
A Homomorphic Encryption Framework for Privacy-Preserving Spiking Neural Networks

 ,
,  , and
, and
Abstract
:1. Introduction
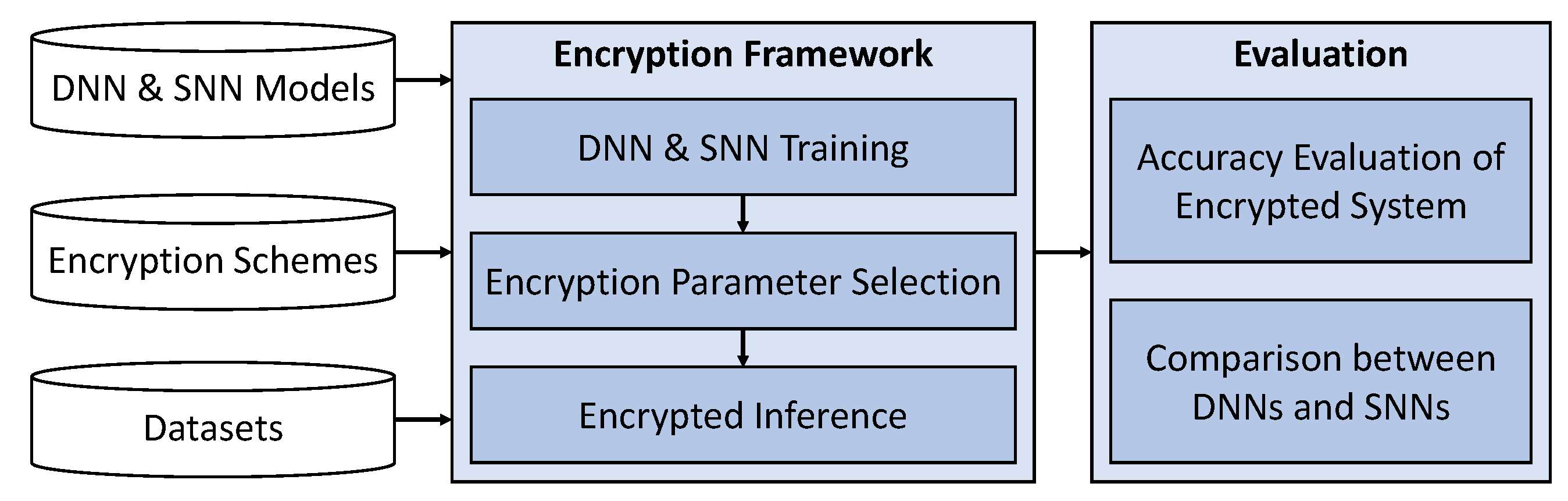
- We design an encryption framework based on the BVF HE scheme that can execute privacy-preserving DNNs and SNNs (Section 3).
- The encryption parameters are properly selected to obtain good tradeoffs between security and computational efficiency (Section 3.4).
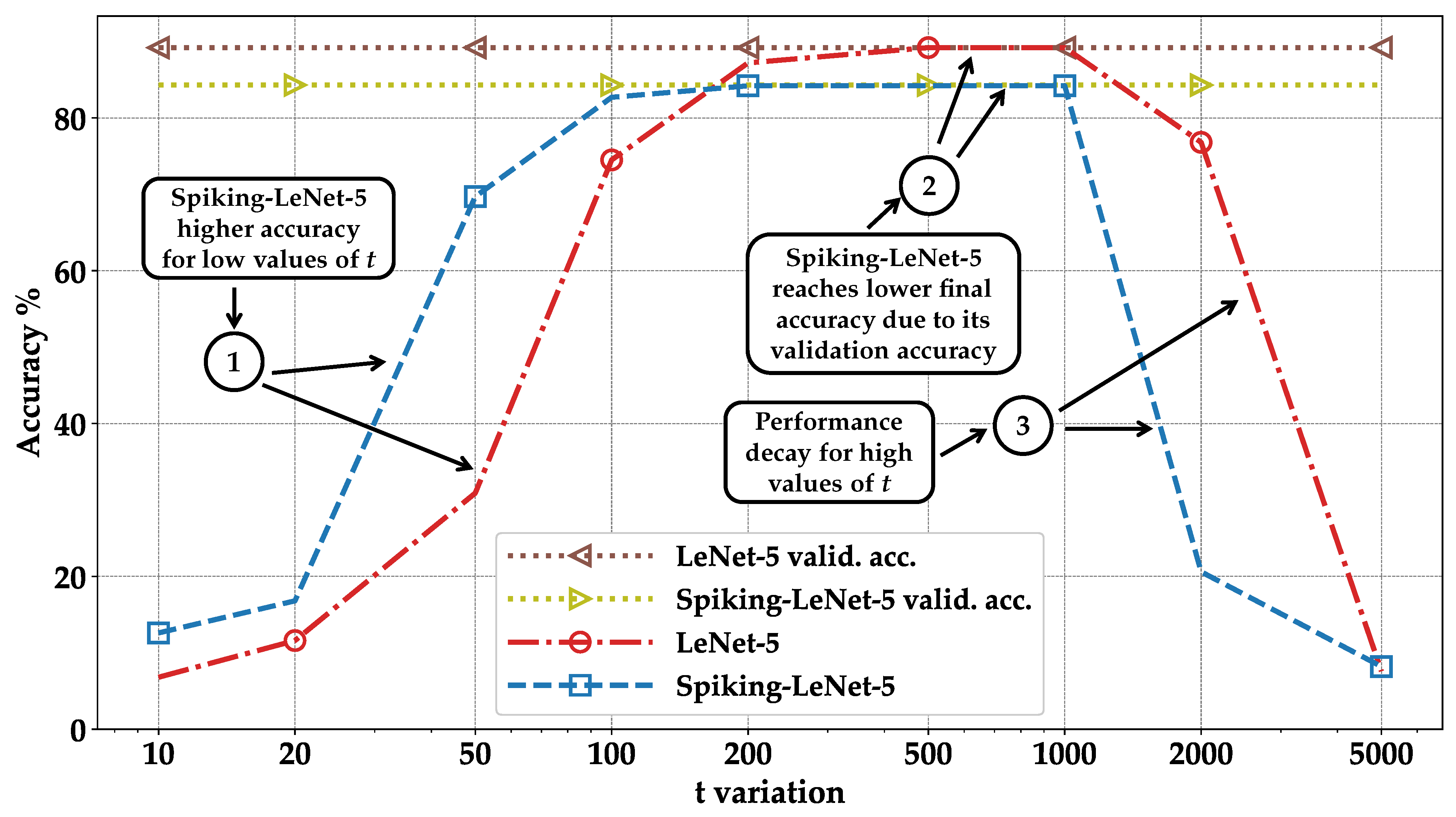
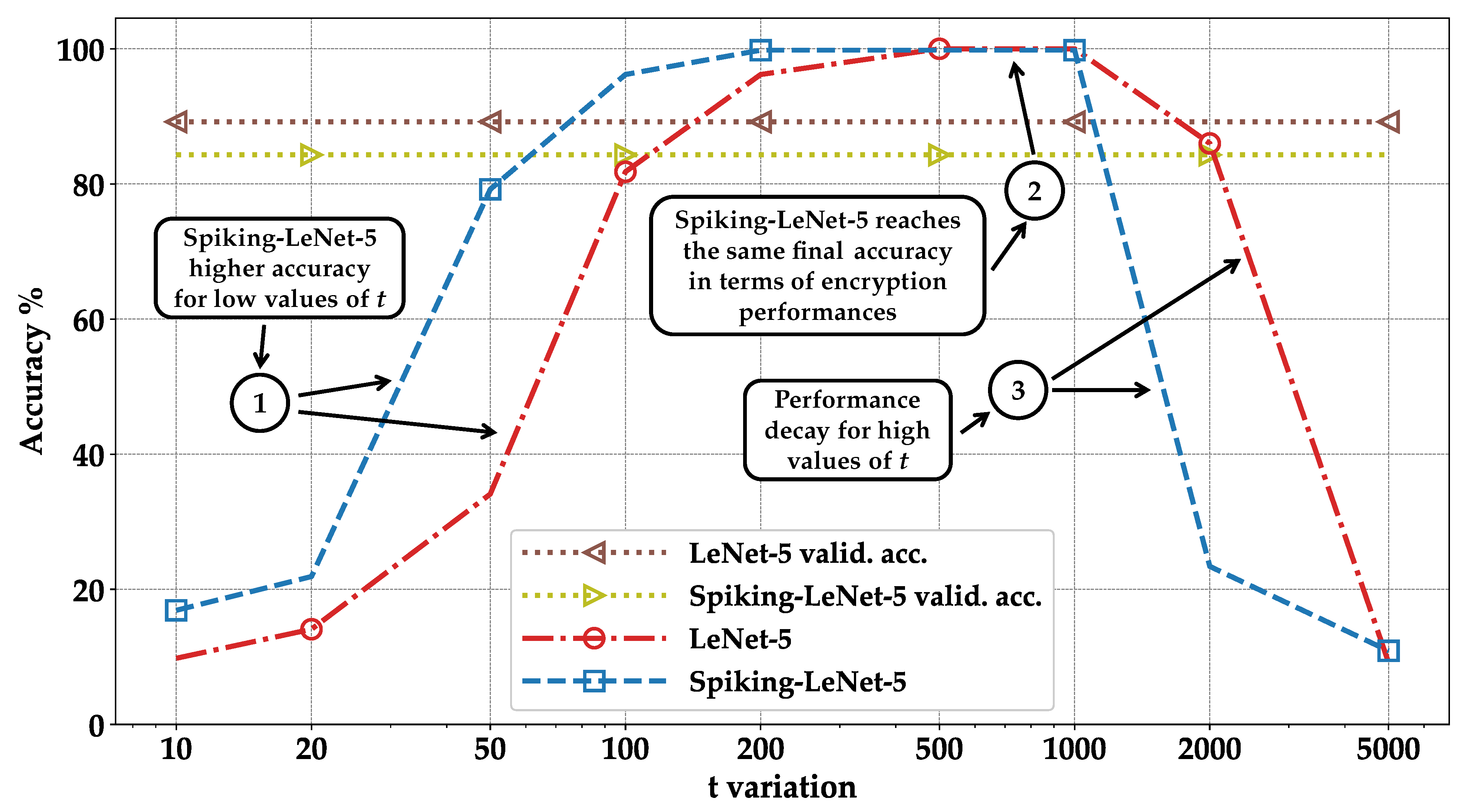
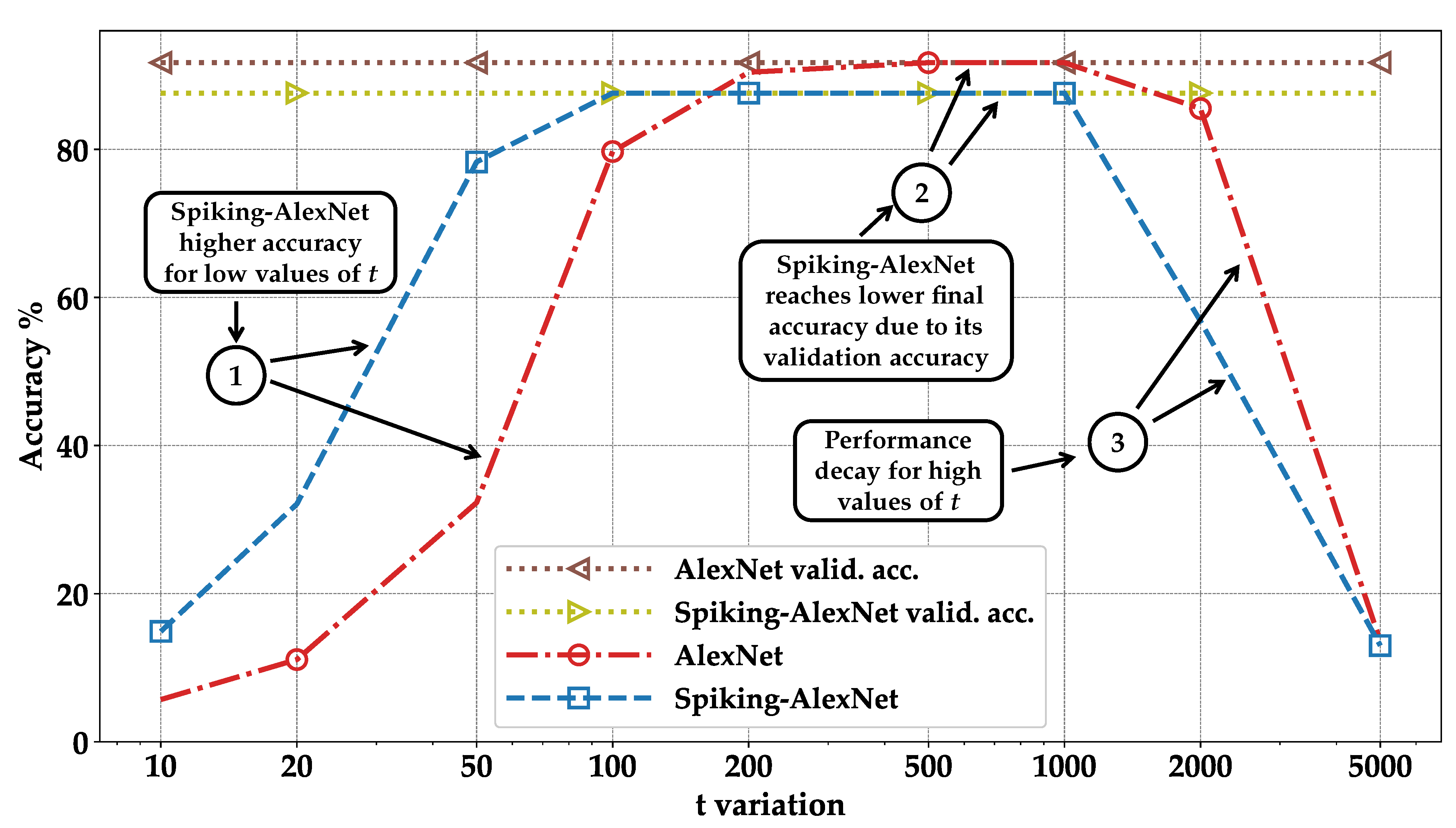
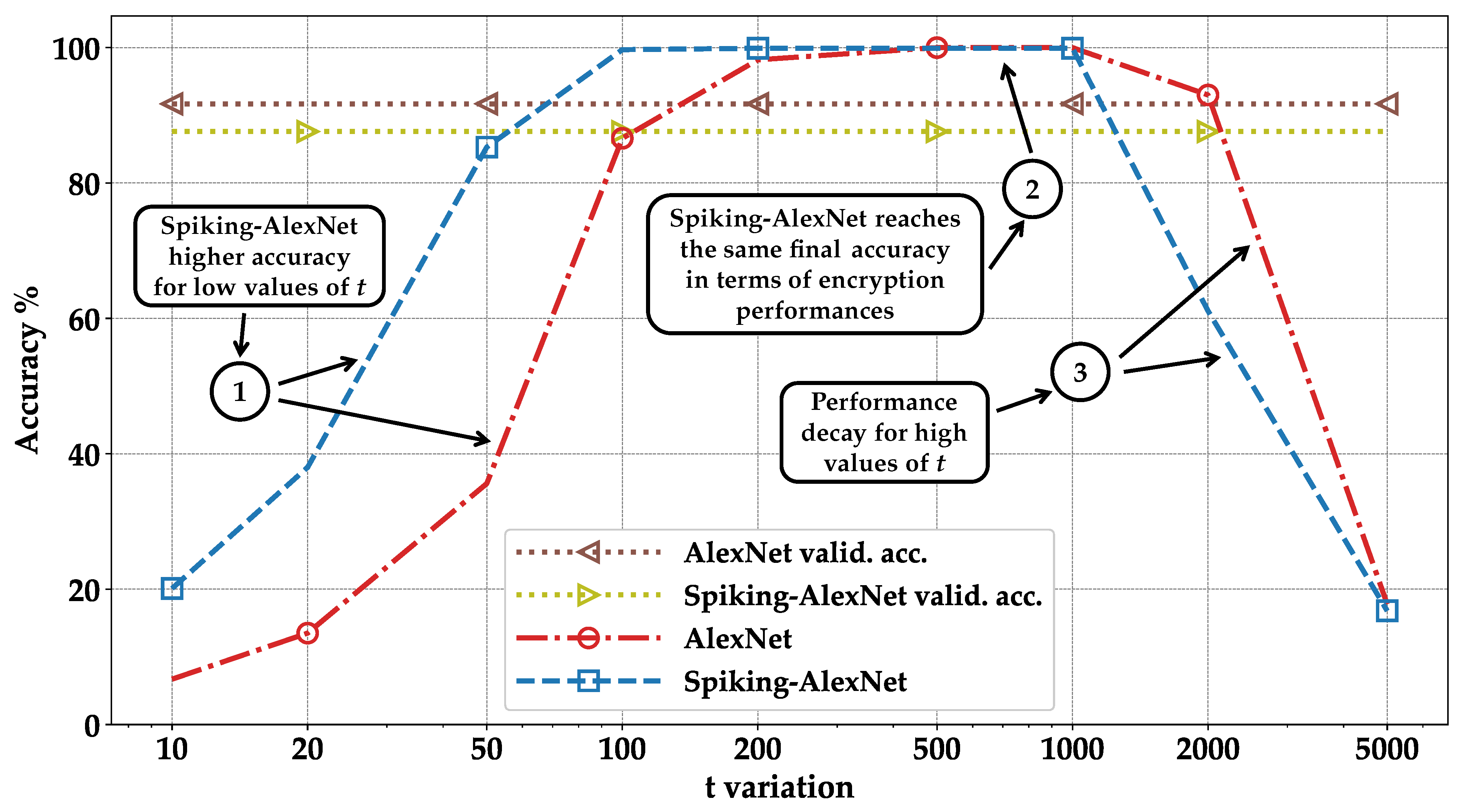
- We implement the encryption framework, evaluate the accuracy of encrypted models, and compare the results between DNNs and SNNs. We observe that the SNNs achieve up to 40% higher accuracy than DNNs for low values of the plaintext modulus t (Section 4).
2. Background
2.1. Deep Neural Networks and Convolutional Neural Networks
2.2. Spiking Neural Networks
2.3. Homomorphic Encryption and Brakerski/Fan-Vercauteren Scheme
3. Proposed Encryption Framework
3.1. FashionMNIST
3.2. LeNet-5 and AlexNet
3.3. Spiking-LeNet-5, Spiking-AlexNet and Norse
- —represents the inverse of the synaptic time constant. It determines the rate at which the synaptic input decays over time;
- —represents the inverse of the membrane time constant. This parameter influences the rate at which the neuron’s membrane potential decays without input;
- —specifies the leak potential of the neuron. It is the resting potential of the neuron’s membrane when there is no synaptic input or other stimuli;
- —defines the threshold potential of the neuron. The neuron generates an action potential when the membrane potential reaches or exceeds this threshold;
- —represents the reset potential of the neuron. After firing an action potential, the membrane potential is reset to this value.
3.4. HE Parameters and Pyfhel
- m—represents the polynomial modulus degree, influencing the encryption scheme’s computational capabilities and security level;
- t—denotes the plaintext modulus and determines the size and precision of the encrypted plaintext values;
- q—represents the ciphertext modulus, determining the size of the encrypted ciphertext values and affecting the security and computational performance of the encryption scheme.
4. Results and Discussion
- Training of the LeNet-5, AlexNet, Spiking-LeNet-5, and Spiking-AlexNet models on the training set of the FashionMNIST dataset;
- Validating the models on the test set of the same dataset;
- Creating encrypted models based on the previously trained models [59];
- Encrypting the test set;
- Evaluating the encrypted images on the encrypted LeNet-5, AlexNet, Spiking-LeNet-5, and Spiking-AlexNet models.
4.1. Training Phase
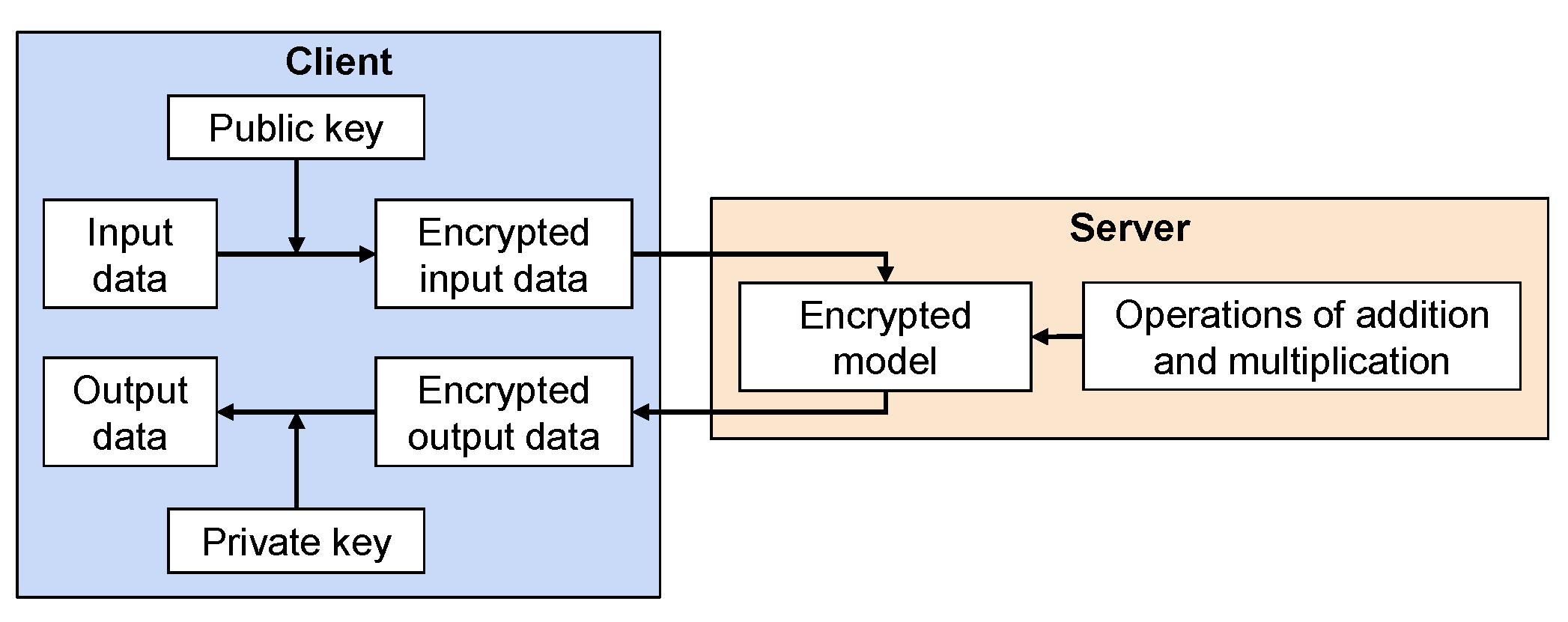
4.2. Encryption
4.3. Evaluation
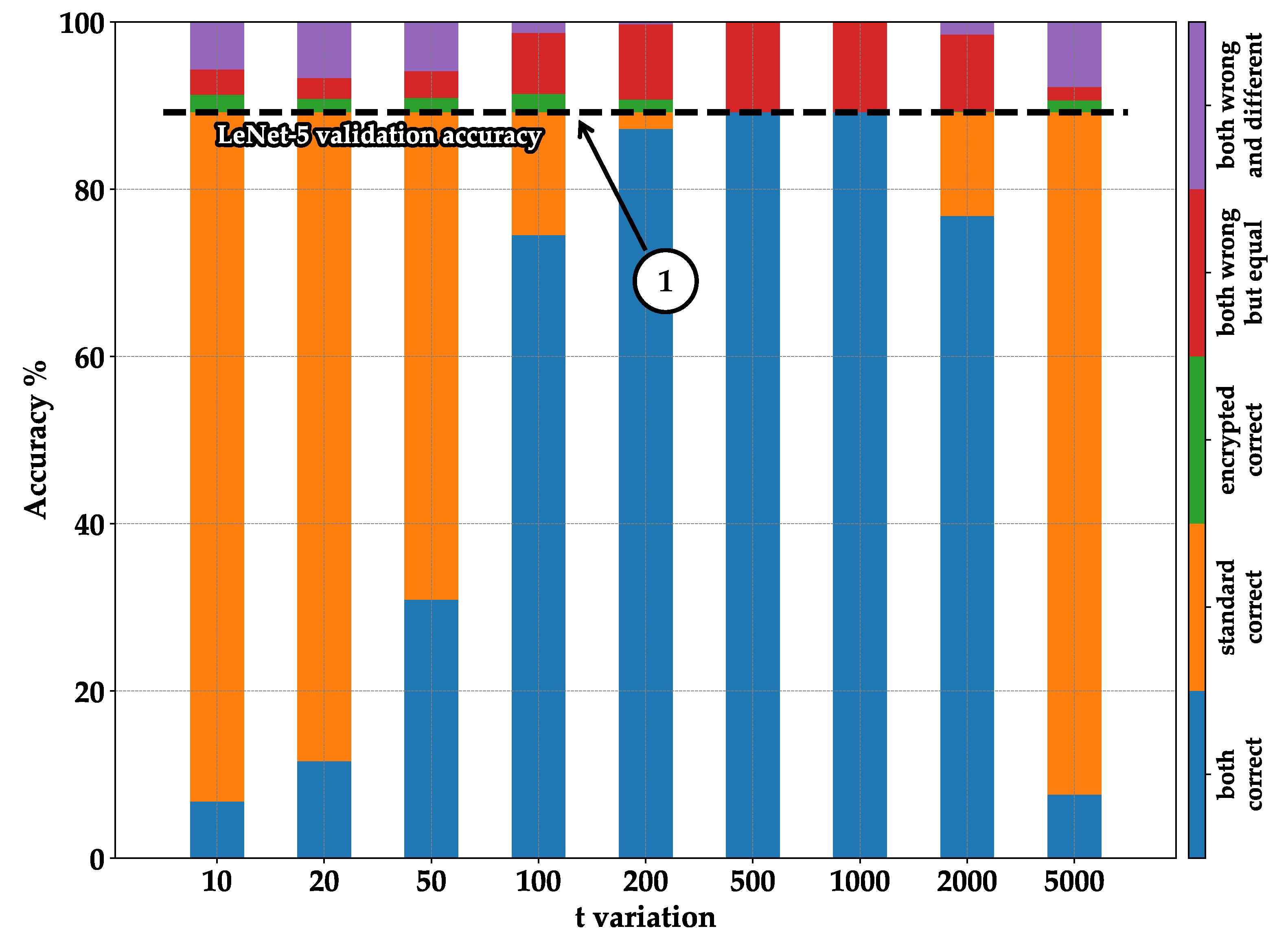
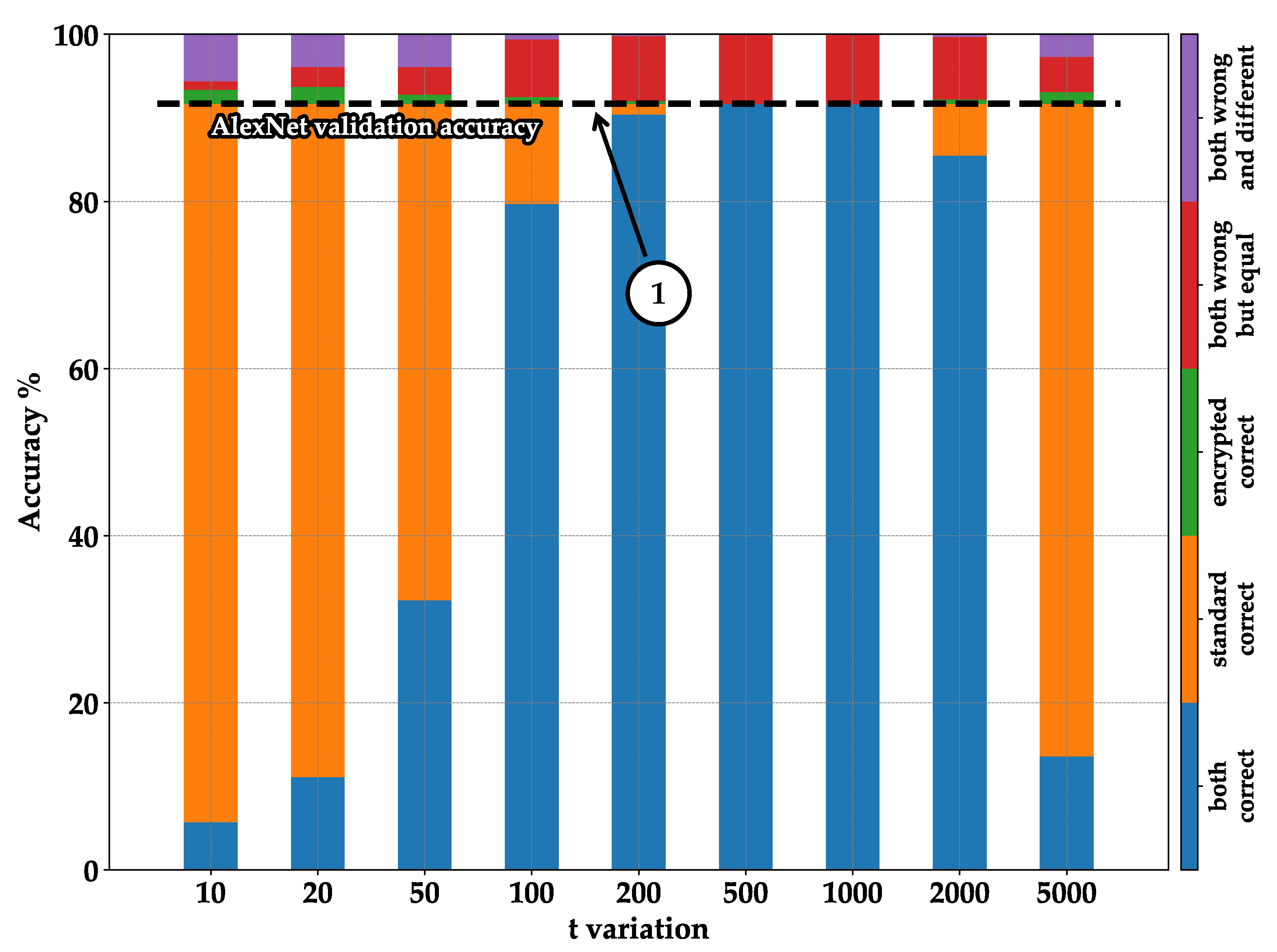
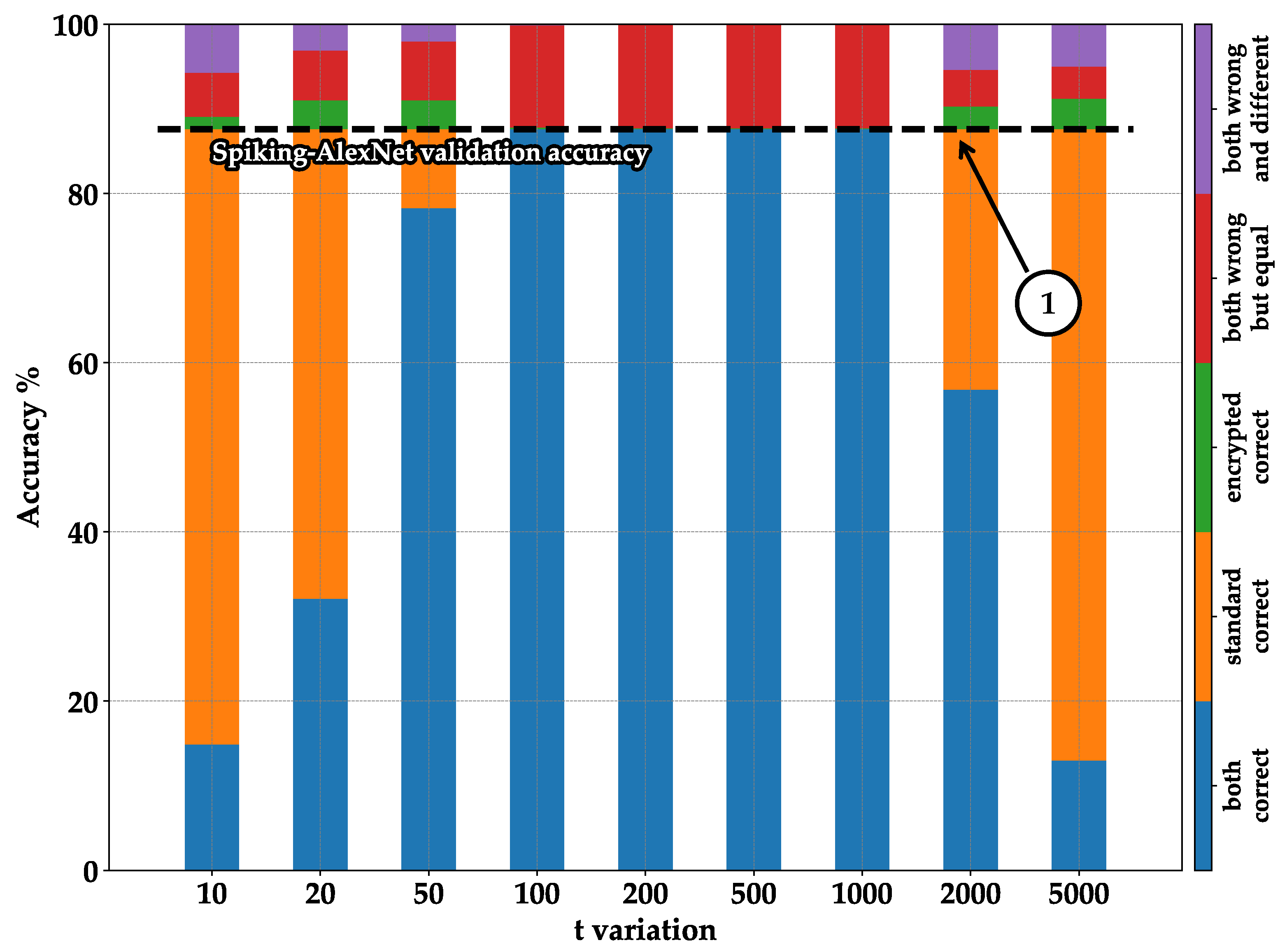
- Blue—both correct: indicates the number of images classified correctly in both the standard and encrypted executions;
- Orange—standard correct: represents the case where images are classified correctly in the standard execution but not in the encrypted one. It can be observed that by summing the blue and orange columns, we always obtain the same result: the accuracy of validation during training (see pointer ➀—Figure 8, Figure 9, Figure 10 and Figure 11);
- Green—encrypted correct: represents images classified correctly in the encrypted case but not in the standard one. It can be noticed that the percentages are generally low; this is because the encrypted model mistakenly classified the images differently from the standard model, but by chance, it happened to choose the correct label. Therefore, this column part does not represent a valid statistical case but rather randomness;
- Red—both wrong but equal: indicates cases where the encrypted model was classified identically to the standard one but did not classify the correct label. This part is essential, as it shows the encrypted model working correctly by emulating the standard model, even though the classification is incorrect overall;
- Purple—both wrong and different: shows cases where the encrypted model made mistakes by not producing the same result as the standard model, and the standard model also made mistakes by not classifying correctly.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| ML | Machine Learning |
| DNNs | Deep Neural Networks |
| SNNs | Spiking Neural Networks |
| HE | Homomorphic Encryption |
| PHE | Partially Homomorphic Encryption |
| SHE | Somewhat Homomorphic Encryption |
| FHE | Fully Homomorphic Encryption |
| BFV | Brakerski/Fan-Vercauteren |
| CNNs | Convolutional Neural Networks |
| LIF | Leaky Integrate-and-Fire |
| NB | Noise Budget |
References
- Capra, M.; Bussolino, B.; Marchisio, A.; Masera, G.; Martina, M.; Shafique, M. Hardware and Software Optimizations for Accelerating Deep Neural Networks: Survey of Current Trends, Challenges, and the Road Ahead. IEEE Access 2020, 8, 225134–225180. [Google Scholar] [CrossRef]
- Dave, S.; Marchisio, A.; Hanif, M.A.; Guesmi, A.; Shrivastava, A.; Alouani, I.; Shafique, M. Special Session: Towards an Agile Design Methodology for Efficient, Reliable, and Secure ML Systems. In Proceedings of the 40th IEEE VLSI Test Symposium, VTS 2022, San Diego, CA, USA, 25–27 April 2022; pp. 1–14. [Google Scholar] [CrossRef]
- Shafique, M.; Marchisio, A.; Putra, R.V.W.; Hanif, M.A. Towards Energy-Efficient and Secure Edge AI: A Cross-Layer Framework ICCAD Special Session Paper. In Proceedings of the IEEE/ACM International Conference on Computer Aided Design, ICCAD 2021, Munich, Germany, 1–4 November 2021; pp. 1–9. [Google Scholar] [CrossRef]
- Simeone, O.; Rajendran, B.; Grüning, A.; Eleftheriou, E.; Davies, M.; Denève, S.; Huang, G. Learning Algorithms and Signal Processing for Brain-Inspired Computing. IEEE Signal Process. Mag. 2019, 36, 12–15. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- von Kügelgen, J. On Artificial Spiking Neural Networks: Principles, Limitations and Potential. Master’s Thesis, University of Barcelona, Barcelona, Spain, 2017. [Google Scholar]
- Diamond, A.; Nowotny, T.; Schmuker, M. Comparing Neuromorphic Solutions in Action: Implementing a Bio-Inspired Solution to a Benchmark Classification Task on Three Parallel-Computing Platforms. Front. Neurosci. 2016, 9, 491. [Google Scholar] [CrossRef]
- Barni, M.; Orlandi, C.; Piva, A. A privacy-preserving protocol for neural-network-based computation. In Proceedings of the 8th workshop on Multimedia & Security, MM&Sec 2006, Geneva, Switzerland, 26–27 September 2006; pp. 146–151. [Google Scholar] [CrossRef]
- Fan, J.; Vercauteren, F. Somewhat Practical Fully Homomorphic Encryption. IACR Cryptol. ePrint Arch. 2012, 2012, 144. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Johnson, J.D.; Li, J.; Chen, Z. Reinforcement Learning: An Introduction: R.S. Sutton, A.G. Barto, MIT Press: Cambridge, MA, USA, 1998; p. 322, ISBN 0-262-19398-1. Neurocomputing 2000, 35, 205–206. [Google Scholar] [CrossRef]
- Ponulak, F.; Kasiński, A. Introduction to spiking neural networks: Information processing, learning and applications. Acta Neurobiol. Exp. 2011, 71, 409–433. [Google Scholar]
- Paugam-Moisy, H.; Bohté, S.M. Computing with Spiking Neuron Networks. In Handbook of Natural Computing; Rozenberg, G., Bäck, T., Kok, J.N., Eds.; Springer: Berlin, Germany, 2012; pp. 335–376. [Google Scholar] [CrossRef]
- Tavanaei, A.; Ghodrati, M.; Kheradpisheh, S.R.; Masquelier, T.; Maida, A. Deep learning in spiking neural networks. Neural Netw. 2019, 111, 47–63. [Google Scholar] [CrossRef]
- Marchisio, A.; Nanfa, G.; Khalid, F.; Hanif, M.A.; Martina, M.; Shafique, M. Is Spiking Secure? A Comparative Study on the Security Vulnerabilities of Spiking and Deep Neural Networks. In Proceedings of the 2020 International Joint Conference on Neural Networks, IJCNN 2020, Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Marchisio, A.; Pira, G.; Martina, M.; Masera, G.; Shafique, M. R-SNN: An Analysis and Design Methodology for Robustifying Spiking Neural Networks against Adversarial Attacks through Noise Filters for Dynamic Vision Sensors. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, IROS 2021, Prague, Czech Republic, 27 September–1 October 2021; pp. 6315–6321. [Google Scholar] [CrossRef]
- El-Allami, R.; Marchisio, A.; Shafique, M.; Alouani, I. Securing Deep Spiking Neural Networks against Adversarial Attacks through Inherent Structural Parameters. In Proceedings of the Design, Automation & Test in Europe Conference & Exhibition, DATE 2021, Grenoble, France, 1–5 February 2021; pp. 774–779. [Google Scholar] [CrossRef]
- Kim, Y.; Chough, J.; Panda, P. Beyond classification: Directly training spiking neural networks for semantic segmentation. Neuromorph. Comput. Eng. 2022, 2, 44015. [Google Scholar] [CrossRef]
- Meftah, B.; Lézoray, O.; Chaturvedi, S.; Khurshid, A.A.; Benyettou, A. Image Processing with Spiking Neuron Networks. In Artificial Intelligence, Evolutionary Computing and Metaheuristics—In the Footsteps of Alan Turing; Yang, X., Ed.; Springer: Berlin, Germany, 2013; Volume 427, pp. 525–544. [Google Scholar] [CrossRef]
- Viale, A.; Marchisio, A.; Martina, M.; Masera, G.; Shafique, M. CarSNN: An Efficient Spiking Neural Network for Event-Based Autonomous Cars on the Loihi Neuromorphic Research Processor. In Proceedings of the International Joint Conference on Neural Networks, IJCNN 2021, Shenzhen, China, 18–22 July 2021; pp. 1–10. [Google Scholar] [CrossRef]
- Cordone, L.; Miramond, B.; Thiérion, P. Object Detection with Spiking Neural Networks on Automotive Event Data. In Proceedings of the International Joint Conference on Neural Networks, IJCNN 2022, Padua, Italy, 18—23 July 2022; pp. 1–8. [Google Scholar] [CrossRef]
- Viale, A.; Marchisio, A.; Martina, M.; Masera, G.; Shafique, M. LaneSNNs: Spiking Neural Networks for Lane Detection on the Loihi Neuromorphic Processor. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, IROS 2022, Kyoto, Japan, 23–27 October 2022; pp. 79–86. [Google Scholar] [CrossRef]
- Massa, R.; Marchisio, A.; Martina, M.; Shafique, M. An Efficient Spiking Neural Network for Recognizing Gestures with a DVS Camera on the Loihi Neuromorphic Processor. In Proceedings of the 2020 International Joint Conference on Neural Networks, IJCNN 2020, Glasgow, UK, 19–24 July 2020; pp. 1–9. [Google Scholar] [CrossRef]
- Indiveri, G.; Sandamirskaya, Y. The Importance of Space and Time for Signal Processing in Neuromorphic Agents: The Challenge of Developing Low-Power, Autonomous Agents That Interact With the Environment. IEEE Signal Process. Mag. 2019, 36, 16–28. [Google Scholar] [CrossRef]
- Lee, J.; Delbrück, T.; Pfeiffer, M. Training Deep Spiking Neural Networks using Backpropagation. arXiv 2016, arXiv:1608.08782. [Google Scholar] [CrossRef]
- Lee, C.; Sarwar, S.S.; Roy, K. Enabling Spike-based Backpropagation in State-of-the-art Deep Neural Network Architectures. arXiv 2019, arXiv:1903.06379. [Google Scholar]
- Gentry, C. Fully homomorphic encryption using ideal lattices. In Proceedings of the 41st Annual ACM Symposium on Theory of Computing, STOC 2009, Bethesda, MD, USA, 31 May–2 June 2009; pp. 169–178. [Google Scholar] [CrossRef]
- Orlandi, C.; Piva, A.; Barni, M. Oblivious Neural Network Computing via Homomorphic Encryption. EURASIP J. Inf. Secur. 2007, 2007, 037343. [Google Scholar] [CrossRef]
- Stehlé, D.; Steinfeld, R.; Tanaka, K.; Xagawa, K. Efficient Public Key Encryption Based on Ideal Lattices. In Proceedings of the Advances in Cryptology-ASIACRYPT 2009, 15th International Conference on the Theory and Application of Cryptology and Information Security, Tokyo, Japan, 6–10 December 2009; Volume 5912, pp. 617–635. [Google Scholar] [CrossRef]
- Damgård, I.; Jurik, M. A Generalisation, a Simplification and Some Applications of Paillier’s Probabilistic Public-Key System. In Proceedings of the Public Key Cryptography, 4th International Workshop on Practice and Theory in Public Key Cryptography, PKC 2001, Cheju Island, Republic of Korea, 13–15 February 2001; Volume 1992, pp. 119–136. [Google Scholar] [CrossRef]
- Rivest, R.L.; Dertouzos, M.L. On Data Banks and Privacy Homomorphisms; Academic Press, Inc.: Cambridge, MA, USA, 1978. [Google Scholar]
- Bos, J.W.; Lauter, K.E.; Loftus, J.; Naehrig, M. Improved Security for a Ring-Based Fully Homomorphic Encryption Scheme. IACR Cryptol. ePrint Archive 2013, 2013, 75. [Google Scholar]
- Chabanne, H.; de Wargny, A.; Milgram, J.; Morel, C.; Prouff, E. Privacy-Preserving Classification on Deep Neural Network. IACR Cryptol. ePrint Arch. 2017, 2017, 35. [Google Scholar]
- Falcetta, A.; Roveri, M. Privacy-Preserving Deep Learning With Homomorphic Encryption: An Introduction. IEEE Comput. Intell. Mag. 2022, 17, 14–25. [Google Scholar] [CrossRef]
- Brakerski, Z.; Vaikuntanathan, V. Efficient Fully Homomorphic Encryption from (Standard) $\mathsf{LWE}$. SIAM J. Comput. 2014, 43, 831–871. [Google Scholar] [CrossRef]
- Gentry, C. A Fully Homomorphic Encryption Scheme. Ph.D. Thesis, Stanford University, Stanford, CA, USA, 2009. [Google Scholar]
- Brakerski, Z.; Gentry, C.; Vaikuntanathan, V. Fully Homomorphic Encryption without Bootstrapping. IACR Cryptol. ePrint Arch. 2011, TR11, 277. [Google Scholar]
- Boneh, D.; Goh, E.; Nissim, K. Evaluating 2-DNF Formulas on Ciphertexts. In Proceedings of the Theory of Cryptography, Second Theory of Cryptography Conference, TCC 2005, Cambridge, MA, USA, 10–12 February 2005; Volume 3378, pp. 325–341. [Google Scholar] [CrossRef]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-MNIST: A Novel Image Dataset for Benchmarking Machine Learning Algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Deng, L. The MNIST Database of Handwritten Digit Images for Machine Learning Research. IEEE Signal Process. Mag. 2012, 29, 141–142. [Google Scholar] [CrossRef]
- Patiño-Saucedo, A.; Rostro-González, H.; Serrano-Gotarredona, T.; Linares-Barranco, B. Event-driven implementation of deep spiking convolutional neural networks for supervised classification using the SpiNNaker neuromorphic platform. Neural Netw. 2020, 121, 319–328. [Google Scholar] [CrossRef] [PubMed]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019; pp. 8024–8035. [Google Scholar]
- Ibarrondo, A.; Viand, A. Pyfhel: PYthon For Homomorphic Encryption Libraries. In Proceedings of the WAHC ’21: Proceedings of the 9th on Workshop on Encrypted Computing & Applied Homomorphic Cryptography, Virtual Event, Republic of Korea, 15 November 2021; pp. 11–16. [Google Scholar] [CrossRef]
- Pehle, C.G.; Pedersen, J.E. Norse—A Deep Learning Library for Spiking Neural Networks. 2021. Available online: https://norse.ai/docs/ (accessed on 1 August 2023).
- Sengupta, A.; Ye, Y.; Wang, R.; Liu, C.; Roy, K. Going Deeper in Spiking Neural Networks: VGG and Residual Architectures. arXiv 2018, arXiv:1802.02627. [Google Scholar] [CrossRef] [PubMed]
- Izhikevich, E.M. Simple model of spiking neurons. IEEE Trans. Neural Netw. 2003, 14, 1569–1572. [Google Scholar] [CrossRef]
- Roy, K.; Jaiswal, A.R.; Panda, P. Towards spike-based machine intelligence with neuromorphic computing. Nature 2019, 575, 607–617. [Google Scholar] [CrossRef]
- Han, B.; Roy, K. Deep Spiking Neural Network: Energy Efficiency Through Time Based Coding. In Proceedings of the Computer Vision—ECCV 2020—16th European Conference, Glasgow, UK, 23–28 August 2020; Volume 12355, pp. 388–404. [Google Scholar] [CrossRef]
- Zenke, F.; Ganguli, S. SuperSpike: Supervised Learning in Multilayer Spiking Neural Networks. Neural Comput. 2018, 30. [Google Scholar] [CrossRef] [PubMed]
- Ponulak, F.; Kasinski, A.J. Supervised Learning in Spiking Neural Networks with ReSuMe: Sequence Learning, Classification, and Spike Shifting. Neural Comput. 2010, 22, 467–510. [Google Scholar] [CrossRef]
- Guo, W.; Fouda, M.E.; Eltawil, A.; Salama, K. Efficient training of spiking neural networks with temporally-truncated local backpropagation through time. Front. Neurosci. 2023, 17, 1047008. [Google Scholar] [CrossRef] [PubMed]
- Chen, H.; Laine, K.; Player, R. Simple Encrypted Arithmetic Library—SEAL v2.1. IACR Cryptol. ePrint Arch. 2017, 224. Available online: https://eprint.iacr.org/2017/224 (accessed on 1 August 2023).
- Papernot, N.; McDaniel, P.D.; Sinha, A.; Wellman, M.P. Towards the Science of Security and Privacy in Machine Learning. arXiv 2016, arXiv:1611.03814. [Google Scholar]
- Yao, A.C. Protocols for Secure Computations (Extended Abstract). In Proceedings of the 23rd Annual Symposium on Foundations of Computer Science, Chicago, IL, USA, 3–5 November 1982; pp. 160–164. [Google Scholar] [CrossRef]
- Paillier, P. Public-Key Cryptosystems Based on Composite Degree Residuosity Classes. In Proceedings of the Advances in Cryptology—EUROCRYPT ’99, International Conference on the Theory and Application of Cryptographic Techniques, Prague, Czech Republic, 2–6 May 1999; pp. 223–238. [Google Scholar] [CrossRef]
- Disabato, S.; Falcetta, A.; Mongelluzzo, A.; Roveri, M. A Privacy-Preserving Distributed Architecture for Deep-Learning-as-a-Service. In Proceedings of the 2020 International Joint Conference on Neural Networks, IJCNN 2020, Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Gilad-Bachrach, R.; Dowlin, N.; Laine, K.; Lauter, K.E.; Naehrig, M.; Wernsing, J. CryptoNets: Applying Neural Networks to Encrypted Data with High Throughput and Accuracy. In Proceedings of the 33nd International Conference on Machine Learning, ICML 2016, New York City, NY, USA, 19–24 June 2016; Volume 48, pp. 201–210. [Google Scholar]
- Kim, Y.; Venkatesha, Y.; Panda, P. PrivateSNN: Privacy-Preserving Spiking Neural Networks. In Proceedings of the Thirty-Sixth AAAI Conference on Artificial Intelligence, AAAI 2022, Thirty-Fourth Conference on Innovative Applications of Artificial Intelligence, IAAI 2022, The Twelveth Symposium on Educational Advances in Artificial Intelligence, EAAI 2022, Virtual Event, 22 February–1 March 2022; pp. 1192–1200. [Google Scholar]
- Smith, L.N. Cyclical Learning Rates for Training Neural Networks. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision, WACV 2017, Santa Rosa, CA, USA, 24–31 March 2017; pp. 464–472. [Google Scholar] [CrossRef]
- Rice, L.; Wong, E.; Kolter, J.Z. Overfitting in adversarially robust deep learning. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, Virtual Event, 13–18 July 2020; Volume 119, pp. 8093–8104. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Janocha, K.; Czarnecki, W.M. On Loss Functions for Deep Neural Networks in Classification. arXiv 2017, arXiv:1702.05659. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Cammarota, R. Intel HERACLES: Homomorphic Encryption Revolutionary Accelerator with Correctness for Learning-oriented End-to-End Solutions. In Proceedings of the 2022 on Cloud Computing Security Workshop, CCSW 2022, Los Angeles, CA, USA, 7 November 2022; p. 3. [Google Scholar] [CrossRef]
- Badawi, A.A.; Bates, J.; Bergamaschi, F.; Cousins, D.B.; Erabelli, S.; Genise, N.; Halevi, S.; Hunt, H.; Kim, A.; Lee, Y.; et al. OpenFHE: Open-Source Fully Homomorphic Encryption Library. In Proceedings of the 10th Workshop on Encrypted Computing & Applied Homomorphic Cryptography, Los Angeles, CA, USA, 7 November 2022; pp. 53–63. [Google Scholar] [CrossRef]
- Cousins, D.B.; Polyakov, Y.; Badawi, A.A.; French, M.; Schmidt, A.G.; Jacob, A.P.; Reynwar, B.; Canida, K.; Jaiswal, A.R.; Mathew, C.; et al. TREBUCHET: Fully Homomorphic Encryption Accelerator for Deep Computation. arXiv 2023, arXiv:2304.05237. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | LeNet-5 | Spiking-LeNet-5 | AlexNet | Spiking-AlexNet |
|---|---|---|---|---|
| Learning Rate | 0.001 | 0.001 | 0.0001 | 0.0001 |
| Epochs | 20 | 20 | 20 | 20 |
| Optimizer [62] | Adam | Adam | Adam | Adam |
| Loss [63] | Cross Entropy | Negative Log-Likelihood | Cross Entropy | Negative Log-Likelihood |
| - | 30 | - | 30 | |
| - | 200 | - | 200 | |
| - | 100 | - | 100 | |
| - | 0 | - | 0 | |
| - | 0.5 | - | 0.5 | |
| - | 0 | - | 0 | |
| Encoder | - | Constant Current LIF | - | Constant Current LIF |
| Time (seconds) | LeNet-5 | Spiking-LeNet-5 | AlexNet | Spiking-AlexNet | VGG-16 | Spiking-VGG-16 | ResNet-50 | Spiking-ResNet-50 |
|---|---|---|---|---|---|---|---|---|
| Normal execution (unencrypted) | 0.03 | 1 | 30 | 1000 | 70 | 2300 | 10 | 300 |
| Encrypted execution | 31 | 930 | 30,060 | 901,800 | 70,140 | 2,104,200 | 10,020 | 300,600 |
| Encryption | 1 | 30 | 60 | 1800 | 140 | 4200 | 20 | 600 |
| Processing time of encrypted data | 30 | 900 | 30,000 | 900,000 | 70,000 | 2,100,000 | 10,000 | 300,000 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nikfam, F.; Casaburi, R.; Marchisio, A.; Martina, M.; Shafique, M. A Homomorphic Encryption Framework for Privacy-Preserving Spiking Neural Networks. Information 2023, 14, 537. https://doi.org/10.3390/info14100537
Nikfam F, Casaburi R, Marchisio A, Martina M, Shafique M. A Homomorphic Encryption Framework for Privacy-Preserving Spiking Neural Networks. Information. 2023; 14(10):537. https://doi.org/10.3390/info14100537
Chicago/Turabian StyleNikfam, Farzad, Raffaele Casaburi, Alberto Marchisio, Maurizio Martina, and Muhammad Shafique. 2023. "A Homomorphic Encryption Framework for Privacy-Preserving Spiking Neural Networks" Information 14, no. 10: 537. https://doi.org/10.3390/info14100537
APA StyleNikfam, F., Casaburi, R., Marchisio, A., Martina, M., & Shafique, M. (2023). A Homomorphic Encryption Framework for Privacy-Preserving Spiking Neural Networks. Information, 14(10), 537. https://doi.org/10.3390/info14100537