
Defining Nodes and Edges in Other Languages in Cognitive Network Science—Moving beyond Single-Layer Networks


Abstract
1. Introduction
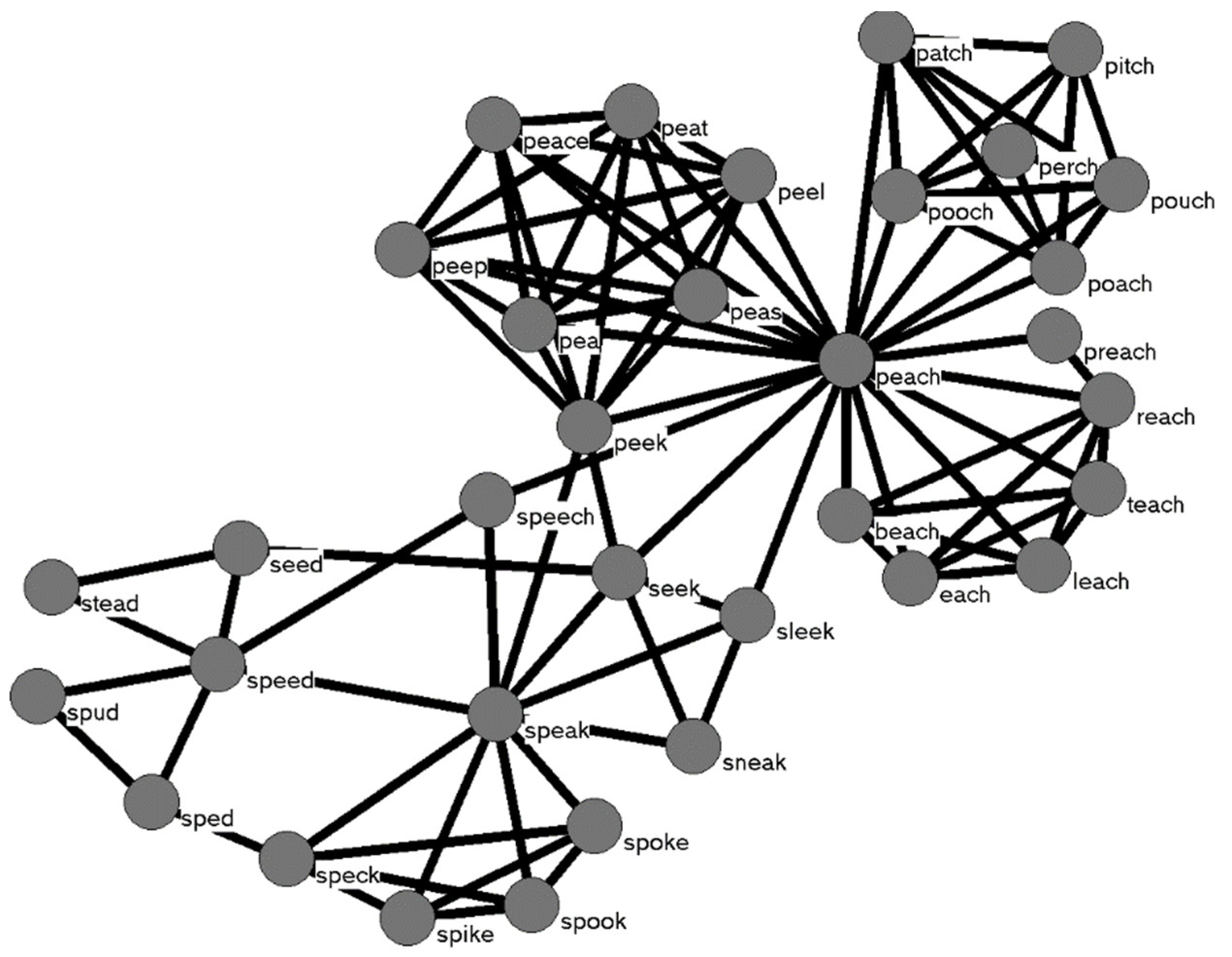
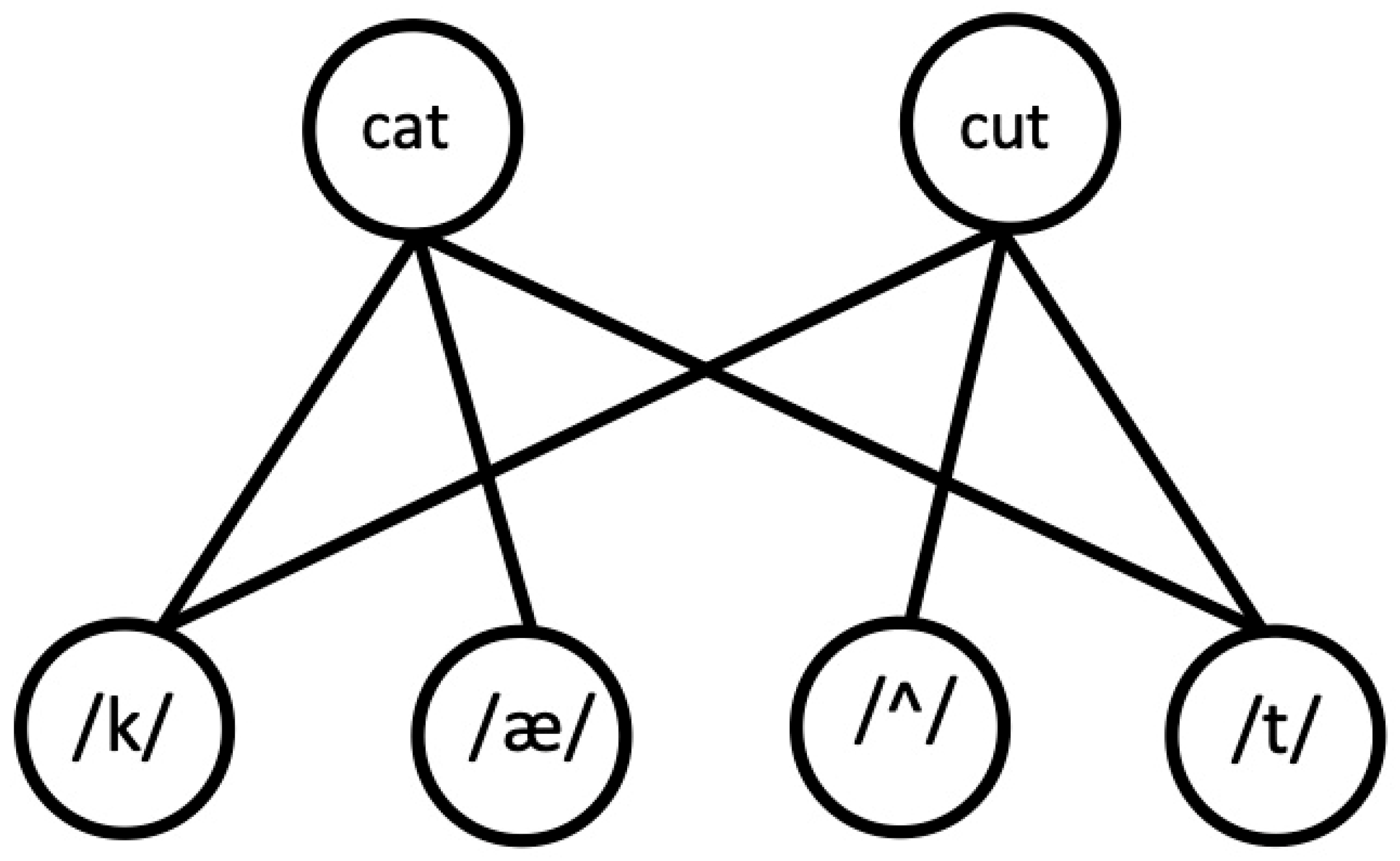
2. The Definition of “Connection” and American Sign Language
2.1. Methodology
2.2. Results
2.3. Discussion
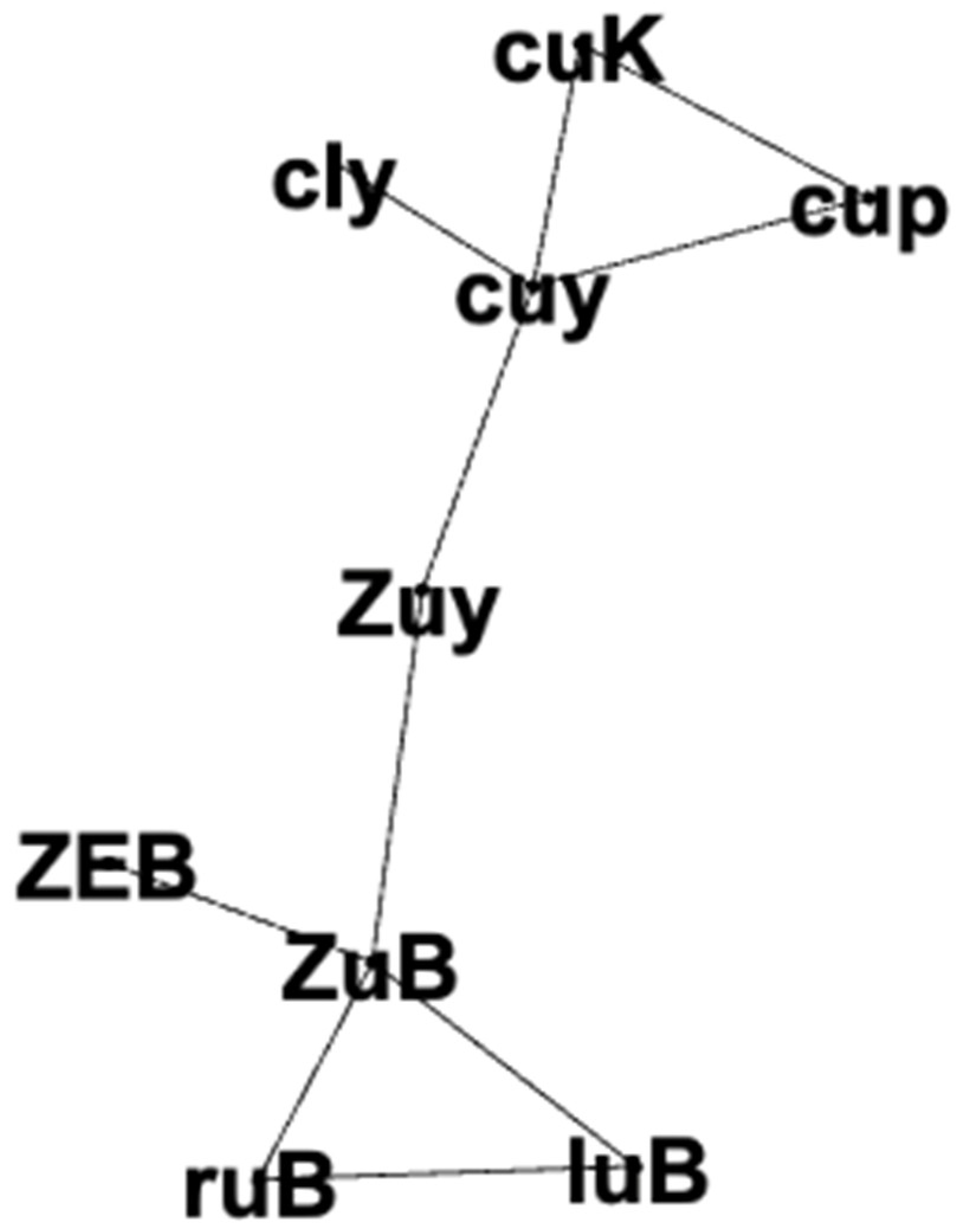
3. The Definition of “Node” and Kaqchikel
3.1. Methodology
3.2. Results
3.3. Discussion
4. Conclusion: Moving Forward with Cognitive Network Science
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Guest, M.; Zito, M.; Hulleman, J.; Bertamini, M. On the usefulness of graph-theoretic properties in the study of perceived nu-merosity. Behav. Res. Methods 2022, 54, 2381–2397. [Google Scholar] [CrossRef] [PubMed]
- Siew, C.S.Q.; Wulff, D.U.; Beckage, N.M.; Kenett, Y.N. Cognitive Network Science: A review of research on cognition through the lens of representations, processes, and dynamics. Complexity 2019, 2108423. [Google Scholar] [CrossRef]
- Vitevitch, M.S. What can graph theory tell us about word learning and lexical retrieval? J. Speech Lang. Heart Res. 2008, 51, 408–422. [Google Scholar] [CrossRef] [PubMed]
- Vitevitch, M.S. (Ed.) . Network Science in Cognitive Psychology; Routledge: London, UK, 2019. [Google Scholar]
- Vitevitch, M.S. What Can Network Science Tell Us About Phonology and Language Processing? Top. Cogn. Sci. 2021, 14, 127–142. [Google Scholar] [CrossRef] [PubMed]
- Neal, Z.P. The Connected City: How Networks Are Shaping the Modern Metropolis; Routledge: New York, NY, USA, 2013. [Google Scholar]
- Steyvers, M.; Tenenbaum, J.B. The Large-Scale Structure of Semantic Networks: Statistical Analyses and a Model of Semantic Growth. Cogn. Sci. 2005, 29, 41–78. [Google Scholar] [CrossRef] [PubMed]
- Carpenter, G.A.; Grossberg, S. Adaptive Resonance Theory. In Encyclopedia of Machine Learning and Data Mining; Sammut, C., Webb, G., Eds.; Springer: Berlin, Germany, 2016. [Google Scholar]
- Page, M. Connectionist modelling in psychology: A localist manifesto. Behav. Brain Sci. 2000, 23, 443–467. [Google Scholar] [CrossRef] [PubMed]
- Rogers, T.T.; McClelland, J.L. Parallel Distributed Processing at 25: Further Explorations in the Microstructure of Cognition. Cogn. Sci. 2014, 38, 1024–1077. [Google Scholar] [CrossRef] [PubMed]
- Rash, J.E.; Dillman, R.K.; Bilhartz, B.L.; Duffy, H.S.; Whalen, L.R.; Yasumura, T. Mixed synapses discovered and mapped throughout mammalian spinal cord. Proc. Natl. Acad. Sci. USA 1996, 93, 4235–4239. [Google Scholar] [CrossRef] [PubMed]
- Serrano-Velez, J.L.; Rodriguez-Alvarado, M.; Torres-Vazquez, I.I.; Fraser, S.E.; Yasumura, T.; Vanderpool, K.G.; Rash, J.E.; Rosa-Molinar, E. Abundance of gap junctions at glutamatergic mixed synapses in adult Mosquitofish spinal cord neurons. Front. Neural Circuits 2014, 8, 66. [Google Scholar] [CrossRef] [PubMed]
- Watts, D.J.; Strogatz, S.H. Collective dynamics of ‘small-world’ networks. Nature 1998, 393, 440–442. [Google Scholar] [CrossRef] [PubMed]
- Kleinberg, J.M. Navigation in a small world. Nature 2000, 406, 845. [Google Scholar] [CrossRef] [PubMed]
- Latora, V.; Marchiori, M. Efficient Behavior of Small-World Networks. Phys. Rev. Lett. 2001, 87, 198701. [Google Scholar] [CrossRef] [PubMed]
- Rand, D.G.; Arbesman, S.; Christakis, N.A. Dynamic social networks promote cooperation in experiments with hu-mans. Proc. Natl. Acad. Sci. USA 2011, 108, 19193–19198. [Google Scholar] [CrossRef] [PubMed]
- Shirado, H.; Iosifidis, G.; Christakis, N.A. Assortative mixing and resource inequality enhance collective welfare in sharing networks. Proc. Natl. Acad. Sci. USA 2019, 116, 22442–22444. [Google Scholar] [CrossRef] [PubMed]
- Chan, K.Y.; Vitevitch, M.S. The Influence of the Phonological Neighborhood Clustering Coefficient on Spoken Word Recogni-tion. J. Exp. Psychol. Hum. 2009, 35, 1934–1949. [Google Scholar] [CrossRef] [PubMed]
- Chan, K.Y.; Vitevitch, M.S. Network Structure Influences Speech Production. Cogn. Sci. 2010, 34, 685–697. [Google Scholar] [CrossRef] [PubMed]
- Goldstein, R.; Vitevitch, M.S. The influence of clustering coefficient on word-learning: How groups of similar sounding words facilitate acquisition. Front. Lang. Sci. 2014, 5, 01307. [Google Scholar] [CrossRef] [PubMed]
- Vitevitch, M.S.; Chan, K.Y.; Roodenrys, S. Complex network structure influences processing in long-term and short-term memory. J. Mem. Lang. 2012, 67, 30–44. [Google Scholar] [CrossRef] [PubMed]
- Vitevitch, M.S.; Ng, J.W.; Hatley, E.; Castro, N. Phonological but not semantic influences on the speech-to-song illusion. Q. J. Exp. Psychol. 2021, 74, 585–597. [Google Scholar] [CrossRef] [PubMed]
- Borgatti, S.P. Identifying sets of key players in a social network. Comput. Math. Organ. Theory 2006, 12, 21–34. [Google Scholar] [CrossRef]
- Vitevitch, M.S.; Goldstein, R. Keywords in the mental lexicon. J. Mem. Lang. 2014, 73, 131–147. [Google Scholar] [CrossRef] [PubMed]
- Vitevitch, M.S.; Castro, N. Using network science in the language sciences and clinic. Int. J. Speech-Language Pathol. 2014, 17, 13–25. [Google Scholar] [CrossRef] [PubMed]
- Siew, C.S.Q.; Vitevitch, M.S. Spoken word recognition and serial recall of words from components in the phonological network. J. Exp. Psychol. Learn. Mem. Cogn. 2016, 42, 394–410. [Google Scholar] [CrossRef] [PubMed]
- Vitevitch, M.S.; Sale, M. Identifying the phonological backbone in the mental lexicon. PLoS ONE 2023, 18, e0287197. [Google Scholar] [CrossRef] [PubMed]
- Vitevitch, M.S.; Chan, K.Y.; Goldstein, R. Using English as a ‘model language’ to understand language processing. In Motor Speech Disorders: A Cross-Language Perspective; Miller, N., Lowit, A., Eds.; Multilingual Matters: Bristol, UK, 2014. [Google Scholar]
- Vitevitch, M.S.; Luce, P.A. A Web-based interface to calculate phonotactic probability for words and nonwords in English. Behav. Res. Methods Instrum. Comput. 2004, 36, 481–487. [Google Scholar] [CrossRef] [PubMed]
- Blasi, D.E.; Henrich, J.; Adamou, E.; Kemmerer, D.; Majid, A. Over-reliance on English hinders cognitive science. Trends Cogn. Sci. 2022, 26, 1153–1170. [Google Scholar] [CrossRef] [PubMed]
- Truan, N. Whose language counts?: Native speakerism and monolingual bias in language ideological research: Challenges and directions for further research. Eur. J. Appl. Linguist. 2024, 12, 34–53. [Google Scholar] [CrossRef]
- Arbesman, S.; Strogatz, S.H.; Vitevitch, M.S. The structure of phonological networks across multiple languages. Int. J. Bifurc. Chaos 2010, 20, 679–685. [Google Scholar] [CrossRef]
- Lara-Martínez, P.; Obregón-Quintana, B.; Reyes-Manzano, C.F.; López-Rodríguez, I.; Guzmán-Vargas, L. A multiplex analysis of phonological and orthographic networks. PLoS ONE 2022, 17, e0274617. [Google Scholar] [CrossRef] [PubMed]
- Neergaard, K.D.; Luo, J.; Huang, C.R. Phonological network fluency identifies phonological restructuring through mental search. Sci. Rep. 2019, 9, 15984. [Google Scholar] [CrossRef] [PubMed]
- Kenett, Y.N.; Kenett, D.Y.; Ben-Jacob, E.; Faust, M. Global and Local Features of Semantic Networks: Evidence from the Hebrew Mental Lexicon. PLoS ONE 2011, 6, e23912. [Google Scholar] [CrossRef] [PubMed]
- Xu, Q.; Markowska, M.; Chodorow, M.; Li, P. Modeling Bilingual Lexical Processing Through Code-Switching Speech: A Network Science Approach. Front. Psychol. 2021, 12, 662409. [Google Scholar] [CrossRef] [PubMed]
- Fourtassi, A.; Bian, Y.; Frank, M.C. The Growth of Children’s Semantic and Phonological Networks: Insight From 10 Languages. Cogn. Sci. 2020, 44, e12847. [Google Scholar] [CrossRef] [PubMed]
- Luce, P.A.; Pisoni, D.B. Recognizing Spoken Words: The Neighborhood Activation Model. Ear Heart 1998, 19, 1–36. [Google Scholar] [CrossRef] [PubMed]
- Vitevitch, M.S. The Neighborhood Characteristics of Malapropisms. Lang. Speech 1997, 40, 211–228. [Google Scholar] [CrossRef] [PubMed]
- Vitevitch, M.S. The influence of phonological similarity neighborhoods on speech production. J. Exp. Psychol. Learn. Mem. Cogn. 2002, 28, 735–747. [Google Scholar] [CrossRef] [PubMed]
- Vitevitch, M.S.; Sommers, M.S. The facilitative influence of phonological similarity and neighborhood frequency in speech production in younger and older adults. Mem. Cogn. 2003, 31, 491–504. [Google Scholar] [CrossRef] [PubMed]
- Vitevitch, M.S.; Stamer, M.K. The curious case of competition in Spanish speech production. Lang. Cogn. Process. 2006, 21, 760–770. [Google Scholar] [CrossRef] [PubMed]
- Sadat, J.; Martin, C.D.; Costa, A.; Alario, F.-X. Reconciling phonological neighborhood effects in speech production through single trial analysis. Cogn. Psychol. 2014, 68, 33–58. [Google Scholar] [CrossRef]
- Vitevitch, M.S.; Rodríguez, E. Neighborhood density effects in spoken word recognition in Spanish. J. Multiling. Commun. Disord. 2005, 3, 64–73. [Google Scholar] [CrossRef] [PubMed]
- Arbesman, S.; Strogatz, S.H.; Vitevitch, M.S. Comparative Analysis of Networks of Phonologically Similar Words in English and Spanish. Entropy 2010, 12, 327–337. [Google Scholar] [CrossRef]
- Gruenenfelder, T.M.; Pisoni, D.B. The Lexical Restructuring Hypothesis and Graph Theoretic Analyses of Networks Based on Random Lexicons. J. Speech Lang. Heart Res. 2009, 52, 596–609. [Google Scholar] [CrossRef] [PubMed]
- Turnbull, R.; Peperkamp, S. What governs a language’s lexicon? Determining the organizing principles of phonologi-cal neighbourhood networks. In Complex Networks & Their Applications V; Cherifi, H., Gaito, S., Quattrociocchi, W., Sala, A., Eds.; Complex Networks. Studies in Computational Intelligence; Springer: Cham, Switzerland, 2017; Volume 693. [Google Scholar] [CrossRef]
- Stella, M.; Brede, M. Patterns in the English language: Phonological networks, percolation and assembly models. J. Stat. Mech. Theory Exp. 2015, 2015, P05006. [Google Scholar] [CrossRef]
- Butts, C.T. Revisiting the Foundations of Network Analysis. Science 2009, 325, 414–416. [Google Scholar] [CrossRef] [PubMed]
- Liddell, S. Modality Effects and Conflicting Agendas. In The Study of Signed Languages; Armstrong, D., Karchmer, M., Van Cleve, J., Eds.; Gallaudet University: Washington, DC, USA, 2002; pp. xi–xix. [Google Scholar]
- Dingemanse, M.; Blasi, D.E.; Lupyan, G.; Christiansen, M.H.; Monaghan, P. Arbitrariness, Iconicity, and Systematicity in Language. Trends Cogn. Sci. 2015, 19, 603–615. [Google Scholar] [CrossRef] [PubMed]
- Lepic, R. A usage-based alternative to “lexicalization” in sign language linguistics. Glossa A J. Gen. Linguist. 2019, 4, 23. [Google Scholar] [CrossRef]
- Sevcikova Sehyr, Z.; Caselli, N.; Cohen-Goldberg, A.M.; Emmorey, K. The ASL-LEX 2.0 Project: A database of lexical and phonological properties for 2723 signs in American Sign Language. J. Deaf. Stud. Deaf. Educ. 2021, 26, 263–277. [Google Scholar] [CrossRef] [PubMed]
- Vitevitch, M.S.; Stamer, M.K.; Sereno, J.A. Word Length and Lexical Competition: Longer is the Same as Shorter. Lang. Speech 2008, 51, 361–383. [Google Scholar] [CrossRef] [PubMed]
- Bastian, M.; Heymann, S.; Jacomy, M. Gephi: An Open Source Software for Exploring and Manipulating Networks. Proc. Int. AAAI Conf. Web Soc. Media 2009, 3, 361–362. [Google Scholar] [CrossRef]
- Fortunato, S. Community detection in graphs. Phys. Rep. 2009, 486, 75–174. [Google Scholar] [CrossRef]
- Blondel, V.D.; Guillaume, J.-L.; Lambiotte, R.; Lefebvre, E. Fast unfolding of communities in large networks. J. Stat. Mech. Theory Exp. 2008, 2008, P10008. [Google Scholar] [CrossRef]
- Castro, N.; Vitevitch, M.S. Using Network Science and Psycholinguistic Megastudies to Examine the Dimensions of Phonological Similarity. Lang. Speech 2022, 66, 143–174. [Google Scholar] [CrossRef] [PubMed]
- Greenberg, J.H.; Jenkins, J.J. Studies in the Psychological Correlates of the Sound System of American English. Word 1964, 20, 157–177. [Google Scholar] [CrossRef]
- Landauer, T.K.; Streeter, L.A. Structural differences between common and rare words: Failure of equivalence as-sumptions for theories of word recognition. J. Verbal Learn. Verbal Behav. 1973, 12, 119–131. [Google Scholar] [CrossRef]
- van der Kooij, E. Phonological categories in sign language of the Netherlands. In Utrecht: The Role of Phonetic Implementation and Iconicity; LOT: Warsaw, Poland, 2002. [Google Scholar]
- Vitevitch, M.S.; Castro, N.; Mullin, G.J.D.; Kulphongpatana, Z. The Resilience of the Phonological Network May Have Implications for Developmental and Acquired Disorders. Brain Sci. 2023, 13, 188. [Google Scholar] [CrossRef] [PubMed]
- Vitevitch, M.S.; Mullin, G.J.D. What Do Cognitive Networks Do? Simulations of Spoken Word Recognition Using the Cognitive Network Science Approach. Brain Sci. 2021, 11, 1628. [Google Scholar] [CrossRef] [PubMed]
- Caselli, N.K.; Sehyr, Z.S.; Cohen-Goldberg, A.M.; Emmorey, K. ASL-LEX: A lexical database of American Sign Language. Behav. Res. Methods 2016, 49, 784–801. [Google Scholar] [CrossRef]
- Caselli, N.K.; Cohen-Goldberg, A.M. Lexical access in sign language: A computational model. Front. Psychol. 2014, 5, 428. [Google Scholar] [CrossRef] [PubMed]
- Kenett, Y.N.; Levi, E.; Anaki, D.; Faust, M. The semantic distance task: Quantifying semantic distance with semantic network path length. J. Exp. Psychol. Learn. Mem. Cogn. 2017, 43, 1470–1489. [Google Scholar] [CrossRef] [PubMed]
- Christakis, N.A.; Fowler, J.H. The Spread of Obesity in a Large Social Network over 32 Years. N. Engl. J. Med. 2007, 357, 370–379. [Google Scholar] [CrossRef]
- Vitevitch, M.S.; Goldstein, R.; Johnson, E. Path-length and the misperception of speech: Insights from Network Sci-ence and Psycholinguistics. In Towards a Theoretical Framework for Ana-lyzing Complex Linguistic Networks; Mehler, A., Blanchard, P., Job, B., Banish, S., Eds.; Understanding Complex Systems Series; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Vitevitch, M.S.; Niehorster-Cook, L.; Niehorster-Cook, S. Exploring How Phonotactic Knowledge Can Be Represented in Cognitive Networks. Big Data Cogn. Comput. 2021, 5, 47. [Google Scholar] [CrossRef]
- Vitevitch, M.S.; Aljasser, F.M. Phonotactics in Spoken-Word Recognition. In The Handbook of Speech Perception; Pardo, J.S., Nygaard, L.C., Remez, R.E., Pisoni, D.B., Eds.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2021. [Google Scholar] [CrossRef]
- Liew, C.Y.; Labadin, J.; Kok, W.C.; Eze, M.O. A methodology framework for bipartite network modeling. Appl. Netw. Sci. 2023, 8, 6. [Google Scholar] [CrossRef] [PubMed]
- Levy, O.; Kenett, Y.N.; Oxenberg, O.; Castro, N.; De Deyne, S.; Vitevitch, M.S.; Havlin, S. Unveiling the nature of interaction between semantics and phonology in lexical access based on multilayer networks. Sci. Rep. 2021, 11, 14479. [Google Scholar] [CrossRef] [PubMed]
- Vitevitch, M.S.; Luce, P.A. When words compete: Levels of processing in spoken word perception. Psychol. Sci. 1998, 9, 325–329. [Google Scholar] [CrossRef]
- Vitevitch, M.S.; Luce, P.A. Probabilistic Phonotactics and Neighborhood Activation in Spoken Word Recognition. J. Mem. Lang. 1999, 40, 374–408. [Google Scholar] [CrossRef]
- García Matzar, P.L.; Guaján Pakal, J.O.R. Rukemik ri Kaqchikel Chi’: Gramática Kaqchikel; Editorial Cholsamaj: Guatemala City, Guatemala, 1997. [Google Scholar]
- Rodrigo, L.; Tanaka, M.; Koizumi, M. The role of word order in bilingual speakers’ representation of their two languages: The case of Spanish–Kaqchikel bilinguals. J. Cult. Cogn. Sci. 2019, 4, 275–291. [Google Scholar] [CrossRef]
- Tummons, E.J. Positional Roots in Kaqchikel Maya; University of Kansas: Lawrence, KS, USA, 2010; Available online: http://hdl.handle.net/1808/7426 (accessed on 8 July 2024).
- Haspelmath, M. The indeterminacy of word segmentation and the nature of morphology and syntax. Folia Linguist. 2011, 45. [Google Scholar] [CrossRef]
- Pinker, S. Rules of language. Science 1991, 253, 530–535. [Google Scholar] [CrossRef] [PubMed]
- Battiston, F.; Cencetti, G.; Iacopini, I.; Latora, V.; Lucas, M.; Patania, A.; Young, J.-G.; Petri, G. Networks beyond pair-wise interactions: Structure and dynamics. Phys. Rep. 2020, 874, 1–92. [Google Scholar] [CrossRef]
- Siew, C.S.Q. Community structure in the phonological network. Front. Psychol. 2013, 4, 553. [Google Scholar] [CrossRef] [PubMed]
- Benham, S.; Goffman, L.; Schweickert, R. An Application of Network Science to Phonological Sequence Learning in Children With Developmental Language Disorder. J. Speech Lang. Heart Res. 2018, 61, 2275–2291. [Google Scholar] [CrossRef] [PubMed]
- Stella, M.; Beckage, N.M.; Brede, M.; De Domenico, M. Multiplex model of mental lexicon reveals explosive learning in humans. Sci. Rep. 2018, 8, 2259. [Google Scholar] [CrossRef] [PubMed]
- Stella, M.; Citraro, S.; Rossetti, G.; Marinazzo, D.; Kenett, Y.N.; Vitevitch, M.S. Cognitive modelling of concepts in the mental lexicon with multilayer networks: Insights, advancements, and future challenges. Psychon. Bull. Rev. 2024, 1–24. [Google Scholar] [CrossRef] [PubMed]
- Citraro, S.; Vitevitch, M.S.; Stella, M.; Rossetti, G. Feature-rich multiplex lexical networks reveal mental strategies of early language learning. Sci. Rep. 2023, 13, 1474. [Google Scholar] [CrossRef] [PubMed]
- Kenett, Y.N.; Anaki, D.; Faust, M. Investigating the structure of semantic networks in low and high creative persons. Front. Hum. Neurosci. 2014, 8, 407. [Google Scholar] [CrossRef] [PubMed]
- Martinez, A.E.; Vitevitch, M.S. A cognitive network analysis of semantic associates in monolingual English speakers and learners of Kaqchikel. 2024; unpublished manuscript submitted for publication. [Google Scholar]
- Costa, A.; Foucart, A.; Hayakawa, S.; Aparici, M.; Apesteguia, J.; Heafner, J.; Keysar, B. Your Morals Depend on Language. PLoS ONE 2014, 9, e94842. [Google Scholar] [CrossRef] [PubMed]
- McClelland, J.L.; Elman, J.L. The TRACE model of speech perception. Cogn. Psychol. 1986, 18, 1–86. [Google Scholar] [CrossRef] [PubMed]
- Dell, G.S. The retrieval of phonological forms in production: Tests of predictions from a connectionist model. J. Mem. Lang. 1988, 27, 124–142. [Google Scholar] [CrossRef]
- Beckage, N.; Smith, L.; Hills, T. Small Worlds and Semantic Network Growth in Typical and Late Talkers. PLoS ONE 2011, 6, e19348. [Google Scholar] [CrossRef] [PubMed]
- Carlson, M.T.; Sonderegger, M.; Bane, M. How children explore the phonological network in child-directed speech: A survival analysis of children’s first word productions. J. Mem. Lang. 2014, 75, 159–180. [Google Scholar] [CrossRef] [PubMed]
- Siew, C.S.Q.; Vitevitch, M.S. An investigation of network growth principles in the phonological language network. J. Exp. Psychol. Gen. 2020, 149, 2376–2394. [Google Scholar] [CrossRef] [PubMed]
- Wulff, D.U.; De Deyne, S.; Jones, M.N.; Mata, R.; The Aging Lexicon Consortium. New perspectives on the aging lexicon. Trends Cogn. Sci. 2019, 23, 686–698. [Google Scholar] [CrossRef] [PubMed]
- Castro, N.; Stella, M.; Siew, C.S.Q. Quantifying the Interplay of Semantics and Phonology During Failures of Word Retrieval by People With Aphasia Using a Multiplex Lexical Network. Cogn. Sci. 2020, 44, e12881. [Google Scholar] [CrossRef] [PubMed]
- Citraro, S.; Warner-Willich, J.; Battiston, F.; Siew, C.S.Q.; Rossetti, G.; Stella, M. Hypergraph models of the mental lexicon capture greater information than pairwise networks for predicting language learning. New Ideas Psychol. 2023, 71, 101034. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network Measure | 10+ Features | 12+ Features | English |
|---|---|---|---|
| Network Size (# of nodes) | 2723 | 2723 | 19,340 |
| # of Connections | 270,089 | 55,816 | 31,267 |
| Mean Degree | 198.38 | 40.99 | 3.23 |
| Network Diameter | 5 | 16 | 29 |
| Average Path Length | 2.38 | 4.468 | 6.05 |
| Connected Components | 1 | 53 | 11,285 |
| Giant Component (GC) Size (# of nodes) | N/A | 2664 | 6508 |
| # of Connections in GC | N/A | 55,808 | 29,627 |
| # of Communities | 7 | 62 | 11,309 |
| Modularity (Q) | 0.512 | 0.707 | 0.688 |
| Average Clustering Coefficient | 0.471 | 0.512 | 0.316 |
| Network Measure | Kaqchikel | English |
|---|---|---|
| Network Size (# of nodes) | 303 | 19,340 |
| # of Connections | 707 | 31,267 |
| Mean Degree | 4.67 | 3.23 |
| Network Diameter | 13 | 29 |
| Average Path Length | 5.13 | 6.05 |
| Connected Components | 12 | 11,285 |
| Giant Component (GC) Size (# of nodes) | 288 | 6508 |
| # of Connections in GC | 703 | 29,627 |
| # of Communities | 24 | 11,309 |
| Modularity (Q) | 0.698 | 0.688 |
| Average Clustering Coefficient | 0.348 | 0.316 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vitevitch, M.S.; Martinez, A.E.; England, R. Defining Nodes and Edges in Other Languages in Cognitive Network Science—Moving beyond Single-Layer Networks. Information 2024, 15, 401. https://doi.org/10.3390/info15070401
Vitevitch MS, Martinez AE, England R. Defining Nodes and Edges in Other Languages in Cognitive Network Science—Moving beyond Single-Layer Networks. Information. 2024; 15(7):401. https://doi.org/10.3390/info15070401
Chicago/Turabian StyleVitevitch, Michael S., Alysia E. Martinez, and Riley England. 2024. "Defining Nodes and Edges in Other Languages in Cognitive Network Science—Moving beyond Single-Layer Networks" Information 15, no. 7: 401. https://doi.org/10.3390/info15070401
APA StyleVitevitch, M. S., Martinez, A. E., & England, R. (2024). Defining Nodes and Edges in Other Languages in Cognitive Network Science—Moving beyond Single-Layer Networks. Information, 15(7), 401. https://doi.org/10.3390/info15070401