

Explainable Machine Learning Method for Aesthetic Prediction of Doors and Home Designs
 , , and
, , and 
Abstract
1. Introduction
2. Applied Machine Learning Methodology
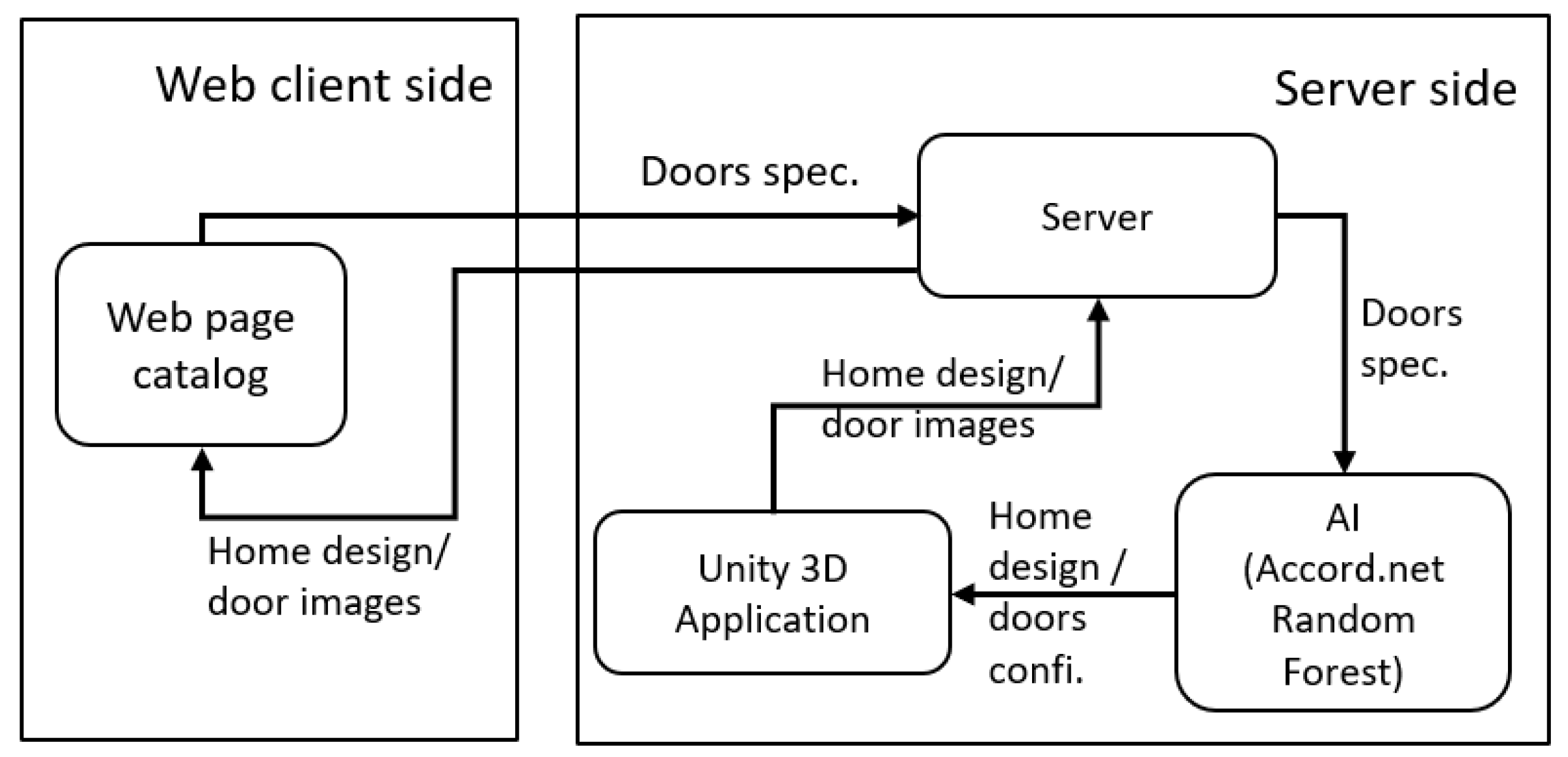
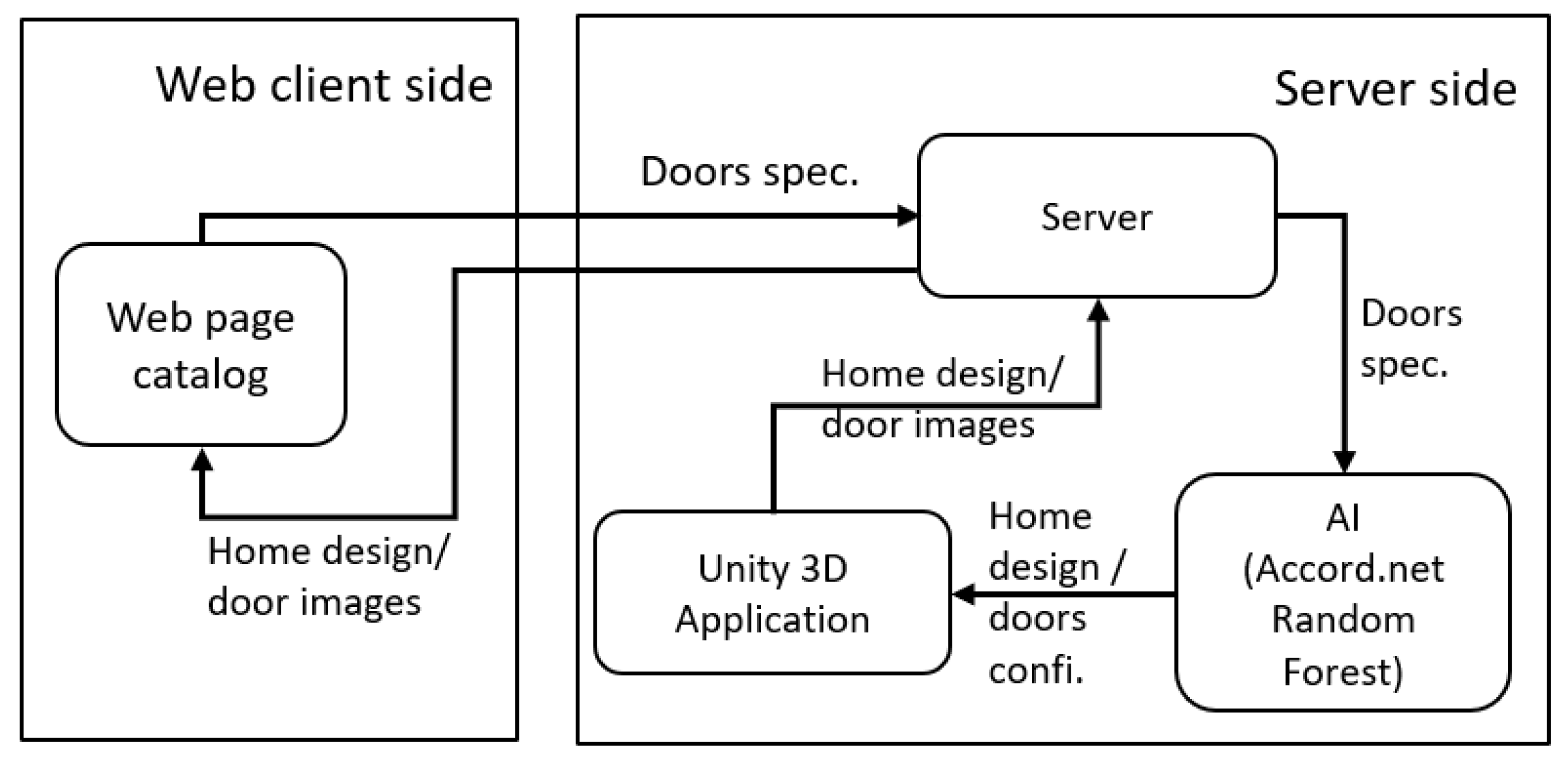
2.1. Web Client–Server Architecture
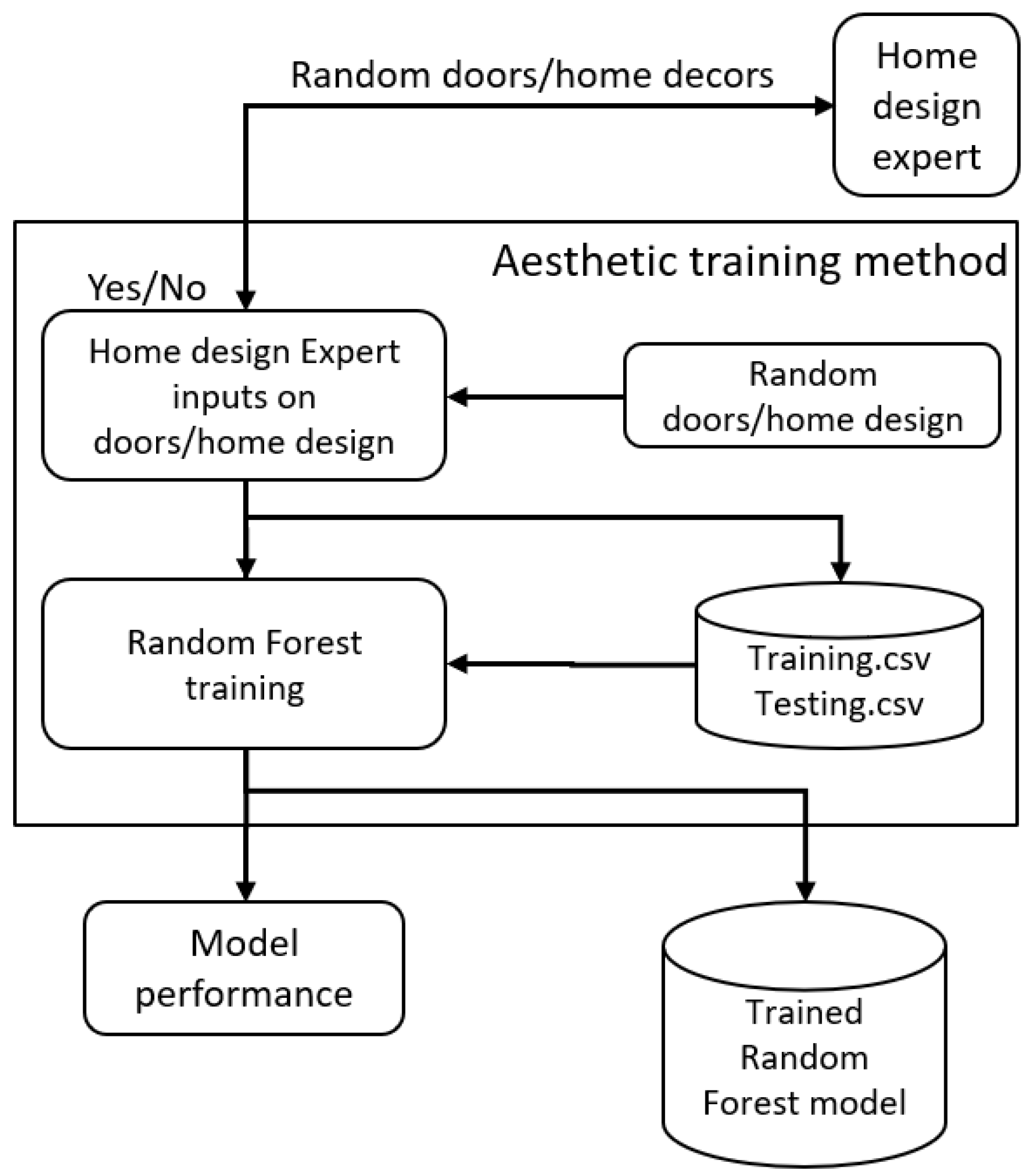
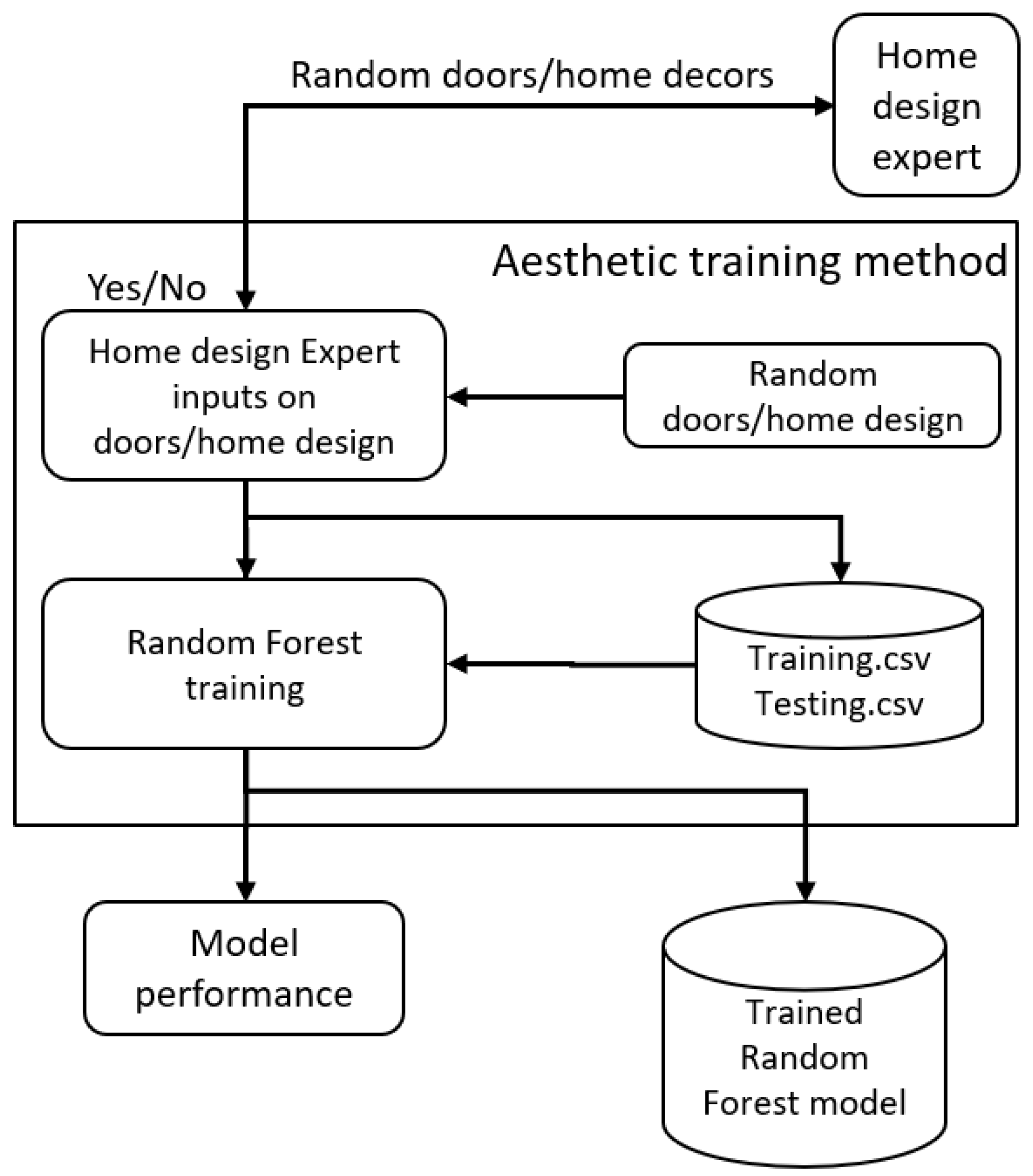
2.2. Training Module
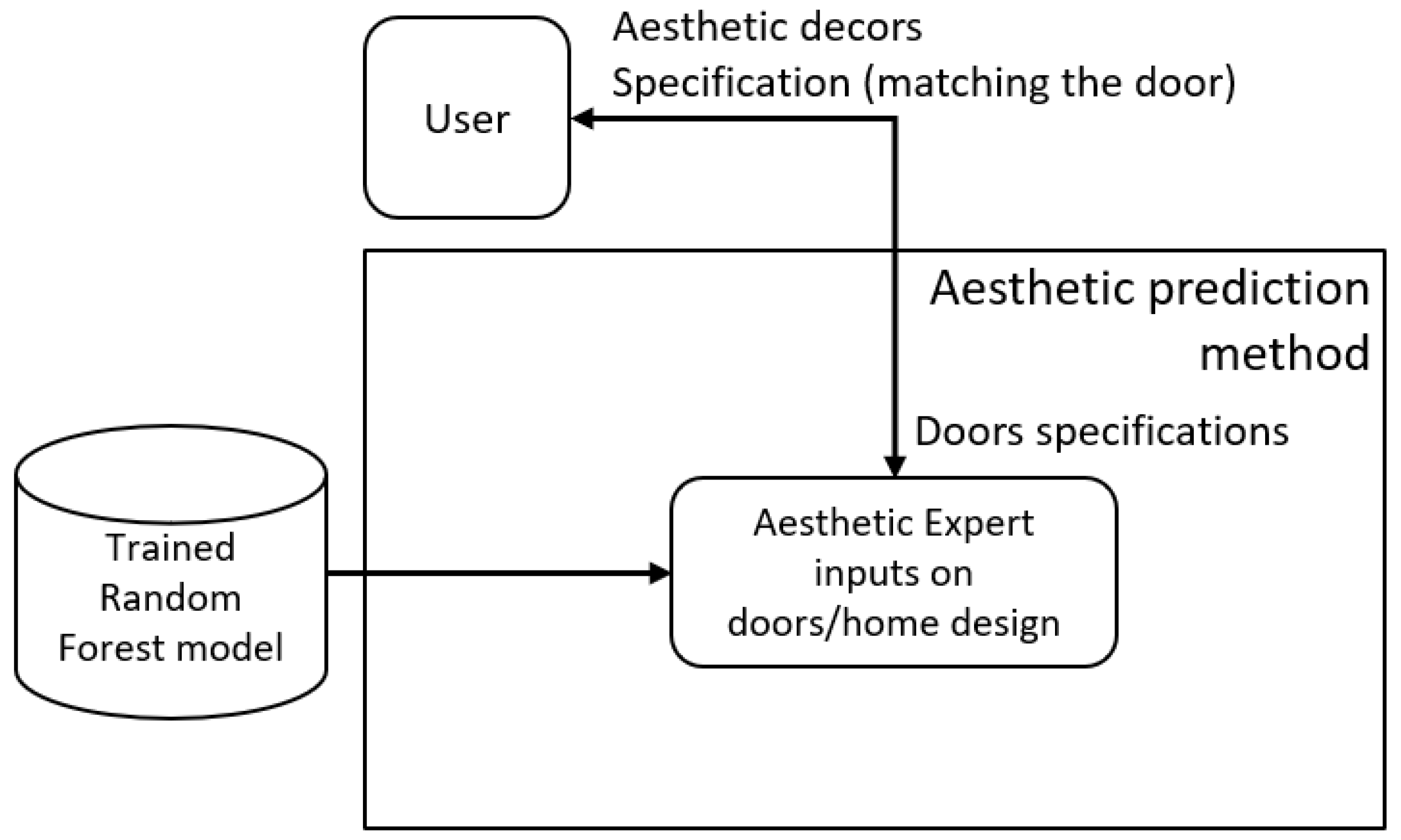
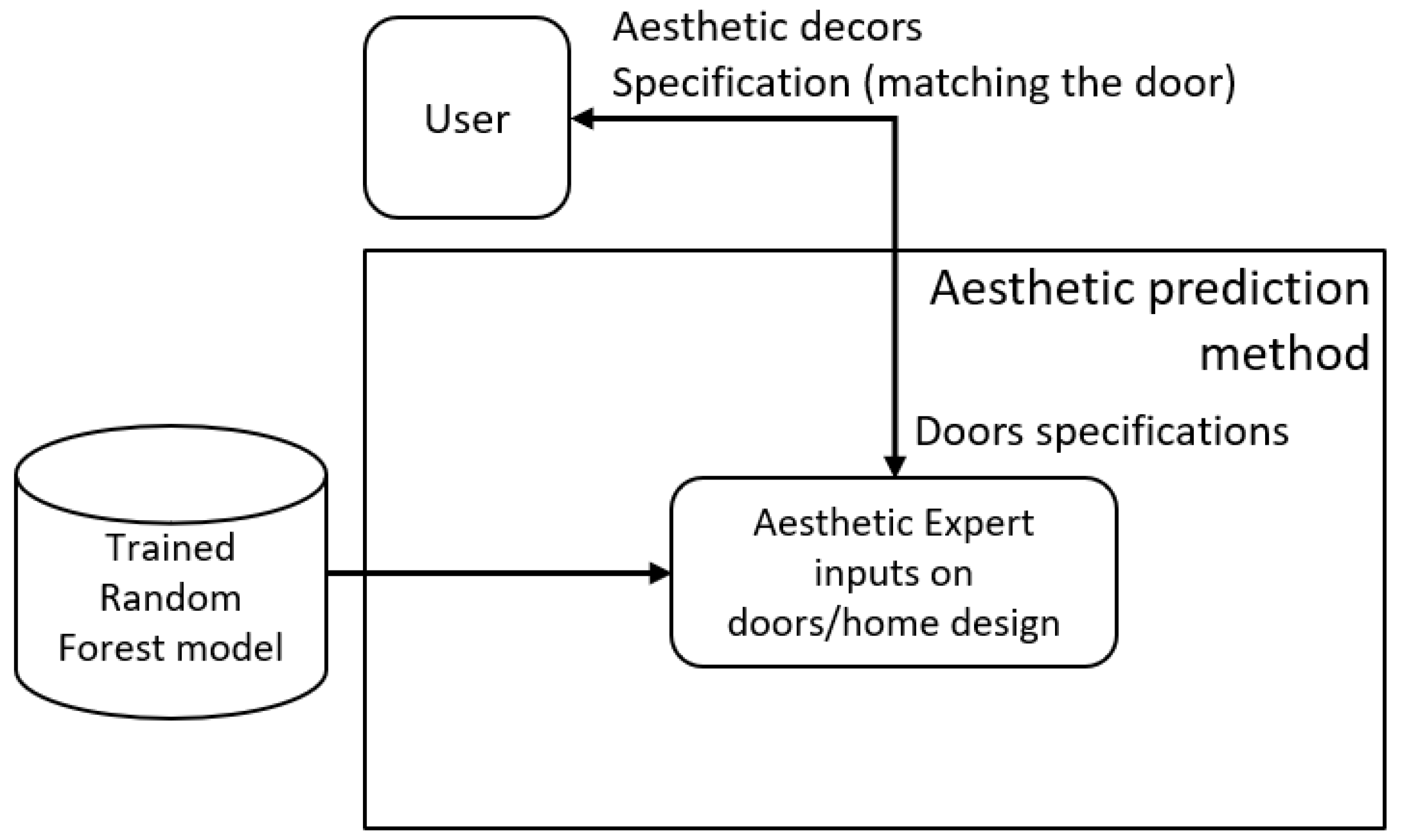
2.3. Prediction Module
3. Results
3.1. Aesthetic Prediction
3.2. Explaining the Results with the Framework
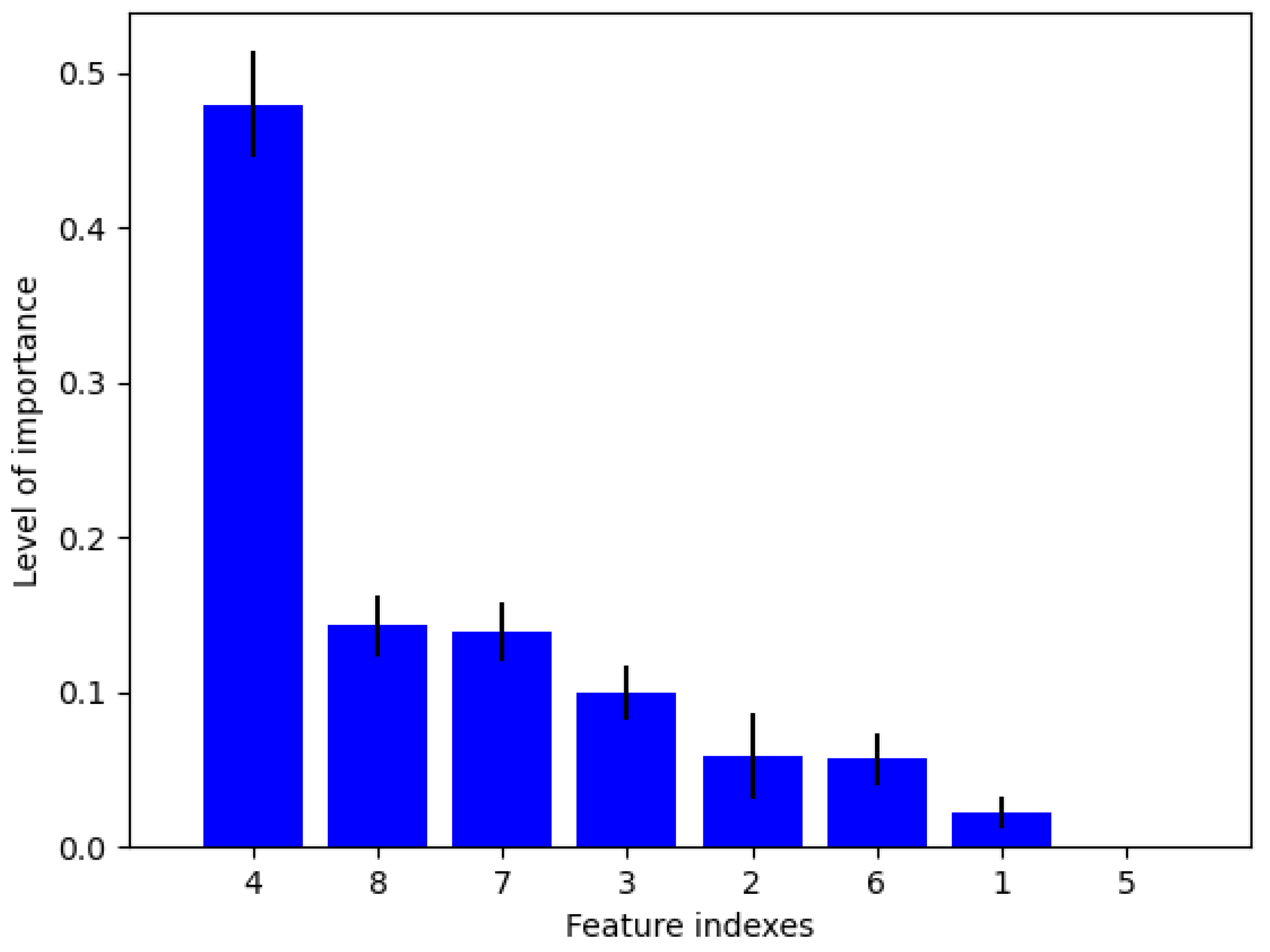
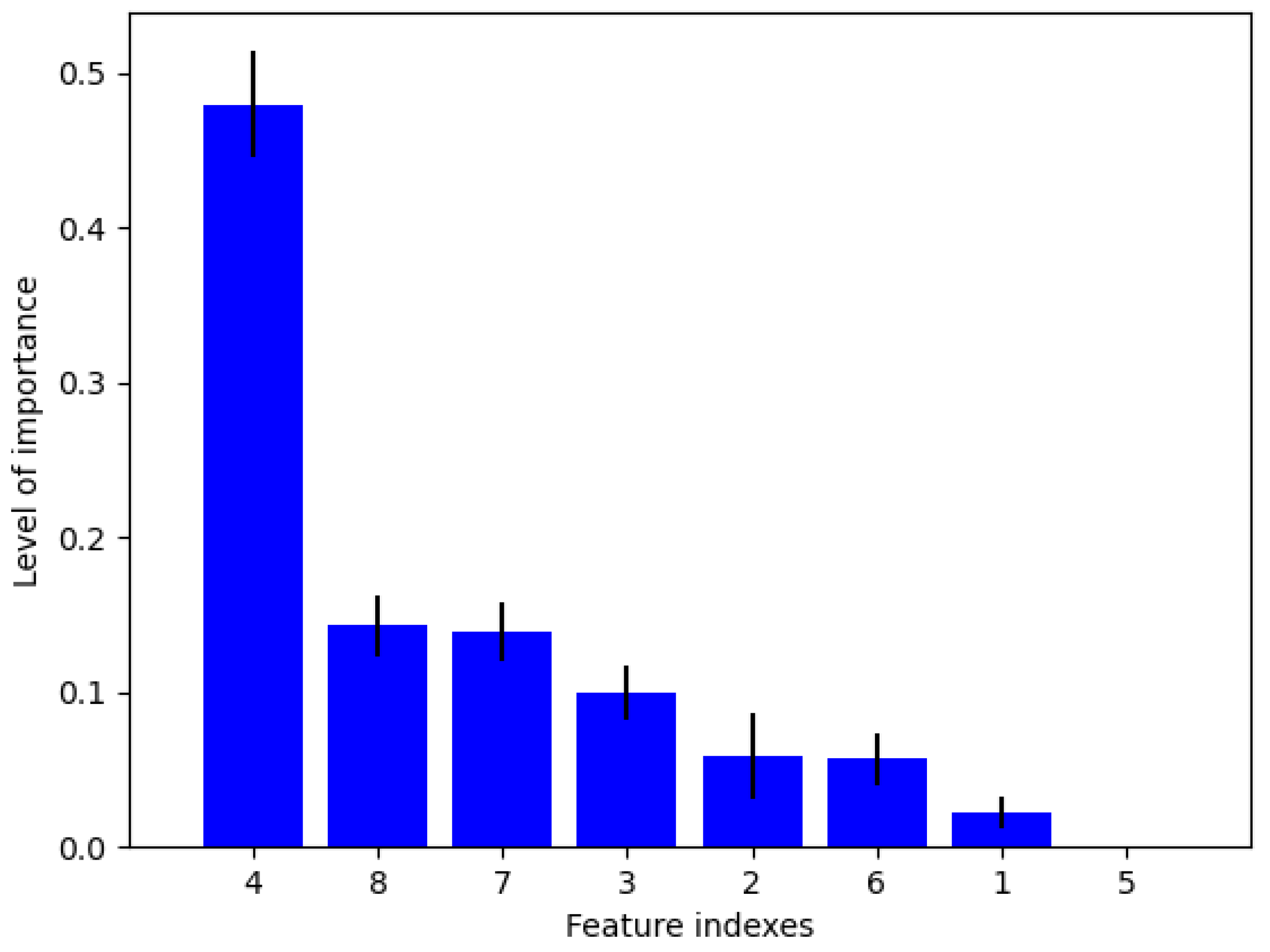
3.2.1. Feature Importance
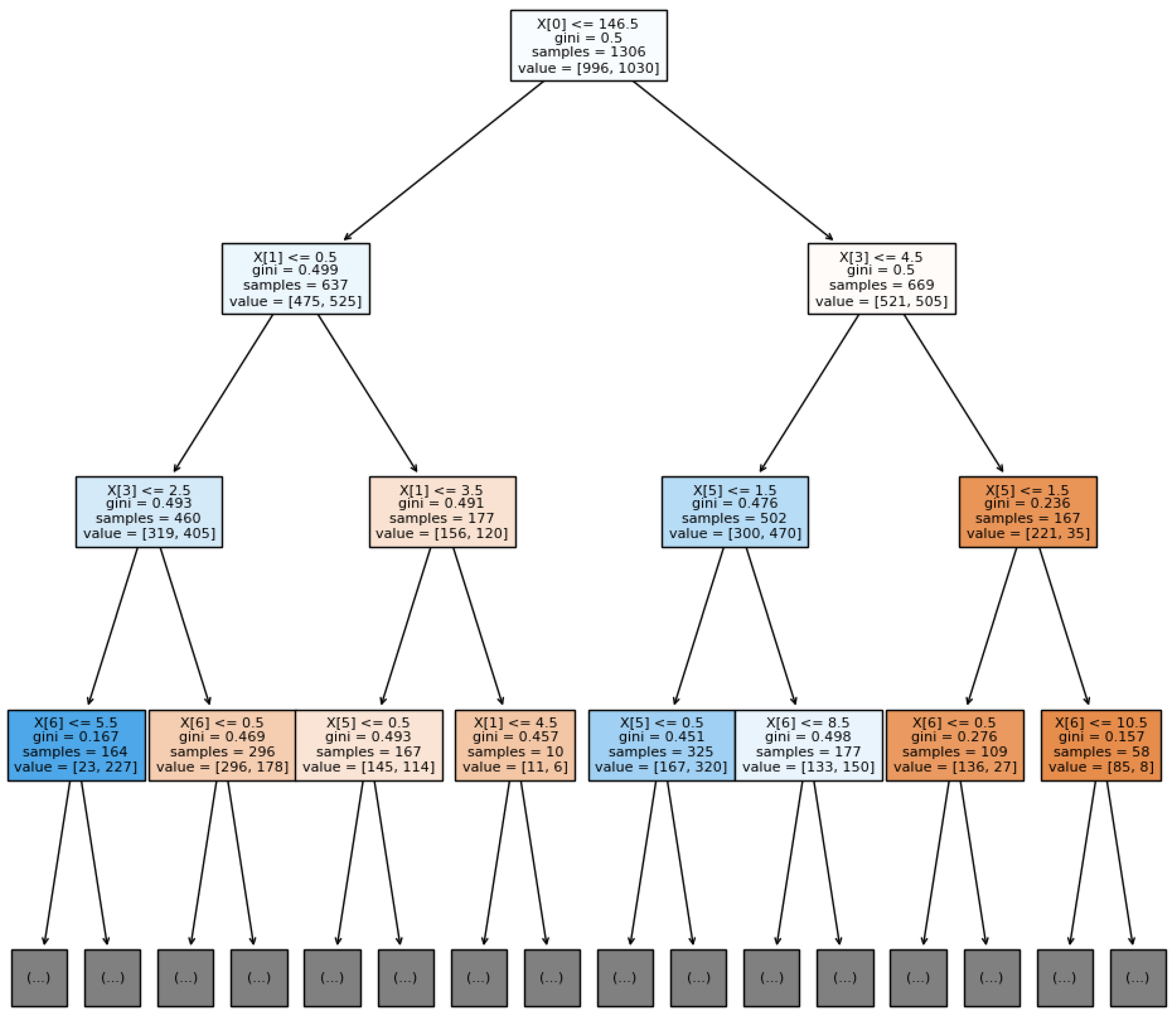
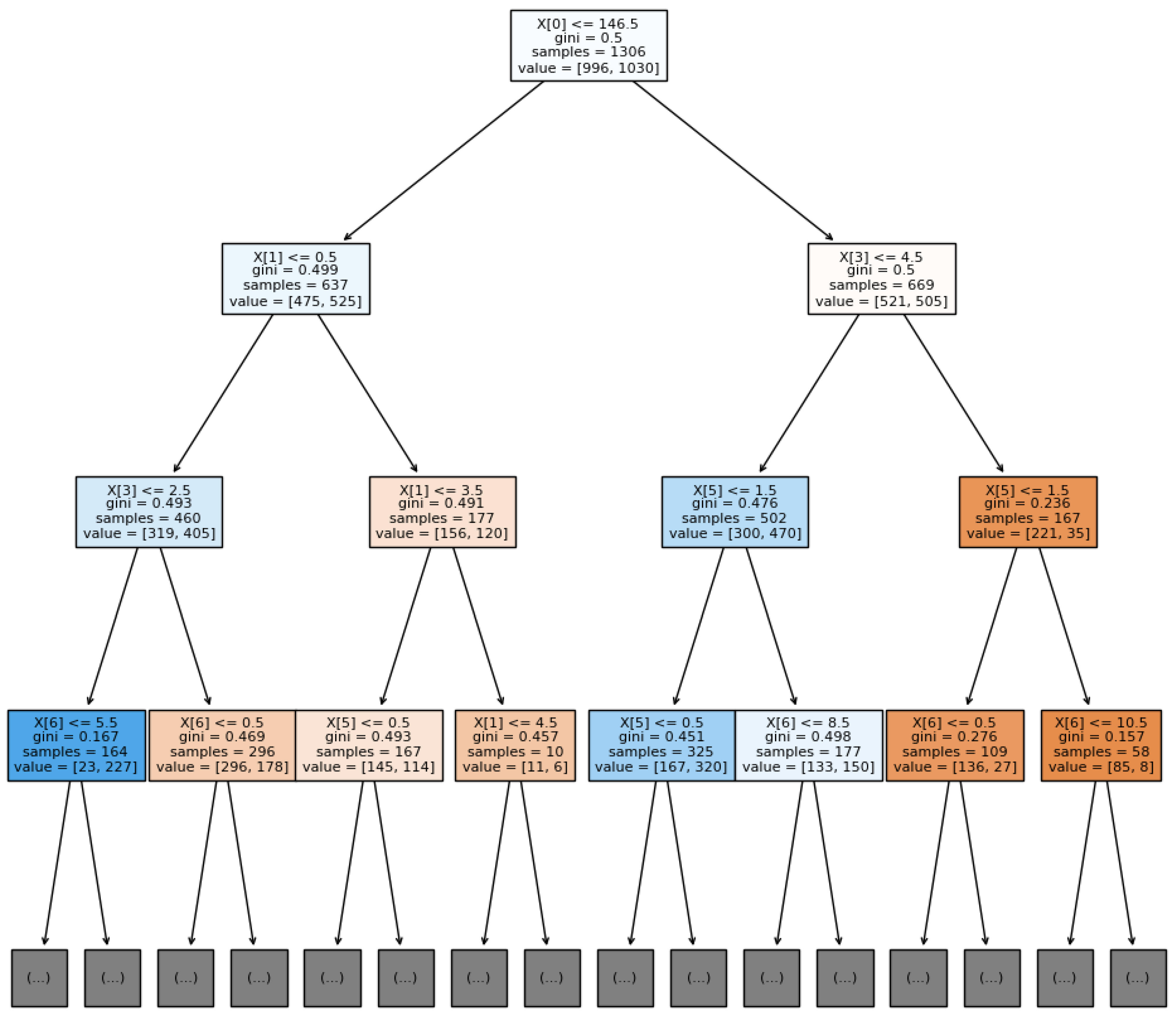
3.2.2. Decision Tree
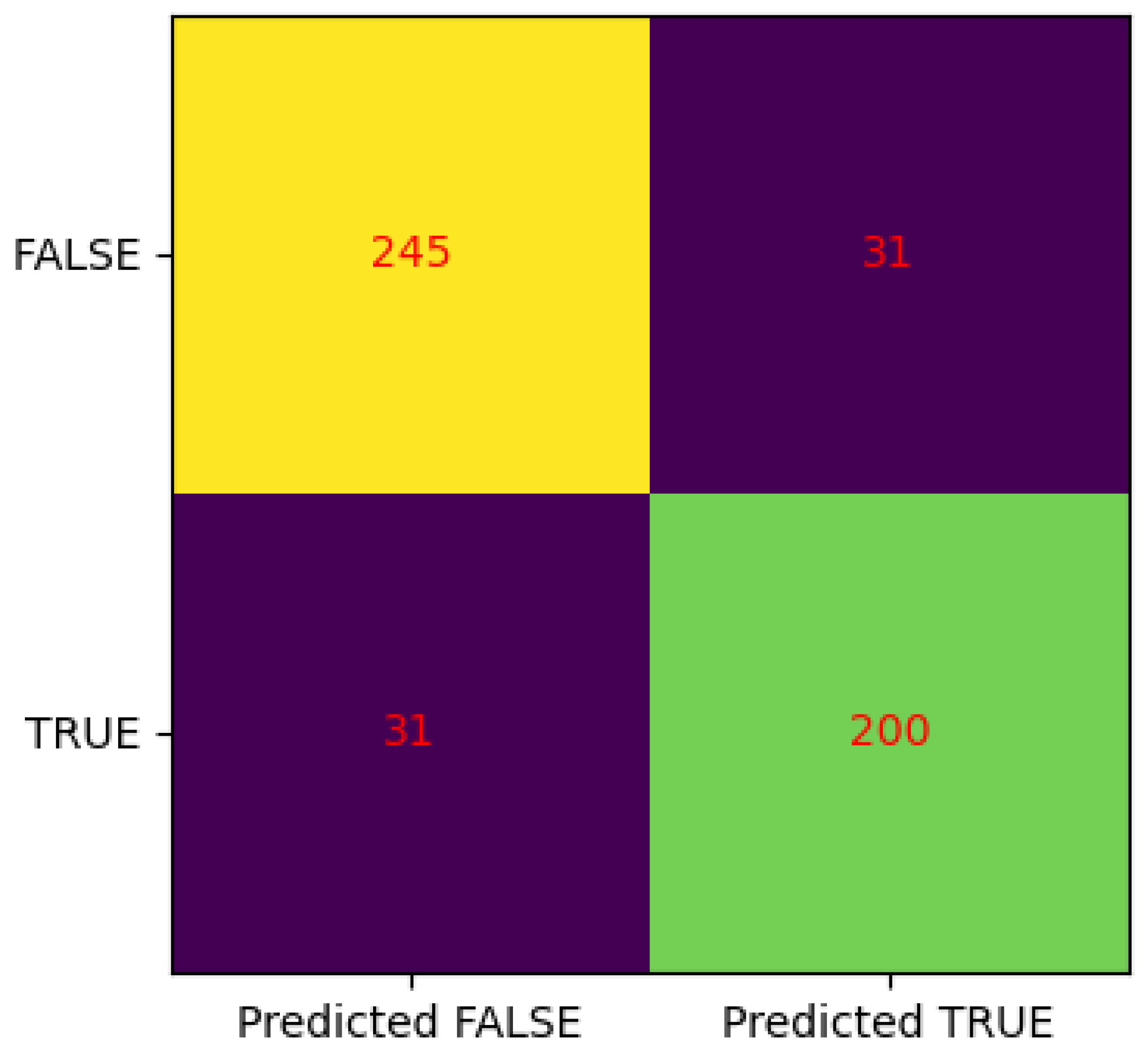
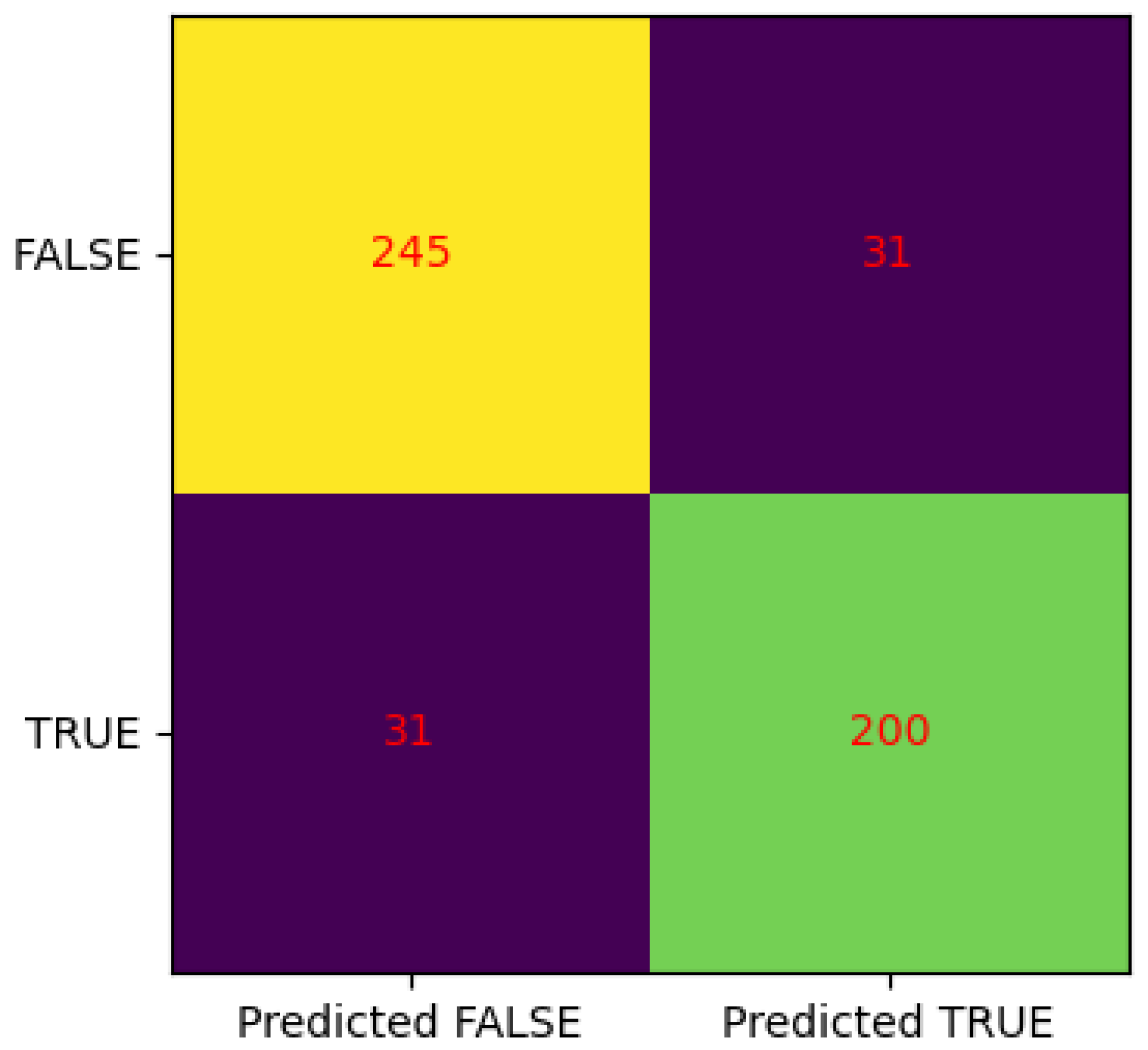
3.2.3. Confusion Matrix
- True Positive (TP): The model correctly predicted the positive class and the actual class was also positive. In this case, the count was 200.
- True Negative (TN): The model correctly predicted the negative class and the actual class was also negative. The count was 245 for this scenario.
- False Positive (FP): The model incorrectly predicted the positive class but the actual class was negative. There were 31 instances where the model made such false positive predictions.
- False Negative (FN): The model incorrectly predicted the negative class but the actual class was positive. Similar to false positives, there were 31 instances where the model made false negative predictions.
3.2.4. Explanation Text
A random forest algorithm is an ensemble machine learning method used for classification and regression tasks. The method involves constructing multiple decision trees at training time and combining their predictions to obtain a final output. Random forest classifiers work by constructing decision trees based on randomly selected subsets of the input features and training data, thus reducing the variance and overfitting issues common in single decision tree models. The final output of the random forest classifier is determined by averaging or voting the predictions of the individual decision trees. The algorithm has gained popularity due to its high accuracy, robustness, and ease of use. It is suitable for various applications such as image classification, fraud detection, and stock market prediction.
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| Artificial Intelligence for Automated Indexes | |
| GHG | Greenhouse Gases |
| MSDLM | Multi-Scene Deep Learning Model |
| NLP | Natural Language Processing |
| RF | Random Forest |
References
- Zhang, Z.; Ban, J. Aesthetic Evaluation of Interior Design Based on Visual Features. Int. J. Mob. Comput. Multimed. Commun. 2022, 13, 1–12. [Google Scholar] [CrossRef]
- Yu, L.; Chung, W. Analysis of Material and Craft Aesthetics Characteristics of Arts and Crafts Works Based on Computer Vision. J. Exp. Nanosci. 2023, 18, 2174693. [Google Scholar] [CrossRef]
- Ataer-Cansizoglu, E.; Liu, H.; Weiss, T.; Mitra, A.; Dholakia, D.; Choi, J.W.; Wulin, D. Room Style Estimation for Style-Aware Recommendation. In Proceedings of the 2019 IEEE International Conference on Artificial Intelligence and Virtual Reality (AIVR), San Diego, CA, USA, 9–11 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 267–2673. [Google Scholar] [CrossRef]
- Lindenthal, T.; Johnson, E.B. Machine Learning, Architectural Styles and Property Values. J. Real Estate Financ. Econ. 2021, 1–32. [Google Scholar] [CrossRef]
- Wang, W.; Zhao, M.; Wang, L.; Huang, J.; Cai, C.; Xu, X. A Multi-Scene Deep Learning Model for Image Aesthetic Evaluation. Signal Process. Image Commun. 2016, 47, 511–518. [Google Scholar] [CrossRef]
- Biau, G.; Scornet, E. A random forest guided tour. Test 2016, 25, 197–227. [Google Scholar] [CrossRef]
- Gulea, T. How not to Use Random Forest. 2019. Available online: https://medium.com/turo-engineering/how-not-to-use-random-forest-265a19a68576 (accessed on 20 February 2024).
- Paul, A.; Mukherjee, D.P.; Das, P.; Gangopadhyay, A.; Chintha, A.R.; Kundu, S. Improved Random Forest for Classification. IEEE Trans. Image Process. 2018, 27, 4012–4024. [Google Scholar] [CrossRef] [PubMed]
- Chang, Y.; Li, W.; Yang, Z. Network Intrusion Detection Based on Random Forest and Support Vector Machine. In Proceedings of the 2017 IEEE International Conference on Computational Science and Engineering (CSE) and IEEE International Conference on Embedded and Ubiquitous Computing (EUC), Guangzhou, China, 21–24 July 2017; Volume 1, pp. 635–638. [Google Scholar] [CrossRef]
- Dessureault, J.S.; Massicotte, D. AI2: A Novel Explainable Machine Learning Framework Using an NLP Interface. In Proceedings of the 2023 8th International Conference on Machine Learning Technologies (ICMLT), New York, NY, USA, 10–12 March 2023; pp. 1–7. [Google Scholar] [CrossRef]
- Dessureault, J.S.; Massicotte, D. AI2: The next leap toward native language based and explainable machine learning framework. arXiv 2023, arXiv:cs.LG/2301.03391. [Google Scholar]
- Haas, J.K. A History of the Unity Game Engine. Ph.D. Thesis, Worcester Polytechnic Institute, Worcester, MA, USA, 2014. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Feature Name | Domains |
|---|---|---|
| Description | ||
| (User choices) | ||
| 1. | Door model | (door models) |
| The model of the door. | ||
| 2. | Wood texture | (wood textures) |
| The wood’s essence and its texture. | ||
| 3. | Dyeing color | (dyeing colors) |
| The color of the dye. | ||
| 4. | Paint texture | (paint colors) |
| The color of the paint. | ||
| 5. | Glass texture | (glass textures) |
| The texture of the glass. | ||
| (AI choices) | ||
| 6. | Home design model | “Bathroom”, |
| “Living room”, | ||
| “Bedroom” | ||
| The model of the home design. | ||
| 7. | Home design color 1 | (colors) |
| The first color of the home design. | ||
| 8. | Home design color 2 | (colors) |
| The second color of the home design. | ||
| (Classes for training purposes) | ||
| 9. | The class | “0” (NO), “1” (YES) |
| The class of the data. |
| Dataset | Training Data | Test Data |
|---|---|---|
| 2534 rows | 2026 rows (80%) | 507 rows (20%) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dessureault, J.-S.; Clément, F.; Ba, S.; Meunier, F.; Massicotte, D. Explainable Machine Learning Method for Aesthetic Prediction of Doors and Home Designs. Information 2024, 15, 203. https://doi.org/10.3390/info15040203
Dessureault J-S, Clément F, Ba S, Meunier F, Massicotte D. Explainable Machine Learning Method for Aesthetic Prediction of Doors and Home Designs. Information. 2024; 15(4):203. https://doi.org/10.3390/info15040203
Chicago/Turabian StyleDessureault, Jean-Sébastien, Félix Clément, Seydou Ba, François Meunier, and Daniel Massicotte. 2024. "Explainable Machine Learning Method for Aesthetic Prediction of Doors and Home Designs" Information 15, no. 4: 203. https://doi.org/10.3390/info15040203
APA StyleDessureault, J.-S., Clément, F., Ba, S., Meunier, F., & Massicotte, D. (2024). Explainable Machine Learning Method for Aesthetic Prediction of Doors and Home Designs. Information, 15(4), 203. https://doi.org/10.3390/info15040203