Bullying | 0.16% | |
| Water sports | 0.10% | |
| 2 | Pull Ups | 98.21% |
| Handstand Pushups | 1.79% |
| RNN Model Number | Category | Accuracy |
|---|---|---|
| 1 | Bullying | 96.60% |
| Water sports | 2.07% | |
| Bodybuilding | 1.34% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Stoleriu, R.; Nascu, A.; Anghel, A.M.; Pop, F. Bullying Detection Solution for GIFs Using a Deep Learning Approach. Information 2024, 15, 446. https://doi.org/10.3390/info15080446
Stoleriu R, Nascu A, Anghel AM, Pop F. Bullying Detection Solution for GIFs Using a Deep Learning Approach. Information. 2024; 15(8):446. https://doi.org/10.3390/info15080446
Chicago/Turabian StyleStoleriu, Razvan, Andrei Nascu, Ana Magdalena Anghel, and Florin Pop. 2024. "Bullying Detection Solution for GIFs Using a Deep Learning Approach" Information 15, no. 8: 446. https://doi.org/10.3390/info15080446
APA StyleStoleriu, R., Nascu, A., Anghel, A. M., & Pop, F. (2024). Bullying Detection Solution for GIFs Using a Deep Learning Approach. Information, 15(8), 446. https://doi.org/10.3390/info15080446