
Aspect-Based Sentiment Analysis with Dependency Relation Weighted Graph Attention

Abstract
1. Introduction
- We use a BERT-pretrained sentiment corpus for word embedding of input text. In such case, BERT can better capture the sentiment information in the text during pretraining, and demonstrate the superiority of the sentiment pretraining model compared to the normal pretraining model in sentiment analysis tasks through experimental results.
- We probe deep into the text for dependency syntax, set initial weights for dissimilar dependencies in line with their relative importance for sentiment classification, and further optimise them through model training.
- We come up with a relation-weighted graph attention network model (WGAT). This model ameliorates the existing attention mechanism and weights the attention score. In this way, the model can assign weights according to the importance of different types of dependencies, so as to concentrate more on important dependencies and heighten classification accuracy.
- Experiments on different datasets prove the effectiveness of our proposed method, whereby the effect of our model is better than other baseline models.
2. Related Work
3. Methodology
3.1. Task Definition
3.2. Word Embedding Layer
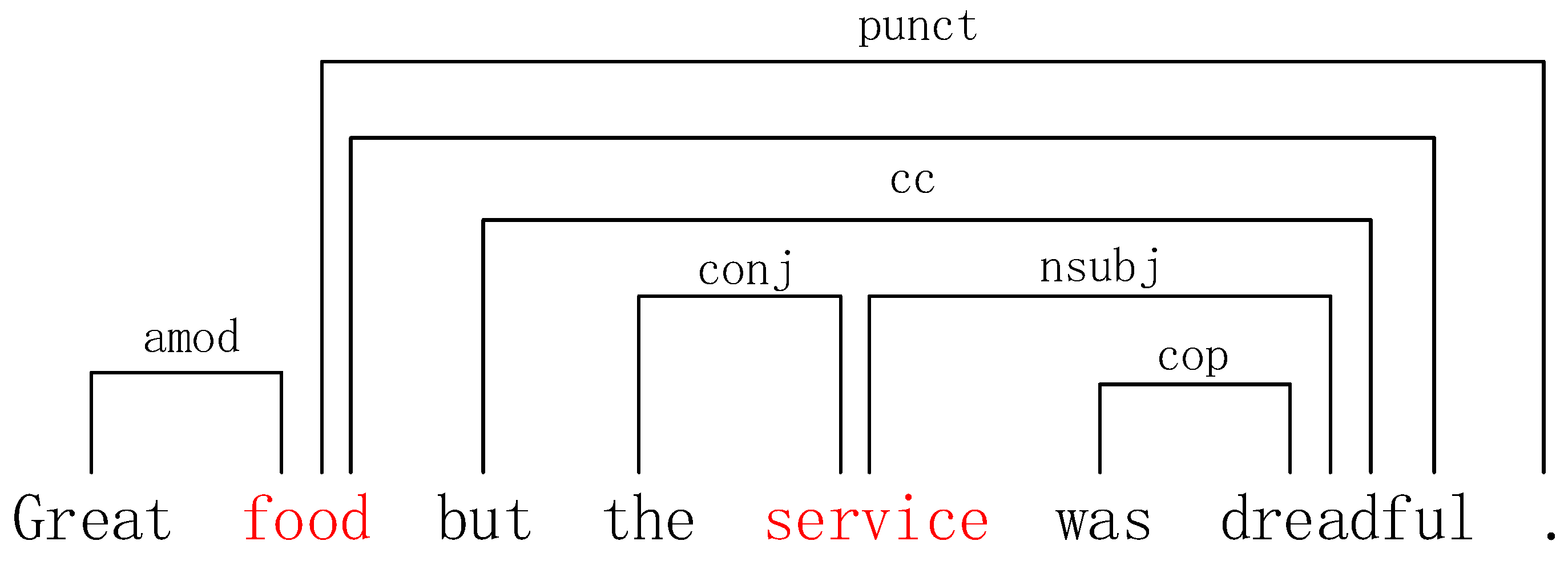
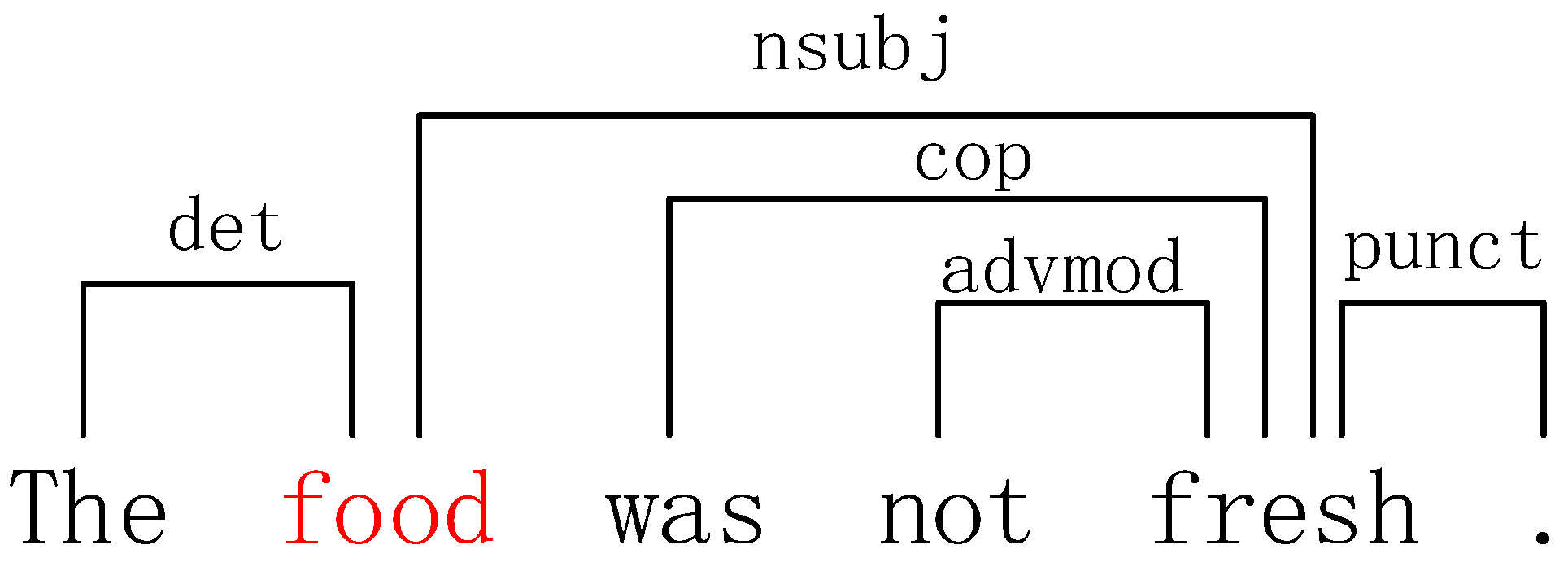
3.3. Syntactic Analysis Layer
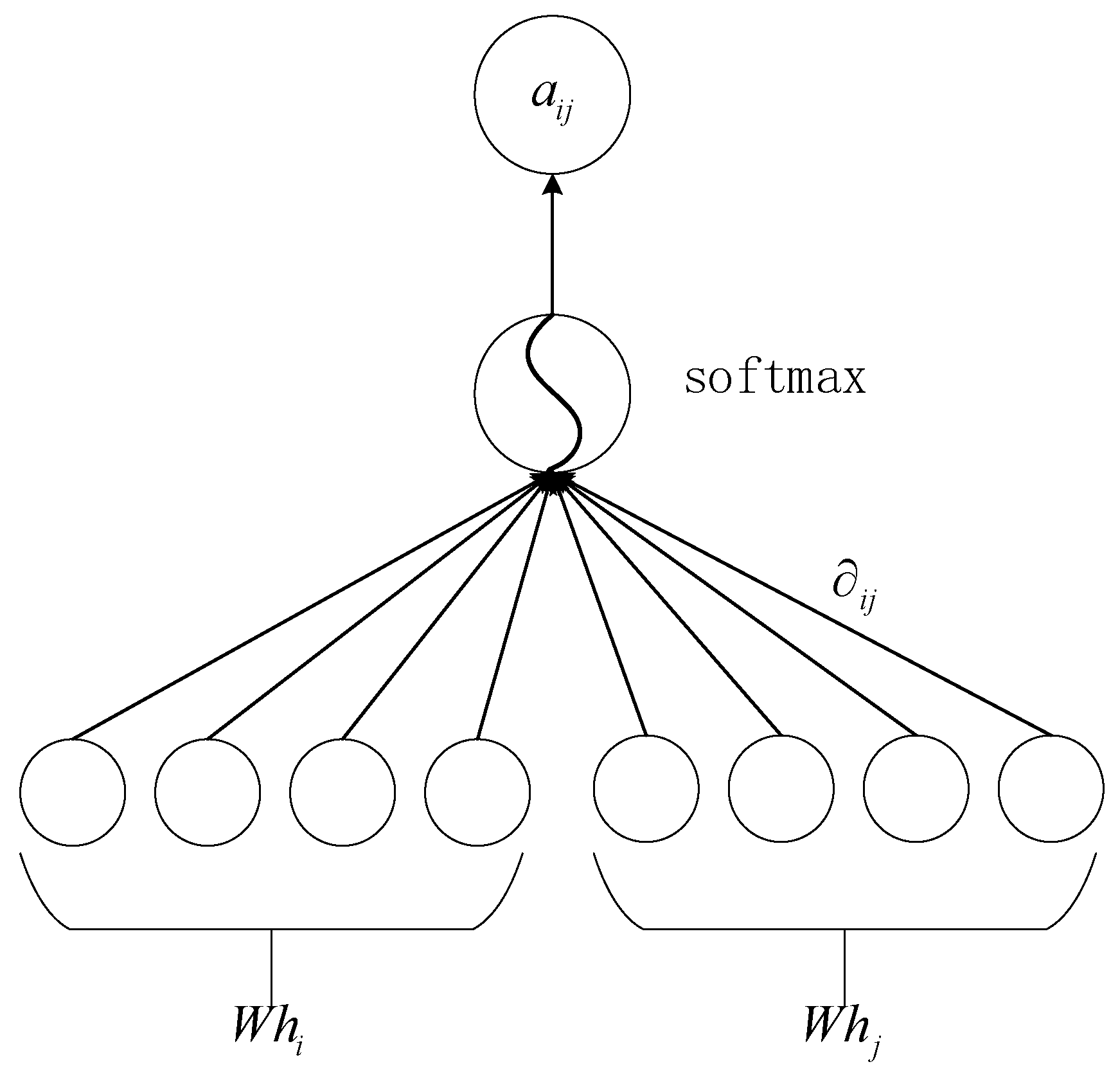
3.4. Graph Attention Network Layer
3.5. Emotional Classification Layer
4. Experiment
4.1. Dataset
4.2. Hyperparameter Setting
4.3. Evaluation Metrics
4.4. Comparison Models
4.5. Experiment Results
4.6. Ablation Studies
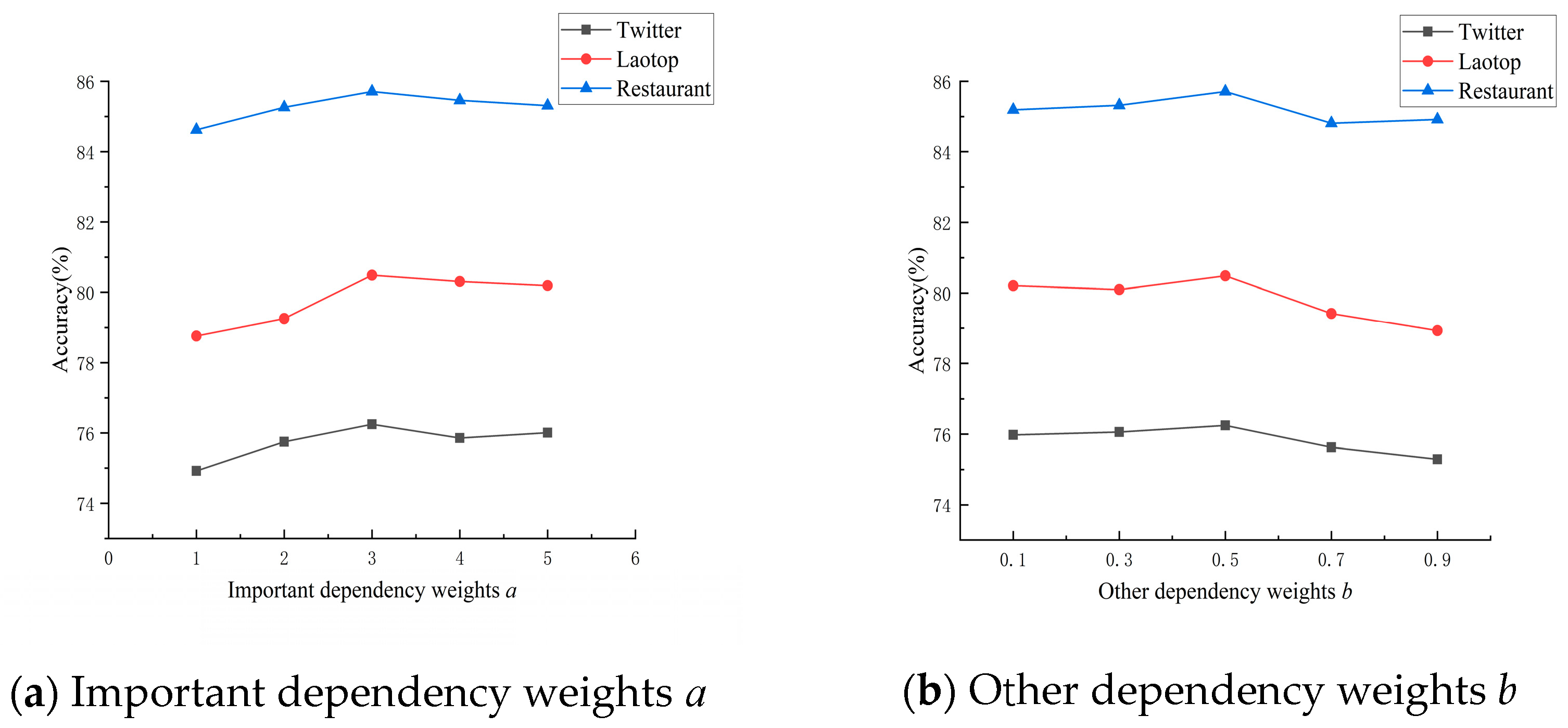
4.7. Effect of Initial Values of Weights
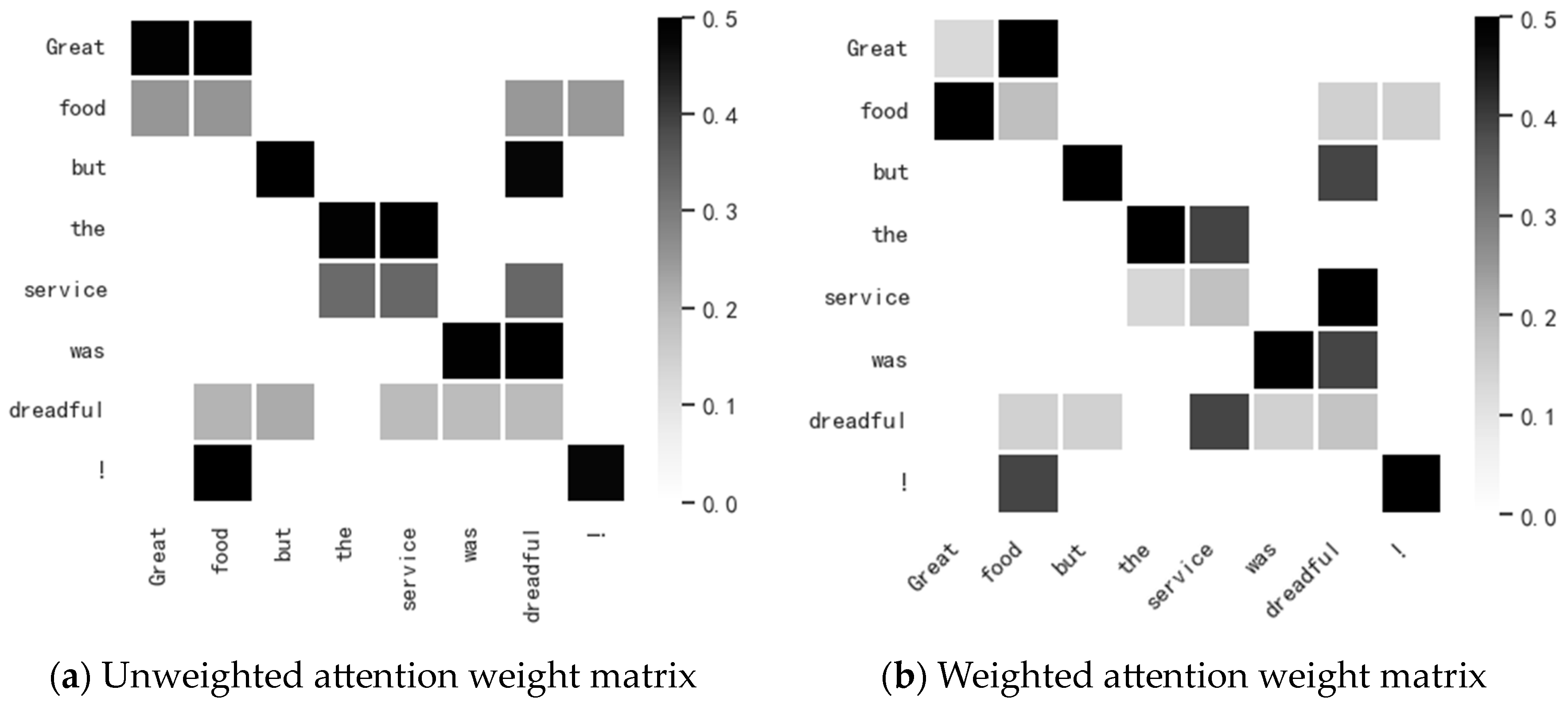
4.8. Visualisation of Attention Mechanisms
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, L.; Wang, S.; Liu, B. Deep Learning for Sentiment Analysis: A Survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1253. [Google Scholar] [CrossRef]
- Wang, T.; Yang, W. Review of Text Sentiment Analysis Methods. Comput. Eng. Appl. 2021, 57, 11–24. [Google Scholar]
- Zhang, Y.; Li, T. Review of Comment-oriented Aspect-based Sentiment Analysis. Comput. Sci. 2020, 47, 7. [Google Scholar] [CrossRef]
- Tang, X.; Liu, G. Research Review on Fine-grained Sentiment Analysis. Libr. Inf. Serv. 2017, 61, 132–140. [Google Scholar]
- Wang, S.Y.; Yuan, K. Sentiment analysis model of college student forum based on RoBERTa-WWM. Comput. Eng. 2022, 48, 292–298, 305. [Google Scholar]
- Shen, Y.; Zhao, X. A Review of Research on Aspect-based Sentiment Analysis based on Deep Learing. Inf. Techol. Stand. 2020, 1, 50–53. [Google Scholar]
- Tang, D.; Qin, B.; Feng, X.; Liu, T. Effective LSTMs for target-dependent sentiment classification. In Proceedings of the 26th International Conference on Computational Linguistics, Osaka, Japan, 11–16 December 2016; pp. 3298–3307. [Google Scholar]
- Wang, Y.; Huang, M.; Zhu, X.; Zhao, L. Attention-based LSTM for aspect-based sentiment classification. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 606–615. [Google Scholar]
- Ma, D.; Li, S.; Zhang, X.; Wang, H. Interactive attention networks for aspect-based sentiment classification. In Proceedings of the 26th International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; pp. 4068–4074. [Google Scholar]
- Meng, F.; Feng, J.; Yin, D.; Chen, S.; Hu, M. Sentiment Analysis with Weighted Graph Convolutional Networks. In EMNLP (Findings); Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 586–595. [Google Scholar]
- Zhang, C.; Li, Q.; Song, D. Aspect-based Sentiment Classification with Aspect-specific Graph Convolutional Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 3–7 November 2019; ACL: Stroudsburg, PA, USA, 2019; pp. 4560–4570. [Google Scholar]
- Mubarok, M.S.; Adiwijaya; Aldhi, M.D. Aspect-based sentiment analysis to review products using Naïve Bayes. AIP Conf. Proc. 2017, 1867, 020060. [Google Scholar]
- Kiritchenko, S.; Zhu, X.; Cherry, C.; Mohammad, S. NRC-Canada-2014: Detecting Aspects and Sentiment in Customer Reviews. In Proceedings of the 8th International Workshop on Semantic Evaluation, Dublin, Ireland, 23–24 August 2014; pp. 437–442. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional Transformer for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 4171–4186. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the 27th Annual Conference on Neural Information Processing Systems 2013, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 3111–3119. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Tang, D.; Qin, B.; Liu, T. Aspect level sentiment classification with deep memory network. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 214–224. [Google Scholar]
- Song, Y.; Wang, J.; Jiang, T.; Liu, Z.; Rao, Y. Targeted sentiment classification with attentional encoder network. In International Conference on Artificial Neural Networks; Springer: Cham, Switzerland, 2019; pp. 93–103. [Google Scholar]
- Zeng, B.; Yang, H.; Xu, R.; Zhou, W.; Han, X. LCF: A Local Context Focus Mechanism for Aspect-Based Sentiment Classification. Appl. Sci. 2019, 9, 3389. [Google Scholar] [CrossRef]
- Tang, X.; Xiao, L. Research on Micro-Blog Topics Mining Model on Dependency Parsing. Inf. Sci. 2021, 57, 11–24. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Huang, X.; Carley, K. Syntax-aware aspect level sentiment classification with graph attention networks. In Proceedings of the Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing(EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 5469–5477. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Wang, K.; Shen, W.; Yang, Y.; Quan, X.; Wang, R. Relational Graph Attention Network for Aspect-based Sentiment Analysis. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 6–8 July 2020; pp. 3229–3238. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; p. 30. [Google Scholar]
- Zhang, D.; Huang, L.; Zhang, R.; Xue, H.; Lin, J.; Yao, L. Fake Review Detection Based on Joint Topic and Sentiment Pre-Training Model. J. Compt. Res. Dev. 2021, 58, 1385–1394. [Google Scholar]
- de Marneffe, M.C.; Manning, C.D. Stanford Typed Dependencies Manual; Technical report; Stanford University: Stanford, CA, USA, 2008. [Google Scholar]
- Pontiki, M.; Galanis, D.; Pavlopoulos, J.; Papageorgiou, H.; Androutsopoulos, I.; Manandhar, S. SemEval-2014 task 4: Aspect based sentiment analysis. In Proceedings of the 8th International Workshop on Semantic Evaluation, Dublin, Ireland, 23–24 August 2014; 24 August 2014; pp. 27–35. [Google Scholar]
- Dong, L.; Wei, F.; Tan, C.; Tang, D.; Zhou, M.; Xu, K. Adaptive recursive neural network for target-dependent twitter sentiment classification. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, Baltimore, Maryland, 22–27 June 2014; Volume 2, pp. 49–54, Short papers. [Google Scholar]
- Zhang, M.; Qian, T. Convolution over Hierarchical Syntactic and Lexical Graphs for Aspect Level Sentiment Analysis. In Empirical Methods in Natural Language Processing; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 3540–3549. [Google Scholar]
- Wang, G.; Li, H.; Qiu, Y.; Yu, B.; Liu, T. Aspect-based Sentiment Classification via Memory Graph Convolutional Network. J. Chin. Inf. Process. 2021, 35, 98–106. [Google Scholar]
- Zhu, L.; Zhu, X.; Guo, J.; Dietze, S. Exploring rich structure information for aspect-based sentiment classification. J. Intell. Inf. Syst. 2022, 60, 97–117. [Google Scholar] [CrossRef]
- Liang, B.; Su, H.; Gui, L.; Cambria, E.; Xu, R. Aspect-based sentiment analysis via affective knowledge enhanced graph convolutional networks. Knowl.-Based Syst. 2022, 235, 107643. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Positive | Negative | Neutral | |||
|---|---|---|---|---|---|---|
| Train | Test | Train | Test | Train | Test | |
| Laptop | 994 | 341 | 870 | 128 | 464 | 169 |
| Restaurant | 2164 | 728 | 807 | 196 | 637 | 196 |
| 1561 | 173 | 1560 | 173 | 3127 | 346 | |
| Parameter | Value |
|---|---|
| Batch size | 16 |
| Dropout rate | 0.1 |
| Epoch | 6 |
| L2 regularisation coefficient | 0.000001 |
| Optimiser | Adam |
| Maximum sentence length | 80 |
| Dataset | Restaurant | Laptop | ||||
|---|---|---|---|---|---|---|
| Acc | F1 | Acc | F1 | Acc | F1 | |
| TD-LSTM | - | - | 75.63 * | - | 68.13 * | - |
| ATAE-LSTM | - | - | 77.20 * | - | 68.70 * | - |
| MEMNET | 68.50 | 67.48 | 77.36 | 67.36 | 71.56 | 65.34 |
| IAN | 67.92 | 65.61 | 76.47 | 67.49 | 71.88 | 66.16 |
| ASGCN | 70.95 | 69.46 | 77.92 | 69.98 | 73.41 | 69.05 |
| Bi-GCN | 70.12 | 68.94 | 78.25 | 70.21 | 74.15 | 69.12 |
| TD-GAT | 71.35 | 69.17 | 79.11 | 71.64 | 75.21 | 72.09 |
| BERT-SPC | 73.12 | 71.32 | 81.02 | 72.81 | 77.81 | 73.41 |
| BERT-AEN | 73.70 | 72.10 | 81.69 | 73.64 | 77.19 | 72.57 |
| BERT-LCF | 73.84 | 72.87 | 82.13 | 74.52 | 78.12 | 73.43 |
| Mem-BERT | 73.13 | 71.94 | 84.76 | 78.46 | 78.70 | 74.06 |
| SEDC-GCN | 73.56 | 71.34 | 84.33 | 79.12 | 77.74 | 74.68 |
| R-GAT-BERT | 74.86 | 72.52 | 84.55 | 78.34 | 78.73 | 75.12 |
| SenticGCN | 74.69 | 72.28 | 84.82 | 79.37 | 79.13 | 76.06 |
| WGAT-SBERT | 76.25 | 74.56 | 85.71 | 80.23 | 80.49 | 77.21 |
| Dataset | Restaurant | Laptop | ||||
|---|---|---|---|---|---|---|
| Acc | F1 | Acc | F1 | Acc | F1 | |
| GAT-Glove | 69.92 | 67.68 | 76.64 | 67.91 | 72.35 | 67.37 |
| WGAT-Glove | 72.05 | 69.23 | 79.84 | 70.11 | 75.95 | 72.24 |
| GAT-SBERT | 73.12 | 71.39 | 83.16 | 76.69 | 77.12 | 73.50 |
| WGAT-BERT | 75.13 | 72.76 | 84.75 | 78.53 | 79.32 | 76.03 |
| WGAT-SBERT | 76.25 | 74.56 | 85.71 | 80.23 | 80.49 | 77.21 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, T.; Wang, Z.; Yang, M.; Li, C. Aspect-Based Sentiment Analysis with Dependency Relation Weighted Graph Attention. Information 2023, 14, 185. https://doi.org/10.3390/info14030185
Jiang T, Wang Z, Yang M, Li C. Aspect-Based Sentiment Analysis with Dependency Relation Weighted Graph Attention. Information. 2023; 14(3):185. https://doi.org/10.3390/info14030185
Chicago/Turabian StyleJiang, Tingyao, Zilong Wang, Ming Yang, and Cheng Li. 2023. "Aspect-Based Sentiment Analysis with Dependency Relation Weighted Graph Attention" Information 14, no. 3: 185. https://doi.org/10.3390/info14030185
APA StyleJiang, T., Wang, Z., Yang, M., & Li, C. (2023). Aspect-Based Sentiment Analysis with Dependency Relation Weighted Graph Attention. Information, 14(3), 185. https://doi.org/10.3390/info14030185