


Three-Stage MPViT-DeepLab Transfer Learning for Community-Scale Green Infrastructure Extraction


Abstract
:1. Introduction
- We reannotate a dataset suitable for training in the task of CSGI extraction.
- We feed the coarse and fine features extracted by MPViT into DeepLabv3+ for pixel-level segmentation of CSGI in the three-stage transfer learning process.
- We confirm that three-stage MPViT-DeepLab transfer learning, along with freezing all BN layers during the second transfer learning, achieves state-of-the-art performance in the CSGI extraction task on the reannotate dataset.
2. Related Work
2.1. Multi-Path Vision Transformer
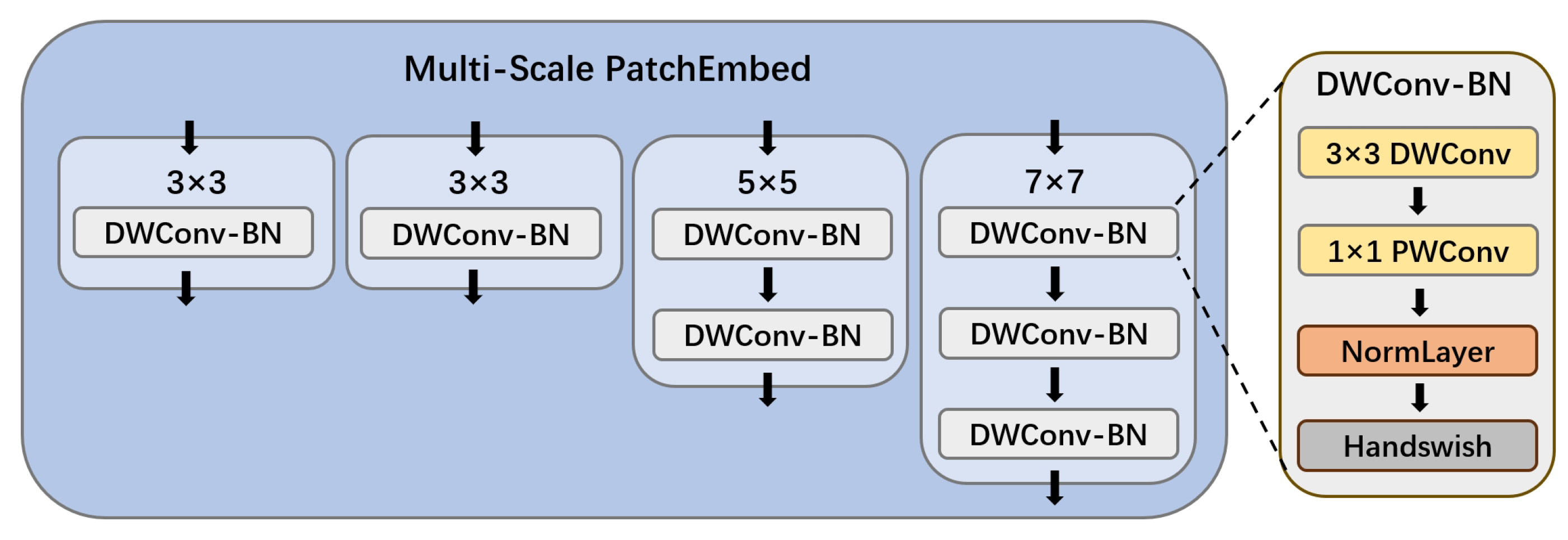
2.1.1. Multi-Scale PatchEmbed Block
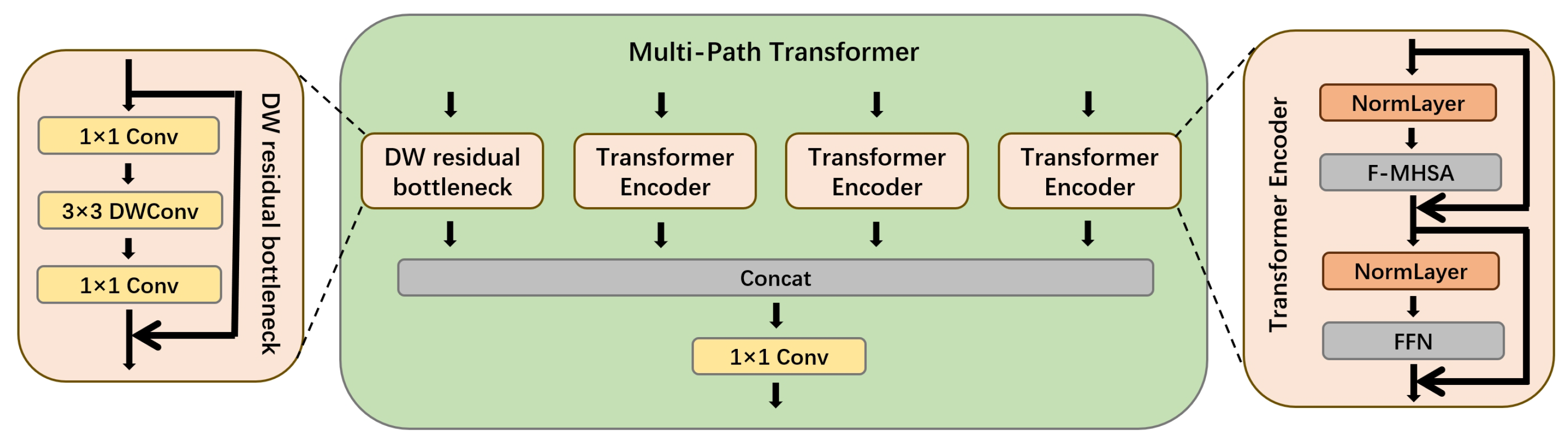
2.1.2. Multi-Path Transformer Block
2.2. DeepLabv3+
3. The Proposed Method
3.1. Dataset
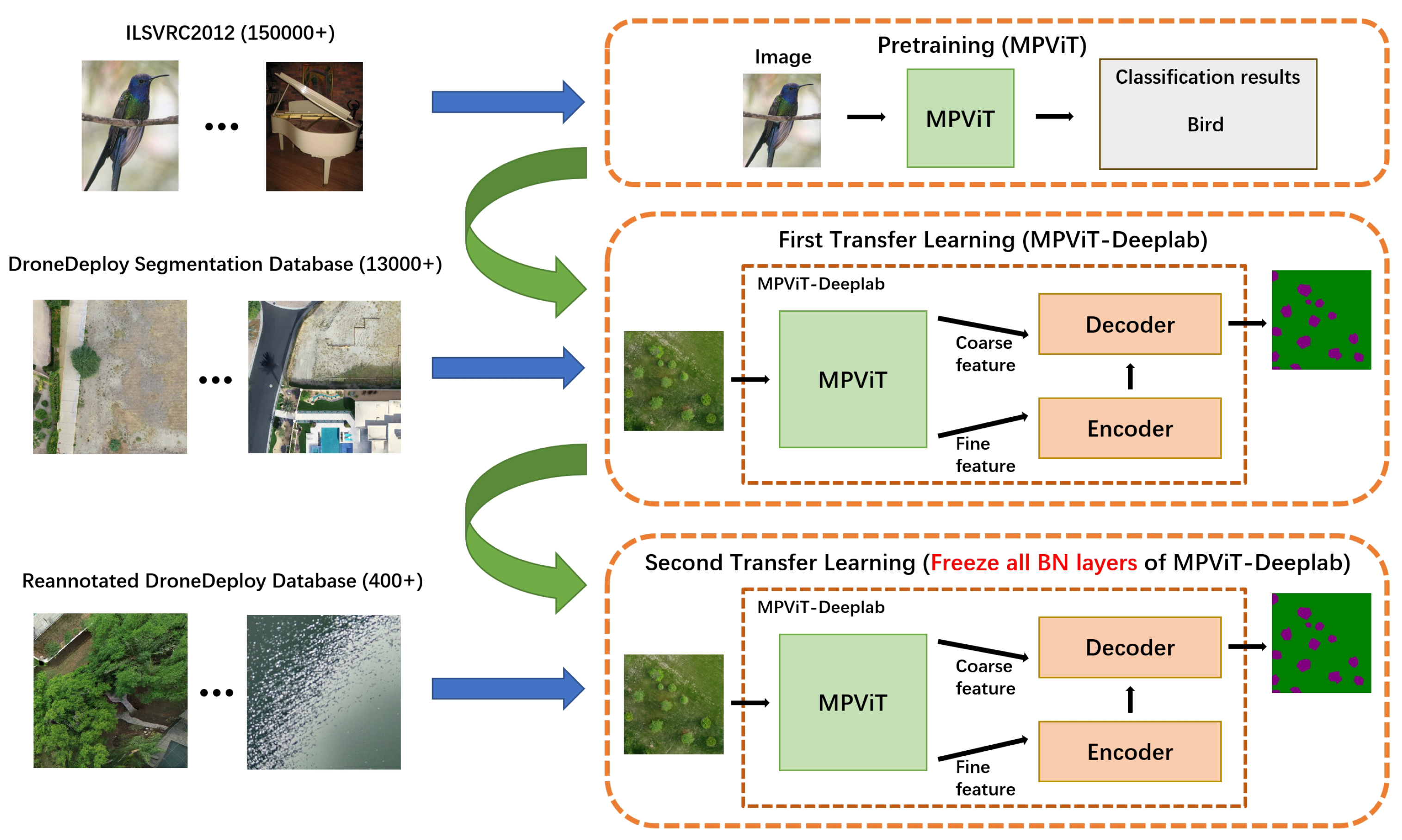
3.2. Three-Stage Transfer Learning
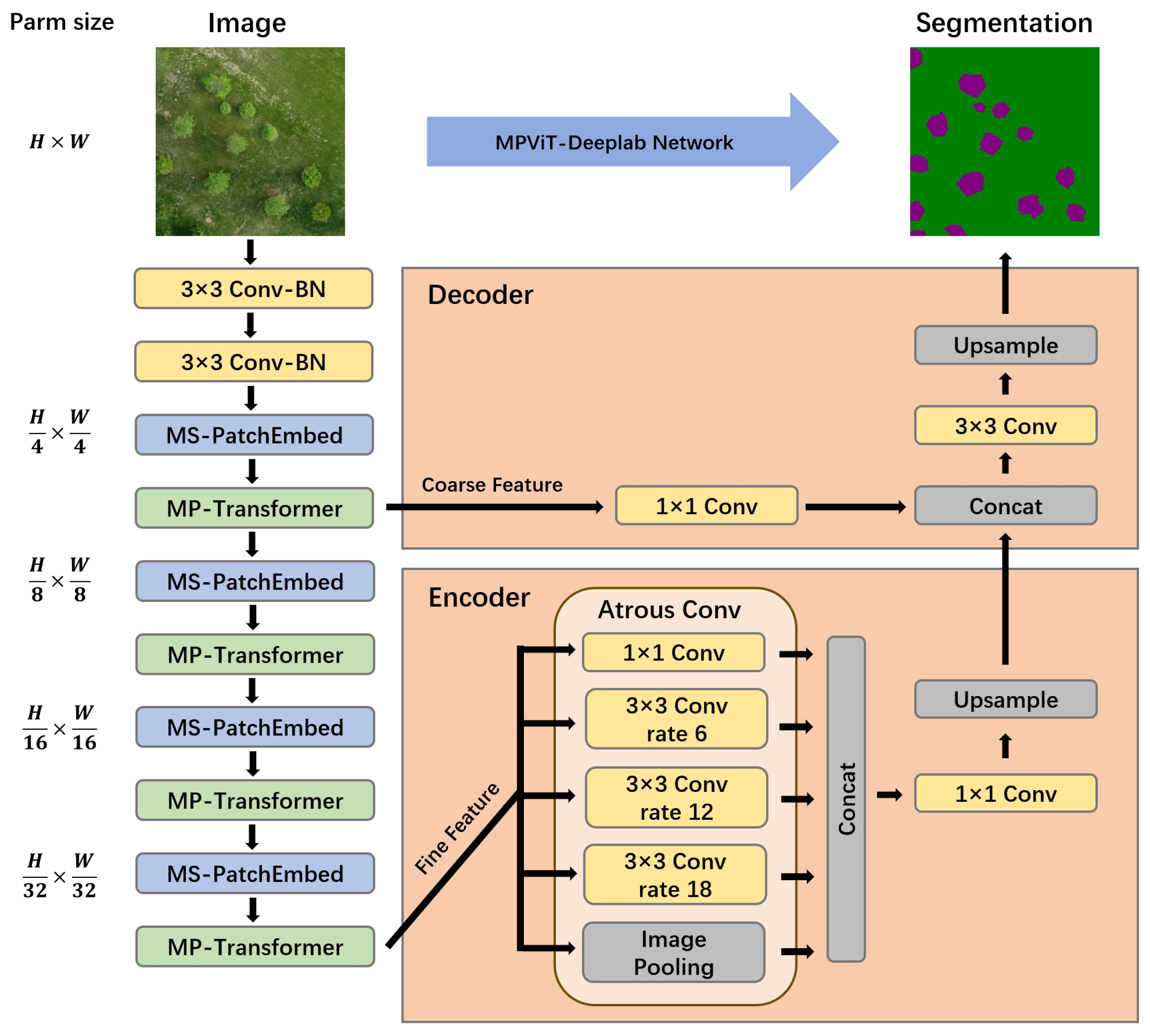
3.3. MPViT-DeepLab
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Shen, C.; Li, M.; Li, F.; Chen, J.; Lu, Y. Study on urban green space extraction from QUICKBIRD imagery based on decision tree. In Proceedings of the 2010 18th International Conference on Geoinformatics, Beijing, China, 18–20 June 2010; pp. 1–4. [Google Scholar]
- Zylshal; Sulma, S.; Yulianto, F.; Nugroho, J.T.; Sofan, P. A support vector machine object based image analysis approach on urban green space extraction using Pleiades-1A imagery. Model. Earth Syst. Environ. 2016, 2, 1–12. [Google Scholar] [CrossRef]
- Liu, W.; Yue, A.; Shi, W.; Ji, J.; Deng, R. An automatic extraction architecture of urban green space based on DeepLabv3plus semantic segmentation model. In Proceedings of the 2019 IEEE 4th International Conference on Image, Vision and Computing (ICIVC), Xiamen, China, 5–7 July 2019; pp. 311–315. [Google Scholar]
- Huerta, R.E.; Yépez, F.D.; Lozano-García, D.F.; Guerra Cobian, V.H.; Ferrino Fierro, A.L.; de León Gómez, H.; Cavazos Gonzalez, R.A.; Vargas-Martínez, A. Mapping urban green spaces at the metropolitan level using very high resolution satellite imagery and deep learning techniques for semantic segmentation. Remote Sens. 2021, 13, 2031. [Google Scholar] [CrossRef]
- Jerome, G. Defining community-scale green infrastructure. In Green Infrastructure; Routledge: London, UK, 2018; pp. 89–95. [Google Scholar]
- Nie, X.; Duan, M.; Ding, H.; Hu, B.; Wong, E.K. Attention mask R-CNN for ship detection and segmentation from remote sensing images. IEEE Access 2020, 8, 9325–9334. [Google Scholar] [CrossRef]
- Wang, H.; Chen, X.; Zhang, T.; Xu, Z.; Li, J. CCTNet: Coupled CNN and transformer network for crop segmentation of remote sensing images. Remote Sens. 2022, 14, 1956. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Proceedings of the Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: 4th International Workshop, DLMIA 2018, and 8th International Workshop, ML-CDS 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, 20 September 2018; pp. 3–11. [Google Scholar]
- Guo, M.; Liu, H.; Xu, Y.; Huang, Y. Building extraction based on U-Net with an attention block and multiple losses. Remote Sens. 2020, 12, 1400. [Google Scholar] [CrossRef]
- Chen, Z.; Li, D.; Fan, W.; Guan, H.; Wang, C.; Li, J. Self-attention in reconstruction bias U-Net for semantic segmentation of building rooftops in optical remote sensing images. Remote Sens. 2021, 13, 2524. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Online, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Lee, Y.; Kim, J.; Willette, J.; Hwang, S.J. Mpvit: Multi-path vision transformer for dense prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 7287–7296. [Google Scholar]
- Samala, R.K.; Chan, H.P.; Hadjiiski, L.M.; Helvie, M.A.; Cha, K.H.; Richter, C.D. Multi-task transfer learning deep convolutional neural network: Application to computer-aided diagnosis of breast cancer on mammograms. Phys. Med. Biol. 2017, 62, 8894. [Google Scholar] [CrossRef] [PubMed]
- Ghafoorian, M.; Mehrtash, A.; Kapur, T.; Karssemeijer, N.; Marchiori, E.; Pesteie, M.; Guttmann, C.R.; de Leeuw, F.E.; Tempany, C.M.; Van Ginneken, B.; et al. Transfer learning for domain adaptation in MRI: Application in brain lesion segmentation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2017: 20th International Conference, Quebec City, QC, Canada, 11–13 September 2017; pp. 516–524. [Google Scholar]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? Adv. Neural Inf. Process. Syst. 2014, 27, 3320–3328. [Google Scholar]
- Raghu, M.; Zhang, C.; Kleinberg, J.; Bengio, S. Transfusion: Understanding transfer learning for medical imaging. Adv. Neural Inf. Process. Syst. 2019, 32, 3342–3352. [Google Scholar]
- Alzubaidi, L.; Al-Amidie, M.; Al-Asadi, A.; Humaidi, A.J.; Al-Shamma, O.; Fadhel, M.A.; Zhang, J.; Santamaría, J.; Duan, Y. Novel transfer learning approach for medical imaging with limited labeled data. Cancers 2021, 13, 1590. [Google Scholar] [CrossRef] [PubMed]
- Li, W.; Huang, R.; Li, J.; Liao, Y.; Chen, Z.; He, G.; Yan, R.; Gryllias, K. A perspective survey on deep transfer learning for fault diagnosis in industrial scenarios: Theories, applications and challenges. Mech. Syst. Signal Process. 2022, 167, 108487. [Google Scholar] [CrossRef]
- Kraus, M.; Feuerriegel, S. Decision support from financial disclosures with deep neural networks and transfer learning. Decis. Support Syst. 2017, 104, 38–48. [Google Scholar] [CrossRef]
- Jeong, G.; Kim, H.Y. Improving financial trading decisions using deep Q-learning: Predicting the number of shares, action strategies, and transfer learning. Expert Syst. Appl. 2019, 117, 125–138. [Google Scholar] [CrossRef]
- Mignone, P.; Pio, G.; Ceci, M. Distributed Heterogeneous Transfer Learning for Link Prediction in the Positive Unlabeled Setting. In Proceedings of the 2022 IEEE International Conference on Big Data (Big Data), Osaka, Japan, 17–20 December 2022; pp. 5536–5541. [Google Scholar]
- Prabhakar, S.K.; Lee, S.W. Holistic approaches to music genre classification using efficient transfer and deep learning techniques. Expert Syst. Appl. 2023, 211, 118636. [Google Scholar] [CrossRef]
- Chen, B.; Koh, Y.S.; Dobbie, G.; Wu, O.; Coulson, G.; Olivares, G. Online Air Pollution Inference using Concept Recurrence and Transfer Learning. In Proceedings of the 2022 IEEE 9th International Conference on Data Science and Advanced Analytics (DSAA), Shenzhen, China, 13–16 October 2022; pp. 1–10. [Google Scholar]
- Cao, X.; Wipf, D.; Wen, F.; Duan, G.; Sun, J. A practical transfer learning algorithm for face verification. In Proceedings of the International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 3208–3215. [Google Scholar]
- Gopalakrishnan, K.; Khaitan, S.K.; Choudhary, A.; Agrawal, A. Deep convolutional neural networks with transfer learning for computer vision-based data-driven pavement distress detection. Constr. Build. Mater. 2017, 157, 322–330. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning PMLR, Lille, France, 7–9 July 2015; pp. 448–456. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Xu, W.; Xu, Y.; Chang, T.; Tu, Z. Co-scale conv-attentional image transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Online, 11–17 October 2021; pp. 9981–9990. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Dronedeploy. DroneDeploy Segmentation Dataset. Available online: https://github.com/dronedeploy/dd-ml-segmentation-benchmark (accessed on 12 June 2023).
- Wkentaro. Labelme. Available online: https://github.com/wkentaro/labelme (accessed on 4 July 2023).
- Zhao, X.; Wang, J. Bridge crack detection based on improved deeplabv3+ and migration learning. J. Comput. Eng. Appl. 2023, 59, 262–269. [Google Scholar]
- Zhang, C.; Jiang, W.; Zhang, Y.; Wang, W.; Zhao, Q.; Wang, C. Transformer and CNN hybrid deep neural network for semantic segmentation of very-high-resolution remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–20. [Google Scholar] [CrossRef]
- Hong, Q.; Sun, H.; Li, B.; Peng, A.; Zhou, L.; Zhang, Z. MpVit-Unet: Multi-path Vision Transformer Unet for Sellar Region Lesions Segmentation. In Proceedings of the 2023 5th International Conference on Intelligent Medicine and Image Processing (IMIP), Tianjin, China, 17–20 March 2023; pp. 51–58. [Google Scholar]
- Wang, W.; Wen, X.; Wang, X.; Tang, C.; Deng, J. CAW: A Remote-Sensing Scene Classification Network Aided by Local Window Attention. Computational Intell. Neurosci. 2022, 2022, 2661231. [Google Scholar] [CrossRef] [PubMed]
- Azad, R.; Heidari, M.; Shariatnia, M.; Aghdam, E.K.; Karimijafarbigloo, S.; Adeli, E.; Merhof, D. Transdeeplab: Convolution-free transformer-based deeplab v3+ for medical image segmentation. In Proceedings of the International Workshop on PRedictive Intelligence In MEdicine, Singapore, 22 September 2022; pp. 91–102. [Google Scholar]
- JetBrains. Pycharm. Available online: https://www.jetbrains.com/pycharm/ (accessed on 6 April 2023).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network | Time (not pre) | MIOU (not pre) | Time (pre) | MIOU (pre) |
|---|---|---|---|---|
| Mob-D | 5 | 27.0 | 3.3 (−1.7) | 54.0 (+27.0) |
| Res-D | 8.7 | 28.0 | 6 (−1.7) | 56.9 (+28.9) |
| Xcep-D | 7.5 | 33.6 | 2.7 (−4.8) | 50.5 (+16.9) |
| MPViT-D | 10.3 | 30.4 | 10 (−0.3) | 54.7 (+24.3) |
| Network | Bush Area | Grass | Lake | Terrace Greenery | Tree | MIOU |
|---|---|---|---|---|---|---|
| Mob-D | 75.4 | 92.9 | 98.6 | 67.5 | 89.0 | 84.7 |
| Res-D | 71.4 | 93.2 | 98.4 | 64.1 | 89.3 | 83.3 |
| Xce-D | 73.9 | 92.6 | 98.3 | 73.1 | 87.2 | 85.0 |
| MPViT-D | 71.1 | 93.8 | 98.2 | 74.8 | 89.4 | 85.4 |
| Network | Bush Area | Grass | Lake | Terrace Greenery | Tree | MIOU |
|---|---|---|---|---|---|---|
| MPViT-D | 71.1 | 93.8 | 98.2 | 74.8 | 89.4 | 85.4 |
| MPViT-D-T | 73.3 | 94.3 | 98.7 | 66.0 | 90.8 | 84.6 |
| MPViT-D-FM | 70.5 | 93.3 | 98.9 | 66.8 | 90.0 | 83.9 |
| MPViT-D-FD | 69.4 | 93.5 | 98.7 | 70.2 | 89.7 | 84.3 |
| MPViT-D-FA | 72.3 | 93.4 | 98.5 | 73.8 | 91.5 | 85.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, H.; Zhao, S.; Deng, H. Three-Stage MPViT-DeepLab Transfer Learning for Community-Scale Green Infrastructure Extraction. Information 2024, 15, 15. https://doi.org/10.3390/info15010015
Li H, Zhao S, Deng H. Three-Stage MPViT-DeepLab Transfer Learning for Community-Scale Green Infrastructure Extraction. Information. 2024; 15(1):15. https://doi.org/10.3390/info15010015
Chicago/Turabian StyleLi, Hang, Shengjie Zhao, and Hao Deng. 2024. "Three-Stage MPViT-DeepLab Transfer Learning for Community-Scale Green Infrastructure Extraction" Information 15, no. 1: 15. https://doi.org/10.3390/info15010015
APA StyleLi, H., Zhao, S., & Deng, H. (2024). Three-Stage MPViT-DeepLab Transfer Learning for Community-Scale Green Infrastructure Extraction. Information, 15(1), 15. https://doi.org/10.3390/info15010015