2.2. Related Work
As technology progresses, the tax base grows, and many governments attempt to improve tax compliance. The degree to which taxpayers comply (or do not comply) with their country’s tax regulations is known as tax compliance [
11]. Most developing countries, in particular, need to improve VAT compliance since it dominates other tax revenues. The slight rise in VAT has a significant influence on most developing nations. It helps them mobilize domestic revenues, which is why governments have invested in VAT to boost their return [
3].
Many developing countries focus on taxation to reduce their reliance on aid or a single source of income for growth. The government’s efforts to increase tax revenue are hampered by rampant tax fraud among citizens. According to the analysis, tax evasion costs the world economy approximately USD 3.1 trillion, or nearly 5.1 percent of the global gross domestic product (GPD), according to the conducted survey. The total healthcare spending in the states surveyed amounted to USD 5.7 trillion. Thus, tax evasion costs approximately 54.9 percent of healthcare spending in the state’s survey. In African and South American countries, for example, the percentages of the health care spending lost to tax evasion are 97.7 percent and 138.5 percent, respectively, [
12].
The review of 46 tax compliance publications found eleven key aspects that researchers have investigated that affect compliance. These factors are the complexity of the tax system, the amount of tax information services, withholding and information reporting, the duties and penalties of tax return preparation, the likelihood of an audit, the progressive and actual level of tax rates, fines for noncompliance, age, gender, education, and income [
13]. Additional research has been conducted, revealing a multitude of factors that are more or less comparable to the findings of Jackson and Milliron, such as psychological factors such as ethics, tax morale, the taxpayer’s view, and others [
14,
15,
16].
In recent years, researchers have concentrated on analyzing VAT compliance following the implementation of the electronic billing machine (EBM). The initial studies on EBMs thus give a sobering result. Even though many governments have great hopes for EBMs to increase their tax revenues, the study revealed that these devices should not be considered a “silver bullet” for tax management [
2]. The results of an IMF study on trends in VAT revenue collection as a proportion of GDP following the implementation of EFDs for nine countries indicated that EFDs are not often connected with any noteworthy increase in VAT revenue. As a result, implementing fiscal devices on their own cannot provide significant benefits in terms of increased revenue or improved long-term compliance [
3]. The exception is Chile, where implementing EFDs was associated with a considerable drop in tax revenues. Still, the country regained its original VAT-to-GDP ratio after an additional three years of tax collection [
3].
The findings of a study on the impact of extract–transform–load (ETRs) on tax compliance for various tax authorities revealed that using ETRs significantly reduces the VAT audit time in the studied population in Kenya, as well as positively and significantly improves compliance attitudes and effective tax administration in the study area. It also discovered a significant increase in VAT compliance among classified hotels by raising the amount of declared VAT liability [
17,
18]. Some challenges associated with using EFDs include recurrent breakdowns, the fairness of tax estimates from taxpayers, a lack of instruction on the usage of EFDs devices, machine maintenance, and under-pricing of tax from traders [
19].
The studies performed in Rwanda over the last five years revealed that sending a reminder of a firm’s future tax requirements through a letter, email, or text message substantially impacts enterprises’ payment of corporate income tax. Applying such a method to EBM receipt issuance might be a powerful tool to improve compliance. Revenue authorities may request a voluntary quarterly VAT adjustment based on questionable tax filings (false receipts) or suspicious pricing patterns. If something goes wrong with their EBM device, it may send businesses automated text messages to notify them of problematic behavior and request an explanation [
20].
According to the “small-scale mystery shopper” study, researchers randomly visited a shop and discovered that just 21 percent of clients were given EBM receipts without asking for them. They also found that asking for a receipt increased the rate of EBM receipt issues to 63 percent of visits and that when tax authority officers sit beside the shop, the percentage increases to 94 percent [
3].
In recent years, there has been a remarkable increase in the application of artificial intelligence and machine learning algorithms to address very complex and emergent challenges as well as tax fraud [
21,
22]. Researchers have applied ML models in different domains depending on the problem they wanted to handle. For instance, Botchey et al. [
6] compared support vector machines (SVMs), gradient boosted decision trees, and naïve Bayes algorithms in predicting mobile money transaction fraud. The findings revealed that the gradient boost decision tree was the best model. Another study in [
23], examined how well sentiment analysis identifies letters from businesses that have engaged in financial misconduct or fraud. The findings indicated that SVM was 81% accurate at providing information about the positive or negative tones and word combinations typical of texts written by fraudsters.
In [
9], the authors compared different supervised machine learning models to detect and predict invoices that have delayed payments and difficult clients, which helps companies take collection measures. Their results revealed that random forest is the most robust and accurate model in identifying whether an invoice would be paid on time, how much of a delay it would cause, and to segment taxpayers.
In the study on financial fraud detection [
7], four different machine learning models were tested for categorizing companies that are more likely to be involved in tax fraud, including k-nearest neighbors, random forest, support vector machine (SVM), and a neural network. The results demonstrated that random forest, with an F1 score of 92%, was a good model for classifying organizations.
As shown in [
24], EBMs are associated with many advantages such as flexibility, easy storage, easy inspection, and quick reimbursement. However, these machines can also present strange electronic-related behaviors, such as the repeated reimbursement of electronic invoices, reimbursement of fake invoices, as well as the frequent replacement of electronic credential status. To identify, evaluate, and deal with the unusual behaviors of EBMs, researchers have suggested a multi-layer perceptron (MLP) model, which they trained using historical invoice data. These were tested using the real-time input of new data for which the model was 95% accurate.
Furthermore, the authors in [
10] suggested the use of artificial intelligence (AI) to combine the data available in the tax administration with digital invoices as a solution. This study emphasizes that in order for a tax administration to identify any type of tax fraud, data from many sources must be combined, necessitating the use of advanced algorithms for data analysis over billions of data points. A different approach to reduce VAT fraud detection is a multi-signature that involves multistage authorizations that help to establish online control was also proposed to be applied to detect VAT fraud as suggested by the authors
In [
8], a different study that uses machine learning techniques was used to focus on anomaly identification in electronic invoice systems. Multi-layer perceptron (MLP) and k-means were employed in this work, and the findings demonstrated that the proposed approach was both capable of effectively detecting malicious attacks and of mining the potential risks in the electronic invoice systems. Finally, this study [
25] was implemented in Tanzania, and the authors suggested the use of electronic fiscal devices (EFDs) in identifying tax fraud. Even though using EFDs boosts revenue, these are also linked to problems with tax fraud, such as under-declaration, failure to use EFDs, and others. As a result, the suggested upgraded EFD includes the ability to recognize under-pricing, failure to use EFD machines, as well as the detection of fake EFD machines.
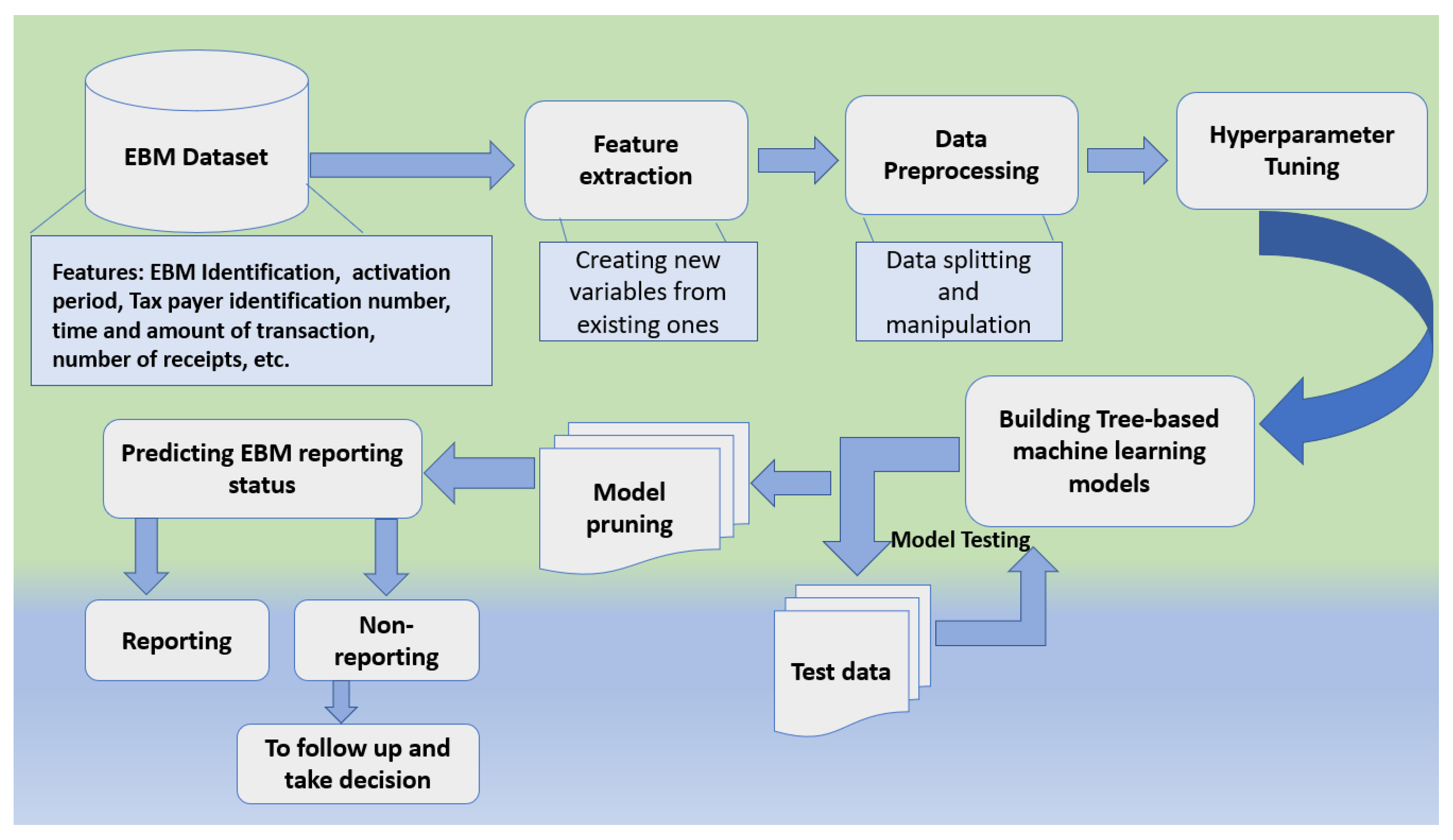
Despite the fact that the above literature shows that most research has focused on examining EBM’s importance in increasing taxpayer compliance as well as contribution to the economy. Additionally, several approaches have attempted to employ machine learning techniques to cope with various economic aspects. Moreover, none of the approaches focused on enhancing taxpayer compliance through research and the prediction of EBM behavior. Our proposed contributes to filling this gap.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}



