1. Introduction
Identifying the author of a computer program is a critical task in digital forensics [
1] and plagiarism detection [
2]. Solutions to this task can be beneficial for litigation related to intellectual property and copyright issues and for various forensic investigations of malicious software.
The existing methods for identifying the author of a computer program can be categorized into three groups: those that analyze the source code [
3,
4,
5,
6,
7], the assembly code of the disassembled program [
8,
9,
10,
11,
12,
13,
14], and universal methods applicable to both cases [
14,
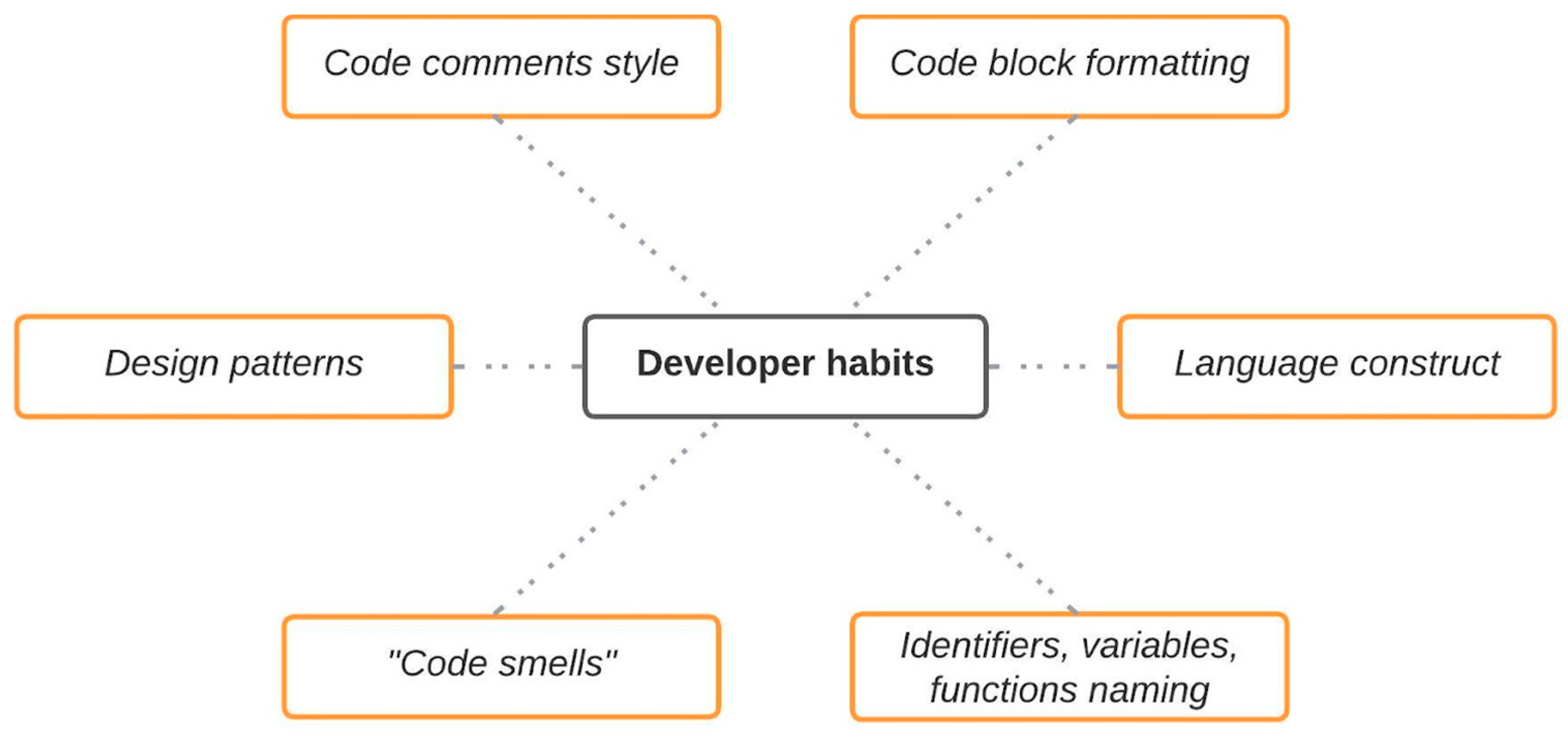
15]. Although these methodologies are based on different algorithms and approaches, all of them share a common principle: each author-programmer has a unique coding style. This style can be identified through the following elements (see
Figure 1):
Figure 1.
Developer habits.
These features belong to the original program source code but are not present in the binary code. However, some of these features remain identifiable even after the program has been compiled and disassembled. As a result, determining authorship based on binary and disassembled code is more methodologically complex and requires modern solutions tailored to this type of analysis.
This study aims to develop a comprehensive solution based on NLP algorithms that enables the precise identification of a program author with high accuracy, utilizing both source and compiled binary codes.
The development of such a methodology requires the utilization of state-of-the-art NLP methods. One actively growing and popular approach is multi-view learning [
17,
18,
19]. Its principle lies in leveraging complementary data sources to provide a comprehensive representation of the research object. However, using this approach as a baseline carries certain risks for the following reasons:
Lack of multiple views. By definition, the multi-view learning process requires multiple distinct and complementary representations to ensure a comprehensive understanding of the research object. However, in the case of the textual representation of source code, additional views that reflect different aspects of the code may be lacking.
Complexity and interpretability. Program code is a highly structured text with numerous complex dependencies. Applying multi-view learning to source code can lead to increased computational complexity and make the interpretation of results more challenging. The machine learning methods used in this research allow for a more controlled process and a simpler interpretation of results.
Limited performance improvement. Multi-view learning can be highly beneficial in domains where different data representations provide additional insights into the research object. However, in the case of program code, such representations may not necessarily lead to improved performance compared to simpler and more interpretable machine learning methods. It is important for us to strike a balance between computational complexity and solution effectiveness.
Binary or disassembled code can be a distinct representation in addition to source code and be used in multi-view learning. This work focuses on the question of whether the use of binary code as a standalone component is possible for this purpose. As an alternative, we propose using an ensemble of classifiers.
The research presents a significant scientific novelty through the introduction of an ensemble of classifiers utilizing Natural Language Processing (NLP) methodologies. This ensemble comprises the author’s hybrid neural network (HNN), SVM equipped with carefully selected feature space, and fastText utilizing experimentally optimized parameters. To the best of our knowledge, these specific approaches have not previously been employed for authorship identification where data are presented as disassembled code. This amalgamation of novel methodologies represents a pioneering contribution to the field.
The paper is organized as follows:
Section 2 focuses on the literature review, including a detailed discussion of the studies aimed at identifying the author of binary programs;
Section 3 provides insights into our previous research concerning program source code authorship, addressing both simple and complex cases; in
Section 4, we expound on the composition and formation of datasets of source and disassembled codes for programs; preliminary experiments conducted to address it are outlined in
Section 5;
Section 6 presents a universal method for identifying program authors based on the findings from the preliminary experiments;
Section 7 focuses on the test cases of the methodology, examining its performance on both source and binary codes; in
Section 8, we present a comprehensive summary of the results obtained and engage in a thorough discussion of the method’s limitations and prospects for future development.
2. Literature Review
An effective system called Binary Authorship Verification with Flow-aware Mixture-of-Shared Language Model (BinMLM) has been developed for determining the authorship of binary codes [
8]. This system utilizes a recurrent neural network (RNN) model that is trained on consecutive opcode traces extracted from the control flow graph (CFG). By combining these methods, unnecessary noise is eliminated, and the unique coding styles of developers can be accurately identified. Additionally, this system proves valuable in situations where limited computing resources are available. The authors conducted tests on disassembled datasets from Google Code Jam (GCJ), Codeforces, and real advanced persistent threat (APT) datasets. For the GCJ dataset, the average Area Under the ROC Curve (AUC-ROC) value was 0.865, with an average precision (AP) of 0.87. For the Codeforces dataset, the AUC-ROC values were 0.85 and 0.86, respectively. These results outperformed the n-gram approach and the method proposed by Caliskan-Islam et al. [
14] by an average of 0.06 for the GCJ dataset and 0.19 for the Codeforces dataset. In addition to its high efficiency, the authors highlight that BinMLM is capable of providing organization-level validation, offering valuable information about the group responsible for an APT attack on software.
The authors of article [
9] solve two related problems in binary code analysis: identifying the author of a program and finding stylistic similarities between programs written by unknown authors. The solution-finding process involves five steps. The first step involves collecting a corpus of programs with known authorship. In the second step, the CFG and instruction sequence are extracted for each binary file. Function template extraction is done using a recursive traversal parser. Among such templates, the authors identify idioms, graphlets, supergraphlets, libcalls, and call graphlets, as well as n-grams. Idioms are small instruction sequences that determine the stylistic features of the disassembled assembly code. Graphlets are subgraphs consisting of three nodes that are part of the CFG. Supergraphlets are adjacent nodes merged into one, and call graphlets are graphlets consisting exclusively of call instruction nodes. Libcalls are the names of imported libraries. In this study, n-grams are considered short byte sequences of length n. In the third step, a subset of functions corresponding to the programmer’s style is selected by calculating mutual information between extracted functions and a specific developer, and then ranking them according to the calculated correlation. The fourth step involves training a Support Vector Machine (SVM) on the labeled corpus. The final step is clustering using the k-means algorithm. To avoid clustering based on the wrong feature, such as program functionality, the information obtained in the fourth step is used. A distance metric was used to transform unlabeled data before clustering, based on the labeled set. To test the approach, the authors used three datasets: GCJ 2009, GCJ 2010, and r CS537 2009. Accuracy was the metric used to evaluate classification performance based on cross-validation. For a combination of 5 function templates for 20 authors, it was 0.77 for GCJ 2009, 0.76 for GCJ 2010, and 0.38 for CS537. For five authors, the accuracy was higher, at 0.94, 0.93, and 0.84, respectively. Adjusted Mutual Information, Normalized Mutual Information, and the Adjusted Rand Index were used to evaluate clustering performance. For the GCJ 2010 dataset, they were 0.6, 0.72, and 0.48, respectively.
The study [
10] focuses on BinGold, a system designed for binary code semantic analysis. The approach involves using dataflow to extract the semantic flow of the registers and semantic components of the control flow graph. These flows and components are then transformed into a new representation called the semantic flow graph (SFG). During binary analysis, many properties related to reflexivity, symmetry, and transitivity of relations are extracted from the SFG. The authors evaluated BinGold on 30 binary applications, including OpenSSL, Pageant, SQLite, and 7z, using precision, recall, and F1 as quality metrics. The metrics were calculated for each application and ranged from 0.66 to 0.9. In addition to similarity estimation, the authors conducted experiments on the GCJ dataset to address two other problems: binary code author identification and cloned component detection in executable files. The F0.5 metric [
11] was 0.8 for the authorship identification task and 0.88 for the cloned component detection task, respectively. The authors argue that their proposed approach is more robust for binary code because the extracted semantic information is less susceptible to easy obfuscation, refactoring, and changes in compilation parameters.
A group of researchers from Princeton University has been working on solving the problem of software author identification for several years. In their previous studies, they focused on de-anonymizing source codes. However, in their recent work [
12], they applied their prior experience to the analysis of binary codes. The authors argue that the most informative features used for source code classification are entirely absent in binary code. Therefore, they propose the utilization of supervised machine learning methods to de-anonymize the authors of binary files. The authors’ experiment consisted of four steps. Initially, they disassembled the binary codes and then decompiled and translated the programs into C-like pseudocode. Subsequently, a fuzzy parser was employed to process the pseudocode, generating abstract syntax trees (ASTs) that contained both syntactic features and n-grams. To reduce dimensionality, the researchers performed a selection process that identified the most informative features from the disassembled and decompiled code using information gain and correlation-based feature selection methods. In the final step, they trained a random forest classifier on the resulting feature vectors. The accuracy of this approach, evaluated using the GCJ dataset, averaged 0.89. The authors emphasize that their method is robust against easy obfuscation techniques, changes in settings and compilation parameters, as well as binary files lacking their character tables.
The article [
13] discusses the issue of performing forensic analysis on binary code files. To simplify reverse engineering in the context of forensic procedures, the authors present a system called the Onion Approach for Binary Authorship Attribution (OBA2). This system is based on three complementary levels: pre-processing, attribution using syntactic features, and attribution using semantic features. To extract meaningful functions, the authors utilize five predefined templates from [
9] idioms, graphlets, supergraphlets, libcalls, and n-grams. These extracted features are then ranked according to their correlation with specific candidate authors and passed to the first level, known as the Stuttering Layer. At this level, a sequence of actions is proposed to identify user-defined functions and eliminate library code. These actions include binary disassembly, application of startup signatures, matching of entry points, compiler identification, accessibility of library signatures, creation of hashing-based patterns, marking of matched functions, and code filtration. The result of the first layer is the creation of function signatures for common libraries, which are essential for extracting user-defined functions. The next level is the Code Analysis Layer, where a combination of algorithms is employed to create an author’s syntactic profile for each candidate author. These author profiles can later be utilized for clustering and classification tasks. The final level is the Register Flow Analysis Layer, which forms a binary code model called a register flow graph. This model captures programming style by analyzing the significant semantic aspects of the code and acts as an abstract intermediate representation between the source and assembly code of the program. The evaluation of the system was performed on the GCJ 2009 and GCJ 2010 datasets. The system achieved an accuracy of 0.93 for three program authors, 0.9 for five authors, and 0.82 for seven authors.
The study [
15] presents an overview of current research in the field of program authorship attribution, focusing on both source code and binary code analysis. The authors aim to compile a comprehensive list of features and characteristics that are potentially relevant to attributing malware authorship. Based on their analysis, the authors identify several informative attributes for source code programs. These include linguistic features, such as the style and vocabulary used, as well as the presence of specific bugs and vulnerabilities. Other significant attributes encompass formatting, specific execution paths, and the AST, CFG, and Program Dependence Graph (PDG) representations of the code. When it comes to binary codes, the authors emphasize additional key features. Firstly, there is the compiler and system information, which can be inferred from unique instruction sequences or system-specific function calls. Furthermore, it is possible to gain insight into the programming language in which the program was written. Overall, the study sheds light on the diverse range of features that can be leveraged for program authorship attribution, both in the context of source code and binary code analysis. This is achieved through support subroutines and library calls preserved in the binary code. Secondly, it involves the opcode sequences, which represent specific actions dictated by assembly instructions such as imul, lea, jmp, and others. Thirdly, it includes strings, which are null-terminated American National Standards Institute (ANSI) strings, constant types used in calculations, and their values serving as offsets. Some informative features were examined in the aforementioned [
9] study, including idioms, graphlets, and n-grams. In addition to these characteristics, system calls and errors are also significant. Within the experiment, three datasets were used: GitHub, GCJ, and Malware. The source codes were compiled with different settings using GNU Compiler Collection (GCC), Xcode, and Intel C++ Compiler (ICC). After disassembling the binary codes with Interactive DisAssembler (IDA), specific features and functions were extracted for subsequent ranking. Finally, the features with the highest ranks were used to evaluate the approaches presented in [
12,
13,
14]. The approaches trained on informative features for 10 authors demonstrated the following accuracies: [
12]—0.84, [
9]—0.8, and [
14]—0.89. Although the last approach proved to be the most effective, it exhibited the fastest decline in accuracy when the number of authors for classification increased. The approach in [
12] was the most robust to changes in the number of authors.
It is worth noting that none of the previously discussed studies conducted additional experiments on method attacks. In software development, some programmers, particularly those involved in malware development, actively seek to protect their anonymity and employ de-anonymization tools. These tools can significantly undermine the accuracy of existing methodologies for determining program authorship. For instance, in [
20], the authors focus on transforming a test binary to preserve the original functionality while inducing misprediction. The article highlights the inherent risks associated with attacks on binary code, where even a single-bit alteration can render the file invalid, lead to runtime failures, or lead to the loss of original functionality. The study explores two types of attacks on binary code: untargeted attacks, causing misprediction towards any incorrect author, and targeted attacks, causing misprediction towards a specific one among the incorrect authors. Researchers identify two primary avenues for attacks: modification of the feature vector and modification of the input binary itself. The authors’ non-targeted attack achieved an average success rate of 0.96, indicating the effectiveness of obfuscating the authors’ style. The targeted attack had a success rate of 0.46, highlighting the complexity and potential for manipulating the programming style of a specific author. In summary, the study’s findings reveal that binary code authorship identification methods relying on code functions are susceptible to authorship attacks due to their vulnerability to modification.
Preventing attacks on methods is not the only aspect that researchers developing source code authorship identification solutions should consider.
Table 1 shows the main advantages and disadvantages of each of the proposed approaches. It takes into account the most important aspects: First, the effectiveness of the approach for identifying the author-virus writer as the target application scenario. Second, robustness to noise in data, that is, the ability to ignore uninformative and/or downgrade the effectiveness of the author’s approach. Third, resistance to obfuscation, one of the most popular methods of attack. Fourth, applicability to both binary and source code, that is, the universality of the approach and the ability to determine authorship based on both the source and binary code of the program.
There were several conclusions drawn from the analysis conducted:
The majority of the features utilized predominantly describe the functionality of the program rather than the author’s style.
The feature space needs to be filtered based on the informativeness of each individual feature.
The effectiveness of the approaches depends on the specific domain. The features used may be characteristic of a particular domain, such as programs written for developer competitions or malicious software.
Feature source importance. The authors employ various decompilation tools that have different functionalities and settings. This variation can have a negative impact on the classification results.
Misleading features. The experimental results indicate that highly ranked informative features are often not informative and are not related to the author’s style. The most common reason for this issue is that the highest scores in mutual information calculations are assigned to code fragments automatically generated by the compiler rather than genuine authorship-related features.
Attacks on authorship attribution methods have the potential to significantly decrease the effectiveness of modern methodologies, as they are not robust against obfuscation and de-anonymization tools. These attacks can undermine the reliability and robustness of the program authorship identification process.
3. Our Previous Research
We examined both simple [
21] and complex cases [
22,
23] when addressing the task of determining the author of a source code. Simple cases encompassed scenarios where the authorship determination involved straightforward source codes containing explicit authorship features. On the other hand, complex cases involved analyzing obfuscated code, code that met coding standards, short commits, mixed training datasets, and artificially generated code.
As part of the study [
21], a series of experiments were conducted to analyze source codes written in the eight most popular programming languages. These codes were written by developers with varying levels of qualification and experience, ranging from engineering students to professionals with extensive corporate development backgrounds.
In the experiments, both SVM and the author’s HNN were considered classifiers. The feature set for SVM included lexical characteristics (such as loop nesting depth, average string length, average function parameter count, etc.), structural characteristics (such as the ratio of whitespace to non-whitespace characters, the ratio of empty lines to code length, the ratio of spaces to code length, etc.), and “code smells” (such as the average number of parameters in class methods, average lines of code in methods, comment length, etc.).
The fast correlation filter (FCF) was employed to filter out uninformative attributes. Its effectiveness compared to other feature selection methods has also been determined in previous studies [
21,
22,
23]. This filter utilized a symmetric uncertainty measure to identify dependencies between features and form a subset of informative features. By using the fast correlation filter, only features that are informative for the specific case are included in the training set. This subset of informative features can account for 10% or more of the original feature set. As a result, we eliminate noise in the training data and enhance the discriminative power of the classifiers being used. The parameters of the SVM were determined based on previous work conducted on related topics [
24].
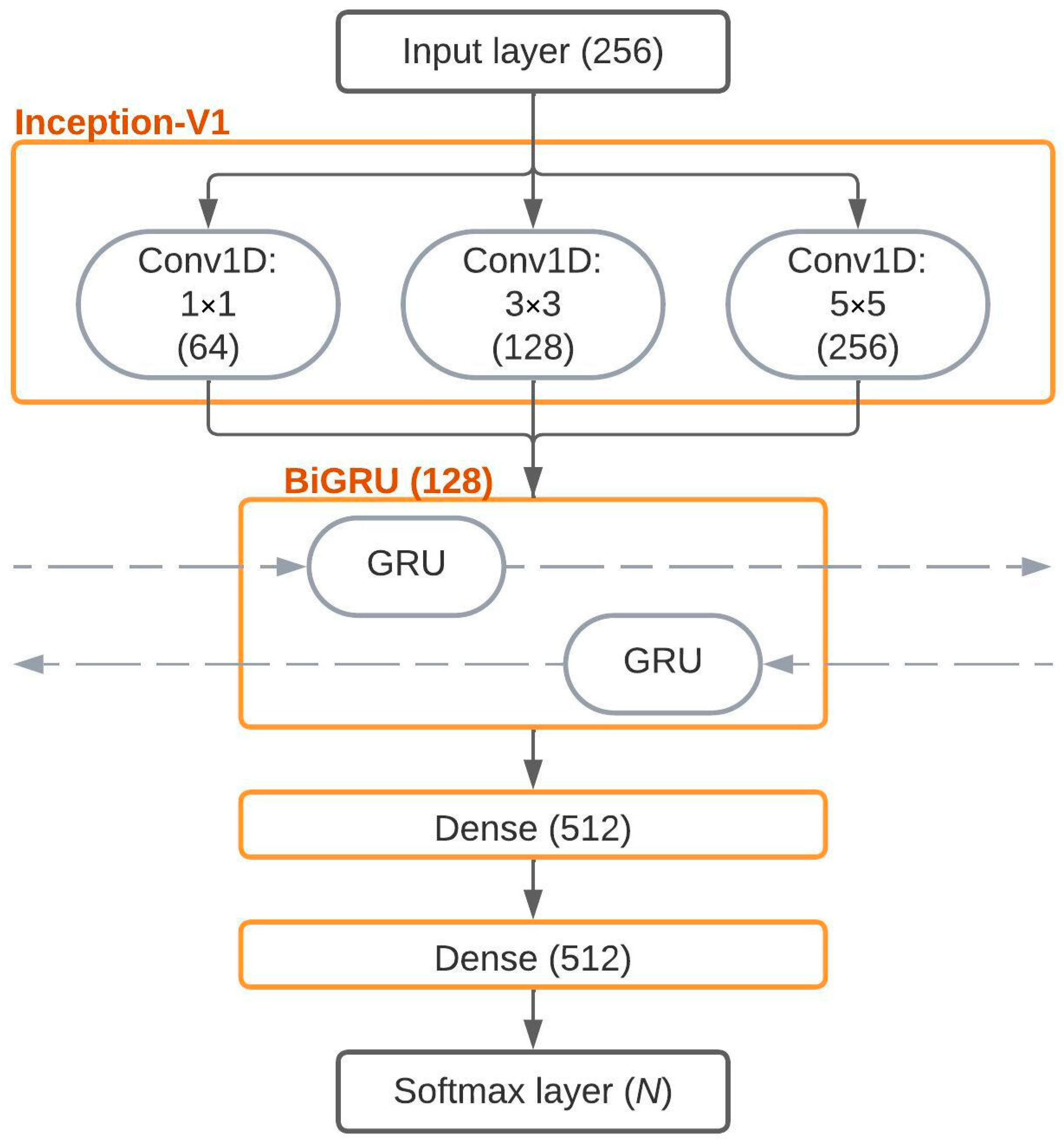
The advantage of HNN (
Figure 2) over SVM lies in its ability to independently extract informative features. The source code was transformed using the one-hot encoding method, creating a vector of 255 zeros and a single one positioned according to the American standard code for information interchange (ASCII) code of the character. This vector was then fed as input into the neural network. The neural network architecture consisted of convolutional, recurrent, and dense layers. The convolutional part employed Inception-v1 with filters of different dimensions (Conv1 × 1, 3 × 3, and 5 × 5) to capture both local and global distinctive characteristics. The recurrent component, represented by a bidirectional gated recurrent unit (BiGRU), captured short-term and long-term temporal dependencies. The dense layers were responsible for scaling the network. Finally, the output layer, which utilized the Softmax function, transformed the logits obtained from the dense layers into a probability distribution based on the number of classes (authors), N. The experimental results demonstrated that, on average across programming languages, HNN outperformed SVM by 5%. HNN achieved an accuracy of 97% in certain cases, while SVM achieved 96% accuracy.
The focus of our previous study [
22] revolved around two complex scenarios: obfuscated source codes and codes written according to coding standards. The author’s HNN was employed to determine the authorship of the source code. Initial experiments revealed a significant decrease in accuracy; however, modifying certain parameters proved effective in making the classifier suitable even for complex cases. By employing updated parameters and expanding the training dataset, HNN exhibited high accuracy in both scenarios. The loss in identification accuracy for obfuscated source codes was found to be below 10%, with an average accuracy of 85%. Similarly, an average accuracy of 85% was achieved when the source code was written according to coding standards.
Other complex cases (mixed datasets, artificially generated source codes, and codes developed collaboratively) were examined in [
23]. Classifiers such as the author’s HNN, fastText, and Bidirectional Encoder Representations from Transformers (BERT) were evaluated for their effectiveness. Among these, the author’s HNN demonstrated the highest performance with an equivalent amount of data. For mixed datasets consisting of two languages, the accuracy was 87%. In the case of datasets involving three or more languages, the accuracy remained at 76%. In scenarios where author identification was conducted based on commits in team-based development, the average accuracy ranged from 87% to 96%, depending on the volume of training data. Finally, for data generated by pre-trained Generative Pretrained Transformer (GPT) models on the source code, the average accuracy was 94%.
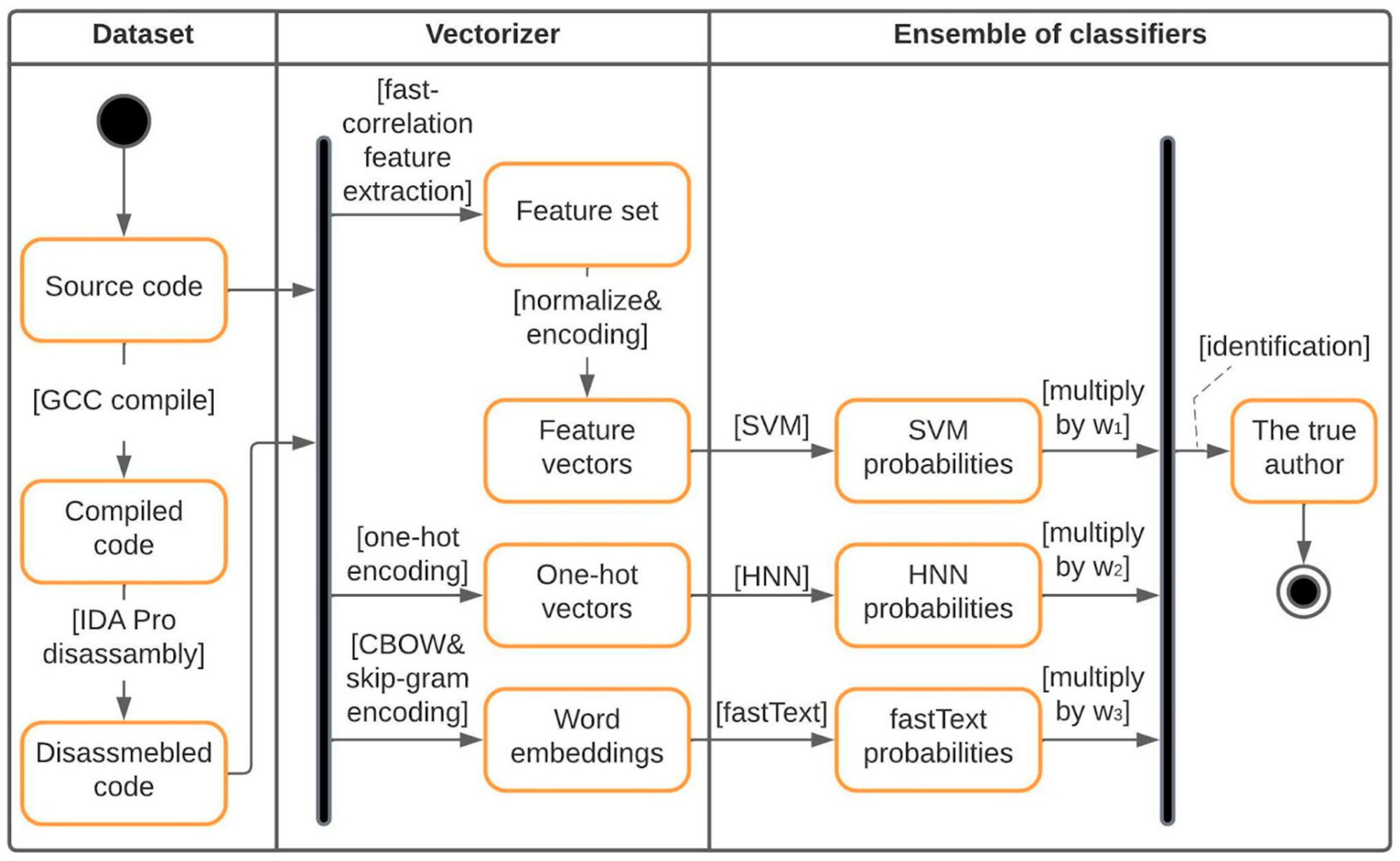
Based on the obtained experience, for the universal methodology of program author identification based on both its source and binary codes, three machine learning models are proposed:
Since disassembled code is significantly longer than the corresponding source code implementing the same program, BERT would require unreasonably high computational and time resources. Therefore, it is not considered within the scope of this research.
5. Experimental Setup
In order to establish an efficient and universally applicable methodology, it is essential to conduct preliminary experiments using individual classifiers. These experiments are designed to assess the accuracy of the selected models, namely HNN, SVM, and fastText. By evaluating the performance of each classifier, we can determine their effectiveness in identifying the author of a program with high accuracy.
In our study, we utilized K-fold cross-validation and compared our results with other works and our own previous experiments [
21,
23,
24], ensuring objectivity and comprehensive evaluation. While we acknowledge the importance of leave-one-user-out (LOUO) and other cross-validation techniques, we believe that K-fold cross-validation was a suitable choice for our research objectives, providing reliable and meaningful results. This approach ensures an objective evaluation and addresses the issue of excessive variability in estimates. Accuracy is used as a quality metric:
where
TP—true positive,
TN—true negative,
FP—false positive, and
FN—false negative.
These parameters are calculated based on the confusion matrix, which stores information about the right and wrong decisions made by the model for each class.
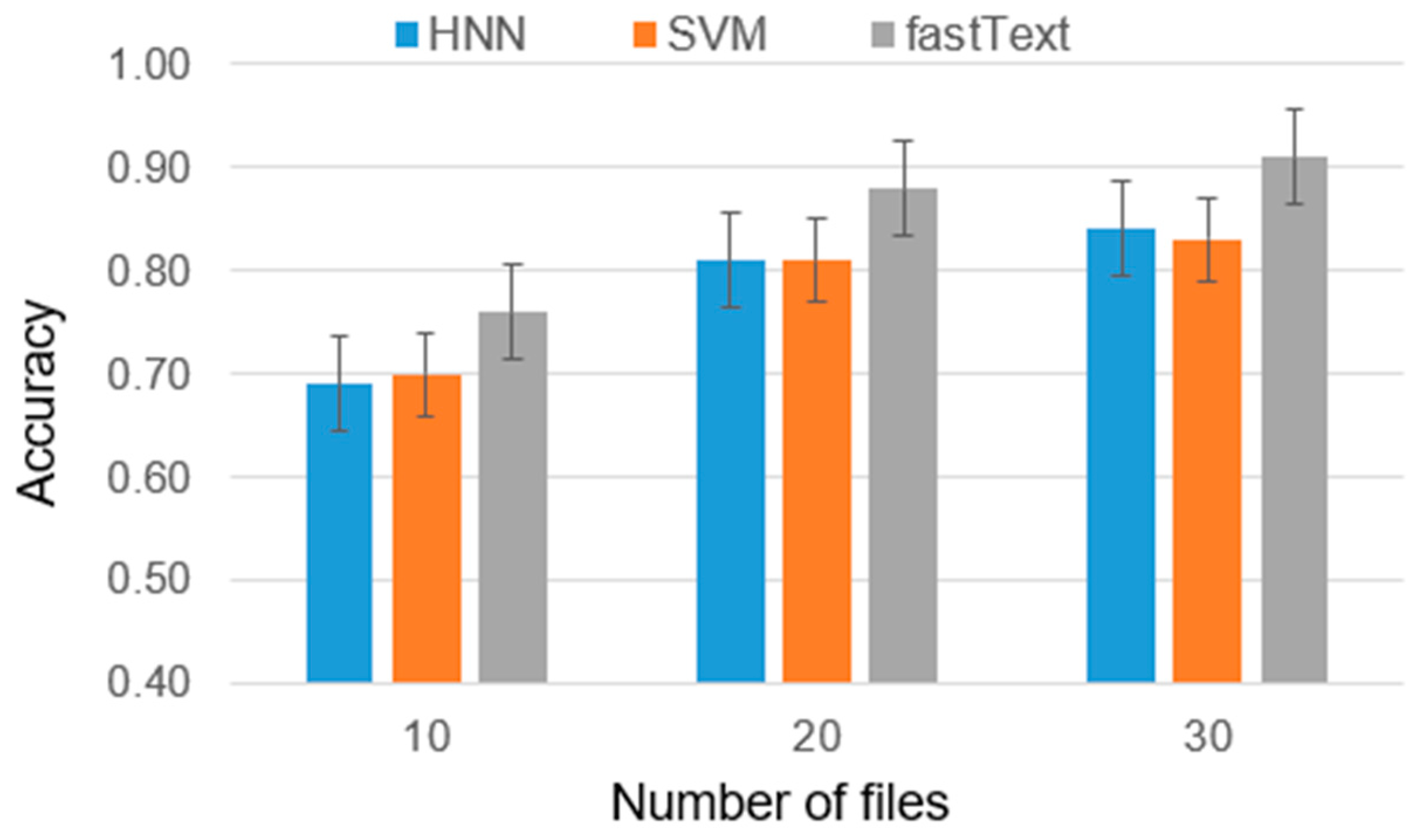
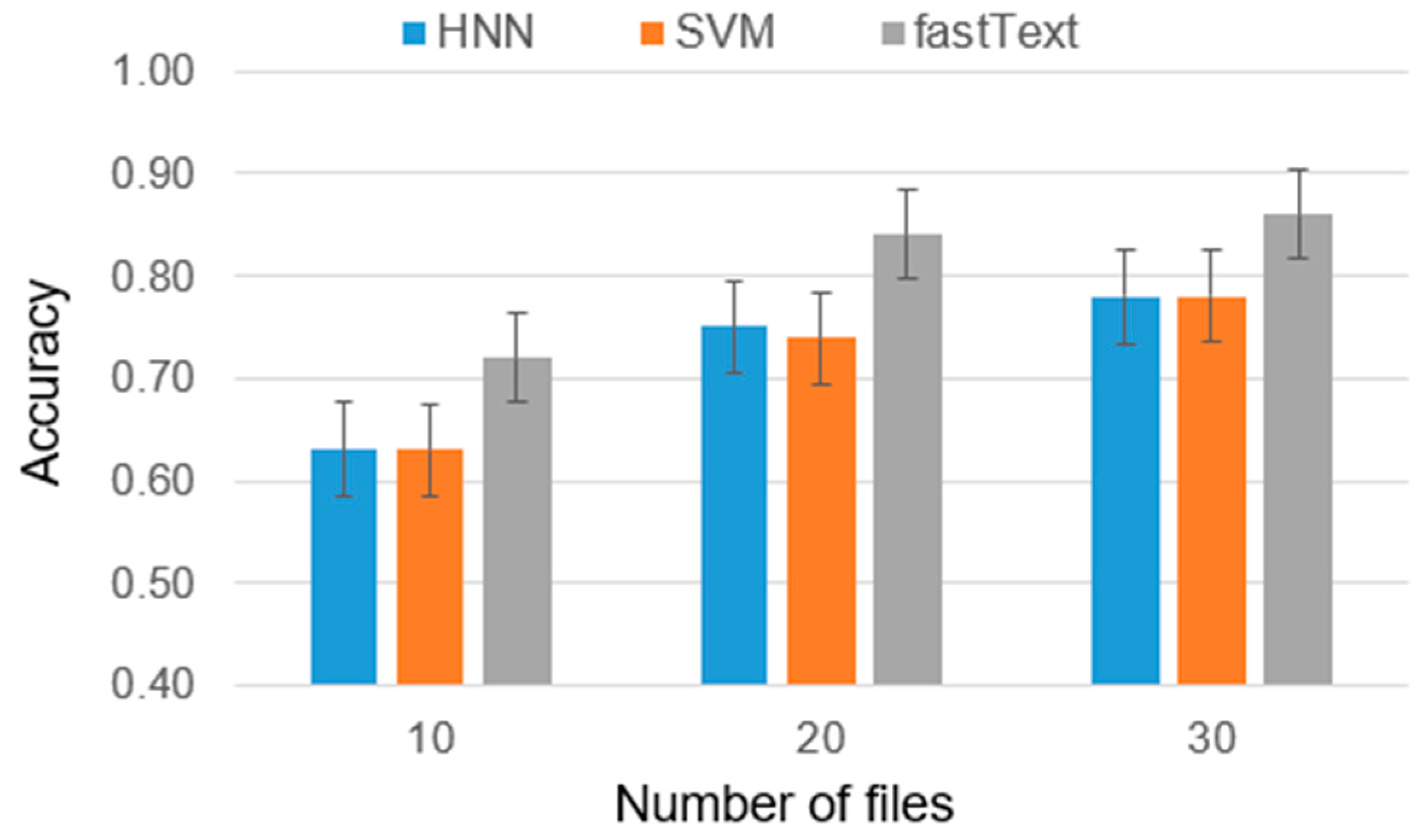
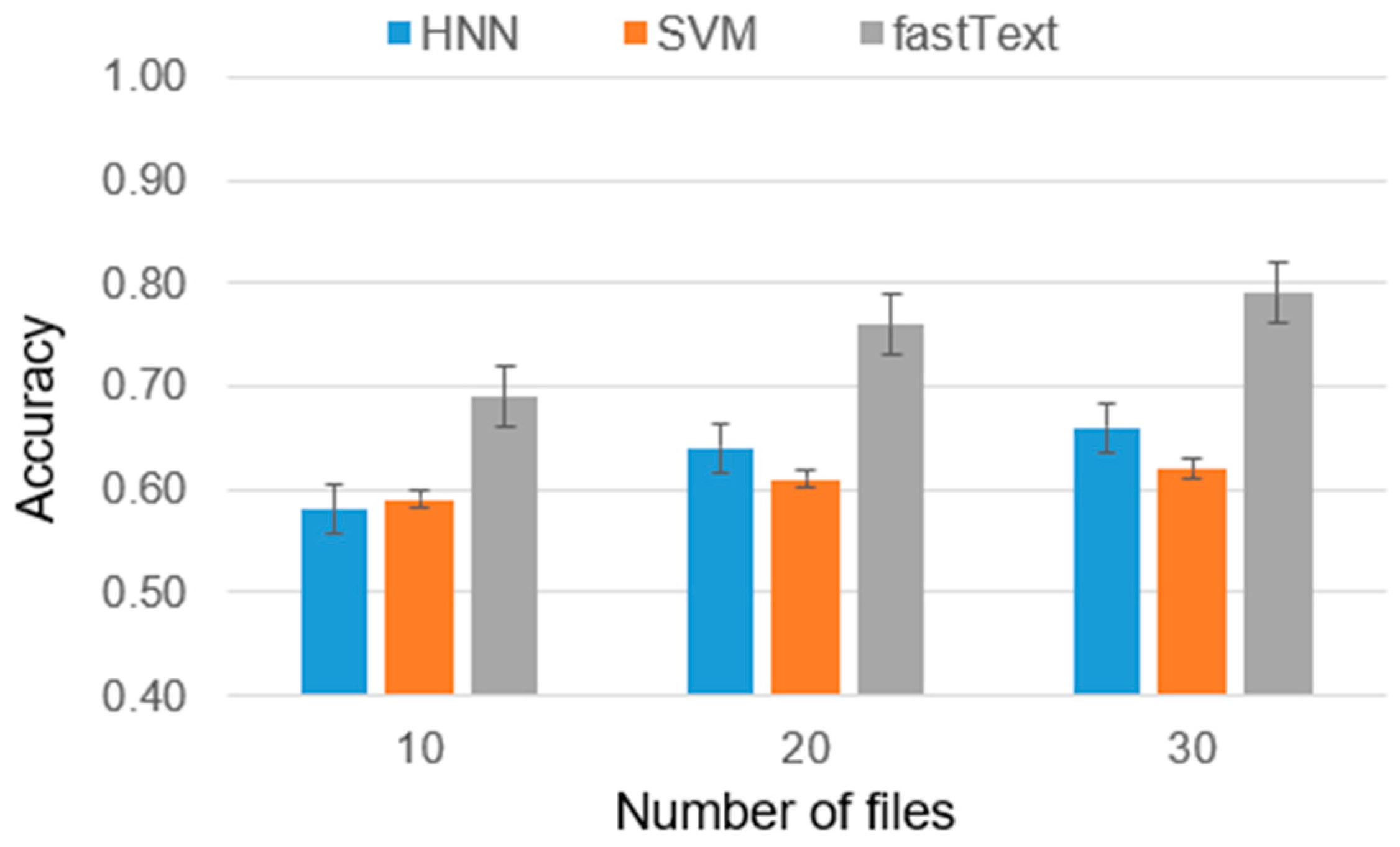
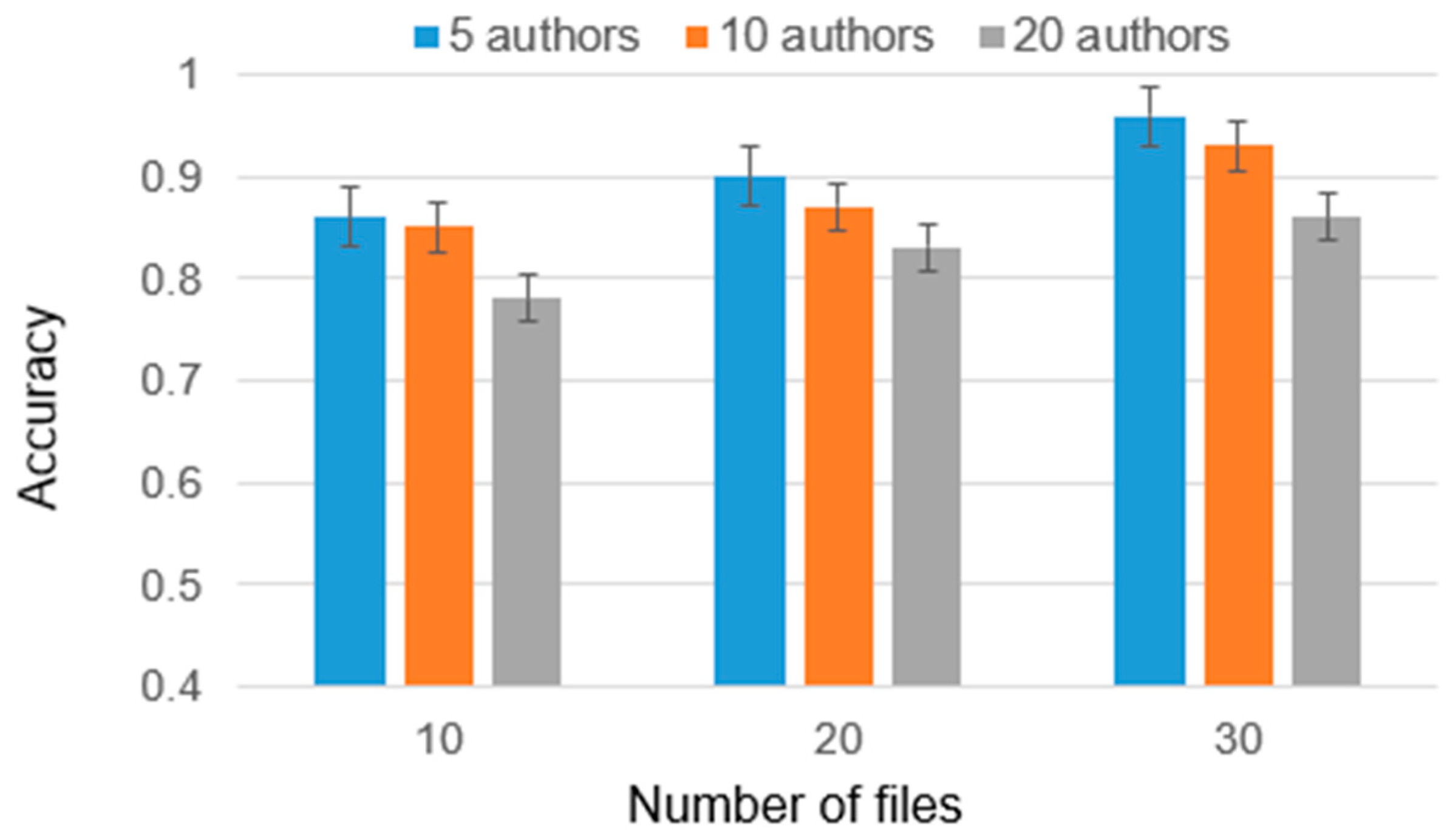
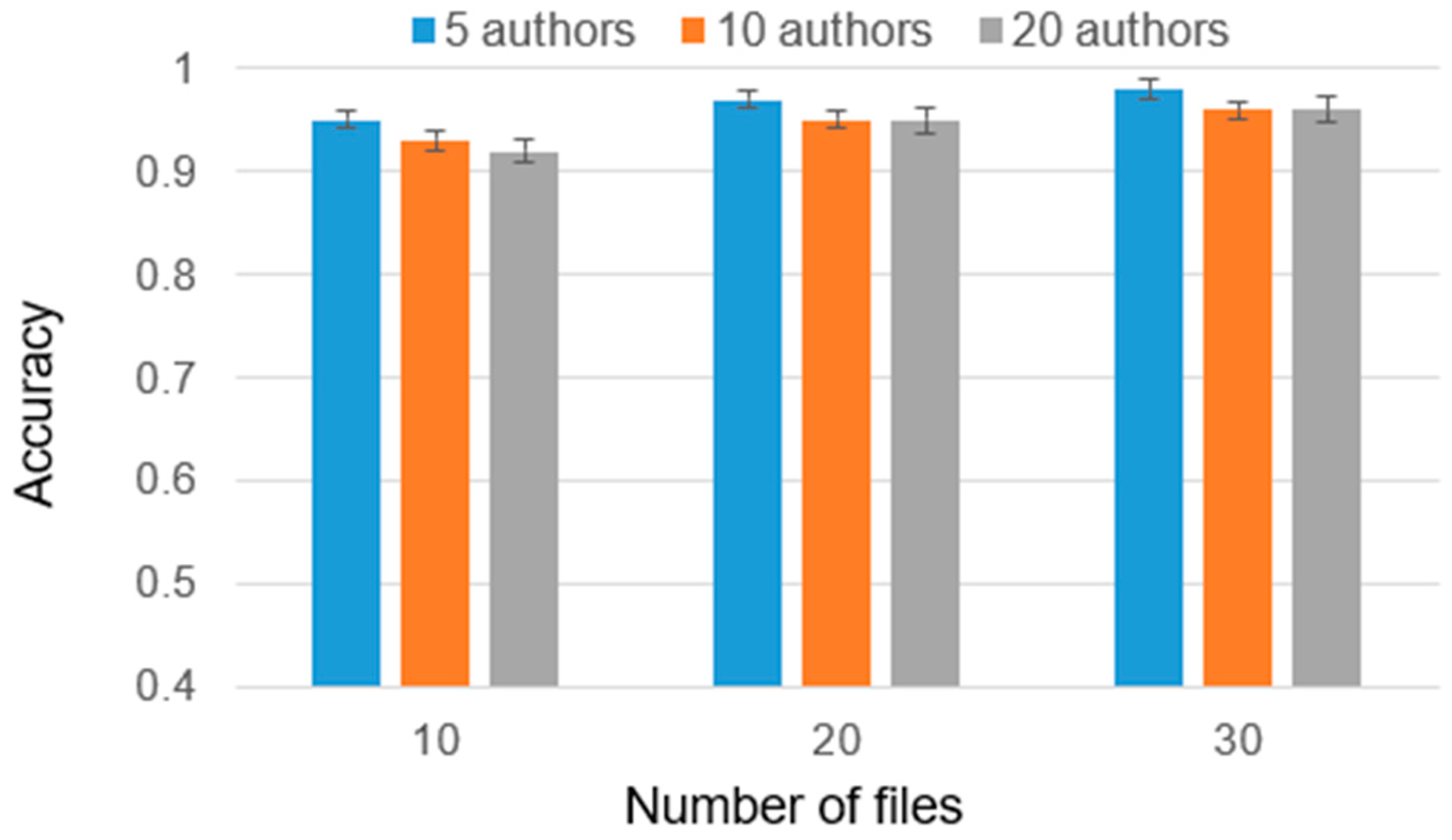
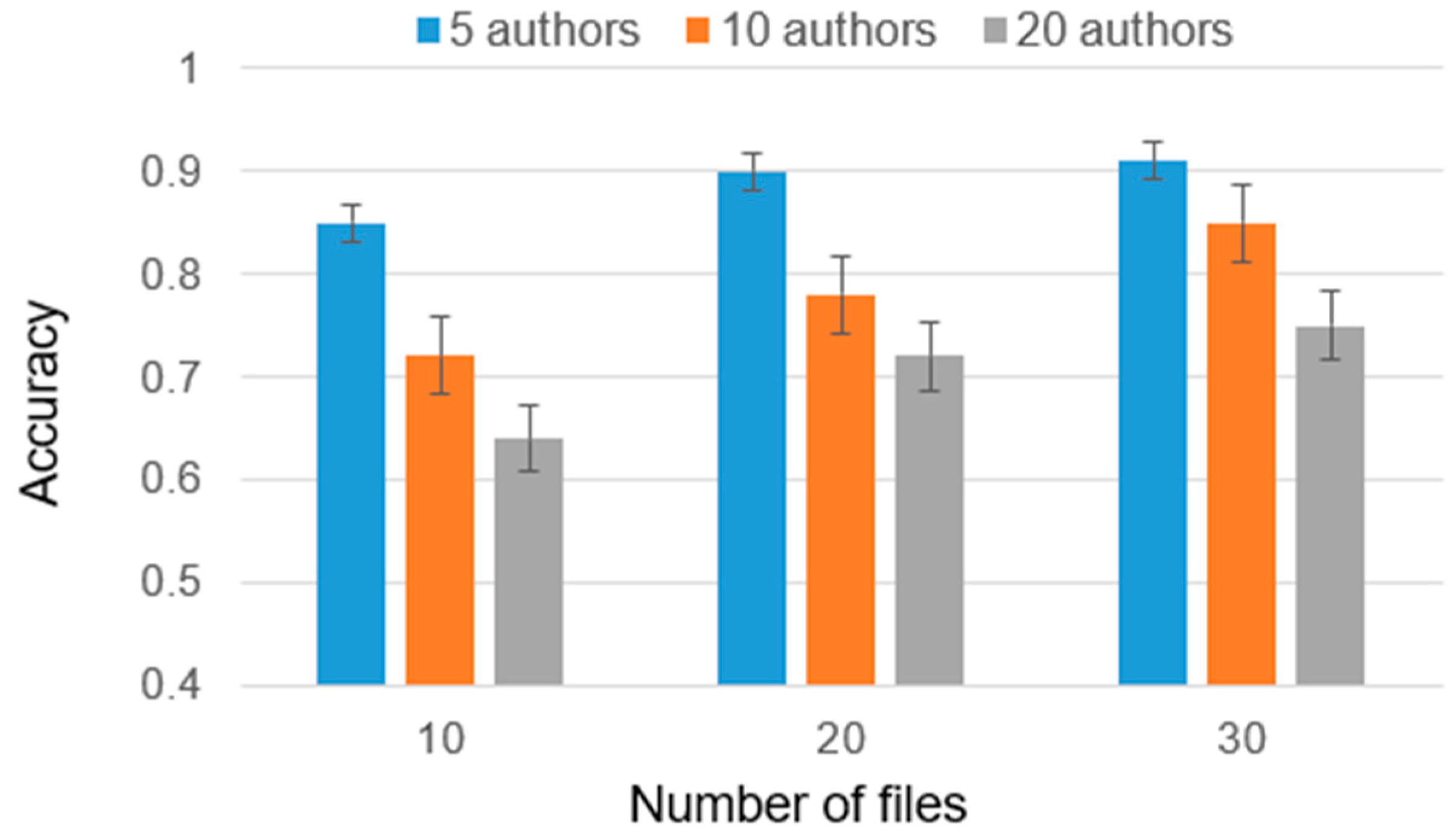
As part of the experiment, cases were considered with 2, 5, and 10 candidate authors, and the number of training files ranged from 10 to 30. The reason for this choice is that analyzing less than 10 files is insufficient for high-accuracy authorship identification and analyzing authors with more than 30 files requires significantly greater computational power due to the larger volume of data involved. Furthermore, it is worth noting that the majority of individuals typically do not possess more than 30 files. Considering these factors, we have chosen to present results only for authors within a range of 10 to 30 files (
Figure 4). This range strikes a balance between obtaining a sufficiently representative sample size and managing computational requirements. The results are presented in
Figure 5,
Figure 6 and
Figure 7.
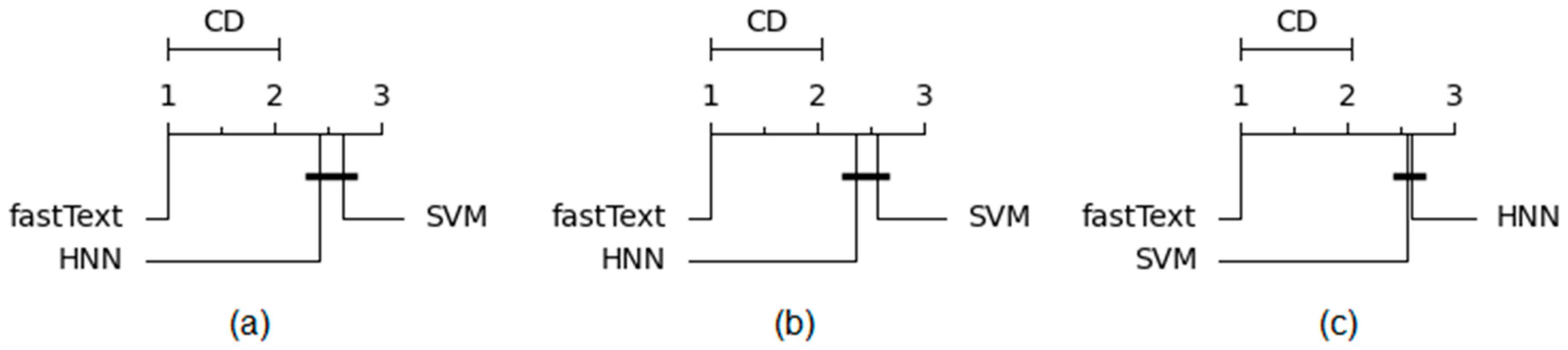
In order to determine the statistical significance of the obtained results, Non-parametric Friedman and Némenyi post hoc tests were employed. We formulated the null hypothesis, stating that the differences in accuracy between fastText, HNN, and SVM are random, and the alternative hypothesis, suggesting the statistical significance of the obtained results. To calculate the
p-value for the Friedman statistical test [
29], the results of the 10-fold cross-validation were used for 2, 5, and 10 authors with 30 files. The
p-value for 2 authors was 0.0000549; for 5 authors, it was 0.0000914; and for 10 authors, it was 0.0000934. In none of the cases did the
p-value exceed the threshold of 0.05, thus leading to the acceptance of the alternative hypothesis, indicating that the differences in model accuracy are significant and not random. Némenyi’s post hoc test [
30] was utilized to assess the differences between the models. The graphical interpretation of the Demshar plot is presented in
Figure 8, where subfigure (a) demonstrates the results for 2 authors, subfigure (b) for 5 authors, and subfigure (c) for 10 authors, respectively.
The results obtained can be interpreted as follows: in the case of two authors, the difference between the average ranks of HNN and SVM is smaller than the critical difference (CD), indicating that the difference in the effectiveness of these models is insignificant. Furthermore, both models were significantly outperformed by fastText in terms of ranks. For five and ten authors, the results were similar, with the difference in effectiveness between HNN and SVM becoming nearly negligible.
Based on the final results of the experiments and tests, it can be concluded that fastText is particularly effective in identifying the author of the disassembled program code. With a sufficient number of codes per author, the accuracy of fastText reaches 0.91. It is important to note that in earlier studies on identifying the author of the source code of a program, fastText showed lower efficiency compared to HNN, with an average difference in accuracy of 5%. However, the combined use of these models as an ensemble of classifiers can provide a universal solution for determining program authorship.
7. Testing of the Methodology for Identifying the Author of the Program
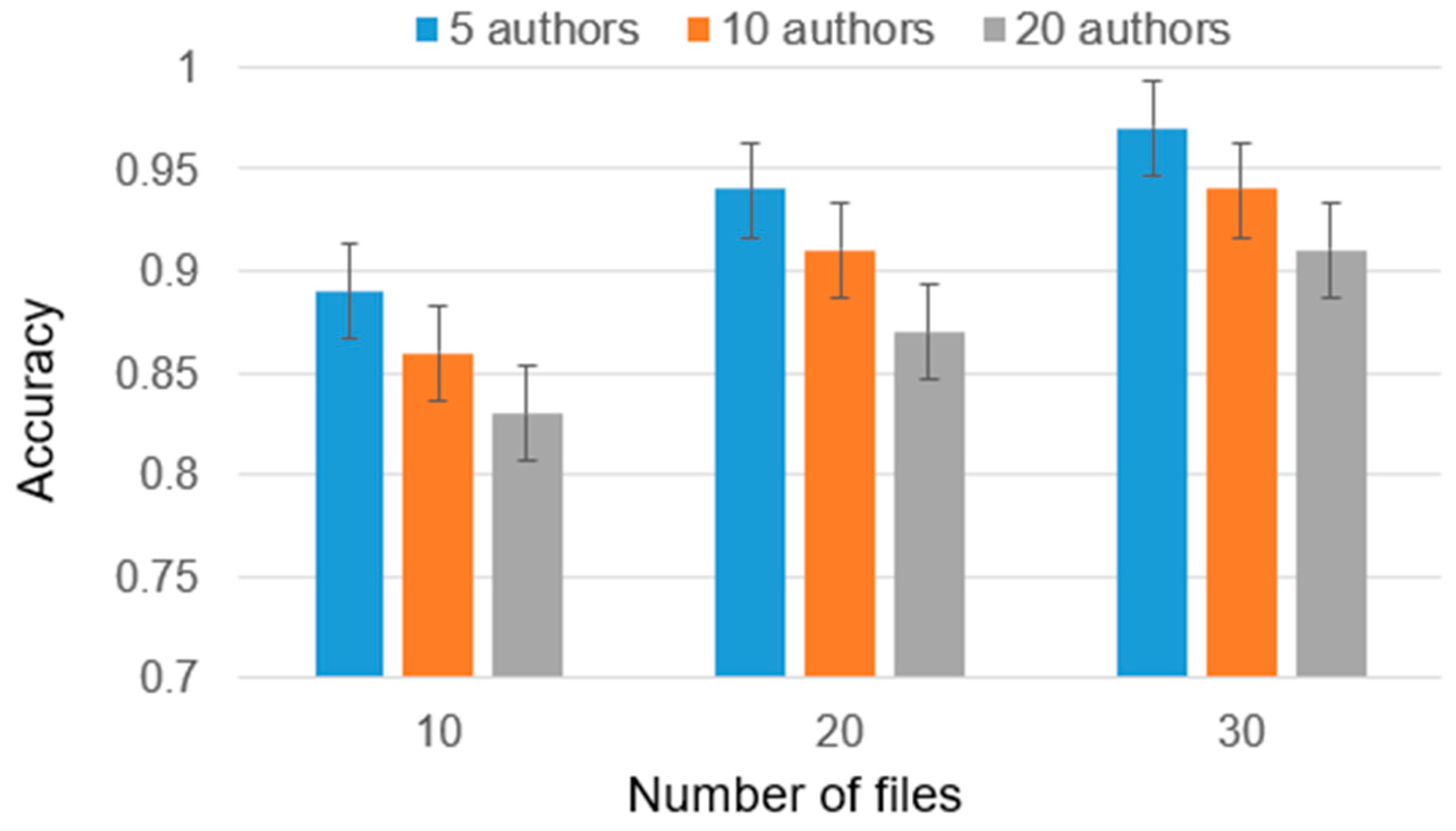
The developed methodology underwent testing for the source and binary codes of programs. Experiments were conducted to evaluate the methodology’s performance in author identification, encompassing both simple and complex cases. In certain experiments, the number of disputed authors was increased to 20, thereby challenging the methodology’s ability to accurately identify the correct author. The results of the ensemble of classifiers, specifically for the analysis of disassembled codes, are illustrated in
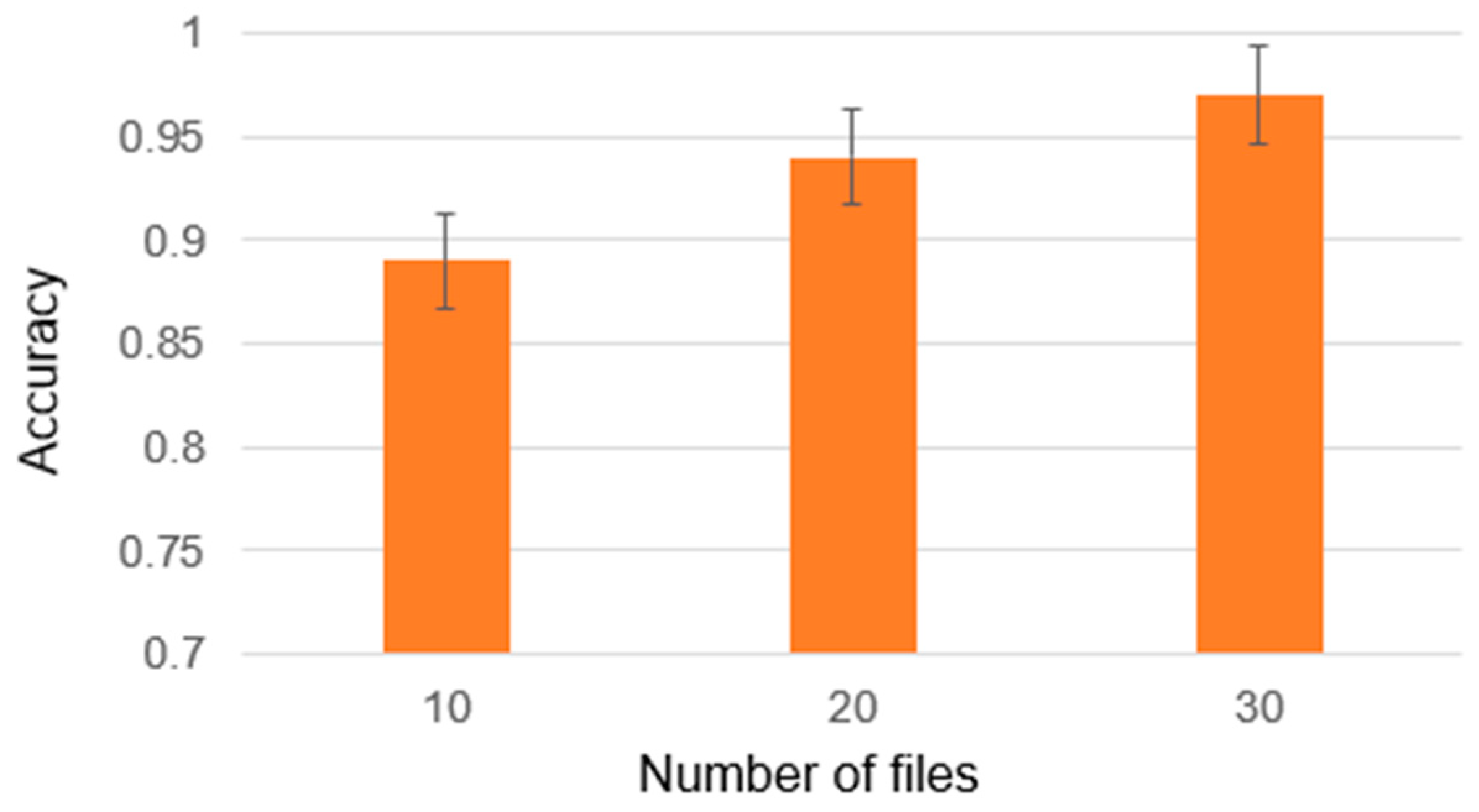
Figure 10. Additionally, the results of the analysis of source codes in simple cases are presented in
Figure 11. These figures provide visual representations of the performance metrics obtained from the experiments, enabling a comprehensive understanding of the classifier’s effectiveness.
Applying the ensemble to binary codes resulted in an accuracy improvement of over 0.1 when compared to using the classifiers individually. With an ample number of training files, the accuracy exceeds 0.9.
The results obtained by the ensemble for the original source codes are comparable to those obtained earlier [
22], that is, the ensemble has no negative effect on this case.
In addition to simple cases of source code author identification, it is crucial to examine more complex cases to ensure the stability of the enhanced methodology. These scenarios include obfuscation, compliance with coding standards, team development, and the use of artificially generated code samples.
In
Figure 12, the results of author identification for obfuscated source code are presented. The obfuscation tool used in this analysis was AnalyzeC [
35]. The obfuscation process with this tool involves the following steps:
Complete removal of comments, spaces, and line breaks;
Adding pseudo complex code that does not change functionality;
Using preprocessor directives: obfuscation may involve manipulating or transforming preprocessor directives, such as #define or #ifdef, to further obfuscate the code’s logic or structure;
Replacing strings with hexadecimal equivalents.
The results obtained by the ensemble are comparable to those obtained earlier [
22], that is, the ensemble does not have a negative effect on this case.
Figure 12.
Results of authorship identification for obfuscated code.
The next case involves identifying the author of source code written by a development team. In this case, programmers utilize a version control system, such as GitLab or GitHub, and commit their changes to the project repository. It is common for source codes to contain indications of multiple authors. Hence, the ability to determine authorship based on commits becomes particularly significant.
During the data collection process, information regarding commits, their content, and authors was obtained utilizing the GitHub API.
Figure 13 illustrates the results of author identification for the source code constructed from these commits. By employing an ensemble of classifiers instead of solely relying on a separate HNN [
23], a noticeable increase in accuracy was achieved. On average, the accuracy gain obtained through the use of the ensemble amounted to 0.03.
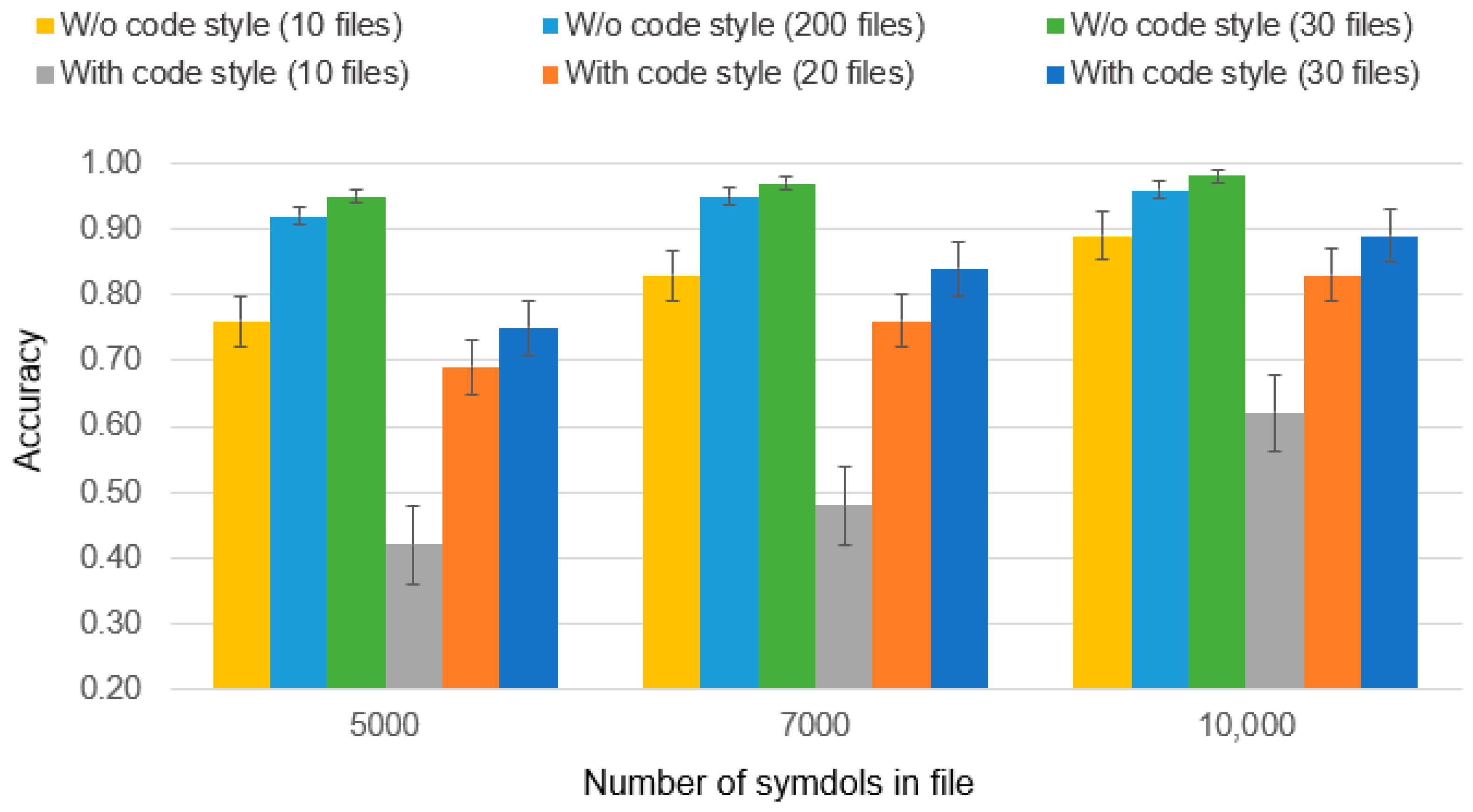
One of the most challenging cases in the early research was the authorship identification of source code written according to coding standards (see
Figure 14). The primary objective of coding standards is to facilitate code maintenance and enhance code readability. However, this can often result in minimizing the unique attributes that could help identify the author.
In the evaluation of this particular case, the source codes of the Linux Kernel [
36] were utilized. These codes, written in C/C++ following widely accepted standards [
37], served as the basis for assessing author identification. Despite the inherent difficulties posed by code conforming to coding standards, an average increase of 0.03 in accuracy was achieved when compared to using the HNN separately [
22].
The final challenging case arises from the increasing popularity of GPT models and their effectiveness in source code generation. Specifically, the experiments focused on the task of distinguishing authorship between different generative models (GPT-3, GPT-2, and RuGPT-3), as illustrated in
Figure 15. To tackle this case, the ensemble approach was employed, which proved to be beneficial. The utilization of an ensemble of classifiers yielded a noteworthy increase of precisely over 0.07 in accuracy when compared to using the HNN alone [
23].
To ensure that our method does not have a negative impact on complex cases compared to simple ones, we conducted a paired samples t-test. This test involves comparing the results of cross-validation between simple and complex cases and calculating a p-value for each pair. The null hypothesis, which states that the difference is not statistically significant, is accepted when the p-value is greater than 0.05. The alternative hypothesis suggests a significant loss in accuracy. For the pair “simple source code—obfuscated source code”, the p-value was 2.35. For the pair “simple source code—commit”, the p-value was 0.06. For the pair “simple source code—artificially generated source code”, the p-value was 0.88. Lastly, for the pair “simple source code—code written according to coding standards”, the p-value was 1.83. None of these pairs yielded a result below the threshold of 0.05, indicating that the difference in accuracy between simple and complex cases is not statistically significant.
The summarized information on the results obtained in this study is presented in
Table 3. To facilitate a clearer comparison, we considered the maximum number of authors (10) and files (30) for both simple and complex cases of source code authorship identification. The table includes the results of the ensemble method and individual classifiers. It also presents the results for SVM with and without the fast correlation filter for feature selection.
The information about the distinction of authorship between generative models has been excluded from the summary table, as their comparison with other obtained results does not provide any valuable insights.
The results we obtained on the GCJ dataset are presented in
Table 4. They are compared to the results reported by the authors in their published works [
10,
13,
14].
Several experiments were carried out to ensure that the developed methodology matches or even surpasses the accuracy of other research teams. Considering that the majority of papers relied on the GCJ dataset for evaluating their approaches, we chose to perform supplementary experiments using our methodology on the same dataset, specifically focusing on binary code analysis. To provide a fair and unbiased comparison, we incorporated the GCJ 2009 and 2010 data into our dataset. The metrics and author counts were consistent with those stated in the referenced articles. It should be noted that in one of the papers [
10], a performance metric different from accuracy (Acc) was used. The authors employed the F0.5 metric, which is calculated as follows:
The table demonstrates that our ensemble-based methodology is on par with, if not superior to, the methods proposed by previous researchers. Notably, the ensemble demonstrates a significant improvement in accuracy in some cases. Furthermore, the ensemble’s performance on the GCJ dataset surpasses that on GitHub. This can be explained by the fact that evaluating classifier accuracy on GCJ data lacks objectivity due to its specific characteristics. The GCJ dataset primarily comprises homogeneous data, enabling the classifier to focus solely on copyright features while disregarding functional differences and program specifics. In contrast, the GitHub dataset consists of heterogeneous data, including different programmer expertise and qualifications and a diverse range of tasks. Consequently, the experiments on GitHub simulate real-world applied problems, leading to a more objective assessment.
8. Conclusions
The article aims to develop a universal methodology for authorship attribution for both source code and assembly code. Several research studies were conducted to identify the most effective classifier among modern NLP algorithms. The results obtained demonstrated that the author’s HNN, developed in previous studies, is the most accurate for analyzing source codes. In contrast, for analyzing assembly codes, fastText with optimal parameters was found to be the most accurate. Based on these findings, it was decided to combine these classifiers into an ensemble and supplement it with SVM, which operates on feature sets selected by experts. The solution based on the ensemble of classifiers was supplemented with weight coefficients that vary depending on the problem being solved. For assembly codes, the highest weight was assigned to fastText solutions, while for source codes, the HNN received the highest weight.
The developed methodology underwent testing for both simple and complex cases. In the simple case, where a sufficient number of authors’ files were available, the accuracy for both source and binary codes exceeded 0.9. Additionally, the accuracy remained comparable to that achieved by the author’s HNN for obfuscated source codes. Moreover, for source codes adhering to coding standards, formed from commits and artificially generated, an average increase in accuracy of 0.04 was achieved.
Thus, we have successfully improved the previously suggested methodology, adopted it to analyze assembly codes, and rendered it universally applicable. This methodology allows, firstly, the identification of the program author even in the absence of its source code, based solely on the disassembled code. This can be particularly useful in cases where authorship needs to be established for malicious software. Secondly, it enables resolving the authorship of the program in legal proceedings involving intellectual property and copyright. A third relevant application is the detection of plagiarism in the educational process, particularly in student programming assignments, aiming to enhance the objectivity of assessment.
Through our extensive research, we have identified the following key advantages of the methodology:
Universality: the ability to identify the author of both assembly and source code based on the program’s text and extracted features.
Efficiency: the technique consistently achieves an accuracy exceeding 0.85 in all experiments, regardless of task complexity or data specificity. This level of accuracy is sufficient for practical applications.
Independence from complicating factors: the methodology remains robust against intentional factors such as obfuscation, coding standards, team collaboration, and artificial generation, as well as unintentional factors such as stylistic changes due to increased experience and programmer skill.
The primary practical application of the proposed approach is authorship identification in malicious programs. This aspect is planned to be further developed in our future work.
The limitations of the methodology, as well as possibilities for further improvement, are described in the following aspects. Firstly, to achieve high authorship identification accuracy, the program needs to be pre-deobfuscated, as even minimal obfuscation significantly reduces the system’s effectiveness. Secondly, the results are directly dependent on the number of authors and the amount of training data available for each author. Increasing the number of authors or lacking a sufficient number of training instances gradually decreases the system’s effectiveness. Thirdly, the full capabilities of the system are not yet fully explored. There is a possibility that the specific programming language or compiler used to write the program may also have a negative impact on the system’s effectiveness.
In future work, we plan to adapt multi-view learning techniques to textual data and incorporate complementary information from source and binary/disassembled code.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}