



A Novel Approach of Resource Allocation for Distributed Digital Twin Shop-Floor


Abstract
1. Introduction
- (1)
- In terms of resource sharing, traditional distributed manufacturing systems encapsulate manufacturing resources digitally to provide consumers with transparent, on-demand service. These distributed manufacturing platforms failed to consider the requirement of real-time interaction between consumers and manufacturing resources.
- (2)
- In terms of resource allocation, a large amount of research on resource allocation focused on multi-objective optimization models and algorithms. However, manufacturing resources in the research were assumed to be in a static state with immutable properties for the proposed models and algorithms.
2. Literature Review
2.1. Cloud Manufacturing
2.2. Digital Twin Shop-Floor
2.3. Research Gaps
- (1)
- To adapt to dynamic manufacturing processes, solving resource allocation problems in DM needs to ensure real-time interaction between consumers and key geographically dispersed facilities (providers), especially in the typical form of distributed manufacturing—cloud manufacturing. Manufacturing processes are different from computing processes, and many machining resource capabilities cannot be fully encapsulated as digitized, fully automated manufacturing services. Manufacturing services like remote and transparent computing services are not suitable for all machining tasks.
- (2)
- In terms of data transmission, although cloud manufacturing provides an environment for remote resource sharing, there is a lack of real-time and efficient transmission mechanisms for twin data in DTS. The conventional centralized cloud computing-based IoT solutions always lead to a heavy burden on the network bandwidth due to the large amount of sensor data collected frequently that have to be transmitted to the central server and this leads to poor response time for the distributed manufacturing system [21]. Twin data require not only high real-time requirements but also the integration of various factors’ data in the shop-floor, as well as the fusion of physical and virtual space data. Therefore, if all manufacturing resources are interconnected and interact through digital twin in a distributed manufacturing platform, there will be a problem of bandwidth competition and severe delay through cloud computing.
- (3)
- In terms of resource allocation, previous research always assumed that the resource allocation systems have all the permissions for manufacturing data, including historical and real-time data of resources (even factory data or shop-floor data). This situation may be possible among shop-floors under the same group, but it is not realistic under different groups. This is because production big data are an important asset and sensitive data of the factory. Although the blockchain technology can ensure the reliability and security of data sharing, one key and difficult point for resource allocation in DM is how to integrate data and when and with whom to share data in order to achieve seamless information flow and decision coordination [35].
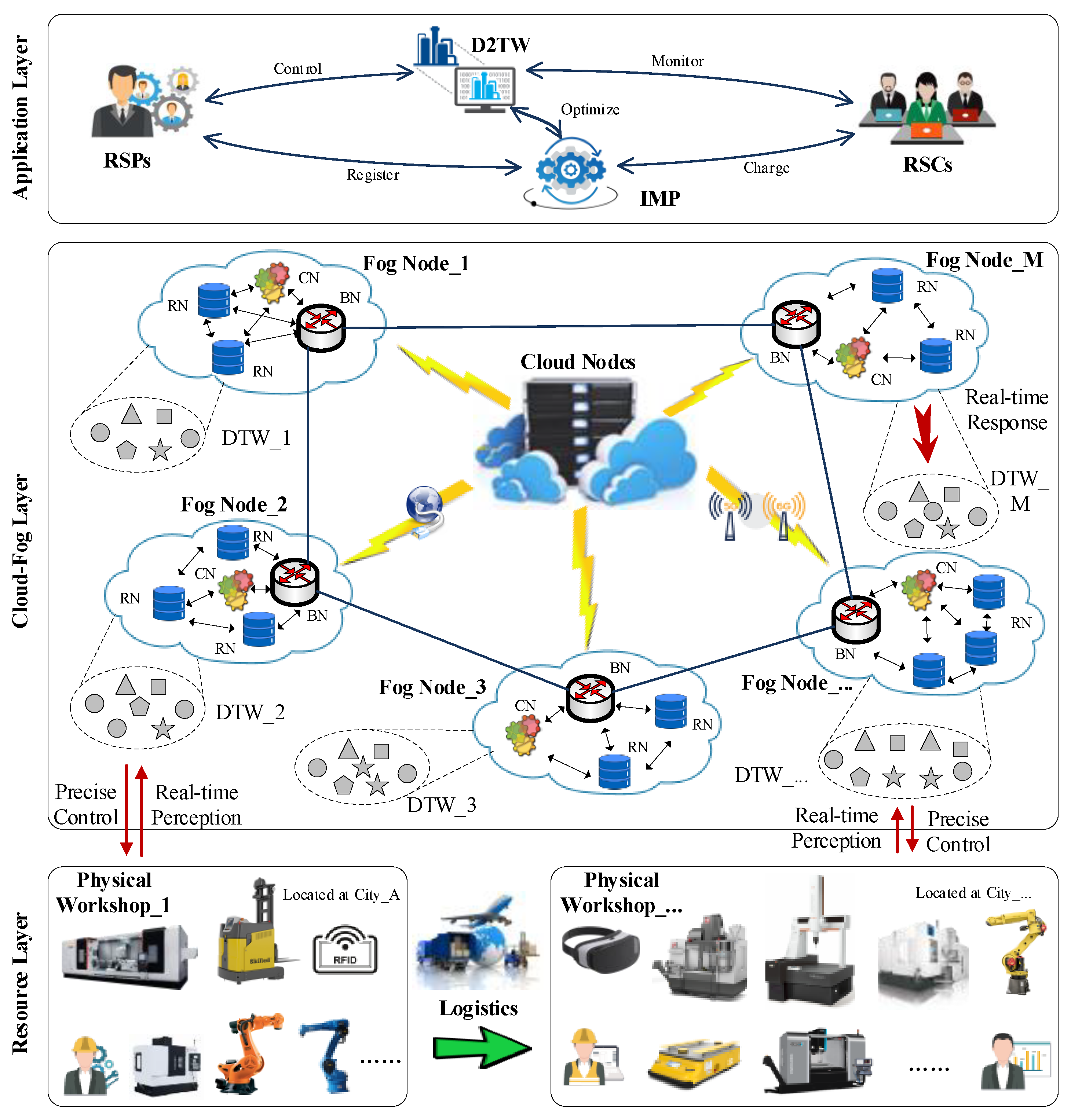
3. Information Architecture for D2TS
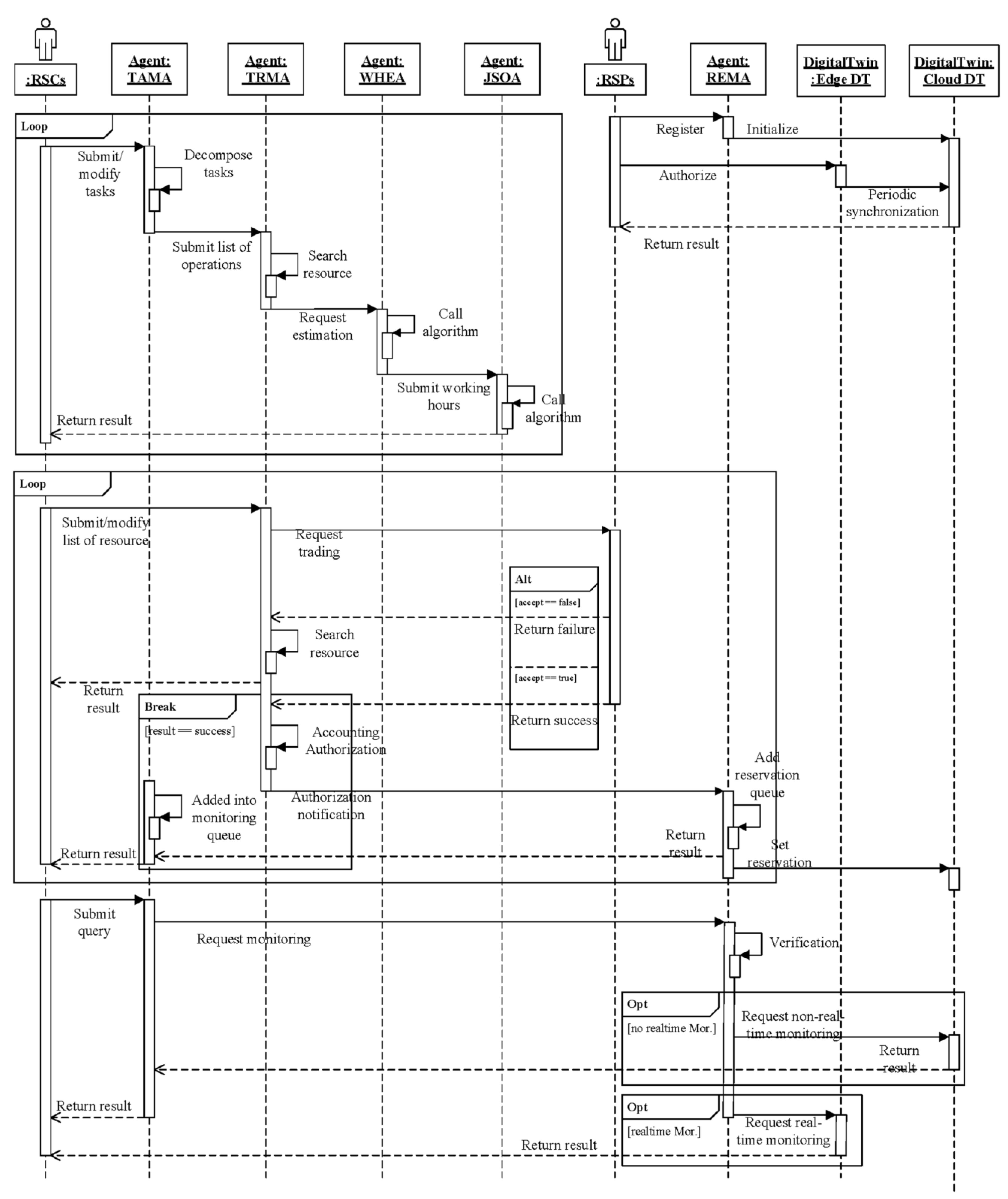
4. Resource Allocation Mechanism for D2TS
- (1)
- CDTFA: Its main function is to link the corresponding edge digital twin at a customized frequency, in order to obtain the status information of physical resources or production progress information, and upload relevant important data to the cloud database. The cloud digital twin is deployed in the CCS, which is a simplified and lightweight version of the edge digital twin. It is an image of the manufacturing resources that are not fully informed and does not have the ability to control physical manufacturing resources. Its main function is to provide cloud platforms with resource search, matching, scheduling, billing, credit, big data, and other services.
- (2)
- CDMFA: It includes both the cloud database and cloud knowledge base [36]. This implementation involves partitioning selection, storage, cataloging, and indexing of massive industrial data. With the help of distributed processing architectures, it meets the batch processing requirements of the CDTFA’s massive data and the ROAFA’s demand for predictive models, intelligent algorithms, process planning, etc., as well as the demand for non-real-time or historical data such as resource trading, credit, quality, cost, and status. The raw data obtained by the cloud digital twin are cleaned to provide high-quality data sources for subsequent storage, management, and analysis.
- (3)
- ROAFA includes some multi-agent modules, such as resource management agent (REMA), task management agent (TAMA), trading management agent (TRMA), working hours estimation agent (WHEA), job scheduling optimization agent (JSOA), etc.
- REMA: It is responsible for providing an entry point for producers to configure the cloud digital twin of manufacturing resources, such as publishing the manufacturing resources they own through semantic description and encapsulation.
- TAMA: It is responsible for the development and modification of process regulations based on cloud computer-aided process planning, as well as the decomposition and combination of complex machining tasks before task execution. During task execution, it provides real-time production monitoring (such as quality) and non-real-time monitoring (such as production progress).
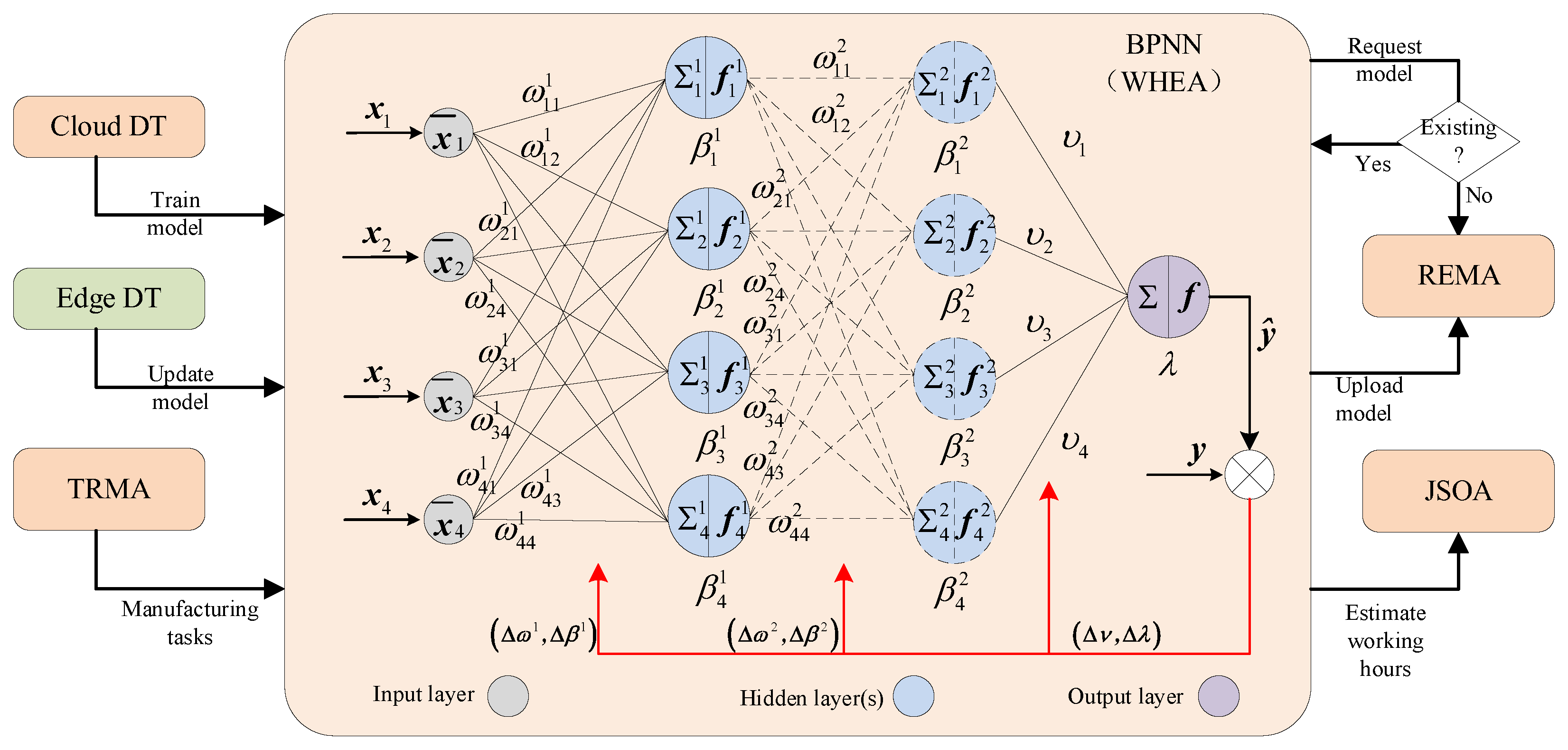
- WHEA: It is responsible for receiving requests from TRMA, predicting the required working hours based on a back propagation neural network (BPNN) model (obtained from the cloud knowledge base), and submitting the results to the JSOA for scheduling optimization.
- JSOA: It is responsible for receiving requests from TAMA. Based on the optimization goals set by the consumers, it calls on the historical transaction data and intelligent optimization algorithms in the cloud database and cloud knowledge base.
- TRMA: It is responsible for resource searching and matching based on the basic task list provided by TAMA before task execution, as well as signing blockchain cooperation agreements. In case of resource failure during task execution, TRMA transfers the processing information to the cloud digital twin node of the replacement resource. After task execution, TRMA settles the order amount with the cloud digital twin that executed the task.
5. Problem Modeling and Algorithms of Resource Allocation for D2TS
5.1. Problem Formulation
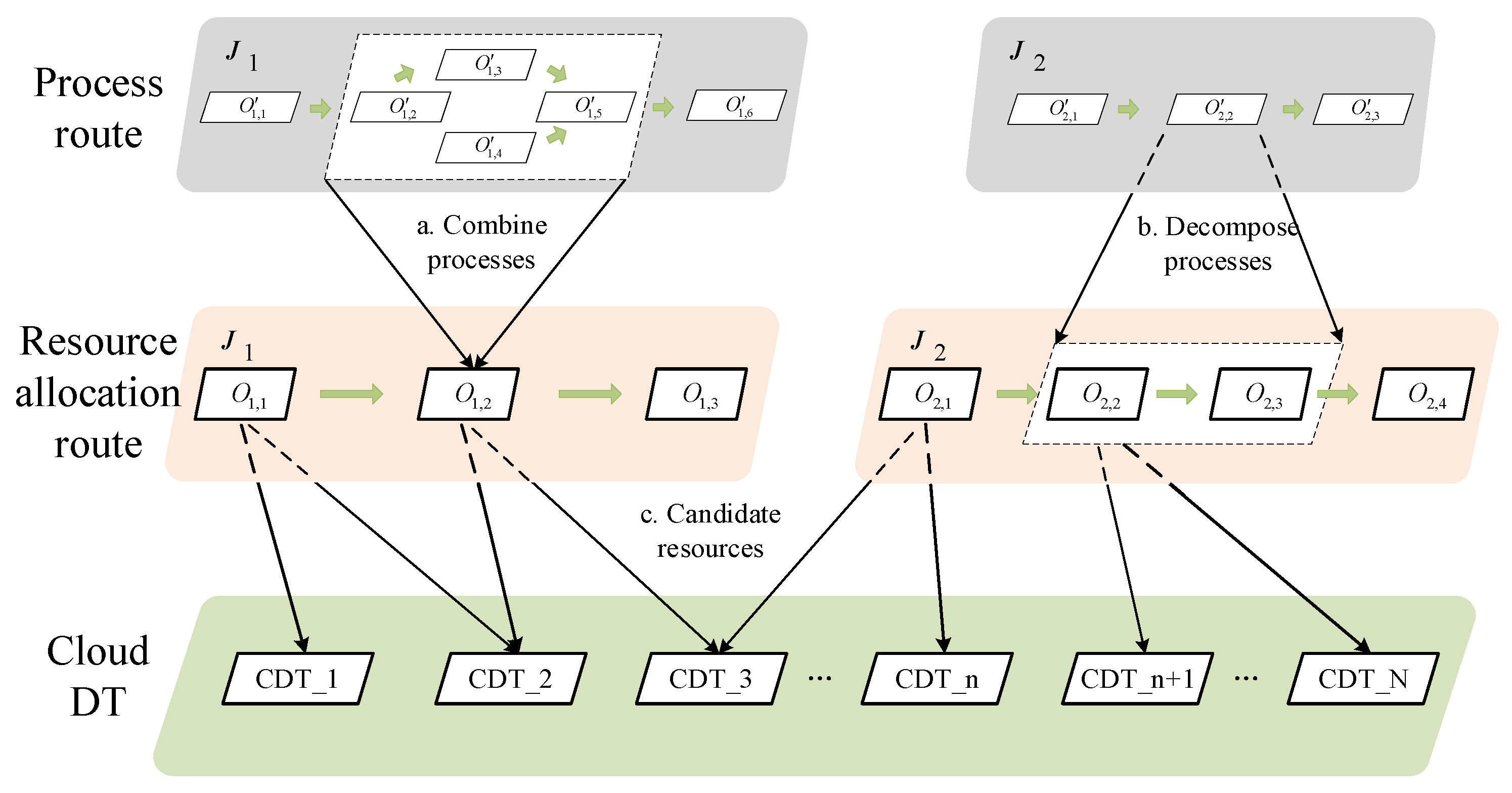
5.2. Resource Allocation Route
5.3. Mathematical Modeling
- (1)
- When the cloud digital twin corresponding to the physical manufacturing resource is in a state of failure, it cannot be used as a candidate resource. When the current state is reservation or working, it can be used as a candidate resource, but it is necessary to further obtain the available time slot in real time.
- (2)
- All operations for all tasks are assumed to be serial. This is because in actual production, parallel and reentrant operations can be transformed into serial ones, and equivalent processing operations can be performed with job scheduling and mathematical modeling.
- (3)
- Each machine can only process one workpiece at a time, and phenomena such as equipment abnormalities, defective products during processing, and material shortages are not considered.
- (4)
- Processing time, preparation time, and transportation time may vary depending on the resources used. If two adjacent operations use the same equipment, the preparation time and transportation time are assumed to be zero.
- (5)
- Transportation time between different resources is considered on a per-workpiece (per-processing task) basis.
5.4. Working Hours Estimation Based on BPNN
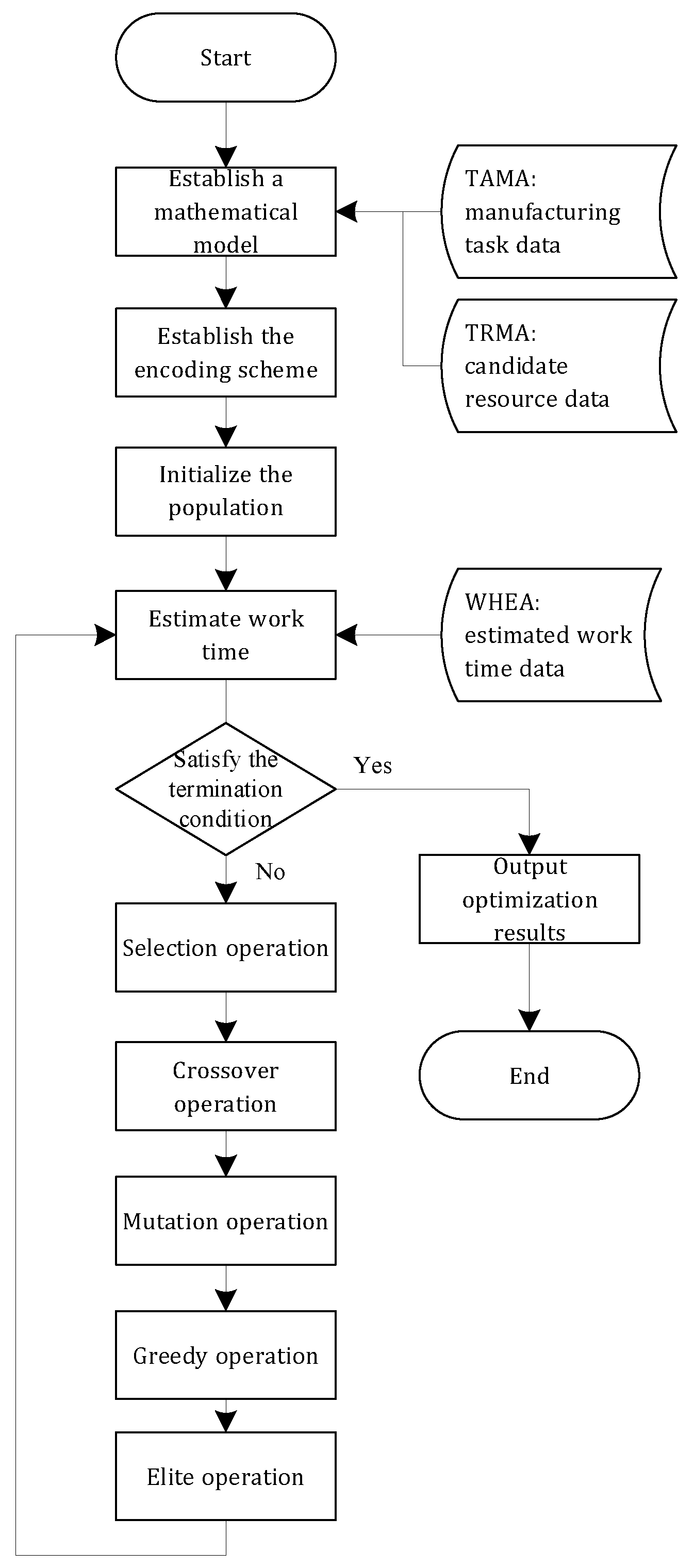
5.5. Job Scheduling Based on IGA
6. Cases Study
6.1. Case of Working Hours Estimation
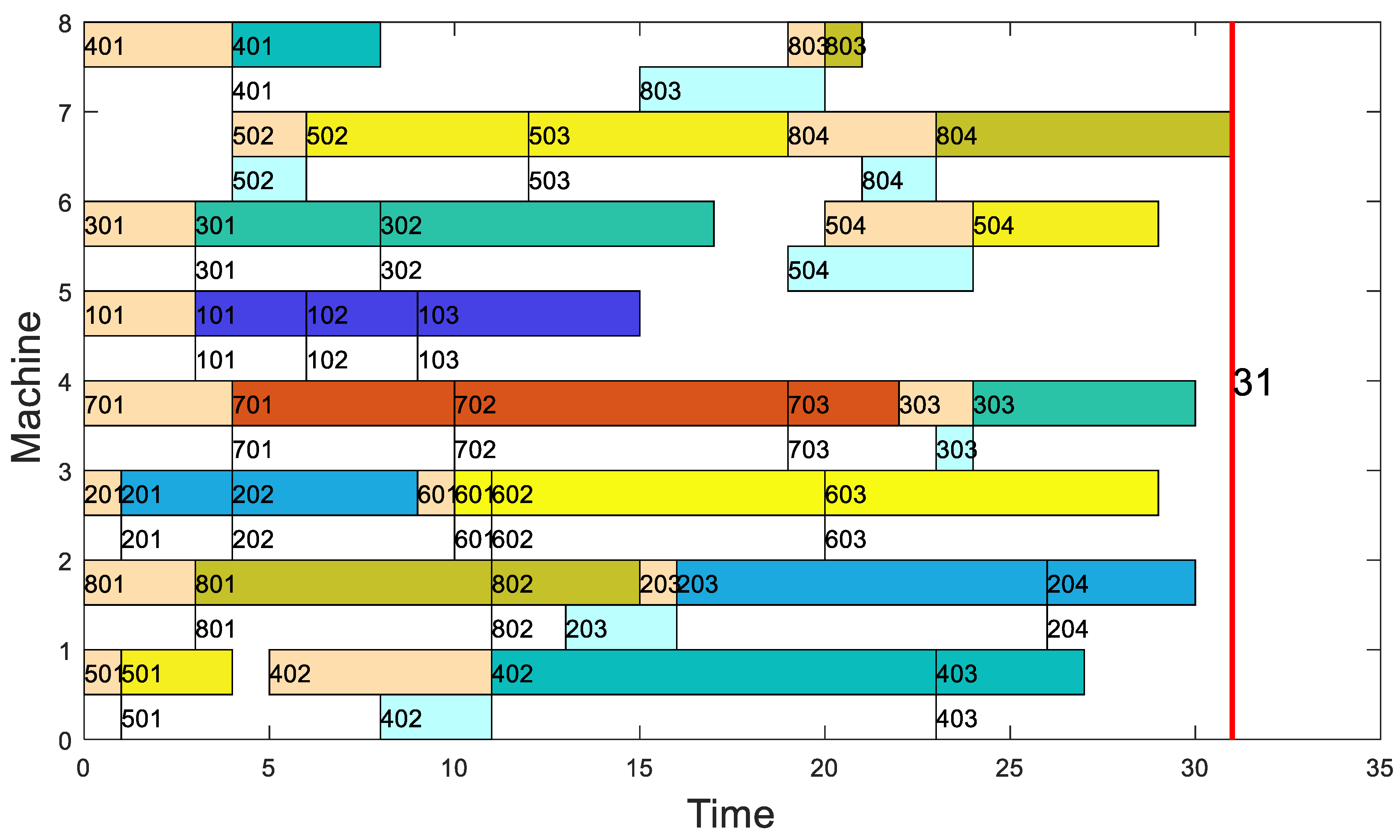
6.2. Case of Job Scheduling
7. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Nomenclature
| DT | Digital twin |
| DTS | Digital twin shop-floor |
| D2TS | Distributed digital twin shop-floor |
| D2TSRA | Distributed digital twin shop-floor resource allocation |
| BP | Back propagation |
| DM | Distributed manufacturing |
| ICTs | Information and communication technologies |
| SMEs | Small and medium-sized enterprises |
| SANs | Sensor and/or actuator nodes |
| DTMC | Digital twin manufacturing cell |
| CPS | Cyber-physical system |
| CNC | Computer numerical control |
| BN | Broker node |
| CN | Computing node |
| RN | Repository node |
| IMP | Intelligent manufacturing platform |
| CCS | Cloud computing space |
| FCS | Fog computing space |
| PRS | Physical resource space |
| CDTFA | Cloud digital twin function area |
| CDMFA | Cloud data management function area |
| ROAFA | Resource optimization allocation function area |
| REMA | Resource management agent |
| TAMA | Task management agent |
| TRMA | Trading management agent |
| WHEA | Working hours estimation agent |
| JSOA | Job scheduling optimization agent |
| CAPP | Computer-aided process planning |
| BPNN | Back propagation neural network |
| IGA | Improved genetic algorithm |
| MAE | Mean absolute error |
| MSE | Mean squared error |
| RMSE | Root mean square error |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Plate Thickness/mm | Welding Rod Diameter/mm | Weld Bead Thickness/mm | Weld Bead Length/m | Working Hours/min |
|---|---|---|---|---|---|
| 1 | 2 | 2.5 | 2 | 0.5 | 5 |
| 2 | 2.5 | 2.5 | 2.5 | 0.9 | 8.1 |
| 3 | 3 | 2.5 | 3 | 1.4 | 11.2 |
| 4 | 24 | 5 | 24 | 1.1 | 118.8 |
| 5 | 5 | 3.2 | 5 | 2 | 20 |
| 6 | 6 | 4 | 6 | 1 | 12 |
| 7 | 8 | 4 | 8 | 0.7 | 11.9 |
| 8 | 10 | 4 | 10 | 1.6 | 40 |
| 9 | 12 | 5 | 12 | 1 | 30 |
| 10 | 14 | 5 | 14 | 1.3 | 48.1 |
| 11 | 16 | 5 | 16 | 0.5 | 24 |
| 12 | 16 | 5 | 16 | 1.9 | 91.2 |
| 13 | 18 | 5 | 18 | 1 | 61 |
| 14 | 20 | 5 | 20 | 0.7 | 52.5 |
| 15 | 2 | 2.5 | 2 | 1.1 | 11 |
| 16 | 2.5 | 2.5 | 2.5 | 1.1 | 8.8 |
| 17 | 3 | 2.5 | 3 | 1.1 | 9.6 |
| 18 | 4 | 3.2 | 4 | 1.1 | 9.9 |
| 19 | 5 | 3.2 | 5 | 1.1 | 11 |
| 20 | 5 | 4 | 6 | 1.1 | 13.2 |
| 21 | 8 | 4 | 8 | 1.1 | 18.7 |
| 22 | 10 | 4 | 10 | 1.1 | 27.5 |
| 23 | 12 | 5 | 12 | 1.1 | 33 |
| 24 | 14 | 5 | 14 | 1.1 | 40.7 |
| 25 | 16 | 5 | 16 | 1.1 | 52.8 |
| 26 | 18 | 5 | 18 | 1.1 | 67.1 |
| 27 | 20 | 5 | 20 | 1.1 | 82.5 |
| 28 | 4 | 3.2 | 4 | 0.7 | 6.3 |
| 29 | 28 | 5.8 | 28 | 1.1 | 136.4 |
| Job | Oper. | Processing Time/Setup Time | |||||||
|---|---|---|---|---|---|---|---|---|---|
| M1 | M2 | M3 | M4 | M5 | M6 | M7 | M8 | ||
| J1 | O1,1 | 5/1 | 3/1 | 5/1 | 3/3 | 3/3 | − | 10/1 | 9/7 |
| O1,2 | 10/4 | − | 5/2 | 8/6 | 3/3 | 9/3 | 9/3 | 6/1 | |
| O1,3 | − | 10/2 | − | 5/2 | 6/3 | 2/1 | 4/1 | 5/4 | |
| J2 | O2,1 | 5/4 | 7/2 | 3/1 | 9/5 | 8/1 | − | 9/5 | − |
| O2,2 | − | 8/2 | 5/5 | 2/1 | 6/3 | 7/7 | 10/8 | 9/4 | |
| O2,3 | − | 10/1 | − | 5/2 | 6/3 | 4/3 | 1/1 | 7/2 | |
| O2,4 | 10/1 | 8/3 | 9/3 | 6/3 | 4/3 | 7/5 | − | − | |
| J3 | O3,1 | 10/3 | − | − | 7/1 | 6/5 | 5/3 | 2/2 | 4/2 |
| O3,2 | − | 10/1 | 6/2 | 4/4 | 8/6 | 9/3 | 10/8 | − | |
| O3,3 | 1/1 | 4/3 | 5/4 | 6/2 | − | 10/7 | − | 7/3 | |
| J4 | O4,1 | 3/2 | 1/1 | 6/1 | 5/5 | 9/7 | 7/6 | 8/4 | 4/4 |
| O4,2 | 12/6 | 11/7 | 7/1 | 8/3 | 10/6 | 5/5 | 6/5 | 9/3 | |
| O4,3 | 4/2 | 6/3 | 2/1 | 10/9 | 3/2 | 9/3 | 5/4 | 7/6 | |
| J5 | O5,1 | 3/1 | 6/5 | 7/6 | 8/6 | 9/8 | − | 10/6 | − |
| O5,2 | 10/7 | − | 7/1 | 4/2 | 9/1 | 8/5 | 6/2 | − | |
| O5,3 | − | 9/6 | 8/5 | 7/2 | 4/3 | 2/2 | 7/6 | − | |
| O5,4 | 11/1 | 9/4 | − | 6/6 | 7/2 | 5/4 | 3/2 | 6/6 | |
| J6 | O6,1 | 6/2 | 7/6 | 1/1 | 4/3 | 6/1 | 9/2 | − | 10/3 |
| O6,2 | 11/4 | − | 9/8 | 9/6 | 9/6 | 7/1 | 6/6 | 4/3 | |
| O6,3 | 10/5 | 5/5 | 9/2 | 10/2 | 11/8 | − | 10/4 | − | |
| J7 | O7,1 | 5/3 | 4/4 | 2/1 | 6/4 | 7/7 | − | 10/9 | − |
| O7,2 | − | 9/8 | − | 9/1 | 11/4 | 9/1 | 10/4 | 5/5 | |
| O7,3 | − | 8/1 | 9/6 | 3/1 | 8/4 | 6/1 | − | 10/8 | |
| J8 | O8,1 | 2/1 | 8/3 | 5/5 | 9/3 | − | 4/2 | − | 10/8 |
| O8,2 | 7/1 | 4/4 | 7/4 | 8/1 | 9/7 | − | 10/10 | − | |
| O8,3 | 9/2 | 9/8 | − | 8/2 | 5/4 | 6/3 | 7/2 | 1/1 | |
| O8,4 | 9/7 | − | 3/2 | 7/6 | 1/1 | 5/4 | 8/4 | − | |
| Candidate Manuf. Resources | Transportation Time | |||||||
|---|---|---|---|---|---|---|---|---|
| M1 | M2 | M3 | M4 | M5 | M6 | M7 | M8 | |
| M1 | 0 | 4 | 2 | 1 | 5 | 1 | 2 | 1 |
| M2 | 1 | 0 | 5 | 1 | 5 | 2 | 5 | 5 |
| M3 | 1 | 3 | 0 | 2 | 3 | 4 | 5 | 5 |
| M4 | 3 | 1 | 3 | 0 | 1 | 4 | 3 | 3 |
| M5 | 4 | 2 | 5 | 3 | 0 | 1 | 4 | 1 |
| M6 | 5 | 5 | 1 | 1 | 2 | 0 | 3 | 2 |
| M7 | 1 | 1 | 2 | 5 | 2 | 5 | 0 | 3 |
| M8 | 3 | 5 | 1 | 5 | 5 | 4 | 2 | 0 |
References
- Matt, D.T.; Rauch, E.; Dallasega, P. Trends towards distributed manufacturing systems modern forms for their design. Procedia CIRP 2015, 33, 185–190. [Google Scholar] [CrossRef]
- Rauch, E.; Dallasega, P. Sustainability in manufacturing and supply chains through distributed manufacturing systems and networks. In Encyclopedia of Sustainable Technologies; Elsevier: Oxford, UK, 2017. [Google Scholar]
- Atmojo, U.D.; Salcic, Z.; Wang, K.I.-K.; Vyatkin, V. A Service-Oriented Programming Approach for Dynamic Distributed Manufacturing Systems. IEEE Trans. Industr. Inform. 2020, 16, 151–160. [Google Scholar] [CrossRef]
- Shafto, M.; Conroy, M.; Doyle, R.; Glaessgen, E.; Wang, L. Modeling, Simulation, Information Technology and Processing Roadmap; National Aeronautics and Space Administration: Washington, DC, USA, 2012. Available online: http://www.nasa.gov (accessed on 22 June 2023).
- Zhang, W.; Zhang, G.; Guo, X.; Zhang, Y.F. Digital twin-driven service model and optimal allocation of manufacturing resources in shared manufacturing. J. Manuf. Syst. 2021, 59, 165–179. [Google Scholar] [CrossRef]
- Grieves, M. Origins of the Digital Twin Concept. 2016. Available online: https://www.researchgate.net/publication/307509727_Origins_of_the_Digital_Twin_Concept (accessed on 20 May 2023).
- Tuegel, E.J.; Ingraffea, A.R.; Eason, T.G.; Spottswood, S.M. Reengineering aircraft structural life prediction using a digital twin. Int. J. Aerosp. Eng. 2011, 7, 154798. [Google Scholar] [CrossRef]
- Tao, F.; Zhang, M. Digital Twin Shop-Floor. A New Shop-Floor Paradigm Towards Smart Manufacturing. IEEE Access 2017, 5, 20418–20427. [Google Scholar] [CrossRef]
- Sanchez, L.M.; Nagi, R. A review of agile manufacturing systems. International. Int. J. Prod. Res. 2001, 39, 3561–3600. [Google Scholar] [CrossRef]
- Rusinko, C. Green manufacturing: An evaluation of environmentally sustainable manufacturing practices and their impact on competitive outcomes. IEEE Trans. Eng. Manag. 2007, 54, 445–454. [Google Scholar] [CrossRef]
- Ren, L.; Zhang, L.; Wang, L.H.; Tao, F.; Chai, X.D. Cloud manufacturing: Key characteristics and applications. Int. J. Ccomput. Integr. Mang. 2017, 30, 501–515. [Google Scholar] [CrossRef]
- Li, B.H.; Zhang, L.; Ren, L.; Chai, X.D.; Tao, F.; Wang, Y.Z.; Yin, C.; Huang, P.; Zhao, X.P.; Zhou, Z.D. Typical features, key technologies, and applications of cloud manufacturing. Comput. Integr. Manuf. Syst. 2012, 18, 1345–1356. [Google Scholar]
- Cheng, Y.; Bi, L.N.; Tao, F.; Ji, P. Hypernetwork-based manufacturing service scheduling for distributed and collaborative manufacturing operations towards smart manufacturing. J. Intell. Manuf. 2020, 2020, 1707–1720. [Google Scholar] [CrossRef]
- Moench, L.; Shen, L.J. Parallel machine scheduling with the total weighted delivery time performance measure in distributed manufacturing. Comput. Oper. Res. 2021, 127, 105126. [Google Scholar] [CrossRef]
- Carlucci, D.; Renna, P.; Materia, S.; Schiuma, G. Intelligent decision-making model based on minority game for resource allocation in cloud manufacturing. Manag. Decis. 2019, 58, 2305–2325. [Google Scholar] [CrossRef]
- Delaram, J.; Houshamand, M.; Ashtiani, F.; Valilai, O.F. A utility-based matching mechanism for stable and optimal resource allocation in cloud manufacturing platforms using deferred acceptance algorithm. J. Manuf. Syst. 2021, 60, 569–584. [Google Scholar] [CrossRef]
- Yin, C.; Xiao, X.; Qiu, L. Constraint characteristics of networked collaborative machining equipment and an optimization selection method. J. Mech. Eng. 2018, 54, 192–201. [Google Scholar] [CrossRef]
- Wu, X.; Sun, L. Real time scheduling of workshop based on data-driven intelligent manufacturing system. Cont. Des. 2020, 35, 523–535. [Google Scholar] [CrossRef]
- Zhou, B.; Bao, J.S.; Li, J.; Lu, Y.Q.; Liu, T.Y.; Zhang, Q. A novel knowledge graph-based optimization approach for resource allocation in discrete manufacturing workshops. Robot. Comput. Integr. Manuf. 2021, 71, 102160. [Google Scholar] [CrossRef]
- Adam, S.; Peter, E.; Botond, K. Trust-based resource sharing mechanism in distributed manufacturing. Int. J. Comput. Integr. Manuf. 2020, 33, 1–21. [Google Scholar] [CrossRef]
- Liu, Y.H.; Yu, W.J.; Dillon, T.; Rahayu, W.; Li, M. Empowering IOT predictive maintenance solutions with AI: A Distributed System for Manufacturing Plant-Wide Monitoring. IEEE Trans. Industr. Inform. 2022, 18, 1345–1354. [Google Scholar] [CrossRef]
- Zhang, H.J.; Zhang, G.H.; Yan, Q. Digital twin-driven cyber-physical production system towards smart shop-floor. J. Ambient Intell. Hum. Comput. 2019, 10, 4439–4453. [Google Scholar] [CrossRef]
- Wang, H.; Lv, L.; Li, X.; Li, H.; Leng, J.; Zhang, Y.; Thomson, V.; Liu, G.; Wen, X.; Sun, C. A safety management approach for Industry 5.0′s human-centered manufacturing based on digital twin. J. Manuf. Syst. 2023, 66, 1–12. [Google Scholar] [CrossRef]
- Zhang, L.T.; Guo, Y.; Qian, W.W.; Wang, W.L.; Liu, D.Y.; Liu, S. Modelling and online training method for digital twin workshop. Int. J. Prod. Res. 2021, 68, 3943–3962. [Google Scholar] [CrossRef]
- Zhang, C.; Zhou, H.; Xiao, J. Multidimensional and multi-scale modeling of digital twin manufacturing cells and edge cloud collaborative configuration. Comput. Integr. Manuf. Syst. 2023, 29, 355–371. [Google Scholar] [CrossRef]
- Qian, W.W.; Guo, Y.; Cui, K.; Wu, P.X.; Fang, W.G.; Liu, D.Y. Multidimensional data modeling and model validation for digital twin workshop. J. Comput. Inf. Sci. Eng. 2021, 21, 031005. [Google Scholar] [CrossRef]
- Liu, J.; Zhuang, C.B.; Liu, J.H.; Miao, T.; Wang, J.Q. Online prediction technology of workshop operating status based on digital twin. Comput. Integr. Manuf. Syst. 2021, 27, 467–477. [Google Scholar] [CrossRef]
- Hong, Q.; Sun, Y.F.; Liu, T.Y.; Fu, L.; Xie, Y.F. TAD-Net: An approach for real-time action detection based on temporal convolution network and graph convolution network in digital twin shop-floor. Digit. Twin 2023, 1, 39–56. [Google Scholar] [CrossRef]
- Liu, S.M.; Lu, Y.Q.; Li, J.; Shen, X.W.; Sun, X.M.; Bao, J.S. A blockchain-based interactive approach between digital twin-based manufacturing systems. Comput. Ind. Eng. 2023, 175, 108827. [Google Scholar] [CrossRef]
- Wang, J.; Liu, Y.; Ren, S.; Wang, C.; Ma, S.Y. Edge computing-based real-time scheduling for digital twin flexible job shop with variable time window. Robot Cim-Int. Manuf. 2023, 79, 108827. [Google Scholar] [CrossRef]
- Wang, X.D.; Hu, X.F.; Ren, Z.J.; Tian, T.C.; Wan, J.F. Knowledge-graph based multi-domain model integration method for digital-twin workshops. Intern. J. Adv. Manuf. Technol. 2023, 128, 405–421. [Google Scholar] [CrossRef]
- Bellavista, P.; Giannelli, C.; Mamei, M.; Mendula, M.; Picone, M. Application-driven network-aware digital twin management in industrial edge environments. IEEE Trans. Industr. Inform. 2021, 17, 7791–7801. [Google Scholar] [CrossRef]
- Vyskocil, J.; Douda, P.; Novak, P.; Wally, B. A digital twin-based distributed manufacturing execution system for industry 4.0 with ai-powered on-the-fly replanning capabilities. Sustainability 2023, 15, 6251. [Google Scholar] [CrossRef]
- Liu, C.; Le Roux, L.; Korner, C.; Tabaste, O.; Lacan, F.; Bigot, S. Digital twin-enabled collaborative data management for metal additive manufacturing systems. J. Manuf. Syst. 2023, 62, 857–874. [Google Scholar] [CrossRef]
- Timothy, S.; Michael, S.; William, Z.B.; Michael, P.B.; Moneer, H.; Thomas, H. Integrated operations management for distributed manufacturing. IFAC-PapersOnLine 2020, 52, 1820–1824. [Google Scholar] [CrossRef]
- Zhang, H.J.; Yan, Q.; Zhang, G.H.; Li, Q.Y.; Yu, J. Dynamic optimization decision of manufacturing resources based on digital twins. Comput. Integr. Manuf. Syst. 2021, 27, 521–535. [Google Scholar] [CrossRef]
- Zhang, G.H.; Hu, Y.F.; Sun, J.H.; Zhang, W.Q. An improved genetic algorithm for the flexible job shop scheduling problem with multiple time constraints. Swarm Evol. Comput. 2020, 54, 100664. [Google Scholar] [CrossRef]
- Xie, N.M.; Chen, N.L. Flexible job shop scheduling problem with interval grey processing time. Appl. Soft Comput. 2018, 70, 513–524. [Google Scholar] [CrossRef]
- Dai, M.; Tang, D.B.; Giret, A.; Salido, M.A. Multi-objective optimization for energy-efficient flexible job shop scheduling problem with transportation constraints. Robot. Comput. Integr. Manuf. 2019, 59, 143–157. [Google Scholar] [CrossRef]
- Luo, S.; Zhang, L.X.; Fan, Y.S. Energy-efficient scheduling for multi-objective flexible job shops with variable processing speeds by grey wolf optimization. J. Clean. Prod. 2019, 234, 1365–1384. [Google Scholar] [CrossRef]









| Ref. | Human–Equipment Interaction | Data Transmission | Resource Allocation |
|---|---|---|---|
| Li et al. [12] (2012) Szaller et al. [20] (2019) | Non-real-time | Distributed | Static |
| Delaram et al. [16] (2021) | Non-real-time | Centralized | Static |
| Cheng et al. [13] (2018) Wu et al. [18] (2020) Zhang et al. [24] (2023) Qian et al. [26] (2021) Liu et al. [27] (2021) Wang et al. [31] (2023) | Real-time | Centralized | Dynamic |
| Hong et al. [28] (2021) | Real-time | Centralized | N/A |
| Möncha and Shen [14] (2020) Yin et al. [17] (2018) | N/A | Distributed | Static |
| Carlucci et al. [15] (2020) Zhou et al. [19] (2021) | N/A | Centralized | Static |
| Zhang et al. [25] (2023) Liu et al. [34] (2022) | Real-time | Distributed | N/A |
| Liu et al. [21] (2022) Liu et al. [29] (2023) Wang et al. [30] (2023) Bellavista et al. [32] (2021) Vyskocil et al. [33] (2023) | Real-time | Distributed | Dynamic |
| This paper | Real-time | Distributed | Dynamic |
| Notations | Description |
|---|---|
| The total number of manufacturing jobs | |
| The total number of candidate manufacturing resources | |
| The set of manufacturing jobs to be scheduled, where represents the i-th manufacturing job | |
| The set of operations for all jobs to be scheduled, where represents the j-th operation of manufacturing job and represents the number of operations for the job | |
| The set of candidate manufacturing resources, where represents the r-th manufacturing resource | |
| The k-th type of time required for operation to be completed using manufacturing resource , when k = 1 it represents preparation time, and when k = 2 it represents processing time | |
| The logistics time required for the manufacturing job to be transported from manufacturing resource to manufacturing resource | |
| Time variable, start time of operation | |
| Time variable, completion time of operation | |
| Decision variable. It is 1 if operation is completed on manufacturing resource and 0 otherwise | |
| Decision variable, the processing sequence of the operation on the manufacturing resource |
| Index | Number of Hidden Nodes | Learning Rate | Number of Iterations for Convergence | MAE | MSE | RMSE |
|---|---|---|---|---|---|---|
| 1 | 3 | 0.1 | 180 | 0.09 | 45.45 | 5.88 |
| 2 | 3 | 0.5 | 146 | 0.06 | 7.68 | 2.71 |
| 3 | 3 | 0.9 | 1292 | 0.12 | 99.44 | 7.02 |
| 4 | 4 | 0.1 | 1738 | 0.42 | 499.98 | 17.41 |
| 5 | 4 | 0.5 | 1912 | 1.03 | 23,953.11 | 75.98 |
| 6 | 4 | 0.9 | 735 | 0.19 | 151.29 | 10.41 |
| 7 | 5 | 0.1 | 403 | 0.32 | 504.25 | 17.34 |
| 8 | 5 | 0.5 | 365 | 0.23 | 213.76 | 12.45 |
| 9 | 5 | 0.9 | 491 | 0.33 | 896.47 | 19.32 |
| 10 | 6 | 0.1 | 259 | 0.26 | 391.11 | 17.15 |
| 11 | 6 | 0.5 | 176 | 0.28 | 215.13 | 13.62 |
| 12 | 6 | 0.9 | 309 | 0.18 | 66.84 | 7.37 |
| 13 | 7 | 0.1 | 223 | 0.22 | 344.33 | 15.55 |
| 14 | 7 | 0.5 | 216 | 0.22 | 289.06 | 13.08 |
| 15 | 7 | 0.9 | 200 | 0.26 | 207.60 | 13.75 |
| 16 | 8 | 0.1 | 139 | 0.31 | 282.64 | 14.93 |
| 17 | 8 | 0.5 | 140 | 0.25 | 274.59 | 14.51 |
| 18 | 8 | 0.9 | 181 | 0.19 | 164.34 | 11.66 |
| 19 | 9 | 0.1 | 153 | 0.24 | 253.58 | 13.88 |
| 20 | 9 | 0.5 | 115 | 0.29 | 299.27 | 15.67 |
| 21 | 9 | 0.9 | 122 | 0.17 | 132.30 | 11.13 |
| 22 | 10 | 0.1 | 128 | 0.21 | 212.96 | 12.42 |
| 23 | 10 | 0.5 | 121 | 0.24 | 178.11 | 11.84 |
| 24 | 10 | 0.9 | 135 | 0.24 | 111.48 | 9.78 |
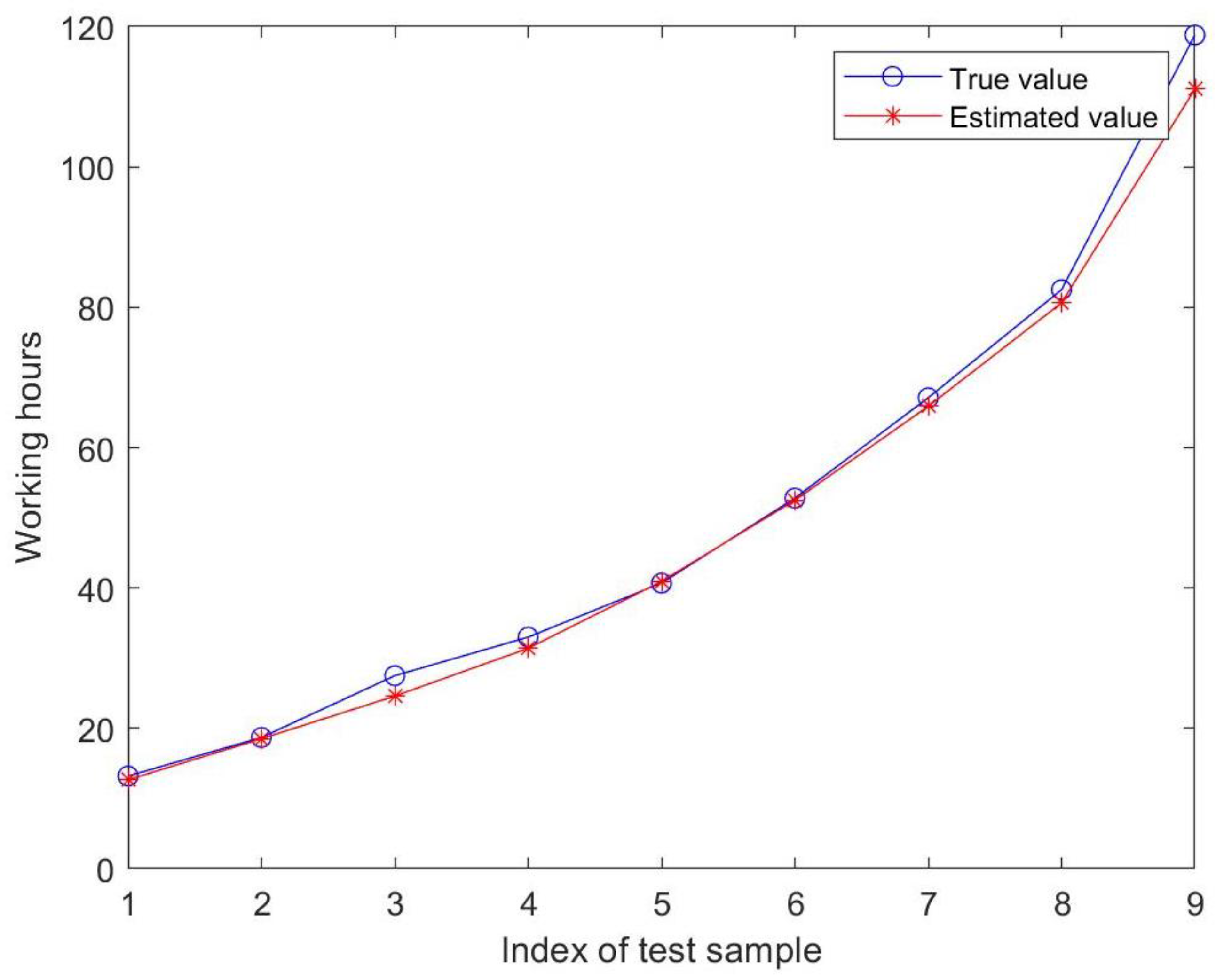
| Index | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| True value | 13.2 | 18.7 | 27.5 | 33 | 40.7 | 52.8 | 67.1 | 82.5 | 118.8 |
| Estimated value | 12.66 | 18.52 | 24.59 | 31.40 | 40.94 | 52.50 | 65.89 | 80.63 | 111.09 |
| Error rate | 4.06% | 0.95% | 10.57% | 4.85% | 0.60% | 0.57% | 1.81% | 2.27% | 6.49% |
| Parameters | Value |
|---|---|
| Number of individuals Maximum number of iterations | 100 100 |
| Initial solution proportion for random generation method | 0.4 |
| Initial solution proportion for maximum priority selection method for remaining processing time | 0.3 |
| Initial solution proportion for uniform distribution method | 0.3 |
| Crossover probability | 0.8 |
| Minimum mutation probability | 0.8 |
| Maximum mutation probability | 0.2 |
| Makespan | Setup Time | Transportation Time | |
|---|---|---|---|
| Solution 1 | 31 | 35 | 26 |
| Solution 2 | 31 | 38 | 23 |
| Solution 3 | 31 | 40 | 21 |
| Solution 4 | 32 | 36 | 24 |
| Solution 5 | 33 | 33 | 21 |
| Solution 6 | 33 | 35 | 11 |
| Solution 7 | 34 | 29 | 14 |
| Solution 8 | 34 | 31 | 13 |
| Solution 9 | 34 | 32 | 12 |
| Solution 10 | 34 | 34 | 11 |
| Solution 11 | 35 | 26 | 16 |
| Solution 12 | 35 | 27 | 8 |
| Solution 13 | 36 | 24 | 6 |
| Solution 14 | 54 | 40 | 5 |
| ELGA | ENGA | MOGWO | IGA | |
|---|---|---|---|---|
| NNS | 6 | 5 | 23 | 14 |
| BMS | 39 | 38 | 31 | 31 |
| BST | 36 | 33 | 28 | 24 |
| BTT | 16 | 7 | 7 | 5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Yan, Q.; Qin, Y.; Chen, S.; Zhang, G. A Novel Approach of Resource Allocation for Distributed Digital Twin Shop-Floor. Information 2023, 14, 458. https://doi.org/10.3390/info14080458
Zhang H, Yan Q, Qin Y, Chen S, Zhang G. A Novel Approach of Resource Allocation for Distributed Digital Twin Shop-Floor. Information. 2023; 14(8):458. https://doi.org/10.3390/info14080458
Chicago/Turabian StyleZhang, Haijun, Qiong Yan, Yan Qin, Shengwei Chen, and Guohui Zhang. 2023. "A Novel Approach of Resource Allocation for Distributed Digital Twin Shop-Floor" Information 14, no. 8: 458. https://doi.org/10.3390/info14080458
APA StyleZhang, H., Yan, Q., Qin, Y., Chen, S., & Zhang, G. (2023). A Novel Approach of Resource Allocation for Distributed Digital Twin Shop-Floor. Information, 14(8), 458. https://doi.org/10.3390/info14080458