Abstract
The problems of machine translation are constantly arising. While the most advanced translation platforms, such as Google and Yandex, allow for high-quality translations of languages with simple grammatical structures, more morphologically rich languages still suffer from the translation of complex sentences, and translation services leave many structural errors. This study focused on designing the rules for the grammatical structures of complex sentences in the Kazakh language, which has a difficult grammar with many rules. First, the types of complex sentences in the Kazakh language were thoroughly observed with the use of templates from the FuzzyWuzzy library. Then, the correction of complex sentences was completed with parallel corpora. The sentences were translated into English and Russian by existing machine translation systems. Therefore, the grammar of both Kazakh–English and Kazakh–Russian language pairs was considered. They both used the rules specifically designed for the post-editing steps. Finally, the performance of the developed algorithm was evaluated for an accuracy score for each pair of languages. This approach was then proposed for use in other corpora generation, post-editing, and analysis systems in future works.
1. Introduction
The Kazakh language is agglutinative with rich morphology and related to the Turkic language group. This study explored the grammatical constructions of the Kazakh language, specifically complex sentences. The relevance of the study was determined by the need to examine the structural and semantic properties of complex sentences. There are three types of complex sentences in the Kazakh language: compound sentences (salalas qurmalas), complex sentences (sabaqtas qurmalas), and compound-complex sentences (aralas qurmalas).
In the Kazakh language, as well as in the English language, a compound sentence (salalas qurmalas) consists of two or more simple sentences independent of each other. The ways of forming compound sentences in Kazakh are like those in English. Simple sentences can be combined into a compound sentence: with a coordinating conjunction (for, and, nor, but, or, yet, so); with a conjunctive adverb (e.g., however, therefore); with a semicolon, colon, or dash.
There are six types of compound sentences in the Kazakh language (in English, a compound sentence does not have such a division): Ynggailas salalas, Sebep-saldar salalas, Qarsylyqty salalas, Tusindirmeli salalas, Talgauly salalas, Kezektes salalas.
Ynggailas salalas [difficult to convey the meaning in one word]—In this kind of sentence, the thought expressed in the first simple sentence and the thought in the second are expressed at the same time, direction, and convenient sense.
Sebep-saldar salalas [causal compound sentence]—In these kinds of sentences, the first sentence expresses the reason for the second sentence, and the second expresses the reason for the first sentence.
Qarsylyqty salalas [opposite compound sentence]—In these kinds of sentences, the event in one of the simple sentences is the opposite of the event in the other.
Tusindirmeli salalas [explanatory compound sentence]—In these kinds of sentences, the first simple sentence points to the second, and the second reveals and explains the meaning of the first sentence.
Talgauly salalas [selective compound sentence]—A sentence type that indicates that only one of the actions mentioned in the simple sentences is performed.
Kezektes salalas [sequential compound sentence]—Simple sentences of this type show that the indicated action sequentially occurs.
A complex sentence (sabaqtas qurmalas) consists of an independent and dependent sentence. Here the second sentence complements the thought of the first. In the Kazakh language, the dependent sentence has an unfinished form of the verb, which is why the thought remains unfinished. In the Kazakh language, the dependent clause always comes first, before the independent clause. Complex sentences are divided into six types: Shartty bagynyngqy-sabaqtas, Qarsylyqty bagynyngqy-sabaqtas, Mezgil bagynyngqy-sabaqtas, Sebep bagynyngqy-sabaqtas, Qimyl-syn bagynyngqy-sabaqtas, Masqat bagynyngqy-sabaqtas.
Shartty bagynyngqy-sabaqtas [type of complex sentence with a conditional expression]—The first simple sentence expresses a condition for the performance or non-performance of an action in the second.
Qarsylyqty bagynyngqy-sabaqtas [type with an adversative expression]—The dependent and independent clauses are used in opposite senses.
Mezgil bagynyngqy-sabaqtas [type with time expression]—The action mentioned in the first simple sentence expresses the time of the action mentioned in the second.
Sebep bagynyngqy-sabaqtas [type with reason expression]—The dependent clause means the reason for the thought expressed in the independent clause.
Qimyl-syn bagynyngqy-sabaqtas [type with expression behavior of action]—The dependent clause names how an action is performed in the independent clause.
Maqsat bagynyngqy-sabaqtas [type with purpose expression]—The dependent clause expresses the purpose of the action in the independent clause.
A mixed complex sentence or compound-complex sentence (aralas qurmalas) consists of at least three simple sentences. If there are three sentences, then one of them is dependent. Each of these types of sentences has its own type of connection to a compound or complex sentence.
In this paper, we considered two language pairs: Kazakh-English and Kazakh-Russian. There are 12 types (forms) of a complex (compound) sentence in the Kazakh language. When translating from English into Kazakh or from Russian into Kazakh, complex (compound) sentences lose their meaning due to the following reasons:
- -
- In the Kazakh language, the dependent clause always comes before the independent clause since, in the dependent clause, the verb is in an incomplete form (that is, some completed event must follow this verb);
- -
- Each type of sentence in Kazakh does not have an exact match in form in English and Russian;
- -
- In Kazakh, the semicolon (;) is not used to connect simple sentences to a complex sentence;
- -
- A case when one simple sentence comes in the middle (inside) of another simple sentence.
For these reasons, the sentence structure may change during translation, and the context acquires a different meaning. And on grammar (mostly verbs), mistakes are often made when translating complex sentences.
For example, in the following complex sentence:
“The actor was happy he got a part in a movie even though the part was small.”
We translated this complex sentence into Kazakh through Google translator and received the following result:
“Актер фильмде рөлге ие болғанына қуанышты болды, бірақ рөл кішкентай болса да.”
Here “Актер фильмде рөлге ие болғанына қуанышты болды” is an independent clause and “бірақ рөл кішкентай болса да” is a dependent clause. The dependent clause is at the end, but in Kazakh, it should be at the beginning since the verb has an unfinished form (болса да). The sentence does not end with the incomplete form of the verb–this is a structural error. With such structural errors, the thought of the sentence will remain incomplete.
The correct version read as follows:
“Бірақ рөл кішкентай болса да, актер фильмде рөлге ие болғанына қуанышты болды.”
Errors in sentence structure make it difficult to understand the text. The sentence structure depends on grammar, style, and sequence. Large datasets for popular languages (in terms of research) allow you to correct grammatical and structural errors based on modern technologies (such as machine learning, hybrid approaches, etc.). However, in most cases, research for low-resource languages suffers from a lack of well-structured and well-formed large datasets. In this regard, problems such as automatic detection and correction of machine translation errors have not yet found an optimal solution. The translations provided by modern machine translation systems suffer from many types of errors, including verb form errors, incorrect lexical choices, word order, word insertion, word deletion, etc. Identifying these most common sentence structure errors is the first step to correcting them and preventing them from occurring. This study paid special attention to the Kazakh language, and it proposed to solve errors in machine translation for the English-Kazakh and Russian-Kazakh language pairs.
Like many other languages from the Turkic group, the Kazakh language has a complex agglutinative morphological form, which strongly affects a text’s structure and semantic meanings. The task becomes more complex when the structures for languages belonging to different language groups and languages from other family groups are analyzed and compared. For example, the Kazakh language belongs to the Turkic language family, and the English language belongs to the Indo-European family, with many differences and inconsistencies. Also, at the moment, the Kazakh language, unfortunately, is a low-resource language, which does not allow conducting experiments and applying modern approaches based on machine learning, which requires big data.
2. Related Work
Exploring the topic of semantic connection in complex sentences, we found that very few works were devoted to this problem. Moreover, even in these small numbers of works, this topic was not fully disclosed.
The structure of complex sentences for the English language was revealed in many works. Study [1] performed pattern matching, which takes an input sentence and returns the corresponding skeletal AMR (abstract value representation), using the extracted structure of complex sentences. In [2], the structuring of subordinating relations in complex sentences was considered. Study [3] discussed correctly using punctuation marks when translating from Russian into Kazakh. Incorrect use of punctuation marks can lead to many problems when translating Russian texts into Kazakh ones, which do not consider the peculiarities of the sentence structure and the rules of word order in the Kazakh language.
The formation of complex sentences was analyzed in [4,5]. Study [5] considered simple and complex sentences with conditional expressions for Kazakh and English languages. Complex sentences were formed by combining simple sentences with a list of verb endings. Study [4] conducted a comparative study and analyzed the relationship, similarities, and differences in forming complex sentences in Uzbek and Kazakh languages. In the Uzbek language, complex sentences are considered in two forms: complex sentences formed with the help of conjunctions and complex sentences without allied ones. In the Kazakh language, three types of complex sentences: compound (salalas), complex (sabaqtas), and compound-complex (aralas) were highlighted. Then the connections between simple sentences to complex ones were formed. According to the work of S. Amanzholov, you can delve into the grammar of the Kazakh language. S. Amanzholov defined complex sentences and revealed special points related to their structure, which was very useful for determining the intricacies of semantic connections in complex sentences [6].
Studies [7,8] considered the group of Turkic languages in the examples of the Tatar, Kyrgyz, and Turkish languages. Turkic languages belong to the agglutinative group of languages. These works were studied to analyze and identify approaches to solving the problems associated with the translation and post-editing of complex sentences. In many works, complex sentences were considered at the level of simple sentences. Complex sentences were divided into simple sentences or segments of phrases. From this point of view, there are three main grammar-checking and post-editing approaches: a rule-based approach, a machine learning-based approach, and a hybrid approach. In the study [8], part-of-speech (POS) marked English texts were checked against a specific set of rules, and a matching rule was applied to correct any errors.
Machine learning is currently the most popular grammar-checking method. They were explored in works [9,10,11]. These methods use an annotated corpus, which is used for statistical analysis of the text to automatically detect and correct grammatical errors. Machine learning-based systems do not require extensive knowledge of grammar, as they are completely dependent on the main corpus. The lack of a large, annotated corpus hinders the use of such methods for grammar checking. In addition, the results largely depend on how clean and well-structured the corpus is. A combination of machine learning and rule-based methods can be used to improve system performance because some bugs are better solved with rule-based techniques, and some are better solved with machine learning. The study [10] showed that a text corpus could be used to train a system to determine the correct sentence pattern, and the results could be filtered by applying manually created rules. The hybrid method helped eliminate a wide range of complex errors. In addition, the tedious work of writing so many rules could be greatly reduced.
Machine learning technology based on neural networks has recently been actively used to solve many problems. The studies [12,13] used statistical machine translation and neural machine translation approaches for low-resource pairs of languages, such as Spanish–Farsi (Persian). The training models, processed on open-source parallel corpora from Tanzil, KDE, OpenSubtitles2018, etc., allowed the achievement of BLEU scores from 31.02 to 38.78.
At the moment, the Kazakh language is a low-resource language, but many scientists and scientific groups have conducted research on various information systems to solve this problem. On the topic of our study, the following works [14,15,16] could be noted, in which different mark-ups were conducted for the Kazakh language and the application of various methods in the tasks of developing machine translation and speech synthesis, taking into account the linguistic properties of the Kazakh language and its inaccessibility.
The volume of training data in the Kazakh language was not sufficient to apply the hybrid approach, but it was supplemented with new data. When the required amount of data is reached, it is planned to connect it to the approach based on machine learning. This paper proposed the rule-based approach to the Kazakh language.
3. Rules and Algorithms for Determining and Editing Complex Sentences for the English-Kazakh and Russian-Kazakh Pairs of Languages
The function of the implemented algorithm was editing the received translation (text in Kazakh, especially compound or complex sentences) through machine translation systems (translation from English or from Russian into Kazakh).
In our programming implementation, post-editing was done at the level of a simple sentence. Therefore, it was necessary to determine the type of given sentence, whether it was simple or complex. If the sentence was complex, then we broke it into simple sentences. After post-editing, the separated simple sentences were put back together into a complex one. When dividing a complex sentence into simple ones and when recombining simple sentences into a complex one, it was necessary to consider the features (determining the boundaries of simple sentences and determining the type of connection) of a complex sentence in the Kazakh language. At this stage, the algorithm for determining the type of offer was triggered.
A step-by-step definition of a type of the complex sentence is shown below in Algorithm 1:
| Algorithm 1: The algorithm for determining a type of the complex sentence |
| 1. Obtaining a text. 2. Breaking a text into sentences. 3. Sentences were checked for a match according to the rule template using the FuzzyWuzzy library for fuzzy comparison. If there were several matches, proceed to step 4. If it matches, then this was a complex sentence of type X (the type of a complex sentence that matched); proceed to step 5. If it did not match, this was a simple sentence; proceed to step 5. 4. When there were multiple matches, the type with the highest match value was selected. 5. End |
Rule templates were composed using regular expressions that considered the syntactic structure of a complex sentence. To develop templates and for further experiments, a parallel corpus of complex sentences was collected in three languages (Kazakh, Russian, and English) (see Table 1). Members of our scientific team manually collected this corpus from various sources (news portals, books, publications, etc.).

Table 1.
Quantitative data of the corpus of complex sentences.
The Kazakh, Russian and English languages have their own syntactic rules for compiling complex sentences. Knowing these rules (formulae), you can determine the types of complex sentences. You can also improve the quality of the translation of complex sentences by knowing the syntactic rules for compiling complex sentences for each language. Table 2 considers the formation of compound sentences in English, Russian, and Kazakh. For each type of complex sentence, rules were developed using regular expressions based on the sentence’s syntactic structure and based on the analysis of examples of complex sentences (see Table 2).
Table 2.
Rules for complex sentences.
In the post-editing of a text, you first need to determine the type of sentence: simple or complex. Then for the post-editing of complex sentences, the task of determining the type of a complex sentence arose. Text editing was performed at the level of sentences, and therefore, it was essential to determine the type of complex sentence for the correct reverse connection of sentences. Rule templates written through regular expressions were used to determine the type of complex sentences (shown in Table 2).
In the second stage, grammatical errors were edited at the level of morphology (nominal and verb endings). To perform this check, we compared two sentences (a complex sentence with a morphological characteristic in Kazakh and a complex sentence with a morphological characteristic in English or Russian) to identify inconsistencies. Morphological characteristics of sentences were taken through the morphological analyzer of the Apertium platform [17,18,19]. If there was a discrepancy, then this meant that you needed to edit according to the algorithm below. If there were no discrepancies, then we left the proposals unchanged.
Designations:
sl_text—text in the source language (Russian or English);
tl_mtext—text in the target language (Kazakh) obtained through machine translation;
sl_text_tag, tl_mtext_tag—marked up view of the above texts.
A step-by-step process of editing the complex sentence is shown below in Algorithm 2:
| Algorithm 2: The algorithm for editing a complex sentence |
|
For the Russian-Kazakh pair, it was possible to apply the model of the order of internal sentences of a complex sentence during editing. In this case, the internal proposal’s place changed according to the scheme shown in Table 3 below during the proposal’s editing.
Table 3.
Model of the order of internal sentences of a complex sentence.
For the English-Kazakh pair, the internal clause order model of the compound sentence was not applied during editing. While editing a sentence, the place of the inner sentence was preserved.
4. Experiments and Results
To conduct the experiments described in this section, we used corpora manually collected by us (members of our scientific team). The parallel corpus of complex sentences was collected in three languages (Kazakh, Russian, and English) (see Table 1). This corpus was collected from various sources (news portals, books, publications, etc.). It is an open-source resource available on the GitHub repository [20]. The corpus volume is shown in Table 1.
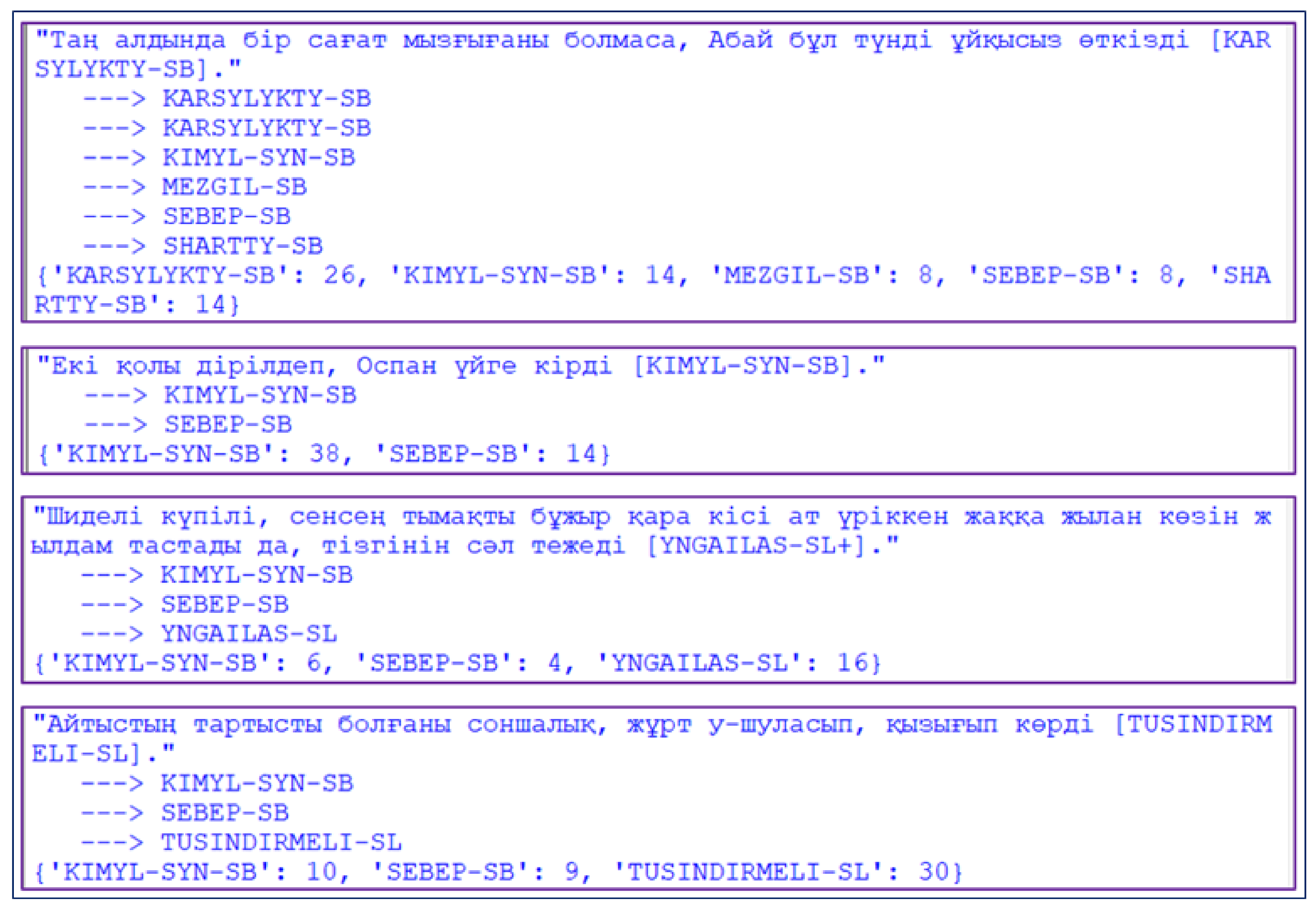
The algorithm for determining the type of complex sentences was implemented in Python 3. The program worked based on regular expressions and with the FuzzyWuzzy package for fuzzy comparison and weight determination. The program was tested on a corpus of complex sentences assembled by the research group, supplemented by simple sentences. As you can see in Figure 1, when several templates matched a sentence, the option with the highest weight was selected from them.

Figure 1.
Calculating the similarity weight of a sentence to a pattern of complex sentence types using the FuzzyWuzzy package.
Next, the prepared corpus for the test was run through a program that determined the type of a complex sentence. An incorrect definition of the type of a complex sentence (shown in Figure 2) occurred when the sentence had no conjunctions and when the sentence had long (meaning the number of words) homogeneous sentence members.

Figure 2.
(a,b) Results of the program for determining the type of a complex sentence.
After determining the type of complex sentence, the text was checked for correctness in terms of grammar. The algorithm for editing complex sentences was also implemented with the Python 3 programming language. The program worked based on the rules that work on POS-tagging.
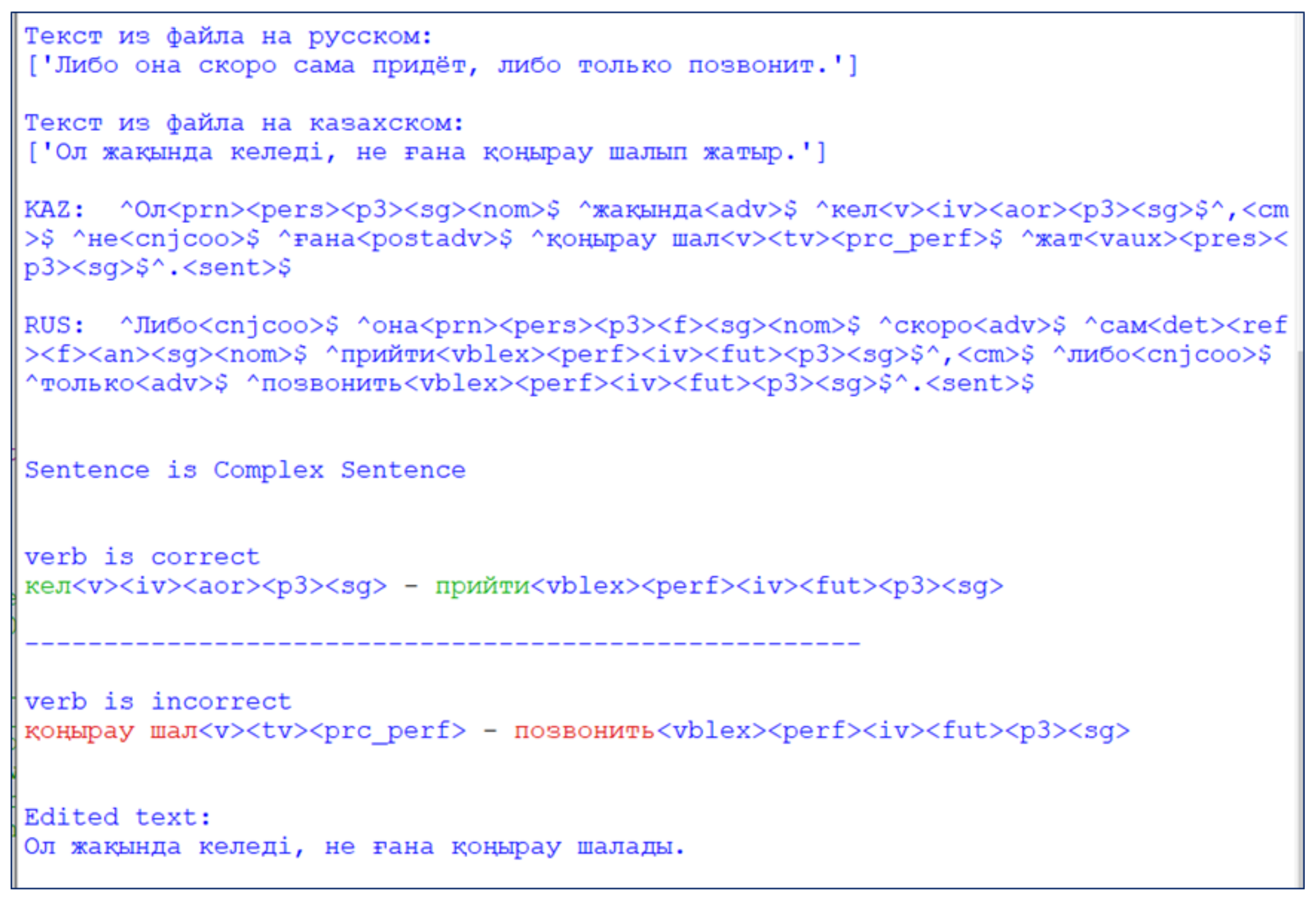
The program was tested on a corpus of complex sentences assembled by the research group. The original texts were translated through the less popular Kazakh-Russian MT to analyze and edit missed errors (see Figure 3).

Figure 3.
Fragment of the result of the text editing program.
At this stage, editing was performed at the level of language morphology and sentence structure. The following indicators were used to assess the quality of post-editing of Kazakh language translation: BLEU, WER, and TER. They are some of the well-known metrics for evaluating machine translation quality. BLEU was one of the first metrics to show a high correlation with human quality ratings. This metric was based on the idea that the closer machine translation is to professional human translation, the better it is [21]. This metric is still one of the most popular and widely used. WER (word error rate) is a general measure of the performance of a machine translation system [22]. TER (translation error rate) is a method used to predict the amount of post-editing of machine translation results [23]. The score (see Table 4) was calculated using BLEU, TER, and WER metrics.
Table 4.
Evaluations of post-editing of complex sentences in English-Kazakh and Russian-Kazakh translation.
In the BLEU metric, the higher the quality of a translation, the higher its score. For TER and WER metrics, it was considered that the lower the score, the better since fewer edits were required. A high score, in turn, meant that additional changes would be required during the post-editing of the translation. According to the evaluation results of the metrics for Russian-Kazakh, it was slightly better than for English-Kazakh. Since our approach is based on rules, it was impossible to cover all cases with rules and required careful analysis. At this stage of the work, the results were obtained with an improvement for Russian-Kazakh BLEU, which increased from 41 to 45, and for English-Kazakh BLEU, which increased from 43 to 46. Solving this problem is still underway. After each stage, we analyzed the obtained results. Based on this analysis, we concluded what improvements are still required.
5. Conclusions and Future Work
Semantic connection in complex sentences in the Kazakh language is provided through the correct use of punctuation marks, connecting words, and forms of verbs. To provide a semantic connection in a complex sentence, we first had to determine the type of complex sentence. Then we used a rule-based approach to edit the complex sentence at the level of simple sentences. If we looked at the errors encountered in the machine translation of complex sentences, we saw that most errors were associated with verbs. When translating complex sentences, the verb form was not preserved, which is very important for the semantic connection of sentences. The following tasks were performed to solve this kind of problem:
- -
- A corpus of complex sentences was assembled, aligned in parallel in English, Kazakh, Russian, and Kazakh;
- -
- Development and implementation of an algorithm for determining the type of complex sentences for post-editing Russian-Kazakh and English-Kazakh machine translation;
- -
- Development and implementation of an algorithm for post-editing complex sentences of Russian-Kazakh and English-Kazakh machine translation.
Many machine translation systems (except Google and Yandex) still lag in terms of the quality of the translation of complex sentences. As a result of translation in such systems, the structure of a complex sentence collapses and loses its main meaning. To eliminate this kind of problem, you must implement machine learning technology. At this time, the corpus (data) is being collected and supplemented for application to machine learning technologies. More specifically, in the future, we are going to connect the use of a recurrent neural network to the rule-based approach. Work is also underway to create dictionaries to connect to machine learning to edit semantic inconsistencies in Russian-Kazakh and English-Kazakh translations. In the future, the analysis and application of the approach developed by the authors can be applied to related languages, such as Kyrgyz, Tatar, Turkish, etc.
Author Contributions
Research of theme, A.T. (Aliya Turganbayeva) and D.R.; formal analysis, A.T. (Aliya Turganbayeva); methodology, A.T. (Aliya Turganbayeva); realization, A.T. (Aliya Turganbayeva); collection of corpora for experiments, A.T. (Aliya Turganbayeva), A.K. and A.T. (Asem Turarbek); writing—original draft preparation, A.T. (Aliya Turganbayeva); writing—review and editing, V.K.; project administration, D.R. All authors have read and agreed to the published version of the manuscript.
Funding
This research was performed and financed by the Ministry of Science and Higher Education of the Republic of Kazakhstan within the framework of the АР 09259556 scientific project.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare that they have no conflict of interest to report regarding the present study.
References
- Yamamoto, Y.; Matsumoto, Y.; Watanabe, T. Dependency patterns of complex sentences and semantic disambiguation for abstract meaning representation parsing. Proceedings of *SEM 2021: The Tenth Joint Conference on Lexical and Computational Semantics, Association for Computational Linguistics, Bangkok, Thailand, 5–6 August 2021; pp. 212–221. [Google Scholar]
- Skrebova, E.G.; Pavlova, Y.E.; Sidorova, N.V. To the question of the influence of linking language means on subordinate relations structuring in a complex sentence (based on the material of the Russian and German languages). Russ. Linguist. Bull. 2020, 23, 61–66. [Google Scholar]
- Yeskermessova, G.A.; Yermekova, T.N.; Zhubaeva, O.S.; Maukanuly, T.; Kenzhekanova, K.K. Communicative and pragmatic function of punctuation. Man India 2017, 97, 265–284. [Google Scholar]
- Qodirova, B.I. Comparison of combined sentences (on the example of Uzbek and Kazakh school textbooks). Pindus J. Cult. Lit. ELT 2021, 9, 96–99. [Google Scholar]
- Luchkova, G.D.; Altayeva, A.K.; Buzhelo, A.S. Semantics and translation of conditional patterns from Kazakh into English and their usage in the language and speech. Mod. Sci. Res. Pract. Appl. 2013, 11311, 126–149. [Google Scholar]
- Amanzholov, S. Sarsen Amanzholov’s Research in the Field of Syntax. 2013. Available online: https://www.referat911.ru/Literatura/srsen-amanzholovty-sintaksis-salasyna-atysty/223386-2436719-place7.html (accessed on 22 May 2022).
- Dubrovina, M.E. The absence of Turkic complex sentences as a consequence of the internal structure of agglutinative languages [Отсутствие тюркских сложноподчиненных предложений как следствие внутреннего устройства агглютинативных языков]. RUDN J. Lang. Stud. Semiot. Semant. 2017, 8, 563–570. (In Russian) [Google Scholar] [CrossRef]
- Naber, D. A Rule-Based Style and Grammar Checker. Bachelor’s Thesis, University of Bielefeld, Bielefeld, Germany, 2003. [Google Scholar]
- Sidorov, G.; Gupta, A.; Tozer, M.; Catala, D.; Catena, A.; Fuentes, S. Rule-based system for automatic grammar correction using syntactic n-grams for English language learning (L2). In Proceedings of the Seventeenth Conference on Computational Natural Language Learning: Shared Task, Association for Computational Linguistics, Sofia, Bulgaria, 8–9 August 2013; pp. 96–101. [Google Scholar]
- Chodorow, M.; Tetreault, J.R.; Han, N. Detection of grammatical errors involving prepositions. In Proceedings of the fourth ACL-SIGSEM workshop on prepositions, Association for Computational Linguistics, Prague, Czech Republic, 28 June 2007; pp. 25–30. [Google Scholar]
- Rozovskaya, A.; Roth, D. Grammar error correction in morphologically rich languages: The case of Russian. Trans. Assoc. Comput. Linguist. 2019, 7, 1–17. [Google Scholar] [CrossRef]
- Ahmadnia, B.; Dorr, B.J. Augmenting neural machine translation through round-trip training approach. Open Comput. Sci. 2019, 9, 268–278. [Google Scholar] [CrossRef]
- Ahmadnia, B.; Aranovich, R.; Dorr, B. Strengthening Low-resource Neural Machine Translation through Joint Learning: The Case of Farsi-Spanish. In Proceedings of the 13th International Conference on Agents and Artificial Intelligence (ICAART 2021), Vienna, Austria, 4–6 February 2021; pp. 475–481. Available online: https://www.scitepress.org/Link.aspx?doi=10.5220/0010362604750481 (accessed on 22 May 2022).
- Kuwanto, G.; Feyza Akyürek, A.; Chara Tourni, I.; Li, S.; Jones, A.G.; Wijaya, D. Low-Resource Machine Translation Training Curriculum Fit for Low-Resource Languages. arXiv 2021, arXiv:2103.13272. [Google Scholar]
- Bekmanova, G.; Yergesh, B.; Sharipbay, A.; Omarbekova, A.; Zakirova, A. Linguistic Foundations of Low-Resource Languages for Speech Synthesis on the Example of the Kazakh Language. In Computational Science and Its Applications—ICCSA 2022 Workshops; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2022; Volume 13379. [Google Scholar]
- Vania, C.; Kementchedjhieva, Y.; Søgaard, A.; Lopez, A. A systematic comparison of methods for low-resource dependency parsing on genuinely low-resource languages. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 5–7 November 2019; pp. 1105–1116. [Google Scholar]
- Washington, J.N.; Salimzyanov, I.; Tyers, F.M. Finite-state morphological transducers for three Kypchak languages. In Proceedings of the 9th Conference on Language Resources and Evaluation, LREC2014, Reykjavik, Iceland, 26–31 May 2014; pp. 3378–3385. [Google Scholar]
- Development of a Free/Open System of Machine Translation from Kazakh into English and Russian (and Vice Versa) Based on the Apertium Platform: Research Report (Final)/Leader; Tukeyev U.A.: Almaty, Kazakhstan, 2017; 77p, No. GR 0115RK00778. (In Russian)
- Tukeyev, U.; Amirova, D.; Karibayeva, A.; Sundetova, A.; Abduali, B. Combined Technology of Lexical Selection in Rule-Based Machine Translation. In Computational Collective Intelligence; Nguyen, N., Papadopoulos, G., Jędrzejowicz, P., Trawiński, B., Vossen, G., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2017; Volume 10449. [Google Scholar] [CrossRef]
- NLP-KazNU. Available online: https://github.com/NLP-KazNU/KazCorpus_Compound_and_Complex_Sentences (accessed on 13 June 2022).
- Coughlin, D. Correlating Automated and Human Assessments of Machine Translation Quality. In Proceedings of the Machine Translation Summit IX: Papers, New Orleans, LA, USA, 23–27 September 2003; pp. 23–27. [Google Scholar]
- Koehn, P. Statistical Machine Translation; Cambridge University Press: Cambridge, UK, 2010. [Google Scholar]
- Snover, M.; Dorr, B.; Schwartz, R.; Micciulla, L.; Makhoul, J. A study of translation edit rate with targeted human annotation. In Proceedings of the 7th Conference of the Association for Machine Translation of the Americas (AMTA 2006), Visions for the Future of Machine Translation, Cambridge, MA, USA, 8–12 August 2006; pp. 223–231. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).