
Attentive Generative Adversarial Network with Dual Encoder-Decoder for Shadow Removal


Abstract
:1. Introduction
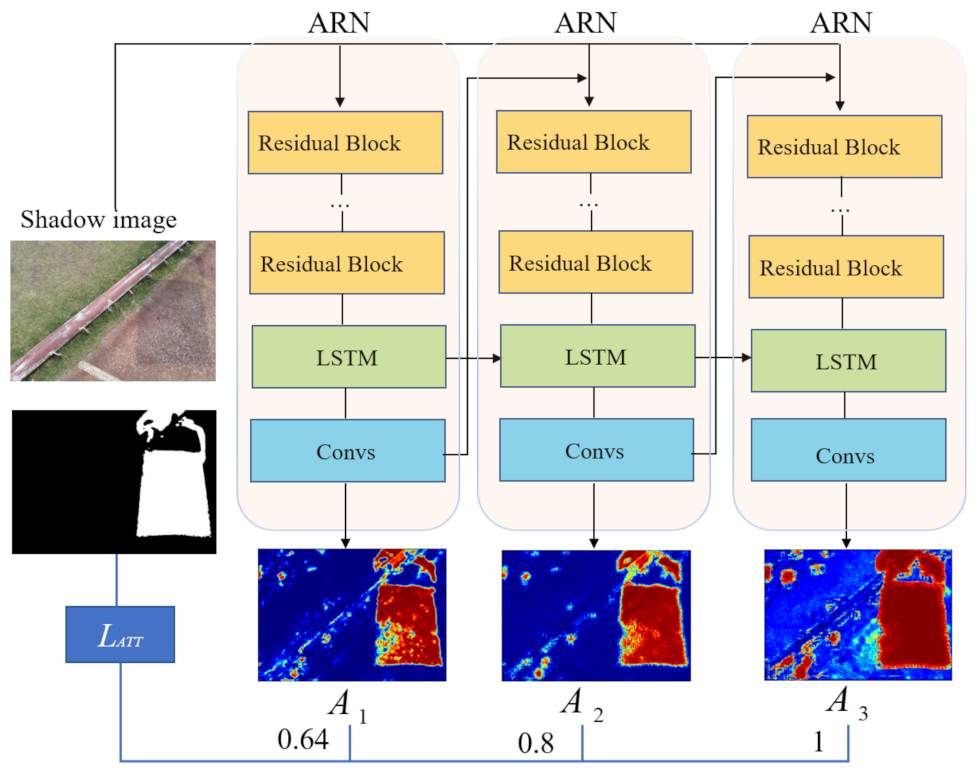
- We design a two-stage network, in which the result of shadow detection is regarded as the attention map to guide the shadow removal. In particular, the attention map is used to compute the spatial variance loss [12] so that the network can focus more on shadows.
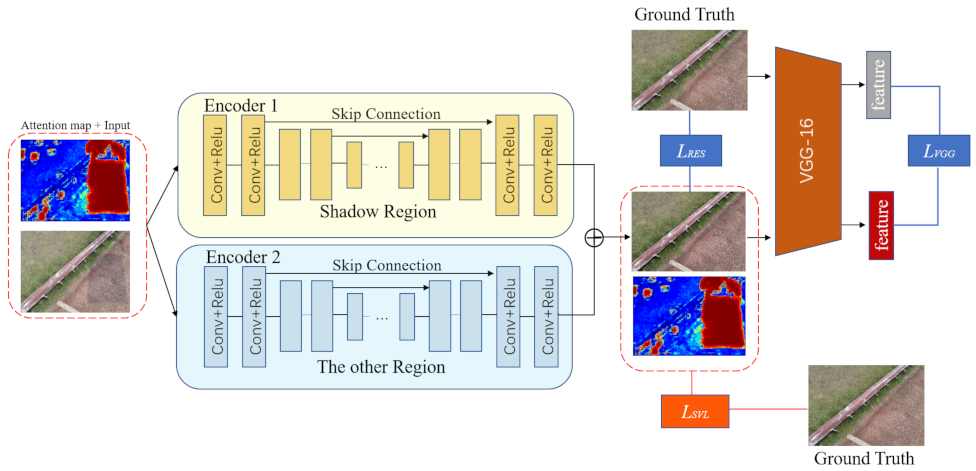
- Novel dual encoder-decoder modules are proposed to process shadowed regions and shadow-free regions separately in order to reduce the inconsistency. The input of encoder-decoder modules is the concatenation of the attention map and shadowed image.
- A feature-level perceptual loss is applied to ensure the similarity between the generated image and the ground truth.
2. Related Work
2.1. Shadow Detection
2.2. Shadow Removal
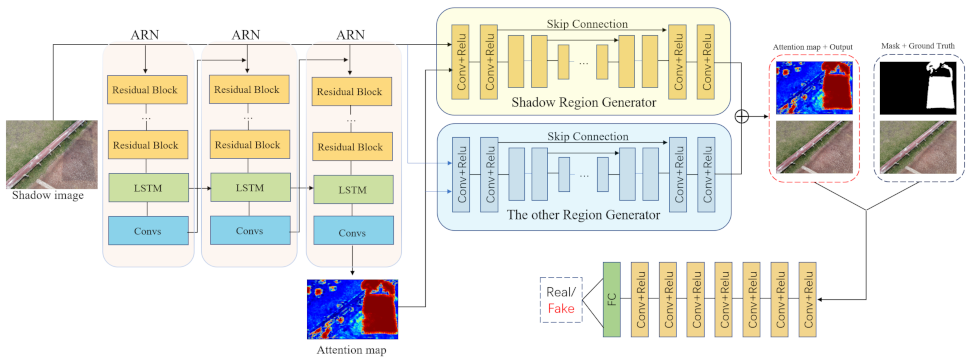
3. Proposed Method
3.1. Generative Netwoks
3.1.1. Attentive-Recurrent Network
3.1.2. Contextual Encoder
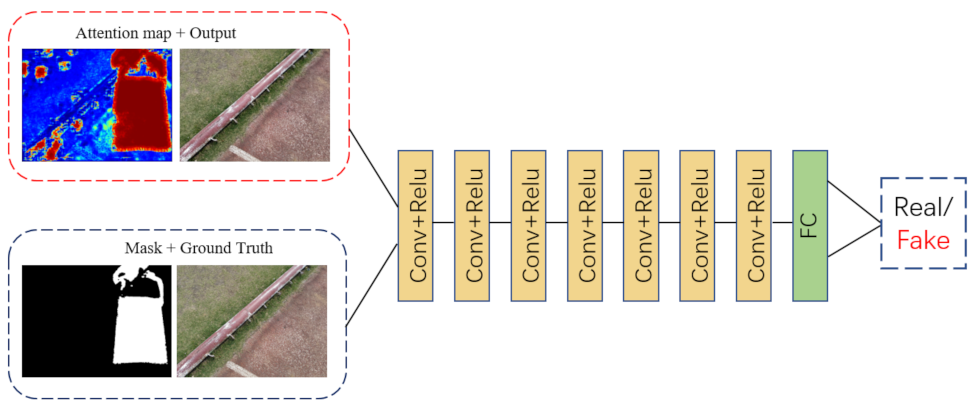
3.2. Discriminative Network
3.3. Implement Details
4. Experiments
4.1. Dataset
4.2. Evaluation Metrics
4.3. Results Comparison
4.3.1. Qualitative and Quantitative Evaluation
4.3.2. Ablation Study
4.4. Discussion
4.4.1. Application
4.4.2. Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Simonelli, A.; Bulo, S.R.; Porzi, L.; Antequera, M.L.; Kontschieder, P. Disentangling Monocular 3D Object Detection: From Single to Multi-Class Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 1219–1231. [Google Scholar] [CrossRef] [PubMed]
- Ong, J.; Vo, B.T.; Vo, B.N.; Kim, D.Y.; Nordholm, S. A Bayesian Filter for Multi-View 3D Multi-Object Tracking With Occlusion Handling. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 2246–2263. [Google Scholar] [CrossRef] [PubMed]
- Gryka, M.; Terry, M.; Brostow, G.J. Learning to remove soft shadows. ACM Trans. Graph. (TOG) 2015, 34, 1–15. [Google Scholar] [CrossRef]
- Guo, R.; Dai, Q.; Hoiem, D. Paired regions for shadow detection and removal. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 2956–2967. [Google Scholar] [CrossRef] [PubMed]
- Khan, S.H.; Bennamoun, M.; Sohel, F.; Togneri, R. Automatic shadow detection and removal from a single image. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 431–446. [Google Scholar] [CrossRef] [PubMed]
- Vicente, T.F.Y.; Hoai, M.; Samaras, D. Leave-one-out kernel optimization for shadow detection and removal. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 682–695. [Google Scholar] [CrossRef] [PubMed]
- Hu, X.; Zhu, L.; Fu, C.-W.; Qin, J.; Heng, P.-A. Direction-aware spatial context features for shadow detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 June 2018; pp. 7454–7462. [Google Scholar]
- Inoue, N.; Yamasaki, T. Deshadownet: Learning from Synthetic Shadows for Shadow Detection and Removal. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 4187–4197. [Google Scholar] [CrossRef]
- Wang, J.; Li, X.; Yang, J. Stacked conditional generative adversarial networks for jointly learning shadow detection and shadow removal. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 June 2018; pp. 1788–1797. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.-Y.; Wong, W.-K.; Woo, W.-C. Convolutional lstm network: A machine learning approach for precipitation nowcasting. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–10 December 2015; pp. 802–810. [Google Scholar]
- Wang, Y.; Tao, X.; Qi, X.; Shen, X.; Jia, J. Image inpainting via generative multi-column convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 331–340. [Google Scholar]
- Finlayson, G.D.; Hordley, S.D.; Lu, C.; Drew, M.S. On the removal of shadows from images. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 59–68. [Google Scholar] [CrossRef] [PubMed]
- Finlayson, G.D.; Drew, M.S.; Lu, C. Entropy minimization for shadow removal. Int. J. Comput. Vis. 2009, 85, 35–57. [Google Scholar] [CrossRef]
- Tian, J.; Qi, X.; Qu, L.; Tang, Y. New spectrum ratio properties and features for shadow detection. Pattern Recognit. 2016, 51, 85–96. [Google Scholar] [CrossRef]
- Lalonde, J.-F.; Efros, A.A.; Narasimhan, S.G. Detecting ground shadows in outdoor consumer photographs. In Proceedings of the European Conference on Computer Vision, Crete, Greece, 5–11 September 2010; pp. 322–335. [Google Scholar]
- Guo, R.; Dai, Q.; Hoiem, D. Single-image shadow detection and removal using paired regions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 21–23 June 2011; pp. 2033–2040. [Google Scholar]
- Vicente, Y.; Tomas, F.; Hoai, M.; Samaras, D. Leave-one-out kernel optimization for shadow detection. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 3388–3396. [Google Scholar]
- Zhu, J.; Samuel, K.G.; Masood, S.Z.; Tappen, M.F. Learning to recognize shadows in monochromatic natural images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 223–230. [Google Scholar]
- Huang, X.; Hua, G.; Tumblin, J.; Williams, L. What characterizes a shadow boundary under the sun and sky? In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 898–905. [Google Scholar]
- Le, H.; Vicente, Y.; Tomas, F.; Nguyen, V.; Hoai, M.; Samaras, D. A+d net: Training a shadow detector with adversarial shadow attenuation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 662–678. [Google Scholar]
- Zheng, Q.; Qiao, X.; Cao, Y.; Lau, R. Distraction-Aware Shadow Detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5162–5171. [Google Scholar]
- Zhu, L.; Deng, Z.; Hu, X.; Fu, C.-W.; Xu, X.; Qin, J.; Heng, P.-A. Bidirectional feature pyramid network with recurrent attention residual modules for shadow detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 121–136. [Google Scholar]
- Nguyen, V.; Vicente, T.F.Y.; Zhao, M.; Hoai, M.; Samaras, D. Shadow detection with conditional generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4520–4528. [Google Scholar]
- Wang, Y.; Zhao, X.; Li, Y.; Hu, X.; Huang, K.; Cripac, N. Densely cascaded shadow detection network via deeply supervised parallel fusion. In Proceedings of the IJCAI, Stockholm, Sweden, 13–19 July 2018; pp. 1007–1013. [Google Scholar]
- Khan, S.H.; Bennamoun, M.; Sohel, F.; Togneri, R. Automatic feature learning for robust shadow detection. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1939–1946. [Google Scholar]
- Vicente, T.F.Y.; Hou, L.; Yu, C.-P.; Hoai, M.; Samaras, D. Large-scale training of shadow detectors with noisily-annotated shadow examples. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 816–832. [Google Scholar]
- Hu, X.; Zhu, L.; Fu, C.-W.; Qin, J.; Heng, P.-A. Direction-Aware Spatial Context Features for Shadow Detection and Removal. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2795–2808. [Google Scholar] [CrossRef]
- Sahoo, S.; Nanda, P.K. Adaptive Feature Fusion and Spatio-Temporal Background Modeling in KDE Framework for Object Detection and Shadow Removal. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 1103–1118. [Google Scholar] [CrossRef]
- Liu, Z.; Yin, H.; Mi, Y.; Pu, M.; Wang, S. Shadow Removal by a Lightness-Guided Network With Training on Unpaired Data. IEEE Trans. Image Process. 2021, 30, 1853–1865. [Google Scholar] [CrossRef] [PubMed]
- Fu, L.; Zhou, C.; Guo, Q.; Xu, F.; Yu, H.; Feng, W.; Liu, Y.; Wang, S. Auto-Exposure Fusion for Single-Image Shadow Removal. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 10571–10580. [Google Scholar]
- Chen, Z.; Long, C.; Zhang, L.; Xiao, C. CANet: A Context-Aware Network for Shadow Removal. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 4723–4732. [Google Scholar]
- Wang, Z.; Bovik, A.C. Mean squared error: Love it or leave it? A new look at signal fidelity measures. IEEE Signal Process. Mag. 2009, 26, 98–117. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.-F. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Gong, H.; Cosker, D. Interactive shadow removal and ground truth for vari-able scene categories. In Proceedings of the BMVC, Nottingham, UK, 1–5 September 2014; pp. 1–11. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | PSNR | SSIM |
|---|---|---|
| Gong et al. [37] | 19.89 | 0.6103 |
| DSC [7] | 23.07 | 0.8639 |
| ST-CGAN [9] | 23.63 | 0.8568 |
| Our Method | 23.71 | 0.8846 |
| Methods | PSNR | SSIM |
|---|---|---|
| O | 20.30 | 0.8174 |
| O+A | 21.01 | 0.8625 |
| T | 20.52 | 0.8570 |
| T+A (Our Method) | 23.71 | 0.8846 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; Zou, H.; Zhang, D. Attentive Generative Adversarial Network with Dual Encoder-Decoder for Shadow Removal. Information 2022, 13, 377. https://doi.org/10.3390/info13080377
Wang H, Zou H, Zhang D. Attentive Generative Adversarial Network with Dual Encoder-Decoder for Shadow Removal. Information. 2022; 13(8):377. https://doi.org/10.3390/info13080377
Chicago/Turabian StyleWang, He, Hua Zou, and Dengyi Zhang. 2022. "Attentive Generative Adversarial Network with Dual Encoder-Decoder for Shadow Removal" Information 13, no. 8: 377. https://doi.org/10.3390/info13080377
APA StyleWang, H., Zou, H., & Zhang, D. (2022). Attentive Generative Adversarial Network with Dual Encoder-Decoder for Shadow Removal. Information, 13(8), 377. https://doi.org/10.3390/info13080377