2.1.1. Acquisition and Preprocessing
The initial raw data used to create the published dataset originated from 9.94 GB of text that represented the mailboxes of employees from 9 Romanian companies. The raw data contained a total of 515 useful mailboxes. We refer to mailboxes as the directories which contain emails and are displayed in an email client (e.g., “Inbox”, “Sent”, “Spam”, “Trash”, “Archive”). By useful mailbox, we consider directories not already marked as dangerous/useless by the email client; in other words, all directories except those like “Junk”, “Spam”, or “Trash”. Each of the 515 mailboxes was initially saved in a text file containing all the emails in that particular mailbox. Each email comprises three components: header, body, and attachments. A mock email can be seen in
Figure 3.
The data were pre-processed in multiple steps. First, we separated each email into its three components, using regular expressions constructed based on the format the data was saved into. The attachments were kept intact, while the header was subjected only to a few data regularization techniques (e.g., replacing null values and saving only the email addresses, not the names). However, the body needed more thorough processing. We started with an initial cleaning that entailed the use of regular expressions for removing HTML (HyperText Markup Language) and CSS artifacts that were present in the body and also the email thread (i.e., an email conversation containing a series of messages and replies) delimiters (i.e., repetition of characters like “_”, “=”, or “−”). An important problem arose when the email body was not just a simple message but a thread. These threads had to be separated into individual emails to capture important relations in the dataset for future experiments. The threads had different kinds of separators before each email; since the data was in the Romanian language, these were either in Romanian or English, depending on the language of the system where the email originated from. We identified the following types of separators:
Simple separators
- –
These are separators that do not contain any information about the message. A few examples of this type of separator are the following:
- *
“-Mesaj redirecționat-”
- *
“-Mesaj original-”
- *
“Begin forwarded message:”
Header-aware separators
- –
These separators include information from the header of that specific message. The following are sample separators included in this category:
- *
“În <date> <user name> <user email> a scris:”
- *
“La <date> <user name> <user email> a scris:”
- *
“On <date> <user name> <user email> wrote:”
- *
“<date> <user name> <user email>:”
- *
“Quoting <user name> <user email>:”
Header-only separators
- –
These separators include portions from the header of that specific message, thus being similar to the header of the original email. However, there is variability in the name of the fields and which field is present in the separator.
We separated the individual messages from threads using regular expressions tailored to the previously mentioned separator types and then divided each message into its header and body. This was done similarly to the main email; however, we constructed a regular expression that would accept a variable number of fields from a predefined list of possible fields since the fields from the header could have a large variability. As such, all the messages contained in threads were extracted. When separating the threads, we also saved a reference for each separated message that points to the previous messages in the thread in order to recreate any thread if need be.
Having the email data processed with the previously described methodology, the only remaining steps were the removal of duplicate and invalid emails. We defined a duplicate as any email where all the fields saved in our dictionary were identical to the ones of another email. While this procedure could not remove all the duplicates, this does not impact the final dataset with manually verified emails. Regarding invalid emails, we defined an email as being invalid if any of the following conditions appear:
The “from” field in the header is missing or null
The “date” field in the header is missing or null
The email’s body and attachment list are both empty
In the end, all these processed emails added up to roughly 400,000 emails, out of which 100,000 were soft duplicates (i.e., emails where the “from” and “date” fields are identical, but the rest of the fields were slightly different, either because of formatting or because of the loopholes in the email thread separation). As previously mentioned, these possible duplicates do not impede the results and contributions of this paper.
2.1.2. Proposed Dataset
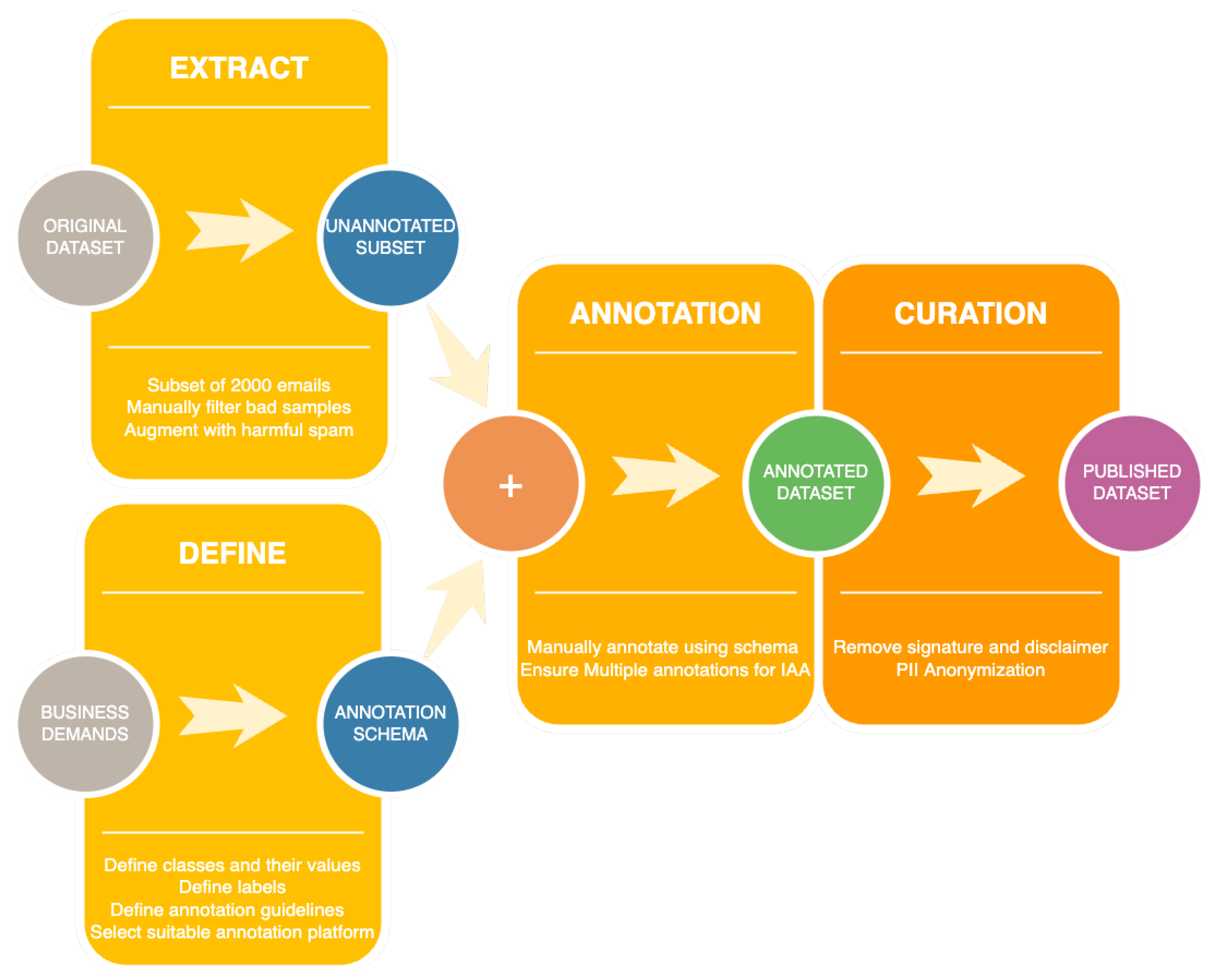
As previously mentioned, our aim is to build a dataset for email classification. To this end, we used Label Studio (
https://labelstud.io/; accessed on 12 May 2023), an open-source annotation platform for manual annotation. An important detail is that even though the raw data came from Romanian companies, a few emails are not in Romanian. For the purpose of this paper, the emails in the subset selected for the annotation process were all written in Romanian, with the exception that an email could have multiple languages (e.g., words in the message are in English or the message is in Romanian, but the disclaimer in English). An overview of the manual annotation procedure is depicted in
Figure 4.
A subset of 1447 emails was selected for annotation purposes using the following steps:
We randomly sampled 2000 of the emails from the original collection;
We manually checked all emails and eliminated the ones that were written in a different language than Romanian; if an email was written in multiple languages, out of which one was Romanian, then that email was kept; in case of soft-duplicates, only one message was kept;
Lastly, we also added a few selected harmful spam emails retrieved from our mail inboxes to the dataset in order to ensure a higher frequency of these messages.
Unlike the previously mentioned datasets containing annotations on whether an email was business-related or personal, we introduced more annotations (or metrics) that provide value in a business context. Towards this end, we defined two subtasks for the annotation process of the selected emails. Considering the available data in an email (i.e., header, body, and attachments), the first subtask was a multi-task classification in a business context. The classes deemed important are the following:
Is SPAM
- –
This class has boolean values (i.e., True or False);
- –
This label is True if the email can be considered relatively harmless or harmful spam according to the classification made in
Section 1. For this annotation task, we considered the following as relatively harmless spam: marketing email (e.g., promotional offers, ads for products, surveys) and newsletters (i.e., news from organizations about their products, services, and offers). Harmful spam emails include phishing, scam, or malspam emails; we opted to combine these two sub-categories since harmful spam had a low frequency in our dataset;
Is Business-Related
- –
This class has boolean values (i.e., True or False).
- –
This label is True if the email is about a subject that can be related to the company’s activity (e.g., tasks, notifications, equipment, financial transactions, legal matters); otherwise, it is False.
Type of Writing Style
- –
This class has one of the following three values: “Formal”, “Neutral”, and “Informal”.
- –
This class specifies the type of language used in the redaction of the email.
An important thing to mention is that the last class is much more subjective than the previous; as such, the opinion of the annotator is more likely to induce bias. The statistics for the multi-task classification can be seen in
Figure 5 and
Figure 6. We present the number of examples annotated with “True” for the classes with binary values while we show the number of examples annotated with each of the three possible values for the writing style class.
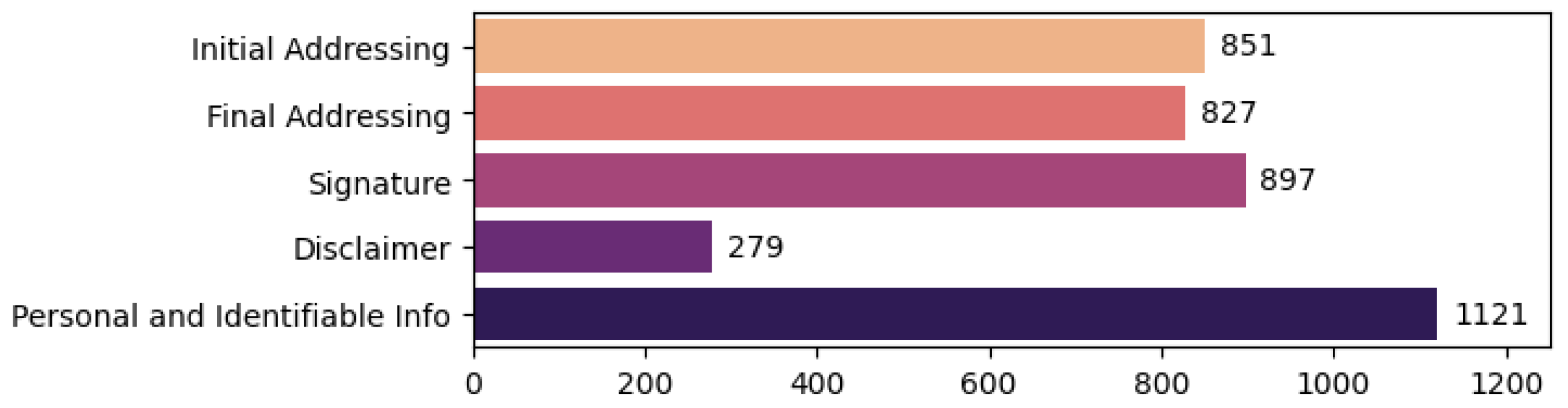
The second subtask was a token classification one, which deals with the identification of text fragments that could hinder the classifier (i.e., signature, disclaimer), as well as other relevant token information. For this, we defined the following labels:
Initial Addressing:
- –
The selected text fragment represents an initial addressing formulation (e.g., “Salut”, “Stimate client”—eng. “Hello”, “Esteemed client”). This is generally at the beginning of the message and has the role of initializing the communication act;
Final Addressing:
- –
The selected text fragment represents a final addressing formulation (e.g., “O zi buna!”, “Mulțumesc!”—eng. “Have a good day!”, “Thank you!”). This is generally at the end of the message and has the role of finalizing the communication act. Typically if there happens to be other text after it, it is usually the signature of the sender or a disclaimer;
Signature:
- –
The selected text fragment represents the signature of the sender. A signature is a fragment of text at the end of the communication, generally between the final addressing and the disclaimer (if both exist) that contains the contact information of the writer. Common information here includes the writer’s name, his position in the company, the name of the company, the address of the company, phone number, fax, emails, and other similar information;
Disclaimer:
- –
The selected text fragment represents the disclaimer, a text which usually contains clauses and legal considerations in relation to the email and its content. Usually, only companies and institutions have a disclaimer for the emails sent by their employees. When it appears, the disclaimer is generally the last part of the email body;
It is important to mention that each example must have a label for each class for the former subtasks (i.e., multi-task email classification), while any of the previously described labels may be missing for the latter subtasks (i.e., token classification). Moreover, one or more labels can overlap for the latter subtask. For example the fragment “Goodbye Josh and have a great day!” would have the label “Initial Addressing”, but “Josh” would also have the label “Personal Identifiable Information”.
Figure 7 presents the total annotated entities for each label type in the token classification task.
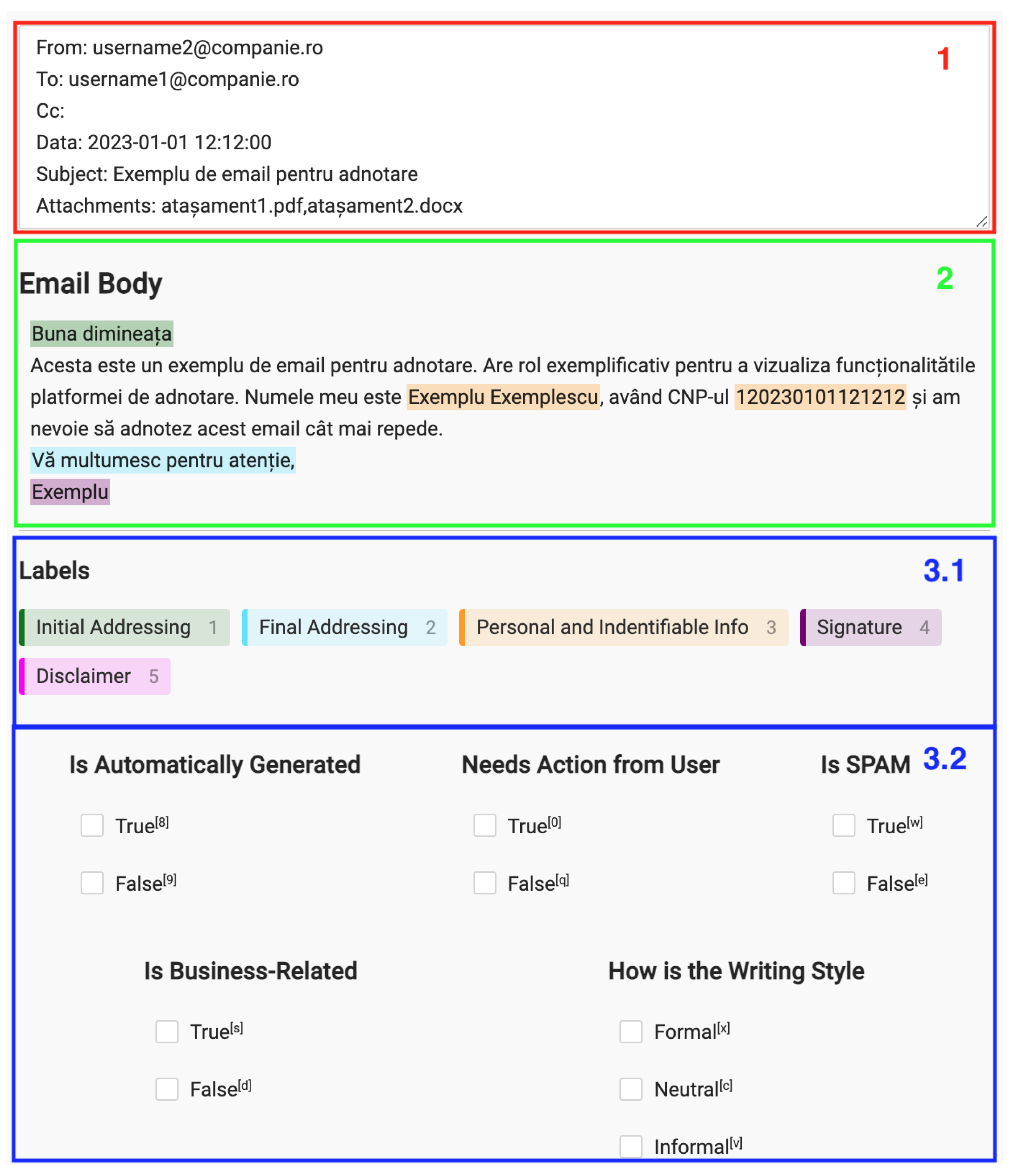
With the previous subtask defined, we constructed the annotation interface and started the labeling process. An example of our annotation interface can be viewed in
Figure 8. It is separated into three parts. The first part, colored in red (
1), contains the header data of the email (i.e., the fields ‘from’, ‘to’, and ‘subject’). The second part, colored in green (
2), contains the body of the email. The third part in blue (
3) is split into two sections: the token classification labels and the multi-task classification classes. The workflow of an annotator was to read the header and the body of the email, click on the relevant token classification label, and then select the corresponding text portion. The granularity of the selection was set at the word level.
The emails were labeled by one of the seven annotators, except for 40 emails which were annotated by all to assess the quality of the annotations. For this, we performed an IAA (Inter-Annotator Agreement) procedure. Two metrics were used to assess IAA for the multi-task classification task, namely Fleiss’ kappa [
36,
37] and Krippendorff’s alpha [
38,
39]. It is generally agreed upon that Fleiss’ kappa is the best metric to be used when data is measured using a nominal scale, and there are more than two annotators. Krippendorff alpha usually has the same values as Fleiss’ kappa if the data is measured using the nominal scale and has no missing values (i.e., our case). Nonetheless, the latter offers more flexibility since it can also be used for data using the ordinal, interval, and ratio scales. Because of this, it should be a more sound method for the annotations in the “How is the Writing Style” category since those are measured on the ordinal scale. As such, we computed both metrics, with the mention the alpha was computed for the nominal scale in the case of binary classes, while it was computed for the ordinal scale when applied to the “Writing Style” class. The IAA for these annotations is presented in
Table 1.
Both IAA values fall in the range [−1, 1]. Thus, both the values for kappa and alpha can be interpreted according to
Table 2. It can be observed that the annotation procedure led to a substantial agreement in almost all classes. The only outliers are “Needs Action from User” and “How is the Writing Style”. Regarding the latter, Krippendorff’s alpha holds a higher importance due to the fact it is measured using an ordinal scale. Because of this, we can conclude that this label reaches moderate agreement between annotators. This is relatively expected since this class is more subjective than the previous ones. As for the “Needs Action from User” class, this class can also be rather subjective since some emails can implicitly suggest that the user needs to complete an action, which is harder to extract compared to explicit instructions.
For the token classification task, which is similar to a NER (Named Entity Recognition) task, the best metric for assessing the IAA is the pair-wise F1 score [
41]. This is because Fleiss’ kappa can severely underestimate the true agreement in this case. As such, we computed the pair-wise F1 score between all annotator pairs using the “seqeval” package (
https://huggingface.co/spaces/evaluate-metric/seqeval; accessed on 12 May 2023) and then averaged the results to obtain the overall F1 score for each label category. This package is used for computing the accuracy, precision, recall, and F1 score for NER-like tasks. The IAA for these annotations can be seen in
Table 3. We can observe that the only label which has a slightly weaker IAA is “Disclaimer”. This is because disclaimers can be very long spans of text in general, and we observed that some annotators correctly identified the start of the disclaimer, but they relatively disagreed on where to end. Some emails, like newsletters, contained information on how to unsubscribe, or other useless information for our task after the legal and confidential information in the disclaimer. However, this did not represent an impediment to our tasks, since we are interested in where the signatures and disclaimers start, rather their ending.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}