
Few-Shot Methods for Aspect-Level Sentiment Analysis


Abstract
1. Introduction
1.1. Cross-Domain Sentiment Analysis
- Domain-dependent expressions. Each domain has its own set of domain-specific words and phrases. A word with a positive sentiment in one domain might be neutral or negative in another. This difference in vocabulary makes it hard for models trained on one domain to accurately interpret sentiment in another [2]. This challenge is also called sparsity [3].
- Context variation. A phrase that indicates positive sentiment in one domain might be interpreted differently in another due to changes in context. For instance, ‘‘easy’’ could be positive in one domain but negative in another, called polarity divergence in [3].
1.2. Aspect-Based Sentiment Analysis (ABSA)
1.3. Few-Shot
- Support set: A labelled sample of novel data type, which a pre-trained model will use to generalize from to classify examples in the query set.
- Query set: This consists of the unlabelled samples for evaluation; it may contain both the new and old types of data on which the model needs to generalize using previously acquired knowledge and information gained from the support set.
1.4. Motivation
- What is the cross-domain performance of large language models fine-tuned on aspect-level sentiment analysis task?
- What is the performance of further fine-tuning such models using traditional gradient-based learning on small labelled samples in the target domain?
- What is the performance of dedicated few-shot methods, when applied to models fine-tuned on aspect-level sentiment analysis data from other domains, using small labelled samples in the target domain?
2. Data
2.1. AspectEmo
- The school subcorpus consists of 1000 documents (94,642 tokens, approximately 95 tokens per text). Texts come from a discussion forum and are opinions on university courses and lecturers.
- The medicine subcorpus consists of 3510 documents (478,505 tokens, approximately 136 tokens per text). The texts were typed by patients on a website intended to help patients find a good doctor.
- The hotels subcorpus consists of 4200 documents (578,259 tokens, approximately 137 tokens per text). Texts originate from the English version of tripadvisor.com.
- The products subcorpus consists of 1000 documents (135,217 tokens, approximately 135 tokens per text). The texts come from a price comparison website.
2.2. Few-Shot Cross-Domain Samples
- Fitness clubs (51);
- Movies (68);
- Restaurants (65).
3. Methods
- Training the base model in the source domain on the AspectEmo dataset (AspectEmo-HerBERT).
- Testing on the target domain using various methods, including domain adaptation and few-shot learning solutions.
3.1. AspectEmo-HerBERT
3.2. Gradient-Based Supervised Learning
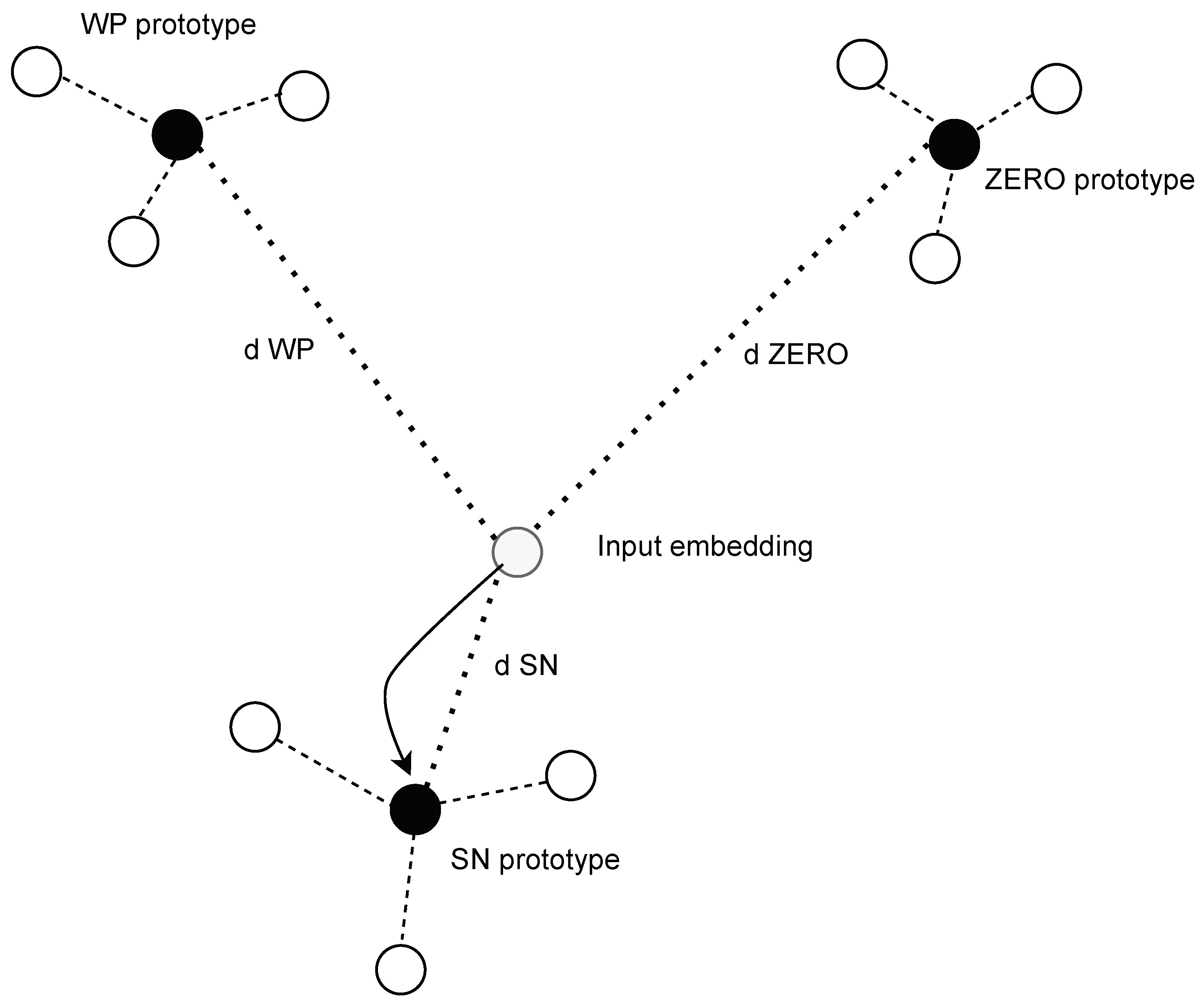
3.3. ProtoNet
- Support set—Based on this set, we count the representations of the embedding vector for each class (e.g., WP prototype, ZERO prototype, etc.) as the average of the embeddings of tokens belonging to a given class in the set S. This is an analogy to the training set.
- Query set—The evaluation of tokens in this set is carried out in a manner similar to that of nearest neighbours in relation to prototypes: by counting the distance of each embedding from the query set to the prototype embeddings of classes calculated on the support set.
3.4. NNShot
4. Results
4.1. Zero-Shot Setting
4.2. Gradient-Based Supervised Learning
4.3. ProtoNet
4.4. NNShot
5. Discussion
6. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, A.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; Bowman, S. GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, Brussels, Belgium, 2–4 November 2018; Linzen, T., Chrupała, G., Alishahi, A., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 353–355. [Google Scholar] [CrossRef]
- Save, A.; Shekokar, N. Analysis of cross domain sentiment techniques. In Proceedings of the 2017 International Conference on Electrical, Electronics, Communication, Computer, and Optimization Techniques (ICEECCOT), Mysuru, India, , 15–16 December 2017; pp. 1–9. [Google Scholar] [CrossRef]
- Al-Moslmi, T.; Omar, N.; Abdullah, S.; Albared, M. Approaches to Cross-Domain Sentiment Analysis: A Systematic Literature Review. IEEE Access 2017, 5, 16173–16192. [Google Scholar] [CrossRef]
- Pan, S.J.; Ni, X.; Sun, J.T.; Yang, Q.; Chen, Z. Cross-domain sentiment classification via spectral feature alignment. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; pp. 751–760. [Google Scholar]
- Blitzer, J.; Dredze, M.; Pereira, F. Biographies, bollywood, boom-boxes and blenders: Domain adaptation for sentiment classification. In Proceedings of the 45th Annual Meeting of the Association of Computational Linguistics, Prague, Czech Public, 25–27 June 2007; pp. 440–447. [Google Scholar]
- Luo, Y.; Guo, F.; Liu, Z.; Zhang, Y. Mere Contrastive Learning for Cross-Domain Sentiment Analysis. In Proceedings of the 29th International Conference on Computational Linguistics, Gyeongju, Republic of Korea, 12–17 October 2022; Calzolari, N., Huang, C.R., Kim, H., Pustejovsky, J., Wanner, L., Choi, K.S., Ryu, P.M., Chen, H.H., Donatelli, L., Ji, H., et al., Eds.; International Committee on Computational Linguistics: New York, NY, USA, 2022; pp. 7099–7111. [Google Scholar]
- Wu, H.; Shi, X. Adversarial Soft Prompt Tuning for Cross-Domain Sentiment Analysis. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022; Muresan, S., Nakov, P., Villavicencio, A., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2022; pp. 2438–2447. [Google Scholar] [CrossRef]
- Socher, R.; Perelygin, A.; Wu, J.; Chuang, J.; Manning, C.D.; Ng, A.; Potts, C. Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; Yarowsky, D., Baldwin, T., Korhonen, A., Livescu, K., Bethard, S., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2013; pp. 1631–1642. [Google Scholar]
- Hu, M.; Liu, B. Mining and summarizing customer reviews. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD-2004), Seattle, WA, USA, 22–25 August 2004. [Google Scholar]
- Yuan, S.; Li, M.; Du, Y.; Xie, Y. Cross-domain aspect-based sentiment classification with hybrid prompt. Expert Syst. Appl. 2024, 255, 124680. [Google Scholar] [CrossRef]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. In Proceedings of the Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 1877–1901. [Google Scholar]
- Varia, S.; Wang, S.; Halder, K.; Vacareanu, R.; Ballesteros, M.; Benajiba, Y.; Anna John, N.; Anubhai, R.; Muresan, S.; Roth, D. Instruction Tuning for Few-Shot Aspect-Based Sentiment Analysis. In Proceedings of the 13th Workshop on Computational Approaches to Subjectivity, Sentiment, & Social Media Analysis, Toronto, ON, Canada, 14 July 2023; pp. 19–27. [Google Scholar] [CrossRef]
- Snell, J.; Swersky, K.; Zemel, R. Prototypical Networks for Few-shot Learning. In Proceedings of the Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Kocoń, J.; Radom, J.; Kaczmarz-Wawryk, E.; Wabnic, K.; Zajączkowska, A.; Zaśko-Zielińska, M. Aspectemo: Multi-domain corpus of consumer reviews for aspect-based sentiment analysis. In Proceedings of the 2021 International Conference on Data Mining Workshops (ICDMW), Auckland, New Zealand, 7–10 December 2021; pp. 166–173. [Google Scholar]
- Mroczkowski, R.; Rybak, P.; Wróblewska, A.; Gawlik, I. HerBERT: Efficiently Pretrained Transformer-based Language Model for Polish. In Proceedings of the 8th Workshop on Balto-Slavic Natural Language Processing, Kiyv, Ukraine, 20 April 2021; pp. 1–10. [Google Scholar]
- Ding, N.; Xu, G.; Chen, Y.; Wang, X.; Han, X.; Xie, P.; Zheng, H.; Liu, Z. Few-NERD: A Few-shot Named Entity Recognition Dataset. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021; pp. 3198–3213. [Google Scholar] [CrossRef]
- Yang, Y.; Katiyar, A. Simple and Effective Few-Shot Named Entity Recognition with Structured Nearest Neighbor Learning. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 6365–6375. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
| Label | Desciption | # of Tokens |
|---|---|---|
| SN | strong negative | 8046 |
| WN | weak negative | 933 |
| ZERO | neutral | 6685 |
| WP | weak positive | 855 |
| SP | strong positive | 9109 |
| AMB | ambiguous | 744 |
| Our Model | Reported in [14] | |
|---|---|---|
| AMB | 11.29 | 15.65 |
| SN | 59.64 | 64.87 |
| SP | 72.44 | 77.42 |
| WP | 26.09 | 28.24 |
| WN | 25.37 | 28.85 |
| ZERO | 46.15 | 56.85 |
| Fitness | Movies | Restaurants | |
|---|---|---|---|
| AMB | 0 | 0 | 0 |
| SN | 0 | 0 | 0 |
| SP | 0 | 0 | 0 |
| WP | 0.02 | 0.03 | 0.03 |
| WN | 0.01 | 0.03 | 0.02 |
| ZERO | 0.02 | 0.02 | 0.03 |
| OVERALL | 0.04 | 0.04 | 0.03 |
| Fitness | Movies | Restaurants | |
|---|---|---|---|
| AMB | 0 | 0 | 0 |
| SN | 0.21 | 0.33 | 0 |
| SP | 0.18 | 0.32 | 0.26 |
| WP | 0.24 | 0 | 0.02 |
| WN | 0 | 0 | 0 |
| ZERO | 0 | 0 | 0 |
| OVERALL | 0.18 | 0.20 | 0.08 |
| Fitness | Movies | Restaurants | |
|---|---|---|---|
| AMB | 0.24 ± 0.05 | 0.04 ± 0.00 | 0.26 ± 0.06 |
| SN | 0.46 ± 0.1 | 0.28 ± 0.06 | 0.31 ± 0.07 |
| SP | 0.47 ± 0.1 | 0.36 ± 0.08 | 0.46 ± 0.1 |
| WP | 0.05 ± 0.01 | 0.16 ± 0.03 | 0.09 ± 0.02 |
| WN | 0.16 ± 0.03 | 0.12 ± 0.03 | 0.13 ± 0.03 |
| ZERO | 0.22 ± 0.04 | 0.17 ± 0.04 | 0.13 ± 0.03 |
| OVERALL | 0.34 ± 0.08 | 0.24 ± 0.05 | 0.31 ± 0.07 |
| Fitness | Movies | Restaurants | |
|---|---|---|---|
| AMB | 0.26 ± 0.06 | 0.04 ± 0.01 | 0.17 ± 0.04 |
| SN | 0.43 ± 0.1 | 0.36 ± 0.08 | 0.32 ± 0.07 |
| SP | 0.49 ± 0.1 | 0.42 ± 0.09 | 0.48 ± 0.1 |
| WP | 0.35 ± 0.08 | 0.19 ± 0.04 | 0.24 ± 0.05 |
| WN | 0.37 ± 0.08 | 0.22 ± 0.05 | 0.31 ± 0.07 |
| ZERO | 0.27 ± 0.06 | 0.26 ± 0.06 | 0.18 ± 0.04 |
| OVERALL | 0.4 ± 0.08 | 0.30 ± 0.07 | 0.33 ± 0.07 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wawer, A. Few-Shot Methods for Aspect-Level Sentiment Analysis. Information 2024, 15, 664. https://doi.org/10.3390/info15110664
Wawer A. Few-Shot Methods for Aspect-Level Sentiment Analysis. Information. 2024; 15(11):664. https://doi.org/10.3390/info15110664
Chicago/Turabian StyleWawer, Aleksander. 2024. "Few-Shot Methods for Aspect-Level Sentiment Analysis" Information 15, no. 11: 664. https://doi.org/10.3390/info15110664
APA StyleWawer, A. (2024). Few-Shot Methods for Aspect-Level Sentiment Analysis. Information, 15(11), 664. https://doi.org/10.3390/info15110664