
Attacking Deep Learning AI Hardware with Universal Adversarial Perturbation


Abstract
:1. Introduction
- To the best of our knowledge, this work, for the first time, proposes and demonstrates an accelerator-based DNN attack that requires little to no knowledge about the target DNN model by exploiting universal adversarial perturbation (UAP). The proposed attack is sneaky enough to obscure its existence yet powerful enough to cause massive damage.
- We propose a novel technique to interleave the UAP noise with the actual image to mislead the trained DNN model when the attack is activated with malware or software/hardware trojans. Since our technique avoids the usual methods of adversarial noise injection at the sensor or camera level and directly injects at the accelerator hardware stage, it is more stealthy.
- We provide a detailed comparative analysis of the complexity, stealth, and implementation challenges of the existing Trojan, fault injection, bit-flip-based, and proposed UAP-based attacks on the AI/deep learning hardware.
2. Background
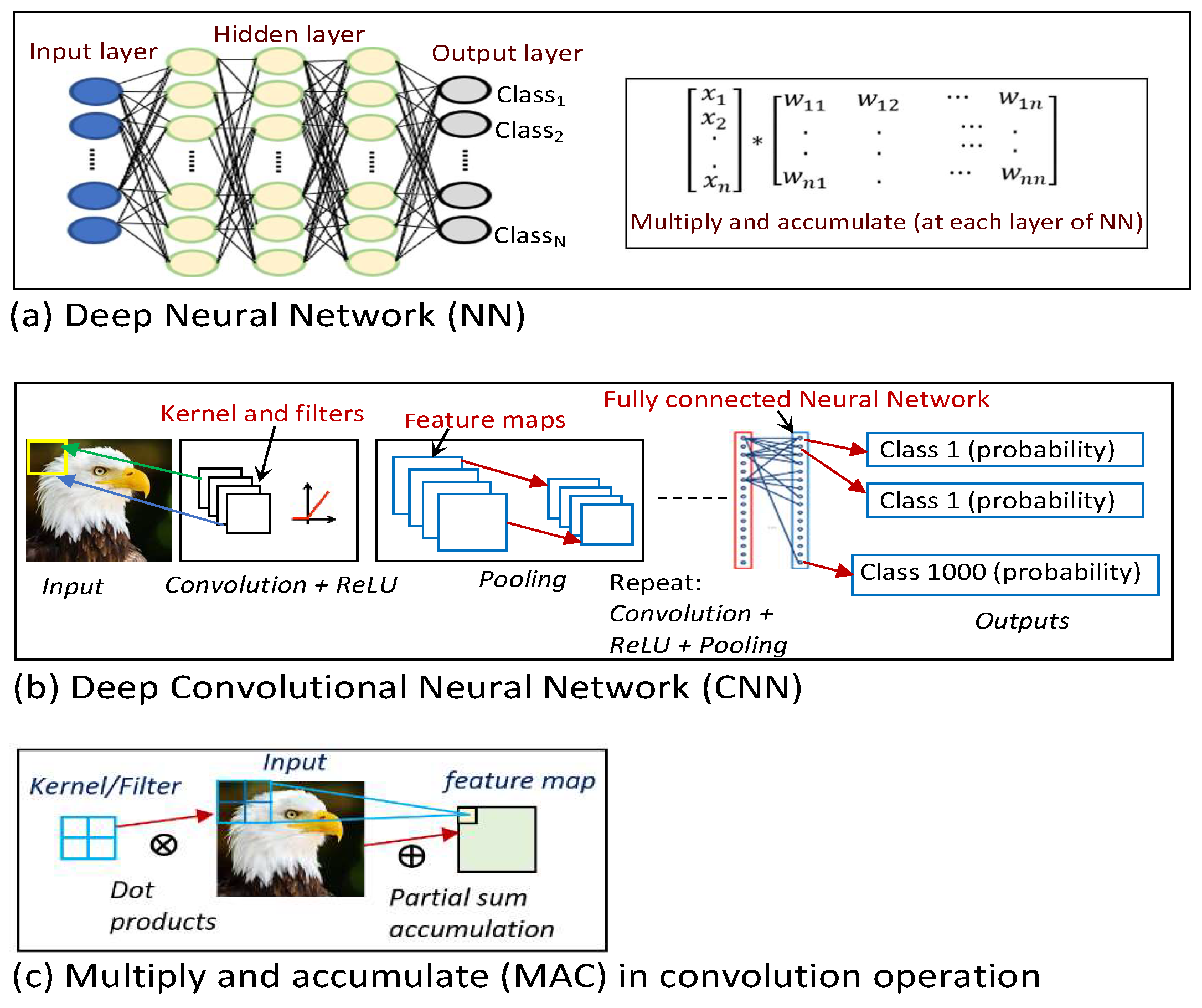
2.1. AI/Deep Learning Neural Networks
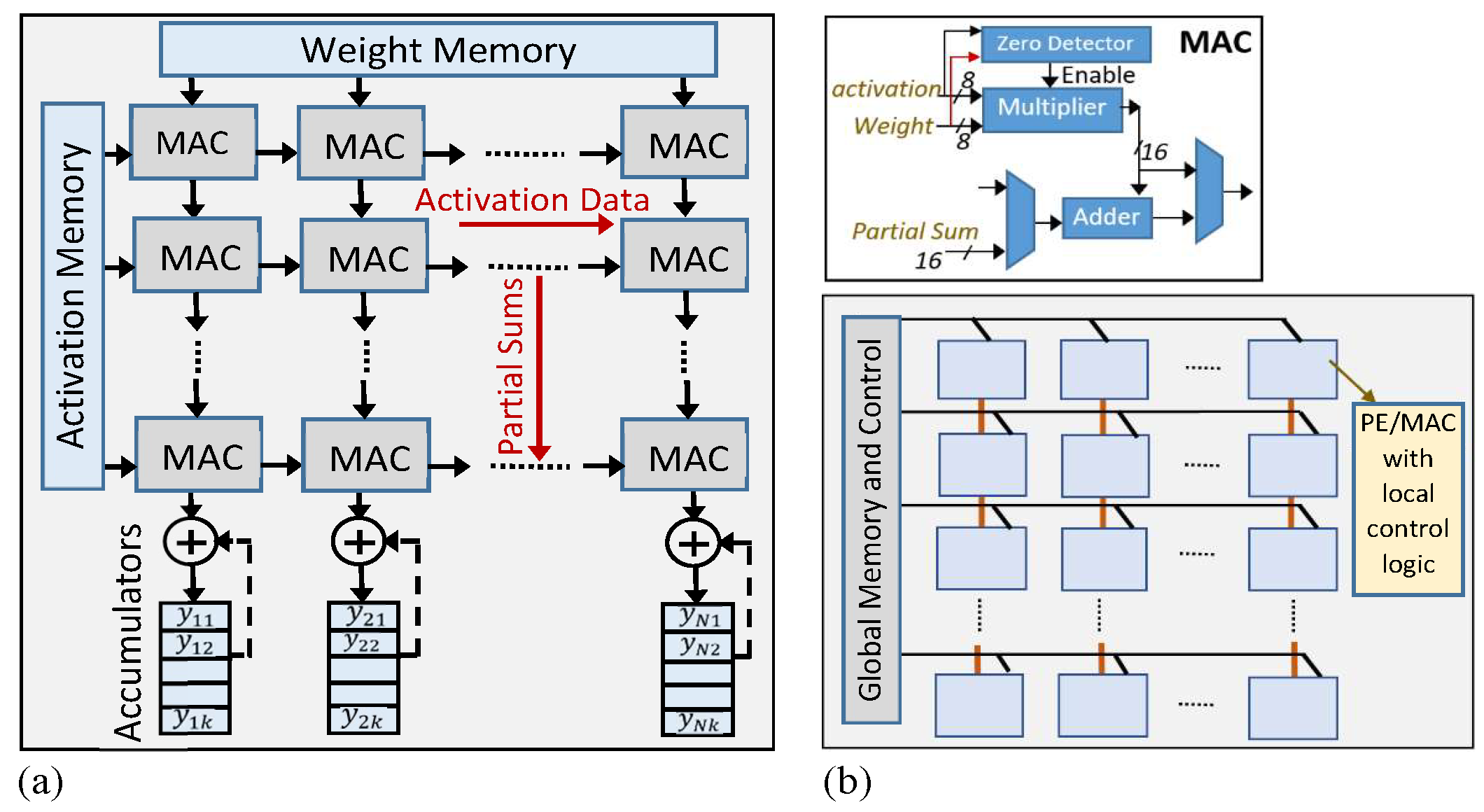
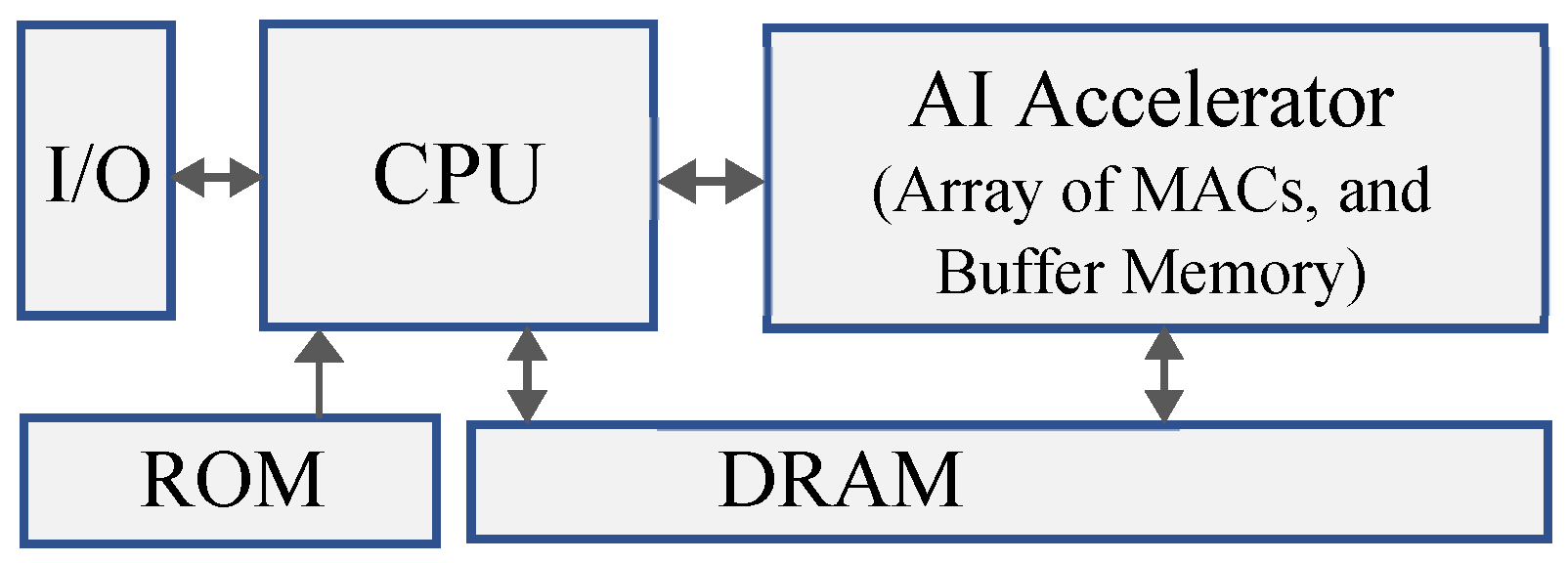
2.2. AI/Deep Learning Accelerator Architecture
2.3. Adversarial Perturbation to Mislead Trained AI Models
- -
- Generalization Property: Deep learning models demonstrate consistency in misclassifying adversarial samples. Adversarial images created for one deep learning model are often erroneously classified by other models with different hyperparameters (i.e., different model architecture, number of layers, initial weights, regularization, etc.) and a different subset of training data [5,6,7,8].
- -
Adversarial Sample Crafting
- -
- Image-based Adversarial Perturbation: In this method [5,6,7], adversarial samples are created on a per-image basis by adding carefully crafted noise to the original image along the gradient directions. Once a particular image is augmented with this noise, it can show its adversarial efficacy across different neural network models. However, to achieve a successful adversarial goal, the perturbation needs to be generated separately for each image [5,6].
- -
- Universal Adversarial Perturbations: In the second method [8], universal adversarial perturbations are generated based on the input (i.e., image) data distribution rather than individual images. In addition to being network-agnostic (i.e., transferable among different state-of-the-art deep learning models), these universal perturbations are image-agnostic and maintain their adversarial efficacy across different images belonging to the same distribution (e.g., ImageNet dataset). For a classification function f that outputs a predicted label for each image , a perturbation vector is the universal adversarial perturbation vector that misleads the classifier f on almost all data points sampled from the distribution of images in such that for most x in the distribution [8]. The algorithm to find v proceeds iteratively over a set of images sampled from the distribution and gradually builds the universal perturbations. Due to their small magnitude, the perturbations are hard to detect and do not significantly alter the data distributions. The universal perturbations were shown to have generalization and transferability properties across different architectures on the ImageNet dataset. This implies that, to fool a new image on an unknown deep neural network, a simple augmentation of a universal perturbation generated on AlexNet/VGG16 architecture is highly likely to misclassify the image.
2.4. Adversarial Attack Strategy during Deep Learning Inference
3. Threat Model

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attack Type | Attack Strategy (Details in Section 4) |
|---|---|
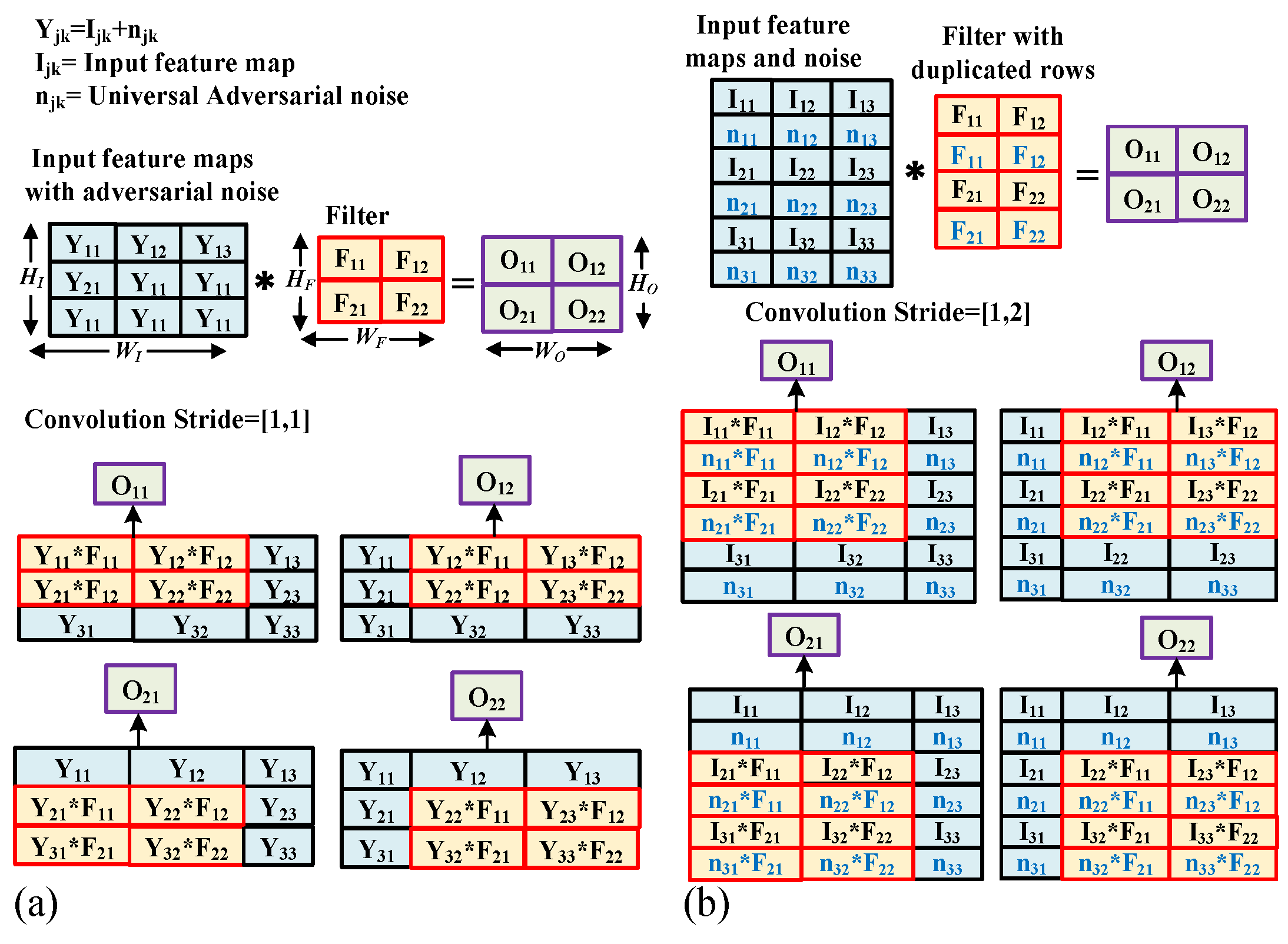
| Malicious Noise Interleaving and Convolution (MNIC) | Universal adversarial noise is interleaved with the original image, and the filter rows are repeated before the first convolution operation (see Figure 3). Malicious modification (e.g., with malware) of the inputs of the ‘Conv2D’ function can accomplish this task. |
4. Accelerator-Level Addition of Adversarial Perturbation
5. Stealth against Adversarial Detection Techniques
5.1. SGX Independence
5.2. Rowhammer Independence
5.3. Bypassing Conventional Countermeasures against Adversarial Noise
5.4. Non-Deterministic Execution
6. Experimental Results
7. Related Work and Comparison
7.1. Trojan-Based Attacks
7.2. Fault Injection Attack
7.3. Bit-Flip Attack
7.4. Comparison of Universal Adversarial Perturbation Attack with Other Attacks
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Google Deepmind. Available online: https://www.deepmind.com/ (accessed on 1 July 2023).
- Sze, V.; Chen, Y.H.; Yang, T.J.; Emer, J.S. Efficient processing of deep neural networks: A tutorial and survey. Proc. IEEE 2017, 105, 2295–2329. [Google Scholar] [CrossRef]
- Jouppi, N.P.; Young, C.; Patil, N.; Patterson, D.; Agrawal, G.; Bajwa, R.; Bates, S.; Bhatia, S.; Boden, N.; Borchers, A.; et al. In-datacenter performance analysis of a tensor processing unit. In Proceedings of the 44th Annual International Symposium on Computer Architecture, Toronto, ON, Canada, 24–28 June 2017; pp. 1–12. [Google Scholar]
- Intel VPUs. Available online: https://www.intel.com/content/www/ 601 us/en/products/details/processors/movidius-vpu.html (accessed on 1 July 2023).
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2014, arXiv:1312.6199. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. In Proceedings of the ICLR, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Tramèr, F.; Kurakin, A.; Papernot, N.; Goodfellow, I.; Boneh, D.; McDaniel, P. Ensemble Adversarial Training: Attacks and Defenses. In Proceedings of the ICLR, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Fawzi, O.; Frossard, P. Universal Adversarial Perturbations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Truong, L.; Jones, C.; Hutchinson, B.; August, A.; Praggastis, B.; Jasper, R.; Nichols, N.; Tuor, A. Systematic Evaluation of Backdoor Data Poisoning Attacks on Image Classifiers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Gu, T.; Dolan-Gavitt, B.; Garg, S. Badnets: Identifying vulnerabilities in the machine learning model supply chain. arXiv 2017, arXiv:1708.06733. [Google Scholar]
- Papernot, N.; McDaniel, P.; Goodfellow, I.; Jha, S.; Celik, Z.B.; Swami, A. Practical Black-Box Attacks against Machine Learning. In Proceedings of the ACM Asia Conference on Computer and Communications Security, Abu Dhabi, United Arab Emirates, 2–6 April 2017. [Google Scholar]
- Yuan, X.; He, P.; Zhu, Q.; Li, X. Adversarial examples: Attacks and defenses for deep learning. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 2805–2824. [Google Scholar] [CrossRef] [PubMed]
- Guin, U.; Huang, K.; DiMase, D.; Carulli, J.M.; Tehranipoor, M.; Makris, Y. Counterfeit integrated circuits: A rising threat in the global semiconductor supply chain. Proc. IEEE 2014, 102, 1207–1228. [Google Scholar] [CrossRef]
- Contreras, G.K.; Rahman, M.T.; Tehranipoor, M. Secure split-test for preventing IC piracy by untrusted foundry and assembly. In Proceedings of the 2013 IEEE International Symposium on Defect and Fault Tolerance in VLSI and Nanotechnology Systems (DFTS), New York, NY, USA, 2–4 October 2013; pp. 196–203. [Google Scholar]
- Symantec. Internet Security Threat Report (ISTR). 2019. Available online: https://docs.broadcom.com/doc/istr-24-executive-summary-en (accessed on 1 July 2023).
- Li, D.; Li, Q. Adversarial Deep Ensemble: Evasion Attacks and Defenses for Malware Detection. IEEE Trans. Inf. Forensics Secur. 2020, 15, 3886–3900. [Google Scholar] [CrossRef]
- Sayadi, H.; Patel, N.; Sasan, A.; Rafatirad, S.; Homayoun, H. Ensemble Learning for Effective Run-Time Hardware-Based Malware Detection: A Comprehensive Analysis and Classification. In Proceedings of the 2018 55th ACM/ESDA/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 24–28 June 2018. [Google Scholar]
- Symantec. W32.Stuxnet Dossier. 2011. Available online: https://web.archive.org/web/20191223000908/https://www.symantec.com/security-center/writeup/2010-071400-3123-99/ (accessed on 1 July 2023).
- Liu, H.; Ji, R.; Li, J.; Zhang, B.; Gao, Y.; Wu, Y.; Huang, F. Universal Adversarial Perturbation via Prior Driven Uncertainty Approximation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Clements, J.; Lao, Y. Hardware trojan attacks on neural networks. arXiv 2018, arXiv:1806.05768. [Google Scholar]
- Rakin, A.S.; He, Z.; Fan, D. Bit-flip attack: Crushing neural network with progressive bit search. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1211–1220. [Google Scholar]
- Hou, X.; Breier, J.; Jap, D.; Ma, L.; Bhasin, S.; Liu, Y. Security Evaluation of Deep Neural Network Resistance Against Laser Fault Injection. In Proceedings of the 2020 IEEE International Symposium on the Physical and Failure Analysis of Integrated Circuits (IPFA), Singapore, 20–23 July 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Liu, W.; Chang, C.H.; Zhang, F.; Lou, X. Imperceptible misclassification attack on deep learning accelerator by glitch injection. In Proceedings of the 2020 57th ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 20–24 July 2020; pp. 1–6. [Google Scholar]
- Zhao, P.; Wang, S.; Gongye, C.; Wang, Y.; Fei, Y.; Lin, X. Fault sneaking attack: A stealthy framework for misleading deep neural networks. In Proceedings of the 2019 56th ACM/IEEE Design Automation Conference (DAC), Las Vegas, NV, USA, 2–6 June 2019; pp. 1–6. [Google Scholar]
- Gao, Y.; Xu, C.; Wang, D.; Chen, S.; Ranasinghe, D.C.; Nepal, S. STRIP: A Defence against Trojan Attacks on Deep Neural Networks. In Proceedings of the 35th Annual Computer Security Applications Conference, Association for Computing Machinery, San Juan, PR, USA, 9–13 December 2019. [Google Scholar]
- Chou, E.; Tramèr, F.; Pellegrino, G. SentiNet: Detecting Localized Universal Attacks Against Deep Learning Systems. In Proceedings of the IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, 21 May 2020. [Google Scholar]
- Ligh, M.; Case, A.; Levy, J.; Walters, A. The Art of Memory Forensics: Detecting Malware and Threats in Windows, Linux, and Mac Memory; Wiley Publishing: Indianapolis, IN, USA, 2014. [Google Scholar]
- Block, F.; Dewald, A. Windows Memory Forensics: Detecting (Un)Intentionally Hidden Injected Code by Examining Page Table Entries. Digit. Investig. 2019, 29, S3–S12. [Google Scholar] [CrossRef]
- Costales, R.; Mao, C.; Norwitz, R.; Kim, B.; Yang, J. Live Trojan Attacks on Deep Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Cimpanu, C. Microsoft Warns about Astaroth Malware Campaign. Available online: https://www.zdnet.com/article/microsoft-warns-about-astaroth-malware-campaign (accessed on 1 July 2023).
- Rafter, D. What Is a Rootkit? And How to Stop Them. Proceedings of the NortonLifeLock. Available online: https://us.norton.com/internetsecurity-malware-what-is-a-rootkit-and-how-to-stop-them.html (accessed on 1 July 2023).
- Zhao, Y.; Hu, X.; Li, S.; Ye, J.; Deng, L.; Ji, Y.; Xu, J.; Wu, D.; Xie, Y. Memory Trojan Attack on Neural Network Accelerators. In Proceedings of the Design, Automation Test in Europe Conference Exhibition (DATE), Florence, Italy, 25–29 March 2019. [Google Scholar]
- Zhang, J.; Zhang, Y.; Li, H.; Jiang, J. HIT: A Hidden Instruction Trojan Model for Processors. In Proceedings of the Design, Automation Test in Europe Conference Exhibition (DATE), Grenoble, France, 9–13 March 2020. [Google Scholar]
- Alam, M.M.; Nahiyan, A.; Sadi, M.; Forte, D.; Tehranipoor, M. Soft-HaT: Software-Based Silicon Reprogramming for Hardware Trojan Implementation. ACM Trans. Des. Autom. Electron. Syst. 2020, 25, 1–22. [Google Scholar] [CrossRef]
- Costan, V.; Devadas, S. Intel SGX Explained. In Proceedings of the Cryptology ePrint Archive; Available online: http://css.csail.mit.edu/6.858/2020/readings/costan-sgx.pdf (accessed on 1 July 2023).
- Akhtar, N.; Liu, J.; Mian, A. Defense Against Universal Adversarial Perturbations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- PyTorch. Available online: https://pytorch.org/ (accessed on 1 July 2023).
- FuseSoC Platform. Available online: https://github.com/olofk/fusesoc (accessed on 1 July 2023).
- Torres-Huitzil, C.; Girau, B. Fault and error tolerance in neural networks: A review. IEEE Access 2017, 5, 17322–17341. [Google Scholar] [CrossRef]
- Hu, X.; Zhao, Y.; Deng, L.; Liang, L.; Zuo, P.; Ye, J.; Lin, Y.; Xie, Y. Practical Attacks on Deep Neural Networks by Memory Trojaning. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2021, 40, 1230–1243. [Google Scholar] [CrossRef]
- Liu, T.; Wen, W.; Jin, Y. SIN 2: Stealth infection on neural network—A low-cost agile neural Trojan attack methodology. In Proceedings of the 2018 IEEE International Symposium on Hardware Oriented Security and Trust (HOST), Washington, DC, USA, 30 April–4 May 2018; pp. 227–230. [Google Scholar]
- Ji, Y.; Liu, Z.; Hu, X.; Wang, P.; Zhang, Y. Programmable Neural Network Trojan for Pre-Trained Feature Extractor. arXiv 2019, arXiv:1901.07766. [Google Scholar]
- Li, W.; Yu, J.; Ning, X.; Wang, P.; Wei, Q.; Wang, Y.; Yang, H. Hu-fu: Hardware and software collaborative attack framework against neural networks. In Proceedings of the 2018 IEEE Computer Society Annual Symposium on VLSI (ISVLSI), Hong Kong, China, 8–11 July 2018; pp. 482–487. [Google Scholar]
- Liu, Y.; Wei, L.; Luo, B.; Xu, Q. Fault injection attack on deep neural network. In Proceedings of the 2017 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), Irvine, CA, USA, 13–16 November 2017; pp. 131–138. [Google Scholar]
- Kim, J.S.; Patel, M.; Yaglikci, A.G.; Hassan, H.; Azizi, R.; Orosa, L.; Mutlu, O. Revisiting RowHammer: An Experimental Analysis of Modern DRAM Devices and Mitigation Techniques. arXiv 2020, arXiv:2005.13121. [Google Scholar]
- Cojocar, L.; Kim, J.; Patel, M.; Tsai, L.; Saroiu, S.; Wolman, A.; Mutlu, O. Are We Susceptible to Rowhammer? An End-to-End Methodology for Cloud Providers. arXiv 2020, arXiv:2003.04498. [Google Scholar]
- Kim, Y.; Daly, R.; Kim, J.; Fallin, C.; Lee, J.H.; Lee, D.; Wilkerson, C.; Lai, K.; Mutlu, O. Flipping bits in memory without accessing them: An experimental study of DRAM disturbance errors. ACM Sigarch Comput. Archit. News 2014, 42, 361–372. [Google Scholar] [CrossRef]
- Mitigations Available for the DRAM Row Hammer Vulnerability, Cisco Blogs. Available online: https://blogs.cisco.com/security/mitigations-available-for-the-dram-row-hammer-vulnerability (accessed on 1 July 2023).
- Mishty, K.; Sadi, M. Designing Efficient and High-Performance AI Accelerators With Customized STT-MRAM. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2021, 29, 1730–1742. [Google Scholar] [CrossRef]



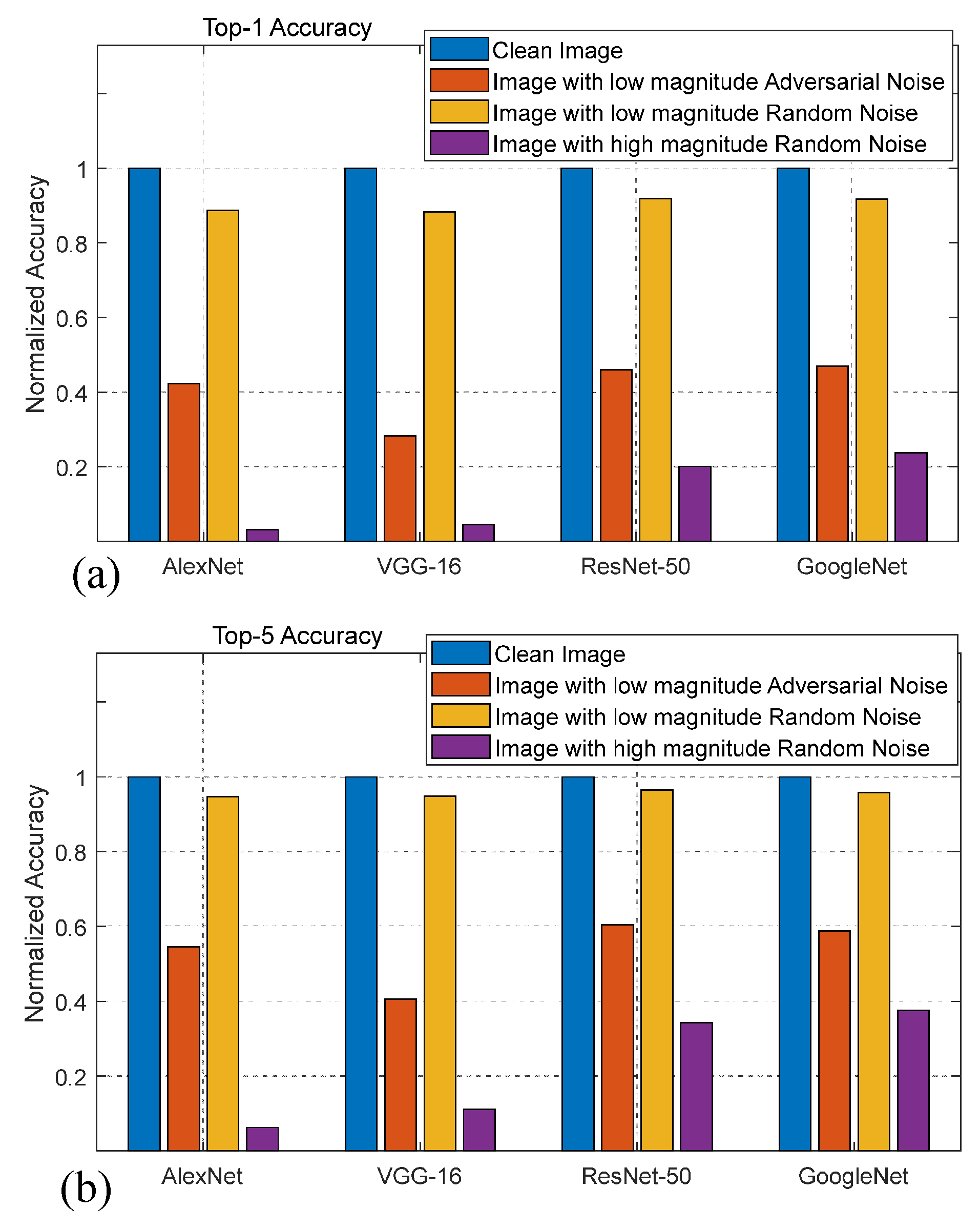

| Network | AlexNet | VGG-16 | ResNet-50 | GoogleNet |
|---|---|---|---|---|
| Adversarial Fooling Rate (%) | 90.8 | 88.9 | 84.2 | 85.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sadi, M.; Talukder, B.M.S.B.; Mishty, K.; Rahman, M.T. Attacking Deep Learning AI Hardware with Universal Adversarial Perturbation. Information 2023, 14, 516. https://doi.org/10.3390/info14090516
Sadi M, Talukder BMSB, Mishty K, Rahman MT. Attacking Deep Learning AI Hardware with Universal Adversarial Perturbation. Information. 2023; 14(9):516. https://doi.org/10.3390/info14090516
Chicago/Turabian StyleSadi, Mehdi, Bashir Mohammad Sabquat Bahar Talukder, Kaniz Mishty, and Md Tauhidur Rahman. 2023. "Attacking Deep Learning AI Hardware with Universal Adversarial Perturbation" Information 14, no. 9: 516. https://doi.org/10.3390/info14090516
APA StyleSadi, M., Talukder, B. M. S. B., Mishty, K., & Rahman, M. T. (2023). Attacking Deep Learning AI Hardware with Universal Adversarial Perturbation. Information, 14(9), 516. https://doi.org/10.3390/info14090516