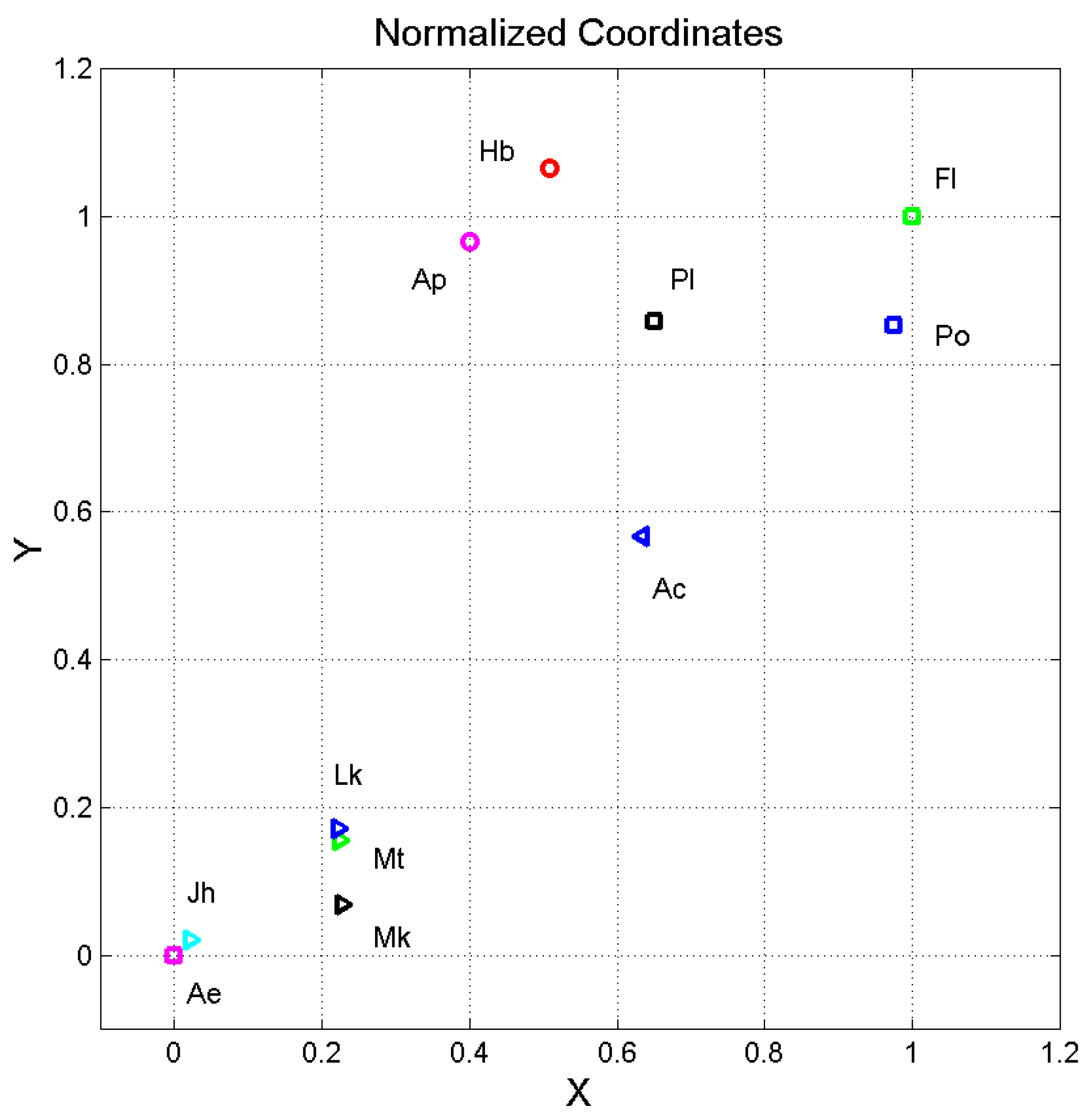
Figure 1.
Normalized coordinates and of the ending point of vector (5) such that Aesop is (0,0) (Ae, magenta square), and Flavius Josephus is (1,1) (Fl, green square). Matthew (Mt, green triangle), Mark (Mk, black triangle), Luke (Lk, blue triangle oriented to the right), John (Jh, cyan triangle), Acts (Ac, blue triangle oriented to the left), Flavius Josephus (Fl, green square), Hebrews (Hb, red circle), Apocalypse (Ap, magenta circle), Polybius (Po, blue square), and Plutarch (Pl, black square).
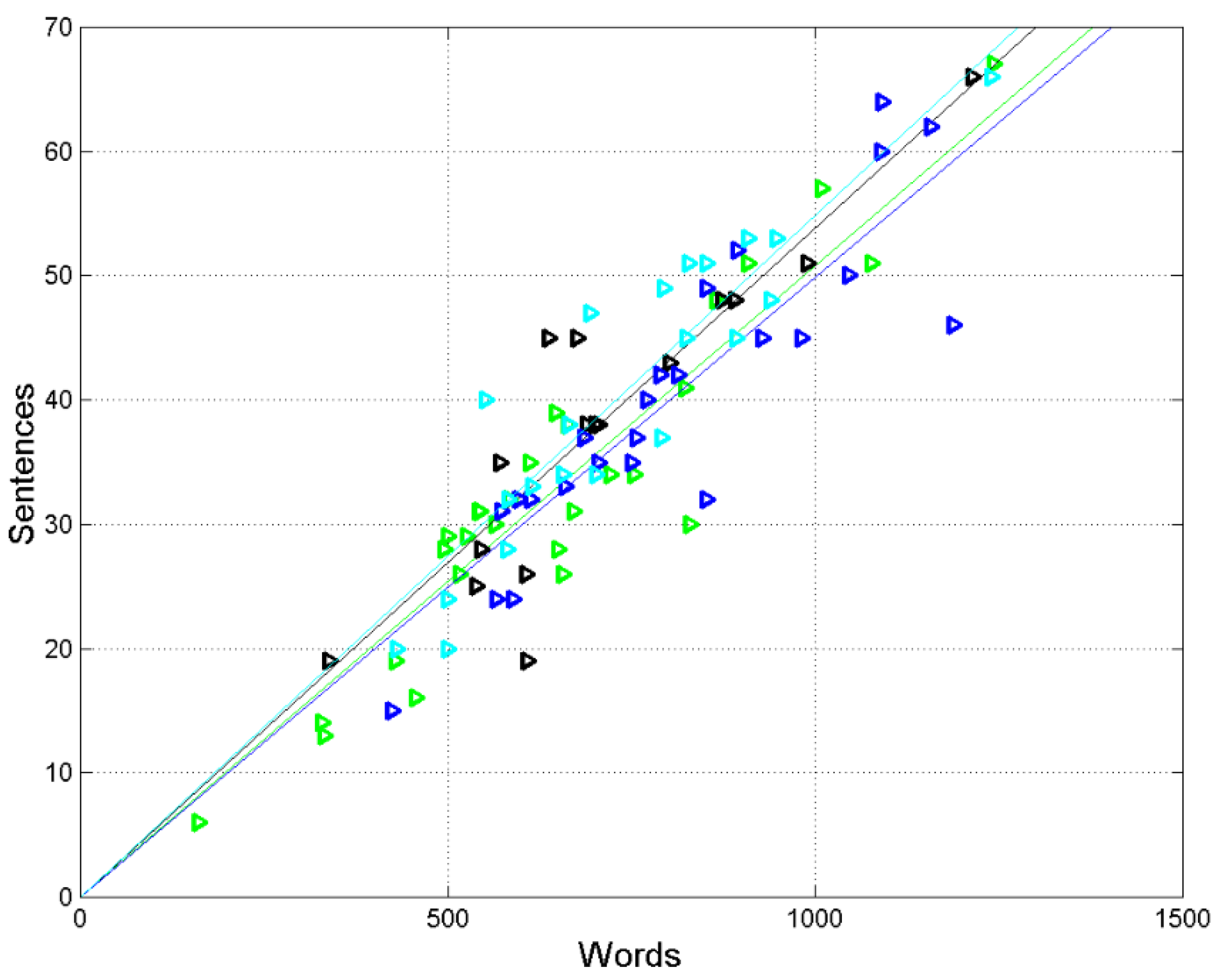
Figure 2.
Scatterplots and regression lines between (words, independent variable) and (sentences, dependent variable) in the following texts: Matthew (green triangles and green line), Mark (black triangles and black line), Luke (blue triangles and blue line), and John (cyan triangles and cyan line).
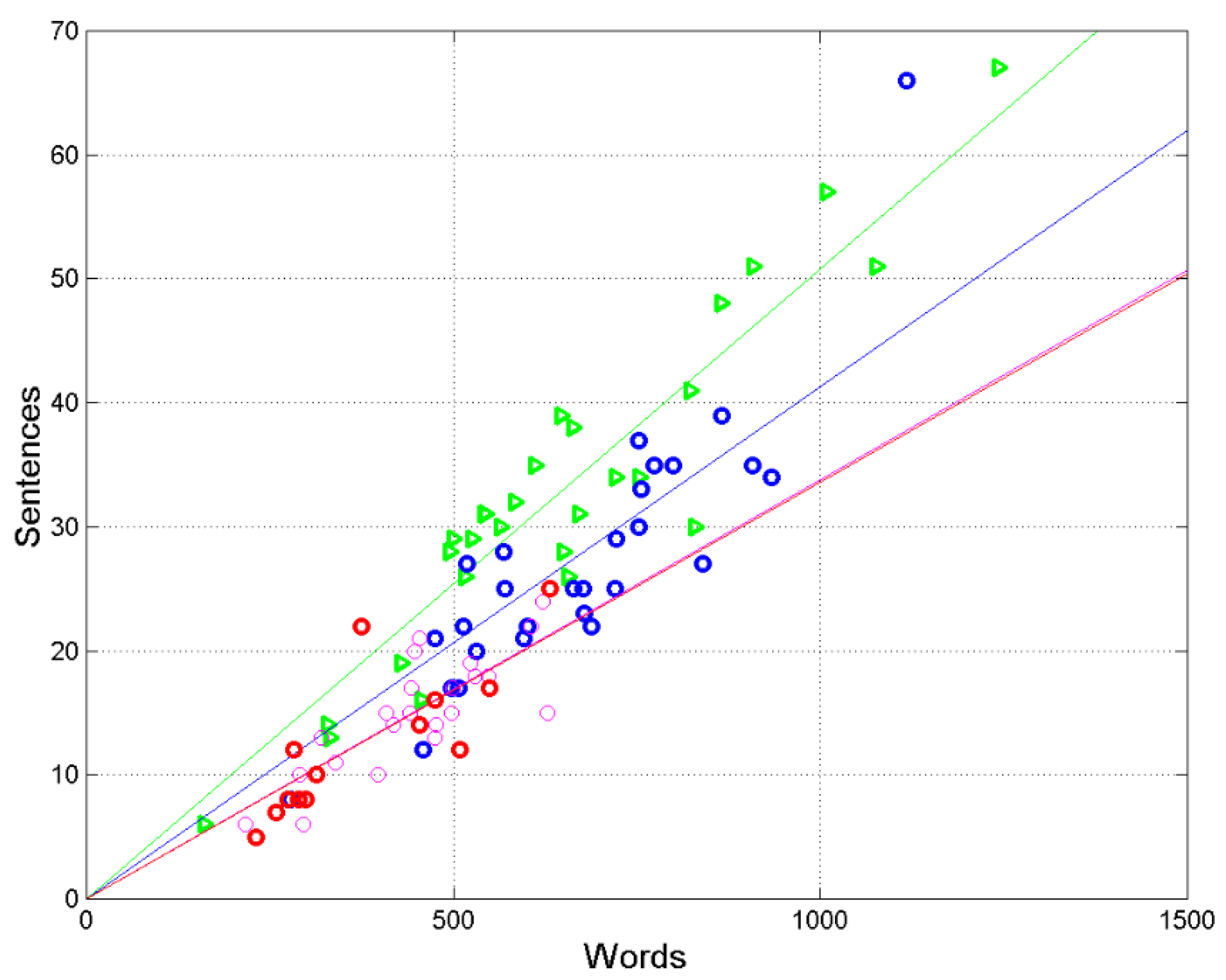
Figure 3.
Scatterplots and regression lines between
(words, independent variable) and
(sentences, dependent variable) in the following texts: Matthew (green triangles and green line), Acts (blue circles and blue line), Hebrews (red circles and red line), and Apocalypse (magenta circles and magenta line). The magenta line (Apocalypse) and the red line (Hebrews) are superposed because they practically coincide (see
Table 3).
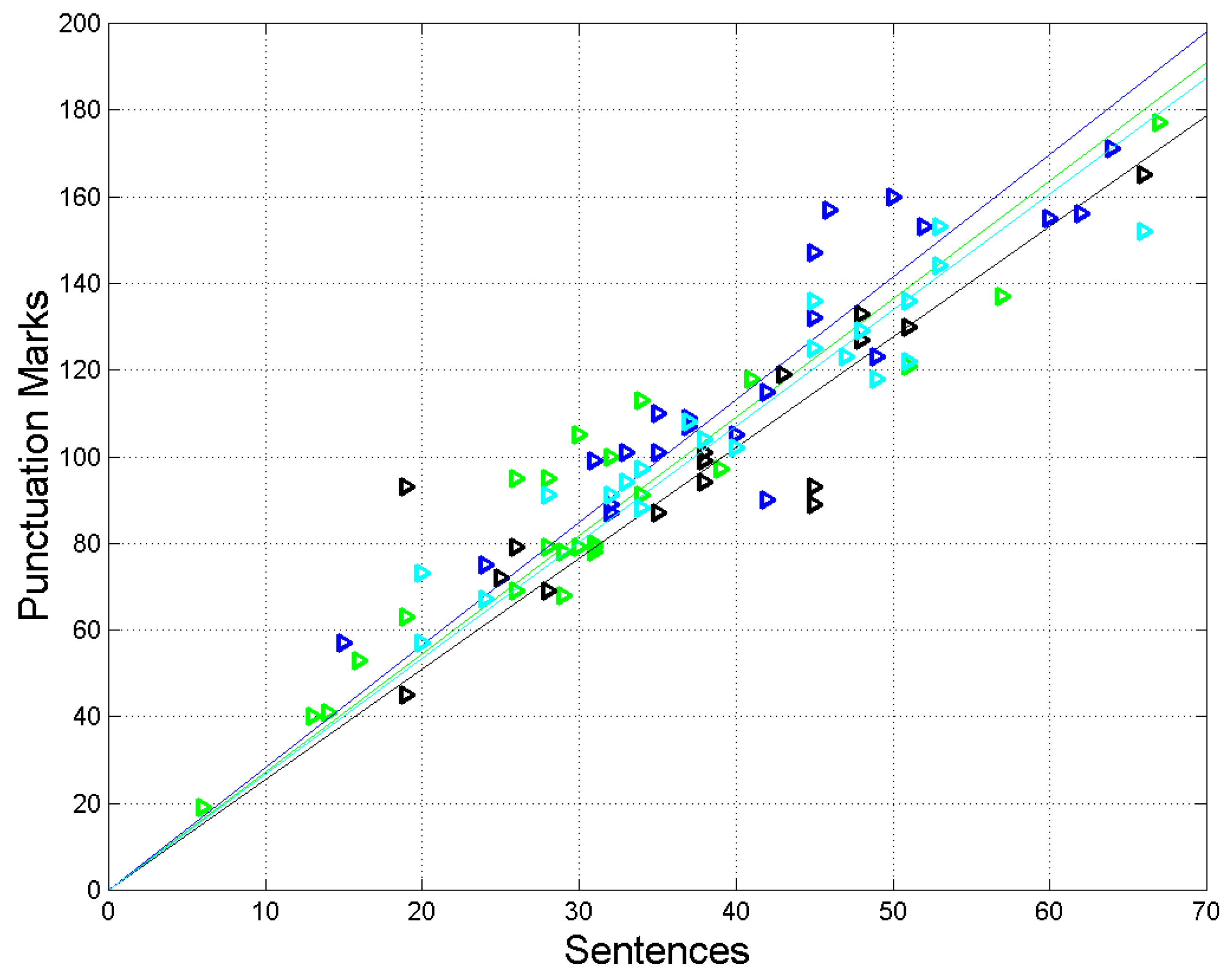
Figure 4.
Scatterplots and regression lines between (sentences, independent variable) and (interpunctions, dependent variable) in the following texts: Matthew (green triangles and green line), Mark (black triangles and black line), Luke (blue triangles and blue line), and John (cyan triangles and cyan line).
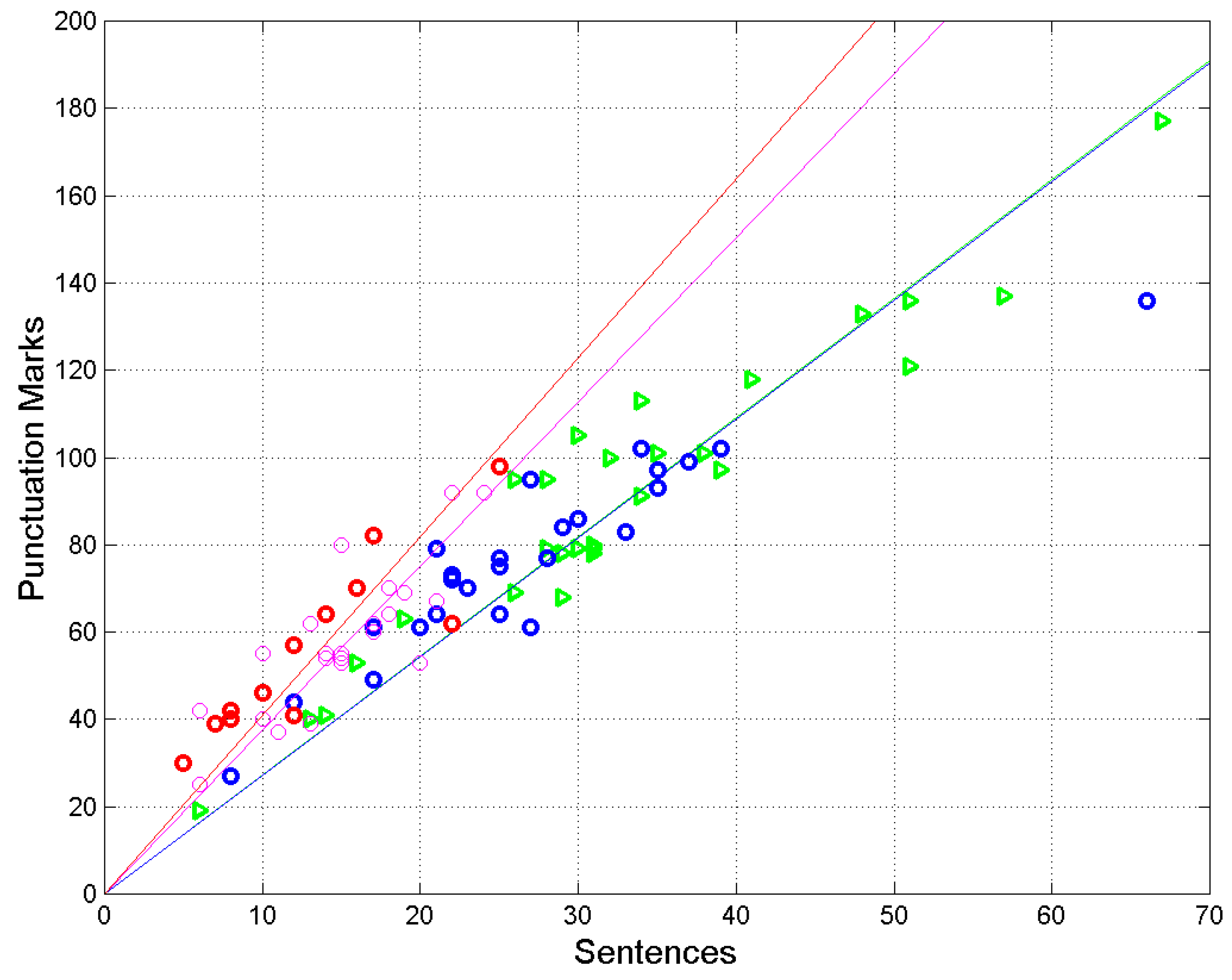
Figure 5.
Scatterplots and regression lines between
(sentences, independent variable) and
(interpunctions, dependent variable) in the following texts: Matthew (green triangles and green line), Acts (blue circles and blue line), Hebrews (red circles and red line), and Apocalypse (magenta circles and magenta line). The green line (Matthew) and the blue line (Acts) are superposed because they practically coincide (see
Table 3).
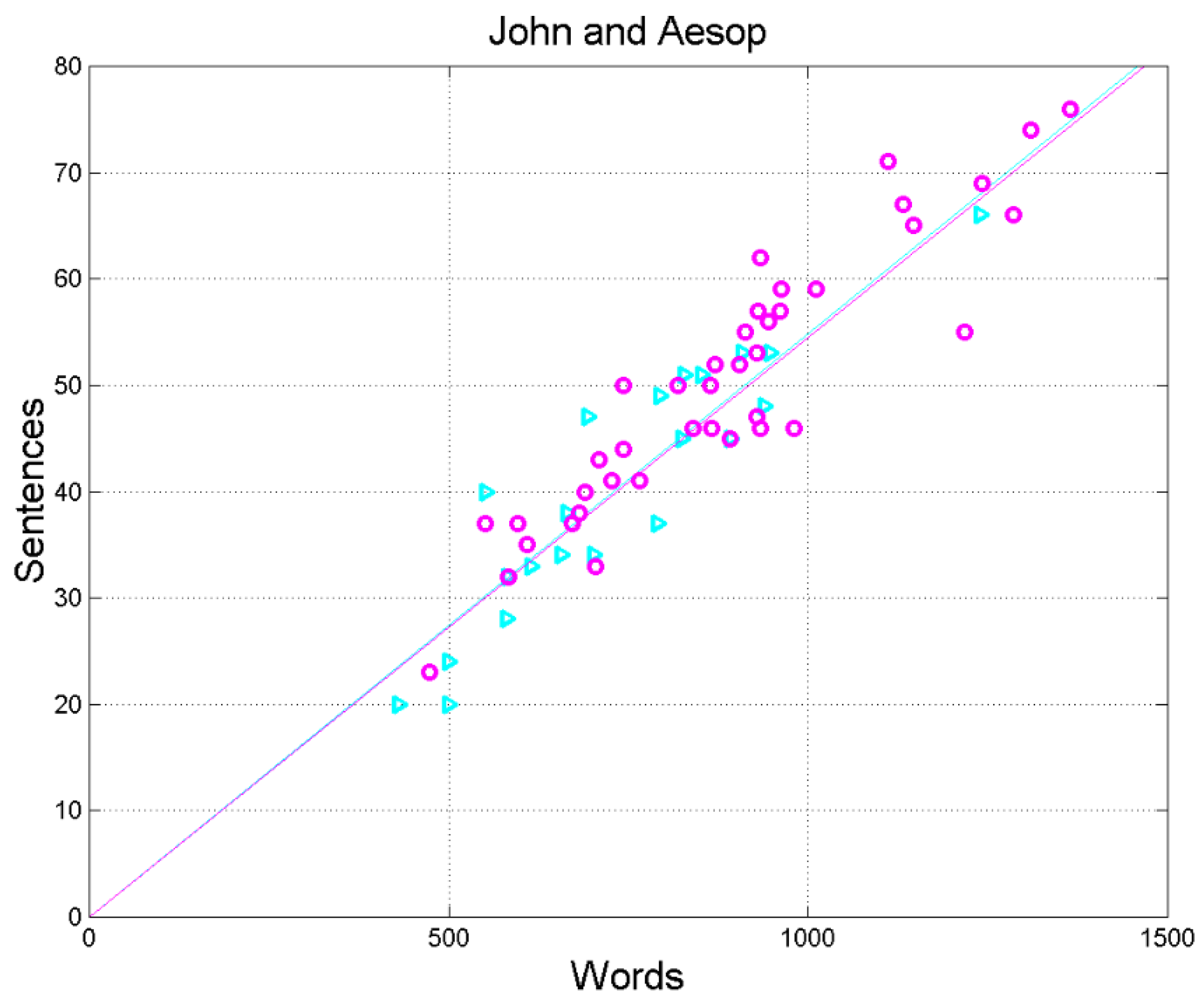
Figure 6.
Scatterplots and regression lines between (words, independent variable) and (sentences, dependent variable) in John (cyan triangles and cyan) and in Aesop (magenta circles and magenta line). Notice that the two regression lines are practically superposed, and the scattering of the two sets are very alike.
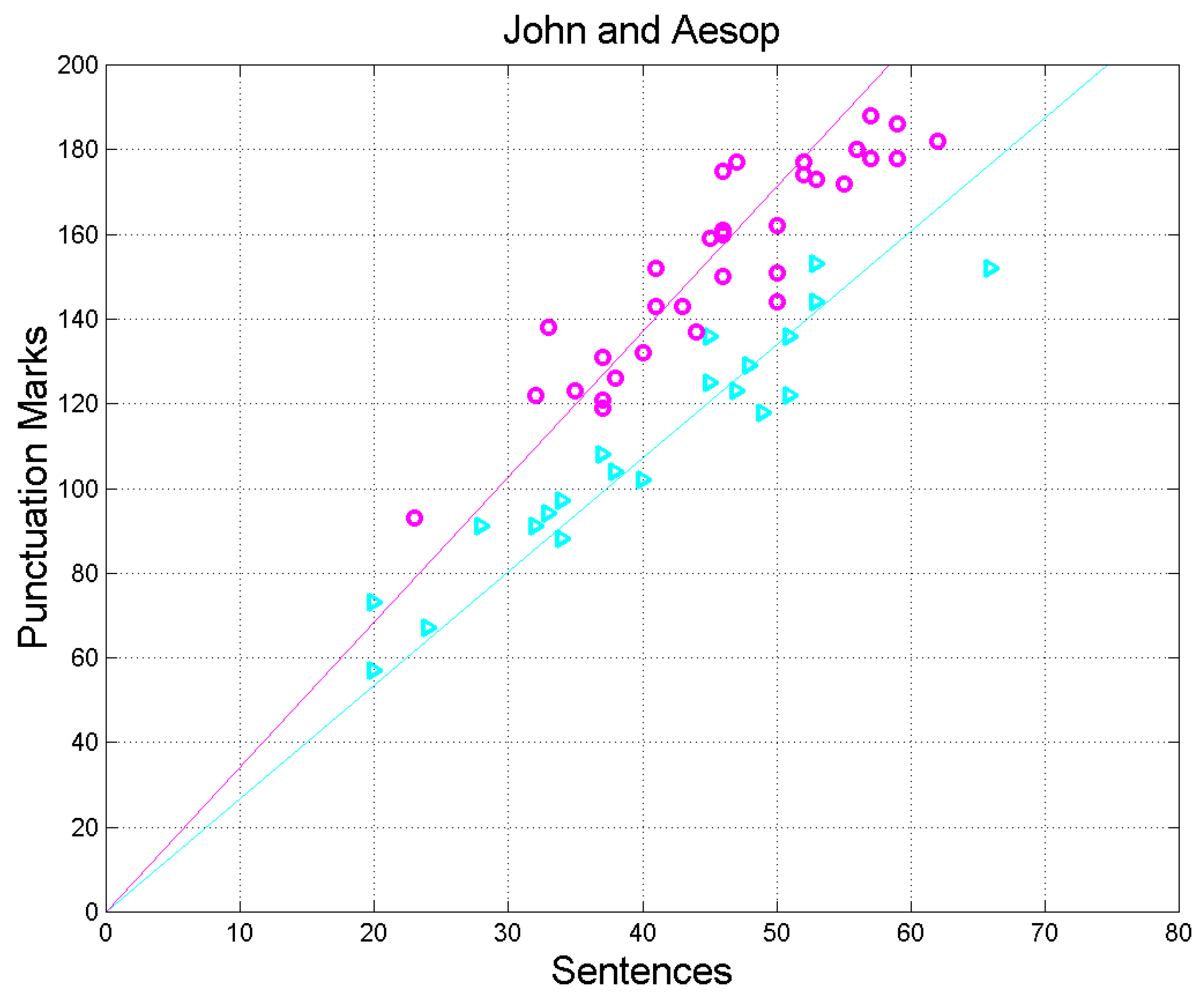
Figure 7.
Scatterplots and regression lines between (sentences, independent variable) and (interpunctions, dependent variable) in John (cyan triangles and cyan line) and in Aesop (magenta circles and magenta line).
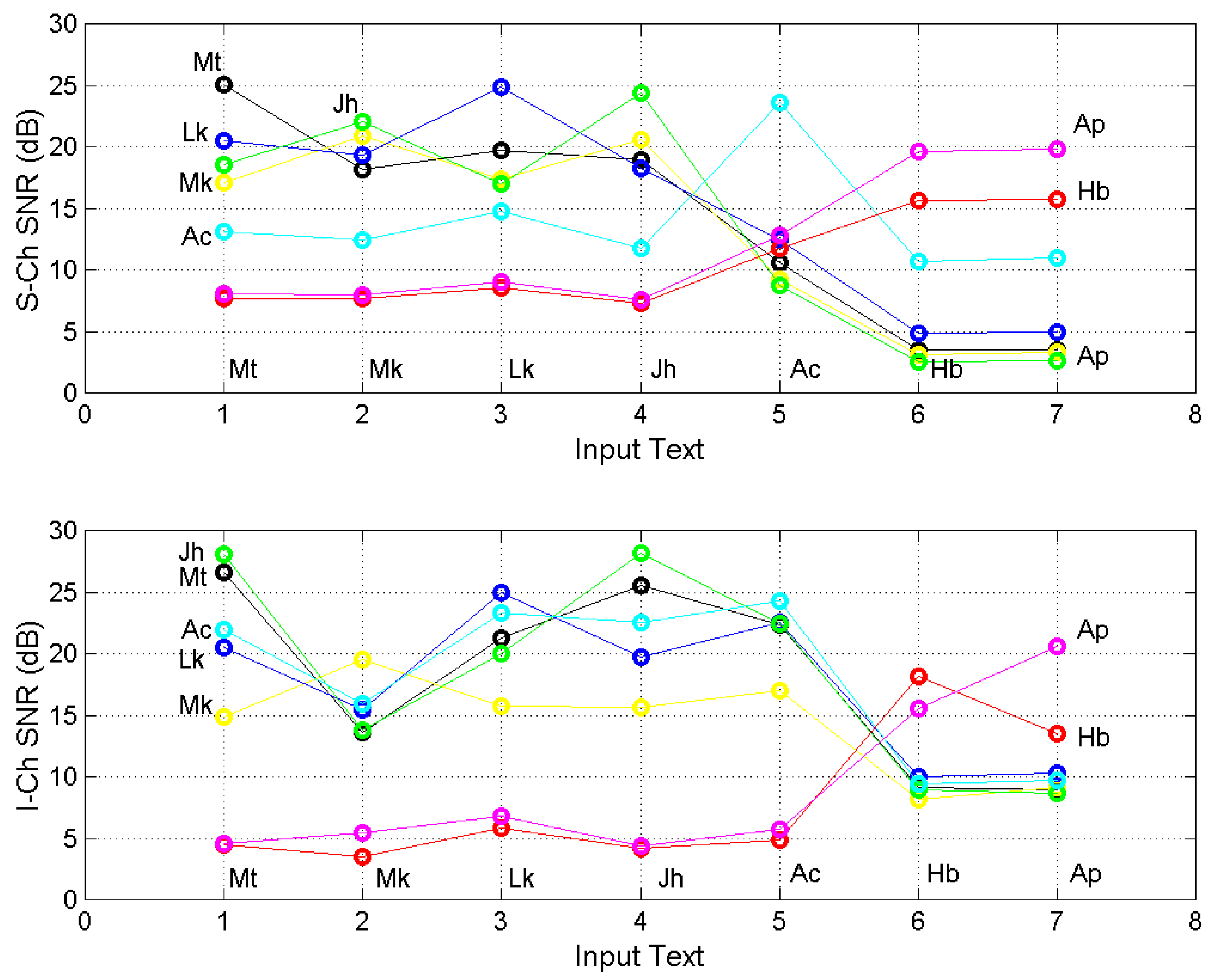
Figure 8.
and
for each NT input texts indicated in abscissa. Upper panel: S-channel; Lower panel: I-channel. Output texts: Matthew, black; Mark, yellow; Luke, blue; John, green; Acts, cyan; Hebrews, red; Apocalypse, magenta. The mean and standard deviation numerical values are reported in
Appendix A. Notice that
.
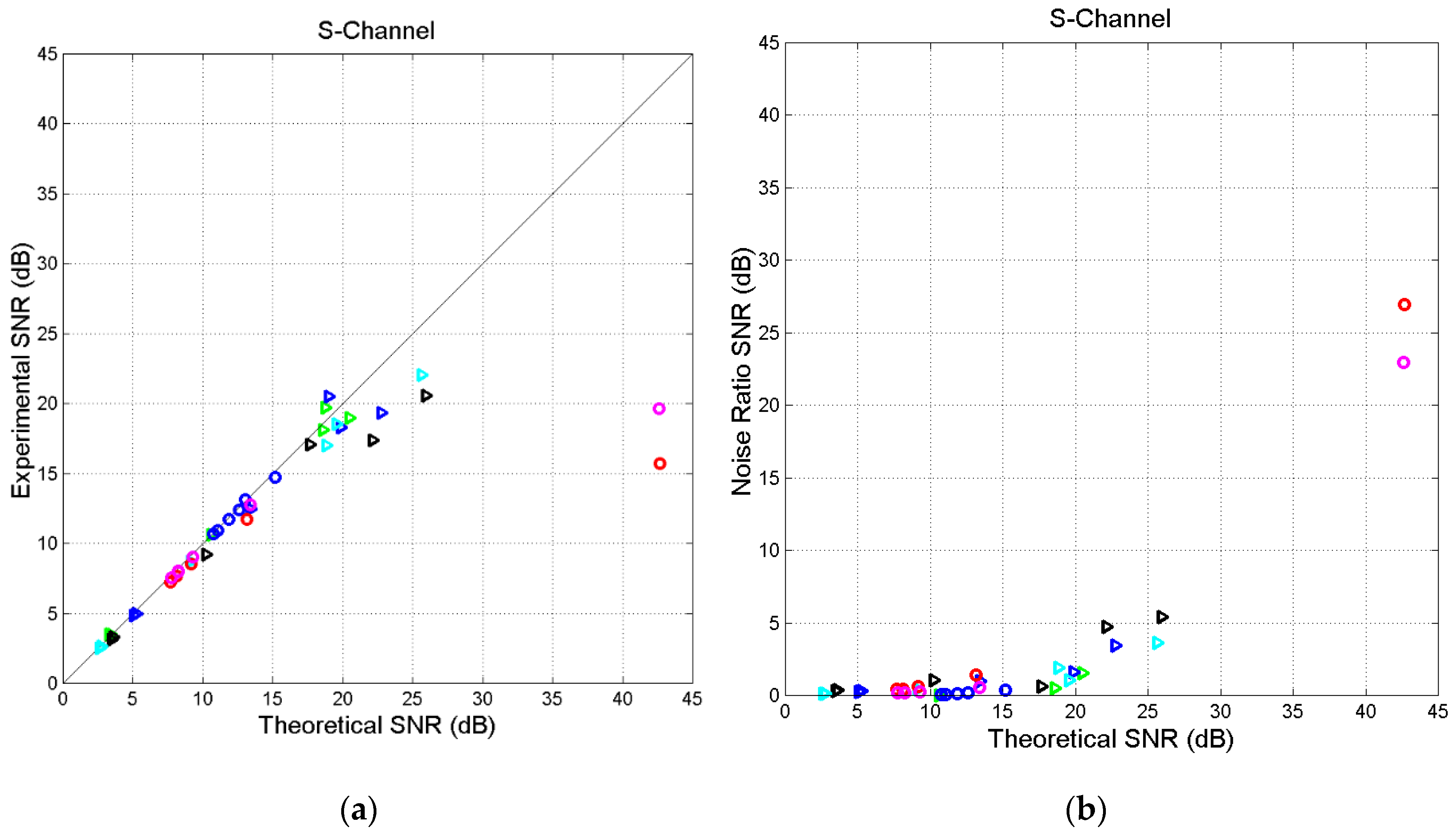
Figure 9.
S-channel. (a) Scatterplot of versus in S-channels. (b) Scatterplot of versus . Matthew (green triangles), Mark (black triangles), Luke (blue triangles), John (cyan triangles), Acts (blue circles), Hebrews (red circles), and Apocalypse (magenta circles).
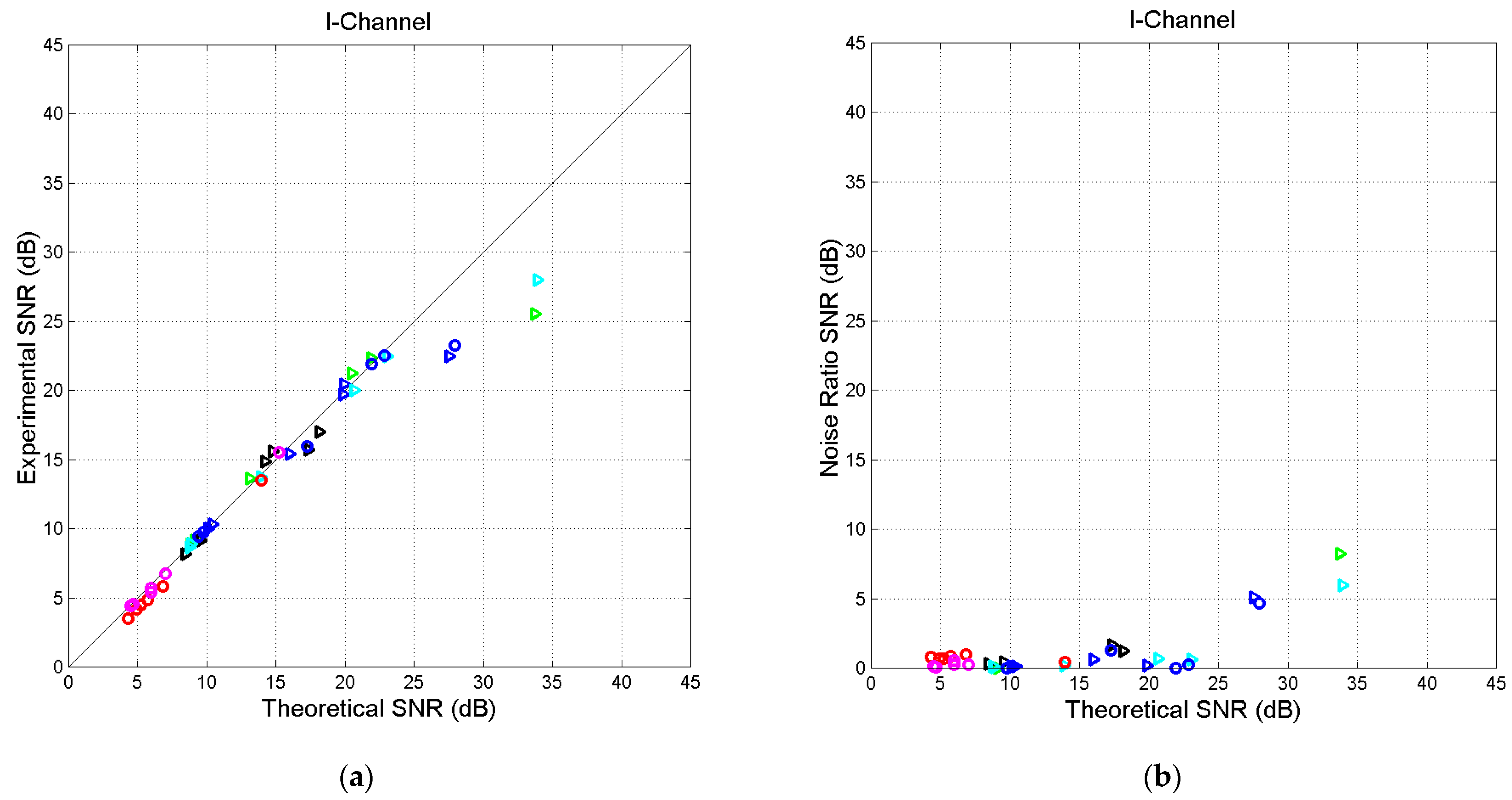
Figure 10.
I-channel. (a) Scatterplot of versus in S-channels. (b) Scatterplot of versus . Matthew (green triangles), Mark (black triangles), Luke (blue triangles), John (cyan triangles), Acts (blue circles), Hebrews (red circles), and Apocalypse (magenta circles).
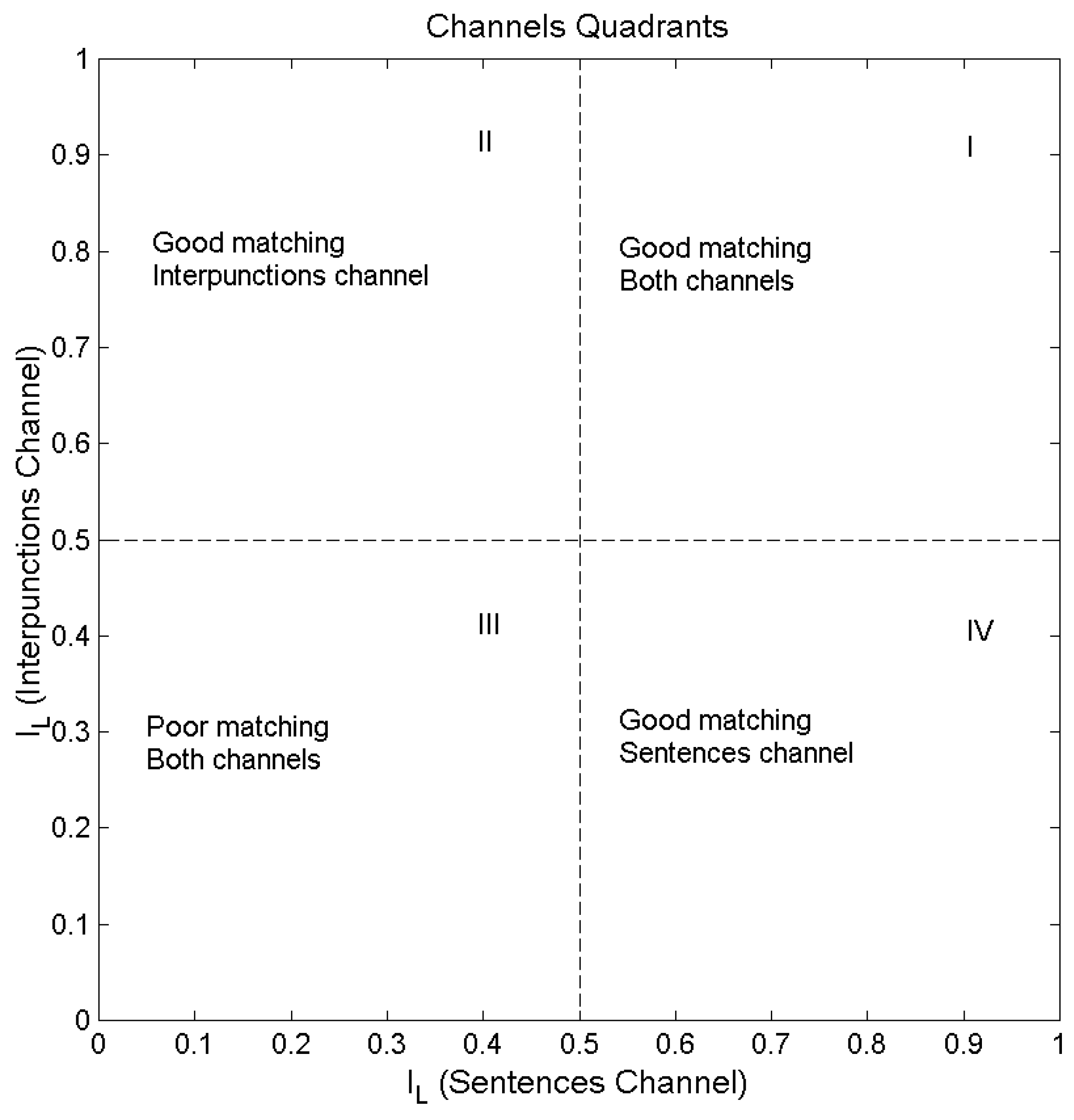
Figure 11.
Matching texts in S-channels and in I-channels.
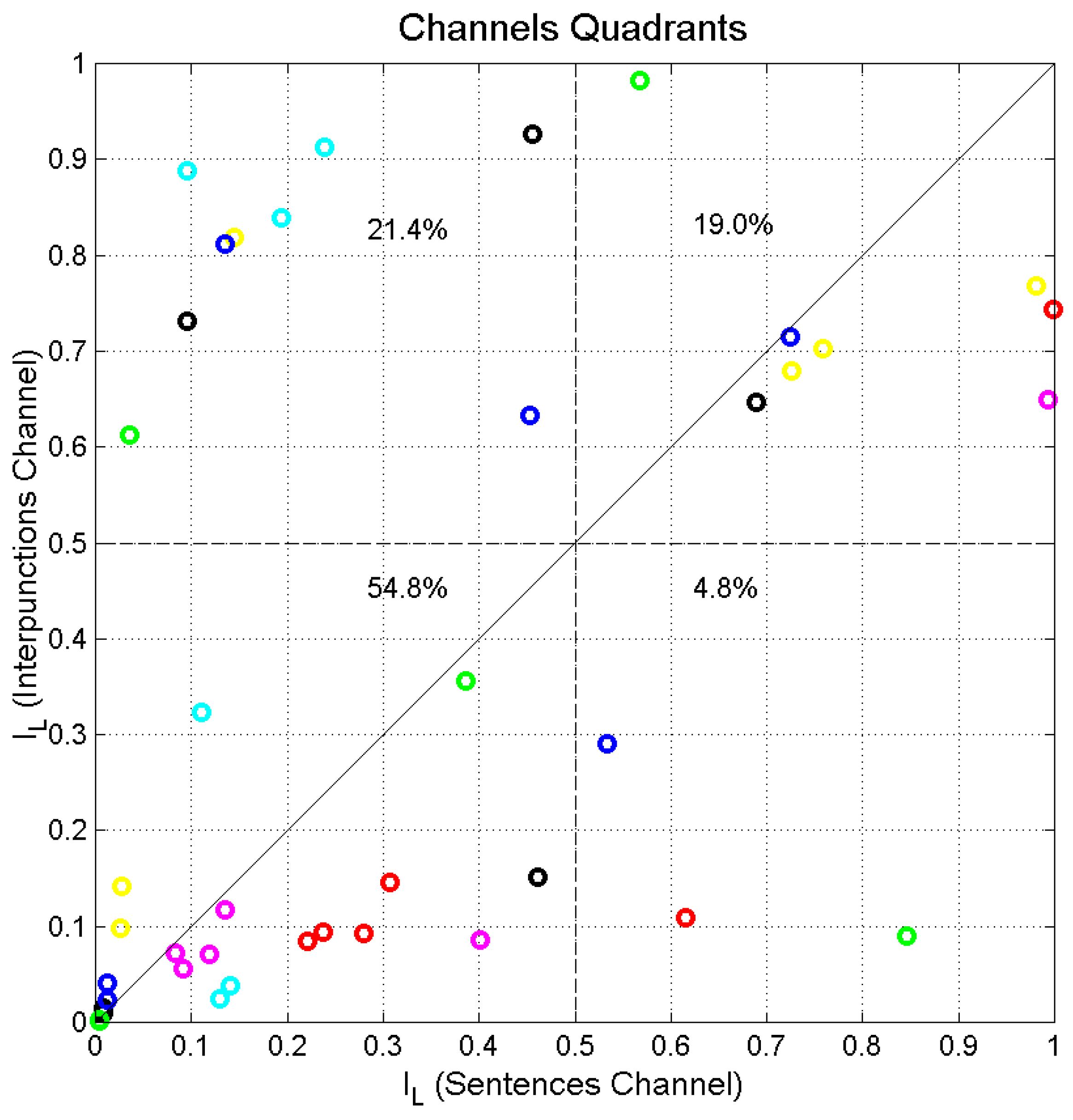
Figure 12.
Scatterplot of
of the interpunctions channel (ordinate scale) versus
of the S-channel (abscissa scale). Output channels (first line in
Table 11 and
Table 12): Matthew, black circles; Mark, yellow; Luke, blue; John, green; Acts, cyan; Hebrews, red; Apocalypse, magenta. The percentages indicate the relative number of cases falling in a quadrant.
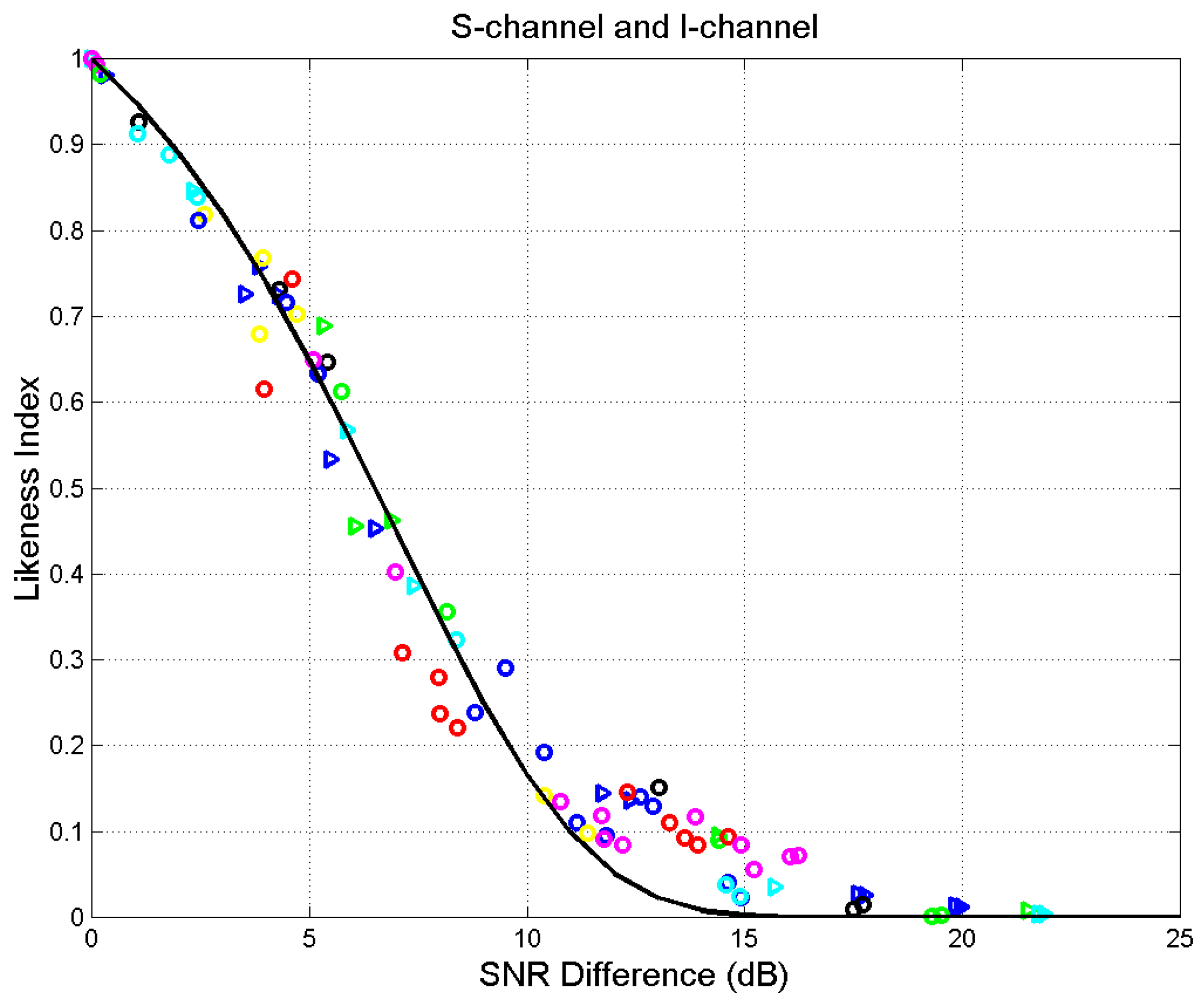
Figure 13.
Scatterplot of of S-channel and I-channel versus . Matthew (green triangles), Mark (black triangles), Luke (blue triangles), John (cyan triangles), Acts (blue circles), Hebrews (red circles), and Apocalypse (magenta circles). The black line draws Equation (15).
Table 1.
New Testament. Mean values (averaged over all chapters) of (characters per word), (words per sentence), (interpunctions per sentence words per interpunctions), and (universal readability index). The genealogies in Matthew (verses 1.1–1.17) and in Luke (verses 3.23–3.38) have been deleted for not biasing the statistical analyses. All parameters have been computed by weighting a chapter with the fraction of total words of the literary text.
| Book | Total Words | | | | | |
|---|
| Matthew | 18,121 | 4.91 | 20.27 | 2.83 | 7.18 | 53.90 |
| Mark | 11,393 | 4.96 | 19.14 | 2.68 | 7.17 | 54.87 |
| Luke | 19,384 | 4.91 | 20.47 | 2.89 | 7.11 | 54.21 |
| John | 15,503 | 4.54 | 18.56 | 2.74 | 6.79 | 57.65 |
| Acts | 18,757 | 5.10 | 25.47 | 2.91 | 8.77 | 41.37 |
| Hebrews | 4940 | 5.33 | 32.00 | 4.53 | 7.02 | 53.10 |
| Apocalypse | 9870 | 4.66 | 30.70 | 3.97 | 7.79 | 49.46 |
Table 2.
Greek literature. Mean values (averaged over all chapters) of (characters per word), (words per sentence), (interpunctions per sentence words per interpunctions, or words interval), and the corresponding (universal readability index). All parameters have been computed by weighting a chapter with the fraction of total words of the literary text.
| Author | Total Words | | | | | |
|---|
| Aesop (620–564 BC, Fables) | 39,122 | 5.24 | 18.29 | 3.46 | 5.28 | 64.95 |
| Polybius (200–118 BC, The Histories) | 256,495 | 5.97 | 29.19 | 3.30 | 8.88 | 37.22 |
| Flavius Josephus (37–100 AD, The Jewish War) | 121,717 | 5.51 | 31.05 | 3.20 | 9.74 | 31.44 |
| Plutarch (46–119 AD, Parallel Lives) | 499,683 | 5.51 | 29.35 | 3.73 | 7.82 | 43.53 |
Table 3.
Slope and the correlation coefficient of the regression lines of versus , and versus in the indicated texts. Four decimal digits are reported because some values differ only from the third digit. These parameters are calculated by uniformly weighing each block text, e.g., weight in Matthew.
| Text | | |
|---|
| | | | | |
|---|
| Matthew | 0.0508 | 0.9410 | 2.7271 | 0.9548 |
| Mark | 0.0538 | 0.8985 | 2.5527 | 0.8800 |
| Luke | 0.0499 | 0.8975 | 2.8296 | 0.9243 |
| John | 0.0549 | 0.9181 | 2.6797 | 0.9517 |
| Acts | 0.0413 | 0.8807 | 2.7192 | 0.9280 |
| Hebrews | 0.0336 | 0.8037 | 4.0970 | 0.9005 |
| Apocalypse | 0.0338 | 0.8063 | 3.7605 | 0.8173 |
Table 4.
Theoretical slope and correlation coefficient of the regression line according to
Section 4, for the indicated input texts. Output channel: Matthew.
| Text | Sentences versus Sentences | Interpunctions versus Interpunctions |
|---|
| | | |
|---|
| Mark | 0.9442 | 0.9940 | 1.0683 | 0.9814 |
| Luke | 1.0180 | 0.9938 | 0.9638 | 0.9960 |
| John | 0.9253 | 0.9981 | 1.0177 | 0.9999 |
| Acts | 1.2300 | 0.9890 | 1.0029 | 0.9968 |
| Hebrews | 1.5119 | 0.9576 | 0.6656 | 0.9891 |
| Apocalypse | 1.5030 | 0.9589 | 0.7252 | 0.9516 |
Table 5.
S-channel. Theoretical signal-to-noise ratio (dB) in the channel between the (input) text indicated in the first column and the (output) text indicated in the first line. For example, if the input is Matthew and the output is Mark, then ; vice versa, if the input is Mark and the output is Matthew, then .
| Text | Matthew | Mark | Luke | John | Acts | Hebrews | Apocalypse |
|---|
| Matthew | | 17.70 | 19.06 | 19.56 | 13.04 | 8.12 | 8.22 |
| Mark | 18.59 | | 22.79 | 25.66 | 12.61 | 8.12 | 8.21 |
| Luke | 18.76 | 22.14 | | 18.87 | 15.14 | 9.14 | 9.26 |
| John | 20.50 | 25.99 | 19.87 | | 11.83 | 7.67 | 7.76 |
| Acts | 10.62 | 10.26 | 13.44 | 9.15 | | 13.13 | 13.36 |
| Hebrews | 3.29 | 3.48 | 5.10 | 2.61 | 10.75 | | 42.61 |
| Apocalypse | 3.46 | 3.64 | 5.29 | 2.77 | 11.04 | 42.68 | |
Table 6.
I-channel. Theoretical signal-to-noise ratio (dB) in the channel between the (input) text indicated in the first column and the (output) text indicated in the first line. For example, if the input is Matthew and the output is Mark, then ; vice versa, if the input is Mark and the output is Matthew, then .
| Text | Matthew | Mark | Luke | John | Acts | Hebrews | Apocalypse |
|---|
| Matthew | | 14.25 | 19.94 | 33.94 | 21.94 | 5.19 | 4.66 |
| Mark | 13.16 | | 16.02 | 13.96 | 17.23 | 4.30 | 5.94 |
| Luke | 20.53 | 17.37 | | 20.70 | 27.93 | 6.82 | 7.02 |
| John | 33.75 | 14.78 | 19.91 | | 22.81 | 4.89 | 4.51 |
| Acts | 21.89 | 18.20 | 27.56 | 23.06 | | 5.73 | 5.96 |
| Hebrews | 9.15 | 8.45 | 10.12 | 8.93 | 9.39 | | 15.25 |
| Apocalypse | 8.85 | 9.60 | 10.45 | 8.80 | 9.75 | 13.92 | |
Table 7.
Theoretical slope and correlation coefficient of the regression line according to
Section 4, for the indicated input texts. Output channel: Hebrews. Notice that five decimal digits are reported for Apocalypse because its value is very close to 1.
| Text | Sentences vs. Sentences | % | Interpunctions vs. Interpunctions |
|---|
| | | | |
|---|
| Matthew | 0.6614 | 0.9576 | | 1.5023 | 0.9891 |
| Mark | 0.6245 | 0.9833 | | 1.6050 | 0.9990 |
| Luke | 0.6733 | 0.9837 | | 1.4479 | 0.9983 |
| John | 0.6120 | 0.9737 | | 1.5289 | 0.9905 |
| Acts | 0.8136 | 0.9897 | | 1.5067 | 0.9977 |
| Apocalypse | 0.9941 | 0.99999 | | 1.0895 | 0.9865 |
Table 8.
Theoretical slope and correlation coefficient of the regression line according to
Section 4, for the indicated input texts. Output channel: Apocalypse. Notice that five decimal digits are reported for Hebrews because its value is very close to 1.
| Text | Sentences vs. Sentences | Interpunctions vs. Interpunctions |
|---|
| | | |
|---|
| Matthew | 0.6654 | 0.9589 | 1.3789 | 0.9516 |
| Mark | 0.6283 | 0.9841 | 1.4731 | 0.9929 |
| Luke | 0.6774 | 0.9845 | 1.3290 | 0.9754 |
| John | 0.6157 | 0.9747 | 1.4033 | 0.9547 |
| Acts | 0.8184 | 0.9903 | 1.3829 | 0.9731 |
| Hebrews | 1.0060 | 0.99999 | 0.9179 | 0.9865 |
Table 9.
Slope
and the correlation coefficient
of the regression lines between
versus
and
versus
for the indicated texts of the Greek literature. The slopes and correlation coefficients have been calculated the same as those reported in
Table 3.
| Author | | |
|---|
| | | |
|---|
| Polybius | 0.0343 | 0.9971 | 3.2432 | 0.9885 |
| Plutarch | 0.0371 | 0.9195 | 3.3539 | 0.9577 |
| Flavius Josephus | 0.0325 | 0.9734 | 3.1891 | 0.9846 |
| Aesop | 0.0545 | 0.9032 | 3.4236 | 0.9302 |
| John | 0.0549 | 0.9181 | 2.6797 | 0.9517 |
Table 10.
S-channel, Greek literature. Theoretical signal-to-noise ratio (dB) in the channel between the (input) text indicated in the first column and the (output) text indicated in the first line. For example, if the input is Polybius and the output is Plutarch, then ; vice versa, if the input is Plutarch and the output is Polybius, then .
| Text | Polybius | Plutarch | Flavius | Aesop | John |
|---|
| Polybius | | 8.48 | 16.08 | 1.42 | 1.78 |
| Plutarch | 9.81 | | 14.12 | 6.51 | 6.38 |
| Flavius Josephus | 15.19 | 12.24 | | 2.30 | 2.47 |
| Aesop | 7.08 | 9.89 | 7.46 | | 28.61 |
| John | 7.28 | 9.78 | 7.51 | 28.74 | |
Table 11.
I-channel, Greek literature. Theoretical signal-to-noise ratio (dB) in the channel between the (input) text indicated in the first column and the (output) text indicated in the first line. For example, if the input is Polybius and the output is Plutarch, then ; vice versa, if the input is Plutarch and the output is Polybius, then .
| Text | Polybius | Plutarch | Flavius | Aesop | John |
|---|
| Polybius | | 16.49 | 30.80 | 12.15 | 13.19 |
| Plutarch | 17.06 | | 18.32 | 21.07 | 13.91 |
| Flavius Josephus | 30.56 | 17.51 | | 12.77 | 14.11 |
| Aesop | 13.07 | 21.42 | 13.94 | | 13.04 |
| John | 10.84 | 11.94 | 12.02 | 10.77 | |
Table 12.
Average value of
in S-channels. For example, in the channels Hebrews
Apocalypse, from
Appendix B, we obtain the average value
. In bold type are the cases in which
.
| | Mt | Mk | Lk | Jh | Ac | Hb | Ap |
|---|
| Mt | 1 | | | | | | |
| Mk | 0.160 | 1 | | | | | |
| Lk | 0.707 | 0.630 | 1 | | | | |
| Jh | 0.511 | 0.914 | 0.419 | 1 | | | |
| Ac | 0.145 | 0.128 | 0.188 | 0.066 | 1 | | |
| Hb | 0.144 | 0.132 | 0.160 | 0.133 | 0.372 | 1 | |
| Ap | 0.063 | 0.059 | 0.074 | 0.044 | 0.271 | 0.996 | 1 |
Table 13.
Average value of in I-channels. In bold type are the cases in which .
| | Mt | Mk | Lk | Jh | Ac | Hb | Ap |
|---|
| Mt | 1 | | | | | | |
| Mk | 0.427 | 1 | | | | | |
| Lk | 0.681 | 0.485 | 1 | | | | |
| Jh | 0.954 | 0.429 | 0.494 | 1 | | | |
| Ac | 0.785 | 0.571 | 0.863 | 0.750 | 1 | | |
| Hb | 0.051 | 0.096 | 0.084 | 0.037 | 0.067 | 1 | |
| Ap | 0.043 | 0.099 | 0.079 | 0.037 | 0.062 | 0.697 | 1 |
Table 14.
Overall total average value of
. For example, in the channels Hebrews
Apocalypse, from
Table 12 and
Table 13 we obtain the average value
. In bold type are the cases in which
.
| | Mt | Mk | Lk | Jh | Ac | Hb | Ap |
|---|
| Mt | 1 | | | | | | |
| Mk | 0.294 | 1 | | | | | |
| Lk | 0.694 | 0.558 | 1 | | | | |
| Jh | 0.733 | 0.674 | 0.457 | 1 | | | |
| Ac | 0.465 | 0.350 | 0.526 | 0.408 | 1 | | |
| Hb | 0.098 | 0.114 | 0.122 | 0.085 | 0.220 | 1 | |
| Ap | 0.053 | 0.079 | 0.077 | 0.041 | 0.167 | 0.847 | 1 |




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}












