
Analyzing Sentiments Regarding ChatGPT Using Novel BERT: A Machine Learning Approach

 ,
,  ,
,  ,
,  , ,
, ,  and
and 
Abstract
:1. Introduction
1.1. Research Questions
- RQ1: What are people’s sentiments about ChatGPT technology?
- RQ2: Which classification model is most effective, such as the proposed transformer-based models, machine learning-based models, and deep learning-based models, for analyzing sentiments about ChatGPT tweets?
- RQ3: What are the impacts of ChatGPT on student learning?
- RQ4: What role does topic modeling play in the sentiment analysis of social media tweets?
1.2. Contributions
- This study aims to analyze people’s perceptions of the trending topic of ChatGPT worldwide. The research contributes by collecting relevant data and examining the sentiments expressed by individuals toward this significant development.
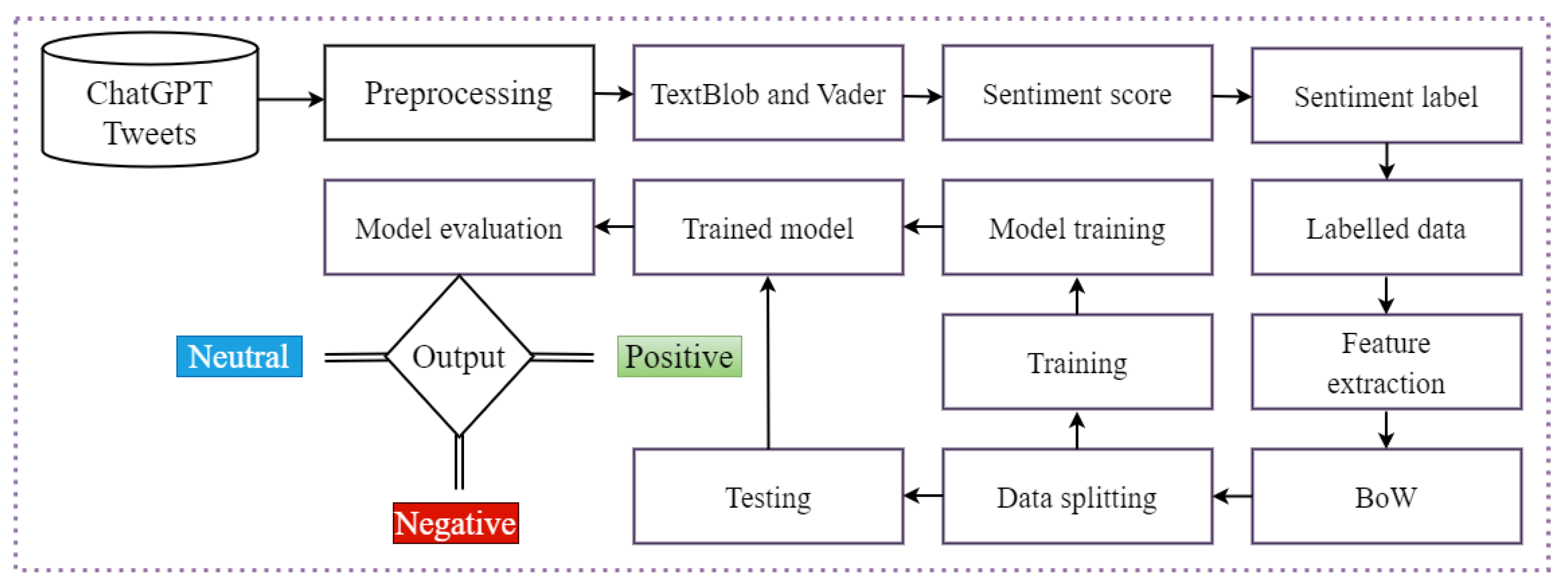
- Tweets related to ChatGPT are collected by utilizing the Tweepy application programming interface (API) and employing various keywords. The collected tweets undergo preprocessing and annotation using Textblob and the valence aware-dictionary (VADER). The bag of words (BoW) feature engineering technique is employed to extract essential features.
- A deep transformer-based BERT model is proposed for the sentiment analysis. It consists of three dense layers of neural networks for enhanced performance. Additionally, machine learning and deep learning models with fine-tuned parameters are utilized for comparison purposes. Notably, this study is the first to investigate ChatGPT raw tweets using Transformers.
- The study utilizes the latent Dirichlet allocation (LDA) approach to extract highly discussed topics from the dataset of ChatGPT tweets. This analysis provides valuable insights into the frequently discussed themes and subjects.
2. Related Work
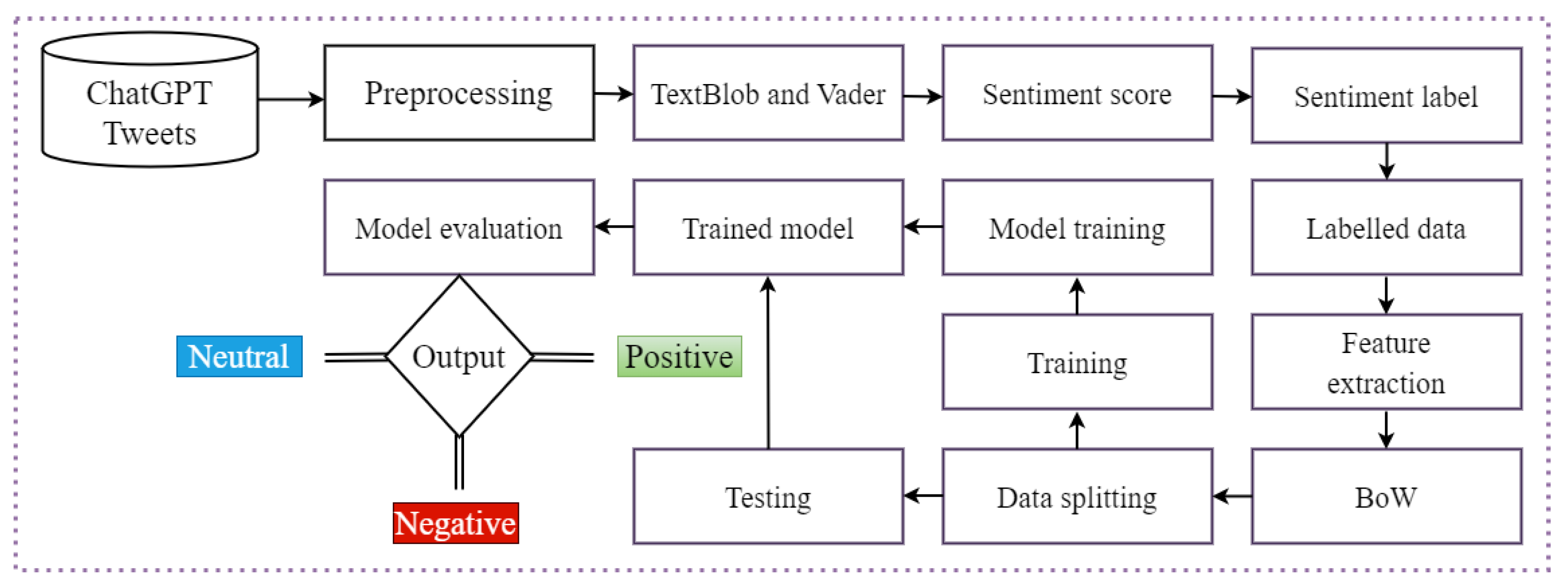
3. Methodology
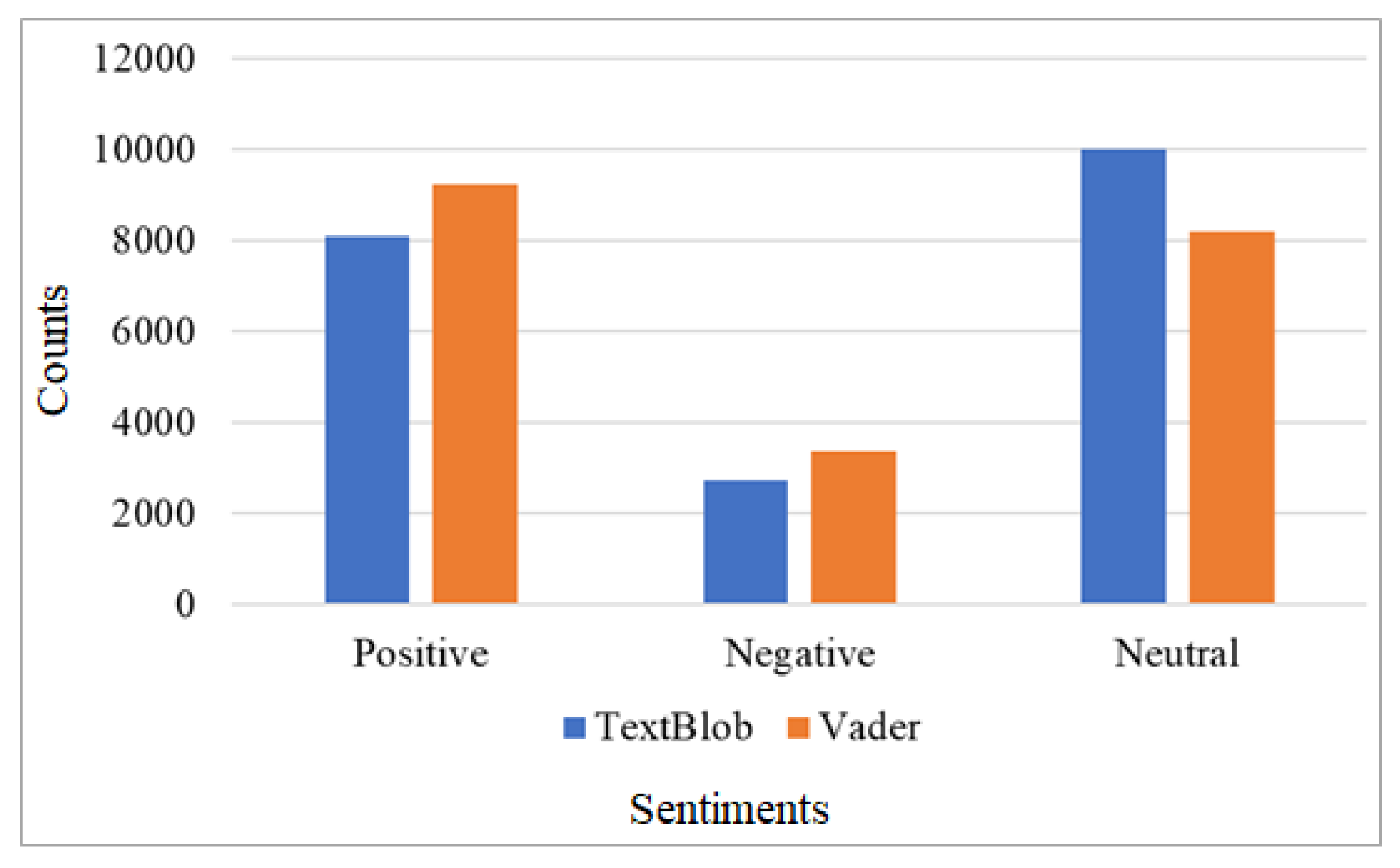
3.1. Dataset Description and Preprocessing
3.2. Lexicon Based Techniques
3.3. Feature Engineering
3.4. Machine and Deep Learning Models
- Logistic Regression: LR [56] is a simple machine learning model used in this study for sentiment classification. LR provides accurate results with preprocessed and highly relatable features. It is simple to implement and utilizes low computational resources. This model may not perform well on large datasets, cause overfitting, and does not learn complex patterns due to its simplicity.
- Random Forest: The RF is an ensemble supervised machine learning model used for classification, regression, and other NLP tasks [57]. The RF ensembles multiple decision trees to form a forest. A large amount of textual data and the ensemble of trees make the model more complex which takes a higher amount of time to train. The RF is powerful and has attained high accuracy for the sentiment analysis.
- Decision Tree: A DT is a supervised non-parametric learning model for classification and regression. The DT predicts a target variable using learned features to classify objects. A decision tree requires less data cleaning than other machine learning methods. In other words, decision trees do not require normalization during the early stages of machine learning tasks. They can handle both categorical and numerical information [58].
- K Nearest Neighbour: The KNN model requires no previous knowledge and does not learn from training data. It is also called the lazy learner. It does not perform well when data is not well normalized and structured. The performance can be manipulated with the distance metrics and K value [59].
- Support Vector Machine: The SVM is mostly used for classification tasks. It performs well where the number of dimensional spaces is greater than the number of samples [17]. The SVM does not perform well on large datasets because the training time increases. It is more robust and handles imbalanced datasets efficiently. The SVM can be used with ‘poly’, ‘linear’, and ‘rbf’ kernels.
- Extra Tree Classifier: The ETC is used for classification and regression [60]. Extra trees do not use the bootstrapping approach and train faster. The ETC requires fewer parameters for tuning compared to RF. Also, with extra trees, the chances of overfitting are less.
- Gradient Boosting Machine (GBM) and Stochastic Gradient Descent (SGD): The GBM [61] and SGD are supervised learning models for classification. To enhance the performance, the GBM combines multiple decision trees, and the SGD optimizes the gradient descent. The GBM is more complex and handles imbalanced data better than the SGD.
- Convolutional Neural Networks (CNN): The CNN [62] is a deep neural network model that is used for image classification, sentiment classification, object detection, and many other tasks. For sentiment classification, it first converts textual data into a numeric format, then make a matrix of word embedding layers. These embedding layers are then passed into convolutional, max-pooling, and dense layers, and the final output is passed through a dense softmax layer for classification.
- Recurrent Neural Network (RNN): The RNN [63] is a widely used model for text classification, speech recognition, and NLP tasks. The RNN can handle sequential data with complex long-term dependencies. This model is expensive to train and has the vanishing gradient issue for text classification.
- Long Shor-Term Memory: The LSTM [64] model was released to handle long-term dependencies, the gradient vanishing issue, and the complex training time. When compared to RNN, this model is much faster and uses less memory. It has three gates, including input, output, and forget, which are used to manage the data flow.
- Bidirectional LSTM: The BiLSTM is a deep learning model which is used for several tasks, including text classification as well [65]. The model provides better results for understanding the text in past and future contexts than the LSTM. It can learn information from both directions.
- Gated Recurrent Unit (GRU): The GRU solves the problem of vanishing gradient, faced by RNN [66]. It is fast and performs well on small datasets. The model has two gates: an update gate and a reset gate.
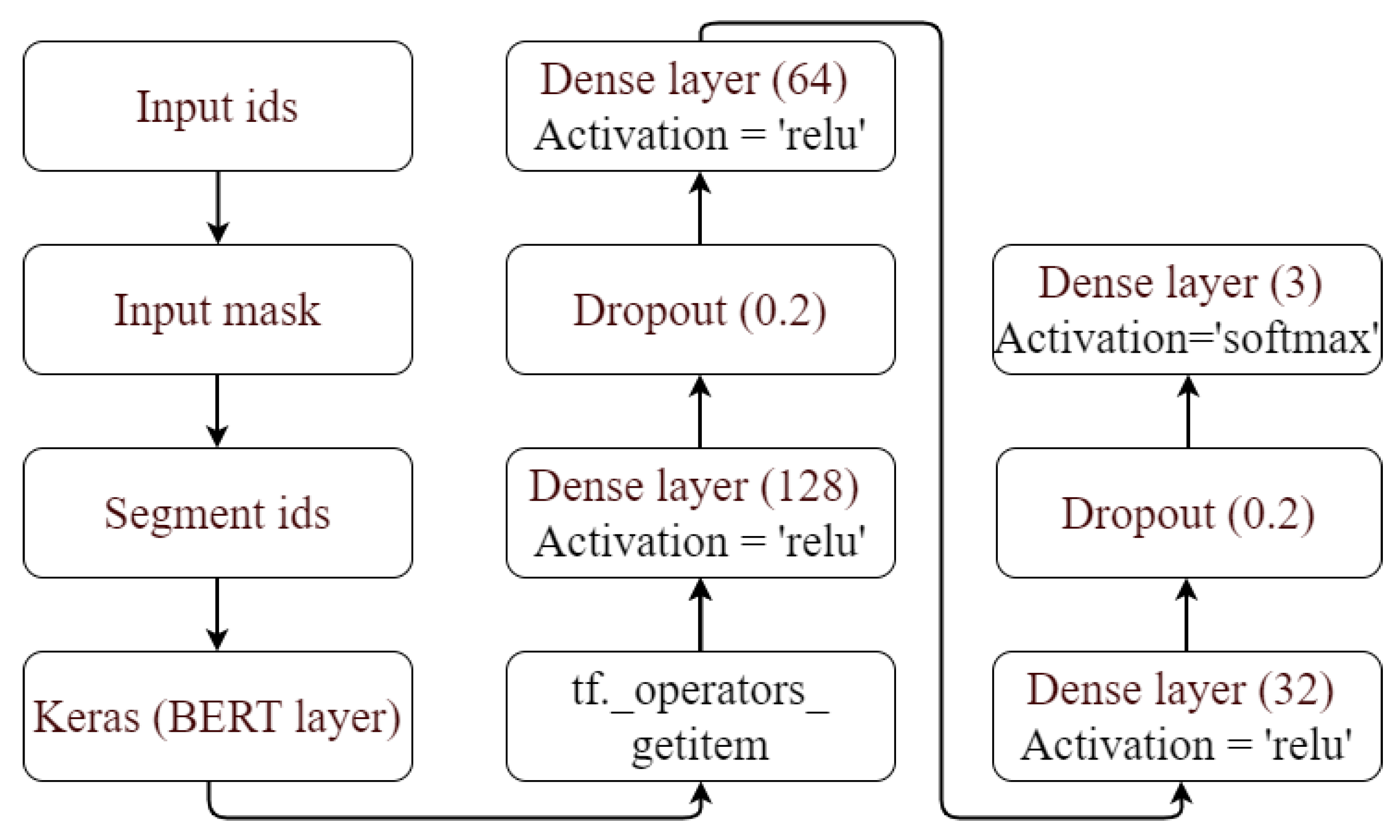
3.5. Transformer Based Architecture
3.6. Performance Metrics
4. Results and Discussion
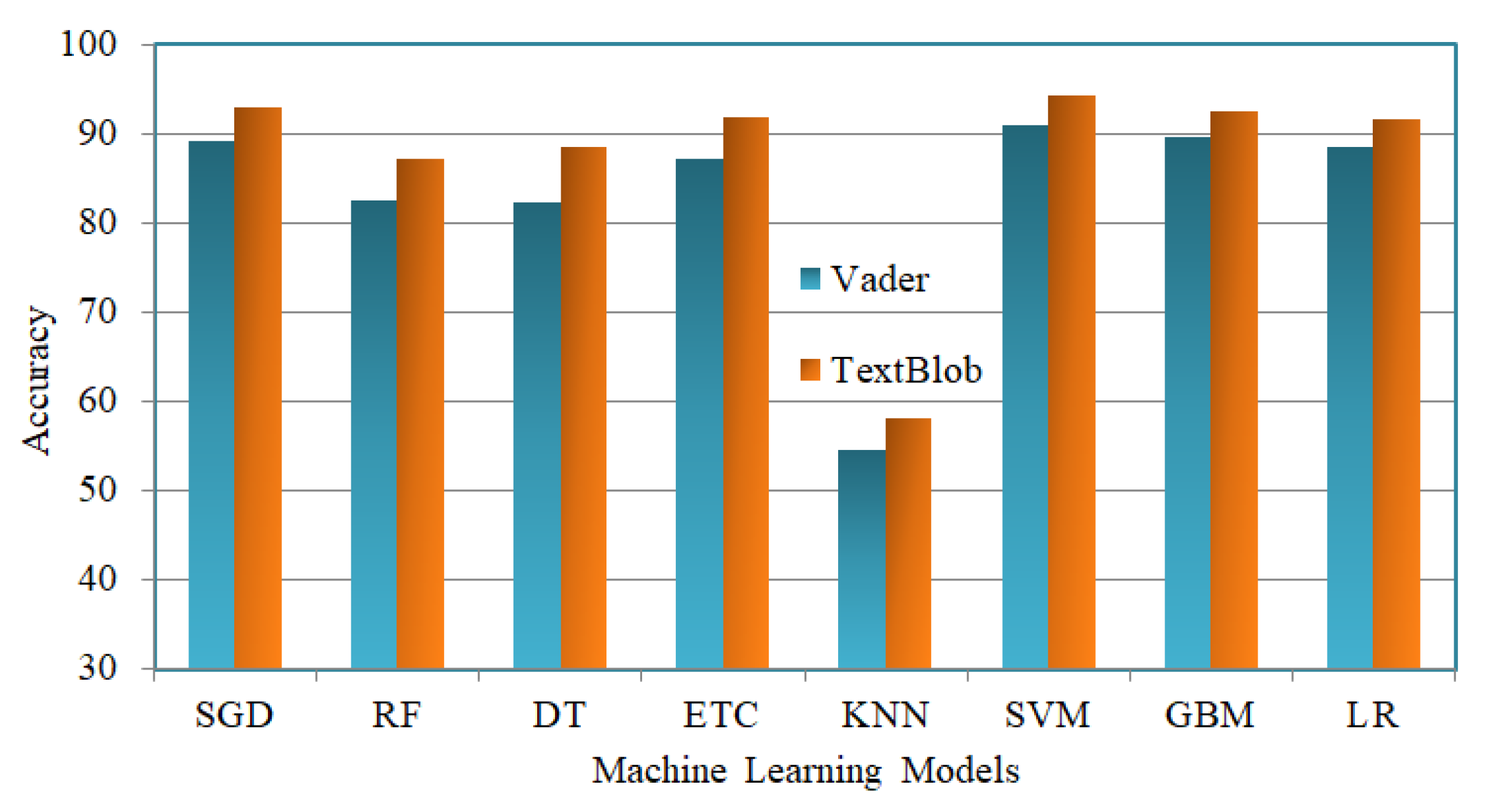
4.1. Results of Machine Learning Models
4.2. Performance of Deep Learning Models
4.3. Results of Transformer-Based Models
4.4. Results of K-Fold Cross-Validation
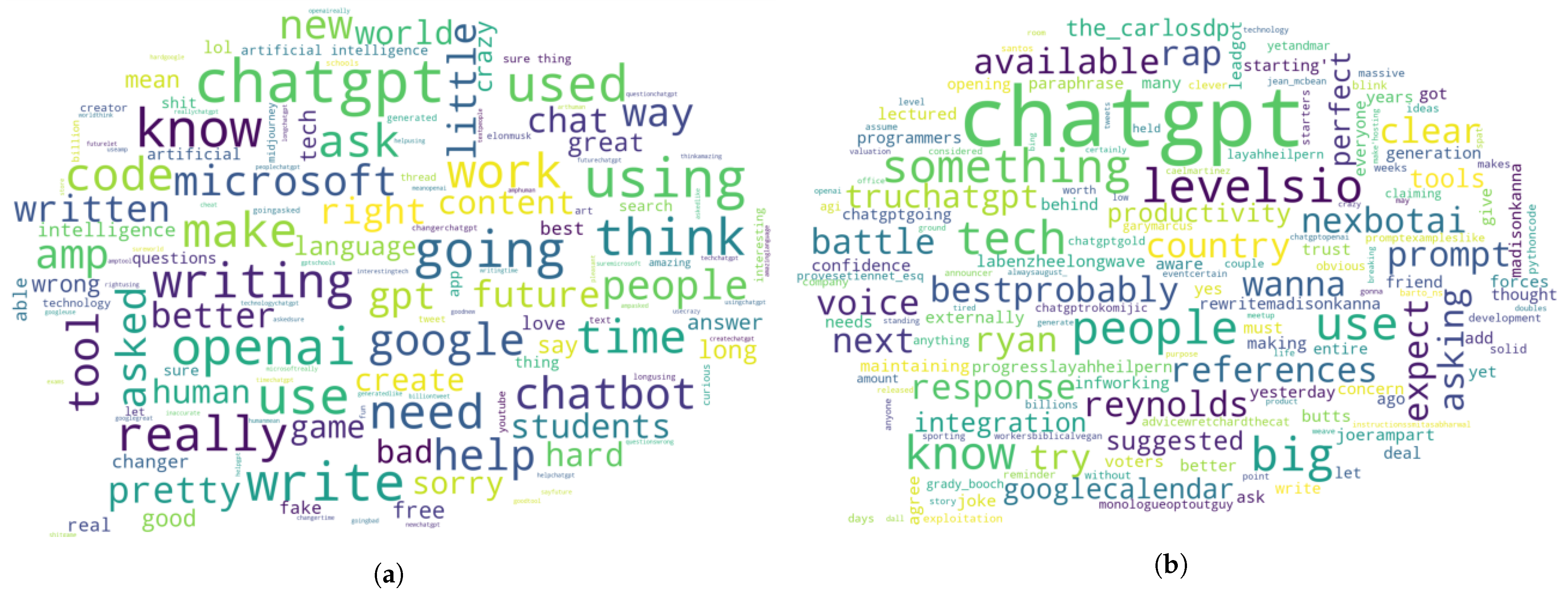
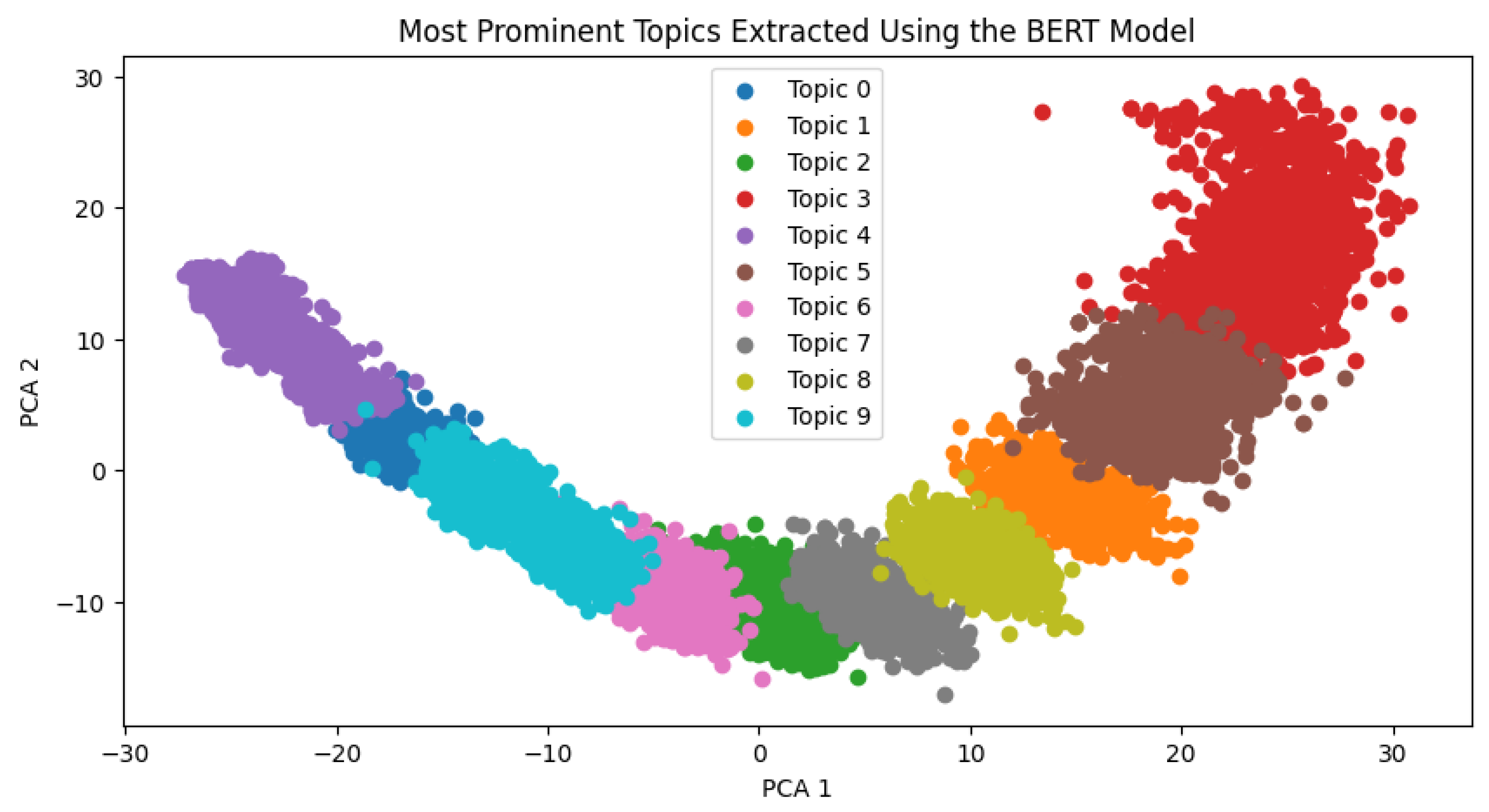
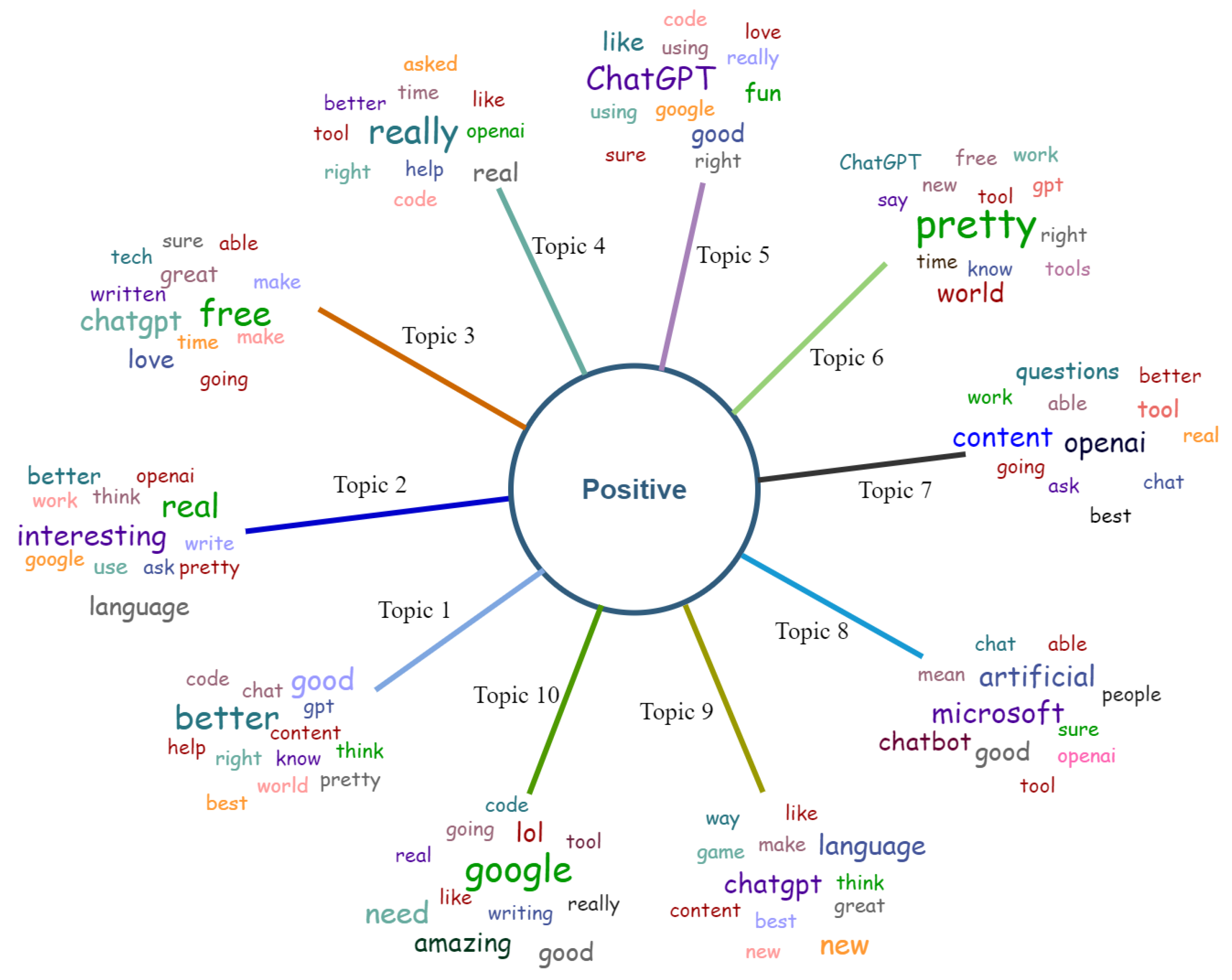
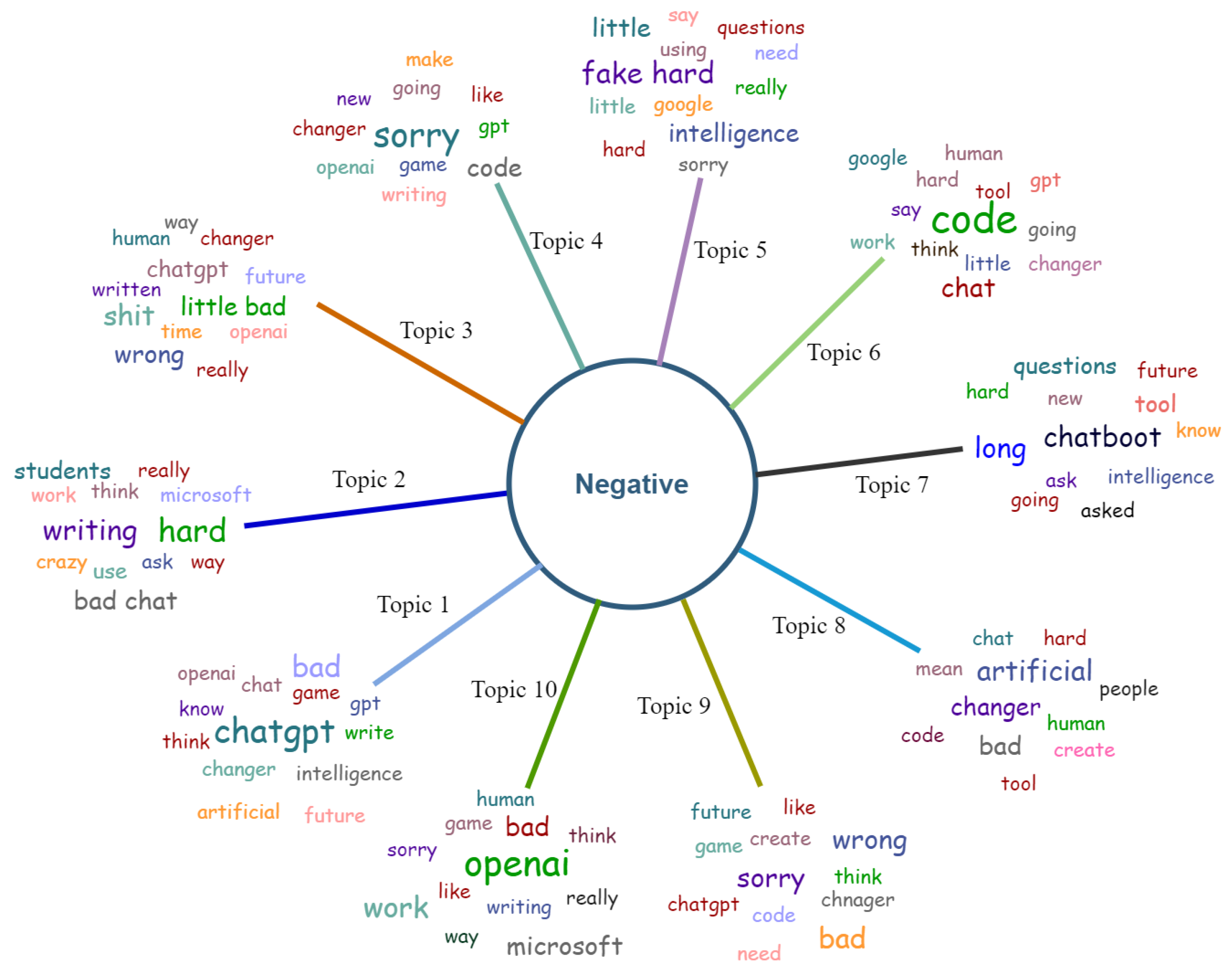
4.5. Topic Modeling Using BERTopic and LDA Method
4.6. Comparison of Proposed Approach with Machine Learning Models Using Statistical Test
4.7. Performance Comparison with State-of-the-Art Studies
4.8. Validation of Proposed Approach on Additional Dataset
4.9. Statistical Significance Test
- Null Hypothesis : The population means of the proposed approach’s results is equal to the compared approach’s results. (No statistical significance)
- Alternative Hypothesis : The population means of the proposed approach’s results is not equal to the compared approach’s results. ( Proposal approach is statistically significant)
4.10. Discussion
- RQ1: What are people’s sentiments about ChatGPT technology?Response: The authors analyzed a large dataset of tweets and were able to determine how individuals feel about ChatGPT technology. The results indicate that users have mixed feelings about ChatGPT, with some expressing positive opinions and others expressing negative views. These results provide useful information about how the public perceives ChatGPT and can assist researchers and developers in understanding the chatbot’s strengths and weaknesses. The favorable perception of chatGPT is attributable to its advanced language generation features and its ability to become involved in human-like interactions. Individuals are attracted by its cognitive power as well as its ability to effectively respond, thereby increasing user interest and satisfaction. The positive sentiments, like the new openai ChatGPT, writes user-generated content in a better way; it is a great language tool that codes you for your specific queries, etc.
- RQ2: Which classification model is most effective, such as the proposed transformer-based models, machine learning-based models, and deep learning-based models, for analyzing sentiments about ChatGPT tweets?Response: The experiments indicate that transformer-based BERT models are more effective and accurate for analyzing sentiments about the ChatGPT tweets. Since transformers make use of self-attention mechanisms, they give the same amount of attention to each component of the sequence that they are processing. They have the ability to virtually process any kind of sequential information. When it comes to natural language processing (NLP), the BERT model takes into account the context of words in both directions (left to right and right to left). Transformers have an in-depth understanding of the meanings of words and are useful for complex problems. In contrast, manual feature engineering, rigorous preprocessing, and a limited dataset are required for machine learning in order to improve accuracy. Additionally, deep learning has a less accurate automatic feature extraction method.
- RQ3: What are the impacts of ChatGPT on student learning?Response: The findings show that ChatGPT may have a significant impact on students’ learning. ChatGPT’s learning capabilities can help students learn when they do not attend school. ChatGPT is not recommended to be used as a substitute for analytical thinking and creative work, but also as a tool to develop research and writing skills. Students’ writing skills may not have improved if they relied completely on ChatGPT. There is also the possibility of receiving erroneous information, becoming excessively reliant on technology, and having poor reasoning skills.
- RQ4: What role does topic modeling play in the sentiment analysis of social media tweets?Response: Topic modeling refers to an unsupervised statistical method to assess whether or not a particular batch of documents contains any “topics” that are more generic in nature. In order to create a summary that is the most accurate depiction of the document’s contents, it extracts the text for commonly used words and phrases. There is a vast amount of unstructured data related to OpenAI ChatGPT, and traditional approaches are incapable of handling such data. Topic modeling can handle and extract meaningful information from unstructured text data efficiently. LDA-based modeling extracts the most discussed topics and prominent positive or negative keywords. It also provides clear information from the large corpus, which is very time-consuming if an individual extracts topics manually.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Meshram, S.; Naik, N.; Megha, V.; More, T.; Kharche, S. Conversational AI: Chatbots. In Proceedings of the 2021 International Conference on Intelligent Technologies (CONIT), Hubli, India, 25–27 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar]
- The Future of Chatbots: 10 Trends, Latest Stats & Market Size. Available online: https://onix-systems.com/blog/6-chatbot-trends-that-are-bringing-the-future-closer (accessed on 23 May 2023).
- Size of the Chatbot Market Worldwide from 2021 to 2030. Available online: https://www.statista.com/statistics/656596/worldwide-chatbot-market/ (accessed on 23 May 2023).
- Chatbot Market in 2022: Stats, Trends, and Companies in the Growing AI Chatbot Industry. Available online: https://www.insiderintelligence.com/insights/chatbot-market-stats-trends/ (accessed on 23 May 2023).
- Malinka, K.; Perešíni, M.; Firc, A.; Hujňák, O.; Januš, F. On the educational impact of ChatGPT: Is Artificial Intelligence ready to obtain a university degree? arXiv 2023, arXiv:2303.11146. [Google Scholar]
- George, A.S.; George, A.H. A review of ChatGPT AI’s impact on several business sectors. Partners Univers. Int. Innov. J. 2023, 1, 9–23. [Google Scholar]
- Lund, B.D.; Wang, T.; Mannuru, N.R.; Nie, B.; Shimray, S.; Wang, Z. ChatGPT and a new academic reality: Artificial Intelligence-written research papers and the ethics of the large language models in scholarly publishing. J. Assoc. Inf. Sci. Technol. 2023, 74, 570–581. [Google Scholar]
- Kirmani, A.R. Artificial Intelligence-Enabled Science Poetry. ACS Energy Lett. 2022, 8, 574–576. [Google Scholar]
- Cotton, D.R.; Cotton, P.A.; Shipway, J.R. Chatting and cheating: Ensuring academic integrity in the era of ChatGPT. Innov. Educ. Teach. Int. 2023, 1–12. [Google Scholar] [CrossRef]
- Tlili, A.; Shehata, B.; Adarkwah, M.A.; Bozkurt, A.; Hickey, D.T.; Huang, R.; Agyemang, B. What if the devil is my guardian angel: ChatGPT as a case study of using chatbots in education. Smart Learn. Environ. 2023, 10, 15. [Google Scholar]
- Edtech Chegg Tumbles as ChatGPT Threat Prompts Revenue Warning. Available online: https://www.reuters.com/markets/us/edtech-chegg-slumps-revenue-warning-chatgpt-threatens-growth-2023-05-02/ (accessed on 23 May 2023).
- Liu, B. Sentiment Analysis and Opinion Mining; Synthesis Lectures on Human Language Technologies; Springer: Cham, Switzerland, 2012; Volume 5, 167p. [Google Scholar]
- Medhat, W.; Hassan, A.; Korashy, H. Sentiment analysis algorithms and applications: A survey. Ain Shams Eng. J. 2014, 5, 1093–1113. [Google Scholar]
- Hussein, D.M.E.D.M. A survey on sentiment analysis challenges. J. King Saud Univ.-Eng. Sci. 2018, 30, 330–338. [Google Scholar]
- Lee, E.; Rustam, F.; Ashraf, I.; Washington, P.B.; Narra, M.; Shafique, R. Inquest of Current Situation in Afghanistan Under Taliban Rule Using Sentiment Analysis and Volume Analysis. IEEE Access 2022, 10, 10333–10348. [Google Scholar]
- Lee, E.; Rustam, F.; Washington, P.B.; El Barakaz, F.; Aljedaani, W.; Ashraf, I. Racism detection by analyzing differential opinions through sentiment analysis of tweets using stacked ensemble gcr-nn model. IEEE Access 2022, 10, 9717–9728. [Google Scholar] [CrossRef]
- Mujahid, M.; Lee, E.; Rustam, F.; Washington, P.B.; Ullah, S.; Reshi, A.A.; Ashraf, I. Sentiment analysis and topic modeling on tweets about online education during COVID-19. Appl. Sci. 2021, 11, 8438. [Google Scholar] [CrossRef]
- Tran, A.D.; Pallant, J.I.; Johnson, L.W. Exploring the impact of chatbots on consumer sentiment and expectations in retail. J. Retail. Consum. Serv. 2021, 63, 102718. [Google Scholar] [CrossRef]
- Muneshwara, M.; Swetha, M.; Rohidekar, M.P.; AB, M.P. Implementation of Therapy Bot for Potential Users With Depression During Covid-19 Using Sentiment Analysis. J. Posit. Sch. Psychol. 2022, 6, 7816–7826. [Google Scholar]
- Parimala, M.; Swarna Priya, R.; Praveen Kumar Reddy, M.; Lal Chowdhary, C.; Kumar Poluru, R.; Khan, S. Spatiotemporal-based sentiment analysis on tweets for risk assessment of event using deep learning approach. Softw. Pract. Exp. 2021, 51, 550–570. [Google Scholar] [CrossRef]
- Aslam, N.; Rustam, F.; Lee, E.; Washington, P.B.; Ashraf, I. Sentiment analysis and emotion detection on cryptocurrency related Tweets using ensemble LSTM-GRU Model. IEEE Access 2022, 10, 39313–39324. [Google Scholar] [CrossRef]
- Aslam, N.; Xia, K.; Rustam, F.; Lee, E.; Ashraf, I. Self voting classification model for online meeting app review sentiment analysis and topic modeling. PeerJ Comput. Sci. 2022, 8, e1141. [Google Scholar] [CrossRef] [PubMed]
- Araujo, A.F.; Gôlo, M.P.; Marcacini, R.M. Opinion mining for app reviews: An analysis of textual representation and predictive models. Autom. Softw. Eng. 2022, 29, 1–30. [Google Scholar] [CrossRef]
- Aljedaani, W.; Mkaouer, M.W.; Ludi, S.; Javed, Y. Automatic classification of accessibility user reviews in android apps. In Proceedings of the 2022 7th international conference on data science and machine learning applications (CDMA), Riyadh, Saudi Arabia, 1–3 March 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 133–138. [Google Scholar]
- Naeem, M.Z.; Rustam, F.; Mehmood, A.; Ashraf, I.; Choi, G.S. Classification of movie reviews using term frequency-inverse document frequency and optimized machine learning algorithms. PeerJ Comput. Sci. 2022, 8, e914. [Google Scholar] [CrossRef]
- Rustam, F.; Mehmood, A.; Ahmad, M.; Ullah, S.; Khan, D.M.; Choi, G.S. Classification of shopify app user reviews using novel multi text features. IEEE Access 2020, 8, 30234–30244. [Google Scholar] [CrossRef]
- Khalid, M.; Ashraf, I.; Mehmood, A.; Ullah, S.; Ahmad, M.; Choi, G.S. GBSVM: Sentiment classification from unstructured reviews using ensemble classifier. Appl. Sci. 2020, 10, 2788. [Google Scholar] [CrossRef]
- Umer, M.; Ashraf, I.; Mehmood, A.; Ullah, S.; Choi, G.S. Predicting numeric ratings for google apps using text features and ensemble learning. ETRI J. 2021, 43, 95–108. [Google Scholar] [CrossRef]
- Rehan, M.S.; Rustam, F.; Ullah, S.; Hussain, S.; Mehmood, A.; Choi, G.S. Employees reviews classification and evaluation (ERCE) model using supervised machine learning approaches. J. Ambient Intell. Humaniz. Comput. 2022, 13, 3119–3136. [Google Scholar] [CrossRef]
- Al Kilani, N.; Tailakh, R.; Hanani, A. Automatic classification of apps reviews for requirement engineering: Exploring the customers need from healthcare applications. In Proceedings of the 2019 Sixth International Conference on Social Networks Analysis, Management and Security (SNAMS), Granada, Spain, 22–25 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 541–548. [Google Scholar]
- Srisopha, K.; Phonsom, C.; Lin, K.; Boehm, B. Same app, different countries: A preliminary user reviews study on most downloaded ios apps. In Proceedings of the 2019 IEEE International Conference on Software Maintenance and Evolution (ICSME), Cleveland, OH, USA, 29 September–4 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 76–80. [Google Scholar]
- Hossain, M.S.; Rahman, M.F. Sentiment analysis and review rating prediction of the users of Bangladeshi Shopping Apps. In Developing Relationships, Personalization, and Data Herald in Marketing 5.0; IGI Global: Pennsylvania, PA USA, 2022; pp. 33–56. [Google Scholar]
- Bello, A.; Ng, S.C.; Leung, M.F. A BERT Framework to Sentiment Analysis of Tweets. Sensors 2023, 23, 506. [Google Scholar] [CrossRef]
- Catelli, R.; Pelosi, S.; Esposito, M. Lexicon-based vs. Bert-based sentiment analysis: A comparative study in Italian. Electronics 2022, 11, 374. [Google Scholar] [CrossRef]
- Patel, A.; Oza, P.; Agrawal, S. Sentiment Analysis of Customer Feedback and Reviews for Airline Services using Language Representation Model. Procedia Comput. Sci. 2023, 218, 2459–2467. [Google Scholar] [CrossRef]
- Mujahid, M.; Kanwal, K.; Rustam, F.; Aljadani, W.; Ashraf, I. Arabic ChatGPT Tweets Classification using RoBERTa and BERT Ensemble Model. Acm Trans. Asian-Low-Resour. Lang. Inf. Process. 2023. [Google Scholar] [CrossRef]
- Bonifazi, G.; Cauteruccio, F.; Corradini, E.; Marchetti, M.; Sciarretta, L.; Ursino, D.; Virgili, L. A Space-Time Framework for Sentiment Scope Analysis in Social Media. Big Data Cogn. Comput. 2022, 6, 130. [Google Scholar] [CrossRef]
- Bonifazi, G.; Corradini, E.; Ursino, D.; Virgili, L. Modeling, Evaluating, and Applying the eWoM Power of Reddit Posts. Big Data Cogn. Comput. 2023, 7, 47. [Google Scholar] [CrossRef]
- Messaoud, M.B.; Jenhani, I.; Jemaa, N.B.; Mkaouer, M.W. A multi-label active learning approach for mobile app user review classification. In Proceedings of the Knowledge Science, Engineering and Management: 12th International Conference, KSEM 2019, Athens, Greece, 28–30 August 2019; Proceedings, Part I 12. Springer: Berlin/Heidelberg, Germany, 2019; pp. 805–816. [Google Scholar]
- Fuad, A.; Al-Yahya, M. Analysis and classification of mobile apps using topic modeling: A case study on Google Play Arabic apps. Complexity 2021, 2021, 1–12. [Google Scholar] [CrossRef]
- Venkatakrishnan, S.; Kaushik, A.; Verma, J.K. Sentiment analysis on google play store data using deep learning. In Applications of Machine Learning; Springer: Singapore, 2020; pp. 15–30. [Google Scholar]
- Alam, S.; Yao, N. The impact of preprocessing steps on the accuracy of machine learning algorithms in sentiment analysis. Comput. Math. Organ. Theory 2019, 25, 319–335. [Google Scholar] [CrossRef]
- Vijayarani, S.; Ilamathi, M.J.; Nithya, M. Preprocessing techniques for text mining-an overview. Int. J. Comput. Sci. Commun. Netw. 2015, 5, 7–16. [Google Scholar]
- R, S.; Mujahid, M.; Rustam, F.; Mallampati, B.; Chunduri, V.; de la Torre Díez, I.; Ashraf, I. Bidirectional encoder representations from transformers and deep learning model for analyzing smartphone-related tweets. PeerJ Comput. Sci. 2023, 9, e1432. [Google Scholar] [CrossRef]
- Kadhim, A.I. An evaluation of preprocessing techniques for text classification. Int. J. Comput. Sci. Inf. Secur. 2018, 16, 22–32. [Google Scholar]
- Loria, S. Textblob Documentation. Release 0.15. 2018, Volume 2. Available online: https://buildmedia.readthedocs.org/media/pdf/textblob/latest/textblob.pdf (accessed on 23 May 2023).
- Borg, A.; Boldt, M. Using VADER sentiment and SVM for predicting customer response sentiment. Expert Syst. Appl. 2020, 162, 113746. [Google Scholar] [CrossRef]
- Karamibekr, M.; Ghorbani, A.A. Sentiment analysis of social issues. In Proceedings of the 2012 International Conference on Social Informatics, Alexandria, VA, USA, 14–16 December 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 215–221. [Google Scholar]
- Kumar, Y.; Koul, A.; Singla, R.; Ijaz, M.F. Artificial intelligence in disease diagnosis: A systematic literature review, synthesizing framework and future research agenda. J. Ambient. Intell. Humaniz. Comput. 2023, 14, 8459–8486. [Google Scholar] [CrossRef]
- Shafique, R.; Aljedaani, W.; Rustam, F.; Lee, E.; Mehmood, A.; Choi, G.S. Role of Artificial Intelligence in Online Education: A Systematic Mapping Study. IEEE Access 2023, 11, 52570–52584. [Google Scholar] [CrossRef]
- George, A.; Ravindran, A.; Mendieta, M.; Tabkhi, H. Mez: An adaptive messaging system for latency-sensitive multi-camera machine vision at the iot edge. IEEE Access 2021, 9, 21457–21473. [Google Scholar] [CrossRef]
- Ravindran, A.; George, A. An edge datastore architecture for Latency-Critical distributed machine vision applications. In Proceedings of the USENIX Workshop on Hot Topics in Edge Computing (HotEdge 18), Boston, MA, USA, 10 July 2018. [Google Scholar]
- Kadhim, A.I. Survey on supervised machine learning techniques for automatic text classification. Artif. Intell. Rev. 2019, 52, 273–292. [Google Scholar] [CrossRef]
- Chen, H.; Wu, L.; Chen, J.; Lu, W.; Ding, J. A comparative study of automated legal text classification using random forests and deep learning. Inf. Process. Manag. 2022, 59, 102798. [Google Scholar] [CrossRef]
- Schröder, C.; Niekler, A. A survey of active learning for text classification using deep neural networks. arXiv 2020, arXiv:2008.07267. [Google Scholar]
- Prabhat, A.; Khullar, V. Sentiment classification on big data using Naïve Bayes and logistic regression. In Proceedings of the 2017 International Conference on Computer Communication and Informatics (ICCCI), Coimbatore, India, 5–7 January 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–5. [Google Scholar]
- Valencia, F.; Gómez-Espinosa, A.; Valdés-Aguirre, B. Price movement prediction of cryptocurrencies using sentiment analysis and machine learning. Entropy 2019, 21, 589. [Google Scholar] [CrossRef] [PubMed]
- Zharmagambetov, A.S.; Pak, A.A. Sentiment analysis of a document using deep learning approach and decision trees. In Proceedings of the 2015 Twelve International Conference on Electronics Computer and Computation (ICECCO), Almaty, Kazakhstan, 27–30 September 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1–4. [Google Scholar]
- Shah, K.; Patel, H.; Sanghvi, D.; Shah, M. A comparative analysis of logistic regression, random forest and KNN models for the text classification. Augment. Hum. Res. 2020, 5, 12. [Google Scholar] [CrossRef]
- Tiwari, D.; Singh, N. Ensemble approach for twitter sentiment analysis. IJ Inf. Technol. Comput. Sci. 2019, 8, 20–26. [Google Scholar] [CrossRef]
- Arya, V.; Mishra, A.K.M.; González-Briones, A. Analysis of sentiments on the onset of COVID-19 using machine learning techniques. ADCAIJ Adv. Distrib. Comput. Artif. Intell. J. 2022, 11, 45–63. [Google Scholar] [CrossRef]
- Severyn, A.; Moschitti, A. Unitn: Training deep convolutional neural network for twitter sentiment classification. In Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval 2015), Denver, CO, USA, 4–5 June 2015; pp. 464–469. [Google Scholar]
- Seo, S.; Kim, C.; Kim, H.; Mo, K.; Kang, P. Comparative study of deep learning-based sentiment classification. IEEE Access 2020, 8, 6861–6875. [Google Scholar] [CrossRef]
- Nowak, J.; Taspinar, A.; Scherer, R. LSTM recurrent neural networks for short text and sentiment classification. In Proceedings of the Artificial Intelligence and Soft Computing: 16th International Conference, ICAISC 2017, Zakopane, Poland, 11–15 June 2017; Proceedings, Part II 16. Springer: Cham, Switzerland, 2017; pp. 553–562. [Google Scholar]
- Mujahid, M.; Rustam, F.; Alasim, F.; Siddique, M.; Ashraf, I. What people think about fast food: Opinions analysis and LDA modeling on fast food restaurants using unstructured tweets. PeerJ Comput. Sci. 2023, 9, e1193. [Google Scholar] [CrossRef]
- Tang, D.; Qin, B.; Liu, T. Document modeling with gated recurrent neural network for sentiment classification. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1422–1432. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Tenney, I.; Das, D.; Pavlick, E. BERT rediscovers the classical NLP pipeline. arXiv 2019, arXiv:1905.05950. [Google Scholar]
- González-Carvajal, S.; Garrido-Merchán, E.C. Comparing BERT against traditional machine learning text classification. arXiv 2020, arXiv:2005.13012. [Google Scholar]
- Cruz, J.C.B.; Cheng, C. Establishing baselines for text classification in low-resource languages. arXiv 2020, arXiv:2005.02068. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. Xlnet: Generalized autoregressive pretraining for language understanding. Adv. Neural Inf. Process. Syst. 2019, 32, 5753–5763. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Amaar, A.; Aljedaani, W.; Rustam, F.; Ullah, S.; Rupapara, V.; Ludi, S. Detection of fake job postings by utilizing machine learning and natural language processing approaches. Neural Process. Lett. 2022, 54, 2219–2247. [Google Scholar] [CrossRef]
- Jelodar, H.; Wang, Y.; Yuan, C.; Feng, X.; Jiang, X.; Li, Y.; Zhao, L. Latent Dirichlet allocation (LDA) and topic modeling: Models, applications, a survey. Multimed. Tools Appl. 2019, 78, 15169–15211. [Google Scholar] [CrossRef]
- Wadhwa, S.; Babber, K. Performance comparison of classifiers on twitter sentimental analysis. Eur. J. Eng. Sci. Technol. 2021, 4, 15–24. [Google Scholar] [CrossRef]
- SemEvel2013 Dataset. Available online: https://www.kaggle.com/datasets/azzouza2018/semevaldatadets?select=semeval-2013-train-all.csv (accessed on 23 May 2023).
- Rustam, F.; Ashraf, I.; Mehmood, A.; Ullah, S.; Choi, G.S. Tweets classification on the base of sentiments for US airline companies. Entropy 2019, 21, 1078. [Google Scholar] [CrossRef]
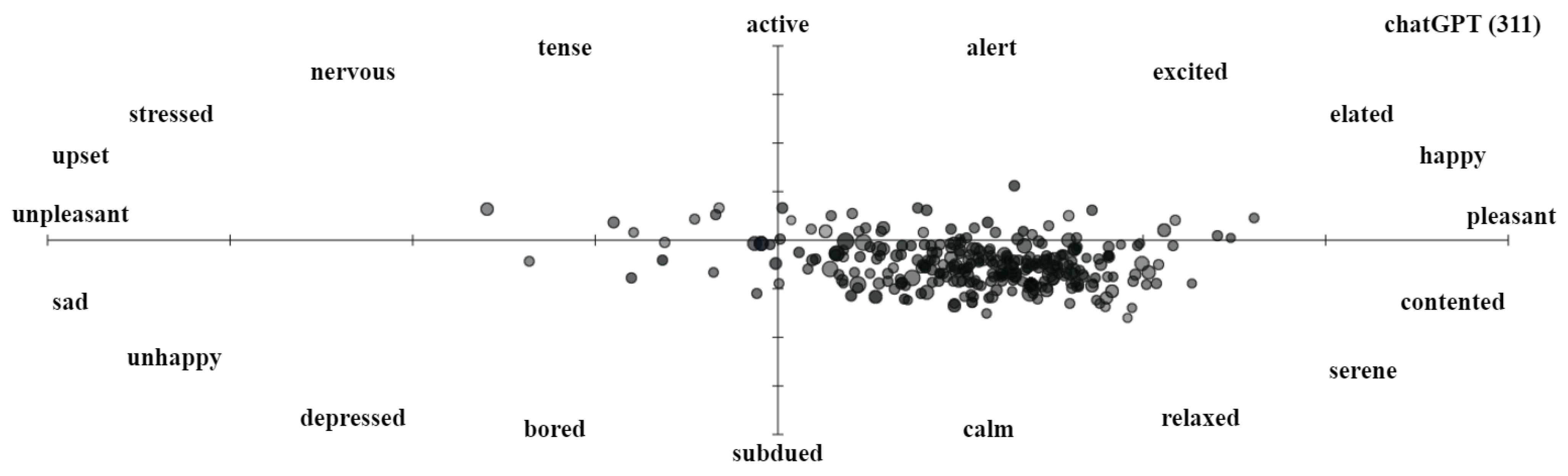
- Sentiment Viz: Tweet Sentiment Visualization. Available online: https://www.csc2.ncsu.edu/faculty/healey/tweet_viz/tweet_app/ (accessed on 23 May 2023).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors | Techniques | Advantages | Disadvantages | Limitations |
|---|---|---|---|---|
| [16] | TextBlob, CNN, RNN, GRU, DT, RF, SVM | The authors make an ensemble model by combining the GRU, CNN, and RNN for the extraction of features from the tweets and detection. They also performed seven experiments to test the proposed ensemble approach. | The authors develop ensemble models, which need a significant amount of time to both train and identify the sentiments. | The authors used a limited dataset and did not develop transformer-based models that are the most up-to-date and that provide high accuracy. |
| [17] | TextBlob, CNN, LSTM, SVM, GBM, KNN, DT, LSTM-CNN | This study employed machine learning as well as deep learning for the analysis of tweets. They utilized various annotation and feature engineering techniques. Machine learning outperformed deep learning with an accuracy of 95%. | The study did not clearly describe the preprocessing stages and their implementations. | The dataset included in this study was restricted to tweets that were not associated with ChatGPT tweets. |
| [18] | BERT | The authors conducted this research to analyze the depression tweets during the period of COVID-19 and achieved remarkable results with BERT. | To speed up computation, the research did not remove stopwords, punctuation, numerical values, etc., from the text. Additionally, the accuracy was inadequate. | The research only proposed one model, which was BERT, and did not compare with other studies. |
| [19] | Naïve Bayes | The data in the study was labeled using the Vader technique, and the Nave Bayes model was implemented to examine the influence of chatbots on customer opinions and demands within the retail industry. | The study detected positive, neutral, and negative sentiments and used the Ancova test only for the experiments. | The study did not use the most important metrics like accuracy, deep models, or transformers. The study is limited to the Nave Bayes model. |
| [21] | LSTM + GRU, CNN, SVM, DT, TFIDF | Their primary area of research revolves around sentiment evaluation and detecting emotions using tweets that are associated with cryptocurrencies. The utilization of an ensemble model, namely the LSTM-GRU model, involves the integration of both LSTM and GRU architectures in order to improve the accuracy of the analysis. | The author used ensemble models, which necessitate substantial time for both training and sentiment identification. | The study is regarding the cryptography analysis. Also, transformers are ignored in this study. |
| [26] | RF, LR, and AC | The study used various feature engineering strategies, including bag-of-words; term frequency, inverse document-frequency, and Chi-2 are employed individually and collectively in order to attain meaningful information from the tweets. | The study employed various feature engineering strategies but did not use cross-dataset experiments with machine learning classifiers. The LR achieved a 83% lowest accuracy. | The study does not use Chatbots or ChatGPT-related tweets for the experiments. In addition, their focus is on utilizing machine learning models for Shopify reviews. |
| [30] | SVM, RF, and NB | The dataset was obtained by the authors from the most popular ten applications. The findings of the study revealed that a baseline 10-fold validation approach resulted in an accuracy rate of 90.8%. | The paper is about app reviews, not ChatGPT tweets. | The accuracy achieved is very low, and the study did not use any deep transformers to improve its efficiency. |
| Tweets | Training | Testing | Total |
|---|---|---|---|
| Positive | 6476 | 1619 | 8095 |
| Negative | 1281 | 546 | 2727 |
| Neutral | 7983 | 1996 | 9979 |
| Total | 16,640 | 4161 | 20,801 |
| Unstructured Tweets | Structured Tweets (Preprocessed) |
|---|---|
| I asked #chatgpt to write a story instalment with Tim giving the octopus a name. Originality wasn’t its strongpoint € | https://t.co/rbB5prcJ2r (accessed on 2 April 2023). | asked chatgpt write story instalment tim giving octopus name originality strongpoint |
| ChatGPT is taking the web by storm; If you’re unable to try it on their site, feel free to test it out through us! € | https://t.co/jfmOQmjSHo (accessed on 2 April 2023). | chatgpt taking web storm unable try site feel free test |
| People weaponizing a powerful AI tool like ChatGPT days into launch has to be the most predictable internet | people weaponizing powerful tool like chatgpt days launch predictable internet |
| Model | Parameters Tuning |
|---|---|
| RF | n_estimators = 100, random_state = 50, max_depth = 150 |
| GBM | n_estimators = 100, random_state = 100, max_depth = 300 |
| LR | random_state = 150, solver = ‘newton-cg’, multi_class = ‘multinomial’, C = 2.0 |
| SVM | kernel = ‘linear’, C = 1.0, random_state = 200 |
| KNN | n_neighbors = 3 |
| DT | random_state = 100, max_depth = 150 |
| ETC | n_estimators = 100, random_state = 150, max_depth = 300 |
| SGD | loss = “hinge”, penalty = “l1”, max_iter = 6 |
| CNN | 616,003 trainable parameters |
| RNN | 633,539 trainable parameters |
| LSTM | 655,235 trainable parameters |
| BILSTM | 726,787 trainable parameters |
| GRU | 692,547 trainable parameters |
| Vader | TextBlob | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Model | Accuracy | Class | Precision | Recall | F1 Score | Accuracy | Precision | Recall | F1 Score |
| SGD | 89.13 | Positive | 93 | 92 | 93 | 92.76 | 94 | 93 | 93 |
| Negative | 84 | 69 | 76 | 89 | 75 | 81 | |||
| Neutral | 87 | 94 | 90 | 93 | 95 | 97 | |||
| RF | 82.40 | Positive | 92 | 83 | 88 | 86.99 | 94 | 85 | 89 |
| Negative | 92 | 43 | 58 | 94 | 47 | 63 | |||
| Neutral | 73 | 98 | 84 | 82 | 99 | 90 | |||
| DT | 82.26 | Positive | 93 | 82 | 87 | 88.29 | 94 | 85 | 90 |
| Negative | 82 | 47 | 60 | 89 | 56 | 69 | |||
| Neutral | 94 | 97 | 84 | 84 | 99 | 91 | |||
| ETC | 87.11 | Positive | 93 | 89 | 91 | 91.80 | 94 | 91 | 93 |
| Negative | 92 | 56 | 69 | 90 | 66 | 76 | |||
| Neutral | 81 | 98 | 89 | 90 | 99 | 94 | |||
| KNN | 54.38 | Positive | 95 | 47 | 22 | 58.03 | 95 | 20 | 34 |
| Negative | 83 | 20 | 33 | 80 | 18 | 30 | |||
| Neutral | 47 | 99 | 64 | 54 | 99 | 70 | |||
| SVM | 90.72 | Positive | 95 | 92 | 94 | 94.23 | 96 | 94 | 95 |
| Negative | 85 | 73 | 79 | 88 | 89 | 83 | |||
| Neutral | 89 | 96 | 92 | 94 | 99 | 96 | |||
| GBM | 89.56 | Positive | 93 | 92 | 92 | 92.28 | 94 | 94 | 94 |
| Negative | 92 | 65 | 76 | 91 | 63 | 74 | |||
| Neutral | 85 | 97 | 91 | 91 | 99 | 95 | |||
| LR | 88.44 | Positive | 93 | 91 | 92 | 91.56 | 95 | 91 | 93 |
| Negative | 89 | 63 | 74 | 92 | 66 | 77 | |||
| Neutral | 84 | 96 | 90 | 89 | 99 | 96 | |||
| Model | Accuracy | Class | Precision | Recall | F1 Score |
|---|---|---|---|---|---|
| CNN | 70.88 | Positive | 73 | 66 | 69 |
| Negative | 56 | 48 | 52 | ||
| Neutral | 71 | 81 | 77 | ||
| RNN | 90.35 | Positive | 91 | 92 | 92 |
| Negative | 80 | 71 | 75 | ||
| Neutral | 92 | 94 | 93 | ||
| LSTM | 92.95 | Positive | 93 | 94 | 93 |
| Negative | 83 | 82 | 82 | ||
| Neutral | 96 | 96 | 96 | ||
| BiLSTM | 93.12 | Positive | 91 | 96 | 93 |
| Negative | 86 | 81 | 83 | ||
| Neutral | 97 | 94 | 12 | ||
| GRU | 92.33 | Positive | 92 | 94 | 93 |
| Negative | 82 | 81 | 82 | ||
| Neutral | 95 | 94 | 95 |
| Model | Accuracy | Class | Precision | Recall | F1 Score |
|---|---|---|---|---|---|
| CNN | 68.77 | Positive | 77 | 68 | 72 |
| Negative | 56 | 44 | 50 | ||
| Neutral | 65 | 80 | 72 | ||
| RNN | 82.40 | Positive | 809 | 88 | 89 |
| Negative | 62 | 66 | 64 | ||
| Neutral | 83 | 82 | 83 | ||
| LSTM | 87.33 | Positive | 89 | 92 | 90 |
| Negative | 74 | 75 | 75 | ||
| Neutral | 91 | 87 | 89 | ||
| BiLSTM | 86.95 | Positive | 88 | 93 | 90 |
| Negative | 76 | 74 | 75 | ||
| Neutral | 91 | 86 | 88 | ||
| GRU | 86.48 | Positive | 88 | 93 | 90 |
| Negative | 74 | 70 | 72 | ||
| Neutral | 90 | 86 | 88 |
| Model | Accuracy | Class | Precision | Recall | F1 Score |
|---|---|---|---|---|---|
| RoBERTa | 93.68 | Positive | 95 | 96 | 93 |
| Negative | 84 | 85 | 85 | ||
| Neutral | 95 | 96 | 96 | ||
| XLNet | 85.96 | Positive | 93 | 83 | 87 |
| Negative | 66 | 77 | 71 | ||
| Neutral | 86 | 91 | 89 | ||
| Proposed BERT | 96.49 | Positive | 96 | 98 | 97 |
| Negative | 92 | 90 | 91 | ||
| Neutral | 98 | 97 | 98 |
| Model | Accuracy | Class | Precision | Recall | F1 Score |
|---|---|---|---|---|---|
| RoBERTa | 86.68 | Positive | 75 | 79 | 77 |
| Negative | 88 | 88 | 88 | ||
| Neutral | 90 | 88 | 89 | ||
| XLNet | 68.51 | Positive | 66 | 72 | 69 |
| Negative | 25 | 45 | 32 | ||
| Neutral | 85 | 70 | 76 | ||
| Proposed BERT | 93.37 | Positive | 97 | 92 | 95 |
| Negative | 87 | 89 | 88 | ||
| Neutral | 93 | 96 | 94 |
| Model | Correct-Predictions | Wrong-Predictions | Total-Predictions |
|---|---|---|---|
| CNN | 2835 | 1165 | 4000 |
| RNN | 3614 | 386 | 4000 |
| LSTM | 3718 | 282 | 4000 |
| BiLSTM | 3725 | 275 | 4000 |
| GRU | 3693 | 307 | 4000 |
| XLNet | 3576 | 584 | 4160 |
| RoBERTa | 3897 | 263 | 4160 |
| Proposed BERT | 4015 | 146 | 4161 |
| Model | Accuracy | Standard Devation | |
|---|---|---|---|
| TextBlob | RoBERTa | 0.91 | ±0.06 |
| XLNet | 0.68 | ±0.18 | |
| Proposed BERT | 0.95 | ±0.01 | |
| VADER | RoBERTa | 0.85 | ±0.02 |
| XLNet | 0.66 | ±0.02 | |
| Proposed BERT | 0.93 | ±0.01 |
| TextBlob | Vader | |||||
|---|---|---|---|---|---|---|
| Scenario | Statistics | p-Value | Statistics | p-Value | ||
| Proposed BERT Vs. SGD | −7.999 | 0.015 | Rejected | −31.128 | 7.284 | Rejected |
| Proposed BERT Vs. RF | −39.167 | 3.661 | Rejected | −3.695 | 0.343 | Rejected |
| Proposed BERT Vs. DT | 0.633 | 0.571 | Rejected | −34.097 | 5.545 | Rejected |
| Proposed BERT Vs. ETC | −63.516 | 8.598 | Rejected | −3.43 | 0.041 | Rejected |
| Proposed BERT Vs. KNN | −8.225 | 0.003 | Rejected | −6.140 | 0.008 | Rejected |
| Proposed BERT Vs. SVM | −9.792 | 0.002 | Rejected | −3.257 | 0.047 | Rejected |
| Proposed BERT Vs. GBM | −9.845 | 0.002 | Rejected | −3.313 | 0.045 | Rejected |
| Proposed BERT Vs. LR | −17.691 | 0.000 | Rejected | −3.368 | 0.043 | Rejected |
| Authors | Model | Dataset | Accuracy | Publication |
|---|---|---|---|---|
| Rustam et al. [26] | Logistic Regression | App reviews | 83% | 2020 |
| Khalid et al. [27] | GBSVM | Twitter Data | 93% | 2020 |
| Wadhwa et al. [75] | Logistic Regression | Twitter Data | 86.51% | 2021 |
| Bello et al. [33] | BERT | Twitter Data | 93% | 2022 |
| Catelli et al. [34] | BERT | E-commerce reviews | 75% | 2021 |
| Patel et al. [35] | BERT | Reviews | 83 | 2022 |
| Proposed | BERT | Twitter Data | 96.49% | 2023 |
| Approach | Accuracy | Class | Precision | Recall | F1 Score |
|---|---|---|---|---|---|
| TextBlob + BERT | 0.97 | Negative | 0.97 | 0.91 | 0.94 |
| Neutral | 0.98 | 0.99 | 0.98 | ||
| Positive | 0.96 | 0.98 | 0.97 | ||
| macro avg | 0.97 | 0.96 | 0.97 | ||
| weighted avg | 0.97 | 0.97 | 0.97 | ||
| Original + LR | 0.65 | Negative | 0.65 | 0.47 | 0.54 |
| Neutral | 0.63 | 0.72 | 0.67 | ||
| Positive | 0.69 | 0.65 | 0.67 | ||
| macro avg | 0.65 | 0.62 | 0.63 | ||
| weighted avg | 0.65 | 0.65 | 0.65 |
| Scenario | Statistic | p-Value | |
|---|---|---|---|
| Proposed BERT Vs. RoBERTa | 3.304 | 3.304 | Rejected |
| Proposed BERT Vs. XLNet | 7.292 | 0.0003 | Rejected |
| Proposed BERT Vs. GRU | 4.481 | 0.004 | Rejected |
| Proposed BERT Vs. BiLSTM | 2.621 | 0.003 | Rejected |
| Proposed BERT Vs. LSTM | 2.510 | 0.045 | Rejected |
| Proposed BERT Vs. RNN | 6.474 | 0.000 | Rejected |
| Proposed BERT Vs. CNN | 8.980 | 0.000 | Rejected |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
R, S.; Mujahid, M.; Rustam, F.; Shafique, R.; Chunduri, V.; Villar, M.G.; Ballester, J.B.; Diez, I.d.l.T.; Ashraf, I. Analyzing Sentiments Regarding ChatGPT Using Novel BERT: A Machine Learning Approach. Information 2023, 14, 474. https://doi.org/10.3390/info14090474
R S, Mujahid M, Rustam F, Shafique R, Chunduri V, Villar MG, Ballester JB, Diez IdlT, Ashraf I. Analyzing Sentiments Regarding ChatGPT Using Novel BERT: A Machine Learning Approach. Information. 2023; 14(9):474. https://doi.org/10.3390/info14090474
Chicago/Turabian StyleR, Sudheesh, Muhammad Mujahid, Furqan Rustam, Rahman Shafique, Venkata Chunduri, Mónica Gracia Villar, Julién Brito Ballester, Isabel de la Torre Diez, and Imran Ashraf. 2023. "Analyzing Sentiments Regarding ChatGPT Using Novel BERT: A Machine Learning Approach" Information 14, no. 9: 474. https://doi.org/10.3390/info14090474
APA StyleR, S., Mujahid, M., Rustam, F., Shafique, R., Chunduri, V., Villar, M. G., Ballester, J. B., Diez, I. d. l. T., & Ashraf, I. (2023). Analyzing Sentiments Regarding ChatGPT Using Novel BERT: A Machine Learning Approach. Information, 14(9), 474. https://doi.org/10.3390/info14090474