1. Introduction
Whisper, as an informal form of communication, has received much attention from researchers in recent years [
1,
2]. Conveying information by speaking in a low voice can avoid being heard by others, and this form of communication is often used in situations where confidentiality is required or to avoid disturbing others. For example, when people need to communicate credit card information and passwords to a biometric system, they speak in a whisper manner to avoid overhearing the content; in some cases, criminals may use whispered speech in telephone conversations to avoid sharing voiceprints with forensic examiners, and for laryngectomy patients, whispered speech is the only form of vocalization. Compared to neutral speech, whispered speech is characterized by a lack of fundamental frequency [
3], a flat spectral slope [
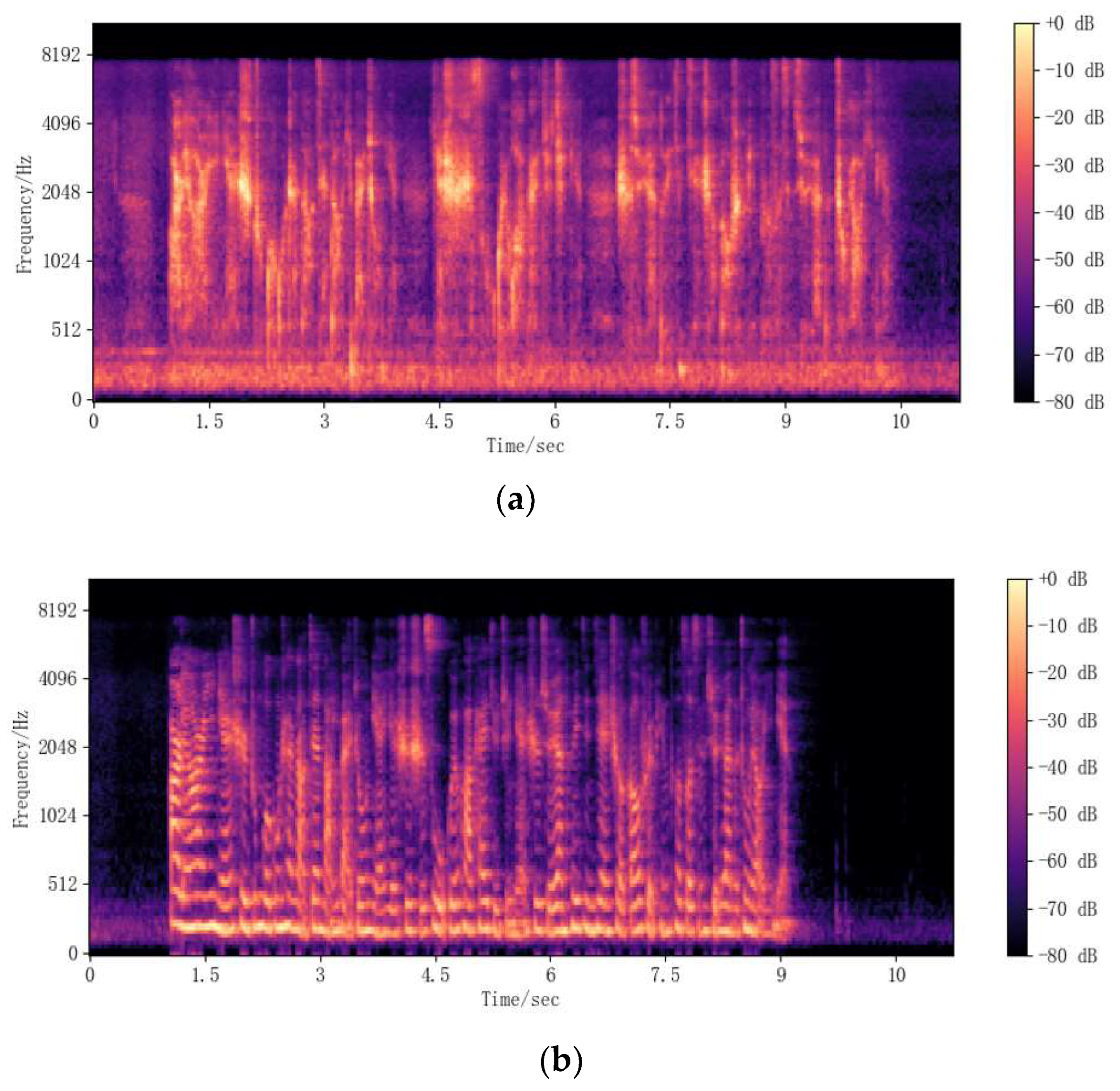
4], a low signal-to-noise ratio, and a greater susceptibility to environmental influences. This makes research in the field of whispering even more challenging.
The current research on whispered speech mainly includes the task of normal/whisper speech classification and detection, whisper-normal conversion [
5], and WSR. The rapid development of Voice Assistant (VA) systems has put forward requirements for classification tasks of whispered and normal speech. Among them, features based on Spectral Information Entropy (SIE) ratios with Gaussian Mixture Model (GMM) classifiers have been proposed for the classification of whispered speech from five different types of speech signals [
6]. Deep Neural Networks (DNNs) and Long Short-Term Memory (LSTM) architectures with logarithmic filter bank energies have been proposed for the frame-level whispered-speech-detection task [
7]. However, the decoding of LSTM takes more time and relies on contextually neighboring frames, which affects real-time decision-making. Furthermore, Convolutional Neural Network (CNN)-based classifiers are able to detect whispered speech at the utterance-level in the presence of unbalanced class learning [
8]. The spectral phase-based features proposed in [
9] can better capture the excitation source information and are effective for whispered speech detection.
For the whisper-normal conversion task, it can be summarized into two main approaches. The first method is the GMM-based conversion method [
10,
11]. This method decomposes the speech signal from the vocoder into specific speech feature parameters. These include speech spectral features, speech fundamental frequency features, and speech non-periodic features. The three features are trained on three GMM whisper conversion models, respectively. Finally, the predicted speech feature parameters are reconstructed into normal speech by the vocoder. However, since the method is based on feature inter-frame mapping and the speech signal is a continuous signal, this results in poor spectral smoothness of the converted speech using this method. The second method mainly starts from DNN [
12]. The whispered speech conversion method based on a Bidirectional Long Short-Term Memory (BiLSTM) network proposed by Meenakshi et al. [
13] is able to handle the feature sequence context information effectively. It has the ability to describe the time–domain relationship of speech signals. The experimental results show that this method generates high-quality speech with better speech listening comfort.
Unlike neutral speech speaker recognition, where enrollment is performed using neutral and/or whispered speech data during WSR, only whispered speech data are used in the test phase. This requires the whisper speaker recognition system to be robust to whispered speech without compromising the performance of the neutral speech speaker recognition system as well.
Current mainstream WSR methods can be broadly classified into three categories. The first class of methods focuses on feature extraction [
14,
15,
16,
17,
18], such as the Mel-scale Frequency Cepstral Coefficient (MFCC), Weighted Instantaneous Frequency, Auditory-inspired Amplitude Modulation Features (AAMFs), Formant-gaps (FoGs) features, and Weighted Modified Linear frequency cepstrum coefficients. Among them, MFCC has been used with GMM and has been used for the speaker recognition task. The method uses maximum a posteriori estimation. The mean hyper-vector of the generalized background model is applied to the speaker frames. From this, the GMM mean hypervector for each speaker is obtained, and a more compact “identity vector” (i-vector) is extracted from this mean hyper-vector. Sarria et al. combined weighted instantaneous frequency features, AAMF, and FoGs features with mean envelope coefficients for WSR. The results show a relative improvement of 3.79% in the effect of FoGs features under whispered speech test conditions, but further research on large corpora is necessary. The second class of methods focuses on feature transformations, such as frequency warping and Feature Mapping (FM) based on DNN [
19,
20]. Naini A R et al. [
21] trained the FM function by optimizing the mean square error between MFCC features and neutral speech features under Dynamic Time Warping (DTW). This method retains only the speaker information and achieves the mapping from whispered speech to neutral speech by maximizing the cosine similarity between the neutral speech and whispered speech i-vectors, achieving a relative improvement of 24%. However, the Mean Squared Error (MSE) does not distinguish between speaker-specific factors, and therefore, MSE-based objective functions are considered inappropriate for WSR. The third category of approaches focuses on the complementary properties of whispered and neutral speech. Sarria-Paja and Falk, in 2017, proposed three new speech feature types to train three different speaker verification systems. Under neutral and whispered speech conditions, the EER improved by 66% and 63%, respectively, compared to the baseline using the traditional MFCC coefficients. In [
22], a new modeling technique was introduced by Vestman et al. This technique involves long-term speech analysis based on the joint utilization of Frequency Domain Linear Prediction and Time-varying Linear Prediction (FDLP-TVLP). In their experiments, they used a corpus of CHAINs to test the speech mismatch condition and demonstrated that the FDLP-TVLP features improved the speaker identification EER by 7–10% over the standard MFCC features.
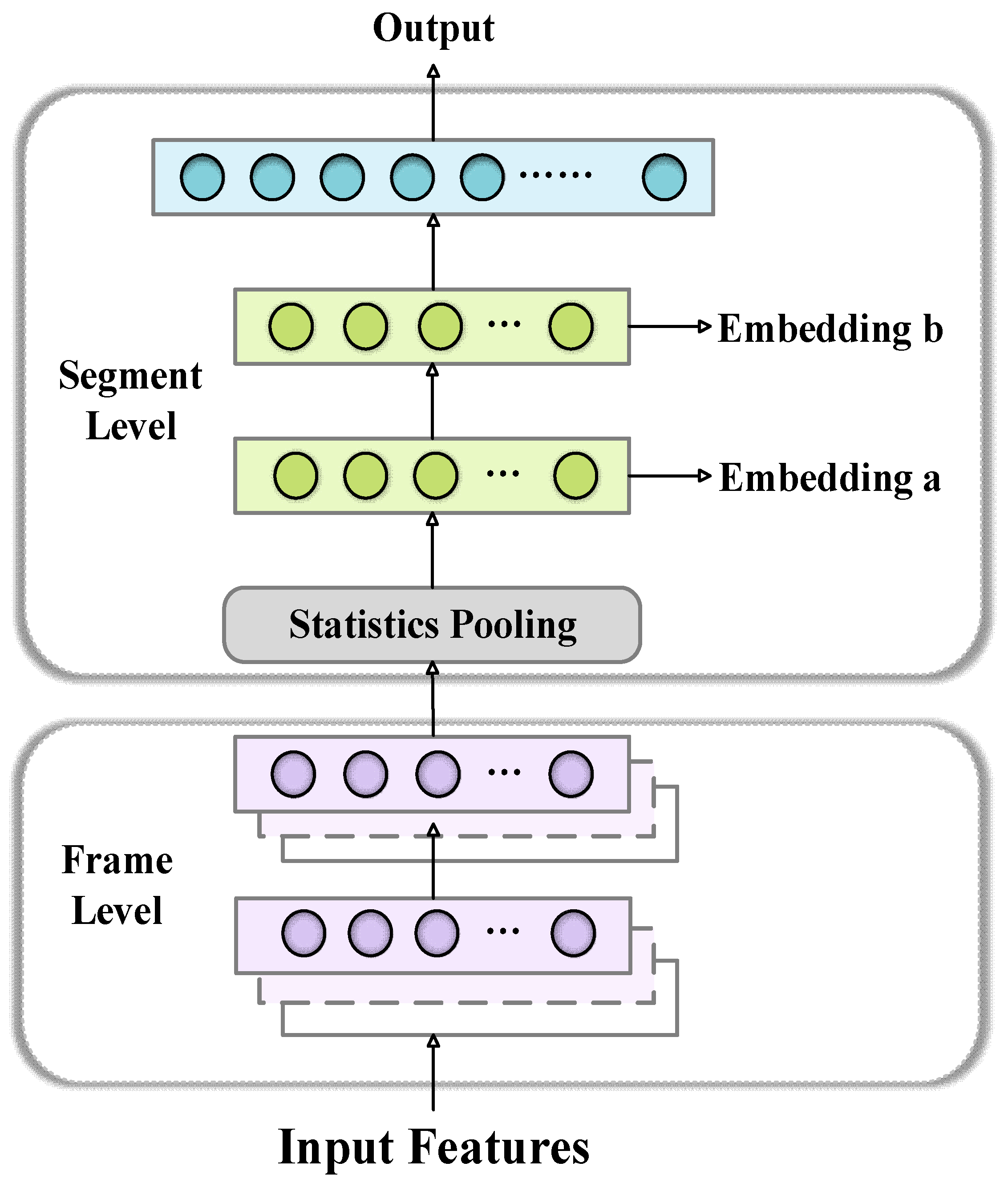
Because of the limited research on WSR, few studies have attempted to explore its relationship with neutral speech speaker recognition. Significant progress has been made in the research on neutral speech speaker recognition. Among them, factor analysis and DNN-embedding-based methods [
23,
24,
25] are considered to be the most advanced in the field of speaker recognition. The mainstream methods are TDNN-based x-vector, ResNet34-based r-vector, and ECAPA-TDNN [
26]-based speaker embedding extraction. Also, since TDNN is a highly competitive model in the field of speaker recognition, it does not require the precise localization of tokens during its training and is able to express the relationship of speech features in the time dimension. Therefore, this network is introduced in the methodology of this paper. Meanwhile, this paper, for the first time, uses the ResNet34 and ECAPA-TDNN model to train the WSR system and compares the effect with the TDNN model to find the most suitable recognition model for whispered speech. Despite the displacement of the low-frequency resonance peaks in whispered speech compared to neutral speech, it also contains a large amount of content and speaker information. Therefore, the feature and embedding extraction methods for neutral speech speaker recognition are instructive for WSR. Transfer learning is a method of transferring knowledge structures from related domains to complete or improve the task in the target domain, which has been widely used in the fields of speech synthesis and target recognition [
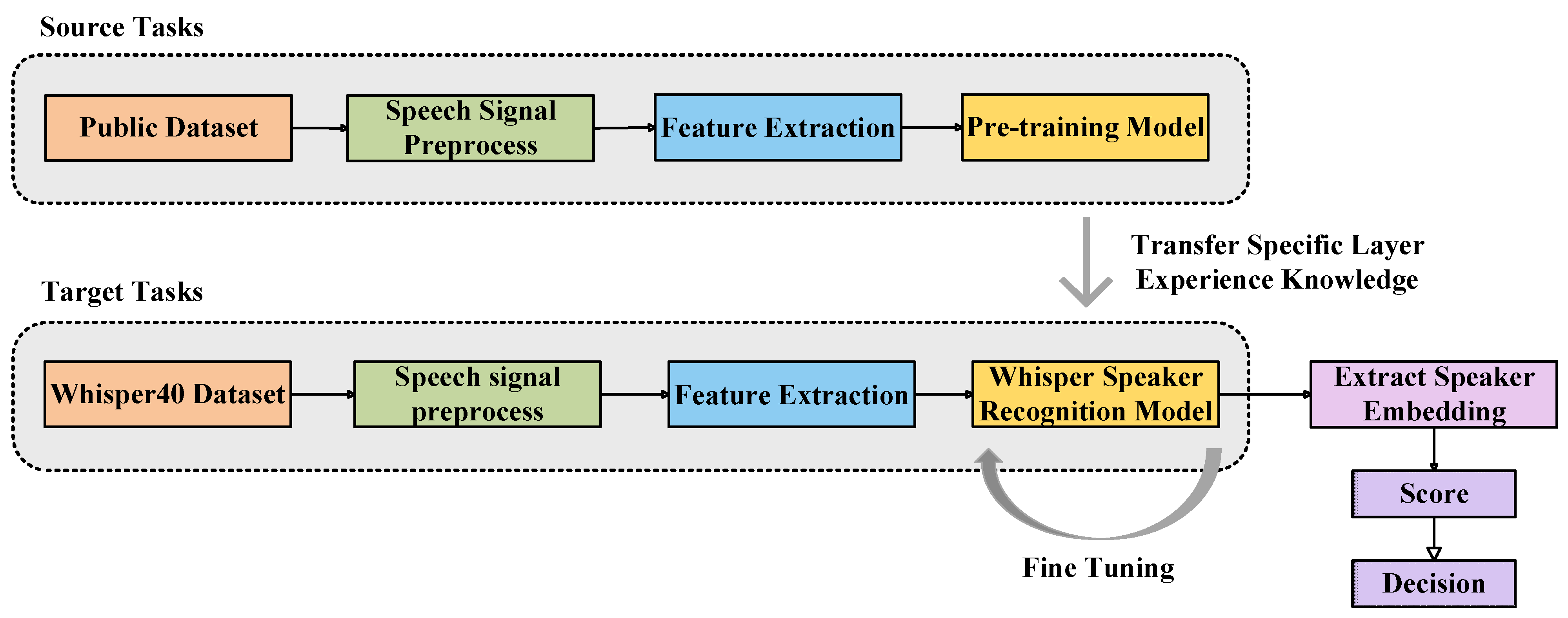
27]. Therefore, in this paper, transfer learning is introduced to use the pre-training specific network layer parameters of TDNN as the initial values of the model for WSR. These parameters are used to initialize and fine-tune the parameters of the model trained on the whisper data in order to improve the accuracy of the WSR.
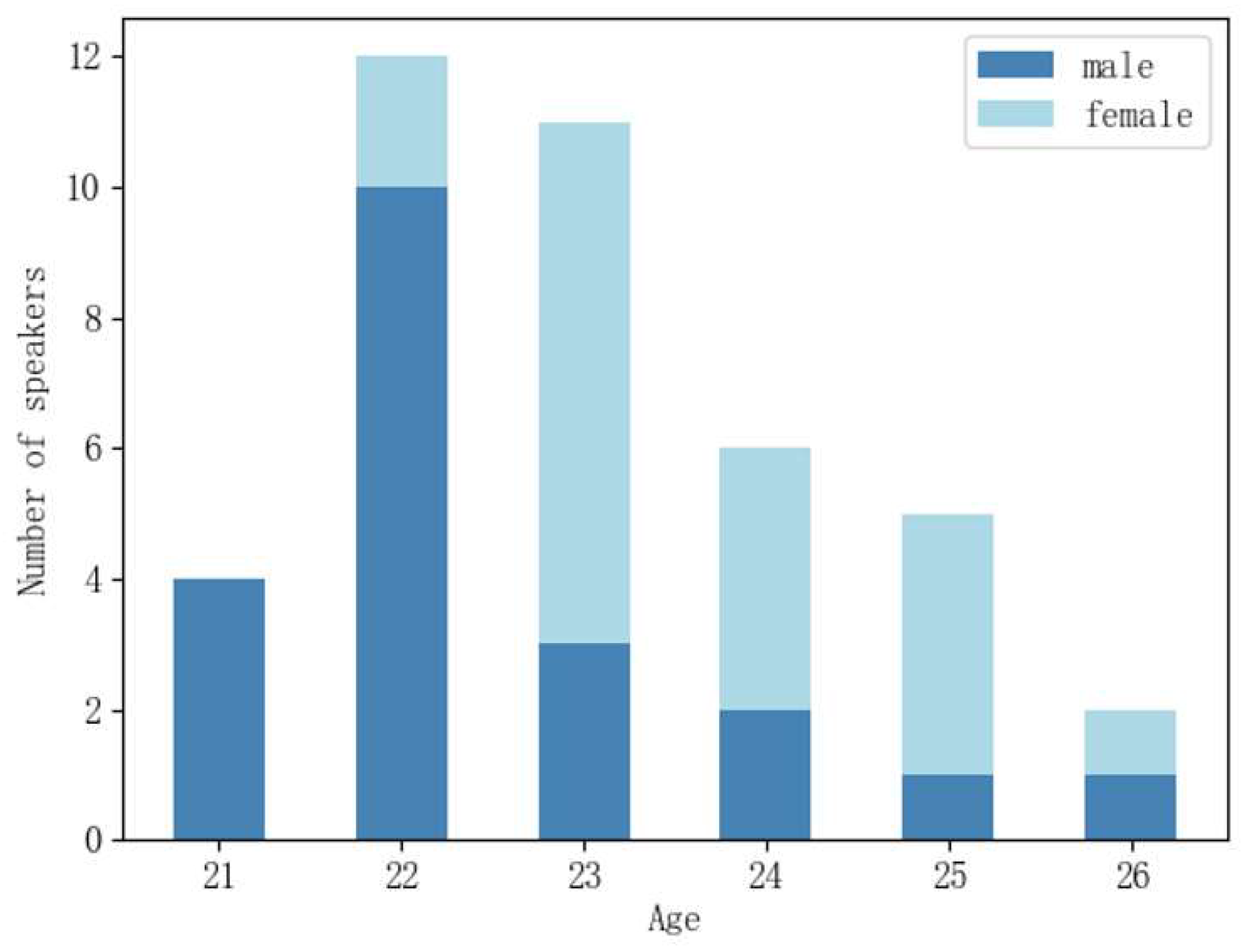
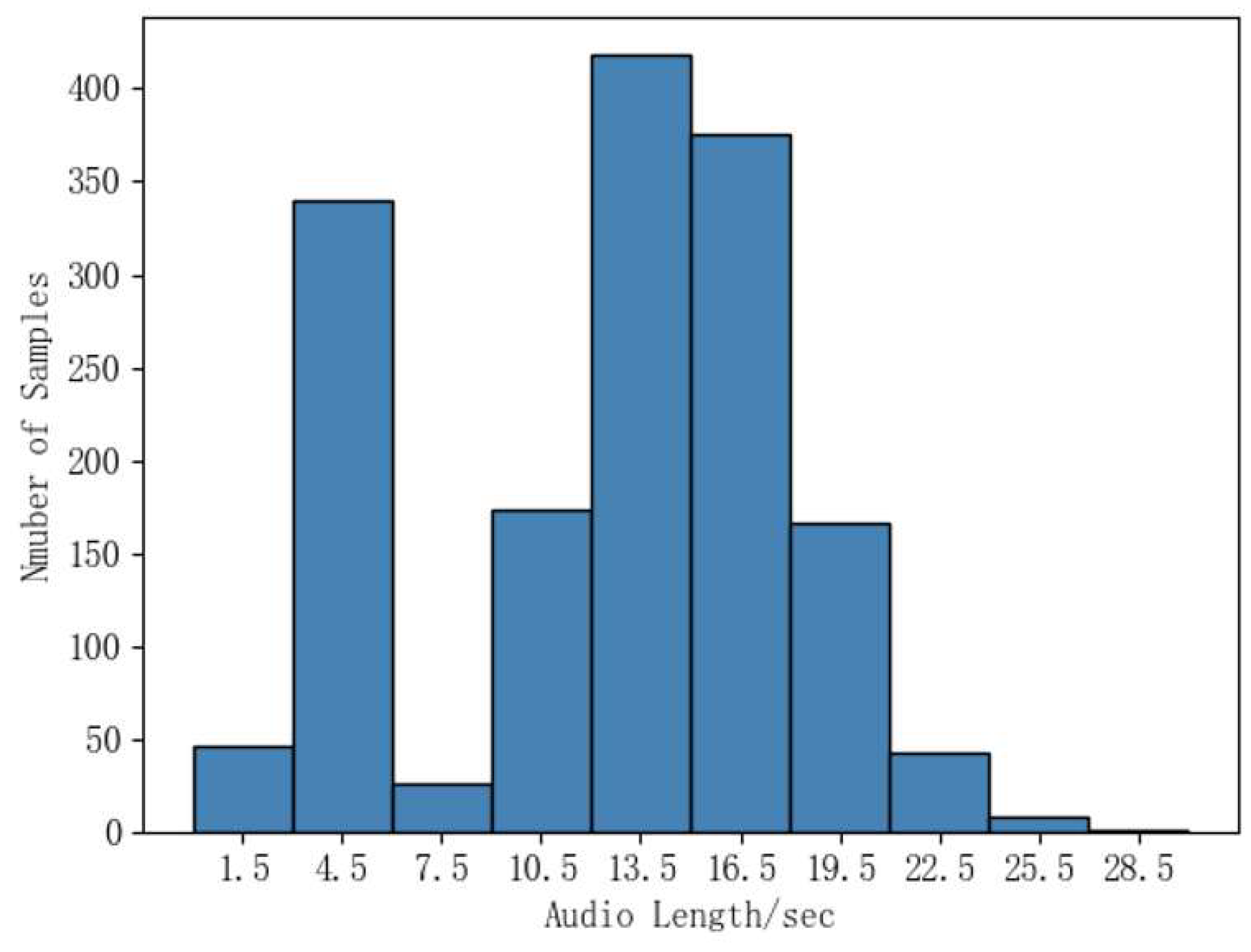
In addition, it is very difficult to introduce advanced DNN-based neutral speech speaker recognition methods into the field of whispered speech due to the lack of a large whisper dataset, as these methods all require large amounts of speaker audio data to build more robust speaker models. Based on this paper, a new whisper dataset, Whisper40, is built, and a WSR system in transfer learning mode is constructed. This dataset consists of 40 people, and each speaker contains neutral speech and whispered speech of the same-text to study the performance of the WSR system across scenarios. Secondly, this paper introduces advanced models in the field of speaker recognition into the WSR system and, at the same time, introduces a new data-augmentation method of audio reverse, as well as same/cross-scene experiments, to further compare the differences between whispered speech and neutral speech. Finally, the small scale of WSR training data makes WSR ineffective. In this paper, based on the idea of transfer learning, the empirical knowledge of specific network layers in the pre-trained model is transferred to the WSR model. The self-collected Whisper40 data and CHAINs data are also utilized for fine-tuning until fitting. The experimental results show that the self-collected Whisper40 dataset is practical, and the adopted data-augmentation method effectively reduces the EER of the WSR system, and the EER of the Chinese WSR after transfer learning is relatively reduced by 27.62%.
The paper is structured as follows. Firstly, the created Whisper40 dataset is compared with existing whisper datasets. Then, we document the collection and organization of Whisper40 and describe the structure of the dataset in detail. Finally, we constructed a WSR system under a transfer learning pattern, which proves that the self-collected dataset has practicality and also shows the importance of the TDNN model in the WSR, as well as the effectiveness of the transfer learning strategy under a small data volume.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}