
A Quick Prototype for Assessing OpenIE Knowledge Graph-Based Question-Answering Systems



Abstract
1. Introduction
2. Related Work
2.1. Knowledge Graph Construction
2.2. Knowledge Graph-Based Question Answering
3. Preliminaries on Knowledge Graphs
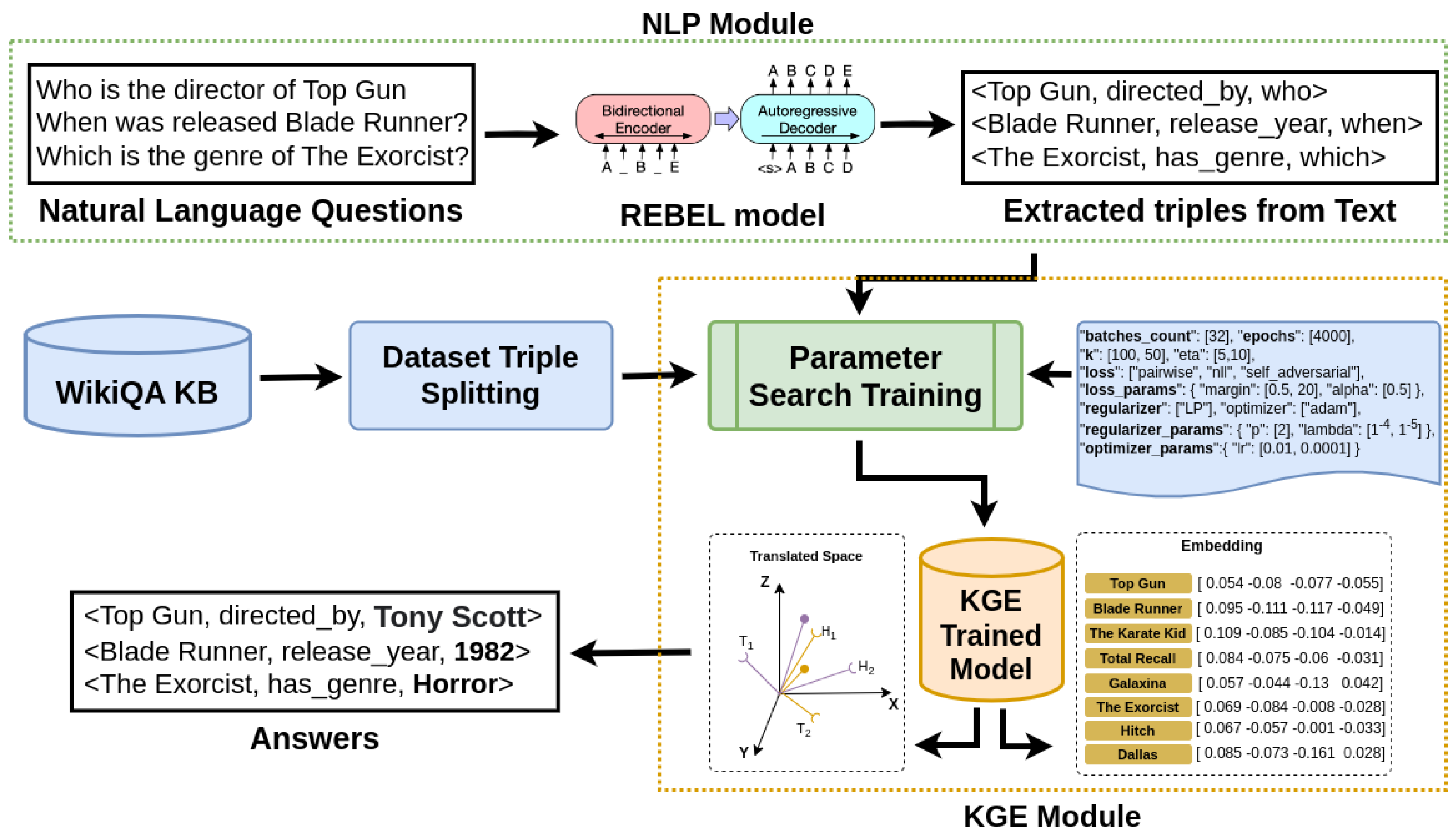
4. The Approach
4.1. NLP Module
4.2. KGE Module
- TransE [36]: It is an energy-based model for learning low-dimensional features of entities. It models relationships by interpreting them as translations acting those low-dimensional embeddings of the entities. The key feature of this model is how well it can automatically add new facts to multi-relational data without the need for additional knowledge.
- DistMult [37]: It forces all the embeddings into diagonal matrices, reducing the dimensional space and transforming the relation into a symmetric one. This makes it unsuitable for general knowledge graphs, since it only uses a diagonal matrix to represent the relationships.
- ComplEx [38]: It handles symmetric and antisymmetric relations, using complex embeddings (real and imaginary parts) involving the conjugate-transpose of one of the two vectors. ComplEx embedding facilitates joint learning of subject and object entities, while preserving the asymmetry of the relation. It uses the Hermitian dot product of embedding subject and object entities. Complex vectors can successfully encapsulate antisymmetric connections, while retaining the efficiency benefits of the dot product, namely linearity in both space and time complexity.
- : denotes the positive part of x;
- : is a margin hyper-parameter;
5. Experimentation
5.1. Dataset
5.2. Question Triple Translation with REBEL
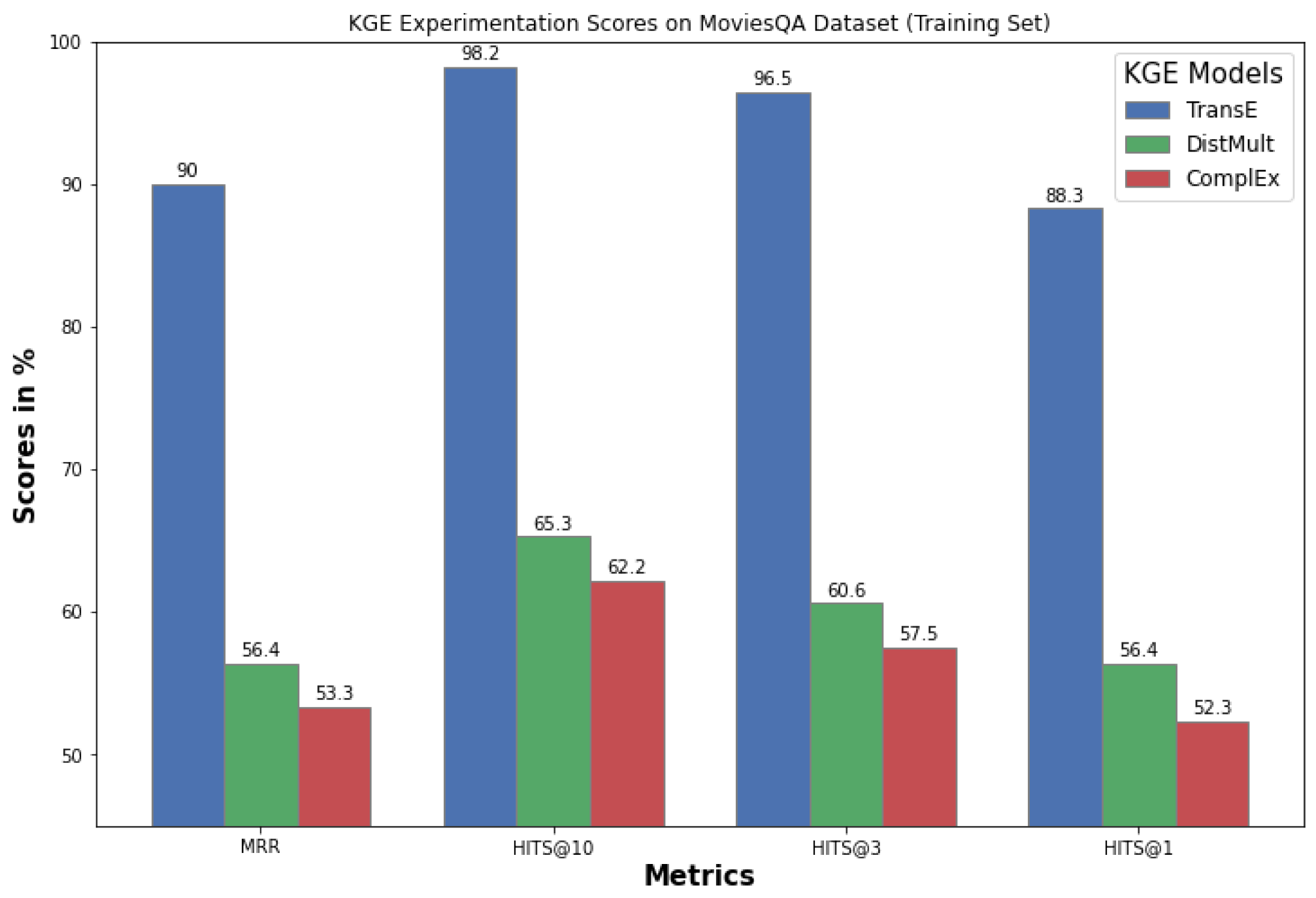
5.3. KGE Evaluation
6. The System at Work: A Use Case
7. Conclusions
- Simple question-answering that exploits existing tools from the literature.
- Leveraging on OpenIE principles to automatically extract structured information from natural language text, guaranteeing scalability, unsupervised learning, flexibility, accuracy, and integration with other natural language processing tools.
- Specializing the system to answer on a selected knowledge base, without retraining the question-triple translator model: in our case, REBEL was tested on a portion of Wikimovies without any pre-training.
- Assessing the quality of a fast composition design in question-answering effectiveness. Our prototypical system shows that the designed pipeline can overcome the state-of-the-art in some specific situations.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Abu-Salih, B. Domain-specific knowledge graphs: A survey. J. Netw. Comput. Appl. 2021, 185, 103076. [Google Scholar] [CrossRef]
- Bonner, S.; Barrett, I.P.; Ye, C.; Swiers, R.; Engkvist, O.; Hoyt, C.T.; Hamilton, W.L. Understanding the performance of knowledge graph embeddings in drug discovery. Artif. Intell. Life Sci. 2022, 2, 100036. [Google Scholar] [CrossRef]
- Wang, M.; Zhang, J.; Liu, J.; Hu, W.; Wang, S.; Li, X.; Liu, W. PDD Graph: Bridging Electronic Medical Records and Biomedical Knowledge Graphs Via Entity Linking. In Proceedings of the Semantic Web–ISWC 2017: 16th International Semantic Web Conference, Vienna, Austria, 21–25 October 2017; Proceedings, Part II. Springer: Berlin/Heidelberg, Germany, 2017; pp. 219–227. [Google Scholar] [CrossRef]
- Mohamed, S.K.; Nounu, A.; Nováček, V. Biological applications of knowledge graph embedding models. Briefings Bioinform. 2021, 22, 1679–1693. [Google Scholar] [CrossRef] [PubMed]
- Day, M.Y. Artificial Intelligence for Knowledge Graphs of Cryptocurrency Anti-Money Laundering in Fintech. In Proceedings of the ASONAM ’21: 2021 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Virtual Event, The Netherlands, 8–11 November 2021; Association for Computing Machinery: New York, NY, USA, 2022; pp. 439–446. [Google Scholar] [CrossRef]
- Wang, H.; Zhao, M.; Xie, X.; Li, W.; Guo, M. Knowledge Graph Convolutional Networks for Recommender Systems. In Proceedings of the WWW ’19: The World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 3307–3313. [Google Scholar] [CrossRef]
- Wu, S.; Wang, M.; Zhang, D.; Zhou, Y.; Li, Y.; Wu, Z. Knowledge-Aware Dialogue Generation via Hierarchical Infobox Accessing and Infobox-Dialogue Interaction Graph Network. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI-21, Montreal, Canada, 19–27 August 2021; Zhou, Z.H., Ed.; International Joint Conferences on Artificial Intelligence Organization: San Francisco, CA, USA, 2021; pp. 3964–3970, Main Track. [Google Scholar] [CrossRef]
- Lukovnikov, D.; Fischer, A.; Lehmann, J.; Auer, S. Neural Network-Based Question Answering over Knowledge Graphs on Word and Character Level. In Proceedings of the WWW ’17: 26th International Conference on World Wide Web, Perth, Australia, 3–7 May 2017; International World Wide Web Conferences Steering Committee: Republic and Canton of Geneva, Switzerland, 2017; pp. 1211–1220. [Google Scholar] [CrossRef]
- Sabou, M.; Höffner, K.; Walter, S.; Marx, E.; Usbeck, R.; Lehmann, J.; Ngonga Ngomo, A.C. Survey on Challenges of Question Answering in the Semantic Web. Semant. Web 2017, 8, 895–920. [Google Scholar] [CrossRef]
- Ji, S.; Pan, S.; Cambria, E.; Marttinen, P.; Yu, P.S. A Survey on Knowledge Graphs: Representation, Acquisition, and Applications. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 494–514. [Google Scholar] [CrossRef] [PubMed]
- Bollacker, K.; Evans, C.; Paritosh, P.; Sturge, T.; Taylor, J. Freebase: A Collaboratively Created Graph Database for Structuring Human Knowledge. In Proceedings of the SIGMOD ’08: 2008 ACM SIGMOD International Conference on Management of Data, Vancouver Canada, 9–12 June 2008; Association for Computing Machinery: New York, NY, USA, 2008; pp. 1247–1250. [Google Scholar] [CrossRef]
- Vrandečić, D.; Krötzsch, M. Wikidata: A Free Collaborative Knowledgebase. Commun. ACM 2014, 57, 78–85. [Google Scholar] [CrossRef]
- Auer, S.; Bizer, C.; Kobilarov, G.; Lehmann, J.; Cyganiak, R.; Ives, Z. DBpedia: A Nucleus for a Web of Open Data. In Lecture Notes in Computer Science, Proceedings of the 6th International Semantic Web Conference (ISWC), Busan, Republic of Korea, 11–15 November 2007; Springer: Berlin/Heidelberg, Germany, 2007; Volume 4825, pp. 722–735. [Google Scholar] [CrossRef]
- Kolluru, K.; Adlakha, V.; Aggarwal, S.; Mausam; Chakrabarti, S. OpenIE6: Iterative Grid Labeling and Coordination Analysis for Open Information Extraction. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Barceló Bávaro Convention Centre, Punta Cana, Dominican Republic, 8–12 November 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 3748–3761. [Google Scholar]
- Martinez-Rodriguez, J.L.; Lopez-Arevalo, I.; Rios-Alvarado, A.B. OpenIE-based approach for Knowledge Graph construction from text. Expert Syst. Appl. 2018, 113, 339–355. [Google Scholar] [CrossRef]
- Huguet Cabot, P.L.; Navigli, R. REBEL: Relation Extraction By End-to-end Language generation. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2021, Punta Cana, Dominican Republic, 16–20 November 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 2370–2381. [Google Scholar] [CrossRef]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 7871–7880. [Google Scholar] [CrossRef]
- Miller, A.; Fisch, A.; Dodge, J.; Karimi, A.H.; Bordes, A.; Weston, J. Key-Value Memory Networks for Directly Reading Documents. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; pp. 1400–1409. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, J.; Li, D.; Li, P. Knowledge Graph Embedding Based Question Answering. In Proceedings of the WSDM ’19: Twelfth ACM International Conference on Web Search and Data Mining, Melbourne, Australia, 11–15 February 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 105–113. [Google Scholar] [CrossRef]
- Bastos, A.; Nadgeri, A.; Singh, K.; Mulang, I.O.; Shekarpour, S.; Hoffart, J.; Kaul, M. RECON: Relation Extraction Using Knowledge Graph Context in a Graph Neural Network. In Proceedings of the WWW ’21: Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 1673–1685. [Google Scholar] [CrossRef]
- Gui, T.; Zou, Y.; Zhang, Q.; Peng, M.; Fu, J.; Wei, Z.; Huang, X. A Lexicon-Based Graph Neural Network for Chinese NER. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 1040–1050. [Google Scholar] [CrossRef]
- Lin, Y.; Shen, S.; Liu, Z.; Luan, H.; Sun, M. Neural Relation Extraction with Selective Attention over Instances. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016. [Google Scholar]
- Han, X.; Gao, T.; Yao, Y.; Ye, D.; Liu, Z.; Sun, M. OpenNRE: An Open and Extensible Toolkit for Neural Relation Extraction. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP): System Demonstrations, Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 169–174. [Google Scholar] [CrossRef]
- Xie, R.; Liu, Z.; Jia, J.; Luan, H.; Sun, M. Representation Learning of Knowledge Graphs with Entity Descriptions. In Proceedings of the AAAI’16: Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 2659–2665. [Google Scholar] [CrossRef]
- Della Rocca, P.; Senatore, S.; Loia, V. A semantic-grained perspective of latent knowledge modeling. Inf. Fusion 2017, 36, 52–67. [Google Scholar] [CrossRef]
- Chen, X.; Zhang, N.; Xie, X.; Deng, S.; Yao, Y.; Tan, C.; Huang, F.; Si, L.; Chen, H. KnowPrompt: Knowledge-Aware Prompt-Tuning with Synergistic Optimization for Relation Extraction. In Proceedings of the WWW ’22: ACM Web Conference 2022, Online, 25–29 April 2022; Association for Computing Machinery: New York, NY, USA, 2022; pp. 2778–2788. [Google Scholar] [CrossRef]
- Zhang, N.; Xu, X.; Tao, L.; Yu, H.; Ye, H.; Xie, X.; Chen, X.; Li, Z.; Li, L.; Liang, X.; et al. DeepKE: A Deep Learning Based Knowledge Extraction Toolkit for Knowledge Base Population. arXiv 2022, arXiv:2201.03335. [Google Scholar]
- Hogan, A.; Blomqvist, E.; Cochez, M.; D’amato, C.; Melo, G.D.; Gutierrez, C.; Kirrane, S.; Gayo, J.E.L.; Navigli, R.; Neumaier, S.; et al. Knowledge Graphs. ACM Comput. Surv. 2021, 54, 1–37. [Google Scholar] [CrossRef]
- Carlson, A.; Betteridge, J.; Kisiel, B.; Settles, B.; Hruschka, E.R.; Mitchell, T.M. Toward an Architecture for Never-Ending Language Learning. In Proceedings of the AAAI’10: Twenty-Fourth AAAI Conference on Artificial Intelligence, Atlanta GA, USA, 11–15 July 2010; AAAI Press: Washington, DC, USA, 2010; pp. 1306–1313. [Google Scholar]
- Fellbaum, C. (Ed.) WordNet: An Electronic Lexical Database; Language, Speech, and Communication; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Suchanek, F.M.; Kasneci, G.; Weikum, G. Yago: A Core of Semantic Knowledge. In Proceedings of the WWW ’07: 16th International Conference on World Wide Web, Banff, AB, Canada, 8–12 May 2007; Association for Computing Machinery: New York, NY, USA, 2007; pp. 697–706. [Google Scholar] [CrossRef]
- Jagvaral, B.; Lee, W.K.; Roh, J.S.; Kim, M.S.; Park, Y.T. Path-based reasoning approach for knowledge graph completion using CNN-BiLSTM with attention mechanism. Expert Syst. Appl. 2020, 142, 112960. [Google Scholar] [CrossRef]
- Jain, N.; Tran, T.K.; Gad-Elrab, M.H.; Stepanova, D. Improving Knowledge Graph Embeddings with Ontological Reasoning. In Proceedings of the Semantic Web–ISWC 2021, Virtual, 24–28 October 2021; Hotho, A., Blomqvist, E., Dietze, S., Fokoue, A., Ding, Y., Barnaghi, P., Haller, A., Dragoni, M., Alani, H., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 410–426. [Google Scholar]
- Chen, W.; Cao, Y.; Feng, F.; He, X.; Zhang, Y. Explainable Sparse Knowledge Graph Completion via High-order Graph Reasoning Network. arXiv 2022, arXiv:2207.07503. [Google Scholar]
- Chen, X.; Jia, S.; Xiang, Y. A review: Knowledge reasoning over knowledge graph. Expert Syst. Appl. 2020, 141, 112948. [Google Scholar] [CrossRef]
- Bordes, A.; Usunier, N.; Garcia-Durán, A.; Weston, J.; Yakhnenko, O. Translating embeddings for modeling multi-relational data. In Proceedings of the NIPS’13: Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; Curran Associates Inc.: Red Hook, NY, USA, 2013; pp. 2787–2795. [Google Scholar]
- Yang, B.; Yih, W.t.; He, X.; Gao, J.; Deng, L. Embedding Entities and Relations for Learning and Inference in Knowledge Bases. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015; p. 12. [Google Scholar]
- Trouillon, T.; Welbl, J.; Riedel, S.; Gaussier, E.; Bouchard, G. Complex Embeddings for Simple Link Prediction. In Proceedings of Machine Learning Research, Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; Balcan, M.F., Weinberger, K.Q., Eds.; PMLR: New York, NY, USA, 2016; Volume 48, pp. 2071–2080. [Google Scholar]
- Chami, I.; Wolf, A.; Juan, D.C.; Sala, F.; Ravi, S.; Ré, C. Low-Dimensional Hyperbolic Knowledge Graph Embeddings. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Stroudsburg, PA, USA; pp. 6901–6914. [Google Scholar] [CrossRef]
- Ren, H.; Dai, H.; Dai, B.; Chen, X.; Yasunaga, M.; Sun, H.; Schuurmans, D.; Leskovec, J.; Zhou, D. LEGO: Latent Execution-Guided Reasoning for Multi-Hop Question Answering on Knowledge Graphs. In Proceedings of Machine Learning Research, Proceedings of the 38th International Conference on Machine Learning, Online, 18–24 July 2021; Meila, M., Zhang, T., Eds.; PMLR: New York, NY, USA, 2021; Volume 139, pp. 8959–8970. [Google Scholar]
- Bast, H.; Haussmann, E. More Accurate Question Answering on Freebase. In Proceedings of the CIKM 15: 24th ACM International on Conference on Information and Knowledge Management, Melbourne, Australia, 19–23 October 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 1431–1440. [Google Scholar] [CrossRef]
- Cohen, W.W.; Sun, H.; Hofer, R.A.; Siegler, M. Scalable Neural Methods for Reasoning With a Symbolic Knowledge Base. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Sen, P.; Oliya, A.; Saffari, A. Expanding End-to-End Question Answering on Differentiable Knowledge Graphs with Intersection. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021f; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 8805–8812. [Google Scholar] [CrossRef]
- Lan, Y.; Jiang, J. Query Graph Generation for Answering Multi-hop Complex Questions from Knowledge Bases. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 969–974. [Google Scholar] [CrossRef]
- Qiu, Y.; Zhang, K.; Wang, Y.; Jin, X.; Bai, L.; Guan, S.; Cheng, X. Hierarchical Query Graph Generation for Complex Question Answering over Knowledge Graph. In Proceedings of the CIKM ’20: 29th ACM International Conference on Information and Knowledge Management, Virtual, 19–23 October 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 1285–1294. [Google Scholar] [CrossRef]
- Qiu, Y.; Wang, Y.; Jin, X.; Zhang, K. Stepwise Reasoning for Multi-Relation Question Answering over Knowledge Graph with Weak Supervision. In Proceedings of the WSDM ’20: 13th International Conference on Web Search and Data Mining, Houston, TX, USA, 3–7 February 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 474–482. [Google Scholar] [CrossRef]
- Sun, H.; Dhingra, B.; Zaheer, M.; Mazaitis, K.; Salakhutdinov, R.; Cohen, W. Open Domain Question Answering Using Early Fusion of Knowledge Bases and Text. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; Association for Computational Linguistics: Brussels, Belgium, 2018; pp. 4231–4242. [Google Scholar] [CrossRef]
- Lu, X.; Pramanik, S.; Saha Roy, R.; Abujabal, A.; Wang, Y.; Weikum, G. Answering Complex Questions by Joining Multi-Document Evidence with Quasi Knowledge Graphs. In Proceedings of the SIGIR’19: 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 105–114. [Google Scholar] [CrossRef]
- Yani, M.; Krisnadhi, A.A. Challenges, Techniques, and Trends of Simple Knowledge Graph Question Answering: A Survey. Information 2021, 12, 271. [Google Scholar] [CrossRef]
- Liang, C.; Norouzi, M.; Berant, J.; Le, Q.; Lao, N. Memory Augmented Policy Optimization for Program Synthesis and Semantic Parsing. In Proceedings of the NIPS’18: 32nd International Conference on Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; Curran Associates Inc.: Red Hook, NY, USA, 2018; pp. 10015–10027. [Google Scholar]
- Chen, X.; Liang, C.; Yu, A.W.; Zhou, D.; Song, D.; Le, Q.V. Neural Symbolic Reader: Scalable Integration of Distributed and Symbolic Representations for Reading Comprehension. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Chen, X.; Liang, C.; Yu, A.W.; Song, D.; Zhou, D. Compositional Generalization via Neural-Symbolic Stack Machines. In Proceedings of the NIPS’20: 34th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020; Curran Associates Inc.: Red Hook, NY, USA, 2020. [Google Scholar]
- Sun, H.; Arnold, A.O.; Bedrax-Weiss, T.; Pereira, F.; Cohen, W.W. Faithful Embeddings for Knowledge Base Queries. In Proceedings of the NIPS’20: 34th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020; Curran Associates Inc.: Red Hook, NY, USA, 2020. [Google Scholar]
- Shi, J.; Cao, S.; Hou, L.; Li, J.Z.; Zhang, H. TransferNet: An Effective and Transparent Framework for Multi-hop Question Answering over Relation Graph. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021. [Google Scholar]
- Rincon-Yanez, D.; Senatore, S. FAIR Knowledge Graph construction from text, an approach applied to fictional novels. In Proceedings of the 1st International Workshop on Knowledge Graph Generation from Text and the 1st International Workshop on Modular Knowledge co-located with 19th Extended Semantic Web Conference (ESWC 2022), Hersonissos, Greece, 30 May 2022; pp. 94–108. [Google Scholar]
- Diamantini, C.; Potena, D.; Storti, E. A Knowledge-Based Approach to Support Analytic Query Answering in Semantic Data Lakes. In Proceedings of the Advances in Databases and Information Systems, Turin, Italy, 5–8 September 2022; Chiusano, S., Cerquitelli, T., Wrembel, R., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 179–192. [Google Scholar]
- Xiangrong, Z.; Daojian, Z.; Shizhu, H.; Kang, L.; Jun, Z. Extracting Relational Facts by an End-to-End Neural Model with Copy Mechanism. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 506–514. [Google Scholar] [CrossRef]
- Roth, D.; Yih, W.t. A Linear Programming Formulation for Global Inference in Natural Language Tasks. In Proceedings of the Eighth Conference on Computational Natural Language Learning (CoNLL-2004) at HLT-NAACL 2004, Boston, MA, USA, 6–7 May 2004; Association for Computational Linguistics: Stroudsburg, PA, USA, 2004; pp. 1–8. [Google Scholar]
- Yao, Y.; Ye, D.; Li, P.; Han, X.; Lin, Y.; Liu, Z.; Liu, Z.; Huang, L.; Zhou, J.; Sun, M. DocRED: A Large-Scale Document-Level Relation Extraction Dataset. In Proceedings of the ACL 2019, Florence, Italy, 28 July–2 August 2019. [Google Scholar]
- Gurulingappa, H.; Rajput, A.M.; Roberts, A.; Fluck, J.; Hofmann-Apitius, M.; Toldo, L. Development of a benchmark corpus to support the automatic extraction of drug-related adverse effects from medical case reports. J. Biomed. Inform. 2012, 45, 885–892. [Google Scholar] [CrossRef] [PubMed]
- Zhang, M. Artificial Higher Order Neural Networks for Economics and Business, 1st ed.; Information Science Reference: Hershey, PA, USA, 2009; Volume 1, p. 517. [Google Scholar]
- Liu, Y.; Zhang, T.; Liang, Z.; Ji, H.; McGuinness, D.L. Seq2RDF: An End-to-end Application for Deriving Triples from Natural Language Text. In CEUR Workshop Proceedings, Proceedings of the ISWC 2018 Posters & Demonstrations, Industry and Blue Sky Ideas Tracks Co-Located with 17th International Semantic Web Conference (ISWC 2018), Monterey, CA, USA, 8–12 October 2018; van Erp, M., Atre, M., López, V., Srinivas, K., Fortuna, C., Eds.; CEUR-WS.org: Aachen, Germany, 2018; Volume 2180. [Google Scholar]
- Rossi, A.; Barbosa, D.; Firmani, D.; Matinata, A.; Merialdo, P. Knowledge graph embedding for link prediction: A comparative analysis. ACM Trans. Knowl. Discov. Data 2021, 15, 1–49. [Google Scholar] [CrossRef]
- Kazemi, S.M.; Poole, D. SimplE Embedding for Link Prediction in Knowledge Graphs. In Proceedings of the NIPS’18: 32nd International Conference on Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; Curran Associates Inc.: Red Hook, NY, USA, 2018; pp. 4289–4300. [Google Scholar]
- Du, Y.; Mordatch, I. Implicit generation and modeling with energy-based models. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Di-Paolo, G.; Rincon-Yanez, D.; Senatore, S. FastKGQA: A Modified Knowledge Base of the MoviesQA Dataset for Prototyping. Zenodo 2023. [Google Scholar] [CrossRef]
- Nayyeri, M.; Xu, C.; Hoffmann, F.; Alam, M.M.; Lehmann, J.; Vahdati, S. Knowledge Graph Representation Learning using Ordinary Differential Equations. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 9529–9548. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Property | TransE | DistMult | ComplEx |
|---|---|---|---|
| Scoring Function | |||
| Type | Translational | Bilinear | Negative Log |
| Family | Geometric | Matrix Factorization | Matrix Factorization |
| Interpretability | High | Medium | Low |
| Performance | Low | Medium | High |
| Complexity | Low | Medium | High |
| Parameter | Value |
|---|---|
| batches count | 32 |
| seed | 0 |
| epochs | 200 |
| k | 100 |
| eta | 100 |
| regularizer | LP |
| optimizer | adam |
| Regularizer | p2 |
| Regularizer | lambda |
| Optimizer:lr | 0.002 |
| negative corruption entities | batch |
| loss | self adversarial |
| loss params: margin | 10 |
| loss params: alpha | 0.001 |
| Model | MRR | Hits@1 | Hits@3 | Hits@10 |
|---|---|---|---|---|
| REBEL + TransE | 88.2 | 85.7 | 96.3 | 98.4 |
| REBEL + DistMult | 41.7 | 40.6 | 47.4 | 41.7 |
| REBEL + ComplEx | 43.7 | 43.2 | 45.4 | 49.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Di Paolo, G.; Rincon-Yanez, D.; Senatore, S. A Quick Prototype for Assessing OpenIE Knowledge Graph-Based Question-Answering Systems. Information 2023, 14, 186. https://doi.org/10.3390/info14030186
Di Paolo G, Rincon-Yanez D, Senatore S. A Quick Prototype for Assessing OpenIE Knowledge Graph-Based Question-Answering Systems. Information. 2023; 14(3):186. https://doi.org/10.3390/info14030186
Chicago/Turabian StyleDi Paolo, Giuseppina, Diego Rincon-Yanez, and Sabrina Senatore. 2023. "A Quick Prototype for Assessing OpenIE Knowledge Graph-Based Question-Answering Systems" Information 14, no. 3: 186. https://doi.org/10.3390/info14030186
APA StyleDi Paolo, G., Rincon-Yanez, D., & Senatore, S. (2023). A Quick Prototype for Assessing OpenIE Knowledge Graph-Based Question-Answering Systems. Information, 14(3), 186. https://doi.org/10.3390/info14030186