

Benchmarking Automated Machine Learning (AutoML) Frameworks for Object Detection



Abstract
1. Introduction
“A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.”
2. Background and Related Works
2.1. Automated Machine Learning (AutoML)
2.2. Review of Benchmarking AutoML Frameworks and Object Detection
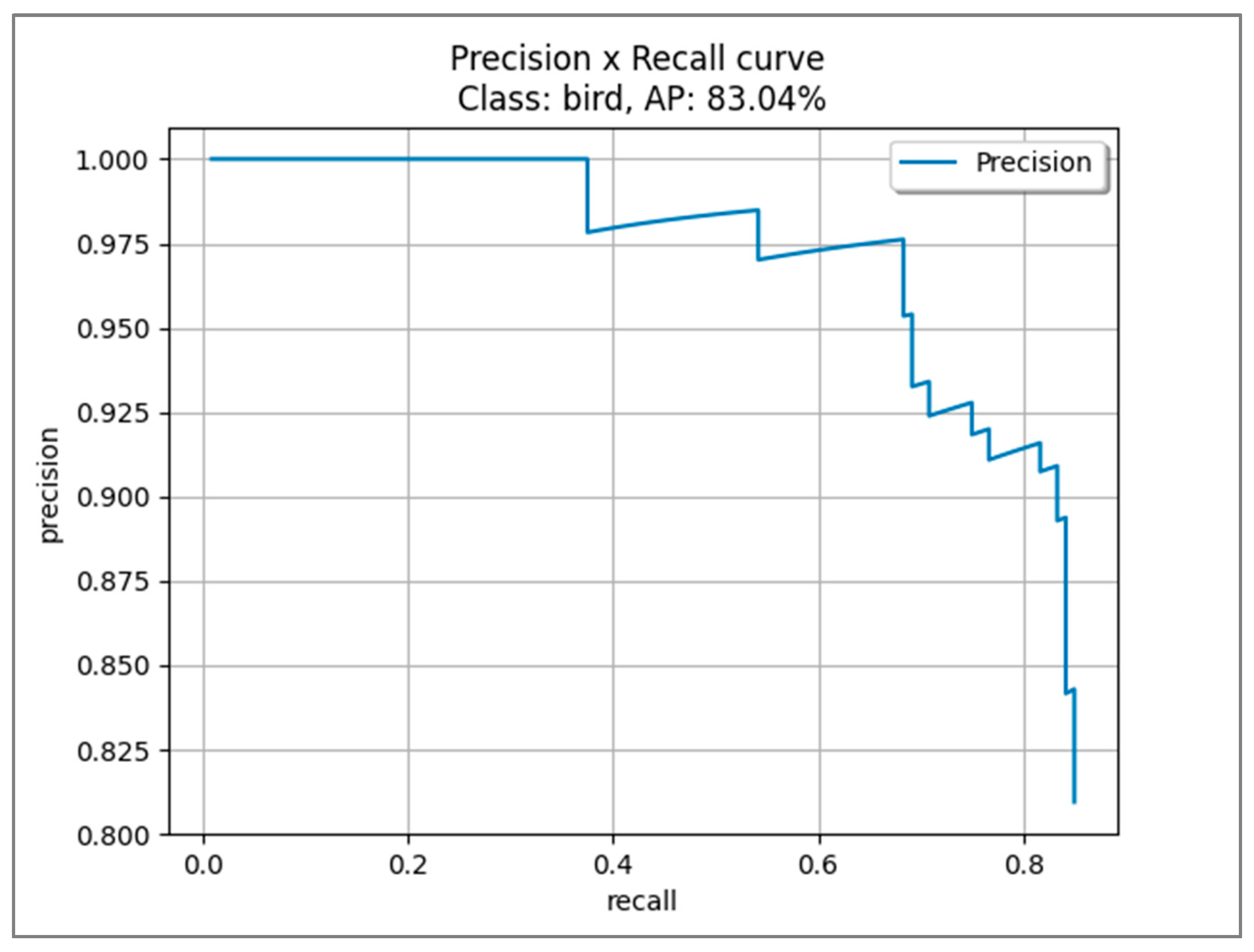
2.3. Metrics for Object Detection
3. Research Methodology
3.1. Selected AutoML Frameworks
3.1.1. TAO (NVIDIA)
3.1.2. AutoGluon
3.1.3. VertexAI (Google)
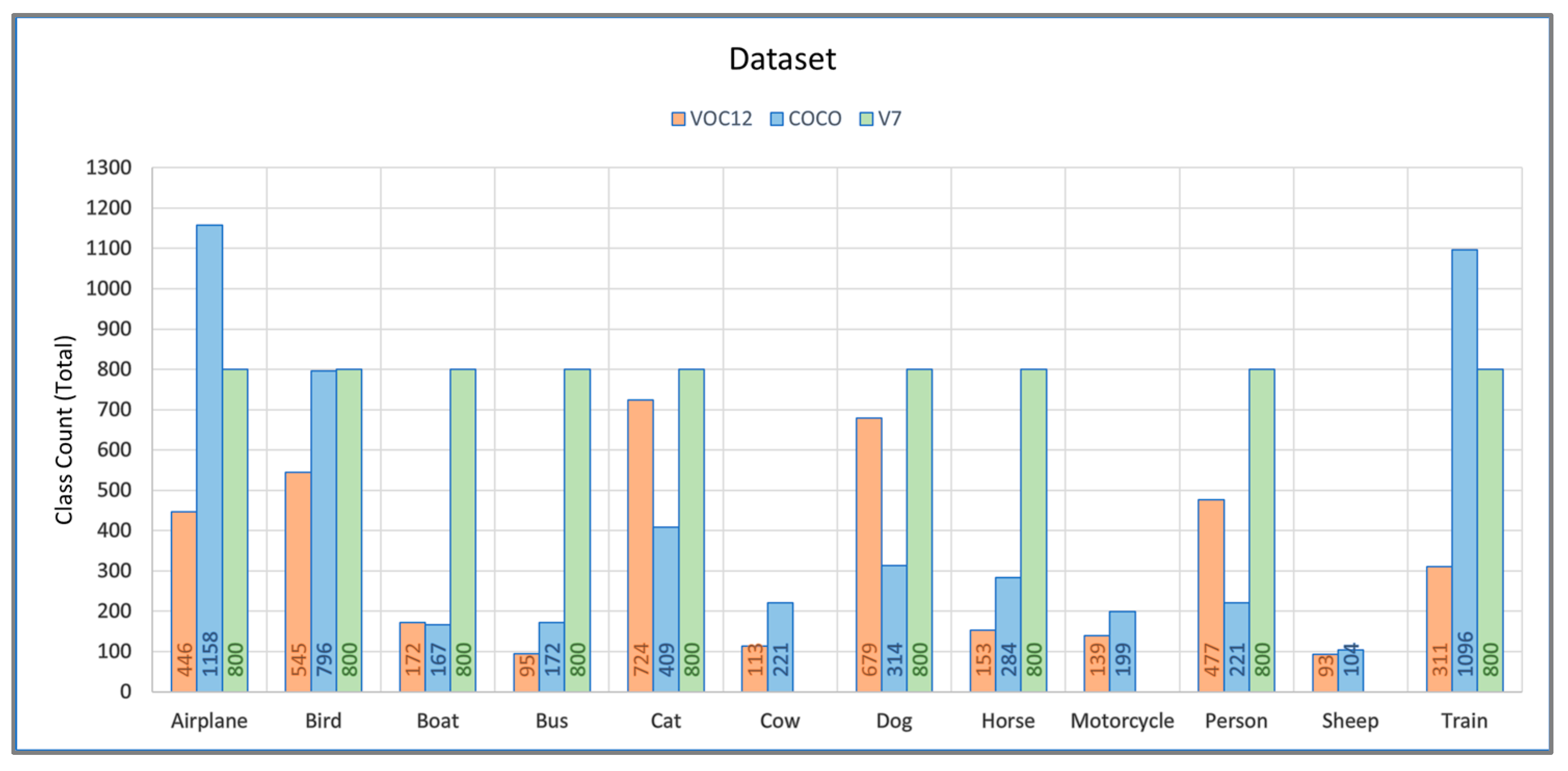
3.2. Datasets
3.2.1. COCO
3.2.2. Pascal VOC2012
3.2.3. Open Images V7
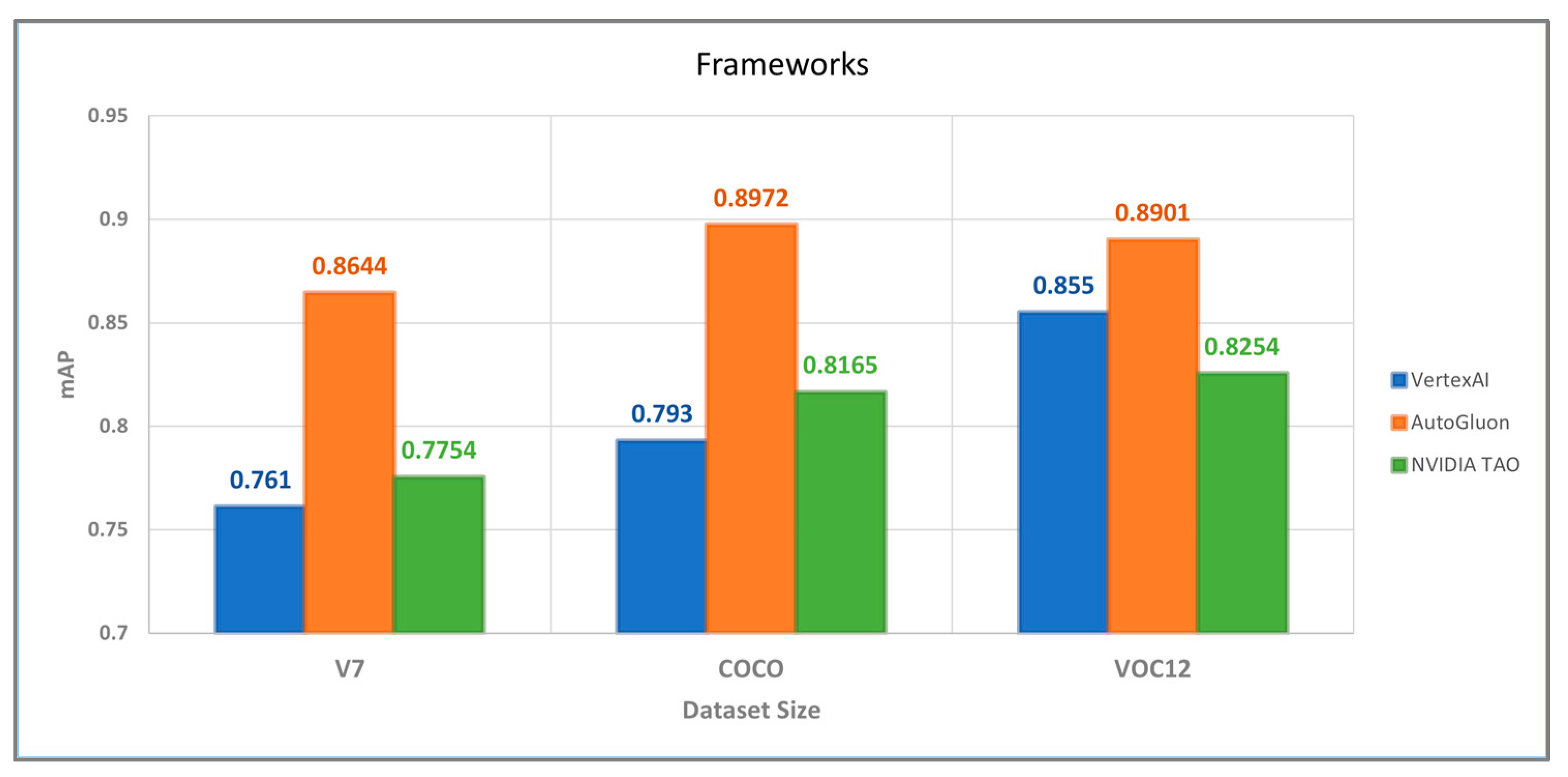
4. Results
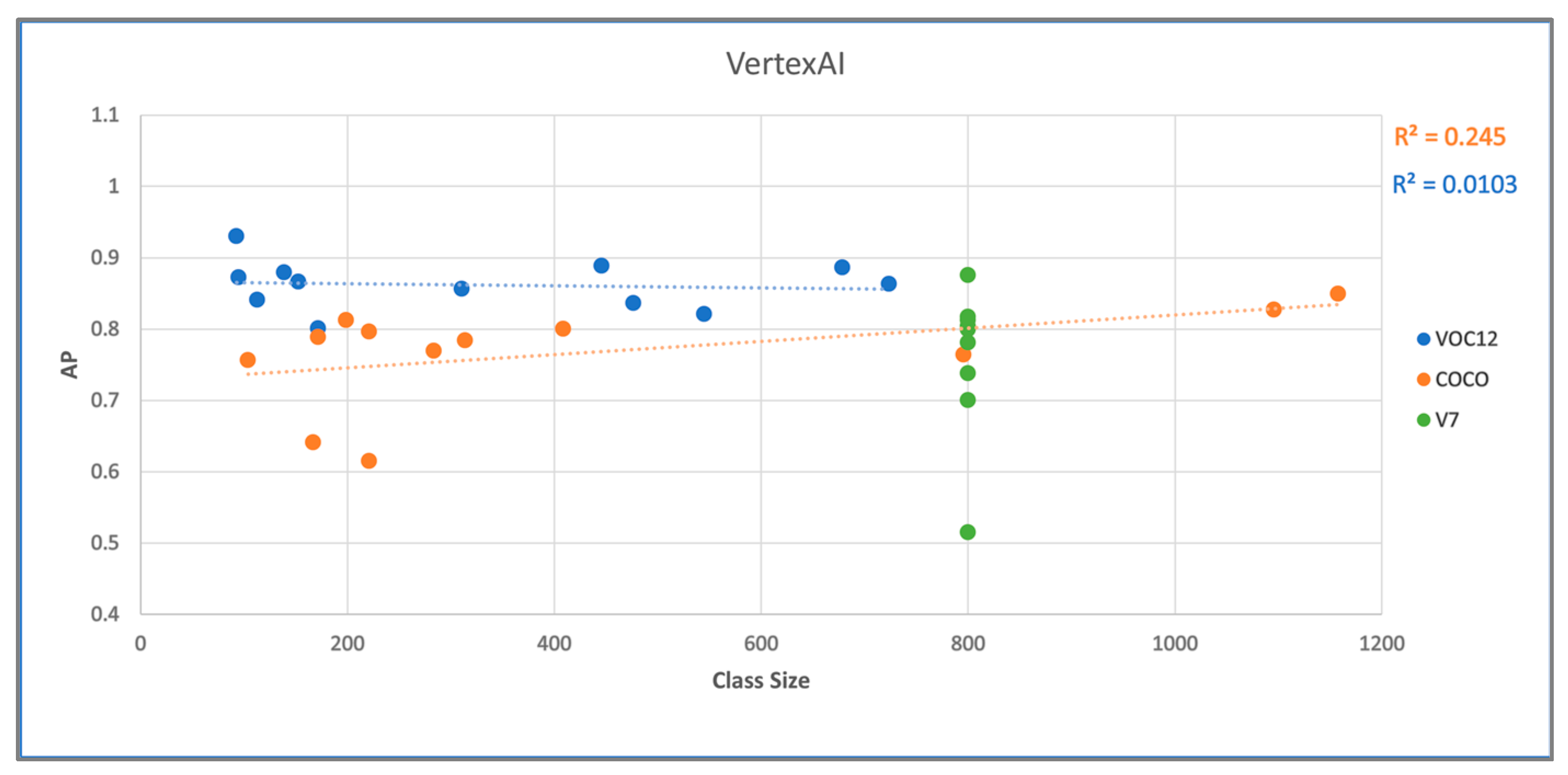
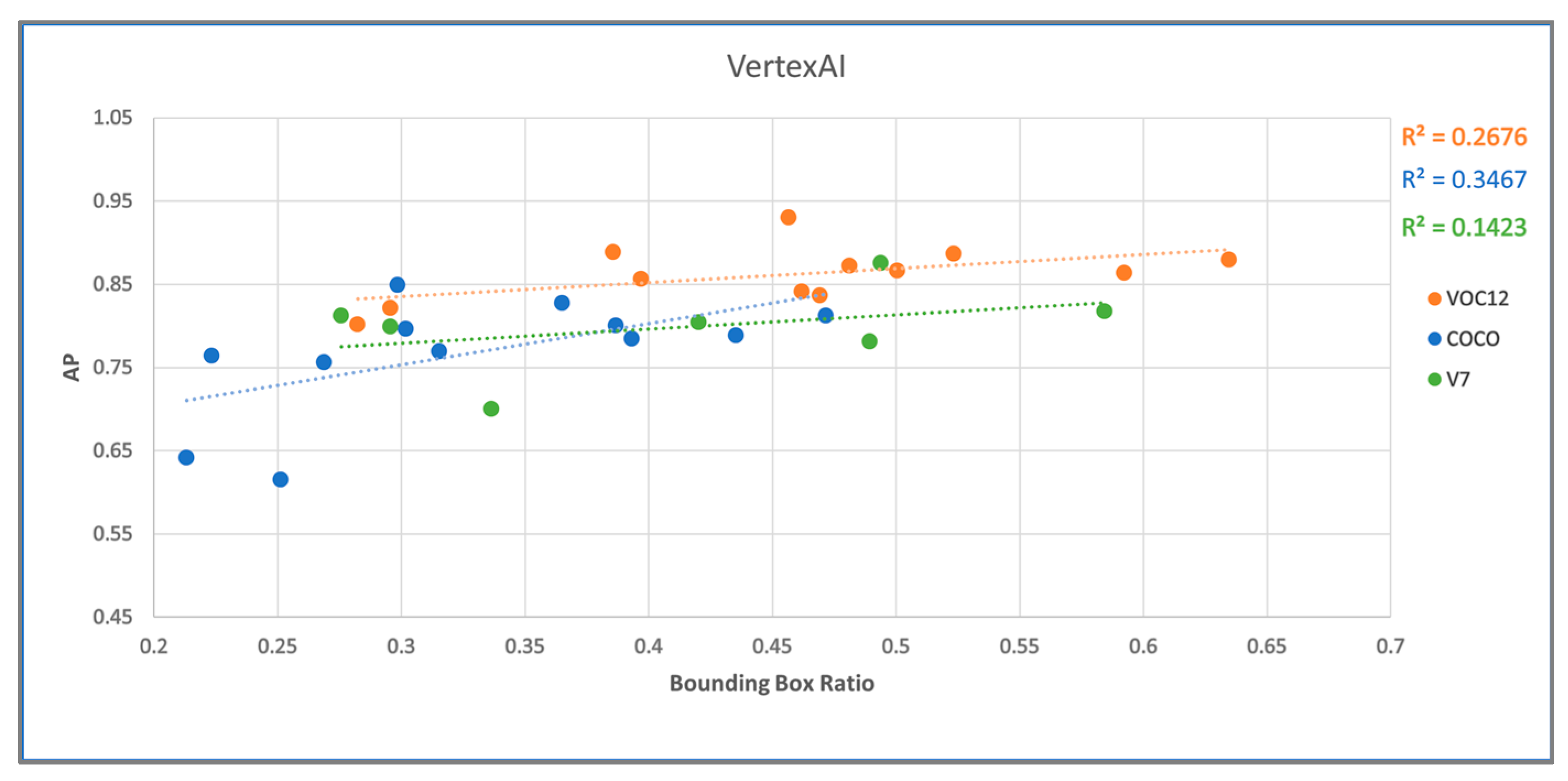
4.1. Vertex AI
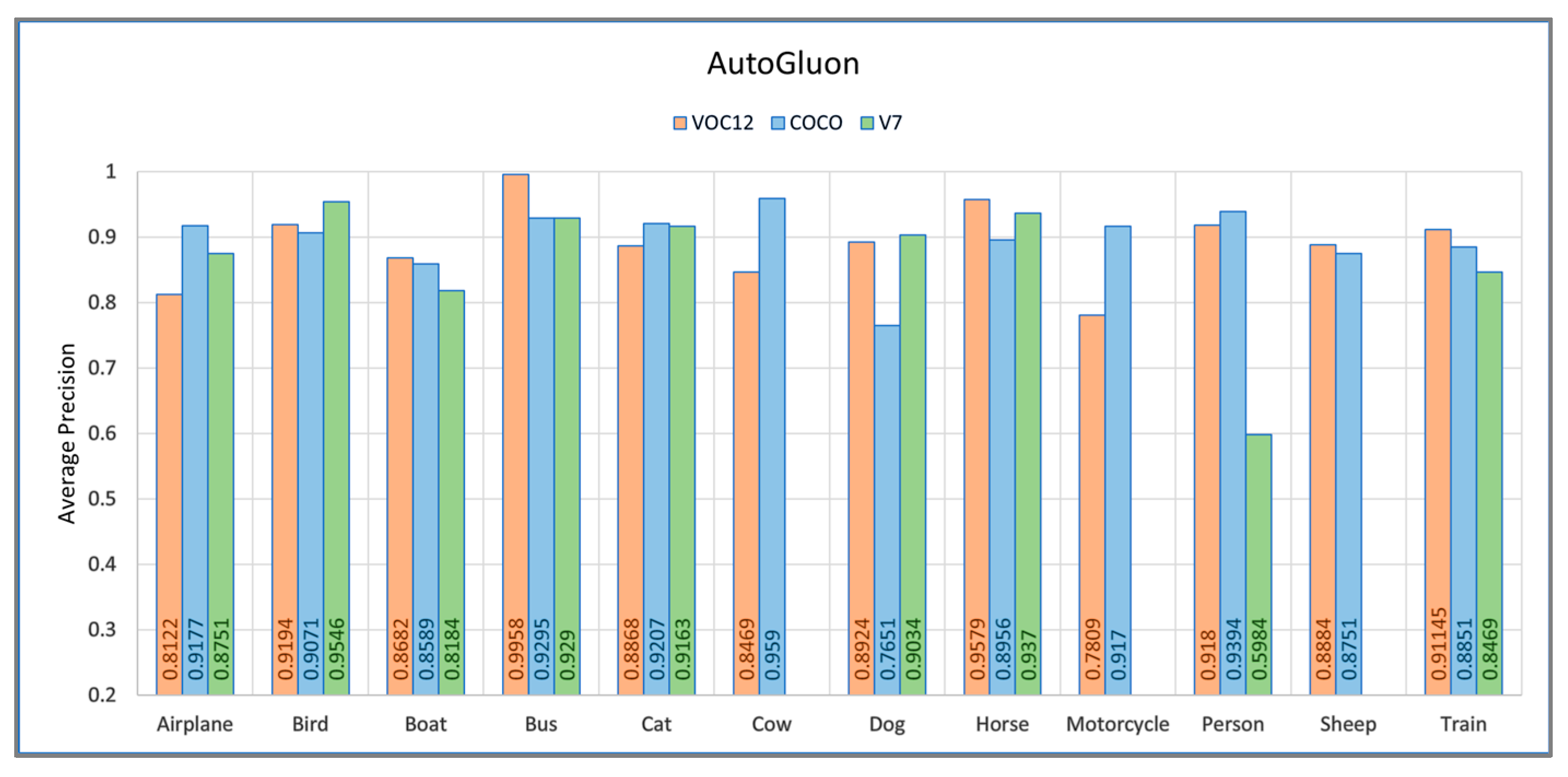
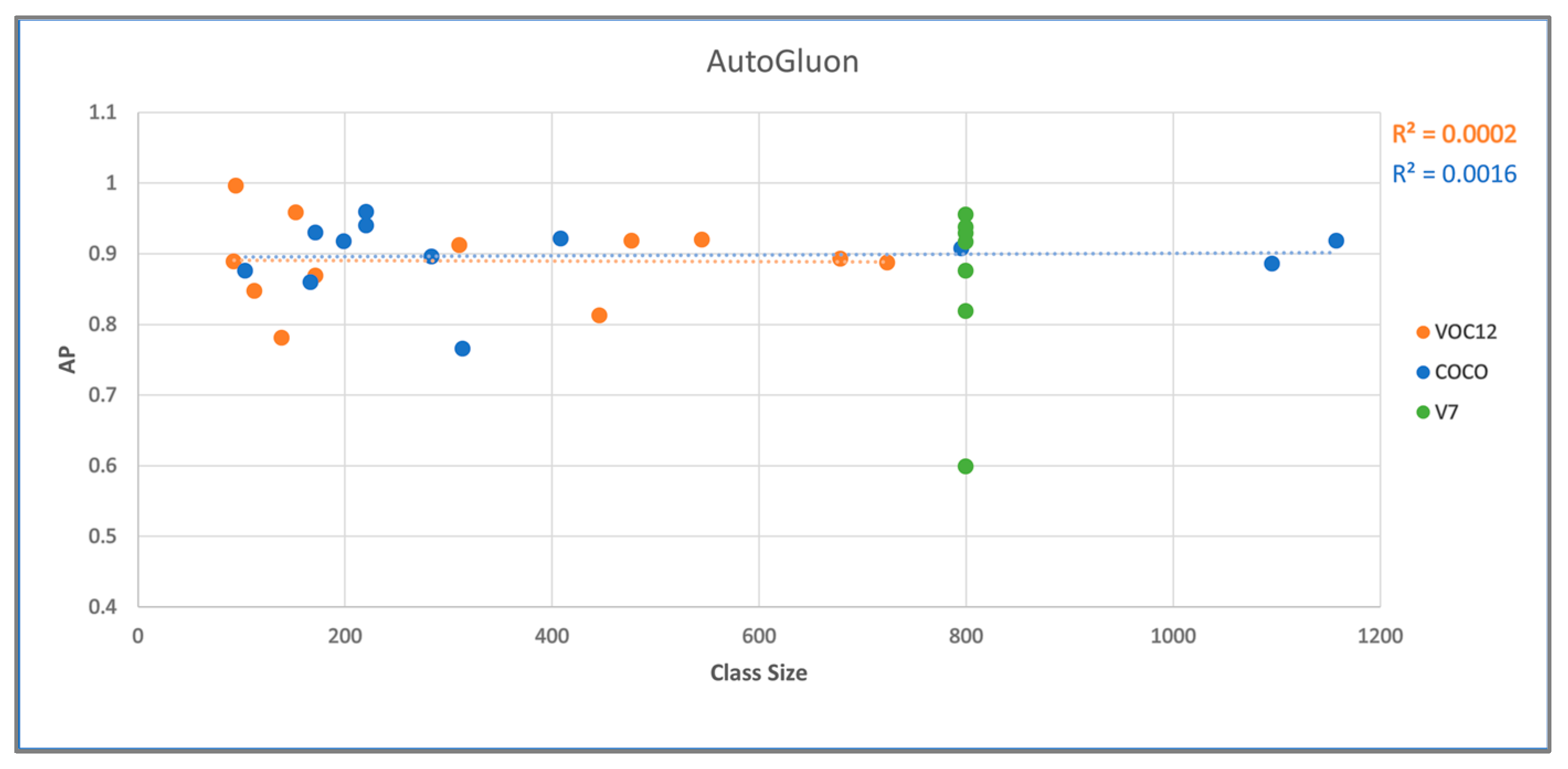
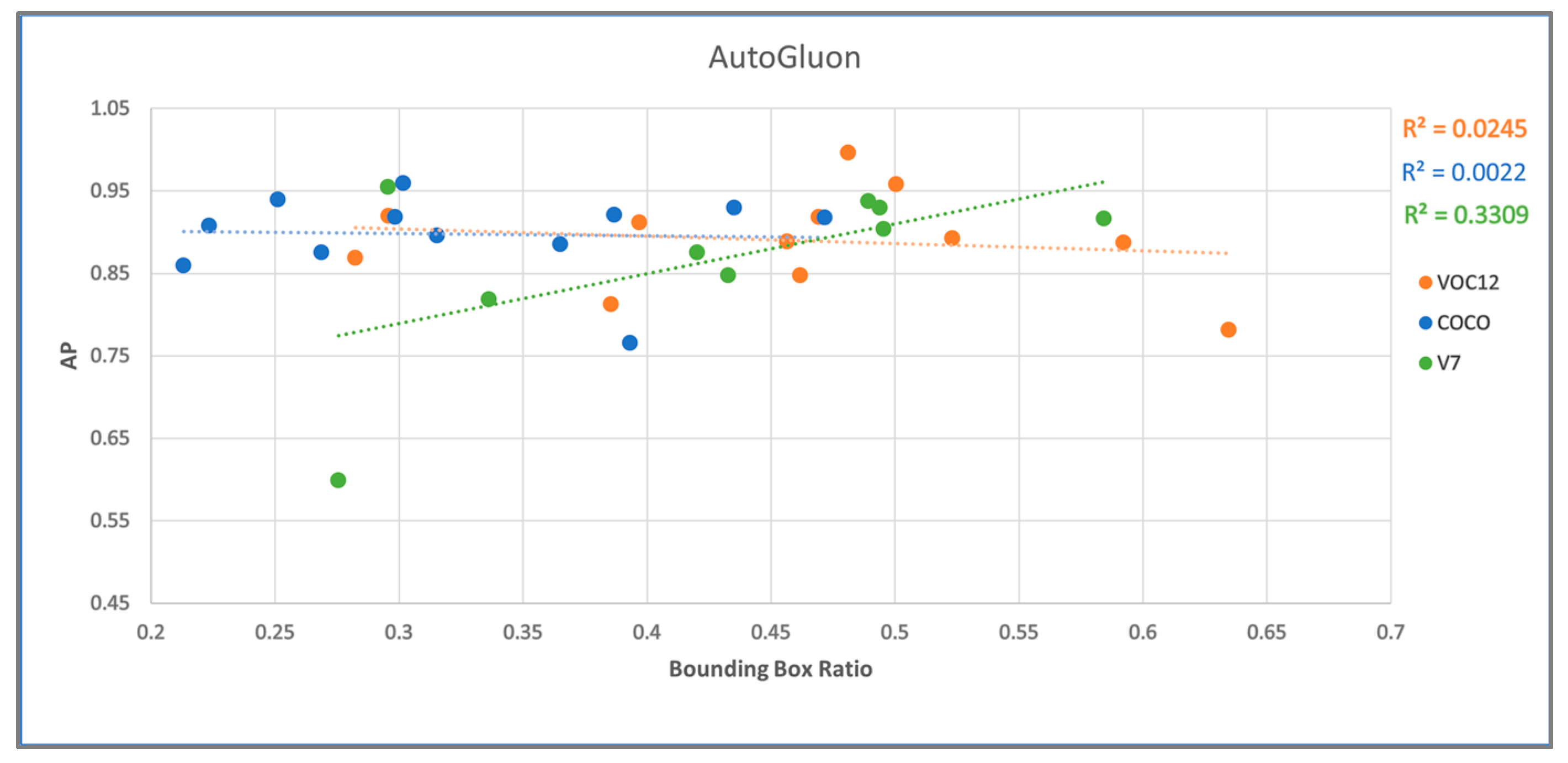
4.2. AutoGluon
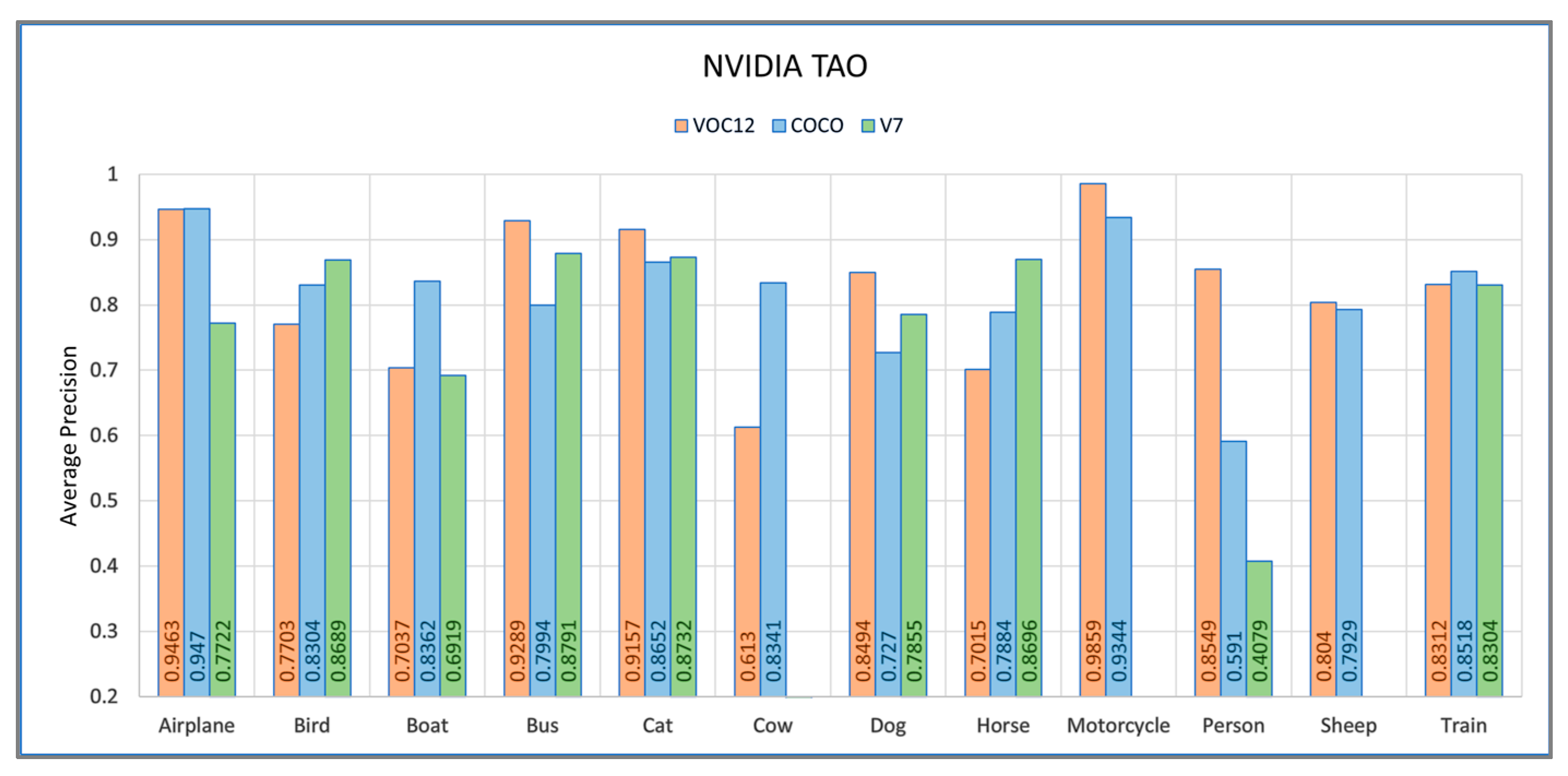
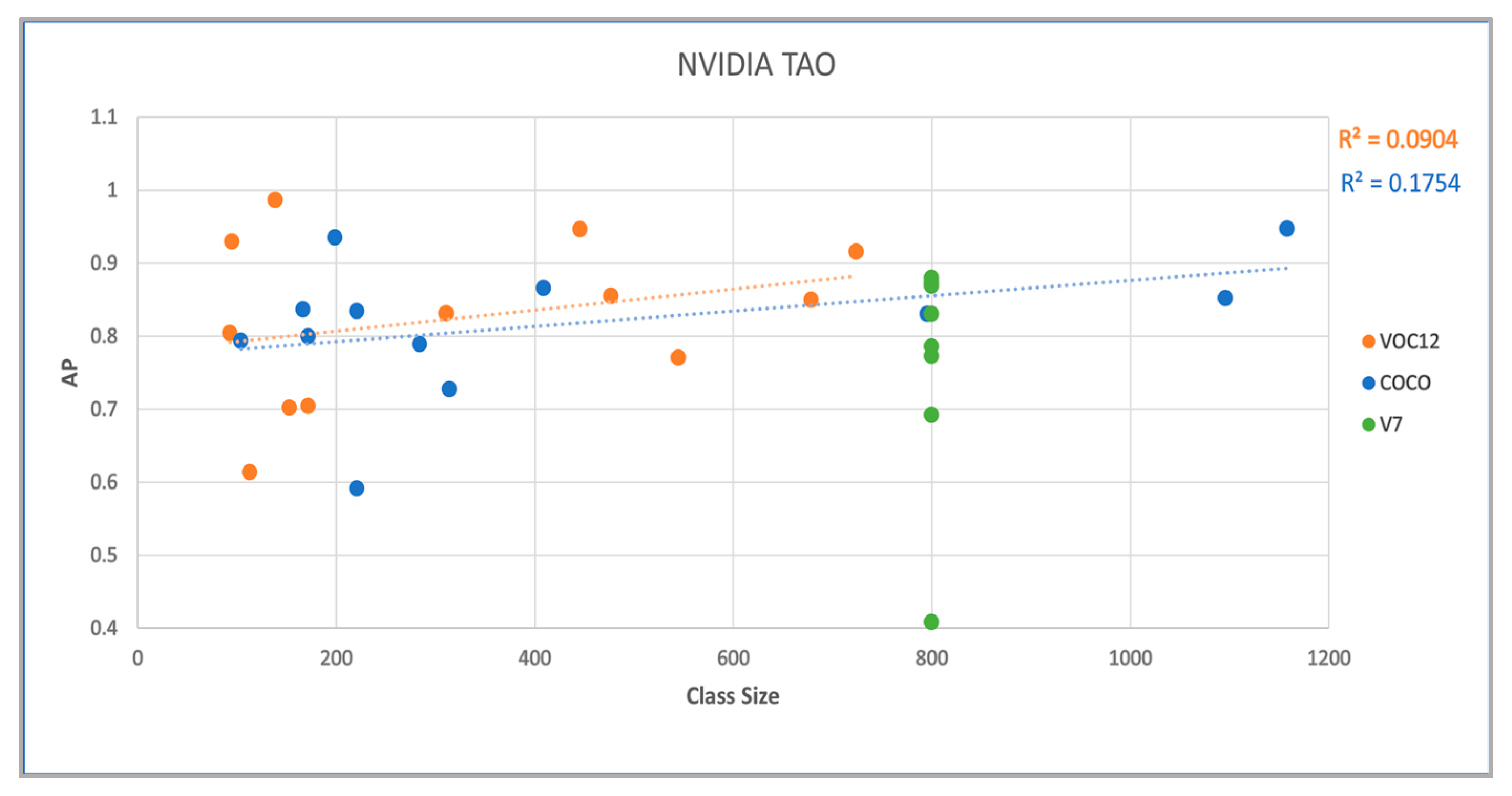
4.3. NVIDIA TAO
5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mitchell, T. Machine Learning; McGraw Hill: New York, NY, USA, 1997. [Google Scholar]
- Ahmad, M.; Aftab, S.; Muhammad, S.S.; Ahmad, S. Machine Learning Techniques for Sentiment Analysis: A Review. Int. J. Multidiscip. Sci. Eng. 2017, 8, 226. [Google Scholar]
- Zheng, R.; Qu, L.; Cui, B.; Shi, Y.; Yin, H. Automl for Deep Recommender Systems: A Survey. arXiv 2022, arXiv:220313922. [Google Scholar] [CrossRef]
- Kononenko, I. Machine Learning for Medical Diagnosis: History, State of the Art and Perspective. Artif. Intell. Med. 2001, 23, 89–109. [Google Scholar] [CrossRef] [PubMed]
- Garg, V.; Chaudhary, S.; Mishra, A. Analysing Auto ML Model for Credit Card Fraud Detection. Int. J. Innov. Res. Comput. Sci. Technol. 2021, 9, 2347–5552. [Google Scholar] [CrossRef]
- Shi, X.; Wong, Y.D.; Chai, C.; Li, M.Z.-F. An Automated Machine Learning (AutoML) Method of Risk Prediction for Decision-Making of Autonomous Vehicles. IEEE Trans. Intell. Transp. Syst. 2020, 22, 7145–7154. [Google Scholar] [CrossRef]
- Liakos, K.G.; Busato, P.; Moshou, D.; Pearson, S.; Bochtis, D. Machine Learning in Agriculture: A Review. Sensors 2018, 18, 2674. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Z.-Q.; Zheng, P.; Xu, S.; Wu, X. Object Detection with Deep Learning: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft Coco: Common Objects in Context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Padilla, R.; Passos, W.L.; Dias, T.L.; Netto, S.L.; Da Silva, E.A. A Comparative Analysis of Object Detection Metrics with a Companion Open-Source Toolkit. Electronics 2021, 10, 279. [Google Scholar] [CrossRef]
- Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J. Object Detection in 20 Years: A Survey. Proc. IEEE 2023, 111, 256–276. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 580–587. [Google Scholar]
- Yamashita, R.; Nishio, M.; Do, R.K.G.; Togashi, K. Convolutional Neural Networks: An Overview and Application in Radiology. Insights Imag. 2018, 9, 611–629. [Google Scholar] [CrossRef]
- Hutter, F.; Kotthoff, L.; Vanschoren, J. Automated Machine Learning: Methods, Systems, Challenges; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Doke, A.; Gaikwad, M. Survey on Automated Machine Learning (AutoML) and Meta Learning. In Proceedings of the 2021 IEEE 12th International Conference on Computing Communication and Networking Technologies (ICCCNT), Kharagpur, India, 6–8 July 2021; pp. 1–5. [Google Scholar]
- Shang, Z.; Zgraggen, E.; Buratti, B.; Kossmann, F.; Eichmann, P.; Chung, Y.; Binnig, C.; Upfal, E.; Kraska, T. Democratizing Data Science through Interactive Curation of Ml Pipelines. In Proceedings of the 2019 International Conference on Management of Data, Amsterdam, The Netherlands, 30 June–5 July 2019; pp. 1171–1188. [Google Scholar]
- Yao, Q.; Wang, M.; Chen, Y.; Dai, W.; Li, Y.-F.; Tu, W.-W.; Yang, Q.; Yu, Y. Taking Human out of Learning Applications: A Survey on Automated Machine Learning. arXiv 2018, arXiv:181013306. [Google Scholar]
- Nagarajah, T.; Poravi, G. A Review on Automated Machine Learning (AutoML) Systems. In Proceedings of the 2019 IEEE 5th International Conference for Convergence in Technology (I2CT), Bombay, India, 29-31 March 2019; pp. 1–6. [Google Scholar]
- Bergstra, J.; Bardenet, R.; Bengio, Y.; Kégl, B. Algorithms for Hyper-Parameter Optimization. Adv. Neural Inf. Process. Syst. 2011, 24, 014008. [Google Scholar]
- Hospedales, T.; Antoniou, A.; Micaelli, P.; Storkey, A. Meta-Learning in Neural Networks: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 5149–5169. [Google Scholar] [CrossRef] [PubMed]
- Karmaker, S.K.; Hassan, M.M.; Smith, M.J.; Xu, L.; Zhai, C.; Veeramachaneni, K. Automl to Date and beyond: Challenges and Opportunities. ACM Comput. Surv. CSUR 2021, 54, 1–36. [Google Scholar]
- Ferreira, L.; Pilastri, A.; Martins, C.M.; Pires, P.M.; Cortez, P. A Comparison of AutoML Tools for Machine Learning, Deep Learning and XGBoost. In Proceedings of the IEEE 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18-22 July 2021; pp. 1–8. [Google Scholar]
- Gijsbers, P.; LeDell, E.; Thomas, J.; Poirier, S.; Bischl, B.; Vanschoren, J. An Open Source AutoML Benchmark. arXiv 2019, arXiv:190700909. [Google Scholar]
- Gijsbers, P.; Bueno, M.L.; Coors, S.; LeDell, E.; Poirier, S.; Thomas, J.; Bischl, B.; Vanschoren, J. Amlb: An Automl Benchmark. arXiv 2022, arXiv:220712560. [Google Scholar]
- Zöller, M.-A.; Huber, M.F. Benchmark and Survey of Automated Machine Learning Frameworks. J Artif Intell Res 2019, 70, 409–472. [Google Scholar] [CrossRef]
- Shi, X.; Mueller, J.W.; Erickson, N.; Li, M.; Smola, A.J. Benchmarking Multimodal AutoML for Tabular Data with Text Fields. arXiv 2021, arXiv:2111.02705. [Google Scholar]
- LeDell, E.; Poirier, S. H2o Automl: Scalable Automatic Machine Learning. In Proceedings of the AutoML Workshop at ICML, Vienna, Austria, 12–18 July 2020; ICML: San Diego, CA, USA, 2020; Volume 2020. [Google Scholar]
- Borji, A.; Cheng, M.-M.; Jiang, H.; Li, J. Salient Object Detection: A Benchmark. IEEE Trans. Image Process. 2015, 24, 5706–5722. [Google Scholar] [CrossRef]
- Lenkala, S.; Marry, R.; Gopovaram, S.R.; Akinci, T.C.; Topsakal, O. Comparison of Automated Machine Learning (AutoML) Tools for Epileptic Seizure Detection Using Electroencephalograms (EEG). Computers 2023, 12, 197. [Google Scholar] [CrossRef]
- Westergaard, G.; Erden, U.; Mateo, O.A.; Lampo, S.M.; Akinci, T.C.; Topsakal, O. Time Series Forecasting Utilizing Automated Machine Learning (AutoML): A Comparative Analysis Study on Diverse Datasets. Information 2024, 15. [Google Scholar] [CrossRef]
- Paladino, L.M.; Hughes, A.; Perera, A.; Topsakal, O.; Akinci, T.C. Evaluating the Performance of Automated Machine Learning (AutoML) Tools for Heart Disease Diagnosis and Prediction. AI 2023, 4, 1036–1058. [Google Scholar] [CrossRef]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object Detection in Optical Remote Sensing Images: A Survey and a New Benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Berg, G. Image Classification with Machine Learning as a Service: A Comparison between Azure, SageMaker, and Vertex AI. Bachelor’s Thesis, Linnaeus University, Växjö, Sweden, 2022. [Google Scholar]
- Padilla, R.; Netto, S.L.; da Silva, E.A.B. A Survey on Performance Metrics for Object-Detection Algorithms. In Proceedings of the 2020 International Conference on Systems, Signals and Image Processing (IWSSIP), Niteroi, Brazil, 1–3 July 2020; pp. 237–242. [Google Scholar]
- He, X.; Zhao, K.; Chu, X. AutoML: A Survey of the State-of-the-Art. Knowl. Based Syst. 2021, 212, 106622. [Google Scholar] [CrossRef]
- De Oliveira, S. AutoML-Study. Available online: https://github.com/Telephos/AutoML-study/tree/main (accessed on 18 January 2024).
- Wang, B.; Xu, H.; Zhang, J.; Chen, C.; Fang, X.; Xu, Y.; Kang, N.; Hong, L.; Jiang, C.; Cai, X.; et al. Vega: Towards an End-to-End Configurable Automl Pipeline. arXiv 2020, arXiv:201101507. [Google Scholar]
- Chen, Y.; Yang, T.; Zhang, X.; Meng, G.; Xiao, X.; Sun, J. Detnas: Backbone Search for Object Detection. In Proceedings of the Advances in Neural Information Processing Systems 32 (NeurIPS 2019), Vancouver, BC, Canada, 8–12 December 2019; Volume 32. [Google Scholar]
- Alexandrova, S.; Tatlock, Z.; Cakmak, M. RoboFlow: A Flow-Based Visual Programming Language for Mobile Manipulation Tasks. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 5537–5544. [Google Scholar]
- Shah, C.; Sinha, D.; Wang, Y.; Cha, S.; Radhakrishnan, S. Access the Latest in Vision AI Model Development Workflows with NVIDIA TAO Toolkit, 5.0; NVIDIA: Santa Clara, CA, USA, 2023. [Google Scholar]
- Ghosh, S.; Srinivasa, S.K.K.; Amon, P.; Hutter, A.; Kaup, A. Deep Network Pruning for Object Detection. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 3915–3919. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision Meets Robotics: The Kitti Dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- AutoGluon. Available online: https://auto.gluon.ai/0.6.2/install.html (accessed on 18 January 2024).
- Hoiem, D.; Divvala, S.K.; Hays, J.H. Pascal VOC 2008 Challenge. In World Literature Today; University of Illinois: Chicago, IL, USA, 2009; Volume 24. [Google Scholar]
- Vertex AI—Train and Use Your Own Models. Available online: https://cloud.google.com/vertex-ai/docs/training-overview (accessed on 18 January 2024).
- FiftyOne 2022. Available online: https://github.com/voxel51/fiftyone (accessed on 18 January 2024).
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Everingham, M.; Eslami, S.A.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes Challenge: A Retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Open Images Dataset V7. Available online: https://storage.googleapis.com/openimages/web/factsfigures_v7.html (accessed on 18 January 2024).
- Oksuz, K.; Cam, B.C.; Kalkan, S.; Akbas, E. Imbalance Problems in Object Detection: A Review. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3388–3415. [Google Scholar] [CrossRef]
- Hao, Y.; Pei, H.; Lyu, Y.; Yuan, Z.; Rizzo, J.-R.; Wang, Y.; Fang, Y. Understanding the Impact of Image Quality and Distance of Objects to Object Detection Performance. arXiv 2022, arXiv:220908237. [Google Scholar]
- Chen, C.; Liu, M.-Y.; Tuzel, O.; Xiao, J. R-CNN for Small Object Detection. In Proceedings of the Computer Vision–ACCV 2016: 13th Asian Conference on Computer Vision, Revised Selected Papers, Part V 13. Taipei, Taiwan, 20–24 November 2016; Springer: Berlin/Heidelberg, Germany, 2017; pp. 214–230. [Google Scholar]
- Vedaldi, A.; Zisserman, A. Structured Output Regression for Detection with Partial Truncation. In Proceedings of the Neural Information Processing Systems, Vancouver, BC, Canada, 7–10 December 2009. [Google Scholar]
- Wang, X.; Han, T.X.; Yan, S. An HOG-LBP Human Detector with Partial Occlusion Handling. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 32–39. [Google Scholar]
- Hoiem, D.; Chodpathumwan, Y.; Dai, Q. Diagnosing Error in Object Detectors. In Proceedings of the European Conference on Computer Vision—ECCV 2012, Florence, Italy, 7–13 October 2012; Fitzgibbon, A., Lazebnik, S., Perona, P., Sato, Y., Schmid, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 340–353. [Google Scholar]
- Nagelkerke, N.J. A Note on a General Definition of the Coefficient of Determination. biometrika 1991, 78, 691–692. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Level | Attribute | Description |
|---|---|---|
| 1 | Programming languages (Python, C++, etc.) | Full manual configuration, no automation |
| 2 | Basic implementation of Decision Tree, KMeans, SVM, etc. | Only machine learning automated |
| 3 | ATM, Rafiki, Amazon AutoML, DataRoboto, H20, Auto-WEKA | Automated Machine Learning Incorporates alternative model exploration and machine learning jointly |
| 4 | Darpa D3M, MLBazar, Rapid Miner | Feature Engineering + level 3 capabilities |
| 5 | ComposeML + Level 4 systems | Prediction engineering + level 4 capabilities |
| 6 | No known AutoML framework | Result summarizing and recommendation + level 5 capabilities |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Oliveira, S.d.; Topsakal, O.; Toker, O. Benchmarking Automated Machine Learning (AutoML) Frameworks for Object Detection. Information 2024, 15, 63. https://doi.org/10.3390/info15010063
Oliveira Sd, Topsakal O, Toker O. Benchmarking Automated Machine Learning (AutoML) Frameworks for Object Detection. Information. 2024; 15(1):63. https://doi.org/10.3390/info15010063
Chicago/Turabian StyleOliveira, Samuel de, Oguzhan Topsakal, and Onur Toker. 2024. "Benchmarking Automated Machine Learning (AutoML) Frameworks for Object Detection" Information 15, no. 1: 63. https://doi.org/10.3390/info15010063
APA StyleOliveira, S. d., Topsakal, O., & Toker, O. (2024). Benchmarking Automated Machine Learning (AutoML) Frameworks for Object Detection. Information, 15(1), 63. https://doi.org/10.3390/info15010063