
Providing a User Extensible Service-Enabled Multi-Fidelity Hybrid Cloud-Deployable SoS Test and Evaluation (T&E) Infrastructure: Application of Modeling and Simulation (M&S) as a Service (MSaaS)


Abstract
:1. Introduction
2. Related Work
- Persistent simulation environments that allow external simulation federates to “easily” integrate into the existing environment(s);
- Virtual Machine (VM) and cloud-deployable simulation instances that are more easily distributed and accessed by authorized users and roles;
- The Risk Management Framework and the ability to support program, service, and DoD-level software Authority to Operate (ATO) on trusted networks (McKeown 2022);
- Software factories provide not only configuration management tools but also wholistic CI/CD pipelines as part of the DevSecOps strategy.
- There is a need for a persistent set of expert simulationists to setup, run, and evolve the specific simulation federates as well as the overall federation to support events, mitigate and fix software and simulation bugs, develop and employ consistent datasets, and help report, deliver, and understand the results;
- A standardized and well-defined common and interaction data model is necessary to allow integration across the simulation federates and to drive the simulation/stimulation interfaces to the C2 community;
- A standardized process with appropriate automation that is co-owned by security accreditation professions is essential to support any type of DoD security and network authorization in order to connect to trusted networks;
- The ability to evolve and enhance the simulation tools and to integrate additional functionality with new or existing tool modifications to support new cyber and/or other non-kinetic capabilities is critical to US warfighting advantage.
3. M&S as a Service Paradigm and Fidelity Management
- Testing new concepts and ideas for innovation in autonomy and human-machine teaming;
- Building trust in autonomy and autonomous behaviors;
- Demonstrating interoperability across platforms and missions;
- Identify interoperability touchpoints across models and systems at different modeling resolutions and fidelities.
4. Simulation, Experimentation, Analytics, and Testing (SEAT) Layered Reference Architecture
4.1. SEAT Vision
- DR-1: The hardware and software environment must allow for running on a range of common computer hardware and operating systems and, for ease of access, must be deployable on cloud computing infrastructure;
- DR-2: The environment must be secure and accessible from remote locations using standard internet protocols for development and use;
- DR-3: The environment must support experimentation, analysis, and test use cases across a variety of users as identified in the Journey-Map effort and at a variety of classification levels;
- DR-4: The simulation environment must allow for standalone execution and/or distributed federated multi-simulation instance execution across fidelity, resolution, and domain dimensions;
- DR-5: The experimentation and analytic environment must allow the integration and distributed use of pre- and post-simulation execution scenario development and analysis tools and be easily integrated with external real-world C2 and other AI-supported decision-support tools;
- DR-6: The environment must be extensible to integrate tools from different scientific and engineering disciplines such as systems engineering (e.g., Cameo Magic Draw, IBM Rhapsody, etc.), M&S (e.g., MATLAB/Simulink, Army OneSAF, Navy NGTS, Air Force AFSIM, etc.), and autonomy and artificial intelligence (e.g., Gazebo, Unreal Engine, etc.) in a common workflow to expedite project deliveries.
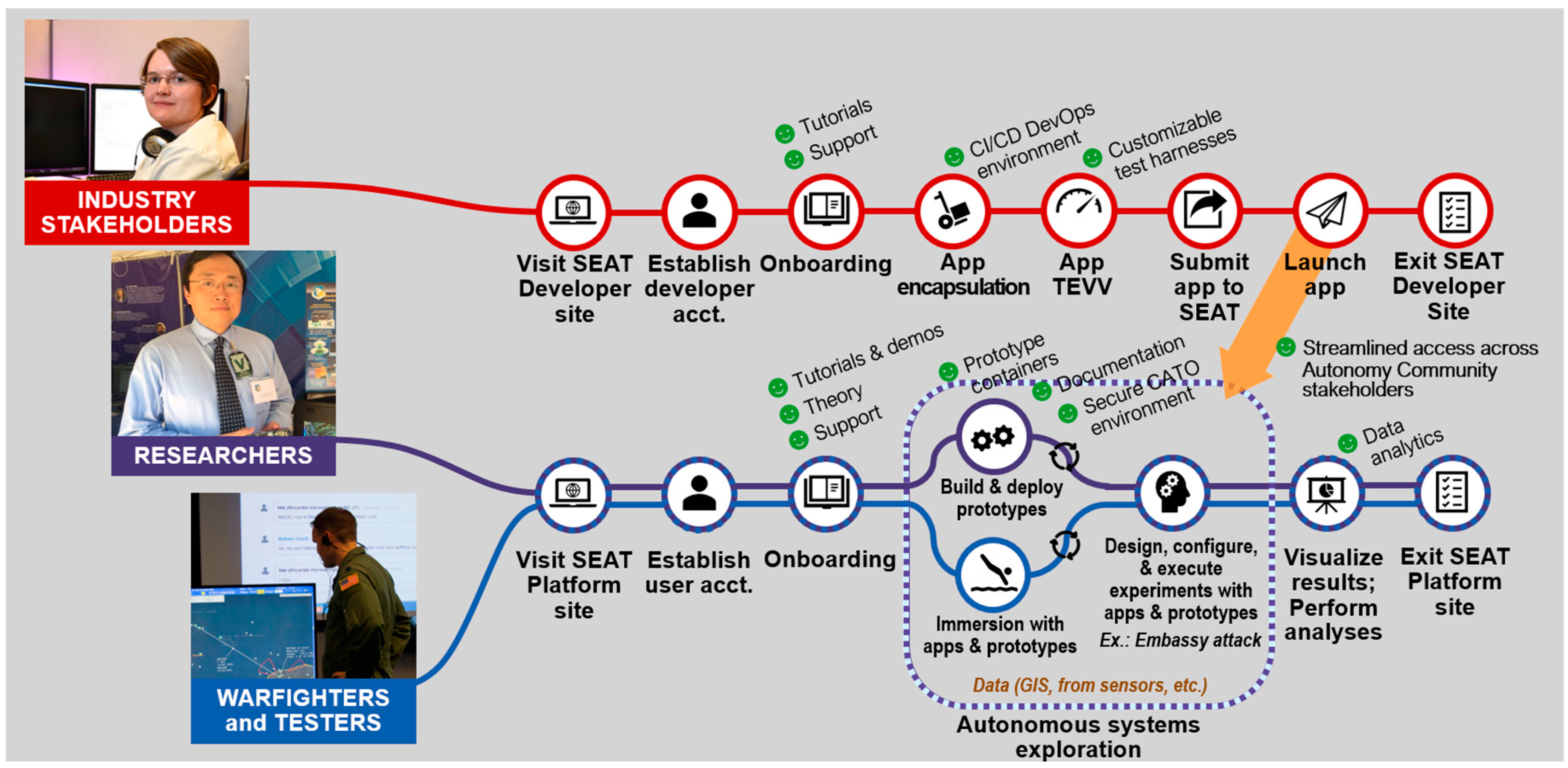
- Warfighter/Test and Evaluation Assessor—A domain expert, evaluator, or end-user that may provide the model or the overall scenario context and is interested in all aspects of the modeled System of Systems (SoS) or may want to test out or experiment with a specific capability;
- Researcher/Developer—A software/systems/simulation engineer that builds or contributes to the SEAT infrastructure and manages the release/build process through the CI/CD DevSecOps methodologies. This user engineers the M&S SoS federation;
- Industry Stakeholder/Practitioner—An external participant who contributes to the SEAT framework in either a passive or active manner and brings modular capabilities for integration into the SEAT environment that are provided by the researcher/developer.
4.2. SEAT Layered Reference Architecture Framework
4.3. SEAT Reference Service Layers
4.3.1. Hardware Infrastructure (IaaS)
4.3.2. Cloud Platform (PaaS) Services
4.3.3. Simulation Infrastructure as a Service (SIMaaS) and Software Utilities as a Service (SaaS) Reference Layer
- Simulation Infrastructure (SIMaaS): This component houses essential and common simulation tools offered as services that can be shared across the executing simulations. Examples of simulation tools that have been integrated as services include Unreal Engine, NetLogo (headless), Gazebo, and customized Command and Control simulation software. These common services include middleware message services such as EMQX, object brokering services such as the High-Level Architecture Runtime Infrastructure (HLA RTI), data transfer services through Distributed Interactive Simulation (DIS), time and event management services, database and repository services, and environmental representation services through project-specific middleware. Other specialized services include damage effects services, vulnerability modeling services, etc.;dsf
- Software Utilities (SaaS): This component houses software libraries and utilities to support scenario creation, data harmonization, and both information and model validation, as well as an asset library for compilation and translation tools. SaaS supports both the SIMaaS and MaaS layers and interfaces with PaaS for deployment on Cloud infrastructure.
4.3.4. Modeling Services (MaaS) Layer Reference Implementation Layers
4.3.5. Experimentation and Gaming Services (EXaaS)
4.3.6. Visualization Services (VISaaS)
4.3.7. Data/Repository Layer
4.3.8. Analytics Layer
4.3.9. User App Layer
4.3.10. Security Layer
5. SEAT Engineering Methodology
- Selection of appropriate SEAT architecture layers: Every SEAT-compliant project and the associated SoS architecture will be different in terms of the different tools and services that need to be brought together for a specific project (Figure 4);
- Unified data model: Having a common data model is a fundamental requirement for integrating two different systems that need to interoperate;
- Transport mechanism between constituent systems: This includes the communication protocols and the actual physical channels for message exchange;
- Hardware/Software interfaces are implemented through Application Programming Interfaces (APIs). This includes various APIs wrapping the hardware/software components;
- Deployment of the software components over the hardware and Cloud infrastructure: If the software is modular, this aspect provides external APIs for access and control, and if it is platform-neutral, then it may be containerized and made available as a container within the Docker paradigm;
- Dependency management for the constituent systems. This includes various software libraries and execution environments that need to be bundled for a certain component;
- Time and event synchronization: This is a critical aspect of any distributed simulation integration. The software systems may have time and event dependencies;
- Information, message, and object brokering. This includes various message brokers for enabling information/data exchange;
- Existing Continuous Integration/Continuous Delivery (CI/CD) mechanisms. This includes various CI/CD pipelines that each of the software components brings;
- Rapid and Continuous Authority to Operate (rATO, cATO): The objective is to have a SEAT environment where new or modified applications can be rapidly approved and incorporated into the simulation environment through a process that supports a Continuous Authority-to-Operate (Continuous ATO or cATO). There are two primary objectives for information assurance: rapid ATO and application approval and security. Rapid ATO is a process by which applications can receive an ATO quickly. Application approval and security provide a mechanism to integrate applications with minimal delay and without jeopardizing security objectives.
- An operational SEAT Development runtime environment that runs the simulations with interoperating models (for Warfighter/Tester);
- An infrastructure development CI/CD pipeline (for Researcher/Provider);
- An application development CI/CD pipeline (for Industry/Vendor).
6. Cloud-Based Infrastructure
6.1. MITRE Symphony Platform
6.2. Infrastructure-as-Code (IaC)
6.3. Hybrid Cloud Deployment
7. MSaaS Workflow Engineering
7.1. Workflow Engineering for M&S
- Onboarding and provisioning;
- Software and simulation integration.
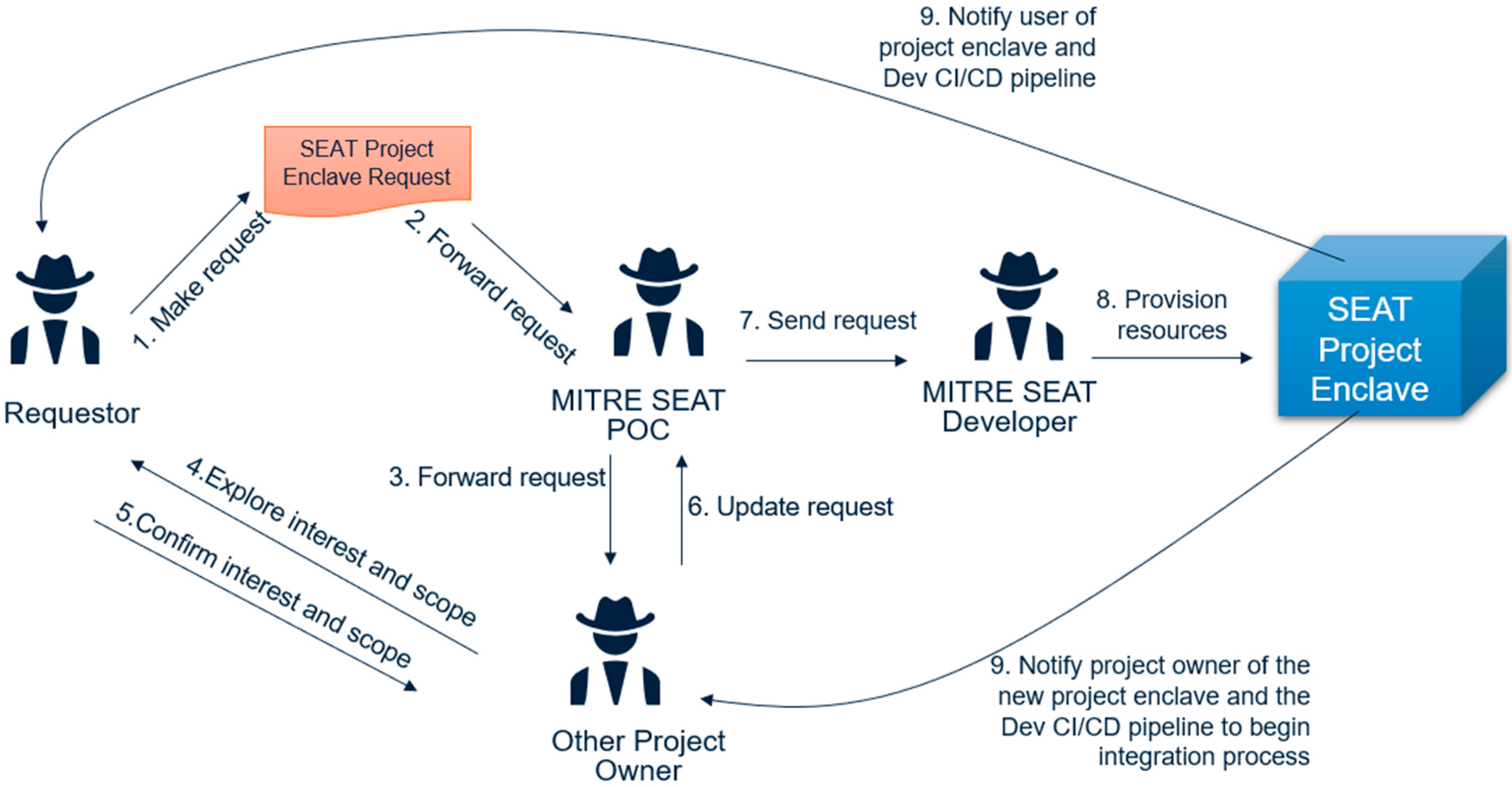
7.1.1. Onboarding and Provisioning Workflows
- Experimentation Workflow: This workflow is executed by the Warfighter or T&E practitioner (Figure 2). This user exercises the integrated solution developed by the other two user types for large-scale concurrent experimentation.
7.1.2. Software and Simulation Integration Workflow
- Passive (read) mode for data listening only: The incoming model/algorithm application, or “app”, will passively listen to the data channels for accessing data/repositories to add value through its app. It may work with or without simulation integration and may provide value addition both during simulation and post-simulation;
- Active (read/write) mode for simulation integration: The incoming application, or “app”, requires comprehensive integration with simulation engines. The level of effort is dependent on a case-by-case basis. Various available simulation interoperability standards, such as DIS, HLA, or Test and Training Enabling Architecture (TENA), could be used to align the data models and implement time synchronization strategies.
8. Case Study
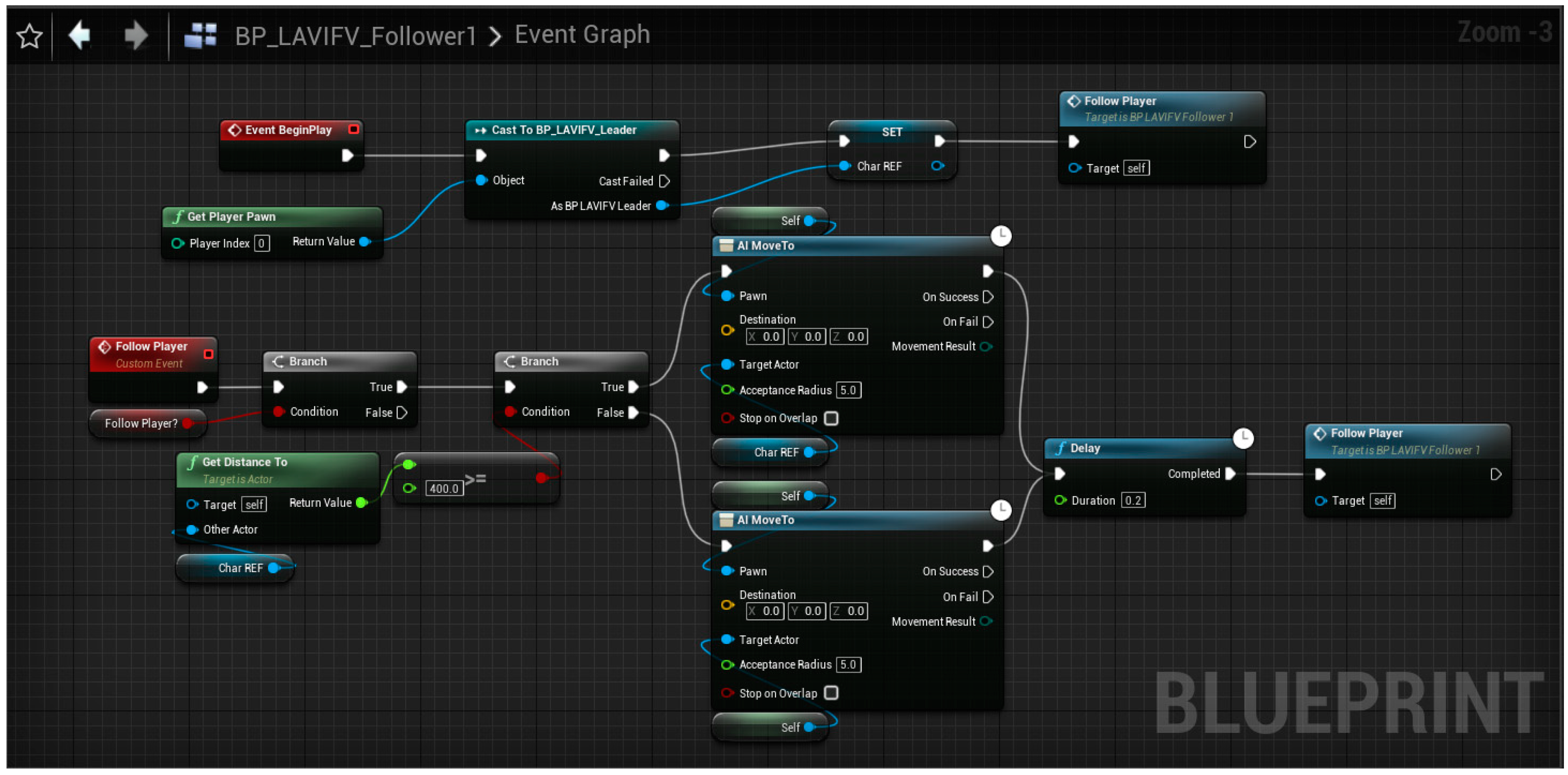
- Models Expedient Leader Follower (ExLF) using unmanned ground vehicles (UGVs) in a high-fidelity, high-resolution environment within a broader mission context;
- Applies MSaaS and the SEAT framework to engineer the M&S architecture;
- Offers the entire augmented architecture as an on-demand test architecture deployable in a cloud environment.
8.1. Scenario Description
- Demonstrate modeling of UGV expedient leader-follower behaviors at high fidelity and resolution using gaming engines such as Unreal Engine;
- Integrated a convoy pattern in a larger mission context using high-fidelity and low-resolution models;
- Demonstrate an integrated multi-fidelity simulation architecture;
- Demonstrate MaaS and SimaaS as separate capabilities;
- Demonstrate the deployment of the entire M&S architecture in an on-demand manner in a target cloud environment.
8.2. Application of SEAT Engineering Methodology
- Selection of appropriate SEAT architecture layers: To implement the scenario, we will be working with the MaaS, SIMaaS, SaaS, PaaS, IaaS, User App, Security, and VISaaS layers from the SEAT layered architecture framework (Figure 3). Table 1 associates the layers with the different tools brought together;
- Unified data model: Google Protocol buffers [35] as our data specification format. The data bindings can be generated in languages such as C++, C#, Dart, Go, Java, and Python;
- 3.
- Transport mechanism between constituent systems: The EMQX (2020) message broker and the MQTT (2020) communication protocol that runs on TCP/IP between the simulation participants (ESimP and Unreal). The EMQX broker is a fully open source (Apache License Version 2.0), highly scalable, highly available distributed MQTT messaging broker for the Internet of Things (IoT), Machine-to-Machine (M2M), and mobile applications that can handle tens of millions of concurrent clients. EMQX supports MQTT V5.0 protocol specifications [36,37] as well as other communications protocols such as MQTT-SN, CoAP, LwM2M, WebSocket, and STOMP.
- 4.
- Hardware/Software interfaces: The Unreal and ESimP M&S systems through the Protocol Buffers interface with the EMQX message broker. EMQX provides various bindings and adapters to interface with the two systems;
- 5.
- Deployment of the software components over the hardware:
- EMQX, ESimP, Flask, and Apache Airflow [38] are deployable on Windows, Linux, and MacOS platforms or as a docker image for cloud deployment;
- Unreal is deployable on Windows platforms within a VM. A plugin called Remote Web Interface was used to develop the service façade in Unreal;
- 6.
- Dependency management for the constituent systems: EMQX requires the Erlang OTP runtime environment. ESimP is built on NetLogo and requires Python binding. Unreal requires specific network configuration for remote visualization. Flask and Workflow engines require Python runtime;
- 7.
- Time synchronization: We adhere to real-time integration, so both Unreal and ESimP advance in real-time. All the propagation delays are negligible as both systems will be within the same enclave;
- 8.
- Information, message, and object brokering: EMQX and RabbitMQ were used as information brokers. EMQX was used to integrate ESimP and Unreal. RabbitMQ was used in building customized workflow execution;
- 9.
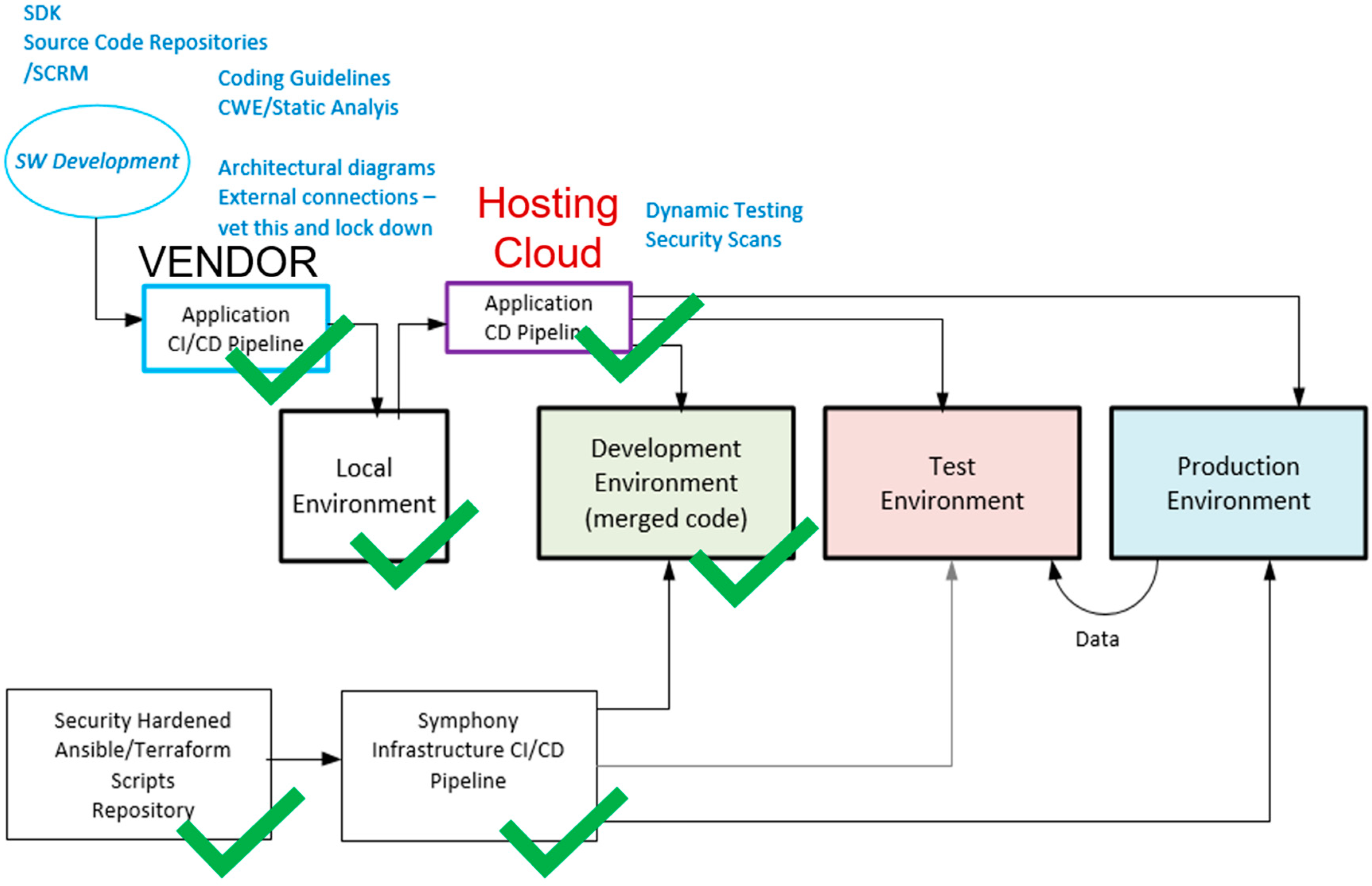
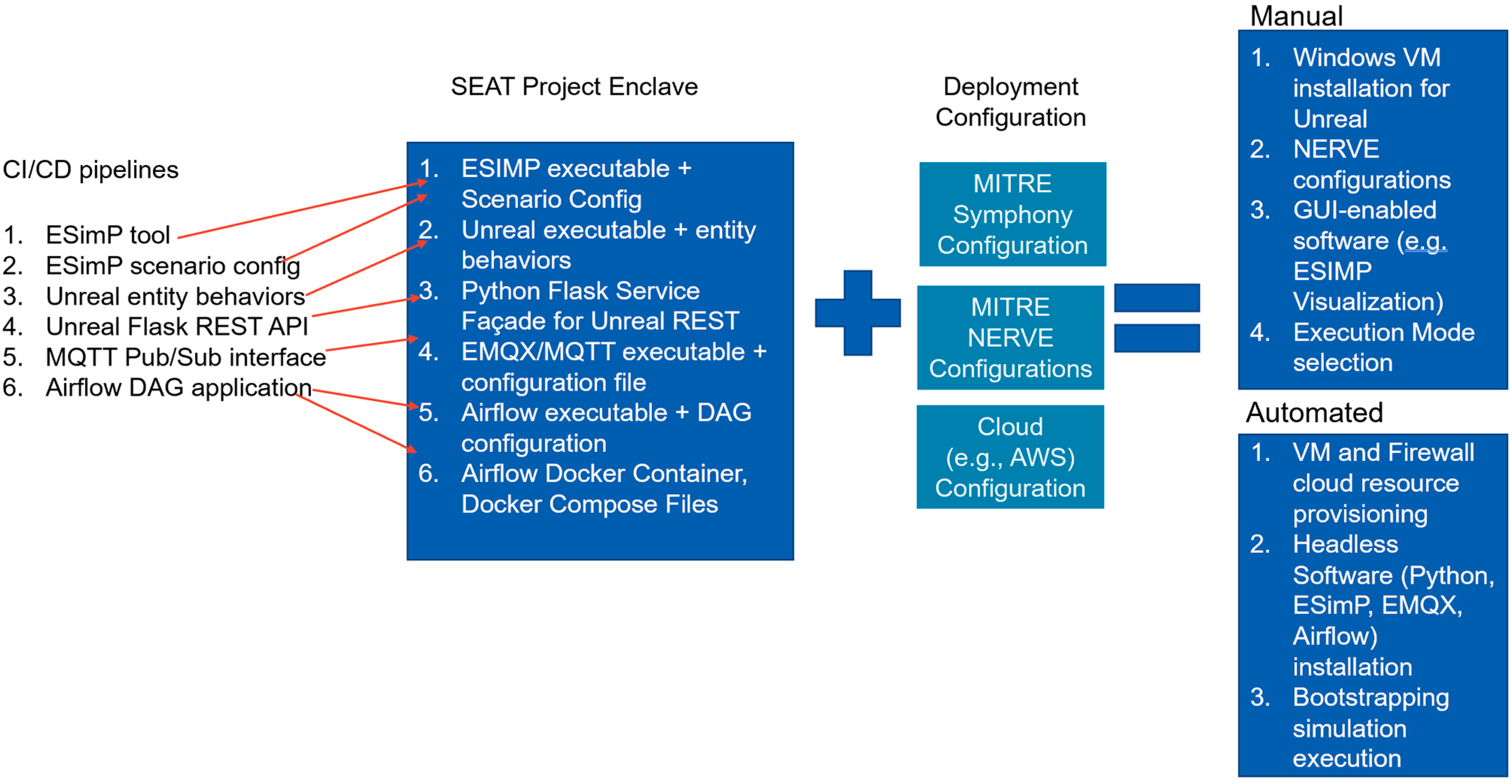
- Existing Continuous Integration/Continuous Delivery (CI/CD) mechanisms: The project had multiple software modules that contributed to the solution. Figure 8 shows various CI/CD pipelines that must be brought together to build the entire M&S architecture solution;
- 10.
- Rapid and Continuous Authority to Operate (r-ATO, c-ATO): As stated earlier, for the purpose of an IA analysis, the SEAT framework can be viewed as a three-tiered system (Figure 5). The operational SEAT environment is the Development Environment Enclave. The infrastructure and application CI/CD pipelines are to be brought together to integrate the modeling and simulation tools and applications in the Development Environment. This entire configuration set, along with the deployment configuration, can be subjected to cATO and rATO processes. Figure 8 shows the various CI/CD pipelines and configurations that support semi-automated deployment. Once the Development Environment Enclave is operational and the scenario is executable as an integrated architecture with ESimP and Unreal, the entire solution architecture is ready for on-demand deployment as a test environment (Figure 5) enclave using the IaC. The green checkmarks in Figure 5 reflect the state of maturity of the semi-automated process.
8.3. ESimP and NetLogo Mission-Level Modeling Environment
8.4. Unreal Engine and Modeling as a Service (MaaS) API Design
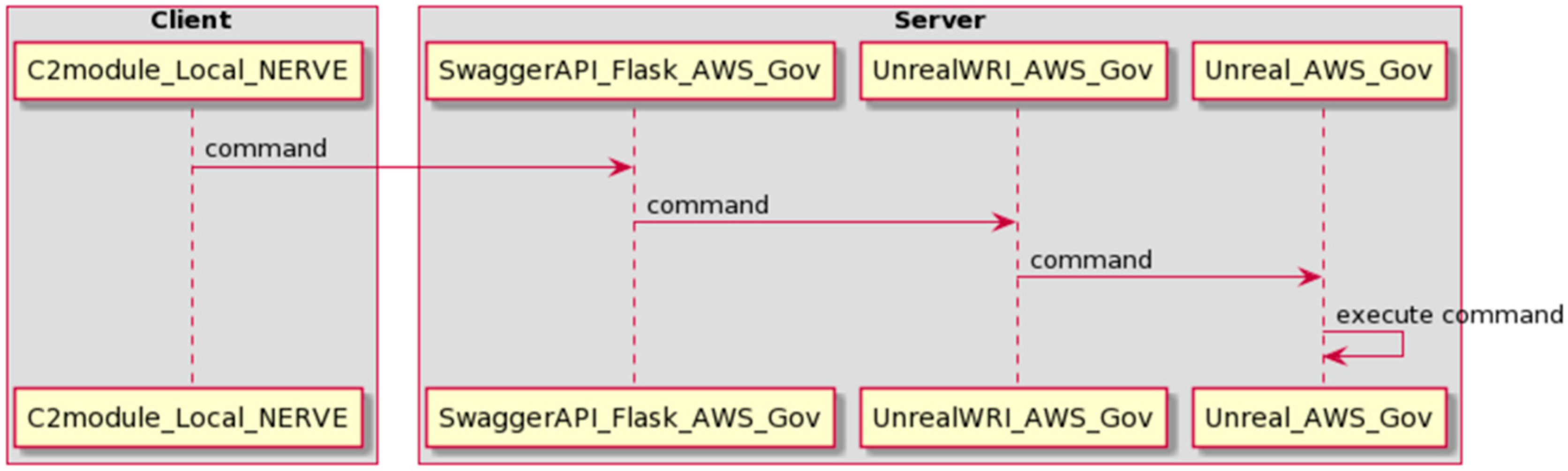
API Architecture
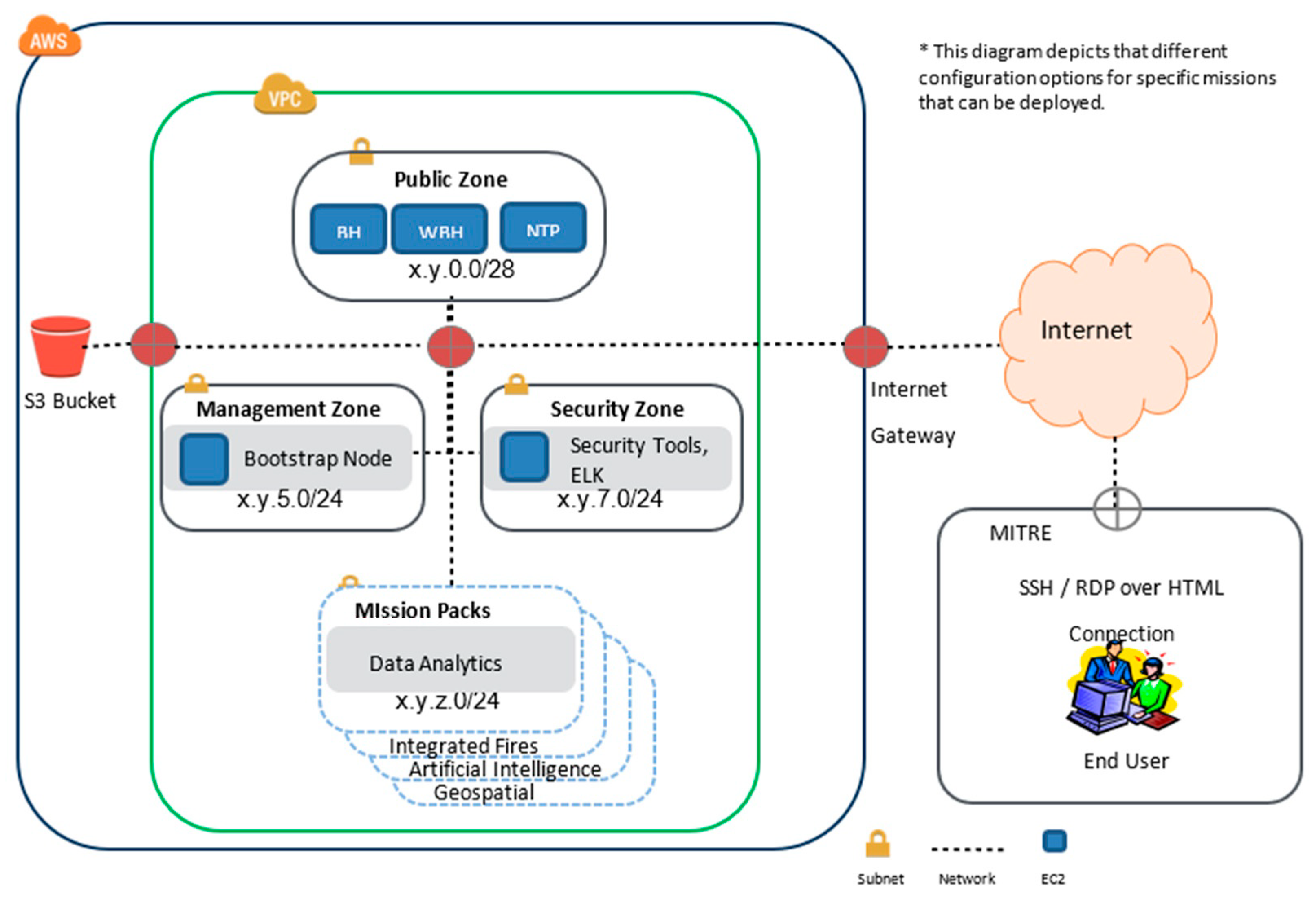
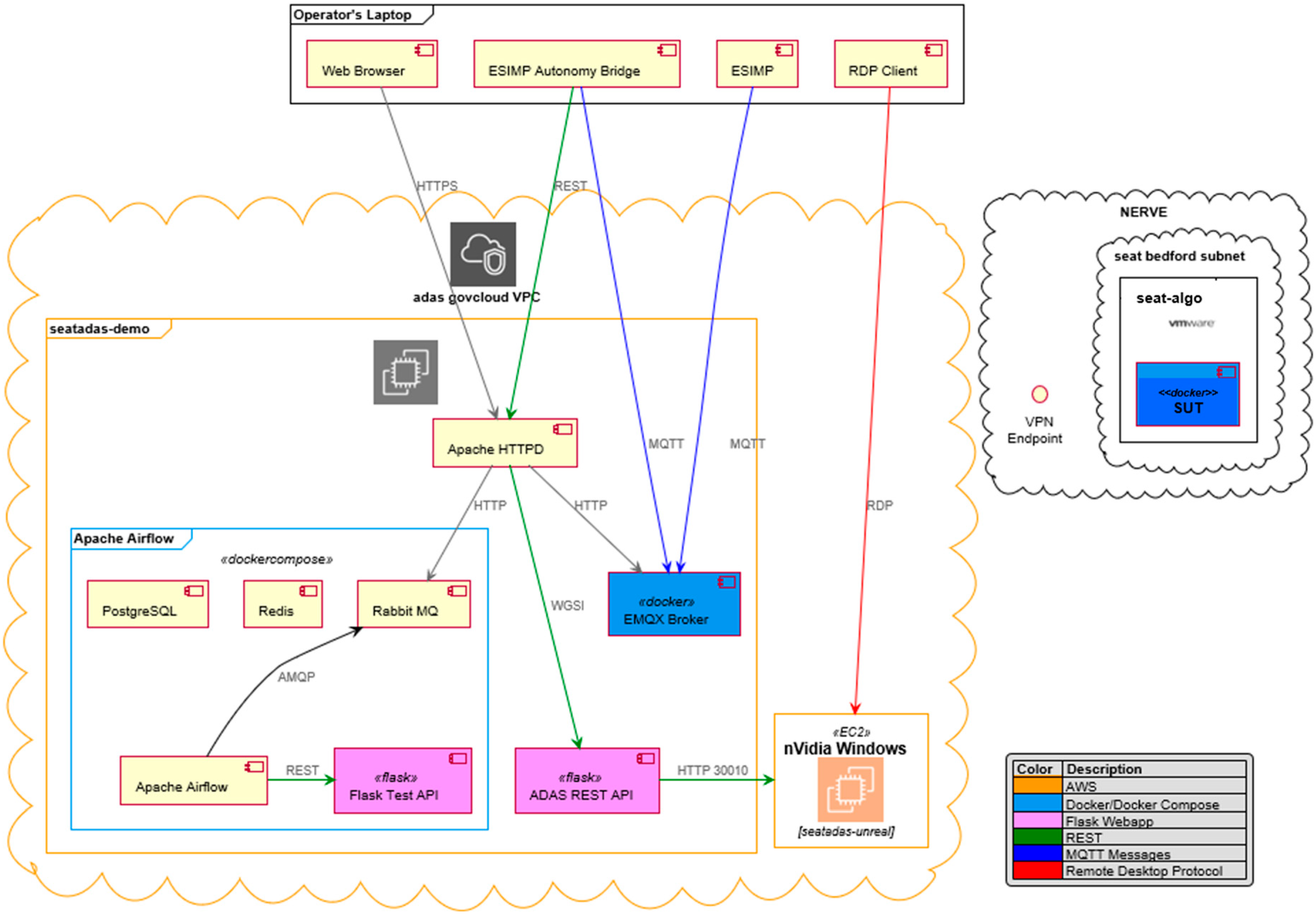
8.5. Cloud Deployment Architectures
- seatadas-demo: Running Linux to handle EMQX, the REST APIs, and Apache Airflow;
- seatadas-unreal: Running Windows to host Unreal.
8.6. On-Demand Deployment for a Test Environment
9. Discussion
- Codebase: A single application codebase tracked with a verified revision control system allowing for managed deployments;
- Dependencies: Explicit declaration, isolation, and management of dependencies;
- Configuration: Explicit storage of configuration information and data in the environment;
- Backing Services: The treatment of backing services as attached resources;
- Build, release, and run: Strict separation of build and run stages;
- Processes: The application should be executed as one or more stateless processes;
- Port binding: Export services via port binding;
- Concurrency: Scale out via the process model;
- Disposability: Maximize robustness with fast startup and graceful shutdown;
- Dev/prod parity: Keep development, staging, and production as similar as possible;
- Logs: Treat logs as event streams;
- Admin processes: Run admin/management tasks as one-off processes.
10. Conclusions
- M&S services are implemented through a layered approach supported by a reference architecture (SEAT layered architecture framework);
- Modular architecture was deployed in a cloud SEAT enclave using MITRE Symphony IaC and IaaS, reproducible to other target cloud infrastructures as well;
- The heterogeneous architecture includes a federated M&S architecture using MaaS and MSaaS principles;
- A modular autonomy controller can be replaced by a more advanced controller for experimentation with other leader-follower formations, leveraging entity-level behavioral APIs for a multi-fidelity experimentation environment;
- The entire M&S architecture is made available on-demand and cloud-ready using MSaaS principles for extensibility, continued development, and large-scale T&E;
- The workflow engineering infrastructure allows expedited development of service facades on various tools to be made available as tools-as-a-service within the layered multi-fidelity architecture for API-enabled SoS;
- The development workflow with associated CI/CD pipelines and various tools as services can be deployed in a semi-automated manner in hybrid cloud settings;
- The 10-step methodology can be reproduced for other M&S and AI-enabled integrated architectures with a rapid turnaround.
Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- David, R.; Nielsen, P. Summer Study on Autonomy; Defense Science Board, Office of Under Secretary of Defense: Washington, DC, USA, 2016.
- Mittal, S.; Martin, J.L.R. Simulation-Based Complex Adaptive Systems. In Guide to Simulation-Based Disciplines: Advancing Our Computational Future; Mittal, S., Durak, U., Oren, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- DeLaurentis, D.A.; Moolchandani, K.; Guariniello, C. System of Systems Modeling and Analysis, 1st ed.; CRC Press: Boca Raton, FL, USA, 2022. [Google Scholar] [CrossRef]
- Mittal, S.; Zeigler, B.P.; Martin, J.L.R.; Sahin, F.; Jamshidi, M. Modeling and Simulation for System of Systems Engineering. In System of Systems Engineering for 21st Century; Jamshidi, M., Ed.; Wiley & Sons: Hoboken, NJ, USA, 2008. [Google Scholar]
- Muehlen, M.; Hamilton, D.; Peak, R. Integration of M&S (Modeling and Simulation), Software Design and DoDAF (Department of Defense Architecture Framework RT 24), A013–Final Technical Report SERC-2012-TR-024, Systems Engineering Research Center. 2012. Available online: https://apps.dtic.mil/sti/pdfs/ADA582069.pdf (accessed on 20 May 2023).
- Mittal, S.; Martin, J.L.R. DEVSML 3.0: Rapid Deployment of DEVS Farm in Cloud Environment using Microservices and Containers. In Proceedings of the Symposium on Theory of Modeling and Simulation, Spring Simulation Multi-Conference, Virginia Beach, VA, USA, 23–26 April 2017. [Google Scholar]
- Air Force. Platform One. 26 October 2021. Available online: https://software.af.mil/team/platformone/ (accessed on 20 May 2023).
- Amazon Cloud Services . 10 September 2023. Available online: https://aws.amazon.com/govcloud-us/?whats-new-ess.sort-by=item.additionalFields.postDateTime&whats-new-ess.sort-order=desc (accessed on 20 May 2023).
- Henninger, A. Strategic Implications of Cloud Computing for Modeling and Simulation (Briefing), IDA. 2016. Available online: https://apps.dtic.mil/sti/pdfs/AD1018235.pdf (accessed on 20 May 2023).
- Mittal, S.; Kasdaglis, N.; Harrell, L.; Wittman, R.; Gibson, J.; Rocca, D. Autonomous and Composable M&S System of Systems with the Simulation, Experimentation, Analytics and Testing (SEAT) Framework. In Proceedings of the Winter Simulation Conference, Orlando, FL, USA, 14–18 December 2020. [Google Scholar]
- Simulation Interoperability Standards Organization. Available online: http://www.sisostds.org (accessed on 20 May 2023).
- IEEE Standard 1278.1-2012; IEEE Standard for Distributed Interactive Simulation—Application Protocols. IEEE: New York, NY, USA. Available online: https://standards.ieee.org/ieee/1278.1/4949/ (accessed on 20 May 2023).
- IEEE Std 1516-2020; Framework and Rules, High Level Architecture Federation Rules. IEEE: New York, NY, USA, 2020.
- IEEE Std 1516.1-2010; Federate Interface Specification, The Runtime Infrastructure (RTI) Service Specification. IEEE: New York, NY, USA, 2010.
- IEEE Std 1516.2-2010; Object Model Template Specification The HLA Object Model Format Specification. IEEE: New York, NY, USA, 2010.
- IEEE Std 1730; Distributed Simulation Engineering and Execution Process. IEEE: New York, NY, USA, 2010.
- Turrel, C.; Brown, R.; Igarza, J.L.; Pixius, K.; Renda, F.; Rouget, C. Federation Development and Execution Process (FEDEP) Tools in Support for NATO Modelling & Simulation (M&S) Programmes; RTO Technical Report, TR-MSG-005; NATO Research and Technology Agency: Neuilly-Sur-Seine Cedex, France, 2004; Available online: https://apps.dtic.mil/dtic/tr/fulltext/u2/a429045.pdf (accessed on 20 May 2023).
- SISO-STD-019-2020; Standard for Command-and-Control Systems- Simulation Systems Interoperation. Simulation Interoperability Standards Organization, Inc.: Orlando, FL, USA, 2020.
- Test and Training Enabling Architecture. Available online: http://tena-sda.org (accessed on 20 May 2023).
- Test Resource Management Center. Test and Training Enabling Architecture Overview. Available online: https://www.trmc.osd.mil/tena-home.html (accessed on 20 May 2023).
- Van den Berg, T.; Siegel, B.; Cramp, A. Containerization of high level architecture-based simulations: A Case Study. J. Def. Model. Simul. 2016, 14, 115–138. [Google Scholar] [CrossRef]
- Kewley, R.; McGroarty, G.; McDonnell, J.; Gallant, S.; Diemunsch, J. Cloud-Based Modeling and Simulation Study Group. Available online: https://www.sisostds.org/StandardsActivities/StudyGroups/CBMSSG.aspx (accessed on 20 May 2023).
- Hannay, J.E.; van den Berg, T. The NATO MSG-136 Reference Architecture for M&S as a Service. STO-MP-MSG-149. 2017. Available online: https://www.sto.nato.int/publications/STO%20Meeting%20Proceedings/STO-MP-MSG-149/MP-MSG-149-03.pdf (accessed on 20 May 2023).
- NATO MSG-136; Modelling and Simulation as a Service, Volume 2: MSaaS Discover Service and Metadata; TR-MSG-136-Part-V. NATO Science and Technology Organization: Neuilly-sur-Seine Cedex, France. Available online: https://apps.dtic.mil/sti/pdfs/AD1078382.pdf (accessed on 20 May 2023).
- Bucher, N. “Always On–On Demand”: Supporting the Development, Test and Training of Operational Networks & Net-Centric Systems. In Proceedings of the NDIA 16th Annual Systems Engineering Conference, Hyatt Regency, Crystal City, VA, USA, 28–31 October 2013. [Google Scholar]
- US Army Futures and Concepts Center, Battle Lab Collaborative Simulation Environment (BLCSE) Overview. Available online: https://www.erdc.usace.army.mil/Media/News-Stories/Article/2782269/battle-lab-collaborative-simulation-environment-offers-erdc-new-capabilities/2021 (accessed on 20 May 2023).
- Open API 3.0. Available online: http://openapis.org (accessed on 20 May 2023).
- Swagger Toolset. Available online: http://swagger.io (accessed on 20 May 2023).
- Async API. Available online: http://asyncapis.com (accessed on 20 May 2023).
- OUSD. DOD Instructure 5000.87: Operation of the Software Acquisition Pathway, under Secretary of Defense for Acquisition and Sustainment; Department of Defense: Washington, VA, USA, 2020.
- Bond, J.; Rocca, D.; Foote, A.; Gibson, J.; Dalphond, J. Symphony Documentation. 4 August 2022. Available online: https://symphonydocs.mitre.org/ (accessed on 20 May 2023).
- Symphony Development Team. Symphony Core. 2022. Available online: https://git.codev.mitre.org/projects/SYMPHONYDEV/repos/symphony-core/ (accessed on 20 May 2023).
- Symphony Team. Internal Symphony Website. 2022. Available online: https://symphony.mitre.org/ (accessed on 20 May 2023).
- McKeown, D. Memorandum for Senior Pentagon Leadership Defense Agency and DoD Field Activity Directors, Subject: Continuous Authorization to Operate (cATO). 2022. Available online: https://mitre.sharepoint.com/sites/straighttalkforgov/Shared%20Documents/General/CONTINUOUS-AUTHORIZATION-TO-OPERATE.PDF (accessed on 20 May 2023).
- Google. Protocol Buffers. 2020. Available online: https://developers.google.com/protocol-buffers (accessed on 20 May 2023).
- EMQX. 2020. Available online: https://www.emqx.io/ (accessed on 20 May 2023).
- MQTT. Available online: http://mqtt.org (accessed on 20 May 2023).
- Airflow. Available online: http://airflow.apache.org (accessed on 20 May 2023).
- Wilensky, U.; Rand, B. Introduction to Agent-Based Modeling: Modeling Natural, Social and Engineering Complex Systems with NetLogo; MIT Press: Cambridge, MA, USA, 2015. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Tool |
|---|---|
| VISaaS | ESimP, Unreal, EMQx Management Console via Browser |
| MaaS | ESimP scripts, Unreal blueprint and models |
| SIMaaS | ESimP NetLogo core, Unreal Engine |
| SaaS | Python, Apache Airflow, RabbitMQ, EMQX |
| PaaS | MITRE Symphony, IaC |
| IaaS | MITRE NERVE, Amazon AWS |
| User App | MIMIC |
| Security | IaC, cATO |
| Layer | API Function | REST URL | Parameters |
|---|---|---|---|
| Coordination Behavior Service API | Destroy a vehicle | /KillVehicle | Vehicle ID |
| Move leader to x/y | /MoveLeader | X/Y | |
| Get current leader position | /LeaderPosition | ||
| Get the requested leader location | /GetRequestedLeaderLocation | ||
| Select vehicle to assume role of leader | /ElectLeader | Vehicle ID | |
| Get situation report that includes all vehicle ID, location, speed, heading | /SitRep | ||
| Stop vehicle | /StopVehicle | Vehicle ID | |
| Start vehicle | /StartVehicle | Vehicle ID | |
| Complex Behavior Service API | Perform box pattern | /PerformBoxPattern | Radius, starting angle (degrees), number of repetitions |
| Perform circle pattern | /PerformCirclePattern | Radius, starting angle (degrees), number of repetitions | |
| Calculate reward for autonomous applications | /Reward | ||
| Spawn red/blue cube with spawn name above | /SpawnActor | Spawn name, X/Y, color(red/blue) | |
| Get basic attributes of vehicle | /DescribeVehicle{Zero,One,Two,Three,Four,Five} | ||
| Primitive Behavior Service API | Get comprehensive attributes of vehicle | /Vehicle{Zero,One,Two,Three,Four,Five}Attributes | |
| Return number of vehicles not destroyed | /NumOfVehicles | ||
| Vehicle speed | /VehicleSpeed | Vehicle ID | |
| Vehicle position | /VehiclePosition | Vehicle ID | |
| Magic move a vehicle | /TeleportVehicle | Vehicle ID, X/Y | |
| Vehicle heading | /VehicleHeading | Vehicle ID | |
| Get vehicle controller attributes | /GetVehicleControllerAttributes |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by The MITRE Corporation. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mittal, S.; Wittman, R.L.; Gibson, J.; Huffman, J.; Miller, H. Providing a User Extensible Service-Enabled Multi-Fidelity Hybrid Cloud-Deployable SoS Test and Evaluation (T&E) Infrastructure: Application of Modeling and Simulation (M&S) as a Service (MSaaS). Information 2023, 14, 528. https://doi.org/10.3390/info14100528
Mittal S, Wittman RL, Gibson J, Huffman J, Miller H. Providing a User Extensible Service-Enabled Multi-Fidelity Hybrid Cloud-Deployable SoS Test and Evaluation (T&E) Infrastructure: Application of Modeling and Simulation (M&S) as a Service (MSaaS). Information. 2023; 14(10):528. https://doi.org/10.3390/info14100528
Chicago/Turabian StyleMittal, Saurabh, Robert L. Wittman, John Gibson, Josh Huffman, and Hans Miller. 2023. "Providing a User Extensible Service-Enabled Multi-Fidelity Hybrid Cloud-Deployable SoS Test and Evaluation (T&E) Infrastructure: Application of Modeling and Simulation (M&S) as a Service (MSaaS)" Information 14, no. 10: 528. https://doi.org/10.3390/info14100528
APA StyleMittal, S., Wittman, R. L., Gibson, J., Huffman, J., & Miller, H. (2023). Providing a User Extensible Service-Enabled Multi-Fidelity Hybrid Cloud-Deployable SoS Test and Evaluation (T&E) Infrastructure: Application of Modeling and Simulation (M&S) as a Service (MSaaS). Information, 14(10), 528. https://doi.org/10.3390/info14100528