1. Introduction
Item response theory (IRT) models [
1,
2,
3,
4] are a popular statistical method for analyzing dichotomous and polytomous random variables. IRT models can be classified into the area of multivariate statistics, which summarize a high-dimensional contingency table with a few latent factor variables of interest. Of particular interest is the application of IRT models in educational large-scale assessment (LSA; [
5]), such as the program for international student assessment (PISA; [
6]), which assesses the ability of students on test items in different cognitive domains, such as mathematics, reading, and science, across a wide range of countries all over the world.
In this article, we focus on unidimensional IRT models. These models are used for scaling cognitive test data to obtain a single unidimensional summary score [
7]. Let
be the vector of
I polytomous random variables (i.e., items)
with
. A unidimensional IRT model [
4] is a statistical model for the multivariate probability distribution
for
, where
The unidimensional latent variable
follows a standard normal distribution with a density function
, although this assumption can be weakened [
8,
9]. Conditional item response probabilities are defined as
, where
is a vector of the unknown item parameters of item
i. Note that a local independence assumption is imposed in (
1), which means that item responses
and
are conditionally independent for all item pairs
given the latent ability variable
. This property justifies the statement that the multivariate contingency table
is summarized by a unidimensional latent variable
.
The item parameters
of the unidimensional IRT model in Equation (
1) can be estimated by the (marginal) maximum likelihood (ML) using an expectation maximization (EM) algorithm [
10,
11]. The estimation can also involve a multi-matrix design in which only a subset of items is administered to each student [
12,
13]. In the likelihood formulation of (
1), non-administered items are skipped in the multiplication terms in (
1).
For dichotomous items, one often uses the abbreviated notation
. The function
is also referred to as the item response function (IRF). A popular choice of
is the two-parameter logistic (2PL; [
14]) model defined by
, where
denotes the logistic link function,
is the item discrimination parameter, and
is the item difficulty parameter. A simplified version of the 2PL model is the Rasch model [
15,
16], which constrains the item discriminations across items, leading to the IRF
. A further alternative is the two-parameter probit (2PP; [
2]) model
that employs the standard normal distribution function
(i.e., the probit link function).
There is increasing interest among researchers to use more flexible IRFs. In particular, the 2PL and 2PP models employ symmetric link functions. A variety of IRFs with asymmetric link functions have been proposed [
17,
18,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28]. These kinds of models might be desirable if items do not follow the simple 2PL or 2PP models. In this article, we focus on item response modeling based on the generalized logistic link function [
29]. This link function has been previously applied in [
30] utilizing ML estimation, while [
31] proposed a Markov chain Monte Carlo (MCMC) estimation approach. In this article, we thoroughly study ML estimation for the generalized logistic IRT model for dichotomous and polytomous item responses. Moreover, we also propose a regularized ML estimation approach aiming to stabilize the item parameter estimates.
The rest of the article is structured as follows. In
Section 2, we introduce the IRT model based on the generalized logistic link function. Moreover, we propose the regularized estimation approach and discuss the application of this link function to polytomous items.
Section 3 includes two simulation studies investigating the performance of estimating the generalized logistic IRT model for dichotomous items.
Section 4 contains two empirical examples of datasets with dichotomous and polytomous items, respectively. Finally, the paper closes with a discussion in
Section 5.
2. Item Response Modeling Based on the Generalized Logistic Link Function
The generalized logistic IRT model relies on the generalized logistic link function
proposed by Stukel [
29]. For the real-valued asymmetry parameters
and
, the link function
is defined by
where
is defined by
The logistic link function is obtained with
. The probit link function is approximately obtained with
. More generally, symmetric link functions are obtained for
, while asymmetry is introduced by imposing
. The cloglog and loglog link functions [
32] can also be well approximated by particular parameter values of
and
[
31].
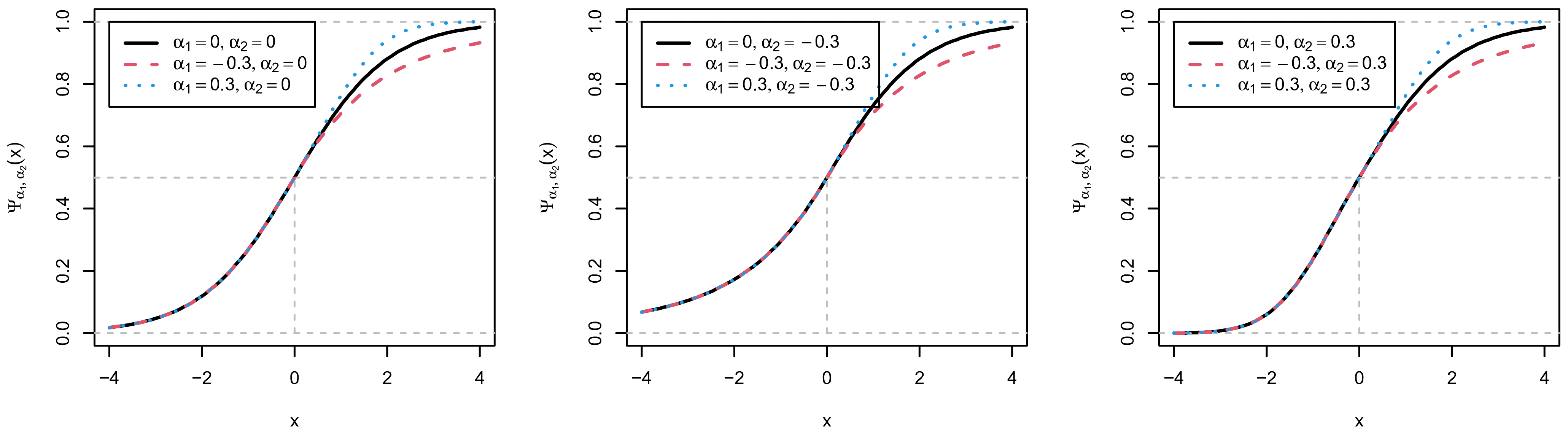
Figure 1 displays the generalized logistic link function
for different values of
and
. It can be seen that
governs the upper tail of the link function (i.e.,
), and
values different from 0 indicate deviations from the logistic link function. For positive values (i.e.,
), the link function
more quickly reaches the upper asymptote of one compared to the logistic link function
, while there is slower convergence to the upper asymptote for negative values of
. Moreover, the
parameter models the deviations from the logistic link function in the lower tail of the link function (i.e., for
).
The generalized logistic link function defined in (
3) can be used to define an IRF for a dichotomous item
by
where
is the vector of item parameters for item
i. In (
4), it is assumed that the shape parameters
and
are item-specific, but it might be desirable for parsimony reasons to constrain them to be equal across items.
Zhang et al. [
31] proposed an MCMC estimation approach. In this approach, the factor variable
must also be sampled, and parameter estimation can sometimes become computationally tedious. Therefore, ML estimation is always a viable alternative and computationally efficient for unidimensional IRT models, which is the reason for pursuing the ML estimation approach in this paper.
In [
31], it was argued that a lower bound of
must be imposed for
and
in order to ensure proper posterior distribution. To ensure a sufficiently stable estimation from experiences in previous research [
30], we also bounded the
and
parameters by one. To this end, we transformed the bounded asymmetry parameters
for
and
, which lie in the interval
, into an unbounded parameter space using the Fisher transformation
[
33]
where
denote the unbounded transformed parameters of the generalized logistic link function. The inverse Fisher transformation
maps unbounded parameters
to bounded parameters
by means of the transformation
In ML estimation of the generalized logistic IRT model for dichotomous item responses, the vector of item parameters for item
i is defined as
. For the item response data
for
N persons and
I items, we define the log-likelihood function
l based on (
1) by
for item responses
of person
p, and
is the vector that collects the item parameters
of all items
. The log-likelihood function can be numerically maximized to obtain the item parameter estimates
. In IRT software, the EM algorithm is frequently utilized [
11,
34].
5. Discussion
In this article, nonregularized and regularized maximum likelihood estimations of the generalized logistic IRT model for dichotomous and polytomous items were investigated. It was shown that parameter estimates were practically unbiased in large samples, and variability decreased with larger sample sizes. Moreover, this was present in the simulation, and the empirical examples that used regularized estimation were able to stabilize parameter estimates.
It should be emphasized that the variability of the estimated item parameters in the generalized logistic IRT model can be noteworthy, even in very large sample sizes such as
. However, as in the three-parameter or four-parameter logistic IRT models, this is likely the case due to the large dependency among the four different item parameters. Nevertheless, estimated item response functions can still be relatively precise, which demonstrates the finding of stable item response functions despite the unstable estimation of item parameters [
57]. Using complex IRT models might be preferable when the primary goal is deriving an optimal scoring rule that maximizes the extent of the extracted information from the observed item responses [
58,
59].
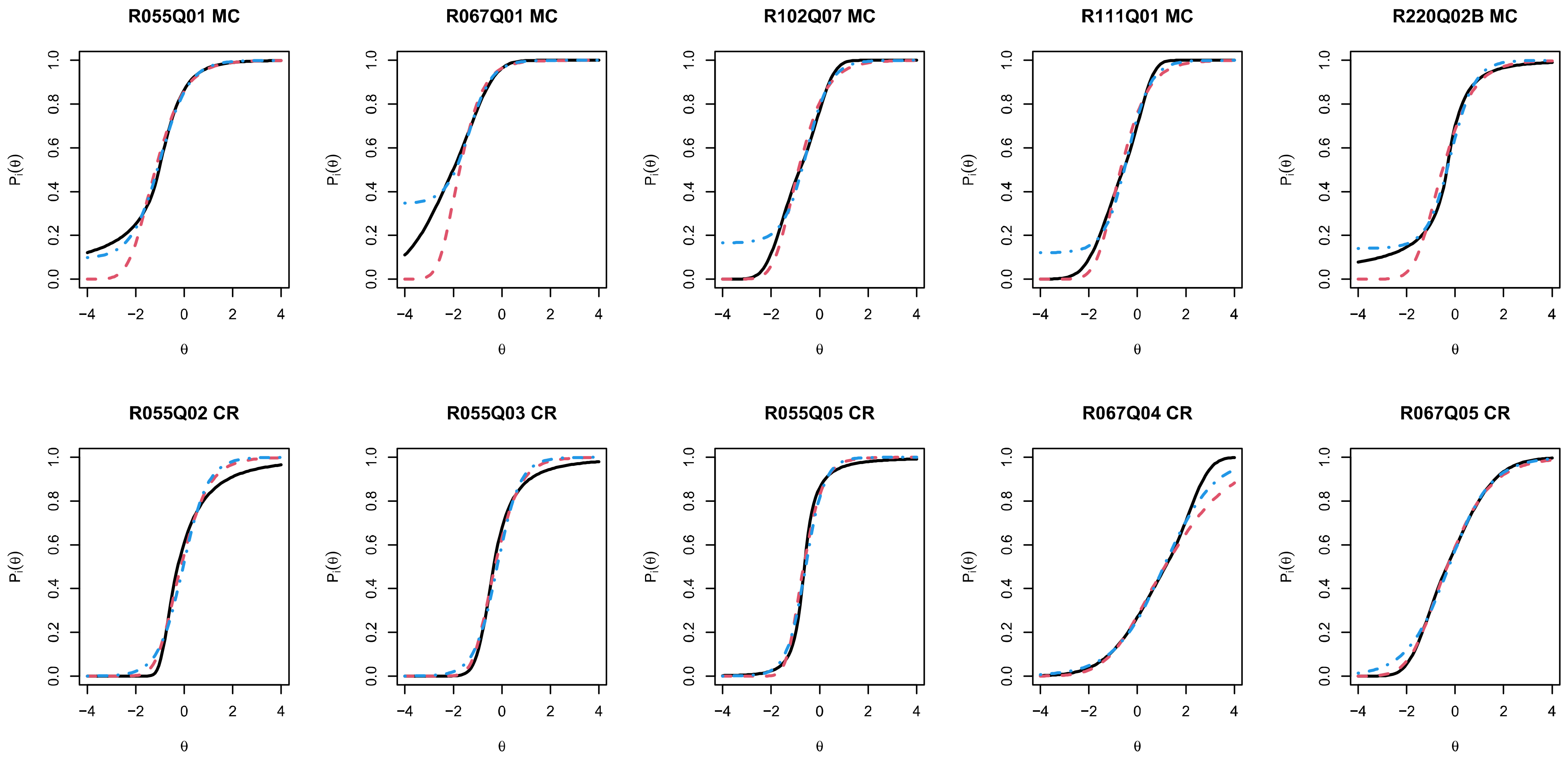
In applications, it is likely that item response functions typically differ for constructed response items and multiple-choice items. It might be interesting and parsimonious to separately estimate and for the two item formats but make them equal for items of the same item format. By estimating this, the guessing or slipping effects can be modeled by the generalized logistic IRT model.
As pointed out by an anonymous reviewer, it would be vital also to compare the generalized logistic IRT model to other IRT models, such as the three- or four-parameter logistic models, in the simulation studies. It might well be the case that despite quite different functional forms of utilized IRT models, there would not be negligible differences in the fitted item response functions of different types of IRT models.
There is a recent discussion about whether distributional assumptions must be taken for granted in ordinal factor analysis for analyzing polytomous items [
60]. Most often, ordinal factor analysis in structural equation modeling software relies on the limited-information estimation method that utilizes tetrachoric or polychoric correlations [
61]. Using polychoric correlations implies that one assumes an underlying normally distributed variable for each item (i.e., a latent normality assumption; [
62,
63,
64]). It is argued in [
60] that the distributional assumption for the underlying latent variable must be known by the researcher and cannot be identified from data. It is important to emphasize that the issue of non-identification is coupled with the goal of using limited information methods and computing a latent correlation matrix (i.e., polychoric correlations or correlations adapted to other pre-specified marginal distributions). To put this in other words, those researchers base the ordinal factor analysis on a normal copula model. When applying the generalized logistic IRT model (i.e., the generalized logistic link function) for exploratory or confirmatory factor analysis, residual distributions different from the normal distribution can be identified. In this case, simply no substantial knowledge is required for factor-analyzing ordinal data if there is enough data available for empirical identification.
As has been demonstrated in the PISA example dataset, other classes of flexible item response functions [
48,
65,
66,
67,
68,
69,
70,
71,
72] can be considered as an alternative to the generalized logistic IRT model. These IRT models might even outperform the generalized logistic IRT model. However, it has been argued that analysis models should not be mainly chosen for statistical reasons in the operational practice in educational large-scale assessment studies [
30,
73,
74,
75,
76]. This poses issues in test linking [
77,
78,
79,
80] if the preferred scoring model were a misspecified IRT model [
81,
82].
Appropriate linking methods should be applied that are relatively robust to model misspecifications (see [
83]).




{kind=link}
{kind=link}
{kind=link}
{kind=link}



