
Multi-Level Attention Split Network: A Novel Malaria Cell Detection Algorithm


Abstract
1. Introduction
- We introduce the Split Contextual Attention Structure (SPCot) module to incorporate contextual information into our feature extraction network. This module enhances the capability of feature extraction and also reduces the complexity of the model via the introduction of a redundant split convolutional (RSConv).
- An MRFH detection head is proposed, introducing the adaptive matching receptive field to resolve the mismatch issue between the receptive field and the target size.
- By using Performance-aware Approximation of Global Channel Pruning (PAGCP) [7] for pruning our model, we significantly reduces the parameter count of our model at the cost of sacrificing minimal accuracy.
2. Related Work
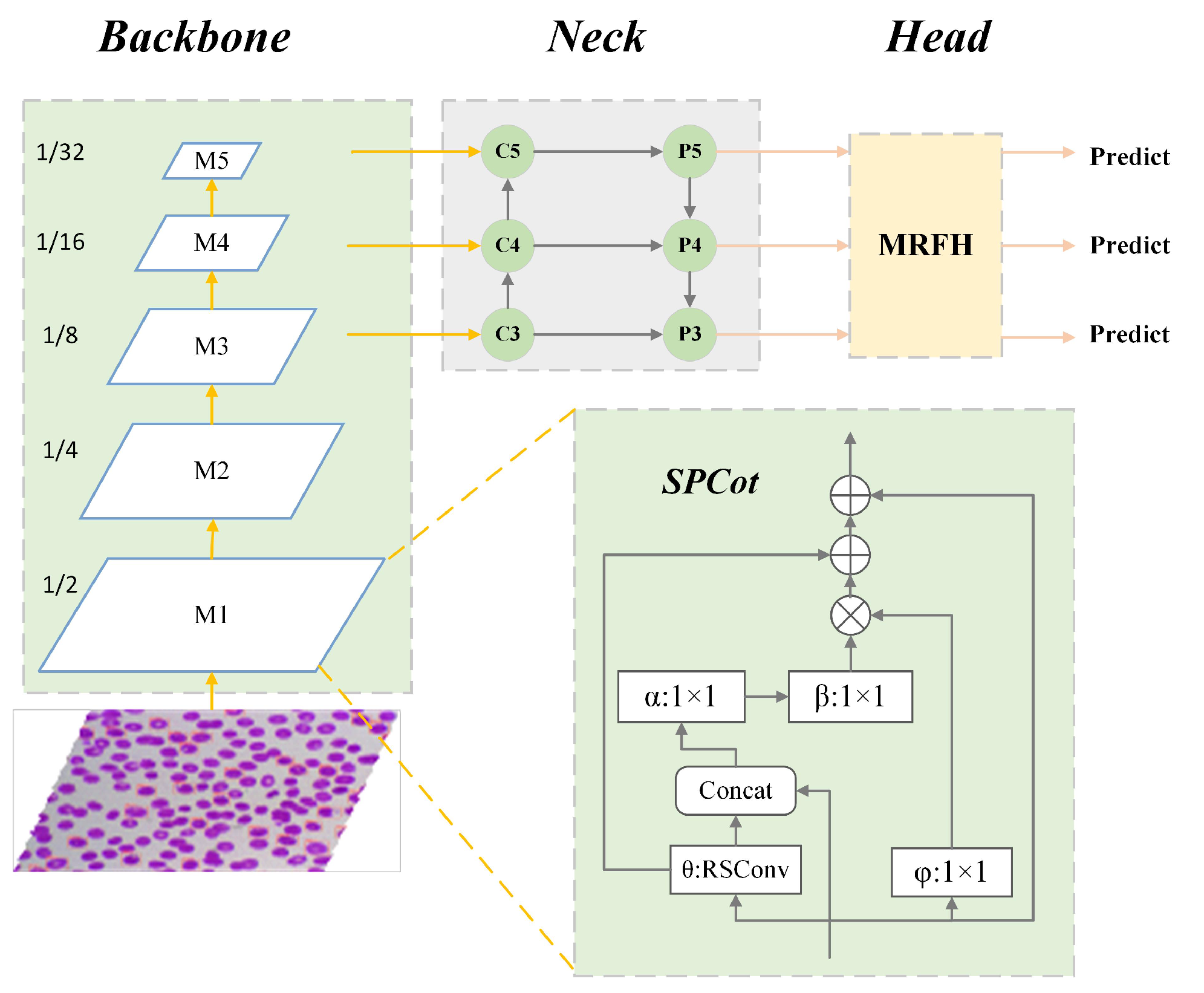
3. MAS-Net
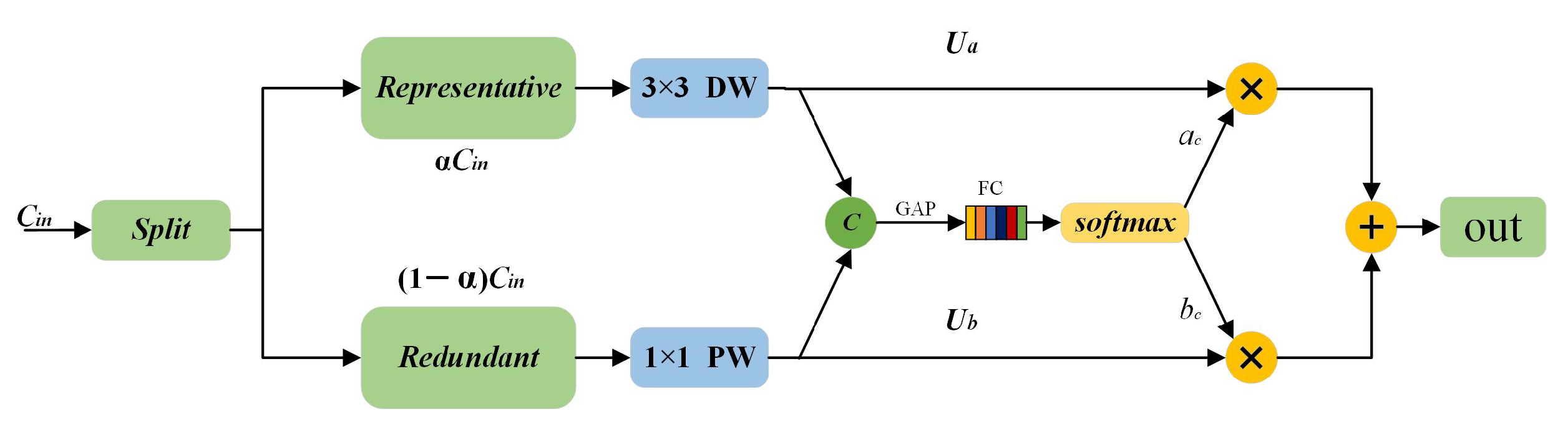
3.1. RSConv
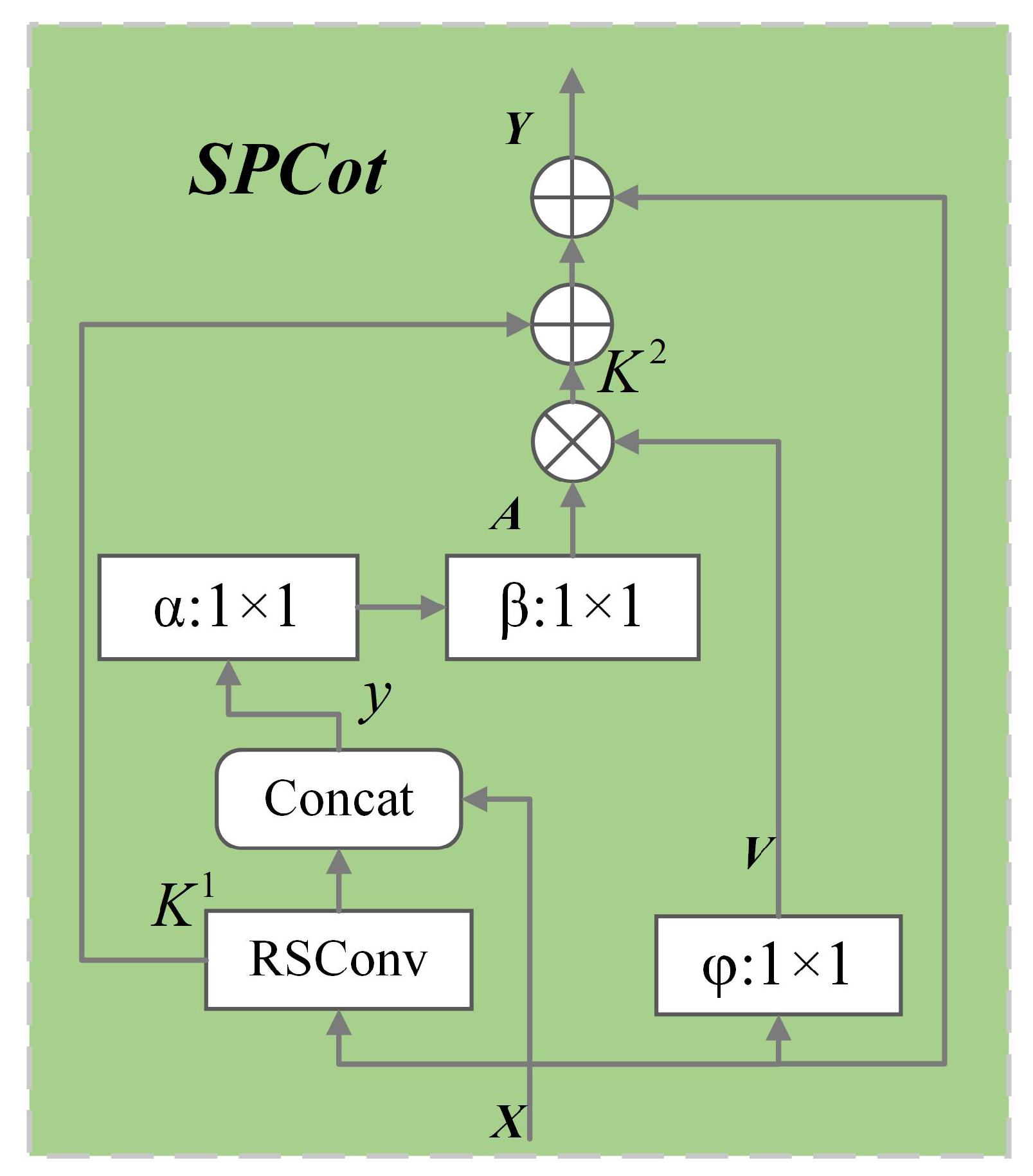
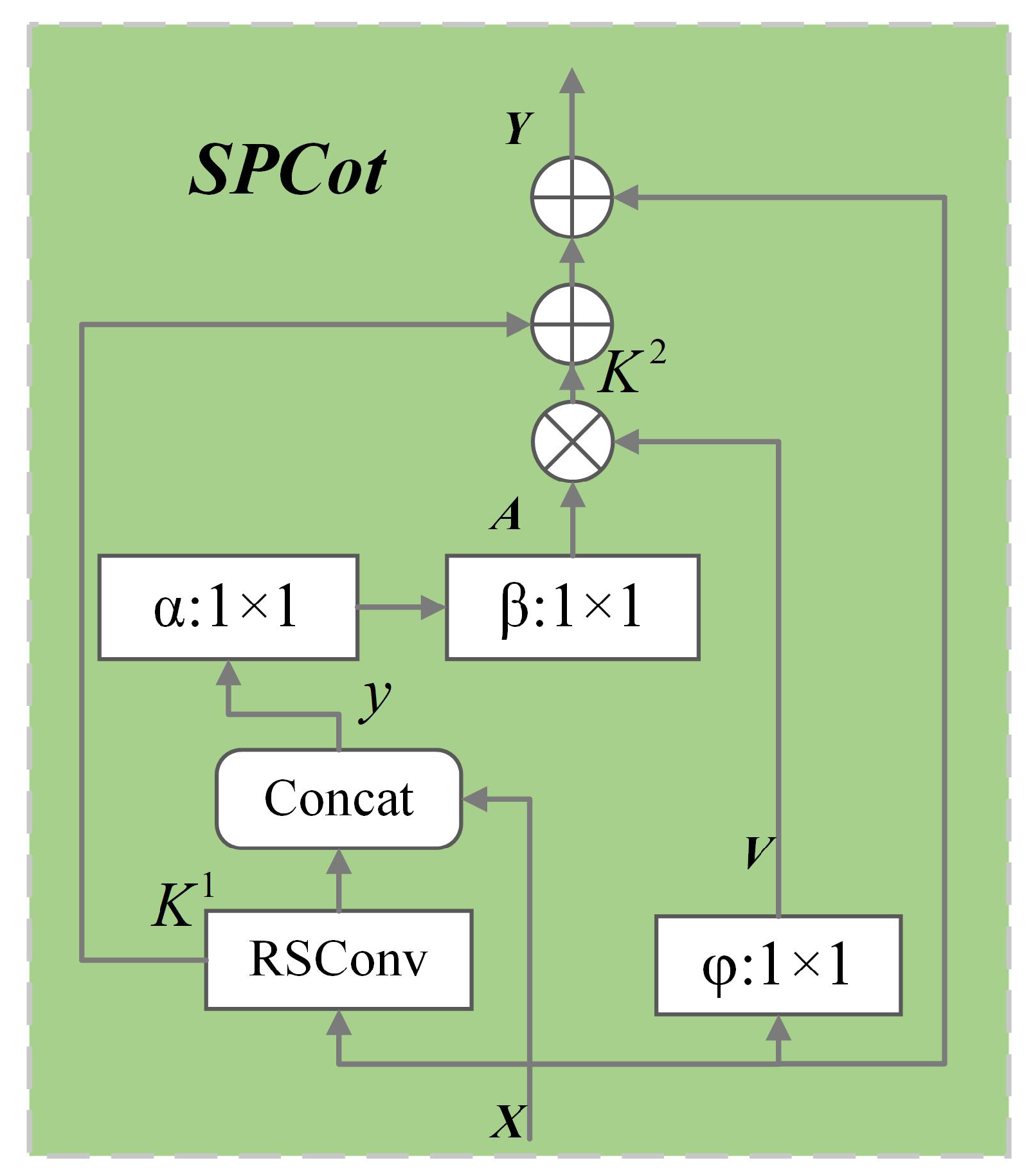
3.2. Split Contextual Attention Structure
| Algorithm 1 Algorithm for self-attention module based on contextual information |
|
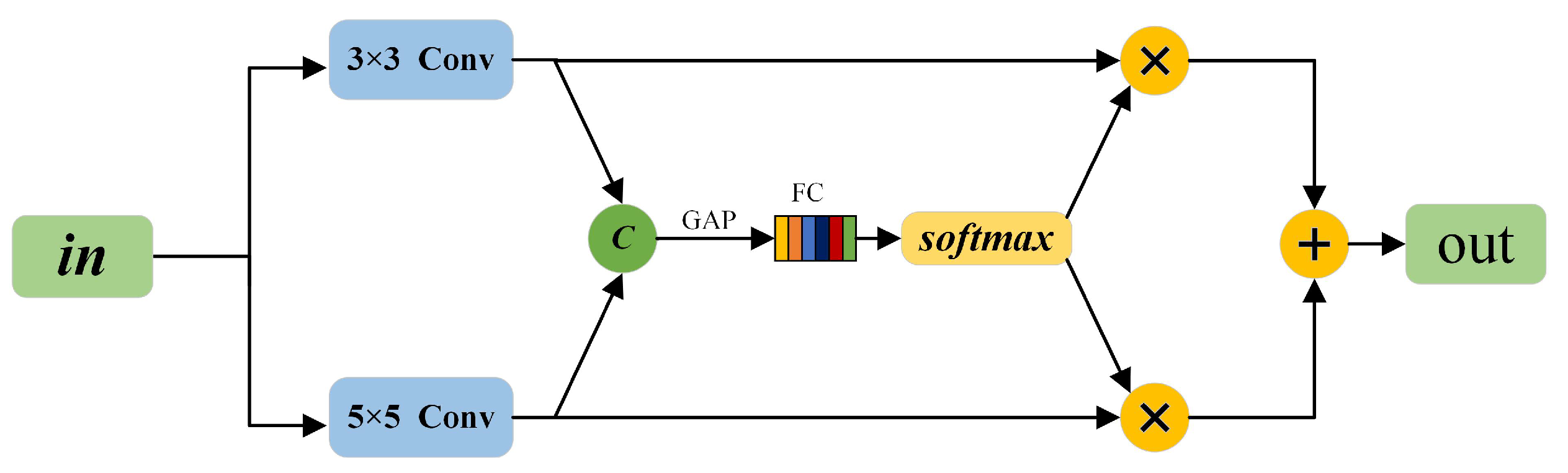
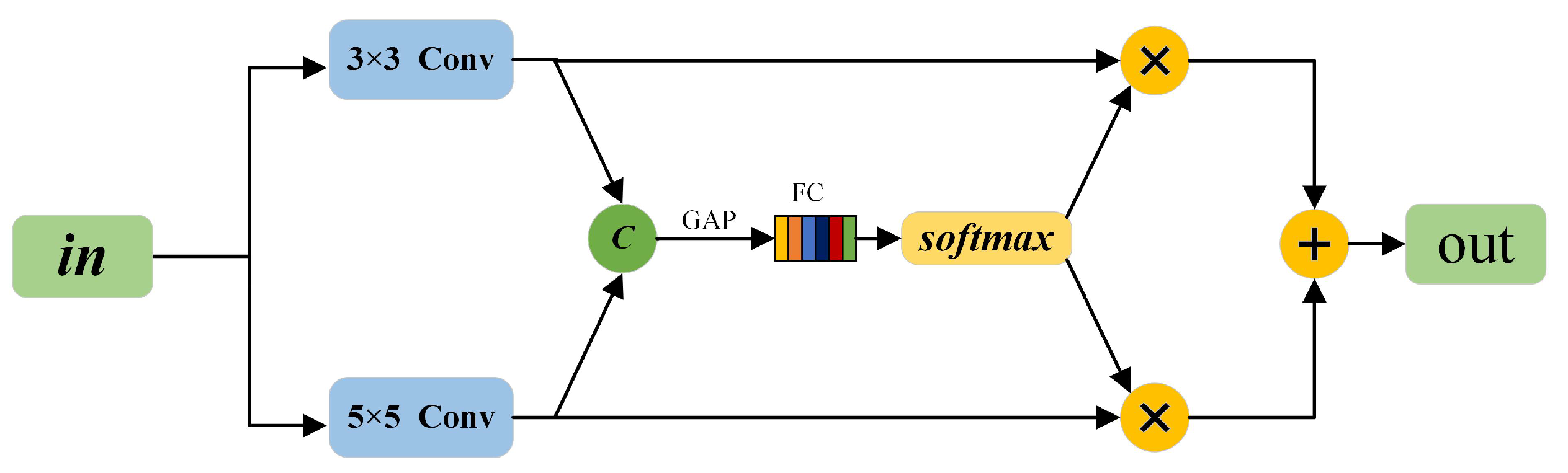
3.3. Multi-Scale Receptive Field Detection Head
3.4. PAGCP
4. Model Training and Result Analysis
4.1. Dataset Introduction
4.2. Experimental Environment
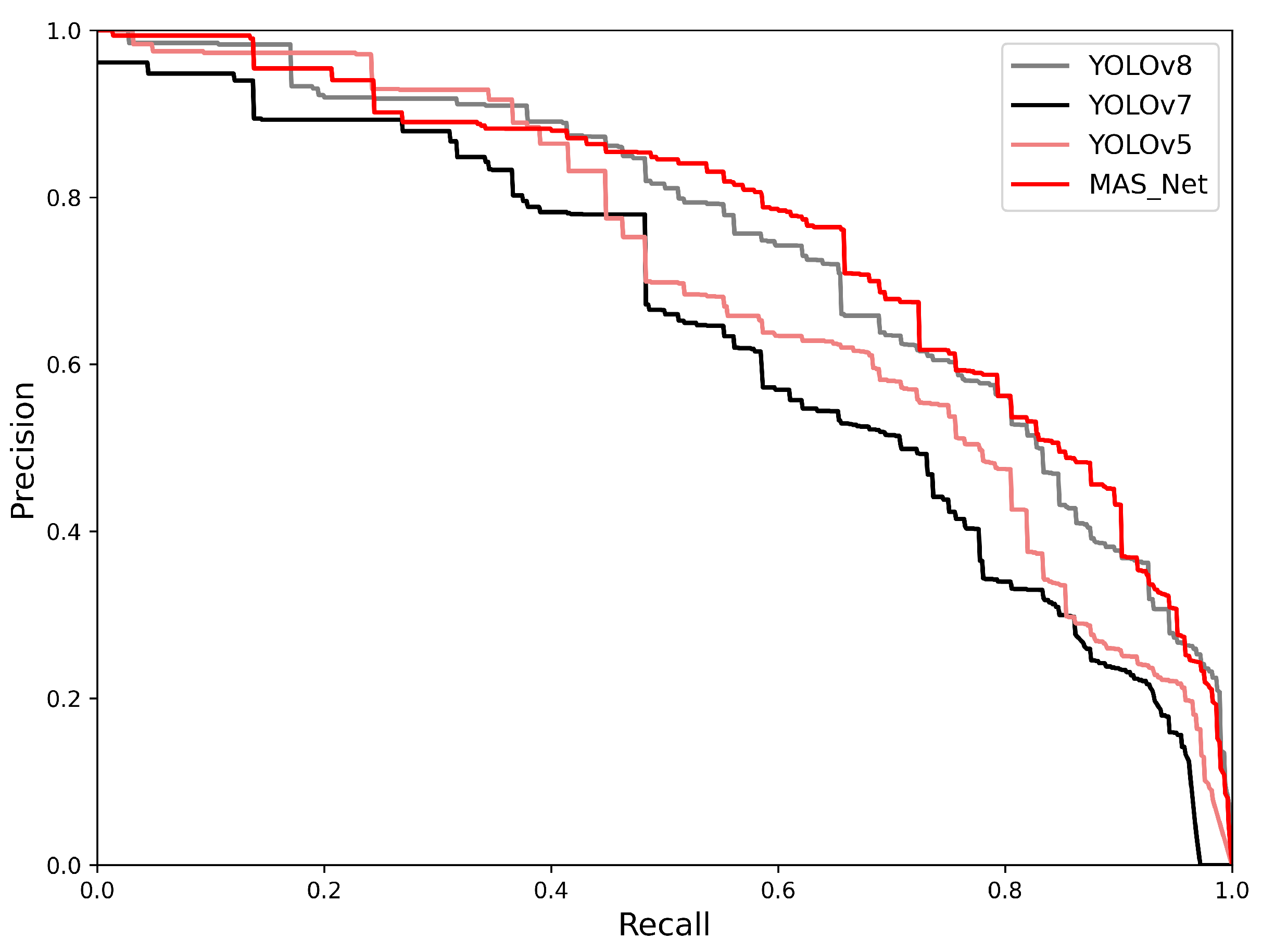
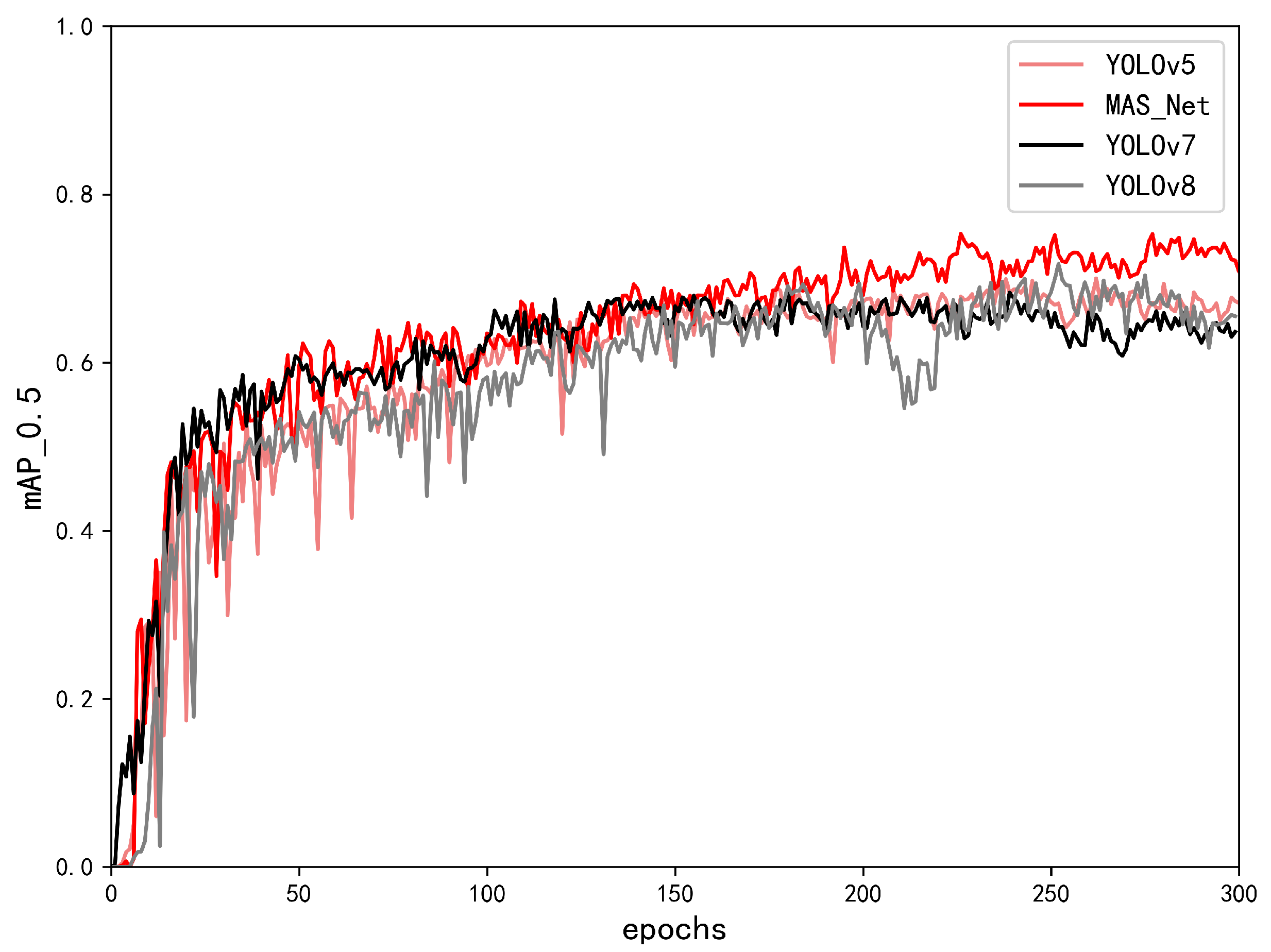
4.3. Results and Analysis
4.4. Grad-CAM
4.5. Experimental Results
5. Conclusions
6. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| MAS-Net | multi-level attention split network |
| SPCot | split contextual attention structure |
| MRFH | multi-scale receptive field detection head |
| RSConv | redundant split convolutional |
| PAGCP | Performance-aware Approximation of Global Channel Pruning |
| NWD | Normalized Wasser-stein Distance |
References
- Rougemont, M.; Van Saanen, M.; Sahli, R.; Hinrikson, H.P.; Bille, J.; Jaton, K. Detection of four Plasmodium species in blood from humans by 18S rRNA gene subunit-based and species-specific real-time PCR assays. J. Clin. Microbiol. 2004, 42, 5636–5643. [Google Scholar] [CrossRef]
- World Health Organization. Basic Malaria Microscopy Part I. Learner’s Guide; World Health Organization: Geneva, Switzerland, 2010. [Google Scholar]
- Bloch, M. The past and the present in the present. Man 1977, 12, 278–292. [Google Scholar] [CrossRef]
- Das, D.; Vongpromek, R.; Assawariyathipat, T.; Srinamon, K.; Kennon, K.; Stepniewska, K.; Ghose, A.; Sayeed, A.A.; Faiz, M.A.; Netto, R.L.A.; et al. Field evaluation of the diagnostic performance of EasyScan GO: A digital malaria microscopy device based on machine-learning. Malar. J. 2022, 21, 122. [Google Scholar] [CrossRef]
- Ayalew, F.; Tilahun, B.; Taye, B. Performance evaluation of laboratory professionals on malaria microscopy in Hawassa Town, Southern Ethiopia. BMC Res. Notes 2014, 7, 839. [Google Scholar] [CrossRef]
- Feng, X.; Levens, J.; Zhou, X.N. Protecting the gains of malaria elimination in China, 2020. Infect. Dis. Poverty 2020, 9, 43. [Google Scholar] [CrossRef]
- Ye, H.; Zhang, B.; Chen, T.; Fan, J.; Wang, B. Performance-aware Approximation of Global Channel Pruning for Multitask CNNs. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 10267–10284. [Google Scholar] [CrossRef] [PubMed]
- Tek, F.B.; Dempster, A.G.; Kale, I. Parasite detection and identification for automated thin blood film malaria diagnosis. Comput. Vis. Image Underst. 2010, 114, 21–32. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Liang, Z.; Powell, A.; Ersoy, I.; Poostchi, M.; Silamut, K.; Palaniappan, K.; Guo, P.; Hossain, M.A.; Sameer, A.; Maude, R.J.; et al. CNN-based image analysis for malaria diagnosis. In Proceedings of the 2016 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Shenzhen, China, 15–18 December 2016; pp. 493–496. [Google Scholar] [CrossRef]
- Vijayalakshmi, A. Deep learning approach to detect malaria from microscopic images. Multimed. Tools Appl. 2020, 79, 15297–15317. [Google Scholar] [CrossRef]
- Rajaraman, S.; Antani, S.K.; Poostchi, M.; Silamut, K.; Hossain, M.A.; Maude, R.J.; Jaeger, S.; Thoma, G.R. Pre-trained convolutional neural networks as feature extractors toward improved malaria parasite detection in thin blood smear images. PeerJ 2018, 6, e4568. [Google Scholar] [CrossRef]
- Dong, Y.; Jiang, Z.; Shen, H.; Pan, W.D.; Williams, L.A.; Reddy, V.V.; Benjamin, W.H.; Bryan, A.W. Evaluations of deep convolutional neural networks for automatic identification of malaria infected cells. In Proceedings of the 2017 IEEE EMBS International Conference on Biomedical & Health Informatics (BHI), Orlando, FL, USA, 16–19 February 2017; pp. 101–104. [Google Scholar] [CrossRef]
- Fuhad, K.; Tuba, J.F.; Sarker, M.R.A.; Momen, S.; Mohammed, N.; Rahman, T. Deep learning based automatic malaria parasite detection from blood smear and its smartphone based application. Diagnostics 2020, 10, 329. [Google Scholar] [CrossRef]
- Hung, J.; Carpenter, A. Applying faster R-CNN for object detection on malaria images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 808–813. [Google Scholar] [CrossRef]
- Dath, M.K.; Nazir, N. Diagnosing malaria with AI and image processing. In Proceedings of the 2023 3rd International Conference on Innovative Practices in Technology and Management (ICIPTM), Uttar Pradesh, India, 22–24 February 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Suraksha, S.; Santhosh, C.; Vishwa, B. Classification of Malaria cell images using Deep Learning Approach. In Proceedings of the 2023 Third International Conference on Advances in Electrical, Computing, Communication and Sustainable Technologies (ICAECT), Bhilai, India, 5–6 January 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Jusman, Y.; Aftal, A.A.; Tyassari, W.; Kanafiah, S.N.A.M.; Hayati, N.; Mohamed, Z. Classification of Parasite Malaria in Schizon Stage with GoogleNet and VGG-19 Pre-Trained Models. In Proceedings of the 2023 10th International Conference on Information Technology, Computer, and Electrical Engineering (ICITACEE), Semarang, Indonesia, 31 August–1 September 2023; pp. 219–223. [Google Scholar] [CrossRef]
- Araujo, F.; Colares, N.; Carvalho, U.; Costa Filho, C.; Costa, M. Plasmodium Life Cycle-Stage Classification on Thick Blood Smear Microscopy Images using Deep Learning: A Contribution to Malaria Diagnosis. In Proceedings of the 2023 19th International Symposium on Medical Information Processing and Analysis (SIPAIM), Mexico City, Mexico, 5–17 November 2023; pp. 1–4. [Google Scholar] [CrossRef]
- Yang, F.; Quizon, N.; Yu, H.; Silamut, K.; Maude, R.J.; Jaeger, S.; Antani, S. Cascading yolo: Automated malaria parasite detection for plasmodium vivax in thin blood smears. In Proceedings of the Medical Imaging 2020: Computer-Aided Diagnosis, Houston, TX, USA, 16–19 February 2020; Volume 11314, pp. 404–410. [Google Scholar]
- Abdurahman, F.; Fante, K.A.; Aliy, M. Malaria parasite detection in thick blood smear microscopic images using modified YOLOV3 and YOLOV4 models. BMC Bioinform. 2021, 22, 112. [Google Scholar] [CrossRef]
- Acula, D.D.; Carlos, J.A.P.; Lumacad, M.M.; Minano, J.C.L.O.; Reodica, J.K.R. Detection and classification of plasmodium parasites in human blood smear images using Darknet with YOLO. In Proceedings of the International Conference on Green Energy, Computing and Intelligent Technology (GEn-CITy 2023), Johor, Malaysia, 10–12 July 2023; pp. 24–31. [Google Scholar] [CrossRef]
- Liu, Z.; Liu, H.; Sun, Y. Detection and Classification of Malaria Parasite Based on Improved YOLOv5 Model. In Proceedings of the 2023 16th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Taizhou, China, 28–30 October 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Guemas, E.; Routier, B.; Ghelfenstein-Ferreira, T.; Cordier, C.; Hartuis, S.; Marion, B.; Bertout, S.; Varlet-Marie, E.; Costa, D.; Pasquier, G. Automatic patient-level recognition of four Plasmodium species on thin blood smear by a real-time detection transformer (RT-DETR) object detection algorithm: A proof-of-concept and evaluation. Microbiol. Spectr. 2024, 12, e01440-23. [Google Scholar] [CrossRef]
- Li, J.; Wen, Y.; He, L. SCConv: Spatial and Channel Reconstruction Convolution for Feature Redundancy. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 6153–6162. [Google Scholar] [CrossRef]
- Li, Y.; Yao, T.; Pan, Y.; Mei, T. Contextual transformer networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 1489–1500. [Google Scholar] [CrossRef]
- Li, C.; Zhou, A.; Yao, A. Omni-dimensional dynamic convolution. arXiv 2022, arXiv:2209.07947. [Google Scholar]
- Gao, S.H.; Cheng, M.M.; Zhao, K.; Zhang, X.Y.; Yang, M.H.; Torr, P. Res2net: A new multi-scale backbone architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 652–662. [Google Scholar] [CrossRef]
- Woo, S.; Debnath, S.; Hu, R.; Chen, X.; Liu, Z.; Kweon, I.S.; Xie, S. Convnext v2: Co-designing and scaling convnets with masked autoencoders. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 16133–16142. [Google Scholar] [CrossRef]
- Yu, W.; Zhou, P.; Yan, S.; Wang, X. Inceptionnext: When inception meets convnext. arXiv 2023, arXiv:2303.16900. [Google Scholar]
- Tang, Y.; Han, K.; Guo, J.; Xu, C.; Xu, C.; Wang, Y. GhostNetv2: Enhance cheap operation with long-range attention. Adv. Neural Inf. Process. Syst. 2022, 35, 9969–9982. [Google Scholar]
- Chen, J.; Kao, S.h.; He, H.; Zhuo, W.; Wen, S.; Lee, C.H.; Chan, S.H.G. Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 12021–12031. [Google Scholar] [CrossRef]
- Maaz, M.; Shaker, A.; Cholakkal, H.; Khan, S.; Zamir, S.W.; Anwer, R.M.; Shahbaz Khan, F. Edgenext: Efficiently amalgamated cnn-transformer architecture for mobile vision applications. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland; pp. 3–20. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 9992–10002. [Google Scholar] [CrossRef]
- Liu, X.; Peng, H.; Zheng, N.; Yang, Y.; Hu, H.; Yuan, Y. EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 14420–14430. [Google Scholar] [CrossRef]
- Wang, A.; Chen, H.; Lin, Z.; Pu, H.; Ding, G. Repvit: Revisiting mobile cnn from vit perspective. arXiv 2023, arXiv:2307.09283. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1577–1586. [Google Scholar] [CrossRef]
- Sifre, L.; Mallat, S. Rigid-motion scattering for texture classification. arXiv 2014, arXiv:1403.1687. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25. Available online: https://proceedings.neurips.cc/paper_files/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf (accessed on 17 January 2024). [CrossRef]
- Zhang, Q.; Jiang, Z.; Lu, Q.; Han, J.; Zeng, Z.; Gao, S.H.; Men, A. Split to be slim: An overlooked redundancy in vanilla convolution. arXiv 2020, arXiv:2006.12085. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. Available online: https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf (accessed on 17 January 2024).
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Yu, X.; Lyu, W.; Zhou, D.; Wang, C.; Xu, W. ES-Net: Efficient scale-aware network for tiny defect detection. IEEE Trans. Instrum. Meas. 2022, 71, 1–14. [Google Scholar] [CrossRef]
- Ljosa, V.; Sokolnicki, K.L.; Carpenter, A.E. Annotated high-throughput microscopy image sets for validation. Nat. Methods 2012, 9, 637. [Google Scholar] [CrossRef]
- He, T.; Zhang, Z.; Zhang, H.; Zhang, Z.; Xie, J.; Li, M. Bag of tricks for image classification with convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 558–567. [Google Scholar] [CrossRef]
- Wang, J.; Xu, C.; Yang, W.; Yu, L. A normalized Gaussian Wasserstein distance for tiny object detection. arXiv 2021, arXiv:2110.13389. [Google Scholar]
- Tan, M.; Le, Q. Efficientnetv2: Smaller models and faster training. In Proceedings of the International conference on machine learning. PMLR, Virtual, 18–24 July 2021; pp. 10096–10106. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part IV 14. Springer: Cham, Switzerland, 2016; pp. 630–645. [Google Scholar]
- Lv, W.; Xu, S.; Zhao, Y.; Wang, G.; Wei, J.; Cui, C.; Du, Y.; Dang, Q.; Liu, Y. Detrs beat yolos on real-time object detection. arXiv 2023, arXiv:2304.08069. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Output Channel | Convolution Size | Number of Repetitions |
|---|---|---|
| 64 | Conv(kernel:,stride 2) | 1 |
| 128 | Conv(kernel:,stride 2) | 1 |
| 128 | SPCot | 3 |
| 256 | Conv(kernel:,stride 2) | 1 |
| 256 | SPCot | 6 |
| 512 | Conv(kernel:,stride 2) | 1 |
| 512 | SPCot | 9 |
| 1024 | Conv(kernel:,stride 2) | 1 |
| 1024 | SPCot | 3 |
| 1024 | SPPF | 1 |
| Algorithm | % | % | % | ||||
|---|---|---|---|---|---|---|---|
| YOLOv5 | 63.4 | 67.8 | 69.9 | 46.3 m | 108.3 | 65.5 | 46 |
| YOLOv7 | 62.9 | 66.9 | 67.8 | 39.2 m | 105.2 | 64.8 | 50 |
| YOLOv8 | 68.8 | 65.3 | 71.7 | 43.6 m | 164.8 | 66.0 | 62 |
| MAS-Net | 73.9 | 72.2 | 75.9 | 48.7 m | 126.2 | 73.0 | 42 |
| MAS-Net-Tiny | 62.6 | 69.8 | 70.6 | 9.6 m | 36.8 | 66.0 | 125 |
| Algorithm | % | % | % | ||||
|---|---|---|---|---|---|---|---|
| MAS-Net | 75.9 | 48.7 m | 126.2 | 42 | - | - | - |
| MAS-Net-Tiny | 70.6 | 9.6 m | 36.8 | 125 | 5.3 | 80.2 | 70.7 |
| Algorithm | % | % | % | ||||
|---|---|---|---|---|---|---|---|
| Efficientnet [19] | 62.3 | 74.5 | 71.8 | 49.2 m | 80.8 | 67.9 | 10 |
| EfficientnetV2 [52] | 64.7 | 65.1 | 72.2 | 74.1 m | 134.0 | 64.9 | 13 |
| ConvnextV2 [29] | 61.3 | 60.3 | 64.3 | 50.6 m | 113.2 | 59.8 | 29 |
| MobilenetV3 [37] | 57.3 | 61.3 | 64.6 | 23.2 m | 43.1 | 59.2 | 28 |
| Fasternet [32] | 63.8 | 65.7 | 68.1 | 23.7 m | 44.4 | 59.2 | 28 |
| ResnetV2 [53] | 61.5 | 65.0 | 64.8 | 51.2 m | 113.0 | 63.2 | 39 |
| Edgenext [33] | 58.8 | 64.8 | 63.7 | 40.1 m | 87.6 | 61.7 | 30 |
| EfficientViT [35] | 68.7 | 63.3 | 68.5 | 33.8 m | 68.0 | 65.9 | 17 |
| RT-DETR [54] | 67.9 | 65.4 | 61.9 | 32.0 m | 87.2 | 66.6 | 100 |
| MAS-Net | 73.9 | 72.2 | 75.9 | 48.7 m | 126.2 | 73.0 | 42 |
| MAS-Net-Tiny | 62.6 | 69.8 | 70.6 | 9.6 m | 36.8 | 66.0 | 125 |
| Mosaic | SPCotNet | MRFH | PAGCP | mAP% | GFLOPs | Para (Million) |
|---|---|---|---|---|---|---|
| √ | - | - | - | 69.0 | 108.3 | 47.9 |
| √ | √ | - | - | 75.5 | 116.2 | 46.6 |
| √ | √ | √ | - | 75.9 | 126.2 | 48.7 |
| √ | √ | * | - | 75.3 | 156.6 | 90.6 |
| √ | √ | √ | √ | 70.6 | 36.8 | 9.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiong, Z.; Wu, J. Multi-Level Attention Split Network: A Novel Malaria Cell Detection Algorithm. Information 2024, 15, 166. https://doi.org/10.3390/info15030166
Xiong Z, Wu J. Multi-Level Attention Split Network: A Novel Malaria Cell Detection Algorithm. Information. 2024; 15(3):166. https://doi.org/10.3390/info15030166
Chicago/Turabian StyleXiong, Zhao, and Jiang Wu. 2024. "Multi-Level Attention Split Network: A Novel Malaria Cell Detection Algorithm" Information 15, no. 3: 166. https://doi.org/10.3390/info15030166
APA StyleXiong, Z., & Wu, J. (2024). Multi-Level Attention Split Network: A Novel Malaria Cell Detection Algorithm. Information, 15(3), 166. https://doi.org/10.3390/info15030166