
Hierarchical Classification of Transversal Skills in Job Advertisements Based on Sentence Embeddings




Abstract
1. Introduction
2. Related Work
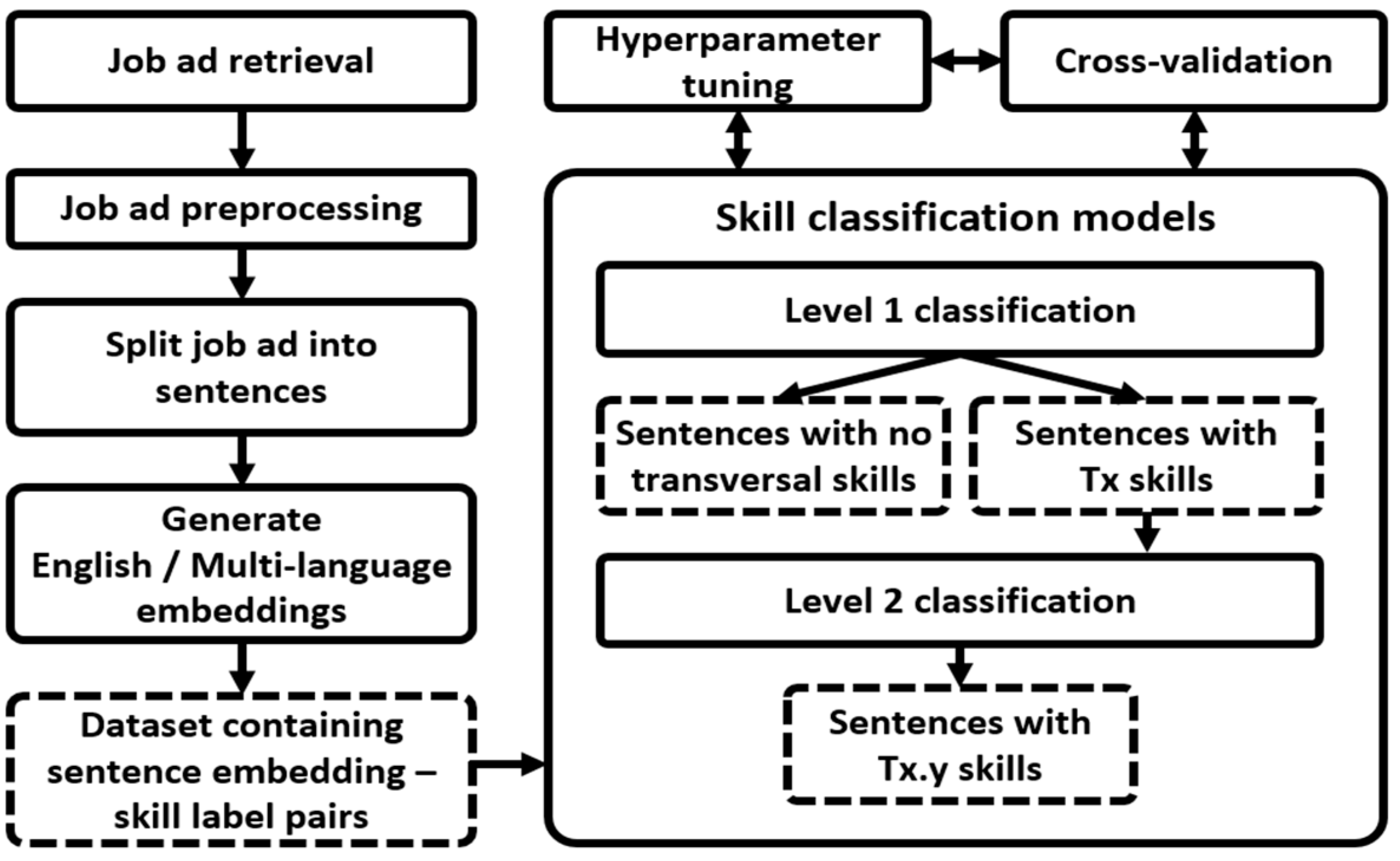
3. Proposed Methodology
3.1. Data Preprocessing
- T1—Core skills and competences;
- T2—Thinking skills and competences;
- T3—Self-management skills and competences;
- T4—Social and communication skills and competences;
- T5—Physical and manual skills and competences;
- T6—Life skills and competences.
3.2. Hierarchical Skill Classification
4. Experimental Results
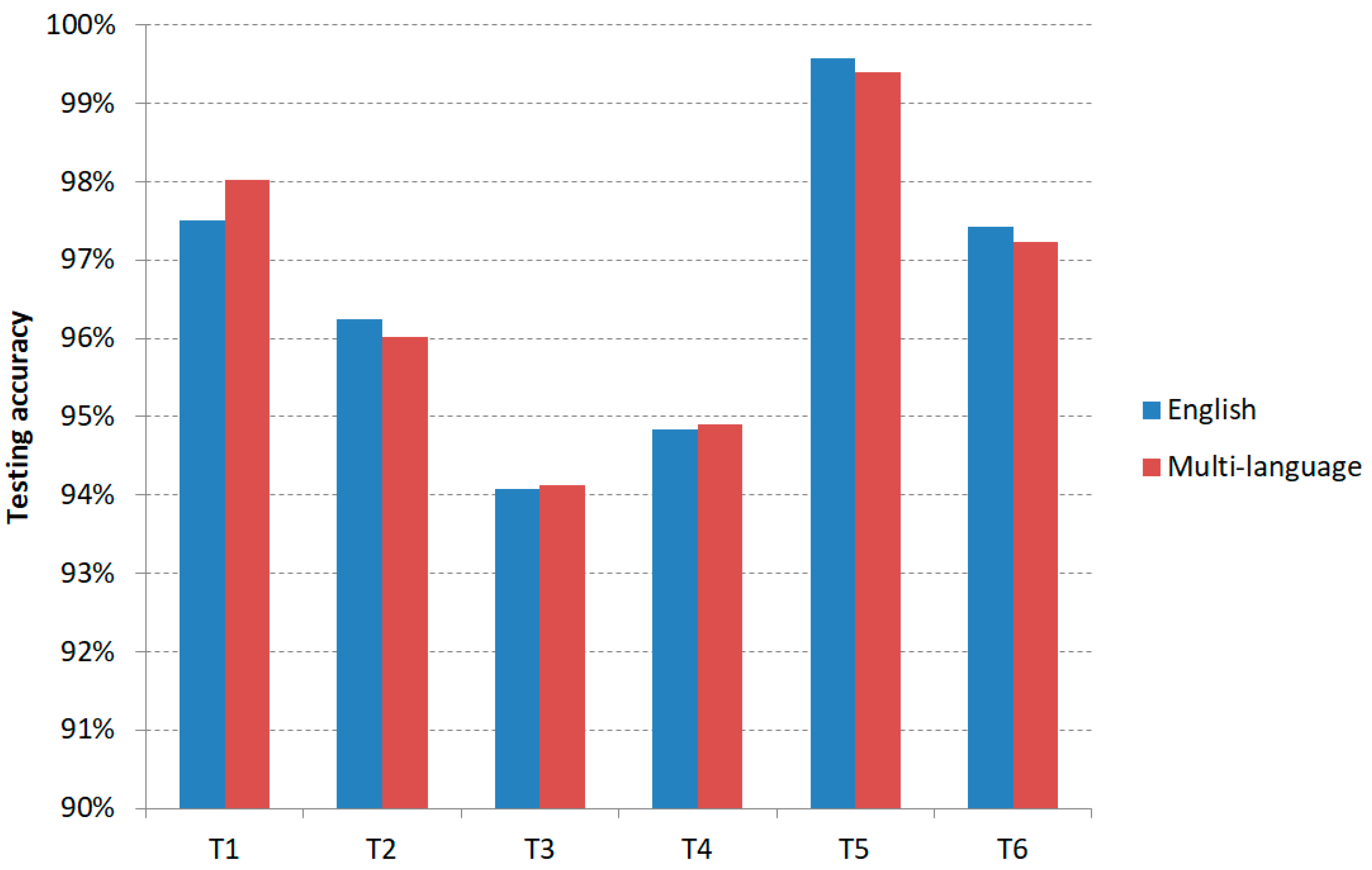
4.1. “Level 1” Classification
4.1.1. The English Language Model
4.1.2. The Multi-Language Model
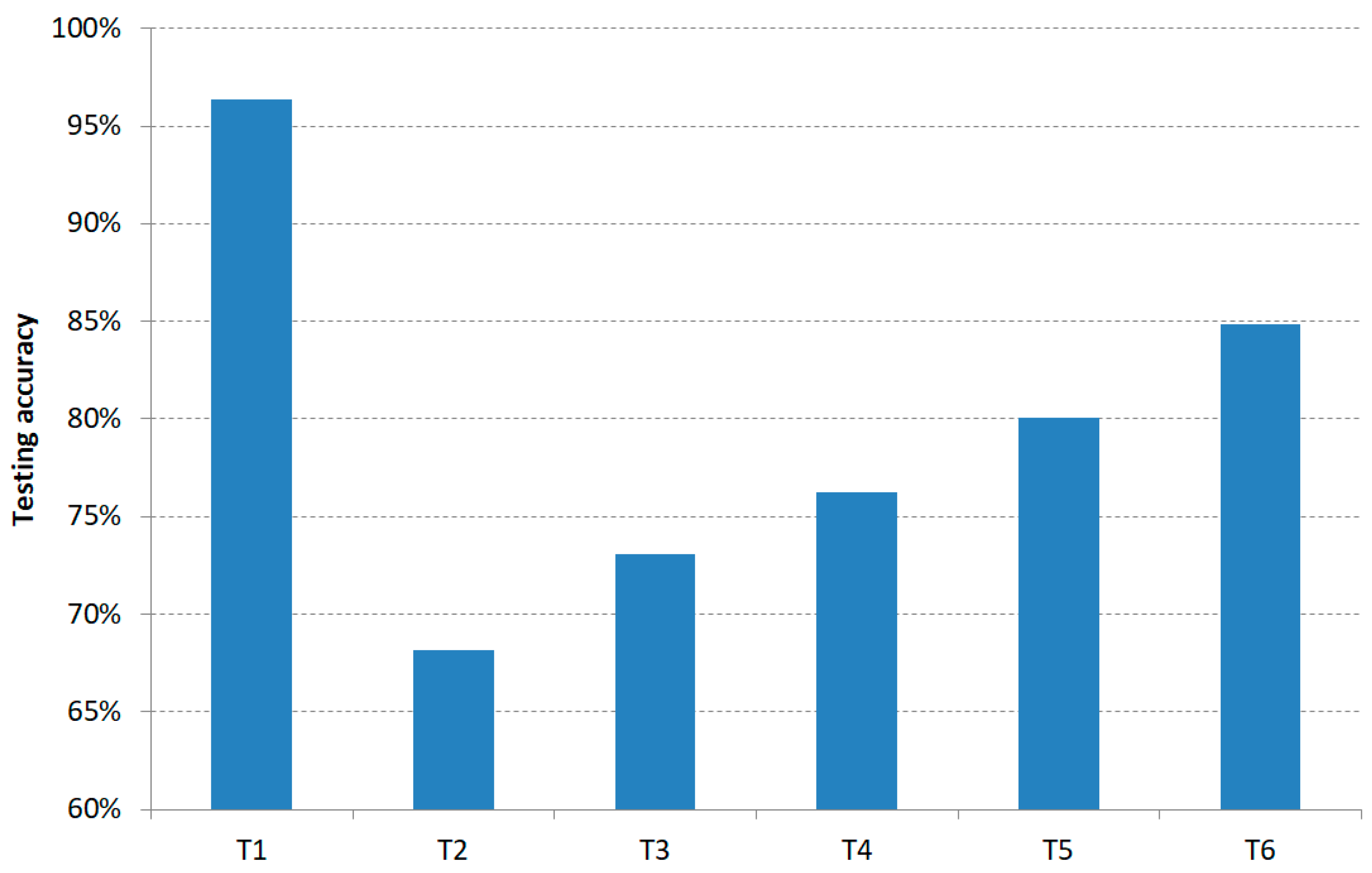
4.2. “Level 2” Classification
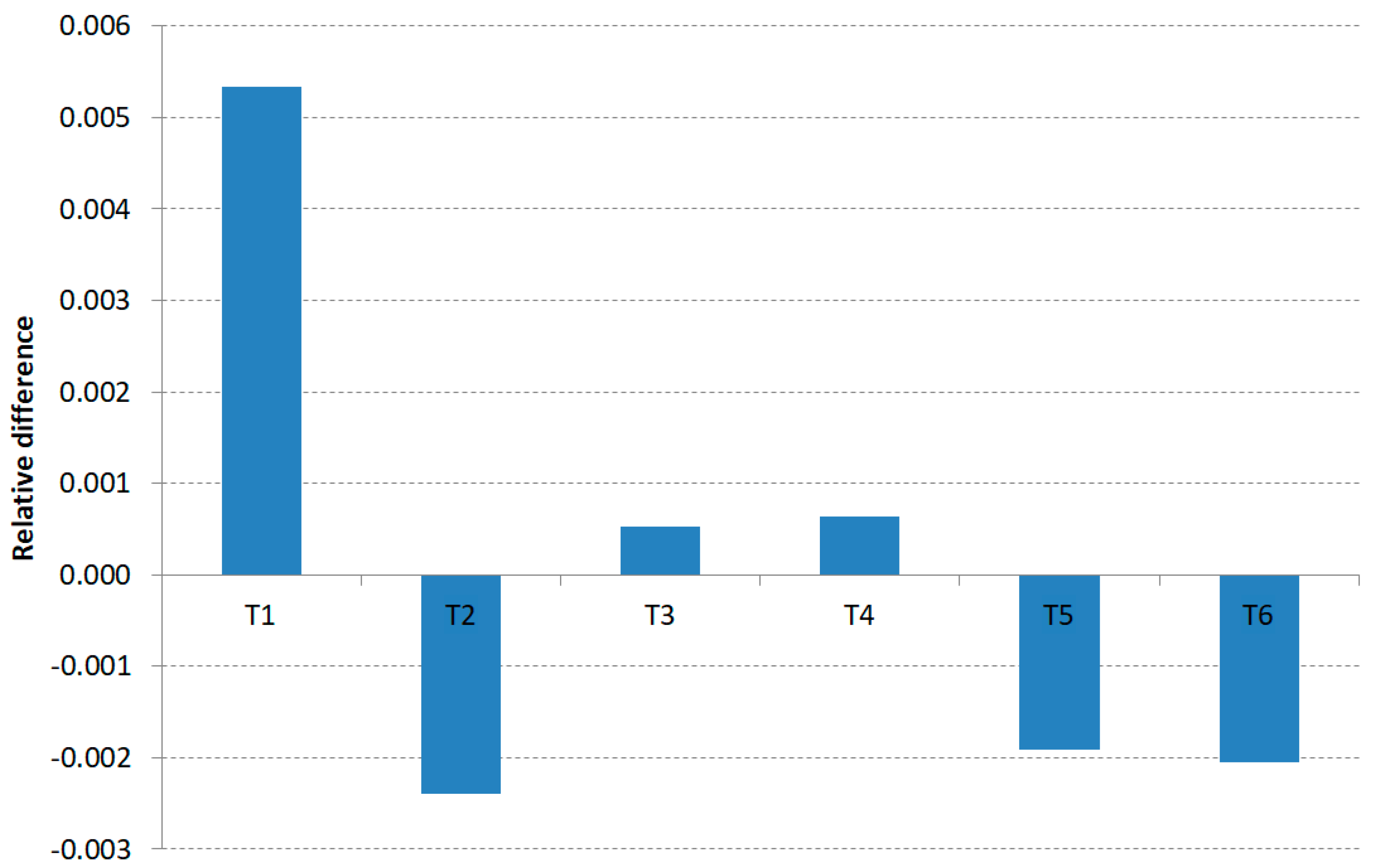
5. Analysis and Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhou, W.; Zhu, Y.; Javed, F.; Rahman, M.; Balaji, J.; McNair, M. Quantifying skill relevance to job titles. In Proceedings of the 2016 IEEE International Conference on Big Data (Big Data), Washington, DC, USA, 5–8 December 2016; pp. 1532–1541. [Google Scholar]
- Papoutsoglou, M.; Mittas, N.; Angelis, L. Mining People Analytics from StackOverflow Job Advertisements. In Proceedings of the 2017 43rd Euromicro Conference on Software Engineering and Advanced Applications (SEAA), Vienna, Austria, 30 August–1 September 2017; pp. 108–115. [Google Scholar]
- Malherbe, E.; Aufaure, M.A. Bridge the terminology gap between recruiters and candidates: A multilingual skills base built from social media and linked data. In Proceedings of the 2016 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), San Francisco, CA, USA, 18–21 August 2016; pp. 583–590. [Google Scholar]
- Sibarani, E.M.; Scerri, S.; Morales, C.; Auer, S.; Collarana, D. Ontology-guided Job Market Demand Analysis: A Cross-Sectional Study for the Data Science field. In Proceedings of the 13th International Conference on Semantic Systems, Ser. Semantics 2017, Amsterdam, The Netherlands, 11–14 September 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 25–32. [Google Scholar]
- Gardiner, A.; Aasheim, C.; Rutner, P.; Williams, S. Skill Requirements in Big Data: A Content Analysis of Job Advertisements. J. Comput. Inf. Syst. 2018, 58, 374–384. [Google Scholar] [CrossRef]
- Chaibate, H.; Hadek, A.; Ajana, S.; Bakkali, S.; Faraj, K. Analyzing the engineering soft skills required by Moroccan job market. In Proceedings of the 2019 5th International Conference on Optimization and Applications (ICOA), Kenitra, Morocco, 25–26 April 2019; pp. 1–6. [Google Scholar]
- Niederman, F.; Sumner, M. Resolving the Skills Paradox: A Content Analysis of a Jobs Database. In Proceedings of the 2019 on Computers and People Research Conference, Nashville, TN, USA, 20–22 June 2019; pp. 164–167. [Google Scholar]
- Rios, J.A.; Ling, G.; Pugh, R.; Becker, D.; Bacall, A. Identifying Critical 21st-Century Skills for Workplace Success: A Content Analysis of Job Advertisements. Educ. Res. 2020, 49, 80–89. [Google Scholar] [CrossRef]
- Debortoli, S.; Maller, O.; Brocke, J.V. Comparing Business Intelligence and Big Data Skills. Bus. Inf. Syst. Eng. 2014, 6, 289–300. [Google Scholar] [CrossRef]
- De Mauro, A.; Greco, M.; Grimaldi, M.; Ritala, P. Human resources for Big Data professions: A systematic classification of job roles and required skill sets. Inf. Process. Manag. 2018, 54, 807–817. [Google Scholar] [CrossRef]
- Gurcan, F.; Sevik, S. Expertise Roles and Skills Required by the Software Development Industry. In Proceedings of the 2019 1st International Informatics and Software Engineering Conference (UBMYK), Ankara, Turkey, 6–7 November 2019; pp. 1–4. [Google Scholar]
- Gurcan, F.; Cagiltay, N.E. Big Data Software Engineering: Analysis of Knowledge Domains and Skill Sets Using LDA-Based Topic Modeling. IEEE Access 2019, 7, 82541–82552. [Google Scholar] [CrossRef]
- Jelodar, H.; Wang, Y.; Yuan, C.; Feng, X.; Jiang, X.; Li, Y.; Zhao, L. Latent Dirichlet allocation (LDA) and topic modeling: Models, applications, a survey. Multimed. Tools Appl. 2019, 78, 15169–15211. [Google Scholar] [CrossRef]
- Javed, F.; Hoang, P.; Mahoney, T.; McNair, M. Large-scale occupational skills normalization for online recruitment. In Proceedings of the Twenty-Ninth AAAI Conference, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Zhao, M.; Javed, F.; Jacob, F.; McNair, M. SKILL: A System for Skill Identification and Normalization. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; pp. 4012–4017. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Process. Syst. 2013, 26, 3111–3119. [Google Scholar]
- Botov, D.; Klenin, J.; Melnikov, A.; Dmitrin, Y.; Nikolaev, I.; Vinel, M. Mining Labor Market Requirements Using Distributional Semantic Models and Deep Learning. In Business Information Systems, Ser. Lecture Notes in Business Information Processing; Abramowicz, W., Corchuelo, R., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 177–190. [Google Scholar]
- Gugnani, A.; Misra, H. Implicit Skills Extraction Using Document Embedding and Its Use in Job Recommendation. AAAI 2020, 34, 13286–13293. [Google Scholar] [CrossRef]
- Le, Q.; Mikolov, T. Distributed representations of sentences and documents. In Proceedings of the International Conference on Machine Learning, PMLR, Baltimore, MD, USA, 17–23 July 2022; pp. 1188–1196. [Google Scholar]
- Van-Duyet, L.; Quan, V.M.; An, D.Q. Skill2vec: Machine Learning Approach for Determining the Relevant Skills from Job Description. arXiv 2019, arXiv:1707.09751. [Google Scholar]
- Li, S.; Shi, B.; Yang, J.; Yan, J.; Wang, S.; Chen, F.; He, Q. Deep Job Understanding at LinkedIn. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Ser. SIGIR ’20, Xi’an, China, 25–30 July 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 2145–2148. [Google Scholar]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching Word Vectors with Subword Information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef]
- Fagerbakk, A.G. Keeping Up with the Market: Extracting Competencies from Norwegian Job Listings. Master’s Thesis, The Arctic University of Norway, Tromsø, Norway, 2021. [Google Scholar]
- Jia, S.; Liu, X.; Zhao, P.; Liu, C.; Sun, L.; Peng, T. Representation of Job-Skill in Artificial Intelligence with Knowledge Graph Analysis. In Proceedings of the 2018 IEEE Symposium on Product Compliance Engineering—Asia (ISPCE-CN), Shenzhen, China, 5–7 December 2018; pp. 1–6. [Google Scholar]
- Lample, G.; Ballesteros, M.; Subramanian, S.; Kawakami, K.; Dyer, C. Neural Architectures for Named Entity Recognition. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 260–270. [Google Scholar]
- Sayfullina, L.; Malmi, E.; Kannala, J. Learning Representations for Soft Skill Matching. In Analysis of Images, Social Networks and Texts, Lecture Notes in Computer Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; pp. 141–152. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar]
- Tamburri, D.A.; Heuvel, W.-J.V.D.; Garriga, M. DataOps for Societal Intelligence: A Data Pipeline for Labor Market Skills Extraction and Matching. In Proceedings of the 2020 IEEE 21st International Conference on Information Reuse and Integration for Data Science (IRI), Las Vegas, NV, USA, 11–13 August 2020; pp. 391–394. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Lukauskas, M.; Šarkauskaitė, V.; Pilinkienė, V.; Stundžienė, A.; Grybauskas, A.; Bruneckienė, J. Enhancing Skills Demand Understanding through Job Ad Segmentation Using NLP and Clustering Techniques. Appl. Sci. 2023, 13, 6119. [Google Scholar] [CrossRef]
- Mathiasen, M.; Nielsen, J.; Laub, S. A Transformer Based Semantic Analysis of (non-English) Danish Job ads. In Proceedings of the 15th International Conference on Computer Supported Education, Prague, Czech Republic, 21–23 April 2023. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019. [Google Scholar]
- Bhola, A.; Halder, K.; Prasad, A.; Kan, M.-Y. Retrieving Skills from Job Descriptions: A Language Model Based Extreme Multi-label Classification Framework. In Proceedings of the 28th International Conference on Computational Linguistics, Online, 8–13 December 2020; pp. 5832–5842. [Google Scholar]
- Cedefop. Online Job Vacancies and Skills Analysis: A Cedefop Pan-European Approach; Publications Office: Luxembourg, 2019; Available online: http://data.europa.eu/doi/10.2801/097022 (accessed on 5 January 2024).
- Applegate, R. Job ads, jobs, and researchers: Searching for valid sources. Libr. Inf. Sci. Res. 2010, 32, 163–170. [Google Scholar] [CrossRef]
- Papoutsoglou, M.; Ampatzoglou, A.; Mittas, N.; Angelis, L. Extracting Knowledge from On-Line Sources for Software Engineering Labor Market: A Mapping Study. IEEE Access 2019, 7, 157595–157613. [Google Scholar] [CrossRef]
- Khaouja, I.; Kassou, I.; Ghogho, M. A Survey on Skill Identification from Online Job Ads. IEEE Access 2021, 9, 118134–118153. [Google Scholar] [CrossRef]
- European Commission, Directorate-General for Employment, Social Affairs and Inclusion, EURES. 2023. Available online: https://eures.ec.europa.eu/index_en (accessed on 5 January 2024).
- European Commission, Directorate-General for Employment, Social Affairs and Inclusion, ESCO Publications: Skills & Competences. 2022. Available online: https://esco.ec.europa.eu/en/classification/skill_main (accessed on 5 January 2024).
- Reimers, N.; Gurevych, I. Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, Online, 16–20 November 2020; Association for Computational Linguistics: Kerrville, TX, USA, 2020. [Google Scholar]
- Zhang, J.; Zhao, Y.; Saleh, M.; Liu, P.J. PEGASUS: Pre-Training with Extracted Gap-Sentences for Abstractive Summarization. 2020. Available online: https://github.com/google-research/pegasus (accessed on 5 January 2024).
- Adarsh, A. Pegasus-Paraphrase Library. 2022. Available online: https://github.com/adarshgowdaa/pegasus-paraphrase (accessed on 5 January 2024).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. Trial | Architecture and Hyperparameters | Motivation |
|---|---|---|
| 1 | 768: 128 (elu): 1 (sigmoid) n = 1000, η = 0.001, opt = Adam | Simple architecture (one hidden layer) |
| 2 | 768: 1536 (tanh): 512 (tanh): 128 (tanh): 32 (tanh): 8 (tanh): 1 (sigmoid) n = 1000, η = 0.001, opt = Adam | Complex architecture (five hidden layers) |
| 3 | 768: 20 (lrelu): 4 (lrelu): 1 (sigmoid) n = 1000, η = 0.001, opt = Adam | Medium size architecture (two hidden layers), strong information compression in the first hidden layer |
| 4 | 768: 81 (lrelu): 9 (lrelu): 1 (sigmoid) n = 1000, η = 0.001, opt = Adam | Medium size architecture (two hidden layers), balanced information compression |
| 5 | 768: 81 (sigmoid): 9 (sigmoid): 1 (sigmoid) n = 1000, η = 0.001, opt = Adam | Sigmoid activation function in the hidden layers |
| 6 | 768: 81 (tanh): 9 (tanh): 1 (sigmoid) n = 1000, η = 0.001, opt = Adam | Hyperbolic tangent activation function in the hidden layers |
| 7 | 768: 81 (lrelu): 9 (lrelu): 1 (sigmoid) n = 1000, η = 0.001, opt = RMSprop | Leaky ReLU activation function in the hidden layers and the RMSprop optimizer |
| 8 | 768: 81 (lrelu): 9 (lrelu): 1 (sigmoid) n = 1000, η = 0.01, opt = Adam | Higher learning rate (0.01) |
| 9 | 768: 81 (lrelu): 9 (lrelu): 1 (sigmoid) n = 10,000, η = 0.01, opt = Adam | Large number of training epochs (10,000) |
| 10 | 768: 81 (lrelu): 9 (lrelu): 1 (sigmoid) n = 100, η = 0.001, opt = Adam | Small number of training epochs (100) |
| No. Trial | Architecture and Hyperparameters | Motivation |
|---|---|---|
| 1 | 768: 128 (elu): 1 (sigmoid) n = 1000, η = 0.001, opt = Adam | Simple architecture (one hidden layer) |
| 2 | 768: 128 (elu): 1 (sigmoid) n = 1000, η = 0.01, opt = Adam | Higher learning rate (0.01) |
| 3 | 768: 128 (elu): 1 (sigmoid) n = 1000, η = 0.01, opt = RMSprop | RMSprop optimizer |
| 4 | 768: 128 (elu): 1 (sigmoid) n = 10,000, η = 0.01, opt = Adam | Large number of training epochs (10,000) |
| 5 | 768: 128 (lrelu): 1 (sigmoid) n = 1000, η = 0.01, opt = Adam | Leaky ReLU activation function in the hidden layer |
| 6 | 768: 81 (lrelu): 9 (lrelu): 1 (sigmoid) n = 1000, η = 0.01, opt = Adam | Medium size architecture (two hidden layers), balanced information compression |
| 7 | 768: 81 (lrelu): 9 (lrelu): 1 (sigmoid) n = 1000, η = 0.01, opt = RMSprop | RMSprop optimizer |
| English Language Model | ||||||
| Trial | T1 | T2 | T3 | T4 | T5 | T6 |
| 1 | 96.91 | 95.16 | 92.70 | 93.68 | 99.33 | 96.14 |
| 2 | 95.93 | 93.55 | 91.74 | 93.26 | 98.52 | 95.14 |
| 3 | 97.20 | 94.87 | 93.03 | 94.18 | 99.37 | 96.76 |
| 4 | 97.50 | 95.85 | 93.59 | 94.60 | 99.52 | 97.25 |
| 5 | 97.10 | 94.68 | 91.99 | 93.76 | 99.17 | 95.62 |
| 6 | 96.91 | 94.68 | 92.34 | 93.28 | 99.29 | 95.80 |
| 7 | 97.45 | 95.91 | 93.59 | 94.78 | 99.54 | 97.33 |
| 8 | 97.48 | 96.04 | 93.74 | 94.84 | 99.50 | 97.14 |
| 9 | 97.48 | 96.24 | 94.07 | 94.43 | 99.58 | 97.43 |
| 10 | 95.35 | 90.00 | 89.55 | 89.19 | 97.81 | 91.03 |
| Multi-Language Model | ||||||
| Trial | T1 | T2 | T3 | T4 | T5 | T6 |
| 1 | 97.14 | 94.71 | 92.92 | 93.26 | 98.93 | 96.01 |
| 2 | 97.54 | 89.11 | 93.66 | 94.08 | 99.03 | 96.95 |
| 3 | 97.79 | 95.61 | 93.80 | 94.69 | 99.20 | 96.70 |
| 4 | 97.56 | 95.86 | 93.97 | 94.67 | 99.04 | 96.97 |
| 5 | 97.82 | 96.01 | 93.89 | 94.83 | 99.27 | 97.23 |
| 6 | 98.02 | 95.82 | 94.12 | 94.90 | 99.24 | 97.08 |
| 7 | 97.98 | 95.97 | 94.04 | 94.56 | 99.39 | 97.02 |
| No. Trial | Architecture and Hyperparameters | Motivation |
|---|---|---|
| 1 | 768: 128 (lrelu): no (sigmoid) n = 100, η = 0.001, opt = Adam | Simple architecture (one hidden layer) |
| 2 | 768: 128 (lrelu): no (sigmoid) n = 100, η = 0.01, opt = Adam | Higher learning rate (0.01) |
| 3 | 768: 150 (lrelu): 30 (lrelu): no (sigmoid) n = 100, η = 0.01, opt = Adam | Larger architecture (two hidden layers) |
| 4 | 768: 128 (lrelu): no (sigmoid) n = 100, η = 0.01, λ = 10−5, opt = Adam | Regularization |
| 5 | 768: 128 (lrelu): no (sigmoid) n = 1000, η = 0.01, λ = 10−5, opt = Adam | Larger number of training epochs (1000) |
| 6 | 768: 128 (tanh): no (sigmoid) n = 100, η = 0.01, λ = 10−5, opt = Adam | Hyperbolic tangent activation function in the hidden layer |
| 7 | 768: 128 (lrelu): no (sigmoid) n = 50, η = 0.01, λ = 10−5, opt = Adam | Smaller number of training epochs (50) |
| 8 | 768: 128 (elu): no (sigmoid) n = 100, η = 0.01, λ = 10−5, opt = Adam | Exponential Linear Unit (ELU) activation function in the hidden layer |
| 9 | 768: 128 (elu): no (sigmoid) n = 100, η = 0.01, λ = 10−5, opt = RMSprop | RMSprop optimizer |
| 10 | 768: 150 (sigmoid): 30 (sigmoid): no (sigmoid) n = 100, η = 0.01, λ = 10−5, opt = Adam | Larger architecture (two hidden layers) with sigmoid activation function in the hidden layers |
| Trial | T1 | T2 | T3 | T4 | T5 | T6 |
|---|---|---|---|---|---|---|
| 1 | 91.46 | 66.93 | 72.23 | 74.49 | 76.20 | 81.55 |
| 2 | 92.95 | 67.69 | 73.09 | 76.05 | 77.47 | 82.51 |
| 3 | 88.81 | 65.41 | 69.83 | 72.91 | 73.91 | 78.61 |
| 4 | 95.89 | 68.17 | 73.05 | 75.23 | 75.67 | 84.82 |
| 5 | 92.82 | 65.47 | 69.61 | 73.34 | 77.13 | 81.07 |
| 6 | 96.22 | 67.53 | 72.44 | 76.05 | 80.05 | 84.32 |
| 7 | 93.19 | 65.63 | 70.40 | 73.34 | 77.68 | 81.92 |
| 8 | 91.71 | 65.09 | 69.34 | 72.67 | 76.87 | 81.03 |
| 9 | 95.02 | 66.98 | 71.46 | 74.72 | 78.79 | 83.02 |
| 10 | 96.35 | 67.85 | 72.16 | 76.21 | 76.75 | 83.10 |
| T1 | T2 | T3 | T4 | T5 | T6 |
|---|---|---|---|---|---|
| T1.1: 106 | T2.1: 99 | T3.1: 186 | T4.1: 169 | T5.1: 8 | T6.1: 8 |
| T1.2: 7 | T2.2: 101 | T3.2: 176 | T4.2: 181 | T5.2: 13 | T6.2: 10 |
| T1.3: 29 | T2.3: 137 | T3.3: 94 | T4.3: 209 | T6.3: 15 | |
| T2.4: 107 | T3.4: 122 | T4.4: 142 | T6.4: 31 | ||
| T4.5: 54 | T6.5: 32 | ||||
| T6.6: 33 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Leon, F.; Gavrilescu, M.; Floria, S.-A.; Minea, A.A. Hierarchical Classification of Transversal Skills in Job Advertisements Based on Sentence Embeddings. Information 2024, 15, 151. https://doi.org/10.3390/info15030151
Leon F, Gavrilescu M, Floria S-A, Minea AA. Hierarchical Classification of Transversal Skills in Job Advertisements Based on Sentence Embeddings. Information. 2024; 15(3):151. https://doi.org/10.3390/info15030151
Chicago/Turabian StyleLeon, Florin, Marius Gavrilescu, Sabina-Adriana Floria, and Alina Adriana Minea. 2024. "Hierarchical Classification of Transversal Skills in Job Advertisements Based on Sentence Embeddings" Information 15, no. 3: 151. https://doi.org/10.3390/info15030151
APA StyleLeon, F., Gavrilescu, M., Floria, S.-A., & Minea, A. A. (2024). Hierarchical Classification of Transversal Skills in Job Advertisements Based on Sentence Embeddings. Information, 15(3), 151. https://doi.org/10.3390/info15030151