



Understanding Self-Supervised Learning of Speech Representation via Invariance and Redundancy Reduction


Abstract
1. Introduction
- Downstream Task Efficacy: Quantitative effectiveness on a select speech-processing task;
- Disentanglement Analysis: A quantitative assessment of representation decoupling quality and its axis alignment with ground-truth explanatory factors;
- Objective Variants: Ablations examine the impact of training components.
Related Works
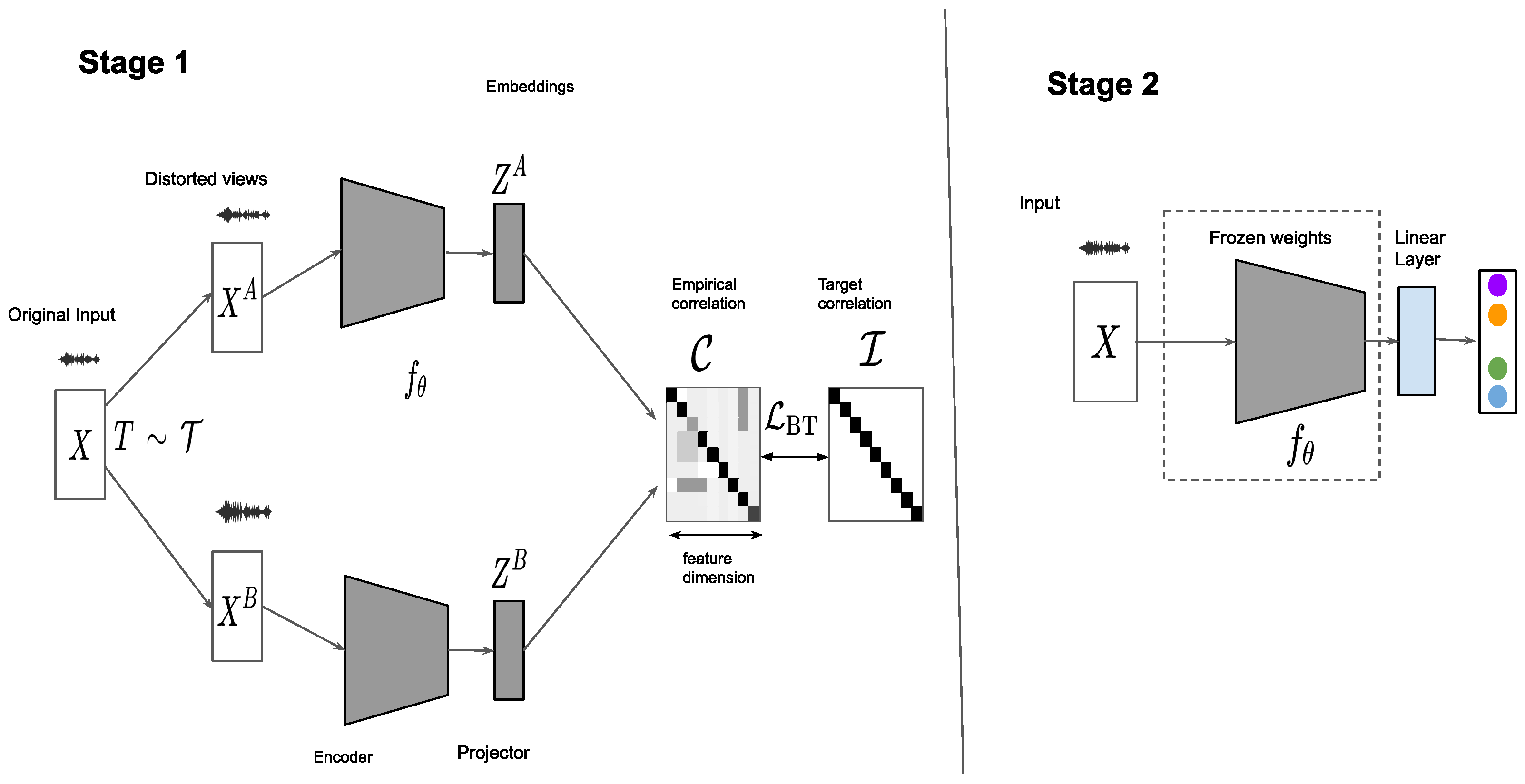
2. Materials and Methods
2.1. Learning Framework
2.2. Datasets
2.3. Experimental Setup
3. Results
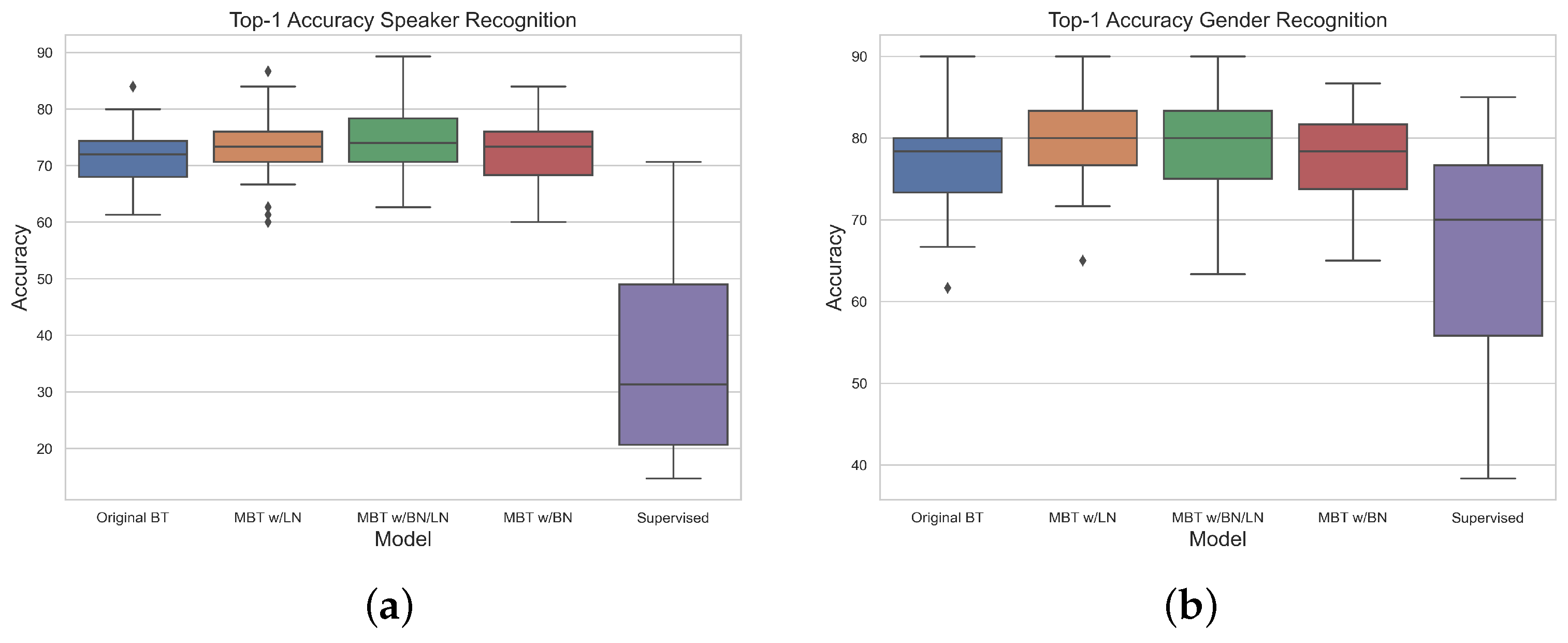
3.1. Effect of Upstream and Downstream Dataset Sizes
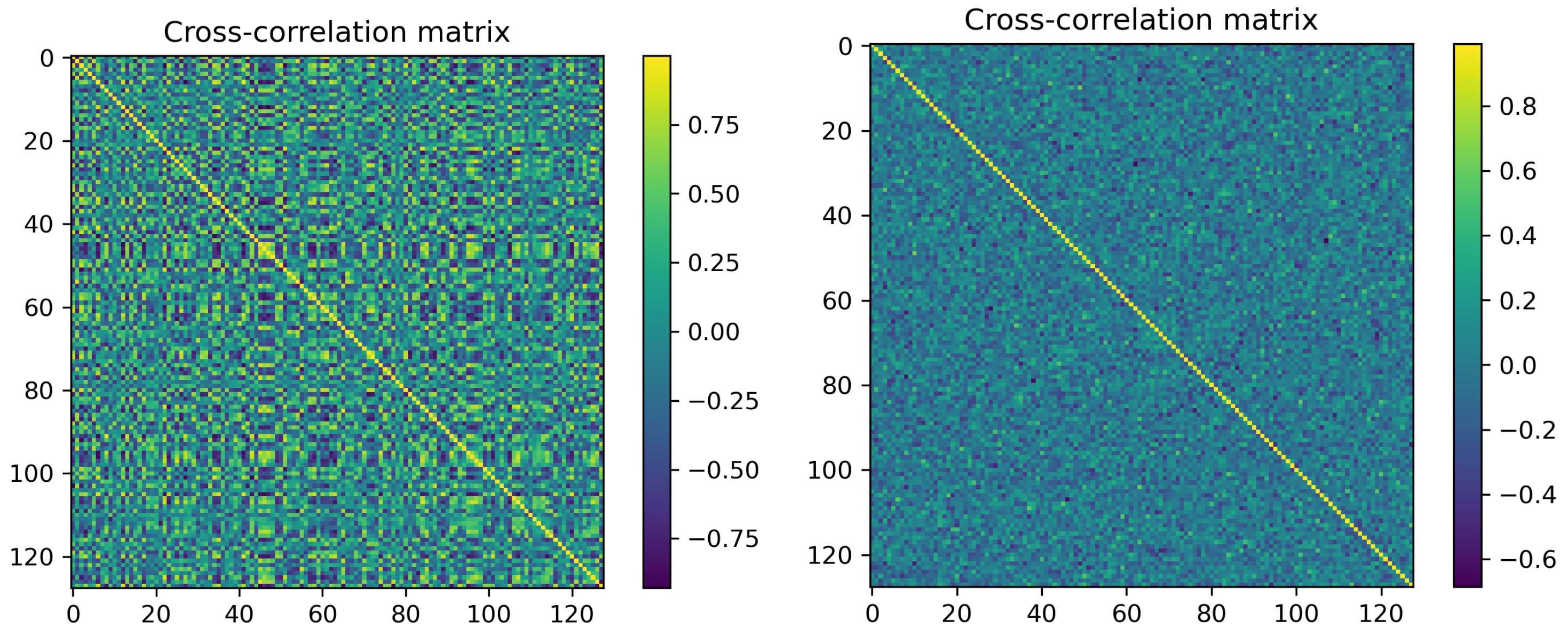
3.2. Can Enforcing Redundancy Reduction and Invariance Result in Disentanglement?
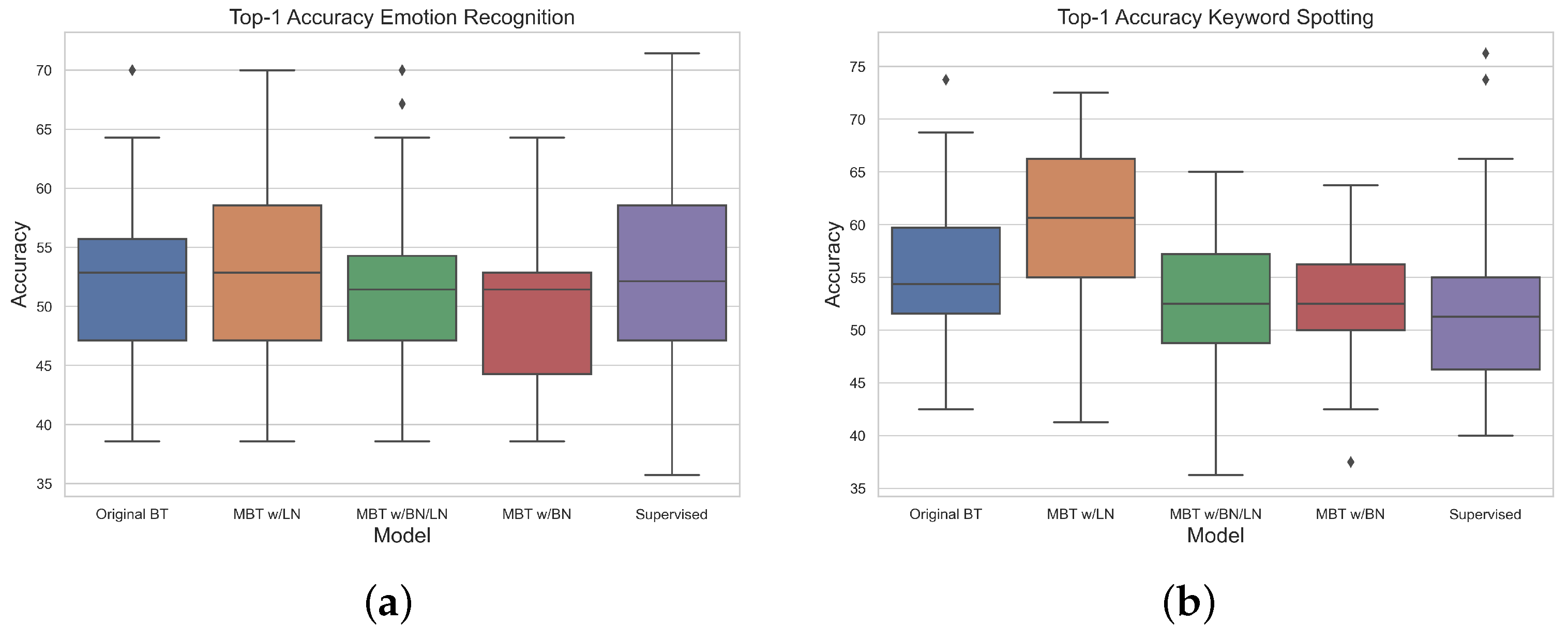
3.3. Ablation of Loss Function Variants
4. Discussion
4.1. Generalization in Downstream Tasks
4.2. Disentanglement of Latent Representations
4.3. Inconsistencies across Different Tasks
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Togneri, R.; Pullella, D. An overview of speaker identification: Accuracy and robustness issues. IEEE Circuits Syst. Mag. 2011, 11, 23–61. [Google Scholar] [CrossRef]
- Tirumala, S.S.; Shahamiri, S.R. A review on deep learning approaches in speaker identification. In Proceedings of the 8th International Conference on Signal Processing Systems, Auckland, New Zealand, 21–24 November 2016; pp. 142–147. [Google Scholar]
- Lukic, Y.; Vogt, C.; Dürr, O.; Stadelmann, T. Speaker identification and clustering using convolutional neural networks. In Proceedings of the 2016 IEEE 26th International Workshop on Machine Learning for Signal Processing (MLSP), Salerno, Italy, 13–16 September 2016; pp. 1–6. [Google Scholar]
- Trong, T.N.; Hautamäki, V.; Lee, K.A. Deep Language: A comprehensive deep learning approach to end-to-end language recognition. In Odyssey; Harper and Row Publishers Inc.: San Francisco, CA, USA, 2016; Volume 2016, pp. 109–116. [Google Scholar]
- Adaloglou, N.; Chatzis, T.; Papastratis, I.; Stergioulas, A.; Papadopoulos, G.T.; Zacharopoulou, V.; Xydopoulos, G.J.; Atzakas, K.; Papazachariou, D.; Daras, P. A comprehensive study on deep learning-based methods for sign language recognition. IEEE Trans. Multimed. 2021, 24, 1750–1762. [Google Scholar] [CrossRef]
- Bhangale, K.B.; Mohanaprasad, K. A review on speech processing using machine learning paradigm. Int. J. Speech Technol. 2021, 24, 367–388. [Google Scholar] [CrossRef]
- Mohamed, A.; Lee, H.Y.; Borgholt, L.; Havtorn, J.D.; Edin, J.; Igel, C.; Kirchhoff, K.; Li, S.W.; Livescu, K.; Maaløe, L.; et al. Self-supervised speech representation learning: A review. IEEE J. Sel. Top. Signal Process. 2022, 16, 1179–1210. [Google Scholar] [CrossRef]
- Kemp, T.; Waibel, A. Unsupervised training of a speech recognizer: Recent experiments. In Proc. EUROSPEECH; 1999; Available online: https://isl.anthropomatik.kit.edu/pdf/Kemp1999.pdf (accessed on 22 January 2024).
- Lamel, L.; Gauvain, J.L.; Adda, G. Lightly supervised and unsupervised acoustic model training. Comput. Speech Lang. 2002, 16, 115–129. [Google Scholar] [CrossRef]
- Oord, A.v.d.; Li, Y.; Vinyals, O. Representation learning with contrastive predictive coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- Chung, Y.A.; Hsu, W.N.; Tang, H.; Glass, J. An unsupervised autoregressive model for speech representation learning. arXiv 2019, arXiv:1904.03240. [Google Scholar]
- Barlow, H. Redundancy reduction revisited. Netw. Comput. Neural Syst. 2001, 12, 241. [Google Scholar] [CrossRef]
- Zbontar, J.; Jing, L.; Misra, I.; LeCun, Y.; Deny, S. Barlow twins: Self-supervised learning via redundancy reduction. In Proceedings of the International Conference on Machine Learning, Virtual Event, 18–24 July 2021; pp. 12310–12320. [Google Scholar]
- Liu, X.; Zhang, F.; Hou, Z.; Mian, L.; Wang, Z.; Zhang, J.; Tang, J. Self-supervised learning: Generative or contrastive. IEEE Trans. Knowl. Data Eng. 2021, 35, 857–876. [Google Scholar] [CrossRef]
- Liu, S.; Mallol-Ragolta, A.; Parada-Cabaleiro, E.; Qian, K.; Jing, X.; Kathan, A.; Hu, B.; Schuller, B.W. Audio self-supervised learning: A survey. Patterns 2022, 3, 100616. [Google Scholar] [CrossRef]
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Maschinot, A.; Liu, C.; Krishnan, D. Supervised contrastive learning. Adv. Neural Inf. Process. Syst. 2020, 33, 18661–18673. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, Virtual Event, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- Grill, J.B.; Strub, F.; Altché, F.; Tallec, C.; Richemond, P.; Buchatskaya, E.; Doersch, C.; Avila Pires, B.; Guo, Z.; Gheshlaghi Azar, M.; et al. Bootstrap your own latent-a new approach to self-supervised learning. Adv. Neural Inf. Process. Syst. 2020, 33, 21271–21284. [Google Scholar]
- Caron, M.; Misra, I.; Mairal, J.; Goyal, P.; Bojanowski, P.; Joulin, A. Unsupervised learning of visual features by contrasting cluster assignments. Adv. Neural Inf. Process. Syst. 2020, 33, 9912–9924. [Google Scholar]
- Koch, G.; Zemel, R.; Salakhutdinov, R. Siamese neural networks for one-shot image recognition. In Proceedings of the ICML Deep Learning Workshop, Lille, France, 6–11 July 2015; Volume 2. [Google Scholar]
- Baevski, A.; Zhou, Y.; Mohamed, A.; Auli, M. wav2vec 2.0: A framework for self-supervised learning of speech representations. Adv. Neural Inf. Process. Syst. 2020, 33, 12449–12460. [Google Scholar]
- Hsu, W.N.; Bolte, B.; Tsai, Y.H.H.; Lakhotia, K.; Salakhutdinov, R.; Mohamed, A. Hubert: Self-supervised speech representation learning by masked prediction of hidden units. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 3451–3460. [Google Scholar] [CrossRef]
- Nagrani, A.; Chung, J.S.; Xie, W.; Zisserman, A. Voxceleb: Large-scale speaker verification in the wild. Comput. Speech Lang. 2020, 60, 101027. [Google Scholar] [CrossRef]
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An asr corpus based on public domain audio books. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Australia, 19–24 April 2015; pp. 5206–5210. [Google Scholar]
- Warden, P. Speech commands: A dataset for limited-vocabulary speech recognition. arXiv 2018, arXiv:1804.03209. [Google Scholar]
- Emotional voice conversion: Theory, databases and ESD. Speech Commun. 2022, 137, 1–18. [CrossRef]
- American Rhetoric Online Speech Bank. World Leaders Address the U.S. Congress. 2011. Available online: https://www.americanrhetoric.com/speechbank.htm (accessed on 22 January 2024).
- Chen, R.T.; Li, X.; Grosse, R.B.; Duvenaud, D.K. Isolating sources of disentanglement in variational autoencoders. Adv. Neural Inf. Process. Syst. 2018, 31. [Google Scholar]
- Do, K.; Tran, T. Theory and evaluation metrics for learning disentangled representations. arXiv 2019, arXiv:1908.09961. [Google Scholar]
- Sepliarskaia, A.; Kiseleva, J.; de Rijke, M. How to not measure disentanglement. arXiv 2019, arXiv:1910.05587. [Google Scholar]
- Kumar, A.; Sattigeri, P.; Balakrishnan, A. Variational inference of disentangled latent concepts from unlabeled observations. arXiv 2017, arXiv:1711.00848. [Google Scholar]
- Ridgeway, K.; Mozer, M.C. Learning deep disentangled embeddings with the f-statistic loss. Adv. Neural Inf. Process. Syst. 2018, 31. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Source | Dataset Name | # Samples | # Classes | Duration (h) | Usage |
|---|---|---|---|---|---|
| [23] | VoxCeleb-1 | 148,642 | 1211 | 340.39 | Upstream |
| [24] | LibriSpeech-100 | 14,385 | 128 | 100 | Upstream |
| [24] | LibriSpeech-360 | 104,935 | 921 | 360 | Upstream |
| [25] | Speech Commands | 7985 | 2 | 2.18 | Downstream |
| [26] | ESD | 7000 | 2 | 5.52 | Downstream |
| [27] | WLUC | 7500 | 5 | 2.05 | Downstream |
| Fraction (%) | Supervised | LibriSpeech-100 | LibriSpeech-360 | VoxCeleb1 | |
|---|---|---|---|---|---|
| SR | 5 | 34.21 | 39.47 | 28.95 | 36.84 |
| 10 | 54.67 | 64.00 | 54.67 | 48.00 | |
| 50 | 75.20 | 83.73 | 77.60 | 68.00 | |
| 100 | 84.53 | 84.93 | 81.20 | 75.07 | |
| GR | 5 | 66.67 | 70.00 | 63.33 | 66.67 |
| 10 | 75.00 | 71.67 | 75.00 | 68.33 | |
| 50 | 79.67 | 88.67 | 87.00 | 78.33 | |
| 100 | 62.67 | 90.17 | 88.67 | 84.67 | |
| KWS | 5 | 47.50 | 52.50 | 62.50 | 45.00 |
| 10 | 51.25 | 52.50 | 50.00 | 50.00 | |
| 50 | 50.76 | 55.33 | 52.28 | 47.72 | |
| 100 | 50.32 | 75.03 | 60.08 | 53.99 | |
| ER | 5 | 48.57 | 54.29 | 51.43 | 68.57 |
| 10 | 61.43 | 47.14 | 44.29 | 50.00 | |
| 50 | 46.57 | 46.29 | 50.86 | 48.86 | |
| 100 | 83.00 | 59.00 | 51.00 | 46.29 |
| Compactness | Holistic | Modularity | |||
|---|---|---|---|---|---|
| Model | MIG | SAP | DCIMIG | JEMMIG | Mod. Score |
| BT-16 | |||||
| BT-32 | |||||
| BT-64 | |||||
| BT-128 | |||||
| BT-512 | |||||
| BT-1024 | |||||
| BT-2048 | |||||
| BT-LS-100 | |||||
| BT-LS-360 | |||||
| BT-VC-1 | |||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Brima, Y.; Krumnack, U.; Pika, S.; Heidemann, G. Understanding Self-Supervised Learning of Speech Representation via Invariance and Redundancy Reduction. Information 2024, 15, 114. https://doi.org/10.3390/info15020114
Brima Y, Krumnack U, Pika S, Heidemann G. Understanding Self-Supervised Learning of Speech Representation via Invariance and Redundancy Reduction. Information. 2024; 15(2):114. https://doi.org/10.3390/info15020114
Chicago/Turabian StyleBrima, Yusuf, Ulf Krumnack, Simone Pika, and Gunther Heidemann. 2024. "Understanding Self-Supervised Learning of Speech Representation via Invariance and Redundancy Reduction" Information 15, no. 2: 114. https://doi.org/10.3390/info15020114
APA StyleBrima, Y., Krumnack, U., Pika, S., & Heidemann, G. (2024). Understanding Self-Supervised Learning of Speech Representation via Invariance and Redundancy Reduction. Information, 15(2), 114. https://doi.org/10.3390/info15020114