Author Contributions
Design of experiments, E.M. and D.D.; Dataset creation, E.M., M.H.I.A. and S.M.; Experiments, M.H.I.A. and S.M.; writing—original draft preparation, E.M.; writing—journal version preparation, D.D. and S.M.; writing—review and editing, G.G. All authors have read and agreed to the published version of the manuscript.
Funding
This paper has been supported by the German Federal Ministry of Education and Research (BMBF, grant 01IS17049).
Institutional Review Board Statement
Not applicable.
Data Availability Statement
Acknowledgments
We would like to acknowledge the help of Social Research Computing Group for providing an opportunity to conduct this research and Paolo Basso and Margherita Musumeci for participating in the first version of this publication. Additionally, we would like to thank Leslie McIntosh for her guidance throughout our research journey.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| NLP | Natural Language Processing |
| LLM | Large Language Model |
| BoW | Bag-of-Words |
| OOD | Out-of-Domain |
| CFG | Context-Free-Grammars |
References
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Scao, T.L.; Fan, A.; Akiki, C.; Pavlick, E.; Ilić, S.; Hesslow, D.; Castagné, R.; Luccioni, A.S.; Yvon, F.; Gallé, M.; et al. Bloom: A 176b-parameter open-access multilingual language model. arXiv 2022, arXiv:2211.05100. [Google Scholar]
- OpenAI. GPT-4 Technical Report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models are Unsupervised Multitask Learners. OpenAI Blog 2019. Available online: https://insightcivic.s3.us-east-1.amazonaws.com/language-models.pdf (accessed on 31 July 2023).
- Keskar, N.S.; McCann, B.; Varshney, L.R.; Xiong, C.; Socher, R. CTRL: A Conditional Transformer Language Model for Controllable Generation. arXiv 2019, arXiv:1909.05858. [Google Scholar] [CrossRef]
- Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; et al. Llama 2: Open Foundation and Fine-Tuned Chat Models. arXiv 2023, arXiv:2307.09288. [Google Scholar] [CrossRef]
- Zellers, R.; Holtzman, A.; Rashkin, H.; Bisk, Y.; Farhadi, A.; Roesner, F.; Choi, Y. Defending Against Neural Fake News. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- OpenAI. ChatGPT. 2022. Available online: https://openai.com/blog/chat-ai/ (accessed on 26 February 2023).
- Chen, M.; Tworek, J.; Jun, H.; Yuan, Q.; Pinto, H.P.d.O.; Kaplan, J.; Edwards, H.; Burda, Y.; Joseph, N.; Brockman, G.; et al. Evaluating large language models trained on code. arXiv 2021, arXiv:2107.03374. [Google Scholar]
- Liu, Y. Fine-tune BERT for extractive summarization. arXiv 2019, arXiv:1903.10318. [Google Scholar]
- Dergaa, I.; Chamari, K.; Zmijewski, P.; Saad, H.B. From human writing to artificial intelligence generated text: Examining the prospects and potential threats of ChatGPT in academic writing. Biol. Sport 2023, 40, 615–622. [Google Scholar] [CrossRef]
- Stokel-Walker, C. AI bot ChatGPT writes smart essays-should academics worry? Nature 2022. [Google Scholar] [CrossRef]
- Maynez, J.; Narayan, S.; Bohnet, B.; McDonald, R. On Faithfulness and Factuality in Abstractive Summarization. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Association for Computational Linguistics. Online, 5–10 August 2021; pp. 1906–1919. [Google Scholar] [CrossRef]
- Tian, R.; Narayan, S.; Sellam, T.; Parikh, A.P. Sticking to the facts: Confident decoding for faithful data-to-text generation. arXiv 2019, arXiv:1910.08684. [Google Scholar]
- Stribling, J.; Krohn, M.; Aguayo, D. SCIgen—An Automatic CS Paper Generator. 2005. Available online: https://pdos.csail.mit.edu/archive/scigen/ (accessed on 1 March 2023).
- Taylor, R.; Kardas, M.; Cucurull, G.; Scialom, T.; Hartshorn, A.; Saravia, E.; Poulton, A.; Kerkez, V.; Stojnic, R. Galactica: A large language model for science. arXiv 2022, arXiv:2211.09085. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Mitchell, E.; Lee, Y.; Khazatsky, A.; Manning, C.D.; Finn, C. DetectGPT: Zero-Shot Machine-Generated Text Detection using Probability Curvature. arXiv 2023, arXiv:2301.11305. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Mosca, E.; Abdalla, M.H.I.; Basso, P.; Musumeci, M.; Groh, G. Distinguishing Fact from Fiction: A Benchmark Dataset for Identifying Machine-Generated Scientific Papers in the LLM Era. In Proceedings of the 3rd Workshop on Trustworthy Natural Language Processing (TrustNLP 2023), Toronto, ON, Canada, 9–14 July 2023; pp. 190–207. [Google Scholar]
- Maronikolakis, A.; Schutze, H.; Stevenson, M. Identifying automatically generated headlines using transformers. arXiv 2020, arXiv:2009.13375. [Google Scholar]
- Liyanage, V.; Buscaldi, D.; Nazarenko, A. A Benchmark Corpus for the Detection of Automatically Generated Text in Academic Publications. In Proceedings of the Thirteenth Language Resources and Evaluation Conference, LREC 2022, Marseille, France, 20–25 June 2022; pp. 4692–4700. [Google Scholar]
- Wang, Y.; Mansurov, J.; Ivanov, P.; Su, J.; Shelmanov, A.; Tsvigun, A.; Whitehouse, C.; Afzal, O.M.; Mahmoud, T.; Aji, A.F.; et al. M4: Multi-generator, Multi-domain, and Multi-lingual Black-Box Machine-Generated Text Detection. arXiv 2023, arXiv:2305.14902. [Google Scholar] [CrossRef]
- He, X.; Shen, X.; Chen, Z.; Backes, M.; Zhang, Y. MGTBench: Benchmarking Machine-Generated Text Detection. arXiv 2023, arXiv:2303.14822. [Google Scholar] [CrossRef]
- Li, Y.; Li, Q.; Cui, L.; Bi, W.; Wang, L.; Yang, L.; Shi, S.; Zhang, Y. Deepfake Text Detection in the Wild. arXiv 2023, arXiv:2305.13242. [Google Scholar] [CrossRef]
- Bird, S.; Dale, R.; Dorr, B.; Gibson, B.; Joseph, M.; Kan, M.Y.; Lee, D.; Powley, B.; Radev, D.; Tan, Y.F. The ACL Anthology Reference Corpus: A Reference Dataset for Bibliographic Research in Computational Linguistics. In Proceedings of the Sixth International Conference on Language Resources and Evaluation (LREC’08); European Language Resources Association (ELRA), Marrakech, Morocco, 15–20 July 2008. [Google Scholar]
- arXiv.org submitters. arXiv Dataset 2023. [CrossRef]
- Cohan, A.; Goharian, N. Scientific Article Summarization Using Citation-Context and Article’s Discourse Structure. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 12–17 September 2015; pp. 390–400. [Google Scholar] [CrossRef]
- Saier, T.; Färber, M. Bibliometric-Enhanced arXiv: A Data Set for Paper-Based and Citation-Based Tasks. In Proceedings of the 8th International Workshop on Bibliometric-Enhanced Information Retrieval (BIR 2019) Co-Located with the 41st European Conference on Information Retrieval (ECIR 2019), Cologne, Germany, 14 April 2019; pp. 14–26. [Google Scholar]
- Lo, K.; Wang, L.L.; Neumann, M.; Kinney, R.; Weld, D. S2ORC: The Semantic Scholar Open Research Corpus. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 4969–4983. [Google Scholar] [CrossRef]
- Kashnitsky, Y.; Herrmannova, D.; de Waard, A.; Tsatsaronis, G.; Fennell, C.C.; Labbe, C. Overview of the DAGPap22 Shared Task on Detecting Automatically Generated Scientific Papers. In Proceedings of the Third Workshop on Scholarly Document Processing, Association for Computational Linguistics. Gyeongju, Republic of Korea, 17 October 2022; pp. 210–213. [Google Scholar]
- Gao, L.; Biderman, S.; Black, S.; Golding, L.; Hoppe, T.; Foster, C.; Phang, J.; He, H.; Thite, A.; Nabeshima, N.; et al. The Pile: An 800GB Dataset of Diverse Text for Language Modeling. arXiv 2021, arXiv:2101.00027. [Google Scholar]
- Waswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the NIPS, 4–9 December 2017. [Google Scholar]
- Anil, R.; Dai, A.M.; Firat, O.; Johnson, M.; Lepikhin, D.; Passos, A.; Shakeri, S.; Taropa, E.; Bailey, P.; Chen, Z.; et al. PaLM 2 Technical Report. arXiv 2023, arXiv:2305.10403. [Google Scholar] [CrossRef]
- Maheshwari, H.; Singh, B.; Varma, V. SciBERT Sentence Representation for Citation Context Classification. In Proceedings of the Second Workshop on Scholarly Document Processing, Online, 10 June 2021; pp. 130–133. [Google Scholar]
- MacNeil, S.; Tran, A.; Leinonen, J.; Denny, P.; Kim, J.; Hellas, A.; Bernstein, S.; Sarsa, S. Automatically Generating CS Learning Materials with Large Language Models. arXiv 2022, arXiv:2212.05113. [Google Scholar]
- Swanson, B.; Mathewson, K.; Pietrzak, B.; Chen, S.; Dinalescu, M. Story centaur: Large language model few shot learning as a creative writing tool. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations, Online, 21–23 April 2021; pp. 244–256. [Google Scholar]
- Liu, S.; He, T.; Li, J.; Li, Y.; Kumar, A. An Effective Learning Evaluation Method Based on Text Data with Real-time Attribution—A Case Study for Mathematical Class with Students of Junior Middle School in China. ACM Trans. Asian Low Resour. Lang. Inf. Process. 2023, 22, 63:1–63:22. [Google Scholar] [CrossRef]
- Jawahar, G.; Abdul-Mageed, M.; Lakshmanan, L.V.S. Automatic Detection of Machine Generated Text: A Critical Survey. In Proceedings of the 28th International Conference on Computational Linguistics, COLING 2020, Barcelona, Spain (Online), 8–13 December 2020; pp. 2296–2309. [Google Scholar] [CrossRef]
- Gehrmann, S.; Strobelt, H.; Rush, A.M. Gltr: Statistical detection and visualization of generated text. arXiv 2019, arXiv:1906.04043. [Google Scholar]
- Fagni, T.; Falchi, F.; Gambini, M.; Martella, A.; Tesconi, M. TweepFake: About detecting deepfake tweets. PLoS ONE 2021, 16, e0251415. [Google Scholar] [CrossRef]
- Kushnareva, L.; Cherniavskii, D.; Mikhailov, V.; Artemova, E.; Barannikov, S.; Bernstein, A.; Piontkovskaya, I.; Piontkovski, D.; Burnaev, E. Artificial Text Detection via Examining the Topology of Attention Maps. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021, Virtual Event/Punta Cana, Dominican Republic, 7–11 November 2021; Moens, M., Huang, X., Specia, L., Yih, S.W., Eds.; Association for Computational Linguistics: Cedarville, OH, USA, 2021; pp. 635–649. [Google Scholar] [CrossRef]
- Bakhtin, A.; Gross, S.; Ott, M.; Deng, Y.; Ranzato, M.; Szlam, A. Real or fake? Learning to discriminate machine from human generated text. arXiv 2019, arXiv:1906.03351. [Google Scholar]
- Ippolito, D.; Duckworth, D.; Callison-Burch, C.; Eck, D. Automatic detection of generated text is easiest when humans are fooled. arXiv 2019, arXiv:1911.00650. [Google Scholar]
- Kirchenbauer, J.; Geiping, J.; Wen, Y.; Shu, M.; Saifullah, K.; Kong, K.; Fernando, K.; Saha, A.; Goldblum, M.; Goldstein, T. On the Reliability of Watermarks for Large Language Models. arXiv 2023, arXiv:2306.04634. [Google Scholar] [CrossRef]
- Amancio, D.R. Comparing the topological properties of real and artificially generated scientific manuscripts. Scientometrics 2015, 105, 1763–1779. [Google Scholar] [CrossRef]
- Williams, K.; Giles, C.L. On the use of similarity search to detect fake scientific papers. In Proceedings of the Similarity Search and Applications: 8th International Conference, SISAP 2015, Glasgow, UK, 12–14 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 332–338. [Google Scholar]
- Nguyen, M.T.; Labbé, C. Engineering a tool to detect automatically generated papers. In Proceedings of the BIR 2016 Bibliometric-enhanced Information Retrieval, Padua, Italy, 20 March 2016. [Google Scholar]
- Cabanac, G.; Labbé, C. Prevalence of nonsensical algorithmically generated papers in the scientific literature. J. Assoc. Inf. Sci. Technol. 2021, 72, 1461–1476. [Google Scholar] [CrossRef]
- Beltagy, I.; Lo, K.; Cohan, A. SciBERT: A Pretrained Language Model for Scientific Text. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 3615–3620. [Google Scholar] [CrossRef]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- Glazkova, A.; Glazkov, M. Detecting generated scientific papers using an ensemble of transformer models. In Proceedings of the Third Workshop on Scholarly Document Processing, Gyeongju, Republic of Korea, 17 October 2022; pp. 223–228. [Google Scholar]
- Liu, Z.; Yao, Z.; Li, F.; Luo, B. Check Me If You Can: Detecting ChatGPT-Generated Academic Writing using CheckGPT. arXiv 2023, arXiv:2306.05524. [Google Scholar] [CrossRef]
- Yang, L.; Jiang, F.; Li, H. Is ChatGPT Involved in Texts? Measure the Polish Ratio to Detect ChatGPT-Generated Text. arXiv 2023, arXiv:2307.11380. [Google Scholar] [CrossRef]
- Rudduck, P. PyMuPDF: Python Bindings for the MuPDF Renderer. 2021. Available online: https://pypi.org/project/PyMuPDF/ (accessed on 7 March 2023).
- Stribling, J.; Aguayo, D. Rooter: A Methodology for the Typical Unification of Access Points and Redundancy. 2021. Available online: https://dipositint.ub.edu/dspace/bitstream/123456789/2243/1/rooter.pdf (accessed on 31 July 2023).
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. Adv. Neural Inf. Process. Syst. 2014, 27, 3104–3112. [Google Scholar]
- Cox, D.R. The regression analysis of binary sequences. J. R. Stat. Soc. Ser. B 1958, 20, 215–232. [Google Scholar] [CrossRef]
- Salton, G.; Buckley, C. Term-weighting approaches in automatic text retrieval. Inf. Process. Manag. 1988, 24, 513–523. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Ichter, B.; Xia, F.; Chi, E.; Le, Q.; Zhou, D. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. arXiv 2023, arXiv:2201.11903. [Google Scholar]
- Hadsell, R.; Chopra, S.; LeCun, Y. Dimensionality reduction by learning an invariant mapping. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 2, pp. 1735–1742. [Google Scholar]
- Müllner, D. Modern hierarchical, agglomerative clustering algorithms. arXiv 2011, arXiv:1109.2378. [Google Scholar]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Lundberg, S.; Lee, S.I. A Unified Approach to Interpreting Model Predictions. International Conference on Machine Learning. arXiv 2017, arXiv:1705.07874. [Google Scholar]
- Mosca, E.; Szigeti, F.; Tragianni, S.; Gallagher, D.; Groh, G. SHAP-Based Explanation Methods: A Review for NLP Interpretability. In Proceedings of the 29th International Conference on Computational Linguistics, Gyeongju, Republic of Korea, 12–17 October 2022; pp. 4593–4603. [Google Scholar]
- Mosca, E.; Harmann, K.; Eder, T.; Groh, G. Explaining Neural NLP Models for the Joint Analysis of Open-and-Closed-Ended Survey Answers. In Proceedings of the 2nd Workshop on Trustworthy Natural Language Processing (TrustNLP 2022), Seattle, WA, USA, 14 July 2022; pp. 49–63. [Google Scholar] [CrossRef]
- Thomas, G.; Hartley, R.D.; Kincaid, J.P. Test-retest and inter-analyst reliability of the automated readability index, Flesch reading ease score, and the fog count. J. Read. Behav. 1975, 7, 149–154. [Google Scholar] [CrossRef]
- Gunning, R. The Technique of Clear Writing; McGraw-Hill: New York, NY, USA, 1952; Available online: https://books.google.de/books?id=ofI0AAAAMAAJ (accessed on 31 July 2023).
- DiMascio, C. py-readability-metrics. 2019. Available online: https://github.com/cdimascio/py-readability-metrics (accessed on 31 July 2023).
- Mosca, E.; Agarwal, S.; Rando Ramírez, J.; Groh, G. “That Is a Suspicious Reaction!”: Interpreting Logits Variation to Detect NLP Adversarial Attacks. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022; pp. 7806–7816. [Google Scholar] [CrossRef]
- Huber, L.; Kühn, M.A.; Mosca, E.; Groh, G. Detecting Word-Level Adversarial Text Attacks via SHapley Additive exPlanations. In Proceedings of the 7th Workshop on Representation Learning for NLP, Dublin, Ireland, 26 May 2022; pp. 156–166. [Google Scholar] [CrossRef]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C. Hugging Face’s Transformers: State-of-the-Art Natural Language Processing. 2019. Available online: https://github.com/huggingface/transformers (accessed on 31 July 2023).
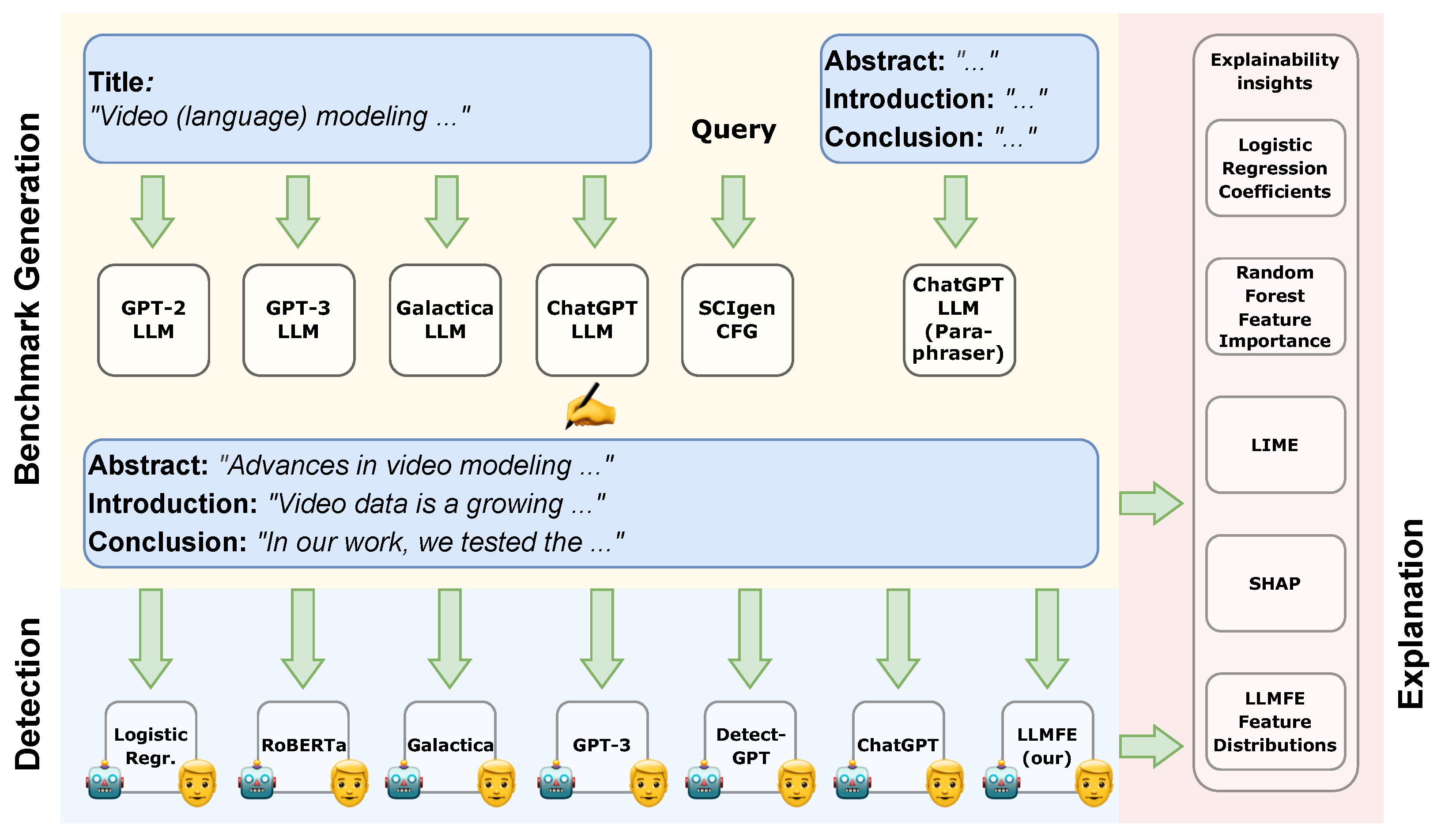
Figure 1.
This work’s overview. Six methods are used to machine-generate papers, which are then mixed with human-written ones to create our benchmark dataset. Seven models are then tested as baselines to identify the authorship of a given output.
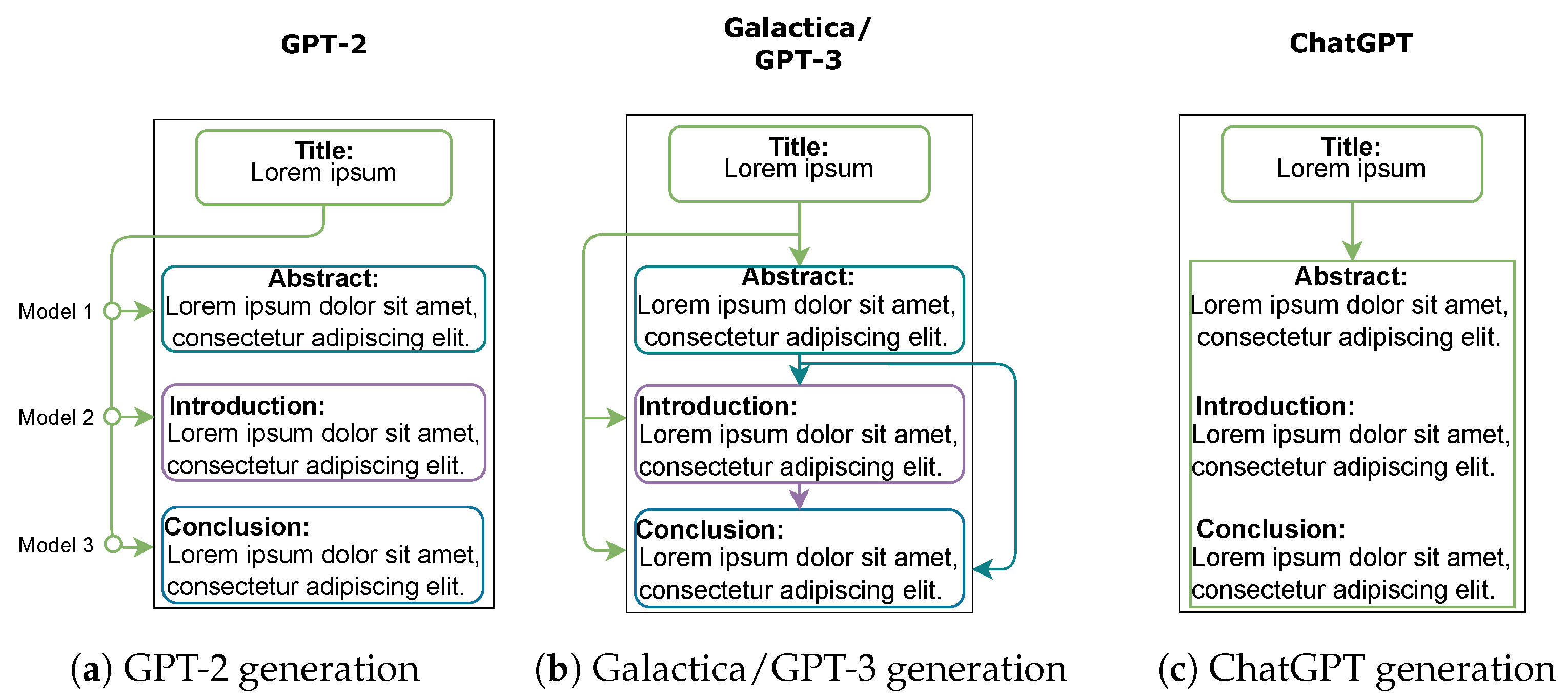
Figure 2.
Generation pipeline used for each model. For GPT-2 (a), the abstract, introduction, and conclusion sections are generated by three separately fine-tuned model instances, each based solely on the paper title. In the case of Galactica and GPT-3 (b), each section is generated conditioning on the previous sections. Finally, ChatGPT’s generation sequence (c) requires only the title to generate all the necessary sections at once.
Figure 3.
Our co-created test dataset TEST-CC contains 4000 papers with varying shares of real and ChatGPT-paraphrased sections.
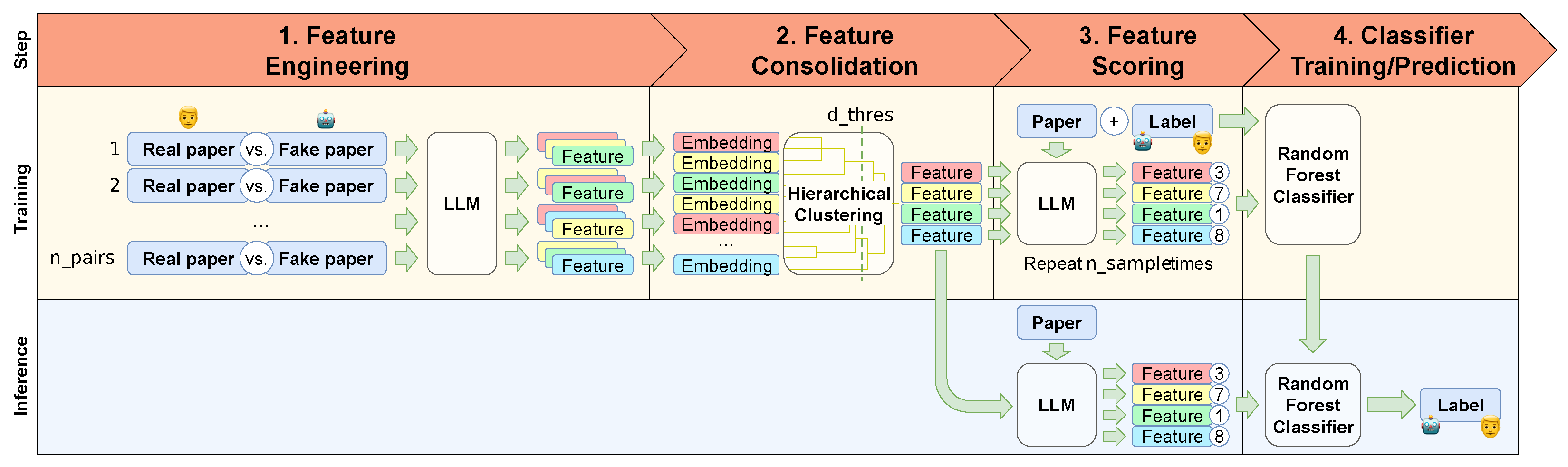
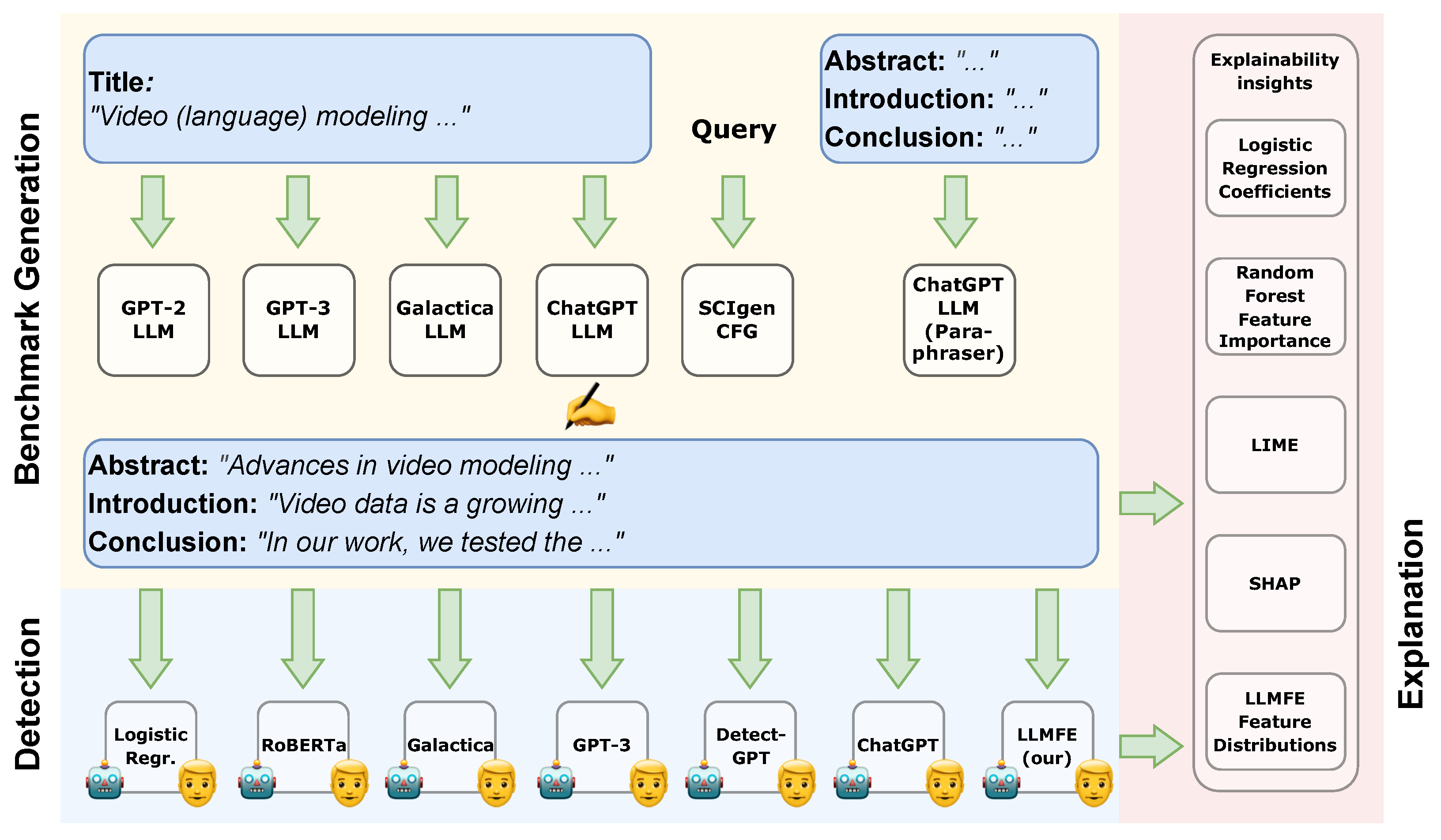
Figure 4.
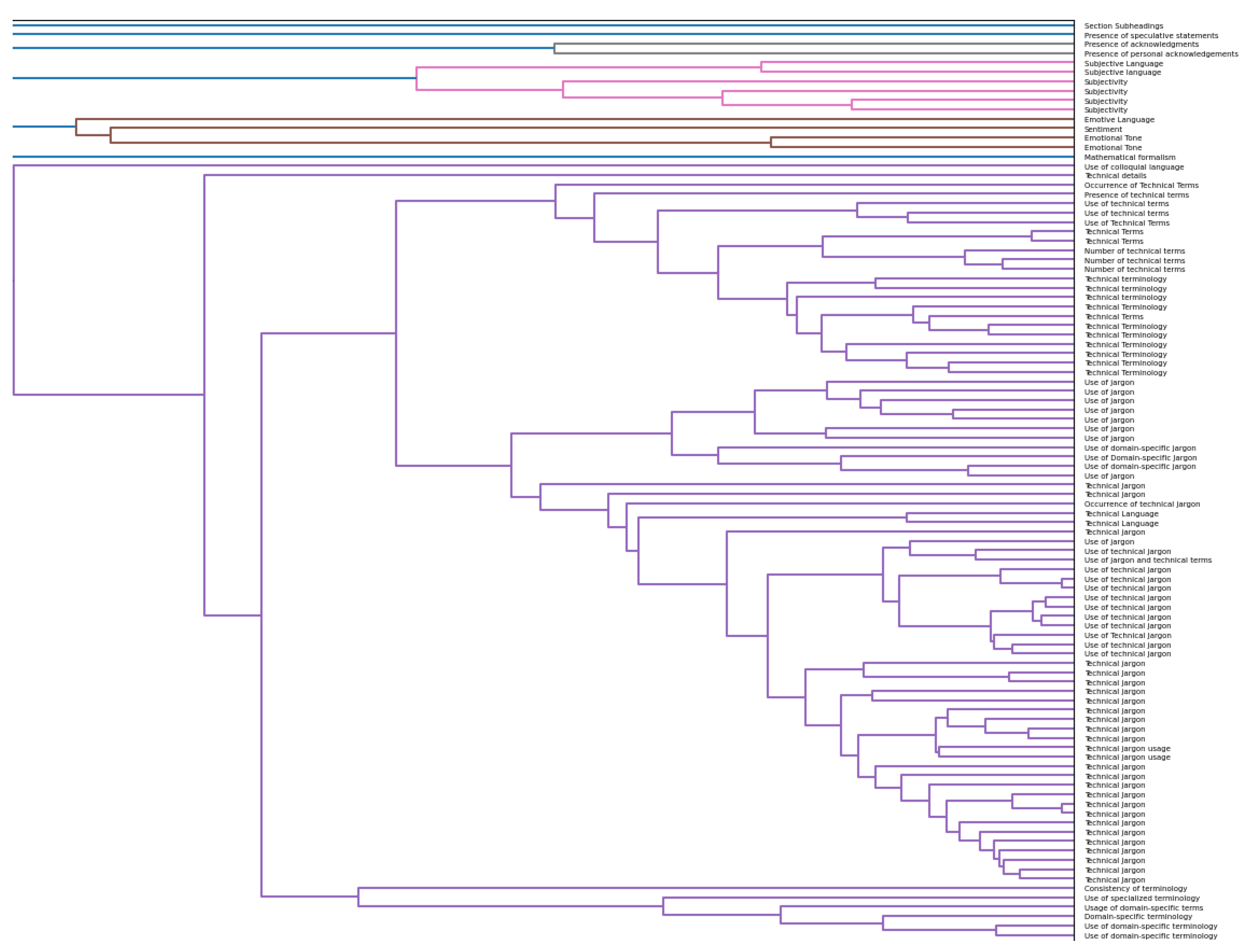
LLMFE follows a four-step process: (1) Generate features suitable for distinguishing real and fake papers using the LLM based on multiple pairs of one real and one fake paper each. (2) Remove duplicate features through hierarchical clustering on embeddings of the feature descriptions. (3) Score scientific papers along the remaining features using the LLM. (4) Finally, train a Random Forest Classifier to predict the real or fake label based on the feature scores.
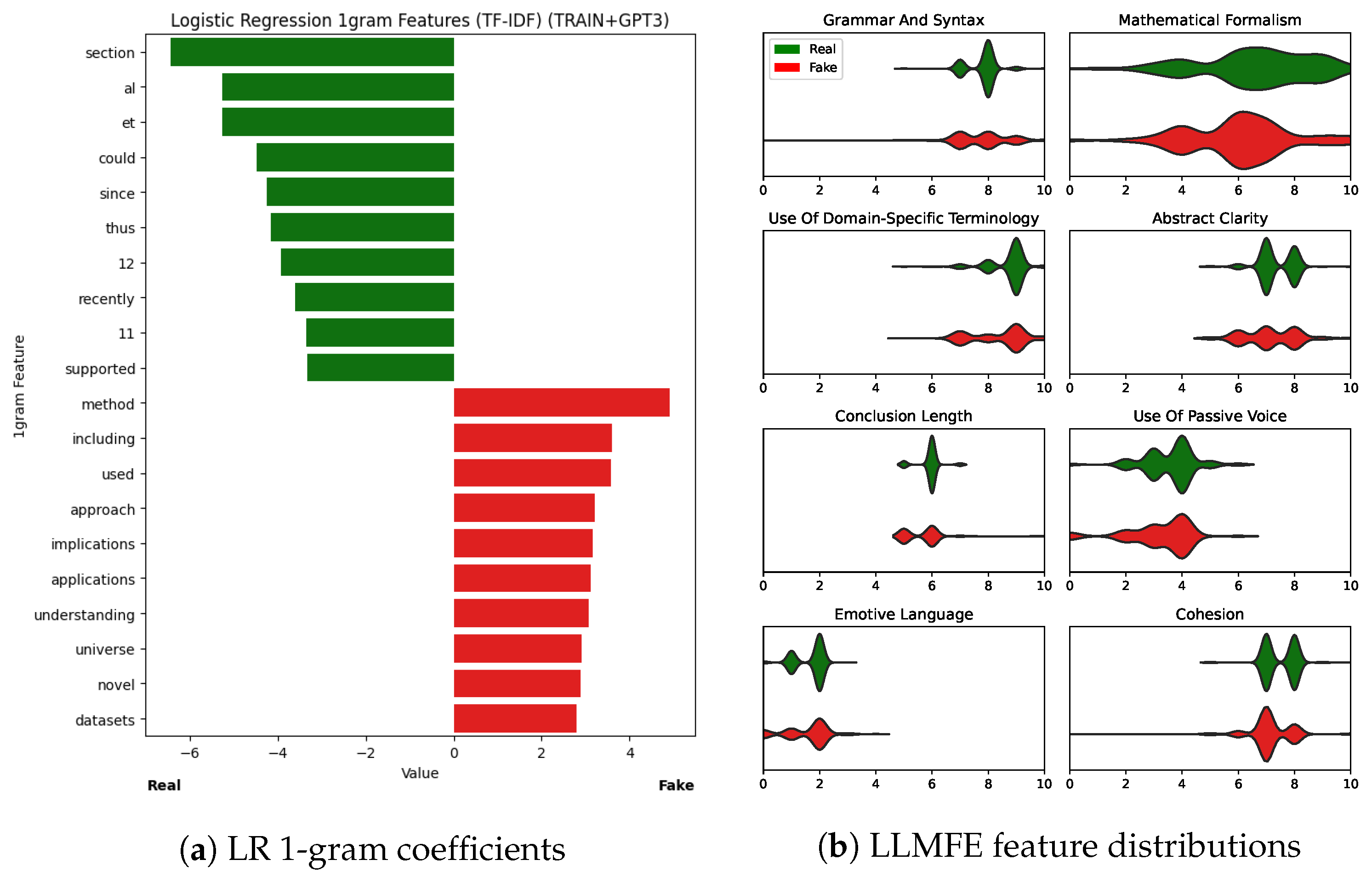
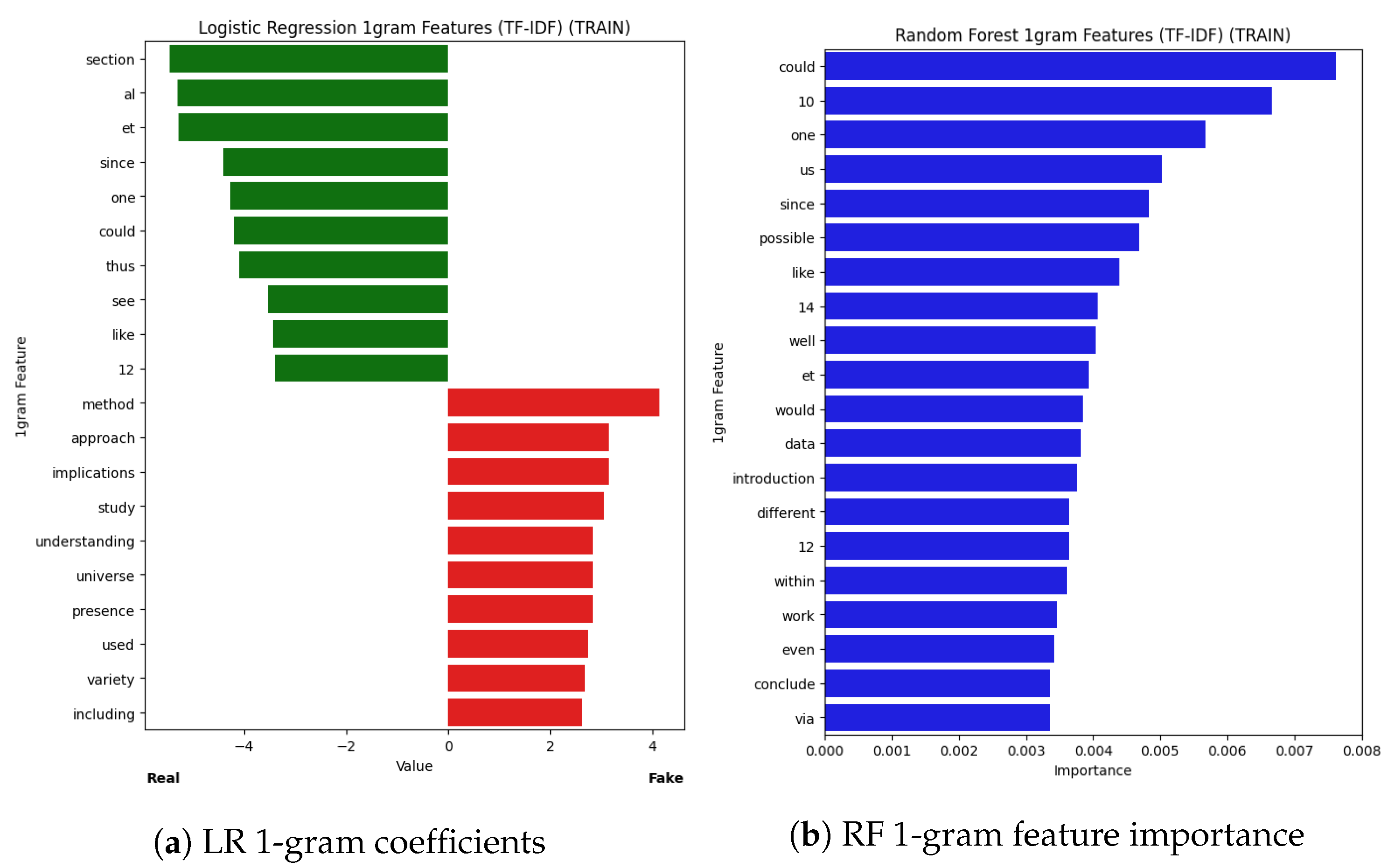
Figure 5.
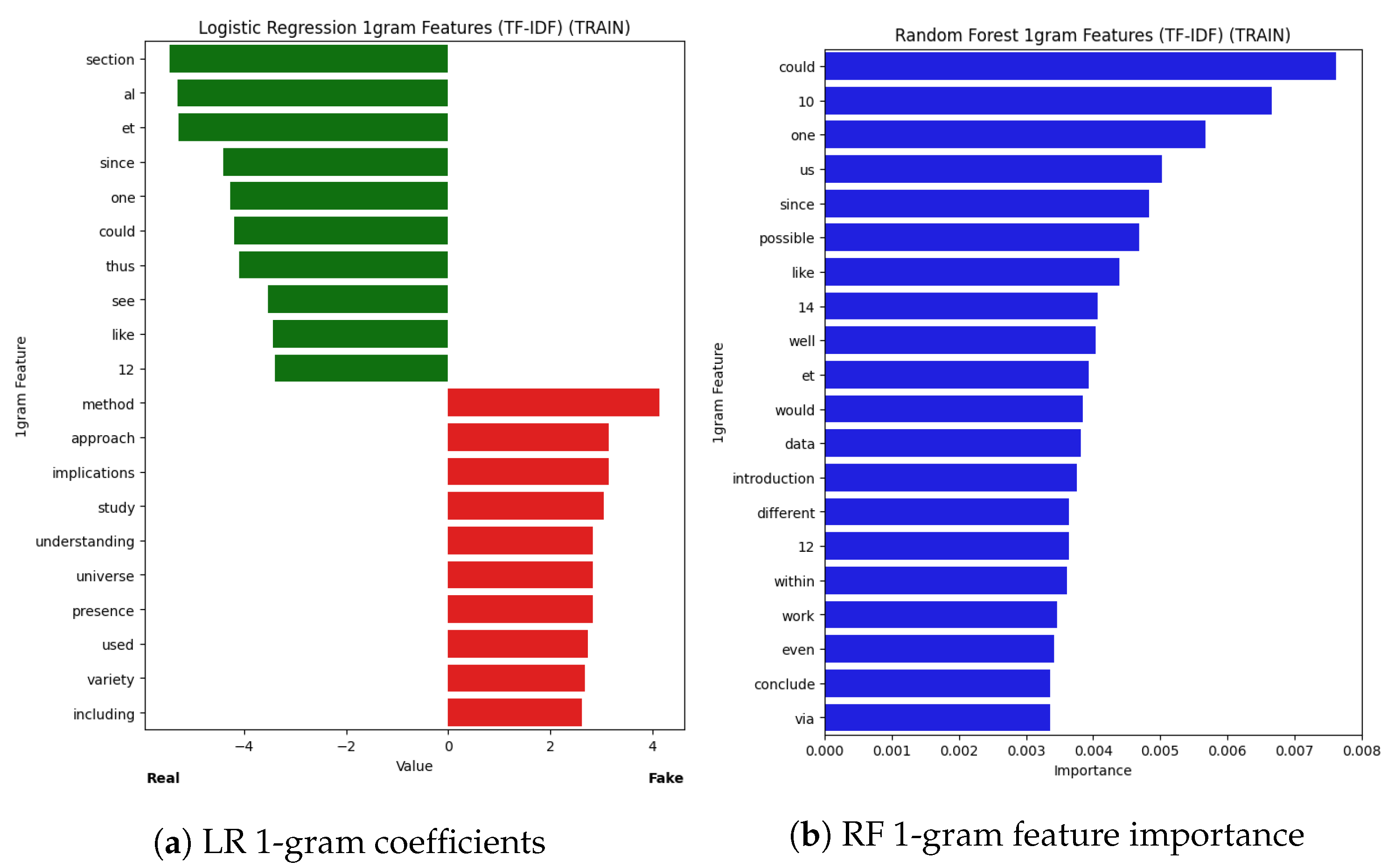
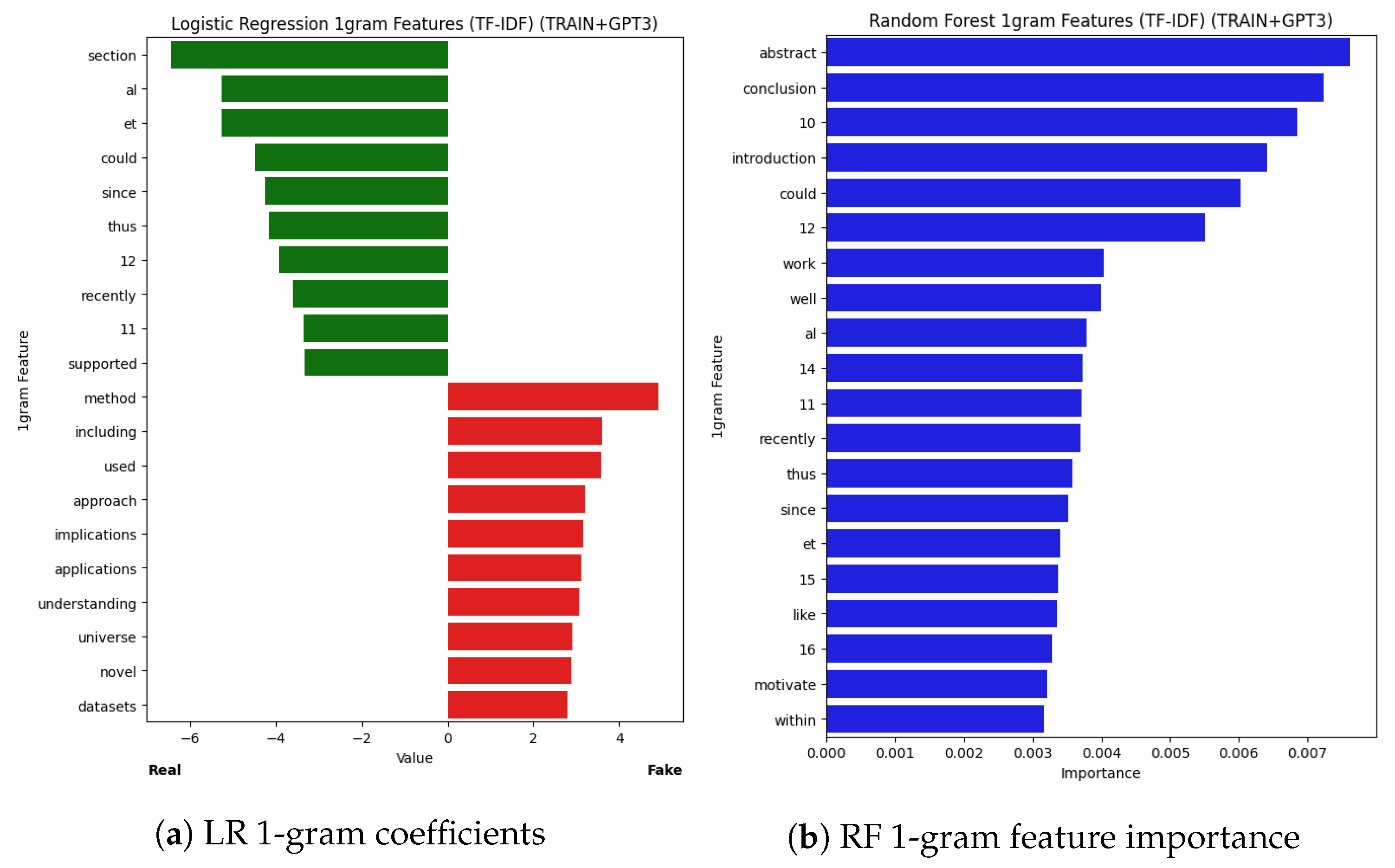
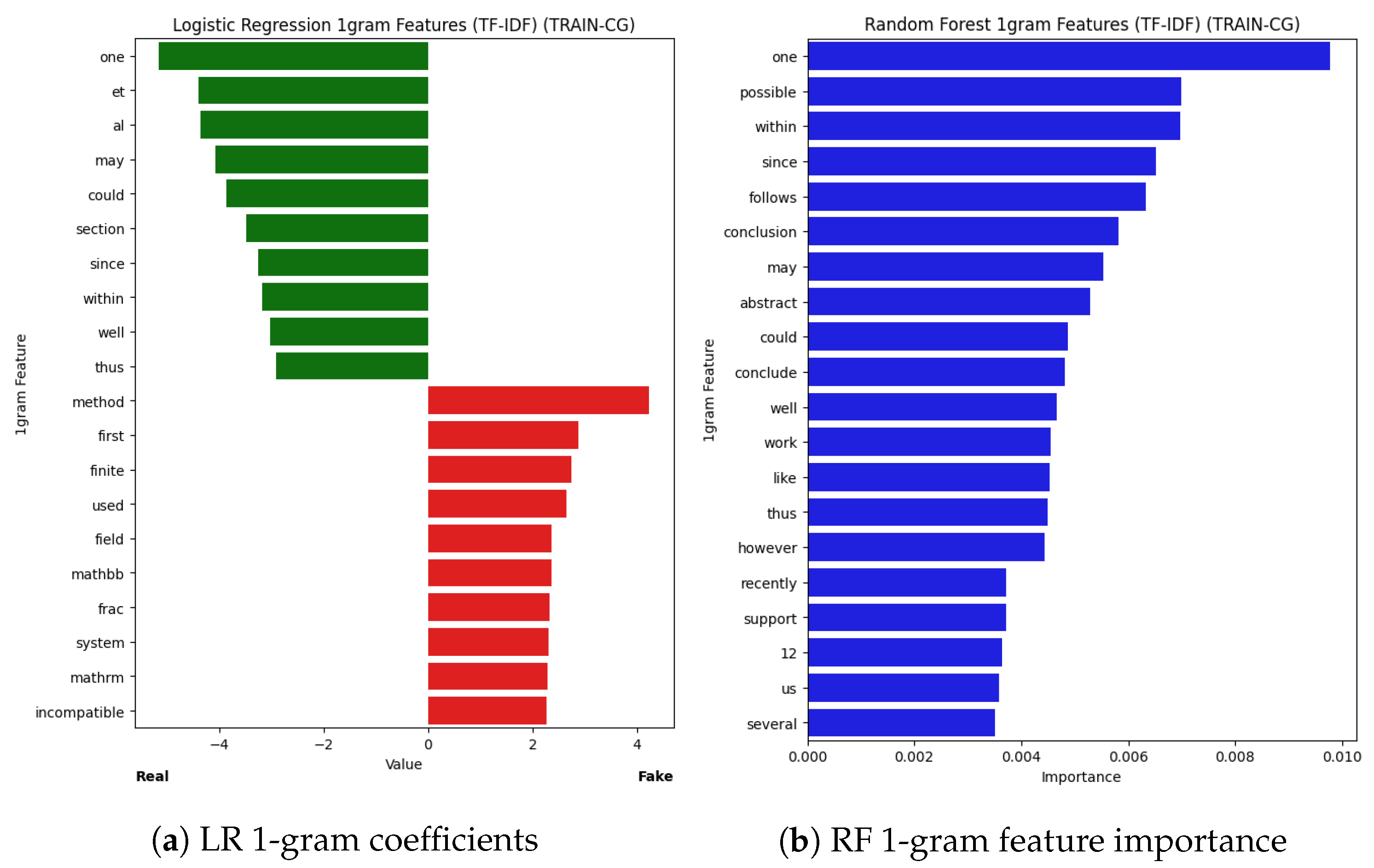
Explainability insights from our Logistic Regression (LR) and Large Language Model Feature Extractor (LLMFE) classifiers. (a) shows the 1-grams with the 10 lowest (indicating real) and highest (indicating fake) coefficients learned by LR. (b) shows the distributions of scores for the eight most important features (according to Random Forest feature importance) learned by LLMFE.
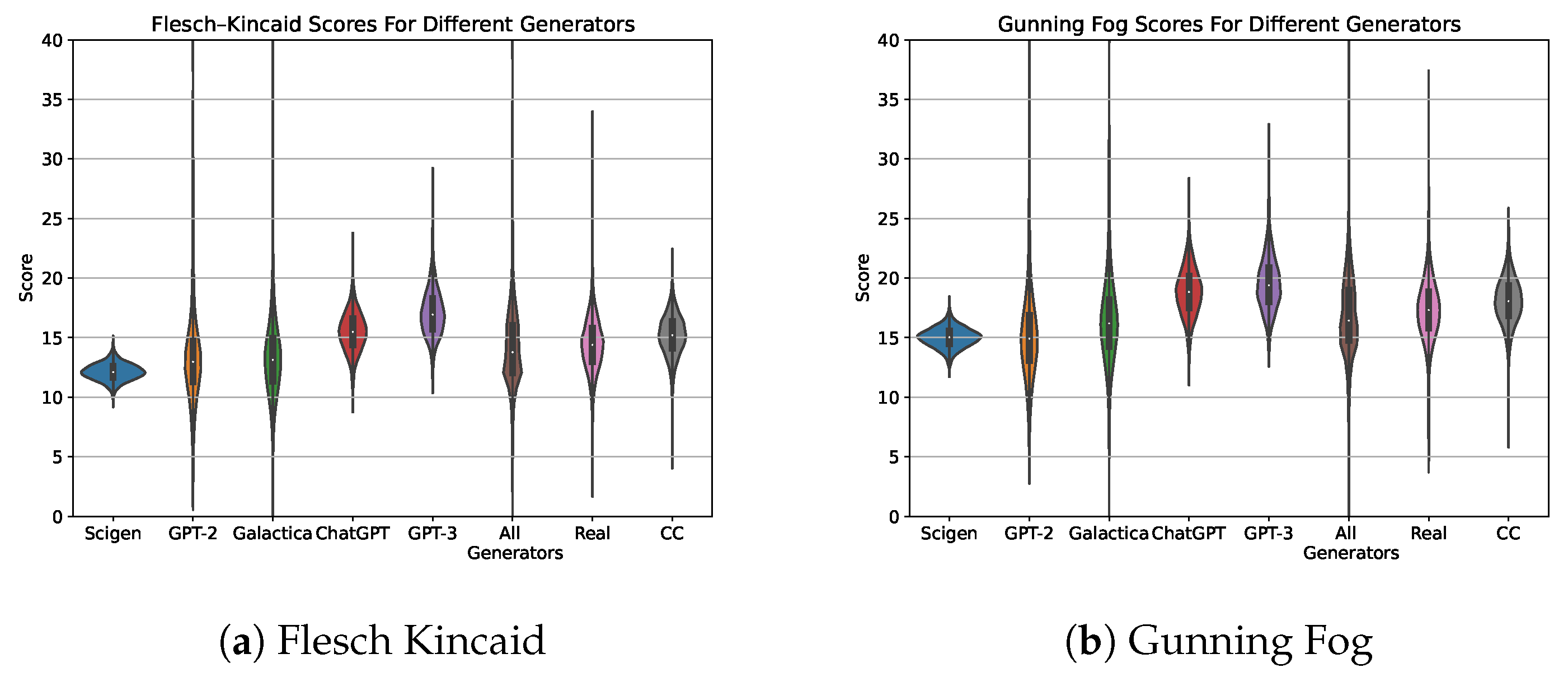
Figure 6.
Distribution of readability metrics for papers from the different generators. (a) shows Flesch–Kincaid scores while (b) shows Gunning Fog scores for all generators.
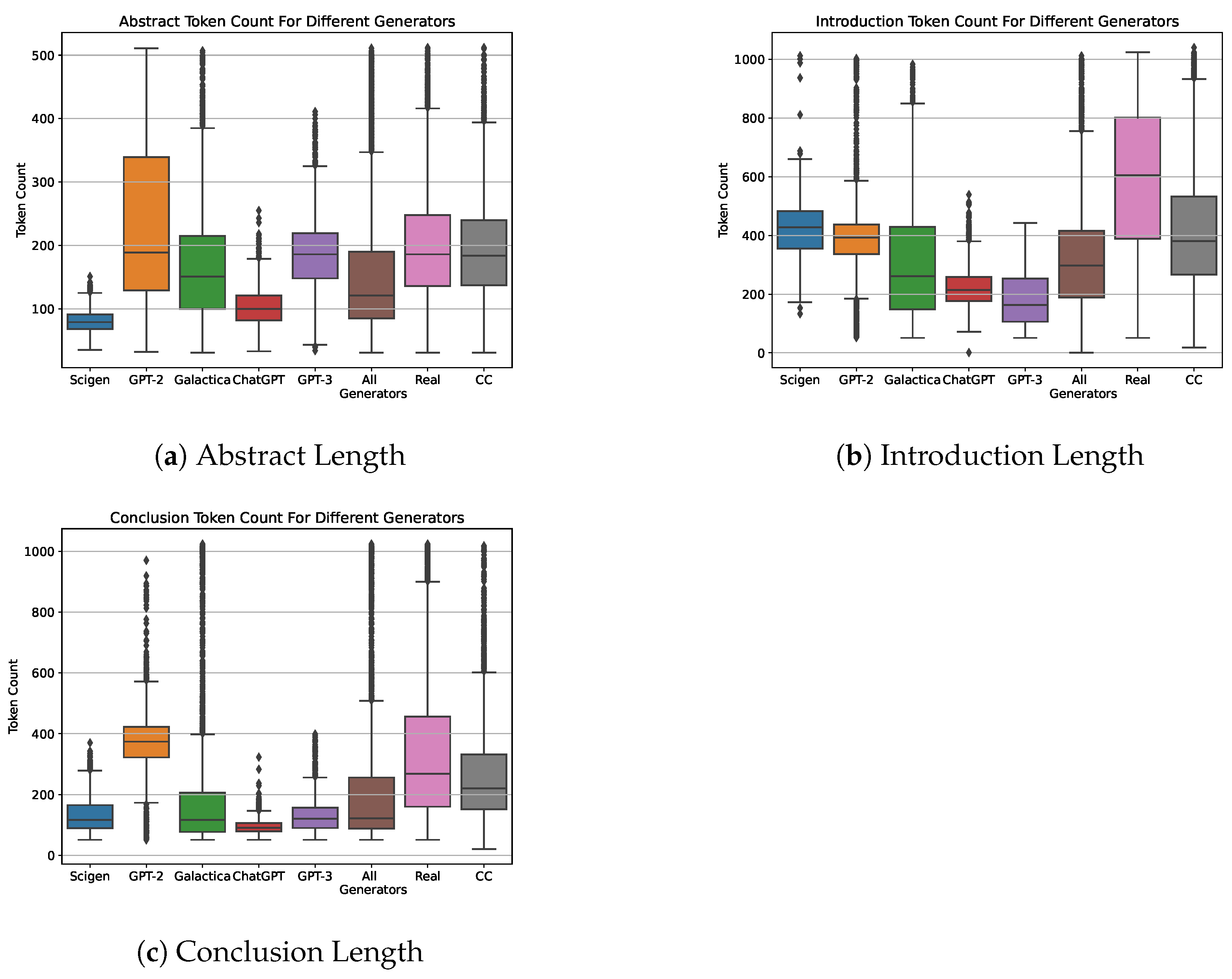
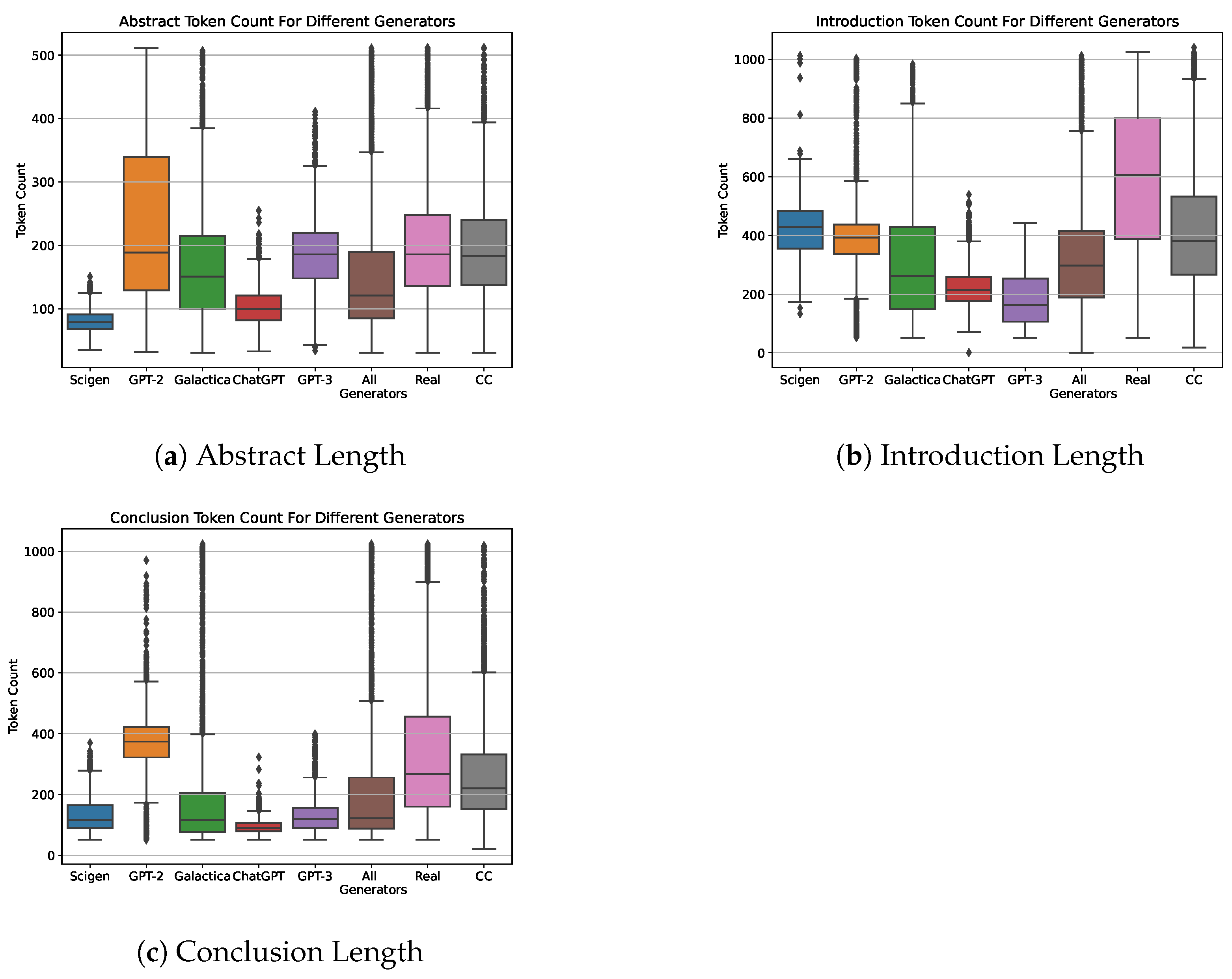
Figure 7.
The generators exhibit different tendencies for the length of the generated fake scientific papers. (a) shows the length distribution of generated abstracts, (b) shows the same for introductions, and (c) shows conclusion lengths.
Figure 8.
Paraphrasing sections with ChatGPT has a tendency to result in sections shorter than the original. The reduction in section length is most visible for the longer introduction and conclusion sections. For an analysis of lengths of generated
fake scientific papers, see
Figure 7 in the appendix.
Table 1.
Data sources included in our dataset and their respective sizes.
| Source | Quantity | Tokens |
|---|
| arXiv parsing 1 (real) | 12 k | 13.4 M |
| arXiv parsing 2 (real) | 4 k | 3.2 M |
| SCIgen (fake) | 3 k | 1.8 M |
| GPT-2 (fake) | 3 k | 2.9 M |
| Galactica (fake) | 3 k | 2.0 M |
| ChatGPT (fake) | 3 k | 1.2 M |
| GPT-3 (fake) | 1 k | 0.5 M |
| ChatGPT (paraphrased real) | 4 k | 3.5 M |
| Total real (extraction) | 16 k | 16.6 M |
| Total fake (generators) | 13 k | 8.4 M |
| Total co-created (paraphrased) | 4 k | 3.5 M |
| Total | 33 k | 28.5 M |
Table 2.
Overview of the datasets used to train and evaluate the classifiers. Each column represents the number of papers used per source. Concerning
real papers, unless indicated, we use samples extracted with parsing 1 (see
Section 3.1).
| | arXiv | ChatGPT | GPT-2 | SCIgen | Galactica | GPT-3 | ChatGPT |
|---|
| Dataset | (Real) | (Fake) | (Fake) | (Fake) | (Fake) | (Fake) | (Co-Created) |
|---|
| Standard train (TRAIN) | 8 k | 2 k | 2 k | 2 k | 2 k | - | - |
| Standard train subset (TRAIN-SUB) | 4 k | 1 k | 1 k | 1 k | 1 k | - | - |
| TRAIN without ChatGPT (TRAIN-CG) | 8 k | - | 2 k | 2 k | 2 k | - | - |
| TRAIN plus GPT-3 (TRAIN + GPT3) | 8 k | 2 k | 2 k | 2 k | 2 k | 1.2 k | - |
| Standard test (TEST) | 4 k | 1 k | 1 k | 1 k | 1 k | - | - |
| Out-of-domain GPT-3 only (OOD-GPT3) | - | - | - | - | - | 1 k | - |
| Out-of-domain real (OOD-REAL) | 4 k (parsing 2) | - | - | - | - | - | - |
| ChatGPT only (TECG) | - | 1 k | - | - | - | - | - |
| Co-created test (TEST-CC) | - | - | - | - | - | - | 4 k |
Table 3.
Experiment results reported with accuracy metric. Out-of-domain experiments, i.e., evaluation on unseen generators, are highlighted in blue. Highest values per test set are highlighted in bold. (*) ChatGPT-IO and LLMFE accuracies have been evaluated on randomly sampled subsets of 100 scientific papers per test set due to API limits.
| Model | Train Dataset | TEST | OOD-GPT3 | OOD-REAL | TECG | TEST-CC |
|---|
| LR-1gram (tf-idf) (our) | TRAIN | 95.3% | 4.0% | 94.6% | 96.1% | 7.8% |
| LR-1gram (tf-idf) (our) | TRAIN + GPT3 | 94.6% | 86.5% | 86.2% | 97.8% | 13.7% |
| LR-1gram (tf-idf) (our) | TRAIN-CG | 86.6% | 0.8% | 97.8% | 32.6% | 1.2% |
| RF-1gram (tf-idf) (our) | TRAIN | 94.8% | 24.7% | 87.3% | 100.0% | 8.1% |
| RF-1gram (tf-idf) (our) | TRAIN + GPT3 | 91.7% | 95.0% | 69.3% | 100.0% | 15.1% |
| RF-1gram (tf-idf) (our) | TRAIN-CG | 97.6% | 7.0% | 95.0% | 57.0% | 1.7% |
| Galactica (our) | TRAIN | 98.4% | 25.9% | 95.5% | 84.0% | 6.8% |
| Galactica (our) | TRAIN + GPT3 | 98.5% | 71.2% | 95.1% | 84.0% | 12.0% |
| Galactica (our) | TRAIN-CG | 96.4% | 12.4% | 97.6% | 61.3% | 2.4% |
| RoBERTa (our) | TRAIN | 72.3% | 55.5% | 50.0% | 100.0% | 63.5% |
| RoBERTa (our) | TRAIN + GPT3 | 65.7% | 100.0% | 29.1% | 100.0% | 75.0% |
| RoBERTa (our) | TRAIN-CG | 86.0% | 2.0% | 92.5% | 76.5% | 9.2% |
| GPT-3 (our) | TRAIN-SUB | 100.0% | 25.9% | 99.0% | 100.0% | N/A |
| DetectGPT | - | 61.5% | 0.0% | 99.9% | 68.7% | N/A |
| ChatGPT-IO (our) (*) | - | 69.0% | 49.0% | 89.0% | 0.0% | 3.0% |
| LLMFE (our) (*) | TRAIN + GPT3 | 80.0% | 62.0% | 70.0% | 90.0% | 33.0% |
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}