
Unsupervised Learning in NBA Injury Recovery: Advanced Data Mining to Decode Recovery Durations and Economic Impacts




Abstract
1. Introduction
1.1. Related Work
1.2. Research Overview
2. Data and Methods
2.1. Research Questions/Hypothesis
- Can we identify anomalous recovery times for various types of body injuries in the NBA using unsupervised learning methods? (DBSCAN)
- What patterns and associations exist between types of injuries, recovery durations, sociodemographics, and their impact on team financial outcomes in the NBA?
2.2. Methodology
2.2.1. Data Collection
2.2.2. Data Engineering
Text Mining and Categorization in Injury Data
Transformation of Contract Data into Salary Data
2.2.3. Anomaly Detection Methodology
DBSCAN Algorithm Application
Isolation Forest Algorithm
Detection of Statistical Anomalies via the Z Score
Ensemble Anomaly Detection Strategy
2.2.4. Methodology for Association Rules
Theoretical Basis
- Support [51] indicates the frequency or prevalence of an item set in the dataset.
- ○
- The support of an itemset is defined as the proportion of transactions in the dataset that contain the itemset. Mathematically, this process is expressed as follows:
- Confidence [52] measures the likelihood of occurrence of the consequent in a transaction given the presence of the antecedent.
- ○
- The confidence of a rule (where and are disjoint itemsets) measures the likelihood of being present in transactions that contain . It is calculated as follows:
- Lift [53] assesses the strength of a rule over the random occurrence of the antecedent and consequent, indicating the rule’s effectiveness in predicting the consequent.
- ○
- Lift evaluates the performance of a rule compared to the expected performance if and are independent. The lift of a rule is given by:
Implementation Process
Significance in Research
3. Results
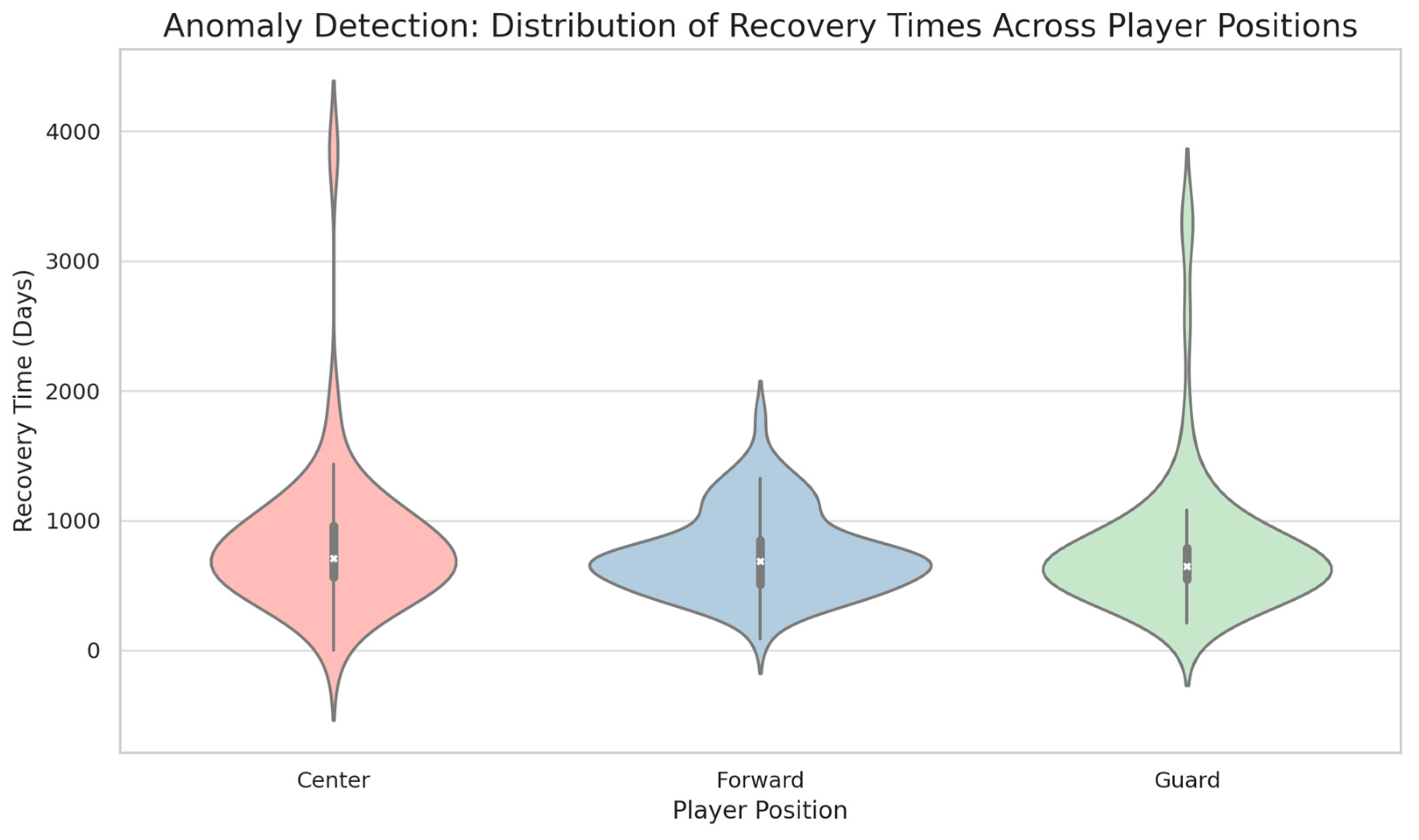
3.1. Anomaly Detection during Recovery
3.2. Association Rules in Recovery Times
4. Discussion
4.1. Unconventional Recovery Durations
4.2. Interplay between Player Attributes, Injury Types, and Recovery
4.3. Financial Aspects and Recovery Dynamics
4.4. Physical Attributes and Recovery Patterns
4.5. Threats to Validity
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Brefeld, U.; Davis, J.; Van Haaren, J.; Zimmermann, A. (Eds.) Machine Learning and Data Mining for Sports Analytics; Springer: Cham, Switzerland, 2022. [Google Scholar] [CrossRef]
- Rossi, A.; Perri, E.; Pappalardo, L.; Cintia, P.; Iaia, F. Relationship between External and Internal Workloads in Elite Soccer Players: Comparison between Rate of Perceived Exertion and Training Load. Appl. Sci. 2019, 9, 5174. [Google Scholar] [CrossRef]
- Mehrotra, K.G.; Mohan, C.K.; Huang, H. Clustering-Based Anomaly Detection Approaches. In Anomaly Detection Principles and Algorithms; Springer: Cham, Switzerland, 2017; pp. 41–55. [Google Scholar]
- Wang, X.; Huang, D.; Zhao, X. Design of the Sports Training Decision Support System Based on Improved Association Rule, the Apriori Algorithm. Intell. Autom. Soft Comput. 2020, 26, 755–763. [Google Scholar] [CrossRef]
- Bahnert, A.; Norton, K.; Lock, P. Association between post-game recovery protocols, physical and perceived recovery, and performance in elite Australian Football League players. J. Sci. Med. Sport 2013, 16, 151–156. [Google Scholar] [CrossRef] [PubMed]
- Maffulli, N.; Longo, U.G.; Gougoulias, N.; Caine, D.; Denaro, V. Sport injuries: A review of outcomes. Br. Med. Bull. 2011, 97, 47–80. [Google Scholar] [CrossRef] [PubMed]
- Nwachukwu, B.U.; Anthony, S.G.; Lin, K.M.; Wang, T.; Altchek, D.W.; Allen, A.A. Return to play and performance after anterior cruciate ligament reconstruction in the National Basketball Association: Surgeon case series and literature review. Physician Sportsmed. 2017, 45, 303–308. [Google Scholar] [CrossRef] [PubMed]
- Truong, L.K.; Mosewich, A.D.; Miciak, M.; Pajkic, A.; Le, C.Y.; Li, L.C.; Whittaker, J.L. Balance, reframe, and overcome: The attitudes, priorities, and perceptions of exercise-based activities in youth 12–24 months after a sport-related ACL injury. J. Orthop. Res. 2022, 40, 170–181. [Google Scholar] [CrossRef] [PubMed]
- Hewett, T.E.; Myer, G.D.; Ford, K.R.; Paterno, M.V.; Quatman, C.E. Mechanisms, prediction, and prevention of ACL injuries: Cut risk with three sharpened and validated tools. J. Orthop. Res. 2016, 34, 1843–1855. [Google Scholar] [CrossRef]
- Laver, L.; Kocaoglu, B.; Cole, B.; Arundale, A.J.H.; Bytomski, J.; Amendola, A. Basketball Sports Medicine and Science; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar] [CrossRef]
- Krosshaug, T.; Nakamae, A.; Boden, B.P.; Engebretsen, L.; Smith, G.; Slauterbeck, J.R.; Hewett, T.E.; Bahr, R. Mechanisms of Anterior Cruciate Ligament Injury in Basketball. Am. J. Sports Med. 2007, 35, 359–367. [Google Scholar] [CrossRef]
- Kalaian, S.A.; Kasim, R. Predictive Analytics. In Handbook of Research on Organizational Transformations through Big Data Analytics; IGI Global: Hershey, PA, USA, 2015; pp. 12–29. [Google Scholar] [CrossRef]
- Jauhiainen, S.; Kauppi, J.-P.; Leppänen, M.; Pasanen, K.; Parkkari, J.; Vasankari, T.; Kannus, P.; Äyrämö, S. New Machine Learning Approach for Detection of Injury Risk Factors in Young Team Sport Athletes. Int. J. Sports Med. 2021, 42, 175–182. [Google Scholar] [CrossRef]
- Terner, Z.; Franks, A. Modeling Player and Team Performance in Basketball. Annu. Rev. Stat. Appl. 2021, 8, 1–23. [Google Scholar] [CrossRef]
- Sarlis, V.; Chatziilias, V.; Tjortjis, C.; Mandalidis, D. A Data Science approach analysing the Impact of Injuries on Basketball Player and Team Performance. Inf. Syst. 2021, 99, 101750. [Google Scholar] [CrossRef]
- Cohan, A.; Schuster, J.; Fernandez, J. A deep learning approach to injury forecasting in NBA basketball. J. Sports Anal. 2021, 7, 277–289. [Google Scholar] [CrossRef]
- Kester, B.S.; Behery, O.A.; Minhas, S.V.; Hsu, W.K. Athletic performance and career longevity following anterior cruciate ligament reconstruction in the National Basketball Association. Knee Surg. Sports Traumatol. Arthrosc. 2017, 25, 3031–3037. [Google Scholar] [CrossRef]
- Khan, M.; Ekhtiari, S.; Burrus, T.; Madden, K.; Rogowski, J.P.; Bedi, A. Impact of Knee Injuries on Post-retirement Pain and Quality of Life: A Cross-Sectional Survey of Professional Basketball Players. HSS J. 2020, 16, 327–332. [Google Scholar] [CrossRef]
- Harris, J.D.; Erickson, B.J.; Bach, B.R.; Abrams, G.D.; Cvetanovich, G.L.; Forsythe, B.; McCormick, F.M.; Gupta, A.K.; Cole, B.J. Return-to-Sport and Performance after Anterior Cruciate Ligament Reconstruction in National Basketball Association Players. Sports Health 2013, 5, 562–568. [Google Scholar] [CrossRef]
- Iwamoto, J.; Ito, E.; Azuma, K.; Matsumoto, H. Sex-specific differences in injury types among basketball players. Open Access J. Sports Med. 2015, 6, 1–6. [Google Scholar] [CrossRef]
- Taylor, J.B.; Ford, K.R.; Nguyen, A.D.; Terry, L.N.; Hegedus, E.J. Prevention of Lower Extremity Injuries in Basketball: A Systematic Review and Meta-Analysis. Sports Health 2015, 7, 392–398. [Google Scholar] [CrossRef]
- Trojian, T.H.; Cracco, A.; Hall, M.; Mascaro, M.; Aerni, G.; Ragle, R. Basketball injuries: Caring for a basketball team. Curr. Sports Med. Rep. 2013, 12, 321–328. [Google Scholar] [CrossRef] [PubMed]
- Minhas, S.V.; Kester, B.S.; Larkin, K.E.; Hsu, W.K. The Effect of an Orthopaedic Surgical Procedure in the National Basketball Association. Am. J. Sports Med. 2016, 44, 1056–1061. [Google Scholar] [CrossRef] [PubMed]
- Afara, I.O.; Sarin, J.K.; Ojanen, S.; Finnilä, M.A.J.; Herzog, W.; Saarakkala, S.; Korhonen, R.K.; Töyräs, J. Machine Learning Classification of Articular Cartilage Integrity Using Near Infrared Spectroscopy. Cell. Mol. Bioeng. 2020, 13, 219–228. [Google Scholar] [CrossRef] [PubMed]
- Maffulli, N.; Longo, U.G.; Spiezia, F.; Denaro, V. Sports Injuries in Young Athletes: Long-Term Outcome and Prevention Strategies. Phys. Sportsmed. 2010, 38, 29–34. [Google Scholar] [CrossRef] [PubMed]
- Lu, Y.; Pareek, A.; Lavoie-Gagne, O.Z.; Forlenza, E.M.; Patel, B.H.; Reinholz, A.K.; Forsythe, B.; Camp, C.L. Machine Learning for Predicting Lower Extremity Muscle Strain in National Basketball Association Athletes. Orthop. J. Sports Med. 2022, 10, 232596712211117. [Google Scholar] [CrossRef]
- Jauhiainen, S.; Kauppi, J.P.; Krosshaug, T.; Bahr, R.; Bartsch, J.; Äyrämö, S. Predicting ACL Injury Using Machine Learning on Data From an Extensive Screening Test Battery of 880 Female Elite Athletes. Am. J. Sports Med. 2022, 50, 2917–2924. [Google Scholar] [CrossRef] [PubMed]
- Sarlis, V.; George, P.; Christos, T. Sports Analytics and Text Mining NBA Data to Assess Recovery from Injuries and Their Economic Impact. Computers 2023, 12, 261. [Google Scholar] [CrossRef]
- Rehman, S.U.; Asghar, S.; Fong, S.; Sarasvady, S. DBSCAN: Past, present and future. In Proceedings of the Fifth International Conference on the Applications of Digital Information and Web Technologies (ICADIWT 2014), Bangalore, India, 17–19 February 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 232–238. [Google Scholar]
- Liu, F.T.; Ting, K.M.; Zhou, Z.-H. Isolation Forest. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 413–422. [Google Scholar]
- Rousseeuw, P.J.; Hubert, M. Anomaly detection by robust statistics. WIREs Data Min. Knowl. Discov. 2018, 8, e1236. [Google Scholar] [CrossRef]
- Borgelt, C.; Kruse, R. Induction of Association Rules: Apriori Implementation. In Compstat; Physica-Verlag HD: Heidelberg, Germany, 2002; pp. 395–400. [Google Scholar]
- Zhang, C.; Zhang, S. (Eds.) Negative Association Rule. In Association Rule Mining; Springer: Berlin/Heidelberg, Germany, 2002; pp. 47–84. [Google Scholar]
- Chomątek, Ł.; Sierakowska, K. Automation of Basketball Match Data Management. Information 2021, 12, 461. [Google Scholar] [CrossRef]
- swar. nba_api. 2023. Available online: https://github.com/swar/nba_api (accessed on 15 November 2023).
- ESPN. NBA Stats. Available online: https://www.espn.com/nba/stats (accessed on 15 November 2023).
- Glez-Peña, D.; Lourenço, A.; López-Fernández, H.; Reboiro-Jato, M.; Fdez-Riverola, F. Web scraping technologies in an API world. Brief Bioinform. 2014, 15, 788–797. [Google Scholar] [CrossRef]
- Ochieng, P.J.; London, A.; Krész, M. A Forward-Looking Approach to Compare Ranking Methods for Sports. Information 2022, 13, 232. [Google Scholar] [CrossRef]
- Zadeh, L.A. Fuzzy logic. Computer 1988, 21, 83–93. [Google Scholar] [CrossRef]
- Alexandridis, G.; Varlamis, I.; Korovesis, K.; Caridakis, G.; Tsantilas, P. A Survey on Sentiment Analysis and Opinion Mining in Greek Social Media. Information 2021, 12, 331. [Google Scholar] [CrossRef]
- Li, L.; Pratap, A.; Lin, H.-T.; Abu-Mostafa, Y.S. Improving Generalization by Data Categorization. In Knowledge Discovery in Databases: PKDD 2005, Proceedings of the 9th European Conference on Principles and Practice of Knowledge Discovery in Databases, Porto, Portugal, 3–7 October 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 157–168. [Google Scholar]
- Vatsalan, D.; Bhaskar, R.; Gkoulalas-Divanis, A.; Karapiperis, D. Privacy Preserving Text Data Encoding and Topic Modelling. In Proceedings of the 2021 IEEE International Conference on Big Data (Big Data), Orlando, FL, USA, 15–18 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1308–1316. [Google Scholar]
- Brunnermeier, M.K.; Sannikov, Y. On the Optimal Inflation Rate. Am. Econ. Rev. 2016, 106, 484–489. [Google Scholar] [CrossRef]
- Ali, T.; Asghar, S.; Sajid, N.A. Critical analysis of DBSCAN variations. In Proceedings of the 2010 International Conference on Information and Emerging Technologies, Karachi, Pakistan, 14–16 June 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 1–6. [Google Scholar]
- Birant, D.; Kut, A. ST-DBSCAN: An algorithm for clustering spatial–temporal data. Data Knowl. Eng. 2007, 60, 208–221. [Google Scholar] [CrossRef]
- Li, C.; Guo, L.; Gao, H.; Li, Y. Similarity-Measured Isolation Forest: Anomaly Detection Method for Machine Monitoring Data. IEEE Trans. Instrum. Meas. 2021, 70, 1–12. [Google Scholar] [CrossRef]
- Ferragut, E.M.; Laska, J.; Bridges, R.A. A New, Principled Approach to Anomaly Detection. In Proceedings of the 2012 11th International Conference on Machine Learning and Applications, Boca Raton, FL, USA, 12–15 December 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 210–215. [Google Scholar]
- Ghafari, S.M.; Tjortjis, C. A survey on association rules mining using heuristics. WIREs Data Min. Knowl. Discov. 2019, 9, e1307. [Google Scholar] [CrossRef]
- Agrawal, R.; Srikant, R. Fast algorithms for mining association rules. In Proceedings of the 20th International Conference on Very Large Data Bases, VLDB, Santiago de Chile, Chile, 12–15 September 1994; pp. 487–499. [Google Scholar]
- Du, J.; Zhang, X.; Zhang, H.; Chen, L. Research and improvement of Apriori algorithm. In Proceedings of the 2016 Sixth International Conference on Information Science and Technology (ICIST), Dalian, China, 6–8 May 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 117–121. [Google Scholar]
- Dasseni, E.; Verykios, V.S.; Elmagarmid, A.K.; Bertino, E. Hiding Association Rules by Using Confidence and Support. In Information Hiding, Proceedings of the 4th International Workshop, IH 2001, Pittsburgh, PA, USA, 25–27 April 2001; Springer: Berlin/Heidelberg, Germany, 2001; pp. 369–383. [Google Scholar]
- Scheffer, T. Finding Association Rules That Trade Support Optimally against Confidence. In Proceedings of the European Conference on Principles of Data Mining and Knowledge Discovery, Freiburg, Germany, 3–5 September 2001; pp. 424–435. [Google Scholar]
- McNicholas, P.D.; Murphy, T.B.; O’Regan, M. Standardising the lift of an association rule. Comput. Stat. Data Anal. 2008, 52, 4712–4721. [Google Scholar] [CrossRef]
- Fujita, M.; McGeer, P.C.; Yang, J.C.-Y. Multi-Terminal Binary Decision Diagrams: An Efficient Data Structure for Matrix Representation. Form Methods Syst. Des. 1997, 10, 149–169. [Google Scholar] [CrossRef]
- Huyghe, T.; Alcaraz, P.E.; Calleja-González, J.; Bird, S.P. The underpinning factors of NBA game-play performance: A systematic review (2001–2020). Phys. Sportsmed. 2022, 50, 94–122. [Google Scholar] [CrossRef]
- Lian, J.; Sewani, F.; Dayan, I.; Voleti, P.B.; Gonzalez, D.; Levy, I.M.; Musahl, V.; Allen, A. Systematic Review of Injuries in the Men’s and Women’s National Basketball Association. Am. J. Sports Med. 2022, 50, 1416–1429. [Google Scholar] [CrossRef]
- Matthew, B. Financial Management in the Sport Industry; Routledge: London, UK, 2016. [Google Scholar] [CrossRef]
- Mihajlovic, M.; Cabarkapa, D.; Cabarkapa, D.V.; Philipp, N.M.; Fry, A.C. Recovery Methods in Basketball: A Systematic Review. Sports 2023, 11, 230. [Google Scholar] [CrossRef]
- Pearl, J. Causal inference in statistics: An overview. Stat Surv. 2009, 3, 96–146. [Google Scholar] [CrossRef]
- Yakhchi, S.; Ghafari, S.M.; Tjortjis, C.; Fazeli, M. ARMICA-Improved: A New Approach for Association Rule Mining. In Knowledge Science, Engineering and Management, Proceedings of the 10th International Conference, KSEM 2017, Melbourne, VIC, Australia, 19–20 August 2017; Springer: Cham, Switzerland, 2017; pp. 296–306. [Google Scholar]
- Ren, B.; Wang, Z.; Ma, K.; Zhou, Y.; Liu, M. An Improved Method of Heart Rate Extraction Algorithm Based on Photoplethysmography for Sports Bracelet. Information 2023, 14, 297. [Google Scholar] [CrossRef]
- Xiao, J.; Tian, W.; Ding, L. Basketball Action Recognition Method of Deep Neural Network Based on Dynamic Residual Attention Mechanism. Information 2022, 14, 13. [Google Scholar] [CrossRef]
- Pintér, G.; Felde, I. Analyzing the Behavior and Financial Status of Soccer Fans from a Mobile Phone Network Perspective: Euro 2016, a Case Study. Information 2021, 12, 468. [Google Scholar] [CrossRef]


{kind=link}
| Name (Type) | Shape (Rows, Columns) |
|---|---|
| Player sociodemographic information | (781,406, 26) |
| Injuries data (on and off game) | (58,151, 4) |
| Contracts data (signed over seasons) | (7257, 6) |
| Antecedents: Injury Type Consequents: Recovery (0–10 Days) and Team Losses (USD 0–25 million) | Support | Confidence | Lift |
|---|---|---|---|
| Rest | 2% | 95% | 1.71 |
| Respiratory | 1% | 79% | 1.43 |
| General illness | 6% | 77% | 1.39 |
| Neck | 1% | 70% | 1.27 |
| Abdominal | 1% | 66% | 1.19 |
| Hip | 2% | 64% | 1.15 |
| Back | 5% | 63% | 1.14 |
| Cranial | 1% | 63% | 1.14 |
| Unclassified | 1% | 62% | 1.12 |
| Ankle | 8% | 58% | 1.05 |
| Facial subareas | 1% | 57% | 1.03 |
| Heel | 1% | 54% | 0.98 |
| Arm | 1% | 54% | 0.97 |
| Groin | 1% | 53% | 0.95 |
| Thigh | 4% | 52% | 0.94 |
| Knee | 7% | 52% | 0.93 |
| Foot | 3% | 51% | 0.92 |
| Antecedents: Recovery in Days | Consequents: Height (H) in cm Weight (W) in kg Team Losses (TL) in USD M Salary per Game (S) in USD k | Support | Confidence | Lift |
|---|---|---|---|---|
| 0–10 | W: 100–130 kg and TL: 0–25 M | 28% | 50% | 1.01 |
| H: 200–225 cm and TL: 0–25 M | 32% | 58% | 1 | |
| W: 100–130 kg | 28% | 50% | 1 | |
| TL: 0–25 M | 55% | 100% | 1 | |
| H: 200–225 cm | 32% | 58% | 0.99 | |
| S: 0–150 k | 38% | 68% | 0.96 | |
| S: 0–150 k and TL: 0–25 M | 38% | 68% | 0.96 | |
| 10–30 | S: 0–150 k and TL: 0–25 M | 14% | 75% | 1.06 |
| S: 0–150 k | 14% | 75% | 1.05 | |
| H: 200–225 cm | 11% | 60% | 1.02 | |
| H: 200–225 cm and TL: 0–25 M | 11% | 60% | 1.02 | |
| TL: 0–25 M | 18% | 100% | 1 | |
| 30–90 | S: 0–150 k and TL: 0–25 M | 7% | 73% | 1.03 |
| S: 0–150 k | 7% | 73% | 1.03 | |
| W: 100–130 kg | 5% | 51% | 1.02 | |
| W: 100–130 kg and TL: 0–25 M | 5% | 51% | 1.02 | |
| H: 200–225 cm and TL: 0–25 M | 6% | 59% | 1.02 | |
| H: 200–225 cm | 6% | 59% | 1.01 | |
| TL: 0–25 M | 10% | 100% | 1 | |
| 90–180 | H: 200–225 cm | 2% | 61% | 1.03 |
| H: 200–225 cm and TL: 0–25 M | 2% | 60% | 1.03 | |
| TL: 0–25 M | 3% | 100% | 1 | |
| S: 0–150 k | 2% | 69% | 0.97 | |
| S: 0–150 k and TL: 0–25 M | 2% | 69% | 0.97 | |
| 180+ | S: 0–150 k | 7% | 73% | 1.03 |
| W: 70–100 kg | 5% | 50% | 1.03 | |
| S: 0–150 k and TL: 0–25 M | 7% | 73% | 1.02 | |
| H: 200–225 cm | 6% | 58% | 0.99 | |
| TL: 0–25 M | 10% | 98% | 0.98 | |
| H: 200–225 cm and TL: 0–25 M | 6% | 56% | 0.97 | |
| Career ending | S: 0–150 k and H: 200–225 cm and TL: 0–25 M | 2% | 51% | 1.24 |
| S: 0–150 k | 3% | 87% | 1.23 | |
| S: 0–150 k and H: 200–225 cm | 2% | 51% | 1.23 | |
| S: 0–150 k and TL: 0–25 M | 3% | 87% | 1.23 | |
| W: 70–100 kg | 2% | 50% | 1.03 | |
| W: 70–100 kg and TL: 0–25 M | 2% | 50% | 1.03 | |
| TL: 0–25 M | 4% | 100% | 1 | |
| H: 200–225 cm | 2% | 57% | 0.97 | |
| H: 200–225 cm and TL: 0–25 M | 2% | 57% | 0.97 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Papageorgiou, G.; Sarlis, V.; Tjortjis, C. Unsupervised Learning in NBA Injury Recovery: Advanced Data Mining to Decode Recovery Durations and Economic Impacts. Information 2024, 15, 61. https://doi.org/10.3390/info15010061
Papageorgiou G, Sarlis V, Tjortjis C. Unsupervised Learning in NBA Injury Recovery: Advanced Data Mining to Decode Recovery Durations and Economic Impacts. Information. 2024; 15(1):61. https://doi.org/10.3390/info15010061
Chicago/Turabian StylePapageorgiou, George, Vangelis Sarlis, and Christos Tjortjis. 2024. "Unsupervised Learning in NBA Injury Recovery: Advanced Data Mining to Decode Recovery Durations and Economic Impacts" Information 15, no. 1: 61. https://doi.org/10.3390/info15010061
APA StylePapageorgiou, G., Sarlis, V., & Tjortjis, C. (2024). Unsupervised Learning in NBA Injury Recovery: Advanced Data Mining to Decode Recovery Durations and Economic Impacts. Information, 15(1), 61. https://doi.org/10.3390/info15010061