

A Hybrid Univariate Traffic Congestion Prediction Model for IoT-Enabled Smart City



Abstract
1. Introduction
- (a)
- This paper discusses the detailed literature on traffic congestion prediction techniques and different time-series dataset handling techniques.
- (b)
- A novel univariate predictive model is proposed using SARIMA, Bi-LSTM, and back-propagation techniques, which is elaborated in a stepwise manner.
- (c)
- This study discusses the behavior of a big IoT time-series dataset.
- (d)
- The study outlines the comparative analysis of the proposed model with the existing ones.
2. Literature Review
3. Background
3.1. SARIMA
3.2. Bi-LSTM
3.3. Back Propagation Neural Network
- In the first step, input values of the dataset are fed forward from the input layer, then to the hidden layers, and finally to the output layer.
- In the second step, output errors are calculated and then propagated in the backward direction of network. This step helps to tune different features of the neural network.
- These steps repeat until the desired output is achieved with a minimum error value.
4. Proposed Model and Implementation
| Algorithm 1. Pseudocode of proposed model. |
| Input: Yt {y0,y1,y2,…….yi} = Timeseries dataset, i = number of time-series dataset instances Output: Predicted output Oh |
| Begin For each Yi of dataset Y Step 1: Data Preprocessing
|
Step 2: SARIMA (Ytrain, Ytest) // handling linear components of Yt
|
Step 3: Calculating residuals
|
Step 4: Preprocessing residuals
|
Step 5: Bi-LSTM (NLtrain) // handling nonlinear components of NLt
|
Step 6: BPNN (, , Yt) // forecasted values of SARIMA and Bi-LSTM are given as input to produce combined prediction values
|
Step 7: Evaluating model
|
4.1. Algorithmic Steps for the Proposed Model
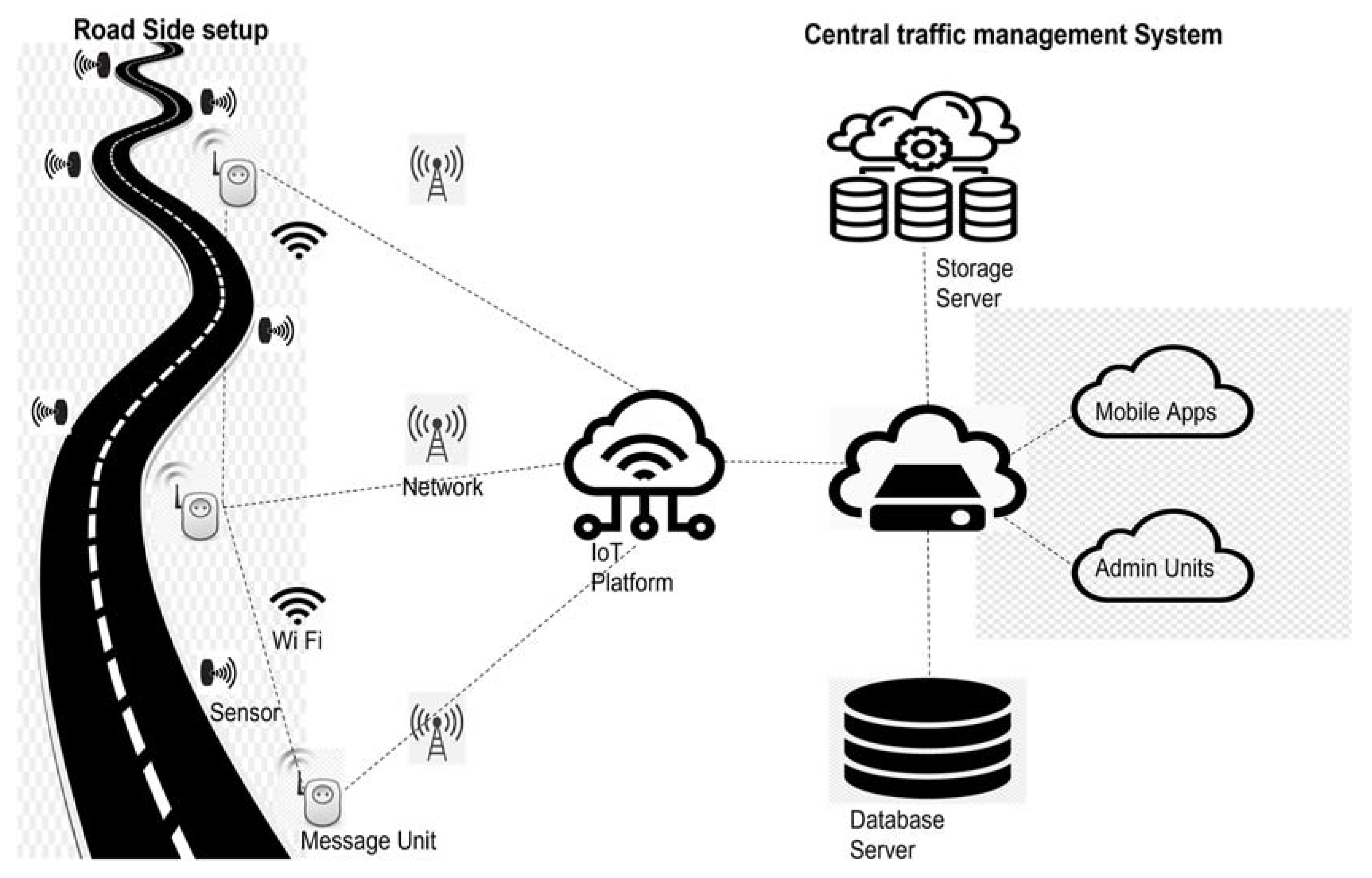
4.2. Dataset Used
- Observational KPI: these KPIs are related to the observation points such as the virtual or physical environment near the sensors used, the environment nearby, and temporal constraints.
- Network connected KPI: these KPI are related to the kind of network used for the connection of the sensors, security measures to be taken for safe connection over the network, etc.
- Data-processing KPI: these KPIs are related to the computational capabilities of the smart city framework. It basically deals with the data processing that can take place inside the functional component of the framework.
4.3. Evaluation Matrices
- Mean Squared Error (MSE): MSE is considered as the best parameter to check the error rate of the regression prediction model. The lower the value of MSE, the better the model is. MSE can be calculated as given in Equation (15):where n denotes the number of data items, Yi denotes the actual values, and Yi represents the predicted value.
- Mean Absolute Error (MAE): MAE is the difference between the predicted values and the actual correct values but in the paired observation. These paired observations are considered to be the ones that are creating the same phenomenon. MAE can be calculated as given by Equation (16):where n denotes the number of data items, yi denotes the predicted values, and xi represents actual correct values.
- Root Mean Squared Error (RMSE): RMSE represents absolute fit of the model with respect to the data. The lower the value of this parameter, the better the model is considered. It can be calculated as given in Equation (17).where n denotes the number of data items, Yi denotes the actual values, and Ŷi represents the predicted value.
- Mean Absolute Percentage Error (MAPE): It is also called Mean Absolute Percentage Deviation (MAPD). It represents keeping track of relative errors with respect to the actual values in percentage. MAPE can be calculated as given in Equation (18):where n denotes the number of data items, Yi denotes the actual values, Yi represents the predicted value, and is a small positive arbitrary value.
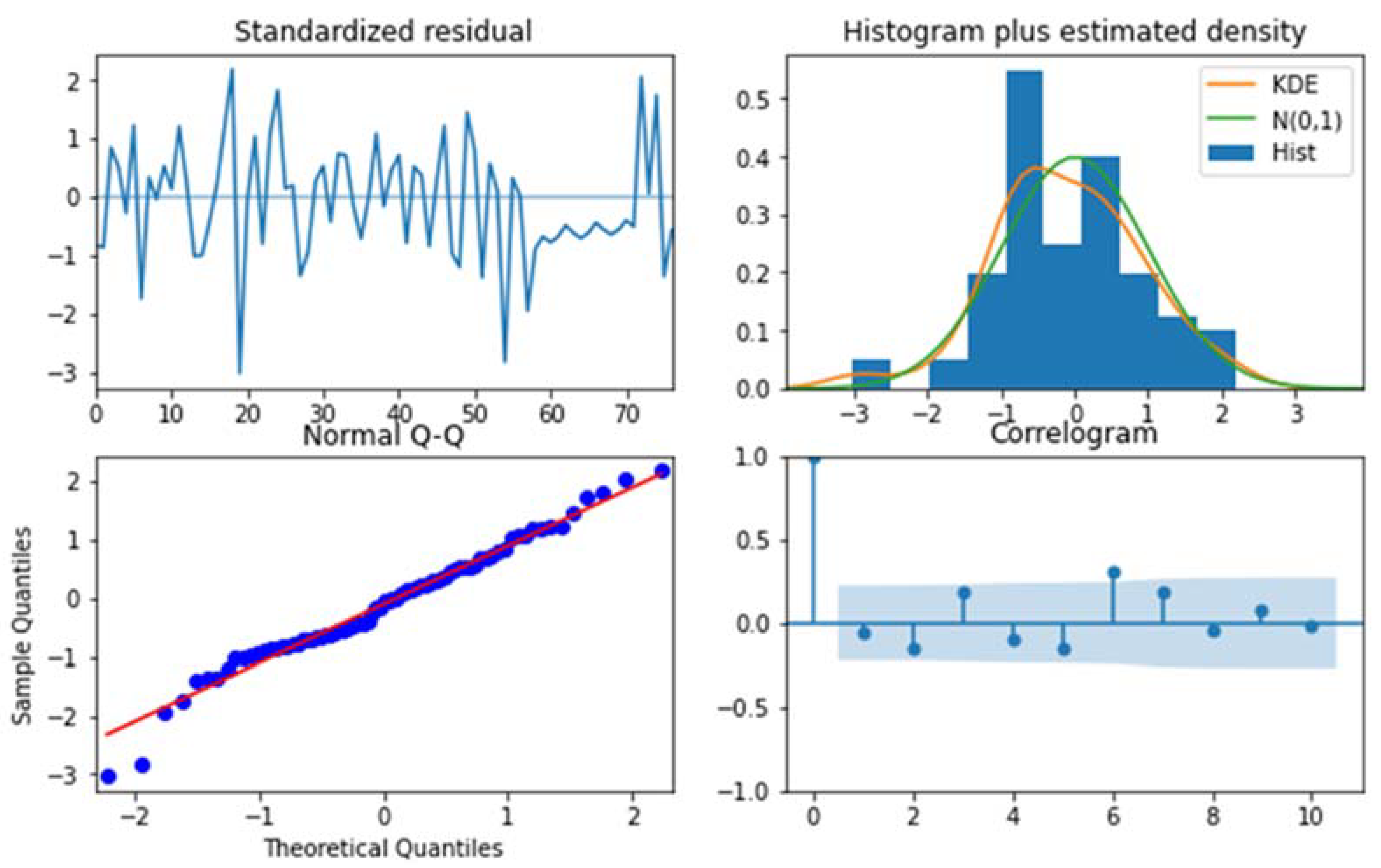
5. Results and Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zheng, Z.; Yang, Y.; Liu, J.; Dai, H.-N.; Zhang, Y. Deep and Embedded Learning Approach for Traffic Flow Prediction in Urban Informatics. IEEE Trans. Intell. Transp. Syst. 2019, 20, 3927–3939. [Google Scholar] [CrossRef]
- Kashyap, A.A.; Raviraj, S.; Devarakonda, A.; Nayak, K.S.R.; Kv, S.; Bhat, S.J. Traffic flow prediction models—A review of deep learning techniques. Cogent Eng. 2022, 9, 2010510. [Google Scholar] [CrossRef]
- Sarrab, M.; Pulparambil, S.; Awadalla, M. Development of an IoT based real-time traffic monitoring system for city governance. Glob. Transit. 2020, 2, 230–245. [Google Scholar] [CrossRef]
- Guerrero-Ibáñez, J.; Zeadally, S.; Contreras-Castillo, J. Sensor Technologies for Intelligent Transportation Systems. Sensors 2018, 18, 1212. [Google Scholar] [CrossRef] [PubMed]
- Chahal, A.; Gulia, P.; Gill, N.S. Different analytical frameworks and big data model for Internet of Things. Indones. J. Electr. Eng. Comput. Sci. 2022, 25, 1159–1166. [Google Scholar] [CrossRef]
- Yadav, S.; Gulia, P.; Gill, N.S. Flow-MotionNet: A neural network-based video compression architecture. Multimed. Tools Appl. 2022, 81, 42783–42804. [Google Scholar] [CrossRef]
- Javaid, S.; Sufian, A.; Pervaiz, S.; Tanveer, M. Smart traffic management system using Internet of Things. In Proceedings of the International Conference on Advanced Communication Technology, ICACT, Chuncheon-si, Republic of Korea, 11–14 February 2018; pp. 393–398. [Google Scholar] [CrossRef]
- Rejeb, A.; Rejeb, K.; Simske, S.; Treiblmaier, H.; Zailani, S. The big picture on the internet of things and the smart city: A review of what we know and what we need to know. Internet Things 2022, 19, 100565. [Google Scholar] [CrossRef]
- Zafar, N.; Haq, I.U.; Chughtai, J.-R.; Shafiq, O. Applying Hybrid Lstm-Gru Model Based on Heterogeneous Data Sources for Traffic Speed Prediction in Urban Areas. Sensors 2022, 22, 3348. [Google Scholar] [CrossRef]
- Sun, T.; Sun, B.; Jiang, Z.; Hao, R.; Xie, J. Traffic Flow Online Prediction Based on a Generative Adversarial Network with Multi-Source Data. Sustainability 2021, 13, 12188. [Google Scholar] [CrossRef]
- Majumdar, S.; Subhani, M.M.; Roullier, B.; Anjum, A.; Zhu, R. Congestion prediction for smart sustainable cities using IoT and machine learning approaches. Sustain. Cities Soc. 2021, 64, 102500. [Google Scholar] [CrossRef]
- Feng, X.; Ling, X.; Zheng, H.; Chen, Z.; Xu, Y. Adaptive Multi-Kernel SVM with Spatial–Temporal Correlation for Short-Term Traffic Flow Prediction. IEEE Trans. Intell. Transp. Syst. 2019, 20, 2001–2013. [Google Scholar] [CrossRef]
- Bogaerts, T.; Masegosa, A.D.; Angarita-Zapata, J.S.; Onieva, E.; Hellinckx, P. A graph CNN-LSTM neural network for short and long-term traffic forecasting based on trajectory data. Transp. Res. Part C Emerg. Technol. 2020, 112, 62–77. [Google Scholar] [CrossRef]
- Neelakandan, S.; Berlin, M.A.; Tripathi, S.; Devi, V.B.; Bhardwaj, I.; Arulkumar, N. IoT-based traffic prediction and traffic signal control system for smart city. Soft Comput. 2021, 25, 12241–12248. [Google Scholar] [CrossRef]
- Aid, A.; Khan, M.A.; Abbas, S.; Ahmad, G.; Fatimat, A. Modelling smart road traffic congestion control system using machine learning techniques. Neural Netw. World 2019, 29, 99–110. [Google Scholar] [CrossRef]
- Rajalakshmi, V.; Vaidyanathan, S.G. Hybrid Time-Series Forecasting Models for Traffic Flow Prediction. Promet Traffic Transp. 2022, 34, 537–549. [Google Scholar] [CrossRef]
- Lu, S.; Zhang, Q.; Chen, G.; Seng, D. A combined method for short-term traffic flow prediction based on recurrent neural network. Alex. Eng. J. 2021, 60, 87–94. [Google Scholar] [CrossRef]
- Tseng, F.-H.; Hsueh, J.-H.; Tseng, C.-W.; Yang, Y.-T.; Chao, H.-C.; Chou, L.-D. Congestion prediction with big data for real-time highway traffic. IEEE Access 2018, 6, 57311–57323. [Google Scholar] [CrossRef]
- Yi, H.; Jung, H.; Bae, S. Deep Neural Networks for traffic flow prediction. In Proceedings of the 2017 IEEE International Conference on Big Data and Smart Computing (BigComp), Jeju, Republic of Korea, 13–16 February 2017; pp. 328–331. [Google Scholar] [CrossRef]
- Bernaś, M. WSN Power Conservation Using Mobile Sink for Road Traffic Monitoring. In Computer Networks, Communications in Computer and Information Science; Kwiecień, A., Gaj, P., Stera, P., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 476–484. [Google Scholar] [CrossRef]
- Bernaś, M. VANETs as a Part of Weather Warning Systems. In Computer Networks, Communications in Computer and Information Science; Kwiecień, A., Gaj, P., Stera, P., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 459–466. [Google Scholar] [CrossRef]
- Bernas, M.; Płaczek, B.; Korski, W. Wireless Network with Bluetooth Low Energy Beacons for Vehicle Detection and Classification. In Computer Networks, Communications in Computer and Information Science; Gaj, P., Sawicki, M., Suchacka, G., Kwiecień, A., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 429–444. [Google Scholar] [CrossRef]
- Zahid, M.; Chen, Y.; Jamal, A.; Mamadou, C.Z. Freeway Short-Term Travel Speed Prediction Based on Data Collection Time-Horizons: A Fast Forest Quantile Regression Approach. Sustainability 2020, 12, 646. [Google Scholar] [CrossRef]
- Zahid, M.; Chen, Y.; Jamal, A.; Memon, M.Q. Short Term Traffic State Prediction via Hyperparameter Optimization Based Classifiers. Sensors 2020, 20, 685. [Google Scholar] [CrossRef]
- Chaturvedi, S.; Rajasekar, E.; Natarajan, S.; McCullen, N. A comparative assessment of SARIMA, LSTM RNN and Fb Prophet models to forecast total and peak monthly energy demand for India. Energy Policy 2022, 168, 113097. [Google Scholar] [CrossRef]
- Medina-Salgado, B.; Sánchez-DelaCruz, E.; Pozos-Parra, P.; Sierra, J.E. Urban traffic flow prediction techniques: A review. Sustain. Comput. Inform. Syst. 2022, 35, 100739. [Google Scholar] [CrossRef]
- Muneer, A.; Ali, R.F.; Almaghthawi, A.; Taib, S.M.; Alghamdi, A.; Ghaleb, E.A.A. Short term residential load forecasting using long short-term memory recurrent neural network. Int. J. Electr. Comput. Eng. 2022, 12, 5589–5599. [Google Scholar] [CrossRef]
- Li, Y.-H.; Harfiya, L.N.; Purwandari, K.; Lin, Y.-D. Real-Time Cuffless Continuous Blood Pressure Estimation Using Deep Learning Model. Sensors 2020, 20, 5606. [Google Scholar] [CrossRef]
- Wang, L.; Xu, X.; Su, Q.; Song, Y.; Wang, H.; Xie, M. Automatic gear shift strategy for manual transmission of mine truck based on Bi-LSTM network. Expert Syst. Appl. 2022, 209, 118197. [Google Scholar] [CrossRef]
- Cai, L.; Zhou, S.; Yan, X.; Yuan, R. A Stacked BiLSTM Neural Network Based on Coattention Mechanism for Question Answering. Comput. Intell. Neurosci. 2019, 2019, e9543490. [Google Scholar] [CrossRef]
- Sun, W.; Wang, Y. Short-term wind speed forecasting based on fast ensemble empirical mode decomposition, phase space reconstruction, sample entropy and improved back-propagation neural network. Energy Convers. Manag. 2018, 157, 1–12. [Google Scholar] [CrossRef]
- Ali, M.I.; Gao, F.; Mileo, A. CityBench: A Configurable Benchmark to Evaluate RSP Engines Using Smart City Datasets. In Proceedings of the Semantic Web—ISWC 2015—14th International Semantic Web Conference, Bethlehem, PA, USA, 11–15 October 2015. [Google Scholar]
- Tönjes, R.; Barnaghi, P.; Ali, M.; Mileo, A.; Hauswirth, M.; Ganz, F.; Ganea, S.; Kjærgaard, B.; Kuemper, D.; Nechifor, S.; et al. Vestergaard. Real Time IoT Stream Processing and Large-scale Data Analytics for Smart City Applications. In Poster Session, European Conference on Networks and Communications; University of Surrey: Surrey, England, 2014. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Deng, Y.; Fan, H.; Wu, S. A hybrid ARIMA-LSTM model optimized by BP in the forecast of outpatient visits. J. Ambient Intell. Human Comput. 2020, in press. [Google Scholar] [CrossRef]
- He, J.; Bai, J. Prediction Technology for Parking Occupancy Based on Multi-dimensional Spatial-Temporal Causality and ANN Algorithm. In Green, Pervasive, and Cloud Computing: 15th International Conference, GPC 2020, Xi’an, China, 13–15 November 2020, Proceedings 15; Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics) 12398 LNCS; Springer: Berlin/Heidelberg, Germany, 2020; pp. 244–256. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| S. No. | Reference | Dataset Used | Model | Performance Matrices |
|---|---|---|---|---|
| 1 | T. Sun et al. [10] | Real time-Time series | IGAN-TF (Bi-LSTM + CNN) | MAE, MSE |
| 2 | S. Majumdar et al. [11] | Real time-Time series | LSTM | Accuracy |
| 3 | T. Bogaerts et al. [13] | Real-time GPS Time series | Graph CNN + LSTM | MAE, MAPE, RMSE |
| 4 | S. Neelakandan et al. [14] | Time series | OWENN | Accuracy, F- score |
| 5 | Aid A. Khan et al. [15] | M1 junction 37 England | MSR2C-ABPNN | Accuracy, RMSE |
| 6 | V. Rajalakshmi et al. [16] | UK highway | ARIMA + MLP/ ARIMA + RNN | MAE, MSE, RMSE and R2 |
| 7 | Lu. Saiqun et al. [17] | Three trunk highway dataset of England | ARIMA + LSTM using BPNN | MAE, MSE, RMSE, MAPE |
| 8 | N. Zafar et al. [9] | FCD data source (data collected by a company) | LSTM + GRU | RMSE, MAPE |
| 9 | M. Zahid et al. [24] | Real-time dataset of Ring Road, Bejing, China | Decision jungle, Local Deep SVM, MLP | F1 score, Accuracy |
| S. No. | Feature | Significance |
|---|---|---|
| 1 | Status | This feature gives the status report of the IoT sensor device used. |
| 2 | avgMeasuredTime | It gives average measured time. |
| 3 | avgSpeed | It gives the average speed of a vehicle for the given time. |
| 4 | medianMeasuredtime | It provides a median time for the sensor to measure speed and count. |
| 5 | TIMESTAMP | This feature gives the exact timestamp for which the vehicle counts and the average speed of the vehicle. |
| 6 | vehicleCount | It gives the number of vehicles on the street for a particular time interval. |
| 7 | _id | It gives the ID of a sensor device. |
| 8 | Report_id | Report ID gives the ID for a particular area location for which all the above features are observed. |
| Hyper Parameter | Bi-LSTM |
|---|---|
| Optimizer | Adam |
| Learning rate | 0.001 |
| Activation function | Sigmoid (layer 1), tanh (layer 2) |
| Dropout rate | 0.2 |
| Epochs | 100 |
| S. No. | Model | MSE | MAE | RMSE | MAPE |
|---|---|---|---|---|---|
| 1. | Graph CNN + LSTM [13] | -- | 4.11 | 5.879 | 0.145 |
| 2. | ARIMA + MLP [16] | 0.71 | 0.55 | 0.84 | -- |
| 3. | ARIMA + RNN [16] | 0.66 | 0.53 | 0.81 | -- |
| 4. | ARIMA + LSTM [17] | 241.66 | 6.53 | 15.54 | 0.119 |
| 5. | ARIMA+ LSTM + BP [35] | -- | 20.00 | 33.17 | 14.13 |
| 6. | ANN [36] | -- | 3.866 | -- | -- |
| 7. | SARIMA | 23.36 | 4.06 | 4.63 | 0.388 |
| 8. | Bi-LSTM | 25.62 | 4.2 | 5.06 | 0.31 |
| 9. | SARIMA + Bi-LSTM | 17.79 | 3.04 | 4.21 | 0.20 |
| 10. | Proposed model (SARIMA + Bi-LSTM + BPNN) | 0.337 | 0.499 | 0.58 | 0.03 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chahal, A.; Gulia, P.; Gill, N.S.; Priyadarshini, I. A Hybrid Univariate Traffic Congestion Prediction Model for IoT-Enabled Smart City. Information 2023, 14, 268. https://doi.org/10.3390/info14050268
Chahal A, Gulia P, Gill NS, Priyadarshini I. A Hybrid Univariate Traffic Congestion Prediction Model for IoT-Enabled Smart City. Information. 2023; 14(5):268. https://doi.org/10.3390/info14050268
Chicago/Turabian StyleChahal, Ayushi, Preeti Gulia, Nasib Singh Gill, and Ishaani Priyadarshini. 2023. "A Hybrid Univariate Traffic Congestion Prediction Model for IoT-Enabled Smart City" Information 14, no. 5: 268. https://doi.org/10.3390/info14050268
APA StyleChahal, A., Gulia, P., Gill, N. S., & Priyadarshini, I. (2023). A Hybrid Univariate Traffic Congestion Prediction Model for IoT-Enabled Smart City. Information, 14(5), 268. https://doi.org/10.3390/info14050268