

Revisiting Softmax for Uncertainty Approximation in Text Classification

Abstract
1. Introduction
2. Related Work
2.1. Uncertainty Quantification
2.2. Uncertainty Metrics
3. Uncertainty Approximation for Text Classification
3.1. Bayesian Learning
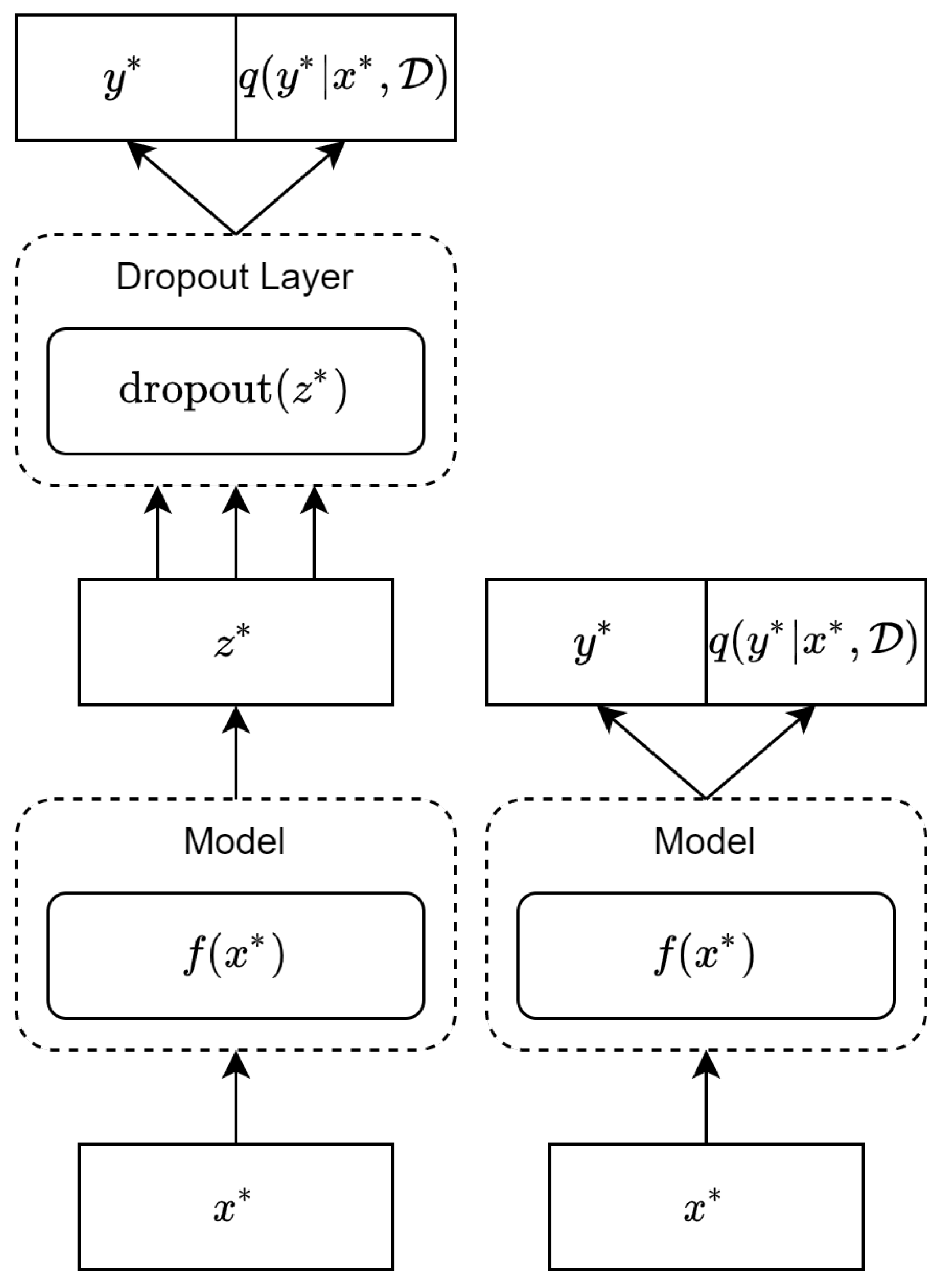
3.2. Monte Carlo Dropout
Combining Sample Predictions
3.3. Softmax
4. Experiments and Results
4.1. Data
4.2. Experimental Setup
MC Dropout Sampling
4.3. Evaluation Metrics
4.3.1. Efficiency
4.3.2. Performance Metrics
4.4. Efficiency Results
4.5. Test Data Holdout Results
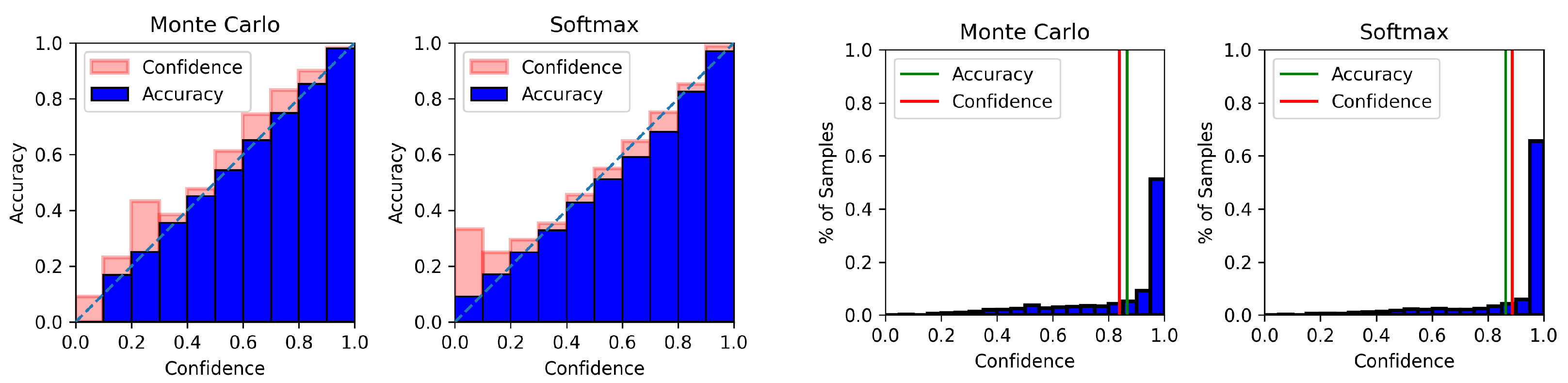
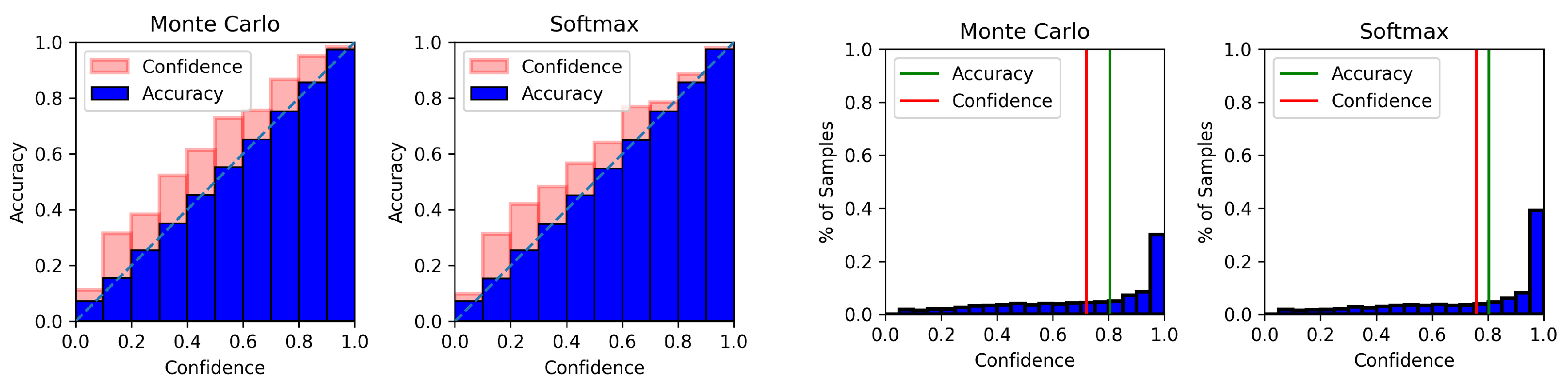
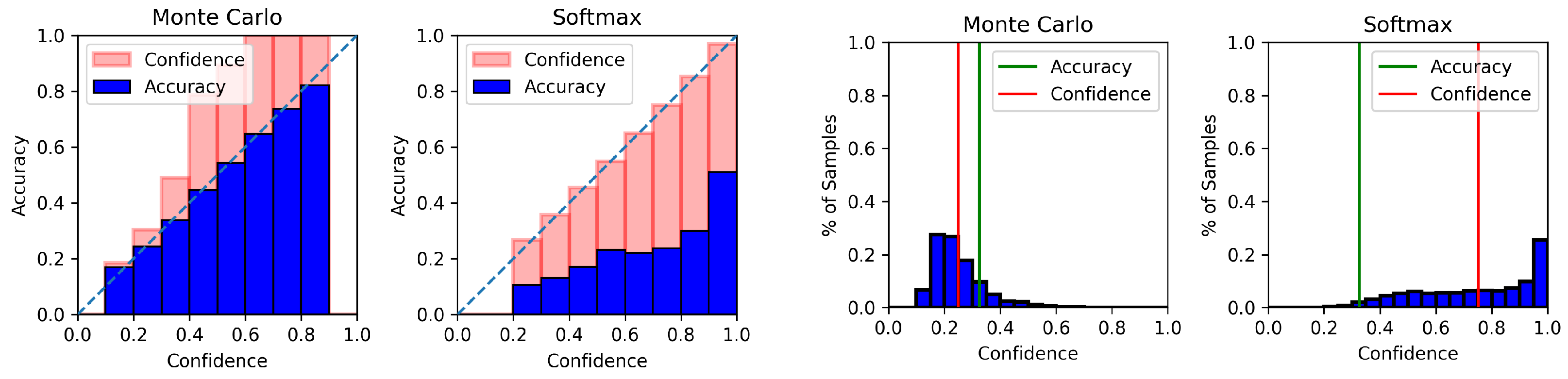
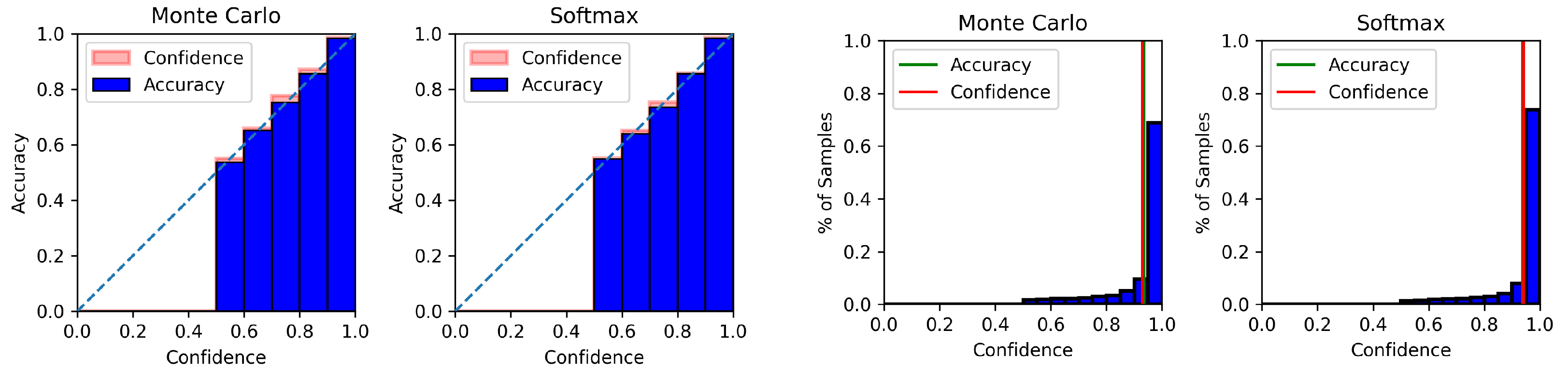
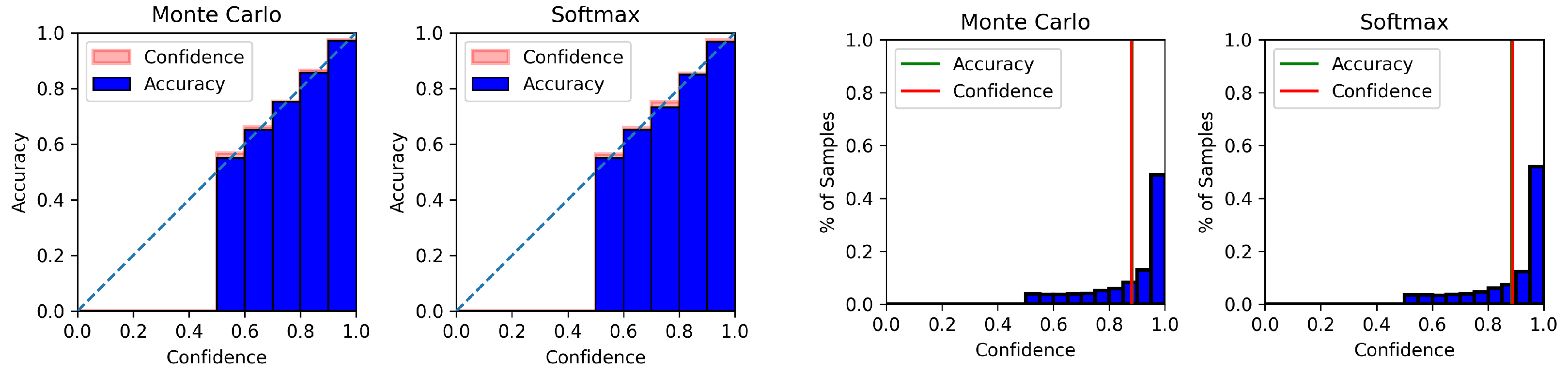
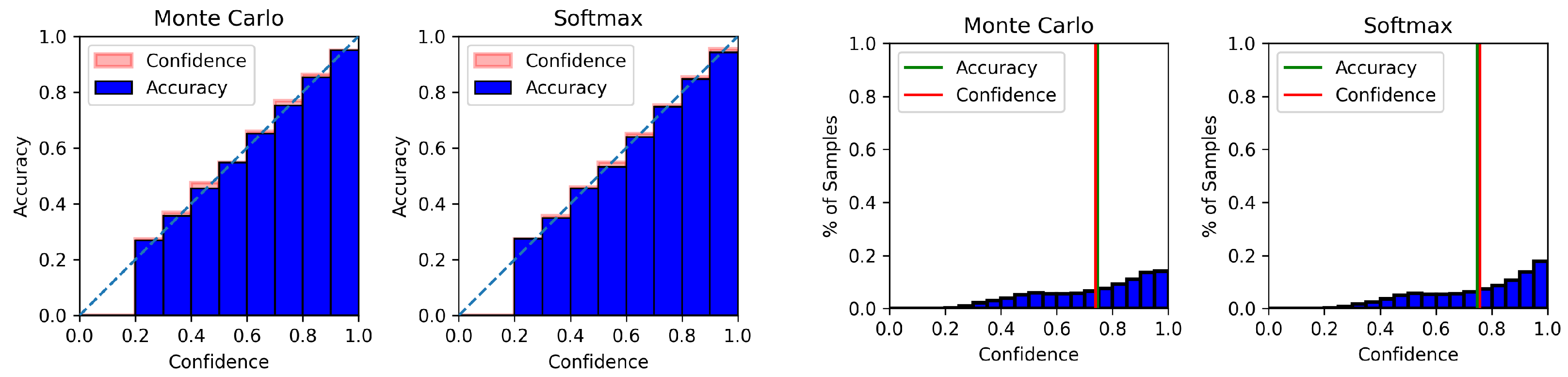
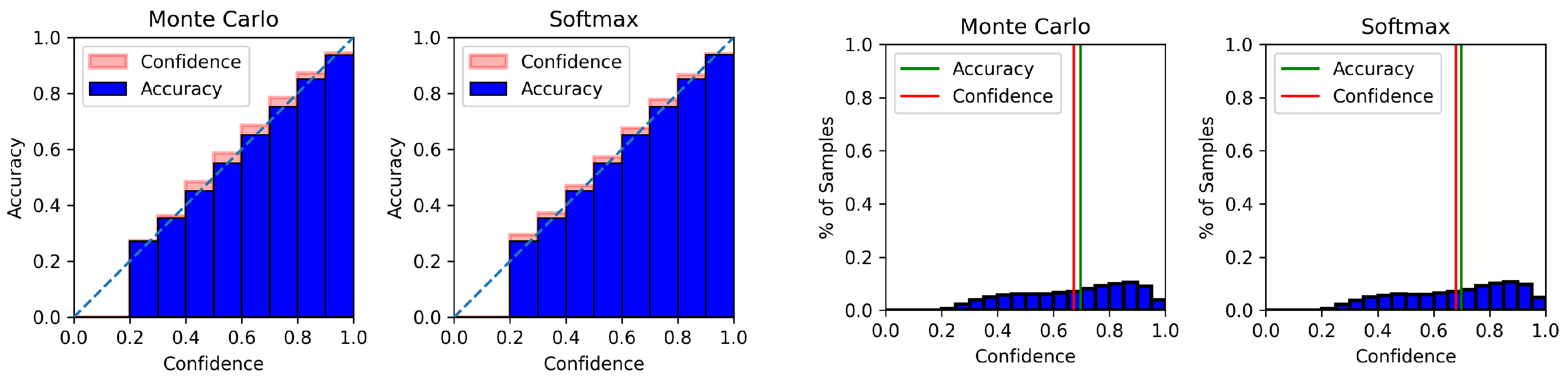
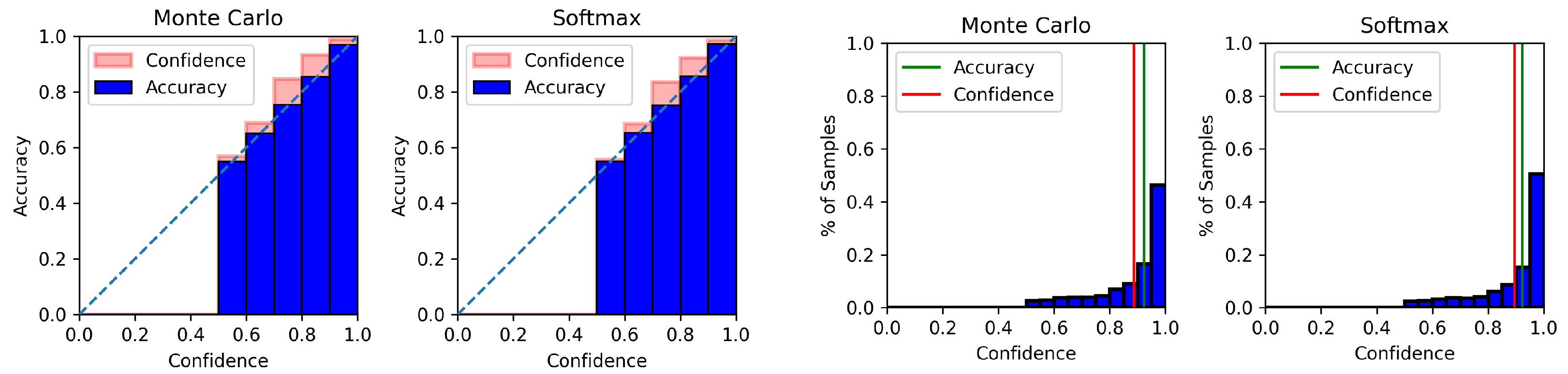
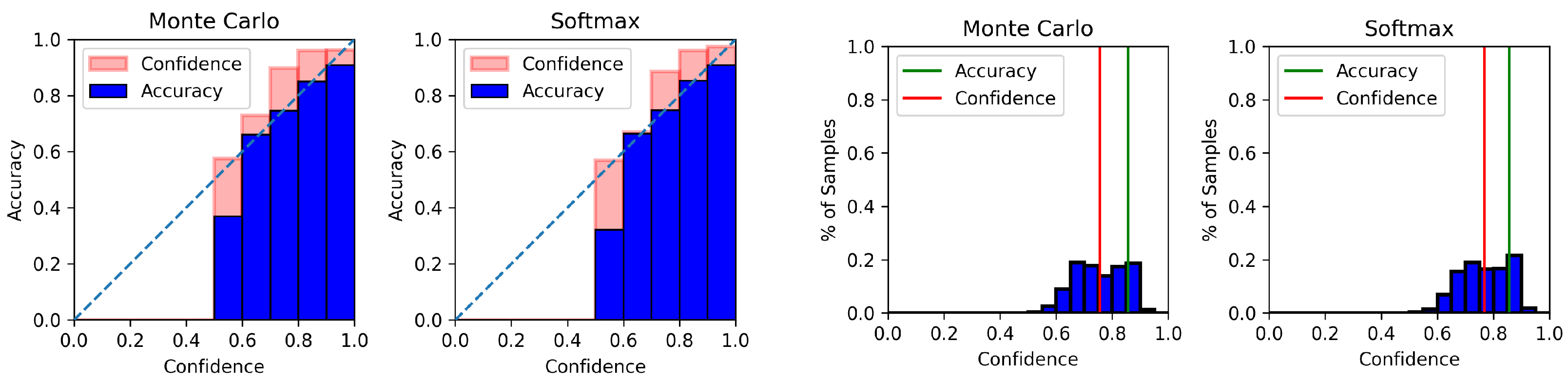
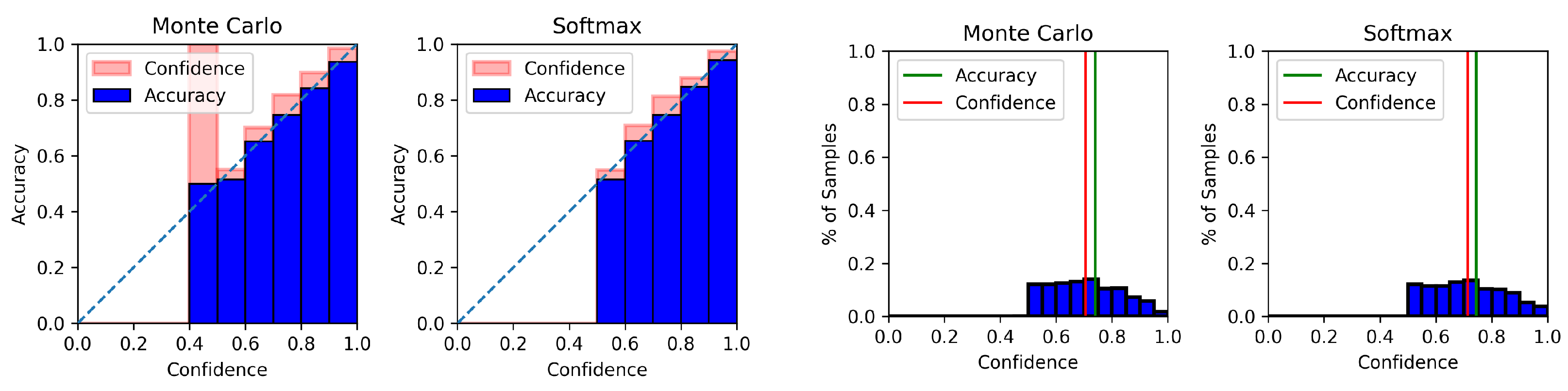
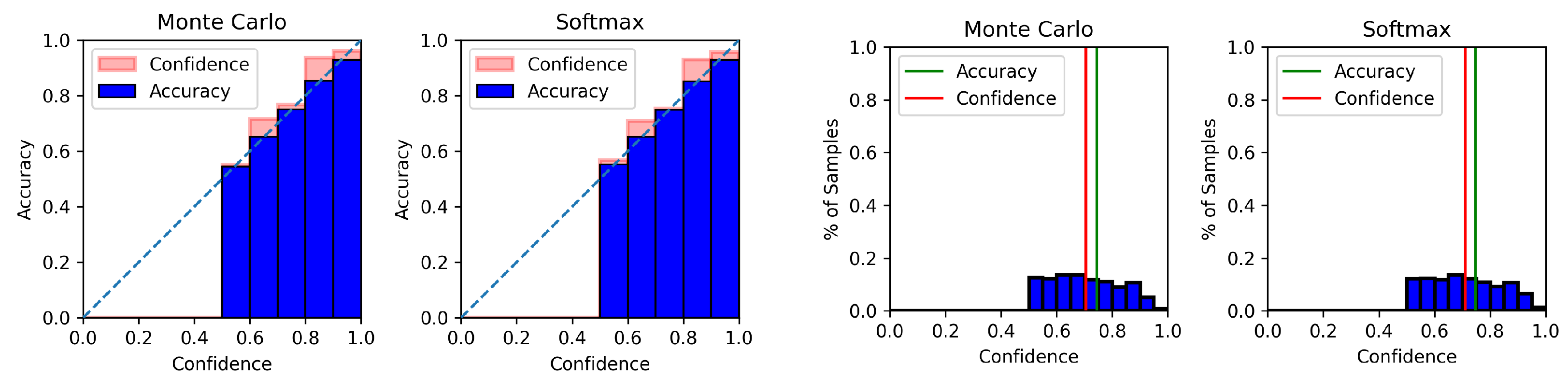
4.6. Model Calibration Results
5. Discussion and Conclusions
6. Limitations
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Reproducibility
Appendix A.1. Computing Infrastructure
Appendix A.2. Hyperparameters
Appendix A.3. Dropout Hyperparameters

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 0% | 10% | 20% | 30% | 40% | |
|---|---|---|---|---|---|
| 0.1 | 0.8598 | 0.9010 | 0.9255 | 0.9408 | 0.9483 |
| 0.2 | 0.8599 | 0.9005 | 0.9256 | 0.9408 | 0.9502 |
| 0.3 | 0.8596 | 0.9007 | 0.9245 | 0.9412 | 0.9491 |
| 0.4 | 0.8601 | 0.8996 | 0.9253 | 0.9425 | 0.9502 |
| 0.5 | 0.8591 | 0.8985 | 0.9225 | 0.9406 | 0.9487 |
Appendix B. Result Tables
| BERT | 0% | 10% | 20% | 30% | 40% |
|---|---|---|---|---|---|
| Mean MC | 0.9354 | 0.9668 (1.0335) | 0.9829 (1.0508) | 0.9901 (1.0585) | 0.9930 (1.0616) |
| DE | 0.9354 | 0.9679 (1.0347) | 0.9789 (1.0465) | 0.9787 (1.0463) | 0.9798 (1.0475) |
| Softmax | 0.9364 | 0.9691 (1.0349) | 0.9847 (1.0516) | 0.9913 (1.0586) | 0.9940 (1.0615) |
| PL-Variance | 0.9364 | 0.9678 (1.0335) | 0.9837 (1.0506) | 0.9901 (1.0574) | 0.9933 (1.0608) |
| GloVe | |||||
| Mean MC | 0.8825 | 0.9170 (1.0391) | 0.9416 (1.0670) | 0.9614 (1.0894) | 0.9730 (1.1025) |
| DE | 0.8825 | 0.9183 (1.0406) | 0.9430 (1.0686) | 0.9449 (1.0707) | 0.9455 (1.0714) |
| Softmax | 0.8824 | 0.9154 (1.0374) | 0.9406 (1.0660) | 0.9598 (1.0878) | 0.9724 (1.1020) |
| PL-Variance | 0.8824 | 0.9162 (1.0383) | 0.9415 (1.0670) | 0.9611 (1.0892) | 0.9736 (1.1034) |
| BERT | 0% | 10% | 20% | 30% | 40% |
|---|---|---|---|---|---|
| Mean MC | 0.7466 | 0.7853 (1.0518) | 0.8137 (1.0898) | 0.8392 (1.1240) | 0.8605 (1.1526) |
| DE | 0.7466 | 0.7850 (1.0513) | 0.8191 (1.0871) | 0.8492 (1.1374) | 0.8684 (1.1631) |
| Softmax | 0.7474 | 0.7875 (1.0537) | 0.8225 (1.1005) | 0.8562 (1.1456) | 0.8845 (1.1834) |
| PL-Variance | 0.7474 | 0.7856 (1.0510) | 0.8144 (1.0896) | 0.8404 (1.1244) | 0.8610 (1.1520) |
| GloVe | |||||
| Mean MC | 0.6979 | 0.7369 (1.0559) | 0.7675 (1.0998) | 0.7962 (1.1408) | 0.8214 (1.1770) |
| DE | 0.6979 | 0.7366 (1.0555) | 0.7716 (1.1056) | 0.8019 (1.1490) | 0.8102 (1.1610) |
| Softmax | 0.6984 | 0.7374 (1.0559) | 0.7730 (1.1068) | 0.8067 (1.1550) | 0.8359 (1.1969) |
| PL-Variance | 0.6984 | 0.7358 (1.0536) | 0.7676 (1.0990) | 0.7961 (1.1398) | 0.8209 (1.1753) |
| BERT | 0% | 10% | 20% | 30% | 40% |
|---|---|---|---|---|---|
| Mean MC | 0.9227 | 0.9569 (1.0370) | 0.9742 (1.0557) | 0.9824 (1.0646) | 0.9878 (1.0705) |
| DE | 0.9227 | 0.9566 (1.0367) | 0.9743 (1.0559) | 0.9767 (1.0585) | 0.9762 (1.0579) |
| Softmax | 0.9230 | 0.9561 (1.0358) | 0.9745 (1.0558) | 0.9834 (1.0655) | 0.9869 (1.0692) |
| PL-Variance | 0.9230 | 0.9566 (1.0364) | 0.9748 (1.0561) | 0.9827 (1.0647) | 0.9869 (1.0693) |
| GloVe | |||||
| Mean MC | 0.8559 | 0.8958 (1.0466) | 0.9168 (1.0712) | 0.9325 (1.0896) | 0.9379 (1.0958) |
| DE | 0.8559 | 0.8914 (1.0415) | 0.9146 (1.0686) | 0.9269 (1.0830) | 0.9319 (1.0889) |
| Softmax | 0.8539 | 0.8941 (1.0471) | 0.9181 (1.0752) | 0.9312 (1.0906) | 0.9393 (1.1001) |
| PL-Variance | 0.8539 | 0.8958 (1.0491) | 0.9209 (1.0785) | 0.9322 (1.0918) | 0.9366 (1.0969) |
| BERT | 0% | 10% | 20% | 30% | 40% |
|---|---|---|---|---|---|
| Mean MC | 0.7407 | 0.7706 (1.0403) | 0.7907 (1.0674) | 0.8149 (1.1001) | 0.8432 (1.1383) |
| DE | 0.7407 | 0.7744 (1.0454) | 0.8008 (1.0811) | 0.8265 (1.1158) | 0.8472 (1.1437) |
| Softmax | 0.7442 | 0.7706 (1.0354) | 0.8006 (1.0758) | 0.8246 (1.1080) | 0.8451 (1.1355) |
| PL-Variance | 0.7442 | 0.7719 (1.0372) | 0.7964 (1.0701) | 0.8100 (1.0884) | 0.8339 (1.1205) |
| GloVe | |||||
| Mean MC | 0.7397 | 0.7658 (1.0354) | 0.7853 (1.0354) | 0.8013 (1.0833) | 0.8202 (1.1088) |
| DE | 0.7397 | 0.7648 (1.0339) | 0.7940 (1.0735) | 0.7998 (1.0812) | 0.8204 (1.1091) |
| Softmax | 0.7442 | 0.7686 (1.0328) | 0.7918 (1.0639) | 0.8023 (1.0780) | 0.8217 (1.0141) |
| PL-Variance | 0.7442 | 0.7686 (1.0328) | 0.7918 (1.0639) | 0.8023 (1.0780) | 0.8204 (1.1023) |
Appendix C. Model Calibration Plots








References
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems 30, Long Beach, CA, USA, 4–9 December 2017; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 5998–6008. [Google Scholar]
- Lin, T.; Wang, Y.; Liu, X.; Qiu, X. A Survey of Transformers. arXiv 2021, arXiv:2106.04554. [Google Scholar] [CrossRef]
- Tay, Y.; Dehghani, M.; Gupta, J.P.; Aribandi, V.; Bahri, D.; Qin, Z.; Metzler, D. Are Pretrained Convolutions Better than Pretrained Transformers? In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021.
- Gawlikowski, J.; Tassi, C.R.N.; Ali, M.; Lee, J.; Humt, M.; Feng, J.; Kruspe, A.; Triebel, R.; Jung, P.; Roscher, R.; et al. A Survey of Uncertainty in Deep Neural Networks. arXiv 2021, arXiv:2107.03342. [Google Scholar]
- Gal, Y.; Ghahramani, Z. Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1050–1059. [Google Scholar]
- Blundell, C.; Cornebise, J.; Kavukcuoglu, K.; Wierstra, D. Weight Uncertainty in Neural Network. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 1613–1622. [Google Scholar]
- Hendrycks, D.; Gimpel, K. A Baseline for Detecting Misclassified and Out-of-Distribution Examples in Neural Networks. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Zhang, X.; Chen, F.; Lu, C.T.; Ramakrishnan, N. Mitigating Uncertainty in Document Classification. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 July 2019; Long and Short Papers. Association for Computational Linguistics: Minneapolis, MN, USA, 2019; Volume 1, pp. 3126–3136. [Google Scholar] [CrossRef]
- He, J.; Zhang, X.; Lei, S.; Chen, Z.; Chen, F.; Alhamadani, A.; Xiao, B.; Lu, C. Towards More Accurate Uncertainty Estimation In Text Classification. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP); Association for Computational Linguistics, Online. 16–20 November 2020; pp. 8362–8372. [Google Scholar] [CrossRef]
- Strubell, E.; Ganesh, A.; McCallum, A. Energy and Policy Considerations for Deep Learning in NLP. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019. [Google Scholar]
- Patterson, D.A.; Gonzalez, J.; Le, Q.V.; Liang, C.; Munguia, L.; Rothchild, D.; So, D.R.; Texier, M.; Dean, J. Carbon Emissions and Large Neural Network Training. arXiv 2021, arXiv:2104.10350. [Google Scholar]
- Ovadia, Y.; Fertig, E.; Ren, J.; Nado, Z.; Sculley, D.; Nowozin, S.; Dillon, J.; Lakshminarayanan, B.; Snoek, J. Can you trust your model’s uncertainty? Evaluating predictive uncertainty under dataset shift. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Henne, M.; Schwaiger, A.; Roscher, K.; Weiss, G. Benchmarking Uncertainty Estimation Methods for Deep Learning with Safety-Related Metrics. In Proceedings of the Workshop on Artificial Intelligence Safety, Co-Located with 34th AAAI Conference on Artificial Intelligence, SafeAI@AAAI 2020, New York, NY, USA, 7 February 2020. [Google Scholar]
- Mozejko, M.; Susik, M.; Karczewski, R. Inhibited Softmax for Uncertainty Estimation in Neural Networks. arXiv 2018, arXiv:1810.01861. [Google Scholar]
- van Amersfoort, J.; Smith, L.; Teh, Y.W.; Gal, Y. Uncertainty Estimation Using a Single Deep Deterministic Neural Network. In Proceedings of the 37th International Conference on Machine Learning, ICML Virtual Event, 13–18 July 2020; Volume 119, pp. 9690–9700, PMLR. [Google Scholar]
- Hinton, G.E.; van Camp, D. Keeping the neural networks simple by minimizing the description length of the weights. In Proceedings of the Sixth Annual Conference on Computational Learning Theory, COLT’93, Santa Cruz, CA, USA, 26–28 July 1993; Association for Computing Machinery: New York, NY, USA, 1993; pp. 5–13. [Google Scholar] [CrossRef]
- Neal, R. Bayesian Training of Backpropagation Networks by the Hybrid Monte Carlo Method; Technical Report; University of Toronto: Toronto, ON, Canada, 1993. [Google Scholar]
- MacKay, D.J.C. A Practical Bayesian Framework for Backpropagation Networks. Neural Comput. 1992, 4, 448–472. [Google Scholar] [CrossRef]
- Lakshminarayanan, B.; Pritzel, A.; Blundell, C. Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Durasov, N.; Bagautdinov, T.; Baque, P.; Fua, P. Masksembles for uncertainty estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13539–13548. [Google Scholar]
- Niculescu-Mizil, A.; Caruana, R. Predicting good probabilities with supervised learning. In Proceedings of the 22nd international conference on Machine learning, ICML’05, Bonn German, 7–11 August 2005; Association for Computing Machinery: New York, NY, USA, 2015; pp. 625–632. [Google Scholar] [CrossRef]
- Guo, C.; Pleiss, G.; Sun, Y.; Weinberger, K.Q. On Calibration of Modern Neural Networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 1321–1330. [Google Scholar]
- Naeini, M.P.; Cooper, G.F.; Hauskrecht, M. Obtaining Well Calibrated Probabilities Using Bayesian Binning. In Proceedings of the AAAI conference on artificial intelligence, Austin, TX, USA, 25–30 January 2015; pp. 2901–2907. [Google Scholar]
- Gal, Y.; Ghahramani, Z. Dropout as a Bayesian Approximation: Appendix. arXiv 2016, arXiv:1506.02157. [Google Scholar]
- Joo, T.; Chung, U.; Seo, M.G. Being Bayesian about Categorical Probability. In Proceedings of the 37th International Conference on Machine Learning, Virtual. 13–18 July 2020; pp. 4950–4961. [Google Scholar]
- Lang, K. NewsWeeder: Learning to Filter Netnews. In Proceedings of the Twelfth International Conference on Machine Learning, Tahoe City, CA, USA, 9–12 July 1995; Prieditis, A., Russell, S., Eds.; Morgan Kaufmann: San Francisco, CA, USA, 1995; pp. 331–339. [Google Scholar] [CrossRef]
- McAuley, J.; Leskovec, J. Hidden factors and hidden topics: Understanding rating dimensions with review text. In Proceedings of the 7th ACM conference on Recommender Systems, RecSys’13, Hong Kong, China, 12–16 October 2013; Association for Computing Machinery: New York, NY, USA, 2013; pp. 165–172. [Google Scholar] [CrossRef]
- Maas, A.L.; Daly, R.E.; Pham, P.T.; Huang, D.; Ng, A.Y.; Potts, C. Learning Word Vectors for Sentiment Analysis. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; Association for Computational Linguistics: Portland, OR, USA, 2011; pp. 142–150. [Google Scholar]
- Socher, R.; Perelygin, A.; Wu, J.; Chuang, J.; Manning, C.D.; Ng, A.Y.; Potts, C. Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, EMNLP 2013, Grand Hyatt Seattle, Seattle, DC, USA, 18–21 October 2013. [Google Scholar]
- Redi, M.; Fetahu, B.; Morgan, J.T.; Taraborelli, D. Citation Needed: A Taxonomy and Algorithmic Assessment of Wikipedia’s Verifiability. In Proceedings of the WWW’19: The Web Conference, San Francisco, CA, USA, 13–17 May 2019. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, EMNLP 2014, Doha, Qatar, 25–29 October 2014. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Zaragoza, H.; d’Alché Buc, F. Confidence Measures for Neural Network Classifiers. In Proceedings of the 7th Conference on Information Processing and Management of Uncertainty in Knowledge-Based Systems, Paris, France, 6–10 July 1998. [Google Scholar]




| 1 | 10 | 25 | 50 | 100 | 1000 |
| 0.8212 | 0.8623 | 0.8540 | 0.8591 | 0.8559 | 0.8573 |
| Forward Passes | Mean MC | DE | |
|---|---|---|---|
| 20 Newsgroups | 1.0876 | 0.0003 | 12.3537 |
| IMDb | 1.386 | 0.0018 | 216.11 |
| Amazon | 4.9126 | 0.0017 | 194.08 |
| WIKI | 1.1149 | 0.0010 | 15.8467 |
| SST-2 | 1.0076 | 0.0003 | 3.4785 |
| Forward Passes | Softmax | PL-Variance | |
| 20 Newsgroups | 0.0130 | 0.0002 | 0.0001 |
| IMDb | 0.0387 | 0.0003 | 0.0003 |
| Amazon | 0.4067 | 0.0004 | 0.0002 |
| WIKI | 0.0149 | 0.0002 | 0.0001 |
| SST-2 | 0.0037 | 0.0002 | 0.0001 |
| BERT | 0% | 10% | 20% | 30% | 40% |
|---|---|---|---|---|---|
| Mean MC | 0.8591 | 0.8985 (1.0459) | 0.9225 (1.0739) | 0.9406 (1.0949) | 0.9487 (1.1043) |
| DE | 0.8591 | 0.9050 (1.0534) | 0.9390 (1.0930) | 0.9584 (1.1156) | 0.9703 (1.1294) |
| Softmax | 0.8576 | 0.9072 (1.0578) | 0.9452 (1.1021) | 0.9620 (1.1216) | 0.9742 (1.1360) |
| PL-Variance | 0.8576 | 0.9006 (1.0501) | 0.9246 (1.0781) | 0.9403 (1.0964) | 0.9484 (1.1058) |
| GloVe | |||||
| Mean MC | 0.7966 | 0.8450 (1.0608) | 0.8674 (1.0888) | 0.8846 (0.1104) | 0.8960 (1.1248) |
| DE | 0.7966 | 0.8469 (1.0631) | 0.8855 (1.1116) | 0.9155 (1.1492) | 0.9416 (1.1820) |
| Softmax | 0.7959 | 0.8465 (1.0636) | 0.8846 (1.1115) | 0.9149 (1.1496) | 0.9402 (1.1813) |
| PL-Variance | 0.7959 | 0.8436 (1.0599) | 0.8667 (1.0891) | 0.8848 (1.1118) | 0.8966 (1.1266) |
| Accuracy | ECE | |
|---|---|---|
| 20 Newsgroups—Mean MC | 0.8655 | 0.0275 |
| 20 Newsgroups—Softmax | 0.8642 | 0.0253 |
| IMDb—Mean MC | 0.9354 | 0.0061 |
| IMDb—Softmax | 0.9364 | 0.0043 |
| Amazon—Mean MC | 0.7466 | 0.0083 |
| Amazon—Softmax | 0.7474 | 0.0097 |
| WIKI—Mean MC | 0.9227 | 0.0370 |
| WIKI—Softmax | 0.9230 | 0.0279 |
| SST-2—Mean MC | 0.7408 | 0.0535 |
| SST-2—Softmax | 0.7442 | 0.0472 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Holm, A.N.; Wright, D.; Augenstein, I. Revisiting Softmax for Uncertainty Approximation in Text Classification. Information 2023, 14, 420. https://doi.org/10.3390/info14070420
Holm AN, Wright D, Augenstein I. Revisiting Softmax for Uncertainty Approximation in Text Classification. Information. 2023; 14(7):420. https://doi.org/10.3390/info14070420
Chicago/Turabian StyleHolm, Andreas Nugaard, Dustin Wright, and Isabelle Augenstein. 2023. "Revisiting Softmax for Uncertainty Approximation in Text Classification" Information 14, no. 7: 420. https://doi.org/10.3390/info14070420
APA StyleHolm, A. N., Wright, D., & Augenstein, I. (2023). Revisiting Softmax for Uncertainty Approximation in Text Classification. Information, 14(7), 420. https://doi.org/10.3390/info14070420